


Journal of Computer Applications ›› 2026, Vol. 46 ›› Issue (6): 1703-1711.DOI: 10.11772/j.issn.1001-9081.2025060695
• Artificial intelligence •
Ziquan LIU, Xuyang SHI( ), Ke LI, Liang LIU, Zhewei ZHU
), Ke LI, Liang LIU, Zhewei ZHU
Received:2025-06-20
Revised:2025-08-15
Accepted:2025-08-21
Online:2025-09-01
Published:2026-06-10
Contact:
Xuyang SHI
About author:LIU Ziquan, born in 2002, M. S. candidate, His research interests include pattern recognition, image segmentation, multimodality.Supported by:
刘紫权, 史旭阳(), 李珂, 刘良, 朱哲维
通讯作者:
史旭阳
作者简介:刘紫权(2002—),男,四川内江人,硕士研究生,主要研究方向:模式识别、图像分割、多模态基金资助:CLC Number:
Ziquan LIU, Xuyang SHI, Ke LI, Liang LIU, Zhewei ZHU. Review of vision-language model architecture development[J]. Journal of Computer Applications, 2026, 46(6): 1703-1711.
刘紫权, 史旭阳, 李珂, 刘良, 朱哲维. 视觉语言模型架构发展综述[J]. 《计算机应用》唯一官方网站, 2026, 46(6): 1703-1711.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2025060695
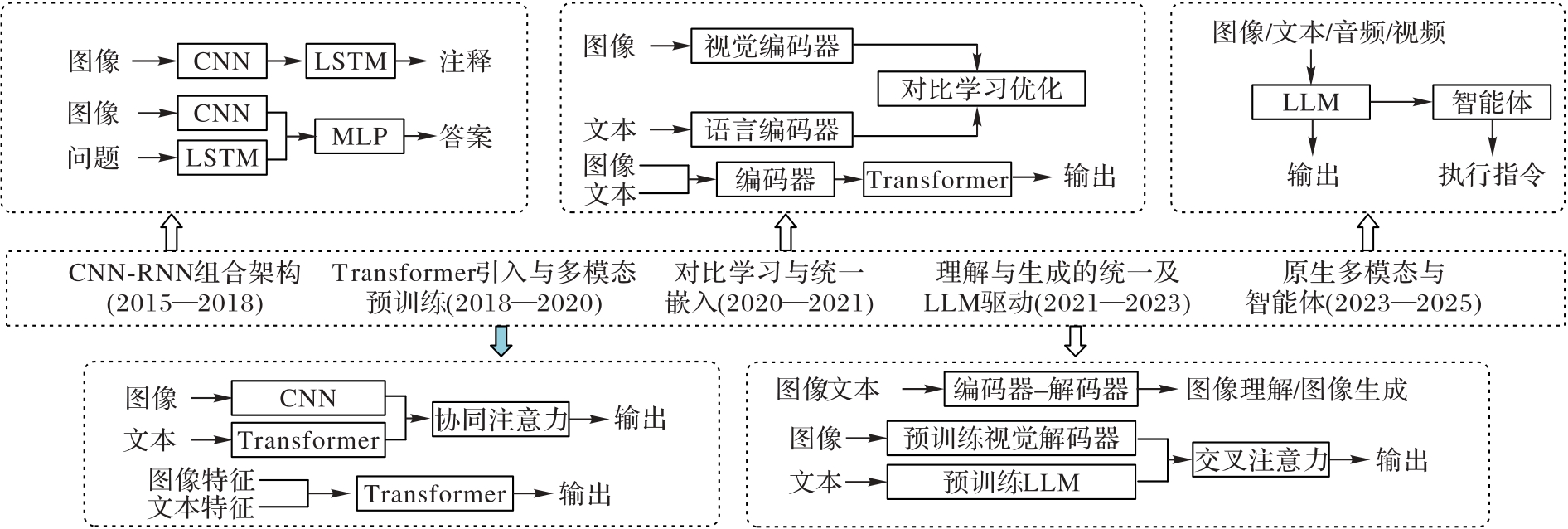
Fig. 1 VLM development process and representative model architectures in each period
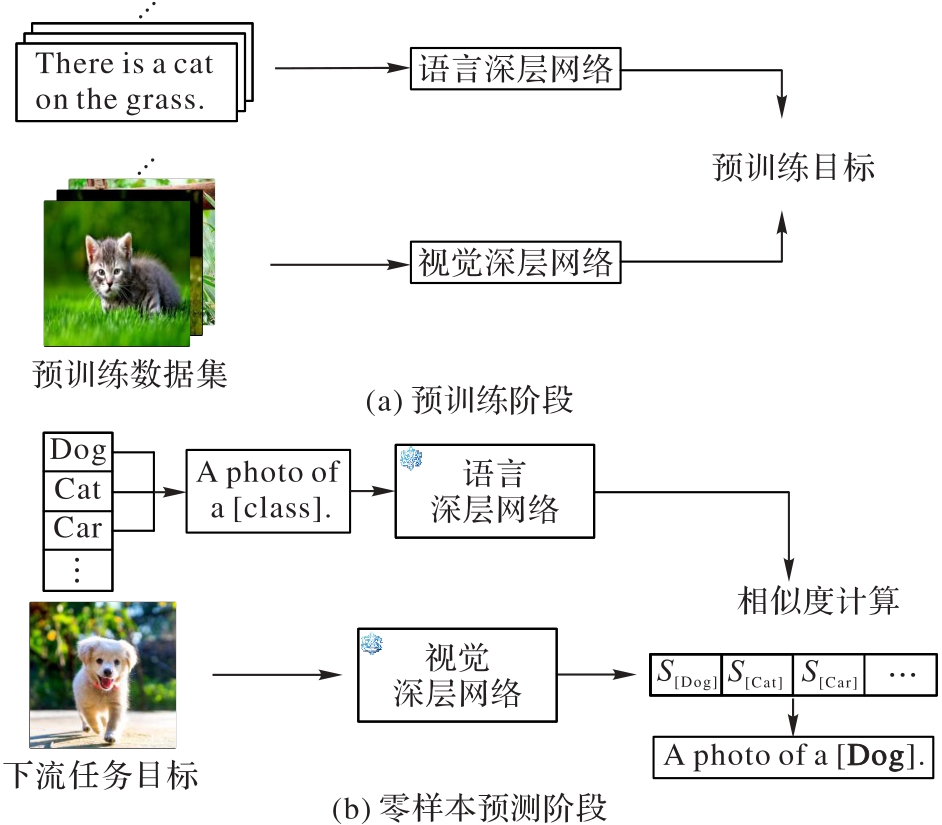
Fig. 2 Training paradigm for VLM vision tasks
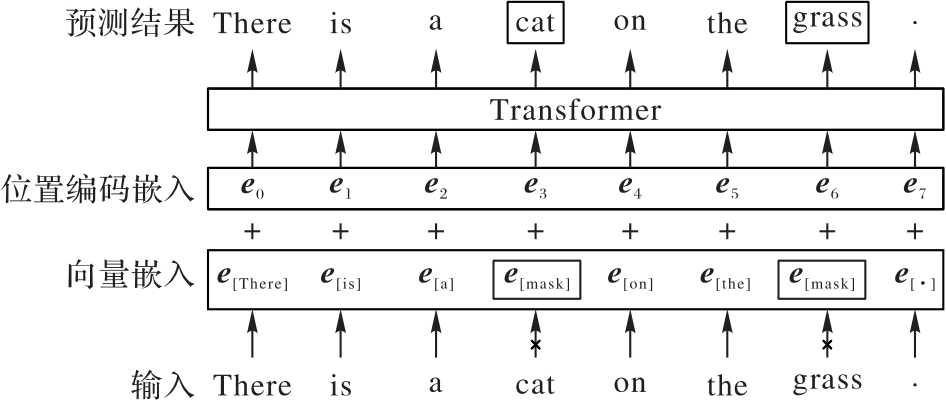
Fig. 3 Masked language modelling
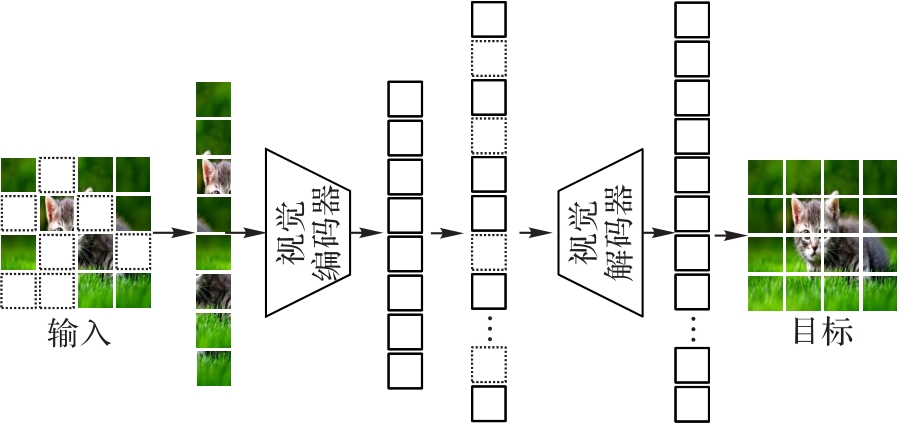
Fig. 4 Masked image modelling
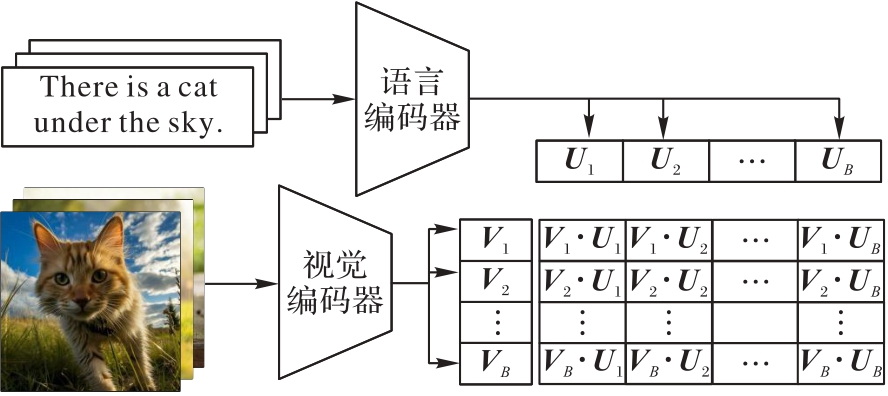
Fig. 5 Contrastive learning
| 分类 | 预训练目标 |
|---|---|
对比 目标 | 图像对比学习(Image Contrastive Learning) |
| 图像-文本对比学习(Image-Text Contrastive Learning) | |
| 图像-文本-标签对比学习(Image-Text-Label Contrastive Learning) | |
生成 目标 | 掩码图像建模(Masked Image Modelling) |
| 掩码语言建模(Masked Language Modelling) | |
| 掩码跨模态建模(Masked Cross-modal Modelling) | |
| 图像到文本生成(Image-to-Text Generation) | |
对齐 目标 | 图像-文本匹配(Image-Text Matching) |
| 区域-单词匹配(Region-Word Matching) |
Tab. 1 Pretraining optimization objective classification
| 分类 | 预训练目标 |
|---|---|
对比 目标 | 图像对比学习(Image Contrastive Learning) |
| 图像-文本对比学习(Image-Text Contrastive Learning) | |
| 图像-文本-标签对比学习(Image-Text-Label Contrastive Learning) | |
生成 目标 | 掩码图像建模(Masked Image Modelling) |
| 掩码语言建模(Masked Language Modelling) | |
| 掩码跨模态建模(Masked Cross-modal Modelling) | |
| 图像到文本生成(Image-to-Text Generation) | |
对齐 目标 | 图像-文本匹配(Image-Text Matching) |
| 区域-单词匹配(Region-Word Matching) |
| 数据集 | 年份 | 样本数/106 | 介绍 |
|---|---|---|---|
| SBU[ | 2011 | 1 | 收集自Flickr website,包含了与图像相关的描述 |
