


Journal of Computer Applications ›› 2026, Vol. 46 ›› Issue (2): 572-579.DOI: 10.11772/j.issn.1001-9081.2025030281
• Multimedia computing and computer simulation • Previous Articles
Mingguang LI1, Chongben TAO1,2( )
)
Received:2025-03-21
Revised:2025-06-04
Accepted:2025-06-09
Online:2025-06-23
Published:2026-02-10
Contact:
Chongben TAO
About author:LI Mingguang, born in 2001, M. S. candidate. His research interests include 3D object detection, multi-modal fusion.Supported by:
李明光1, 陶重犇1,2()
通讯作者:
陶重犇
作者简介:李明光(2001—),男,山东临沂人,硕士研究生,主要研究方向:三维目标检测、多模态融合基金资助:CLC Number:
Mingguang LI, Chongben TAO. Hierarchical cross-modal fusion method for 3D object detection based on Mamba model[J]. Journal of Computer Applications, 2026, 46(2): 572-579.
李明光, 陶重犇. 基于Mamba模型的分级跨模态融合三维目标检测方法[J]. 《计算机应用》唯一官方网站, 2026, 46(2): 572-579.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2025030281
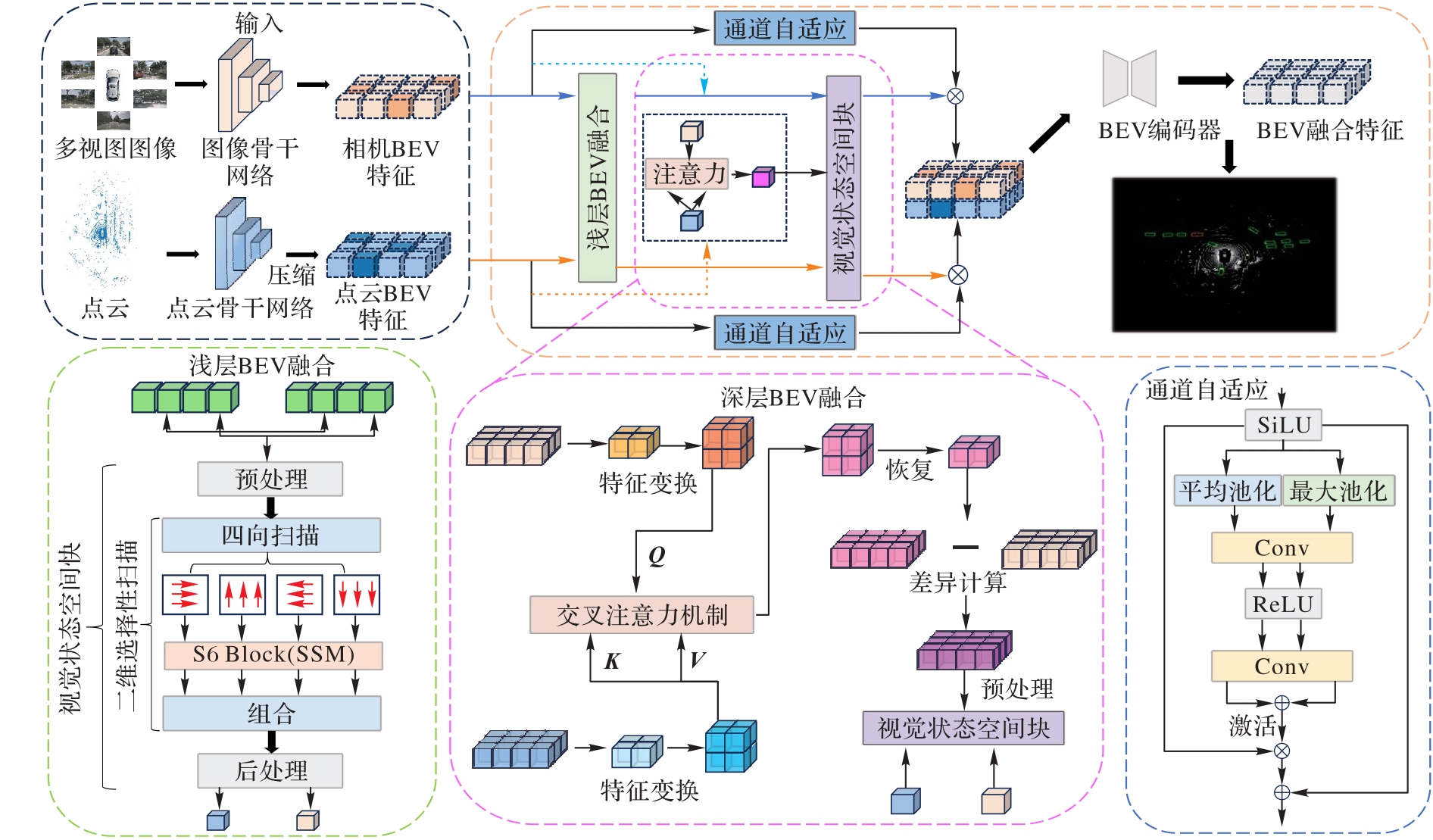
Fig. 1 Framework of proposed method

Fig. 2 Schematic diagram of SS2D
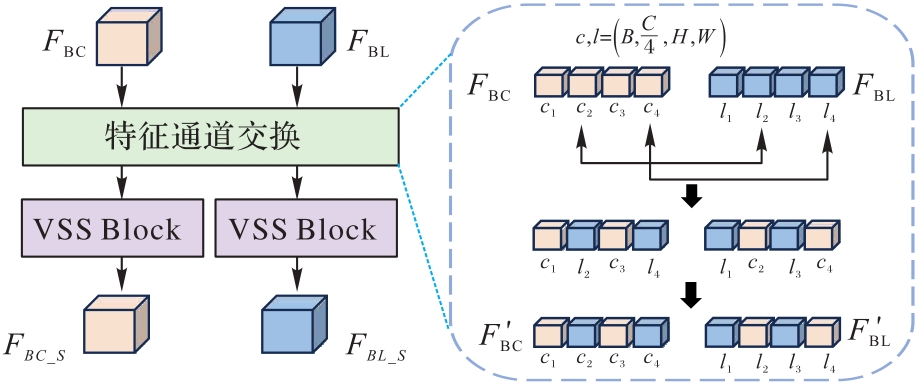
Fig. 3 Feature channel exchange module
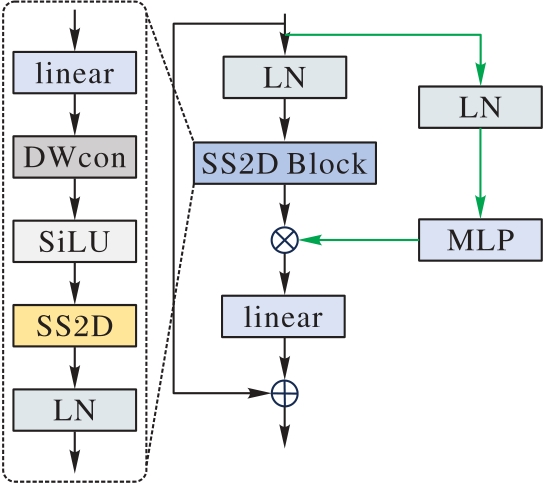
Fig. 4 VSS block
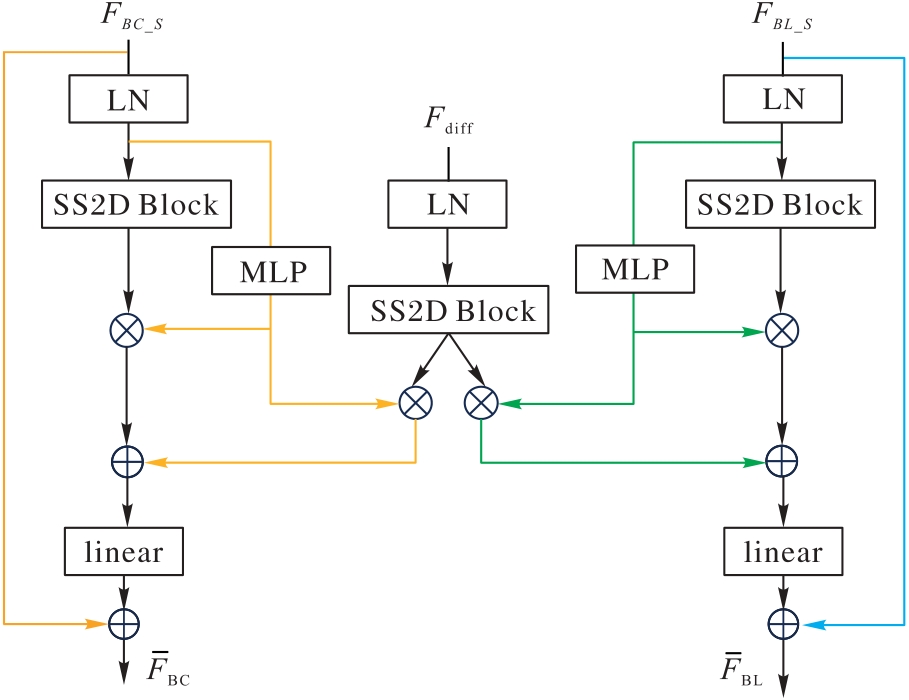
Fig. 5 Schematic diagram of deep feature fusion
| 方法 | 数据 | mAP | NDS | 不同类别的AP | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 汽车 | 卡车 | 建筑车辆 | 公交 | 拖车 | 障碍 | 摩托 | 自行车 | 行人 | 交通锥 | ||||
