


Journal of Computer Applications ›› 2026, Vol. 46 ›› Issue (2): 341-353.DOI: 10.11772/j.issn.1001-9081.2025030273
• Artificial intelligence •
Xue WANG, Liping ZHANG( ), Sheng YAN, Na LI, Xuefei ZHANG
), Sheng YAN, Na LI, Xuefei ZHANG
Received:2025-03-18
Revised:2025-05-22
Accepted:2025-05-26
Online:2025-06-12
Published:2026-02-10
Contact:
Liping ZHANG
About author:WANG Xue, born in 2001, M. S. candidate. Her research interests include educational data mining.Supported by:
王雪, 张丽萍(), 闫盛, 李娜, 张学飞
通讯作者:
张丽萍
作者简介:王雪(2001—),女,内蒙古巴彦淖尔人,硕士研究生,主要研究方向:教育数据挖掘基金资助:CLC Number:
Xue WANG, Liping ZHANG, Sheng YAN, Na LI, Xuefei ZHANG. Review of multi-modal knowledge graph completion methods[J]. Journal of Computer Applications, 2026, 46(2): 341-353.
王雪, 张丽萍, 闫盛, 李娜, 张学飞. 多模态知识图谱补全方法综述[J]. 《计算机应用》唯一官方网站, 2026, 46(2): 341-353.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2025030273
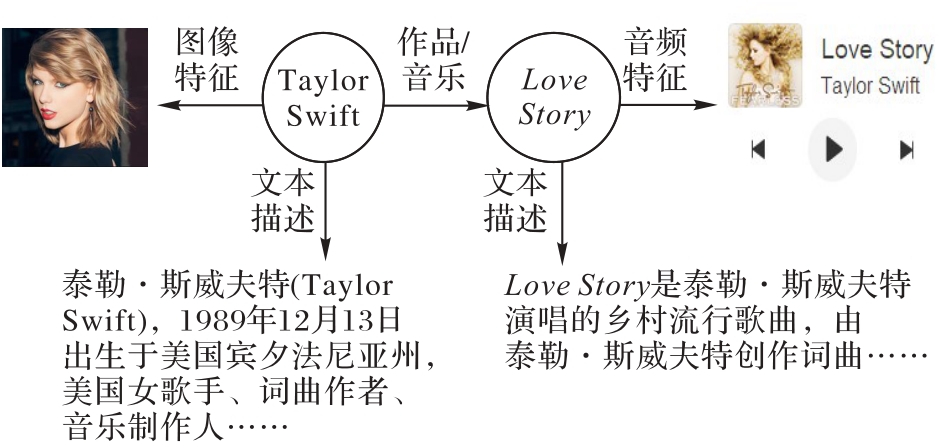
Fig. 1 Example of multi-modal knowledge graph
| 知识图谱分类 | 举例 | 特点 | 应用场景 |
|---|---|---|---|
| 通用知识图谱 | Google Knowledge Graph[ | 整合来自不同来源的信息,包括实体、属性和关系,旨在提高搜索结果的相关性和丰富性 | 自然语言处理中的文本分类、问答系统 |
| 领域知识图谱 | ScholarlyKG[ | 包含学术论文、作者、会议和期刊之间的关系,用于支持学术研究和文献检索 | 教育领域的个性化学习路径规划和教学资源推荐 |
| 常识知识图谱 | ConceptNet[ | 包含大量描述日常概念之间关系的常识性陈述 | 智能搜索中结合常识优化搜索结果 |
| 百科全书型知识图谱 | DBpedia[ | 包含维基百科中的大量实体及其属性,覆盖广泛主题 | 搜索引擎中提供更丰富、准确的搜索结果 |
| 多模态知识图谱 | Visual Genome[ | 包含图像中的视觉实体和它们之间的关系,以及与文本描述的对应关系 | 视觉问答、图像分类 |
Tab. 1 Knowledge graph classification
| 知识图谱分类 | 举例 | 特点 | 应用场景 |
|---|---|---|---|
| 通用知识图谱 | Google Knowledge Graph[ | 整合来自不同来源的信息,包括实体、属性和关系,旨在提高搜索结果的相关性和丰富性 | 自然语言处理中的文本分类、问答系统 |
| 领域知识图谱 | ScholarlyKG[ | 包含学术论文、作者、会议和期刊之间的关系,用于支持学术研究和文献检索 | 教育领域的个性化学习路径规划和教学资源推荐 |
| 常识知识图谱 | ConceptNet[ | 包含大量描述日常概念之间关系的常识性陈述 | 智能搜索中结合常识优化搜索结果 |
| 百科全书型知识图谱 | DBpedia[ | 包含维基百科中的大量实体及其属性,覆盖广泛主题 | 搜索引擎中提供更丰富、准确的搜索结果 |
| 多模态知识图谱 | Visual Genome[ | 包含图像中的视觉实体和它们之间的关系,以及与文本描述的对应关系 | 视觉问答、图像分类 |
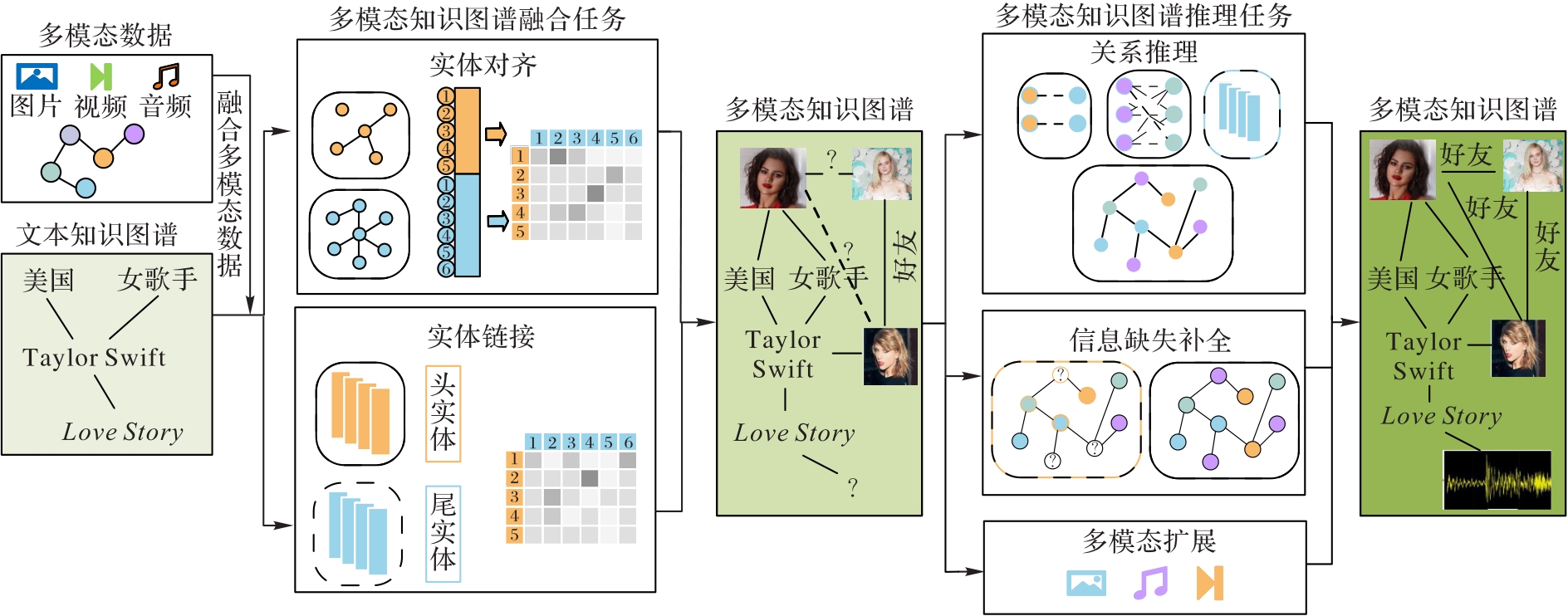
Fig. 2 Construction process of MMKG
| 数据集 | 关系数 | 实体数 | 图像数 | 训练集样本数 | 验证集样本数 | 测试集样本数 |
|---|---|---|---|---|---|---|
| WN9 | 9 | 6 555 | 6 547 | 11 741 | 1 337 | 1 319 |
| FB-IMG | 1 231 | 11 757 | 13 000 | 285 850 | 29 580 | 34 864 |
| FB15K | 1 345 | 14 951 | 13 444 | 414 549 | 59 221 | 118 443 |
| FB15K-237 | 237 | 14 541 | 14 297 | 272 115 | 17 535 | 20 466 |
| WN18RR | 11 | 40 943 | — | 86 835 | 3 034 | 3 134 |
| DB15K | 279 | 14 777 | 13 000 | 69 319 | 9 903 | 19 806 |
| YAGO15K | 32 | 15 404 | 11 194 | 86 020 | 12 289 | 24 577 |
| MKG-W | 169 | 15 000 | 14 463 | 34 196 | 4 276 | 4 274 |
| MKG-Y | 28 | 15 000 | 14 244 | 21 310 | 2 665 | 2 663 |
| KVC16K | 4 | 16 015 | 14 822 | 180 190 | 22 523 | 22 525 |
Tab. 2 Common benchmark datasets
| 数据集 | 关系数 | 实体数 | 图像数 | 训练集样本数 | 验证集样本数 | 测试集样本数 |
|---|---|---|---|---|---|---|
| WN9 | 9 | 6 555 | 6 547 | 11 741 | 1 337 | 1 319 |
| FB-IMG | 1 231 | 11 757 | 13 000 | 285 850 | 29 580 | 34 864 |
| FB15K | 1 345 | 14 951 | 13 444 | 414 549 | 59 221 | 118 443 |
| FB15K-237 | 237 | 14 541 | 14 297 | 272 115 | 17 535 | 20 466 |
| WN18RR | 11 | 40 943 | — | 86 835 | 3 034 | 3 134 |
| DB15K | 279 | 14 777 | 13 000 | 69 319 | 9 903 | 19 806 |