| Microsoft COCO captions[ | 2015 | 0.33 | 从Microsoft COCO数据集[ |
| YFCC100M[ | 2016 | 100 | 包含了9 920万张图像样本和80万条视频样本,均有文本标注 |
| VG[ | 2017 | 0.108 | 多视角的图像理解数据集,包括目标水平信息、场景图和图像问答对,每个样本有50条注释 |
| CC12M[ | 2021 | 12 | 专门用于VLM预训练 |
| LAION-400M[ | 2021 | 400 | 包含了由CLIP过滤后的4亿个图文对 |
| LAION-5B[ | 2022 | 5 800 | 提供了超过58亿个图文对,其中英语图文对有23.2亿个样本 |
| Wukong[ | 2022 | 100 | 大规模中文多模态数据集,包含了收集自互联网的1亿个中文图文对样本 |
| WebLI100B[ | 2025 | 100 000 | 包含1 000亿个图文对,支持多种语言,是目前最大视觉语言数据集之一 |
Tab. 2 Main image-text pair datasets
| 数据集 | 年份 | 样本数/106 | 介绍 |
|---|---|---|---|
| SBU[ | 2011 | 1 | 收集自Flickr website,包含了与图像相关的描述 |
| Microsoft COCO captions[ | 2015 | 0.33 | 从Microsoft COCO数据集[ |
| YFCC100M[ | 2016 | 100 | 包含了9 920万张图像样本和80万条视频样本,均有文本标注 |
| VG[ | 2017 | 0.108 | 多视角的图像理解数据集,包括目标水平信息、场景图和图像问答对,每个样本有50条注释 |
| CC12M[ | 2021 | 12 | 专门用于VLM预训练 |
| LAION-400M[ | 2021 | 400 | 包含了由CLIP过滤后的4亿个图文对 |
| LAION-5B[ | 2022 | 5 800 | 提供了超过58亿个图文对,其中英语图文对有23.2亿个样本 |
| Wukong[ | 2022 | 100 | 大规模中文多模态数据集,包含了收集自互联网的1亿个中文图文对样本 |
| WebLI100B[ | 2025 | 100 000 | 包含1 000亿个图文对,支持多种语言,是目前最大视觉语言数据集之一 |
| 模型 | 视觉编码器 | 语言编码器 | 训练样本数/106 | Top-1准确率/% | ||
|---|---|---|---|---|---|---|
| ImageNet-1K | CIFAR-10 | CIFAR-100 | ||||
| CLIP[ | ViT-L | Transformer | 400 | 76.2 | 95.7 | 77.5 |
| ALIGN[ | EfficientNet | BERT | 1 800 | 76.4 | ||
| RA-CLIP[ | ViT-B | BERT | 15 | 53.5 | 89.4 | 62.3 |
| LA-CLIP[ | ViT-B | Transformer | 400 | 64.4 | 92.4 | 73.0 |
| CoCa[ | ViT-G | Transformer | 4 800 | 86.3 | ||
| FILIP[ | ViT-L | Transformer | 340 | 77.1 | 95.7 | 75.3 |
| Florence[ | CoSwin | RoBERT | 900 | 83.7 | 94.6 | 77.6 |
| UniCL[ | ResNet-101 | Transformer | 16.3 | 71.3 | 97.0 | 81.4 |
| LiT[ | ViT-G | BERT | 4 000 | 85.2 | ||
| MobileCLIP[ | ViT-B | BERT | 1 480 | 71.7 | ||
| Alpha-CLIP[ | ViT-L | BERT | 20 | 68.9 | ||
Tab. 3 Zero-shot prediction results of different models on classification datasets
| 模型 | 视觉编码器 | 语言编码器 | 训练样本数/106 | Top-1准确率/% | ||
|---|---|---|---|---|---|---|
| ImageNet-1K | CIFAR-10 | CIFAR-100 | ||||
| CLIP[ | ViT-L | Transformer | 400 | 76.2 | 95.7 | 77.5 |
| ALIGN[ | EfficientNet | BERT | 1 800 | 76.4 | ||
| RA-CLIP[ | ViT-B | BERT | 15 | 53.5 | 89.4 | 62.3 |
| LA-CLIP[ | ViT-B | Transformer | 400 | 64.4 | 92.4 | 73.0 |
| CoCa[ | ViT-G | Transformer | 4 800 | 86.3 | ||