| PointPillars[ | L | 30.5 | 45.3 | 68.4 | 23.0 | 4.1 | 28.2 | 23.4 | 38.9 | 27.4 | 1.1 | 59.7 | 30.8 |
| CenterPoint[ | L | 60.3 | 67.3 | 85.2 | 53.5 | 20.0 | 63.6 | 56.0 | 71.1 | 59.5 | 30.7 | 84.6 | 78.4 |
| TransFusion-L[ | L | 65.5 | 70.2 | 86.2 | 56.7 | 28.2 | 66.3 | 58.8 | 78.2 | 68.3 | 44.2 | 86.1 | 82.0 |
| MVP[ | LC | 66.4 | 70.5 | 86.8 | 58.5 | 26.1 | 67.4 | 57.3 | 74.8 | 70.0 | 49.3 | 89.1 | 85.0 |
| PointAugmenting[ | LC | 66.8 | 71.0 | 87.5 | 57.3 | 28.0 | 65.2 | 60.7 | 72.6 | 74.3 | 50.9 | 87.9 | 83.6 |
| TransFusion[ | LC | 68.9 | 71.7 | 87.1 | 60.0 | 33.1 | 68.3 | 60.8 | 78.1 | 73.6 | 52.9 | 88.4 | 86.7 |
| BEVFusion_ali [ | LC | 69.8 | 71.9 | 88.1 | 60.9 | 34.4 | 68.5 | 62.1 | 78.2 | 71.8 | 52.2 | 89.2 | 85.5 |
| BEVFusion_mit [ | LC | 70.2 | 72.9 | 88.6 | 60.1 | 39.3 | 69.8 | 63.8 | 80.0 | 74.1 | 51.0 | 89.2 | 86.5 |
| ObjectFusion[ | LC | 71.0 | 73.3 | 89.4 | 59.0 | 40.5 | 71.8 | 63.1 | 76.6 | 78.1 | 53.2 | 90.7 | 87.7 |
| 本文方法 | LC | 72.4 | 73.9 | 89.9 | 65.7 | 37.6 | 73.3 | 65.4 | 82.2 | 76.5 | 53.6 | 91.4 | 88.7 |
Tab. 1 3D object detection performance on nuScenes test set
| 方法 | 数据 | mAP | NDS | 不同类别的AP | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 汽车 | 卡车 | 建筑车辆 | 公交 | 拖车 | 障碍 | 摩托 | 自行车 | 行人 | 交通锥 | ||||
| PointPillars[ | L | 30.5 | 45.3 | 68.4 | 23.0 | 4.1 | 28.2 | 23.4 | 38.9 | 27.4 | 1.1 | 59.7 | 30.8 |
| CenterPoint[ | L | 60.3 | 67.3 | 85.2 | 53.5 | 20.0 | 63.6 | 56.0 | 71.1 | 59.5 | 30.7 | 84.6 | 78.4 |