| YAGO15K | 32 | 15 404 | 11 194 | 86 020 | 12 289 | 24 577 |
| MKG-W | 169 | 15 000 | 14 463 | 34 196 | 4 276 | 4 274 |
| MKG-Y | 28 | 15 000 | 14 244 | 21 310 | 2 665 | 2 663 |
| KVC16K | 4 | 16 015 | 14 822 | 180 190 | 22 523 | 22 525 |
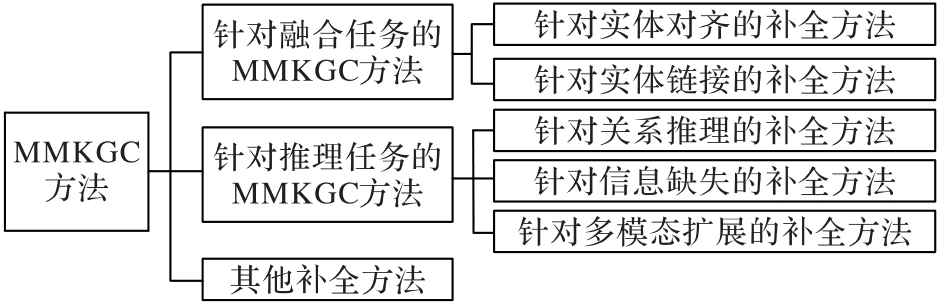
Fig. 3 Classification of MMKGC methods
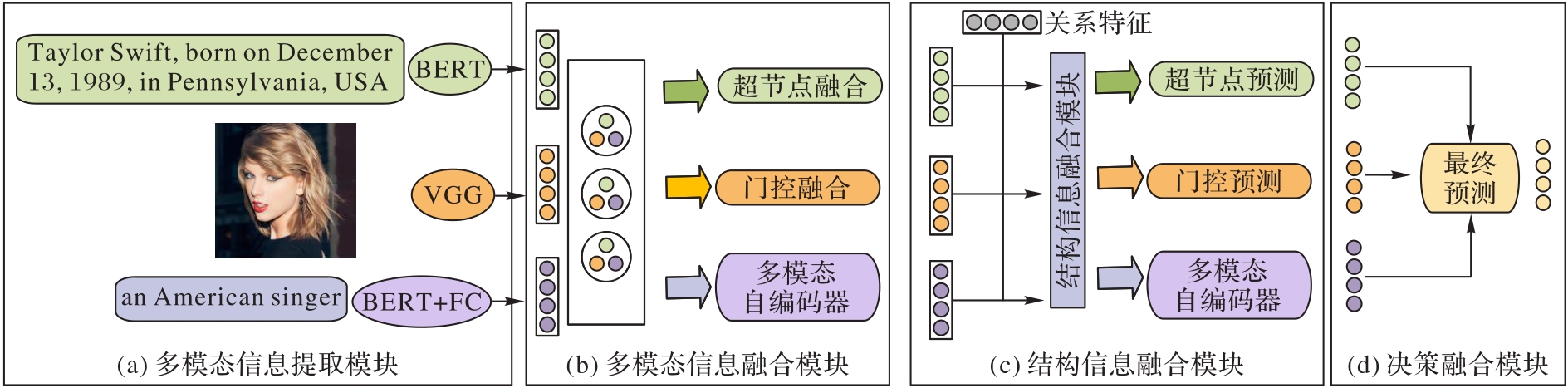
Fig. 4 MFKGC model
| 任务 | 方法 | 特点 |
|---|---|---|
| 实体对齐 | TransAE[ | 引入自编码器来捕捉模态内部和跨模态的语义特征,提升知识图谱补全的效果 |
| VBKGC[ | 通过对负样本生成和模态对齐进行优化,提升多模态知识图谱补全的性能 | |
| MANS[ | 通过模态感知负采样策略,以轻量、高效的方式增强多模态嵌入的模态对齐能力 | |
| TriFac[ | 充分利用结构信息,通过有效的多模态融合提高实体匹配的准确性 | |
| HKA[ | 通过模态特征提取与融合和层次化对齐机制解决模态信息不对齐问题 | |
| IMF[ | 采用基于TuckER分解的双线性融合机制挖掘模态间复杂交互 | |
| 融合任务知识的MMKGC方法[ | 通过任务知识嵌入、模态过滤和同构图建模,结合高效解码器实现任务相关的多模态特征提取与知识图谱补全,提升了模型的任务适应性和预测性能 | |
| HyperRep[ | 通过超图建模优化多模态数据融合并减少信息冗余 | |
| MM-Transformer[ | 通过提取结构、视觉和文本特征,在Transformer框架中进行深度融合 | |
| PABEA[ | 利用图像置信度评估不同图像的重要性,实现更稳健的多模态实体对齐 | |
| 实体链接 | MKBE[ | 通过引入神经网络编码器和解码器,在链路预测任务中显著提升准确率 |
| CamE[ | 通过TCA提取多模态间的共通语义特征,提升多模态信息融合和表示能力 | |
| MKGformer[ | 采用多级融合机制解决模态异质性和噪声问题,具有良好的任务适配性和鲁棒性 | |
| 多级融合知识图谱补全模型[ | 采用多种融合方法提升特征提取效果,缓解信息丢失,并通过特征泛化和重塑增强结构信息融合优化预测性能 | |
| MMCL[ | 通过生成对抗网络融合多模态信息与知识图谱节点,提升三元组真伪判别能力 |
Tab. 3 MMKGC methods for fusion task
| 任务 | 方法 | 特点 |
|---|---|---|
| 实体对齐 | TransAE[ | 引入自编码器来捕捉模态内部和跨模态的语义特征,提升知识图谱补全的效果 |
| VBKGC[ | 通过对负样本生成和模态对齐进行优化,提升多模态知识图谱补全的性能 | |
| MANS[ | 通过模态感知负采样策略,以轻量、高效的方式增强多模态嵌入的模态对齐能力 | |
| TriFac[ | 充分利用结构信息,通过有效的多模态融合提高实体匹配的准确性 | |
| HKA[ | 通过模态特征提取与融合和层次化对齐机制解决模态信息不对齐问题 | |
| IMF[ | 采用基于TuckER分解的双线性融合机制挖掘模态间复杂交互 | |
| 融合任务知识的MMKGC方法[ | 通过任务知识嵌入、模态过滤和同构图建模,结合高效解码器实现任务相关的多模态特征提取与知识图谱补全,提升了模型的任务适应性和预测性能 | |
| HyperRep[ | 通过超图建模优化多模态数据融合并减少信息冗余 | |
| MM-Transformer[ | 通过提取结构、视觉和文本特征,在Transformer框架中进行深度融合 | |
| PABEA[ | 利用图像置信度评估不同图像的重要性,实现更稳健的多模态实体对齐 | |
| 实体链接 | MKBE[ | 通过引入神经网络编码器和解码器,在链路预测任务中显著提升准确率 |
| CamE[ | 通过TCA提取多模态间的共通语义特征,提升多模态信息融合和表示能力 | |
| MKGformer[ | 采用多级融合机制解决模态异质性和噪声问题,具有良好的任务适配性和鲁棒性 | |
| 多级融合知识图谱补全模型[ | 采用多种融合方法提升特征提取效果,缓解信息丢失,并通过特征泛化和重塑增强结构信息融合优化预测性能 | |
| MMCL[ | 通过生成对抗网络融合多模态信息与知识图谱节点,提升三元组真伪判别能力 |
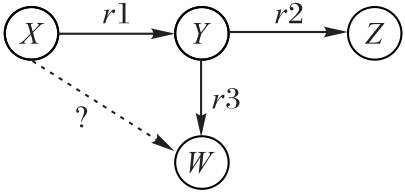
Fig. 5 Schematic diagram ofrelationship inference
| 任务 | 方法 | 特点 |
|---|---|---|
| 关系推理 | IKRL[ | 通过结合图像和知识图谱的结构化信息,提升关系推理的范围和可解释性 |
| MMRNS[ | 通过关系嵌入指导视觉和文本特征的注意力分配,提升语义表示和关系推理能力 | |
| TE-TFN[ | 充分整合上下文路径和多模态信息,提升模型的可解释性和鲁棒性 | |
| MMKGR[ | 结合统一门控注意力网络和感知互补特征的强化学习框架,提升有效性和鲁棒性 | |
| HPMG, HPMG+[ | HPMG方法通过从粗粒度和细粒度两个层面学习多元关系的整体性,最终通过加权求和融合;优化方法HPMG+引入了基于注意力机制的多特征融合方法 | |
| CMR[ | 充分利用语义邻居的语义相似性,显著提升了对未见实体的泛化能力和推理性能 | |
| LAFA[ | 通过结合视觉与结构信息生成实体嵌入,缓解模态矛盾和结构信息丢失的问题 | |
| MR-MKG[ | 使用关系图注意网络编码知识图,捕捉复杂结构和关系,增强模型的推理能力 | |
| 信息缺失 | KBLRN[ | 利用逻辑公式捕捉关系特征,提升复杂知识推理的高效性和鲁棒性 |
| HRGAT[ | 使用预训练模型提取文本、视觉和数值模态的信息,充分捕获结构信息 | |
| MoSE[ | 通过模态分离学习和集成推理缓解模态干扰和模态权重忽视的问题 | |
| MACO[ | 通过模态对抗生成与结构信息一致的视觉特征,解决模态缺失问题 | |
| NativE[ | 结合关系引导的双自适应融合机制和协同模态对抗训练策略,解决模态不平衡问题 | |
| MKGE-MDI[ | 通过双阶段图注意力网络,对模态信息进行加权融合,高效处理缺失数据 | |
| KoPA[ | 通过结构嵌入与LLM之间的交互,以增强该方法的推理能力 | |
| MMKG-T5[ | 充分利用多模态知识图谱的结构特性,通过邻居的上下文信息增强推理能力 | |
| 多模态扩展 | CLIP[ | 利用图像和文本嵌入,结合超节点表示和关系图注意力机制有效补充缺失的信息 |