| FILIP[ | ViT-L | Transformer | 340 | 77.1 | 95.7 | 75.3 |
| Florence[ | CoSwin | RoBERT | 900 | 83.7 | 94.6 | 77.6 |
| UniCL[ | ResNet-101 | Transformer | 16.3 | 71.3 | 97.0 | 81.4 |
| LiT[ | ViT-G | BERT | 4 000 | 85.2 | ||
| MobileCLIP[ | ViT-B | BERT | 1 480 | 71.7 | ||
| Alpha-CLIP[ | ViT-L | BERT | 20 | 68.9 | ||
| [1] | ZHANG J, HUANG J, JIN S, et al. Vision-language models for vision tasks: a survey[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024, 46(8): 5625-5644. |
| [2] | ZHOU X, LIU M, YURTSEVER E, et al. Vision language models in autonomous driving: a survey and outlook[EB/OL]. [2025-07-25].. |
| [3] | 张浩宇,王天保,李孟择,等. 视觉语言多模态预训练综述[J]. 中国图象图形学报, 2022, 27(9): 2652-2682. |
| ZHANG H Y, WANG T B, LI M Z, et al. Comprehensive review of visual-language-oriented multimodal pre-training methods[J]. Journal of Image and Graphics, 2022, 27(9): 2652-2682. | |
| [4] | VINYALS O, TOSHEV A, BENGIO S, et al. Show and tell: a neural image caption generator[C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2015: 3156-3164. |
| [5] | JOHNSON J, KARPATHY A, LI F F. DenseCap: fully convolutional localization networks for dense captioning[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 4565-4574. |
| [6] | ANTOL S, AGRAWAL A, LU J, et al. VQA: visual question answering[C]// Proceedings of the 2015 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2015: 2425-2433. |
| [7] | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2017: 6000-6010. |
| [8] | DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional transformers for language understanding[C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Stroudsburg: ACL, 2019: 4171-4186. |
| [9] | LU J, BATRA D, PARIKH D, et al. ViLBERT: pretraining task-agnostic visiolinguistic representations for vision-and-language tasks[C]// Proceedings of the 33 International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2019: 13-23. |
| [10] | CHEN Y C, LI L, YU L, et al. UNITER: universal image-text representation learning[C]// Proceedings of the 2020 European Conference on Computer Vision, LNCS 12375. Cham: Springer, 2020: 104-120. |
| [11] | RADFORD A, KIM J W, HALLACY C, et al. Learning transferable visual models from natural language supervision [C]// Proceedings of the 38th International Conference on Machine Learning. New York: JMLR.org, 2021: 8748-8763. |