| TransFusion-L[ | L | 65.5 | 70.2 | 86.2 | 56.7 | 28.2 | 66.3 | 58.8 | 78.2 | 68.3 | 44.2 | 86.1 | 82.0 |
| MVP[ | LC | 66.4 | 70.5 | 86.8 | 58.5 | 26.1 | 67.4 | 57.3 | 74.8 | 70.0 | 49.3 | 89.1 | 85.0 |
| PointAugmenting[ | LC | 66.8 | 71.0 | 87.5 | 57.3 | 28.0 | 65.2 | 60.7 | 72.6 | 74.3 | 50.9 | 87.9 | 83.6 |
| TransFusion[ | LC | 68.9 | 71.7 | 87.1 | 60.0 | 33.1 | 68.3 | 60.8 | 78.1 | 73.6 | 52.9 | 88.4 | 86.7 |
| BEVFusion_ali [ | LC | 69.8 | 71.9 | 88.1 | 60.9 | 34.4 | 68.5 | 62.1 | 78.2 | 71.8 | 52.2 | 89.2 | 85.5 |
| BEVFusion_mit [ | LC | 70.2 | 72.9 | 88.6 | 60.1 | 39.3 | 69.8 | 63.8 | 80.0 | 74.1 | 51.0 | 89.2 | 86.5 |
| ObjectFusion[ | LC | 71.0 | 73.3 | 89.4 | 59.0 | 40.5 | 71.8 | 63.1 | 76.6 | 78.1 | 53.2 | 90.7 | 87.7 |
| 本文方法 | LC | 72.4 | 73.9 | 89.9 | 65.7 | 37.6 | 73.3 | 65.4 | 82.2 | 76.5 | 53.6 | 91.4 | 88.7 |
| 方法 | 数据 | mAP | NDS | 不同类别的AP | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 汽车 | 卡车 | 建筑车辆 | 公交 | 拖车 | 障碍 | 摩托 | 自行车 | 行人 | 交通锥 | ||||
| 3D-CVF[ | LC | 52.7 | 62.3 | 83.0 | 45.0 | 15.9 | 48.8 | 49.6 | 65.9 | 51.2 | 30.4 | 74.2 | 65.9 |
| TransFusion[ | LC | 67.3 | 71.2 | 87.6 | 62.0 | 27.4 | 75.7 | 42.8 | 73.9 | 75.4 | 63.1 | 87.8 | 77.0 |
| BEVFusion_ali[ | LC | 67.9 | 71.0 | 88.6 | 65.0 | 28.1 | 75.4 | 41.4 | 72.2 | 76.7 | 65.8 | 88.7 | 76.9 |
| BEVFusion_mit[ | LC | 68.3 | 71.1 | 88.5 | 65.1 | 28.7 | 75.2 | 41.9 | 73.1 | 76.2 | 66.8 | 88.9 | 77.2 |