| RSME[ | 筛选与实体相关的图像,确保视觉模态在适当的关系情境下发挥作用,同时避免噪声的干扰 | |
| TIVA-KG[ | 通过将多模态信息直接关联到完整的三元组,实现对符号化知识的精准表达,提升模型的鲁棒性与泛化能力 |
Tab. 4 MMKGC methods for inference task
| 任务 | 方法 | 特点 |
|---|---|---|
| 关系推理 | IKRL[ | 通过结合图像和知识图谱的结构化信息,提升关系推理的范围和可解释性 |
| MMRNS[ | 通过关系嵌入指导视觉和文本特征的注意力分配,提升语义表示和关系推理能力 | |
| TE-TFN[ | 充分整合上下文路径和多模态信息,提升模型的可解释性和鲁棒性 | |
| MMKGR[ | 结合统一门控注意力网络和感知互补特征的强化学习框架,提升有效性和鲁棒性 | |
| HPMG, HPMG+[ | HPMG方法通过从粗粒度和细粒度两个层面学习多元关系的整体性,最终通过加权求和融合;优化方法HPMG+引入了基于注意力机制的多特征融合方法 | |
| CMR[ | 充分利用语义邻居的语义相似性,显著提升了对未见实体的泛化能力和推理性能 | |
| LAFA[ | 通过结合视觉与结构信息生成实体嵌入,缓解模态矛盾和结构信息丢失的问题 | |
| MR-MKG[ | 使用关系图注意网络编码知识图,捕捉复杂结构和关系,增强模型的推理能力 | |
| 信息缺失 | KBLRN[ | 利用逻辑公式捕捉关系特征,提升复杂知识推理的高效性和鲁棒性 |
| HRGAT[ | 使用预训练模型提取文本、视觉和数值模态的信息,充分捕获结构信息 | |
| MoSE[ | 通过模态分离学习和集成推理缓解模态干扰和模态权重忽视的问题 | |
| MACO[ | 通过模态对抗生成与结构信息一致的视觉特征,解决模态缺失问题 | |
| NativE[ | 结合关系引导的双自适应融合机制和协同模态对抗训练策略,解决模态不平衡问题 | |
| MKGE-MDI[ | 通过双阶段图注意力网络,对模态信息进行加权融合,高效处理缺失数据 | |
| KoPA[ | 通过结构嵌入与LLM之间的交互,以增强该方法的推理能力 | |
| MMKG-T5[ | 充分利用多模态知识图谱的结构特性,通过邻居的上下文信息增强推理能力 | |
| 多模态扩展 | CLIP[ | 利用图像和文本嵌入,结合超节点表示和关系图注意力机制有效补充缺失的信息 |
| RSME[ | 筛选与实体相关的图像,确保视觉模态在适当的关系情境下发挥作用,同时避免噪声的干扰 | |
| TIVA-KG[ | 通过将多模态信息直接关联到完整的三元组,实现对符号化知识的精准表达,提升模型的鲁棒性与泛化能力 |
| [1] | SINGHAL A. Introducing the knowledge graph[EB/OL]. [2024-11-02].. |
| [2] | WANG E, YU Q, CHEN Y, et al. Multi-modal knowledge graphs representation learning via multi-headed self-attention[J]. Information Fusion, 2022, 88: 78-85. |
| [3] | 陈烨,周刚,卢记仓. 多模态知识图谱构建与应用研究综述[J]. 计算机应用研究, 2021, 38(12): 3535-3543. |
| CHEN Y, ZHOU G, LU J C. Survey on construction and application research for multi-modal knowledge graphs[J]. Application Research of Computers, 2021, 38(12): 3535-3543. | |
| [4] | 高茂,张丽萍. 融合多模态资源的教育知识图谱的内涵、技术与应用研究[J]. 计算机应用研究, 2022, 39(8): 2257-2267. |
| GAO M, ZHANG L P. Research on connotation, technology and application of educational knowledge graph based on multi-modal resources[J]. Application Research of Computers, 2022, 39(8): 2257-2267. | |
| [5] | 姚奕,陈朝阳,杜晓明,等. 多模态知识图谱构建技术及其在军事领域的应用综述[J]. 计算机工程与应用, 2024, 60(22): 18-37. |
| YAO Y, CHEN Z Y, DU X M, et al. Survey of multimodal knowledge graph construction technology and its application in military field[J]. Computer Engineering and Applications, 2024, 60(22): 18-37. | |
| [6] | ZHONG L, WU J, LI Q, et al. A comprehensive survey on automatic knowledge graph construction[J]. ACM Computing Surveys, 2024, 56(4): No.94. |
| [7] | ZHU X, LI Z, WANG X, et al. Multi-modal knowledge graph construction and application: a survey[J]. IEEE Transactions on Knowledge and Data Engineering, 2024, 36(2): 715-735. |
| [8] | LIANG W, DE MEO P, TANG Y, et al. A survey of multi-modal knowledge graphs: technologies and trends[J]. ACM Computing Surveys, 2024, 56(11): No.273. |
| [9] | 王春雷,王肖,刘凯. 多模态知识图谱表示学习综述[J]. 计算机应用, 2024, 44(1): 1-15. |
| WANG C L, WANG X, LIU K. Multimodal knowledge graph representation learning: a review[J]. Journal of Computer Applications, 2024, 44(1): 1-15. | |
| [10] | 陈囿任,李勇,温明,等. 多模态知识图谱融合技术研究综述[J]. 计算机工程与应用, 2024, 60(13): 36-50. |
| CHEN Y R, LI Y, WEN M, et al. Research and comprehensive review on multi-modal knowledge graph fusion techniques[J]. Computer Engineering and Applications, 2024, 60(13): 36-50. | |