| [12] | JIA C, YANG Y, XIA Y, et al. Scaling up visual and vision-language representation learning with noisy text supervision[C]// Proceedings of the 38th International Conference on Machine Learning. New York: JMLR.org, 2021: 4904-4916. |
| [13] | KIM W, SON B, KIM I. ViLT: vision-and-language Transformer without convolution or region supervision[C]// Proceedings of the 38th International Conference on Machine Learning. New York: JMLR.org, 2021: 5583-5594. |
| [14] | LI J, SELVARAJU R R, GOTMARE A D, et al. Align before fuse: vision and language representation learning with momentum distillation [C]// Proceedings of the 35th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2021: 9694-9705. |
| [15] | WANG Z, YU J, YU A W, et al. SimVLM: simple visual language model pretraining with weak supervision[EB/OL]. [2025-06-22].. |
| [16] | LI J, LI D, XIONG C, et al. BLIP: bootstrapping language-image pre-training for unified vision-language understanding and generation [C]// Proceedings of the 39th International Conference on Machine Learning. New York: JMLR.org, 2022: 12888-12900. |
| [17] | WANG P, YANG A, MEN R, et al. OFA: unifying architectures, tasks, and modalities through a simple sequence-to-sequence learning framework[C]// Proceedings of the 39th International Conference on Machine Learning. New York: JMLR.org, 2022: 23318-23340. |
| [18] | ALAYRAC J B, DONAHUE J, LUC P, et al. Flamingo: a visual language model for few-shot learning[C]// Proceedings of the 36th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2022: 23716-23736. |
| [19] | LI J, LI D, SAVARESE S, et al. BLIP-2: bootstrapping language-image pre-training with frozen image encoders and large language models[C]// Proceedings of the 40th International Conference on Machine Learning. New York: JMLR.org, 2023: 19730-19742. |
| [20] | LIU H, LI C, WU Q, et al. Visual instruction tuning[C]// Proceedings of the 37th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2023: 34892-34916. |
| [21] | Gemini Team of Google. Gemini 1.5: unlocking multimodal understanding across millions of tokens of context[EB/OL]. [2025-06-22].. |
| [22] | OpenAI. GPT-4o system card[EB/OL]. [2025-06-22].. |