| ObjectFusion[ | LC | 69.9 | 72.3 | 89.6 | 65.2 | 32.1 | 77.5 | 43.6 | 75.8 | 79.4 | 65.1 | 89.4 | 81.3 |
| 本文方法 | LC | 71.3 | 72.5 | 89.8 | 64.2 | 32.7 | 76.2 | 49.6 | 78.6 | 78.9 | 68.4 | 89.7 | 83.8 |
Tab. 2 3D object detection performance on nuScenes validation set
| 方法 | 数据 | mAP | NDS | 不同类别的AP | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 汽车 | 卡车 | 建筑车辆 | 公交 | 拖车 | 障碍 | 摩托 | 自行车 | 行人 | 交通锥 | ||||
| 3D-CVF[ | LC | 52.7 | 62.3 | 83.0 | 45.0 | 15.9 | 48.8 | 49.6 | 65.9 | 51.2 | 30.4 | 74.2 | 65.9 |
| TransFusion[ | LC | 67.3 | 71.2 | 87.6 | 62.0 | 27.4 | 75.7 | 42.8 | 73.9 | 75.4 | 63.1 | 87.8 | 77.0 |
| BEVFusion_ali[ | LC | 67.9 | 71.0 | 88.6 | 65.0 | 28.1 | 75.4 | 41.4 | 72.2 | 76.7 | 65.8 | 88.7 | 76.9 |
| BEVFusion_mit[ | LC | 68.3 | 71.1 | 88.5 | 65.1 | 28.7 | 75.2 | 41.9 | 73.1 | 76.2 | 66.8 | 88.9 | 77.2 |
| ObjectFusion[ | LC | 69.9 | 72.3 | 89.6 | 65.2 | 32.1 | 77.5 | 43.6 | 75.8 | 79.4 | 65.1 | 89.4 | 81.3 |
| 本文方法 | LC | 71.3 | 72.5 | 89.8 | 64.2 | 32.7 | 76.2 | 49.6 | 78.6 | 78.9 | 68.4 | 89.7 | 83.8 |
| 方法 | 数据 | mAPH | 不同类别的APH | ||
|---|---|---|---|---|---|
| 车辆 | 行人 | 自行车 | |||
| PointPillars[ | L | 57.6 | 62.5 | 50.2 | 59.9 |
| PVRCNN[ | L | 63.3 | 68.4 | 57.6 | 64.0 |
| CenterPoint[ | L | 67.6 | 68.4 | 65.8 | 68.5 |
| TransFusion[ | LC | 65.5 | 65.1 | 63.7 | 65.9 |
| PointAugmenting[ | LC | 66.7 | 62.2 | 64.6 | 73.3 |