| [11] | 时振普,吕潇,董彦如,等. 医学领域多模态知识图谱融合技术发展现状研究[J]. 计算机科学与探索, 2025, 19(7): 1729-1746. |
| SHI Z P, LYU X, DONG Y R, et al. Research on development status of multimodal knowledge graph fusion technology in the medical field[J]. Journal of Frontiers of Computer Science & Technology, 2025, 19(7): 1729-1746. | |
| [12] | LIANG K, MENG L, LIU M, et al. A survey of knowledge graph reasoning on graph types: static, dynamic, and multi-modal[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024, 46(12): 9456-9478. |
| [13] | CHEN Z, ZHANG Y, FANG Y, et al. Knowledge graphs meet multi-modal learning: a comprehensive survey[EB/OL]. [2024-11-02].. |
| [14] | CHEN Y, GE X, YANG S, et al. A survey on multimodal knowledge graphs: construction, completion and applications[J]. Mathematics, 2023, 11(8): No.1815. |
| [15] | LIU T. Multi-modal knowledge graph completion: a survey[C]// Proceedings of the 2024 International Conference on Image Processing, Machine Learning and Pattern Recognition. New York: ACM, 2024: 116-121. |
| [16] | PENG C, XIA F, NASERIPARSA M, et al. Knowledge graphs: opportunities and challenges[J]. Artificial Intelligence Review, 2023, 56(11): 13071-13102. |
| [17] | HOGAN A, BLOMQVIST E, COCHEZ M, et al. Knowledge graphs[J]. ACM Computing Surveys, 2022, 54(4): No.71. |
| [18] | ZOU X. A survey on application of knowledge graph[J]. Journal of Physics: Conference Series, 2020, 1487: No.012016. |
| [19] | HAO X, JI Z, LI X, et al. Construction and application of a knowledge graph[J]. Remote Sensing, 2021, 13(13): No.2511. |
| [20] | VERMA S, BHATIA R, HARIT S, et al. Scholarly knowledge graphs through structuring scholarly communication: a review[J]. Complex and Intelligent Systems, 2023, 9(1): 1059-1095. |
| [21] | SPEER R, CHIN J, HAVASI C. ConceptNet 5.5: an open multilingual graph of general knowledge[C]// Proceedings of the 31st AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2017: 4444-4451. |
| [22] | LEHMANN J, ISELE R, JAKOB M, et al. DBpedia: a large-scale, multilingual knowledge base extracted from Wikipedia[J]. Semantic Web — Interoperability, Usability, Applicability, 2015, 6(2): 167-195. |
| [23] | KRISHNA R, ZHU Y, GROTH O, et al. Visual Genome: connecting language and vision using crowdsourced dense image annotations[J]. International Journal of Computer Vision, 2017, 123(1): 32-73. |
| [24] | QUIROGA R Q, REDDY L, KREIMAN G, et al. Invariant visual representation by single neurons in the human brain[J]. Nature, 2005, 435(7045): 1102-1107. |
| [25] | 杜雪盈,刘名威,沈立炜,等. 面向链接预测的知识图谱表示学习方法综述[J]. 软件学报, 2024, 35(1): 87-117. |
| DU X Y, LIU M W, SHEN L W, et al. Survey on representation learning methods of knowledge graph for link prediction[J]. Journal of Software, 2024, 35(1): 87-117. | |
| [26] | XIE R, HEINRICH S, LIU Z, et al. Integrating image-based and knowledge-based representation learning[J]. IEEE Transactions on Cognitive and Developmental Systems, 2020, 12(2): 169-178. |
| [27] | MILLER G A. WordNet: a lexical database for English[J]. Communications of the ACM, 1995, 38(11): 39-41. |