| [23] | KUROKAWA R, OHIZUMI Y, KANZAWA J, et al. Diagnostic performances of Claude 3 Opus and Claude 3.5 Sonnet from patient history and key images in Radiology’s “Diagnosis Please” cases[J]. Japanese Journal of Radiology, 2024, 42(12): 1399-1402. |
| [24] | BROOKS P, PEEBLES B, HOLMES C, et al. Video generation models as world simulators[EB/OL]. [2025-04-17]. . |
| [25] | Team Qwen. Qwen3 technical report[R/OL]. [2025-06-22].. |
| [26] | NIU R, LI J, WANG S, et al. ScreenAgent: a vision language model-driven computer control agent[C]// Proceedings of the 33rd International Joint Conference on Artificial Intelligence. California: ijcai.org, 2024: 6433-6441. |
| [27] | 中国科学院.科学家发布全球首个多模态地理科学大模型 推动地理学与人工智能深度融合[EB/OL].[2025-04-17]. . |
| Chinese Academy of Sciences. Scientists unveil the world’s first multimodal geoscience large model to promote the deep integration of geography and artificial intelligence [EB/OL].[2025-04-17]. . | |
| [28] | SZEGEDY C, LIU W, JIA Y, et al. Going deeper with convolutions[C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2015: 1-9. |
| [29] | HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 770-778. |
| [30] | SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[EB/OL]. [2025-06-22].. |
| [31] | MIKOLOV T, CHEN K, CORRADO G, et al. Efficient estimation of word representations in vector space[EB/OL]. [2025-06-22].. |
| [32] | LIU Y, OTT M, GOYAL N, et al. RoBERTa: a robustly optimized BERT pretraining approach[EB/OL]. [2025-06-22].. |
| [33] | ZHANG M, LI J. A commentary of GPT-3 in MIT technology review 2021 [J]. Fundamental Research, 2021, 1(6): 831-833. |
| [34] | SINGH A, HU R, GOSWAMI V, et al. FLAVA: a foundational language and vision alignment model [C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 15617-15629. |
| [35] | DOU Z Y, KAMATH A, GAN Z, et al. Coarse-to-fine vision-language pre-training with fusion in the backbone[C]// Proceedings of the 36th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2022: 32942-32956. |
| [36] | HE K, CHEN X, XIE S, et al. Masked autoencoders are scalable vision learners[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 15979-15988. |
| [37] | BAO H, DONG L, PIAO S, et al. BEiT: BERT pre-training of image Transformers[EB/OL]. [2025-06-23].. |
| [38] | ORDONEZ V, KULKARNI G, BERG T L. Im2Text: describing images using 1 million captioned photographs [C]// Proceedings of the 25th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2011: 1143-1151. |