| [28] | DENG J, DONG W, SOCHER R, et al. ImageNet: a large-scale hierarchical image database[C]// Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2009: 248-255. |
| [29] | MOUSSELLY-SERGIEH H, BOTSCHEN T, GUREVYCH I, et al. A multimodal translation-based approach for knowledge graph representation learning[C]// Proceedings of the 7th Joint Conference on Lexical and Computational Semantics. Stroudsburg: ACL, 2018: 225-234. |
| [30] | BOLLACKER K, EVANS C, PARITOSH P, et al. Freebase: a collaboratively created graph database for structuring human knowledge[C]// Proceedings of the 2008 ACM SIGMOD International Conference on Management of Data. New York: ACM, 2008: 1247-1250. |
| [31] | BORDES A, USUNIER N, GARCIA-DURÁN A, et al. Translating embeddings for modeling multi-relational data[C]// Proceedings of the 27th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2013: 2787-2795. |
| [32] | TOUTANOVA K, CHEN D. Observed versus latent features for knowledge base and text inference[C]// Proceedings of the 3rd Workshop on Continuous Vector Space Models and their Compositionality. Stroudsburg: ACL, 2015: 57-66. |
| [33] | DETTMERS T, MINERVINI P, STENETORP P, et al. Convolutional 2D knowledge graph embeddings[C]// Proceedings of the 32nd AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2018: 1811-1818. |
| [34] | LIU Y, LI H, GARCIA-DURAN A, et al. MMKG: multi-modal knowledge graphs[C]// Proceedings of the 2019 International Conference on Semantic Web, LNCS 11503. Cham: Springer, 2019: 459-474. |
| [35] | SUCHANEK F M, KASNECI G, WEIKUM G. YAGO: a large ontology from Wikipedia and WordNet[J]. Journal of Web Semantics, 2008, 6(3): 203-217. |
| [36] | XU D, XU T, WU S, et al. Relation-enhanced negative sampling for multimodal knowledge graph completion[C]// Proceedings of the 30th ACM International Conference on Multimedia. New York: ACM, 2022: 3857-3866. |
| [37] | ZHANG Y, CHEN Z, GUO L, et al. NativE: multi-modal knowledge graph completion in the wild[C]// Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2024: 91-101. |
| [38] | PAN H, ZHAI Z, ZHANG Y, et al. Kuaipedia: a large-scale multi-modal short-video encyclopedia[EB/OL]. [2024-10-14].. |
| [39] | WANG Z, LI L, LI Q, et al. Multimodal data enhanced representation learning for knowledge graphs[C]// Proceedings of the 2019 International Joint Conference on Neural Networks. Piscataway: IEEE, 2019: 1-8. |
| [40] | ZHANG Y, ZHANG W. Knowledge graph completion with pre-trained multimodal Transformer and twins negative sampling[EB/OL]. [2025-01-11].. |
| [41] | LI L H, YATSKAR M, YIN D, et al. VisualBERT: a simple and performant baseline for vision and language[EB/OL]. [2024-05-14].. |
| [42] | ZHANG Y, CHEN M, ZHANG W. Modality-aware negative sampling for multi-modal knowledge graph embedding[C]// Proceedings of the 2023 International Joint Conference on Neural Networks. Piscataway: IEEE, 2023: 1-8. |
| [43] | CHEN L, LI Z, XU T, et al. Multi-modal Siamese network for entity alignment[C]// Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. New York: ACM, 2022: 118-126. |
| [44] | LI Q, LI J, WU J, et al. Triplet-aware graph neural networks for factorized multi-modal knowledge graph entity alignment[J]. Neural Networks, 2024, 179: No.106479. |
| [45] | XU Y, LI Y, XU M, et al. HKA: a hierarchical knowledge alignment framework for multimodal knowledge graph completion[J]. ACM Transactions on Multimedia Computing, Communications and Applications, 2024, 20(8): No.256. |
| [46] | LI X, ZHAO X, XU J, et al. IMF: interactive multimodal fusion model for link prediction[C]// Proceedings of the ACM Web Conference 2023. New York: ACM, 2023: 2572-2580. |
| [47] | BALAŽEVIĆ I, ALLEN C, HOSPEDALES T. TuckER: tensor factorization for knowledge graph completion[C]// Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Stroudsburg: ACL, 2019: 5185-5194. |
| [48] | 陈强,张栋,李寿山,等. 融合任务知识的多模态知识图谱补全[J]. 软件学报, 2025, 36(4): 1590-1603. |
| CHEN Q, ZHANG D, LI S S, et al. Task knowledge fusion for multimodal knowledge graph completion[J]. Journal of Software, 2025, 36(4): 1590-1603. | |
| [49] | YU Y, SI X, HU C, et al. A review of recurrent neural networks: LSTM cells and network architectures[J]. Neural Computation, 2019, 31(7): 1235-1270. |
| [50] | DEY R, SALEM F M. Gate-variants of Gated Recurrent Unit (GRU) neural networks[C]// Proceedings of the IEEE 60th International Midwest Symposium on Circuits and Systems. Piscataway: IEEE, 2017: 1597-1600. |
| [51] | JIANG Y, GAO Y, ZHU Z, et al. HyperRep: hypergraph-based self-supervised multimodal representation learning[EB/OL]. [2025-01-14].. |
| [52] | WANG D, TANG K, ZENG J, et al. MM-Transformer: a Transformer-based knowledge graph link prediction model that fuses multimodal features[J]. Symmetry, 2024, 16(8): No.961. |
| [53] | HAMILTON W L, YING Z, LESKOVEC J. Inductive representation learning on large graphs[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2017: 1025-1035. |
| [54] | DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16x16 words: Transformers for image recognition at scale[EB/OL]. [2024-10-22].. |
| [55] | DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional transformers for language understanding[C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Stroudsburg: ACL, 2019: 4171-4186. |
| [56] | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2017: 6000-6010. |
| [57] | 张晓明,陈通庆,王会勇. 基于图像置信度动态引导的多模态实体对齐[J]. 计算机工程,2025,51(12):140-150. |
| ZHANG X M, CHEN T Q, WANG H Y. Dynamic guided multimodal entity alignment based on image confidence[J]. Computer Engineering,2025, 51(12): 140-150. | |
| [58] | PEZESHKPOUR P, CHEN L, SINGH S. Embedding multimodal relational data for knowledge base completion[C]// Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2018: 3208-3218. |
| [59] | YANG B, YIH W T, HE X, et al. Embedding entities and relations for learning and inference in knowledge bases[EB/OL]. [2024-08-19].. |
| [60] | XU D, ZHOU J, XU T, et al. Multimodal biological knowledge graph completion via triple co-attention mechanism[C]// Proceedings of the IEEE 39th International Conference on Data Engineering. Piscataway: IEEE, 2023: 3928-3941. |