| [39] | CHEN X, FANG H, LIN T Y, et al. Microsoft COCO captions: data collection and evaluation server[EB/OL]. [2025-06-23].. |
| [40] | KRISHNA R, ZHU Y, GROTH O, et al. Visual Genome: connecting language and vision using crowdsourced dense image annotations[J]. International Journal of Computer Vision, 2017, 123(1): 32-73. |
| [41] | LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft COCO: common objects in context[C]// Proceedings of the 2014 European Conference on Computer Vision, LNCS 8693. Cham: Springer, 2014: 740-755. |
| [42] | THOMEE B, SHAMMA D A, FRIEDLAND G, et al. YFCC100M: the new data in multimedia research[J]. Communications of the ACM, 2016, 59(2): 64-73. |
| [43] | CHANGPINYO S, SHARMA P, DING N, et al. Conceptual 12M: pushing Web-scale image-text pre-training to recognize long-tail visual concepts[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 3558-3568. |
| [44] | SCHUHMANN C, VENCU R, BEAUMONT R, et al. LAION-400M: open dataset of CLIP-filtered 400 million image-text pairs[DB/OL]. [2025-06-23].. |
| [45] | SCHUHMANN C, BEAUMONT R, VENCU R, et al. LAION-5B: an open large-scale dataset for training next generation image-text models[C]// Proceedings of the 36th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2022: 25278-25294. |
| [46] | GU J, MENG X, LU G, et al. Wukong: a 100 million large-scale Chinese cross-modal pre-training benchmark[C]// Proceedings of the 36th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2022: 26418-26431. |
| [47] | WANG X, ALABDULMOHSIN I, SALZ D, et al. Scaling pre-training to one hundred billion data for vision language models [EB/OL]. [2025-07-12].. |
| [48] | YUAN L, CHEN D, CHEN Y L, et al. Florence: a new foundation model for computer vision[EB/OL]. [2025-06-23].. |
| [49] | YANG J, LI C, ZHANG P, et al. Unified contrastive learning in image-text-label space[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 19141-19151. |
| [50] | YU J, WANG Z, VASUDEVAN V, et al. CoCa: contrastive captioners are image-text foundation models[EB/OL]. [2025-06-23].. |
| [51] | ZHAI X, WANG X, MUSTAFA B, et al. LiT: zero-shot transfer with locked-image text tuning[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 18102-18112. |