| [61] | CHEN X, ZHANG N, LI L, et al. Hybrid Transformer with multi-level fusion for multimodal knowledge graph completion[C]// Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2022: 904-915. |
| [62] | 叶志鸿,吴运兵,戴思翀,等. 多级融合知识图谱补全模型[J]. 计算机科学与探索, 2025, 19(3): 724-737. |
| YE Z H, WU Y B, DAI S C, et al. Multi-level fusion knowledge graph completion model[J]. Journal of Frontiers of Computer Science and Technology, 2025, 19(3): 724-737. | |
| [63] | 许智宏,郝雪梅,王利琴,等. 多模态课程学习知识图谱实体预测方法研究[J]. 计算机科学与探索, 2024, 18(6): 1590-1599. |
| XU Z H, HAO X M, WANG L Q, et al. Research on knowledge graph entity prediction method of multi-modal curriculum learning[J]. Journal of Frontiers of Computer Science and Technology, 2024, 18(6): 1590-1599. | |
| [64] | XIE R, LIU Z, LUAN H, et al. Image-embodied knowledge representation learning[C]// Proceedings of the 26th International Joint Conference on Artificial Intelligence. California: ijcai.org, 2017: 3140-3146. |
| [65] | ALOM M Z, TAHA T M, YAKOPCIC C, et al. The history began from AlexNet: a comprehensive survey on deep learning approaches[EB/OL]. [2024-12-03].. |
| [66] | WANG J, LIU X, LI W, et al. A text-enhanced Transformer fusion network for multimodal knowledge graph completion[J]. IEEE Intelligent Systems, 2024, 39(3): 54-62. |
| [67] | ZHENG S, WANG W, QU J, et al. MMKGR: multi-hop multi-modal knowledge graph reasoning[C]// Proceedings of the IEEE 39th International Conference on Data Engineering. Piscataway: IEEE, 2023: 96-109. |
| [68] | 庞俊,刘小琪,谷峪,等. 基于多粒度注意力网络的知识超图链接预测[J]. 软件学报, 2023, 34(3): 1259-1276. |
| PANG J, LIU X Q, GU Y, et al. Knowledge hypergraph link prediction based on multi-granular attention network[J]. Journal of Software, 2023, 34(3): 1259-1276. | |
| [69] | ZHAO Y, ZHANG Y, ZHOU B, et al. Contrast then memorize: semantic neighbor retrieval-enhanced inductive multimodal knowledge graph completion[C]// Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2024: 102-111. |
| [70] | SHANG B, ZHAO Y, LIU J, et al. LAFA: multimodal knowledge graph completion with link aware fusion and aggregation[C]// Proceedings of the 38th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2024: 8957-8965. |
| [71] | LEE J, WANG Y, LI J, et al. Multimodal reasoning with multimodal knowledge graph[C]// Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2024: 10767-10782. |
| [72] | GARCÍA-DURÁN A, NIEPERT M. KBLRN: end-to-end learning of knowledge base representations with latent, relational, and numerical features[C]// Proceedings of the 2018 Conference on Uncertainty in Artificial Intelligence. Arlington, VA: AUAI Press, 2018: No.149. |
| [73] | ZEMAN V, KLIEGR T, SVÁTEK V. RDFRules: making RDF rule mining easier and even more efficient[J]. Semantic Web — Interoperability, Usability, Applicability, 2021, 12(4): 569-602. |
| [74] | LIANG S, ZHU A, ZHANG J, et al. Hyper-node relational graph attention network for multi-modal knowledge graph completion[J]. ACM Transactions on Multimedia Computing, Communications and Applications, 2023, 19(2): No.62. |
| [75] | ZHAO Y, CAI X, WU Y, et al. MoSE: modality split and ensemble for multimodal knowledge graph completion[C]// Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2022: 10527-10536. |