| [52] | YAO L, HUANG R, HOU L, et al. FILIP: fine-grained interactive language-image pre-training[EB/OL]. [2025-06-23].. |
| [53] | VASU P K A, POURANSARI H, FAGHRI F, et al. MobileCLIP: fast image-text models through multi-modal reinforced training[C]// Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2024: 15963-15974. |
| [54] | XIE C W, SUN S, XIONG X, et al. RA-CLIP: retrieval augmented contrastive language-image pre-training[C]// Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2023: 19265-19274. |
| [55] | FAN L, KRISHNAN D, ISOLA P, et al. Improving CLIP training with language rewrites [C]// Proceedings of the 37th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2023: 35544-35575. |
| [56] | SUN Z, FANG Y, WU T, et al. Alpha-CLIP: a CLIP model focusing on wherever you want[C]// Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2024: 13019-13029. |
| [57] | HARTSOCK I, RASOOL G. Vision-language models for medical report generation and visual question answering: a review[J]. Frontiers in Artificial Intelligence, 2024, 7: No.1430984. |
| [58] | JI J, HOU Y, CHEN X, et al. Vision-language model for generating textual descriptions from clinical images: model development and validation study[J]. JMIR Formative Research, 2024, 8: No.e32690. |
| [59] | SUN Y, WEN X, ZHANG Y, et al. Visual-language foundation models in medical imaging: a systematic review and meta-analysis of diagnostic and analytical applications[J]. Computer Methods and Programs in Biomedicine, 2025,268: No.108870. |
| [60] | AISYAH N, KAUTSAR M D AL, HIDAYAT A, et al. Evaluating vision-language and large language models for automated student assessment in Indonesian classrooms[EB/OL]. [2025-07-12].. |
| [61] | FEICHTER C, SCHLIPPE T. Investigating models for the transcription of mathematical formulas in images[J]. Applied Sciences, 2024, 14(3): No.1140. |
| [1] | Yongbing ZHANG, Lirong YAN, Xiaofen TANG. Progressive dual-stage modality interaction for single-domain generalized object detection [J]. Journal of Computer Applications, 2026, 46(4): 1264-1274. |
| [2] | Mingguang LI, Chongben TAO. Hierarchical cross-modal fusion method for 3D object detection based on Mamba model [J]. Journal of Computer Applications, 2026, 46(2): 572-579. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||