| [76] | ZHANG Y, CHEN Z, ZHANG W. MACO: a modality adversarial and contrastive framework for modality-missing multi-modal knowledge graph completion[C]// Proceedings of the 2023 National CCF International Conference on Natural Language Processing and Chinese Computing, LNCS 14302. Cham: Springer, 2023: 123-134. |
| [77] | LIANG Y. Multimodal knowledge graph embedding with missing data integration[J]. IEEE Transactions on Computational Social Systems, 2025, 12(4): 1824-1836. |
| [78] | ZHANG Y, CHEN Z, GUO L, et al. Making large language models perform better in knowledge graph completion[C]// Proceedings of the 32nd ACM International Conference on Multimedia. New York: ACM, 2024: 233-242. |
| [79] | MA H, KASINETS D, WANG D Z. Transformer-based multimodal knowledge graph completion with link-aware contexts[EB/OL]. [2025-02-11].. |
| [80] | SHASHANK R B, SWAMI S B, PAI A A, et al. Multimodal knowledge graph completion using CLIP-enhanced Hyper-node relational graph attention networks[C]// Proceedings of the 5th International Conference on Electronics and Sustainable Communication Systems. Piscataway: IEEE, 2024: 98-105. |
| [81] | WANG M, WANG S, YANG H, et al. Is visual context really helpful for knowledge graph? a representation learning perspective[C]// Proceedings of the 29th ACM International Conference on Multimedia. New York: ACM, 2021: 2735-2743. |
| [82] | WANG X, MENG B, CHEN H, et al. TIVA-KG: a multimodal knowledge graph with text, image, video and audio[C]// Proceedings of the 31st ACM International Conference on Multimedia. New York: ACM, 2023: 2391-2399. |
| [83] | WU C, CHEN X, WU Z, et al. Janus: decoupling visual encoding for unified multimodal understanding and generation[C]// Proceedings of the 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2025: 12966-12977. |
| [84] | PAHUJA V, LUO W, GU Y, et al. Reviving the context: camera trap species classification as link prediction on multimodal knowledge graphs[C]// Proceedings of the 33rd ACM International Conference on Information and Knowledge Management. New York: ACM, 2024: 1825-1835. |
| [85] | 荆博祥,王海荣,王彤,等. 多模态特征增强的双层融合知识推理方法[J]. 计算机科学与探索, 2025, 19(2): 406-416. |
| JING B X, WANG H R, WANG T, et al. Dual-layer fusion knowledge reasoning with enhanced multi-modal features[J]. Journal of Frontiers of Computer Science and Technology, 2025, 19(2): 406-416. |
| [1] | Sheping ZHAI, Yan HUANG, Qing YANG, Rui YANG. Multi-view entity alignment combining triples and text attributes [J]. Journal of Computer Applications, 2025, 45(6): 1793-1800. |
| [2] | Zeyi CAO, Yan CHANG, Renxin LAI, Shibin ZHANG, Zhi QIN, Lili YAN, Xuejian ZHANG, Yuanhao DI. Attribute-based entity alignment algorithm for decentralized data storage in large-scale institutions [J]. Journal of Computer Applications, 2025, 45(10): 3195-3202. |
| [3] | HUANG Junfu, LI Tianrui, JIA Zhen, JING Yunge, ZHANG Tao. Entity alignment of Chinese heterogeneous encyclopedia knowledge base [J]. Journal of Computer Applications, 2016, 36(7): 1881-1886. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||