| LoGoNet[ | LC | 71.3 | 70.5 | 69.7 | 73.6 |
| 本文方法 | LC | 71.8 | 70.9 | 71.8 | 72.4 |
Tab. 3 Comparison of mAPH of different methods on Waymo validation set
| 方法 | 数据 | mAPH | 不同类别的APH | ||
|---|---|---|---|---|---|
| 车辆 | 行人 | 自行车 | |||
| PointPillars[ | L | 57.6 | 62.5 | 50.2 | 59.9 |
| PVRCNN[ | L | 63.3 | 68.4 | 57.6 | 64.0 |
| CenterPoint[ | L | 67.6 | 68.4 | 65.8 | 68.5 |
| TransFusion[ | LC | 65.5 | 65.1 | 63.7 | 65.9 |
| PointAugmenting[ | LC | 66.7 | 62.2 | 64.6 | 73.3 |
| LoGoNet[ | LC | 71.3 | 70.5 | 69.7 | 73.6 |
| 本文方法 | LC | 71.8 | 70.9 | 71.8 | 72.4 |

Fig. 6 Visualization results on nuScenes dataset
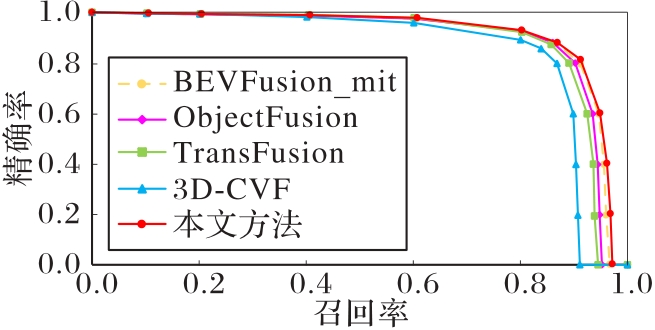
Fig. 7 Comparison of PR curves for cars
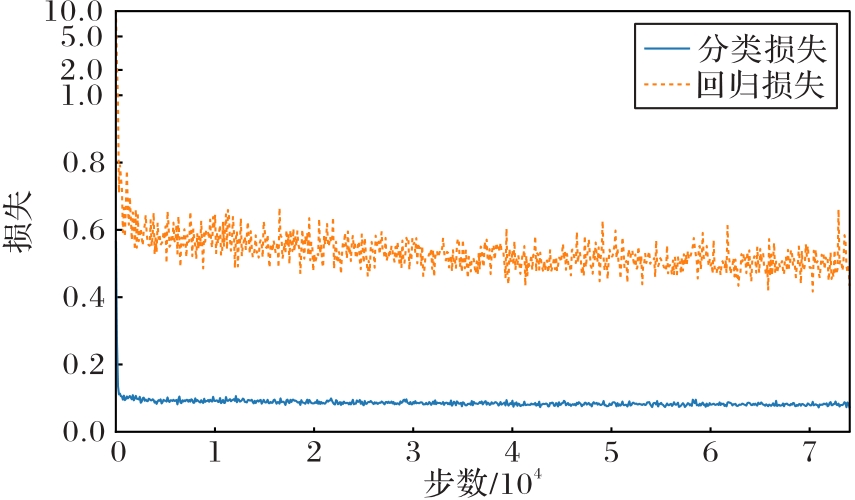
Fig. 8 Classification and regression losses of model
| 方法 | 数据 | MAC/109 | 延时/ms |
|---|---|---|---|
| CenterPoint[ | L | 151.6 | 44.8 |
| TransFusion[ | LC | 483.4 | 86.5 |
| MVP[ | LC | 369.2 | 103.9 |
| BEVFusion_mit[ | LC | 251.7 | 66.2 |
| 本文方法 | LC | 289.5 | 74.8 |
Tab. 4 Comparison of time complexity of different methods
| 方法 | 数据 | MAC/109 | 延时/ms |
|---|---|---|---|
| CenterPoint[ | L | 151.6 | 44.8 |
| TransFusion[ | LC | 483.4 | 86.5 |
| MVP[ | LC | 369.2 | 103.9 |
| BEVFusion_mit[ | LC | 251.7 | 66.2 |
| 本文方法 | LC | 289.5 | 74.8 |

Fig. 9 Vehicle platform for real test
| 方法 | AP | |||
|---|---|---|---|---|
| 汽车 | 公交 | 行人 | 卡车 | |
| Base | 73.2 | 66.4 | 78.8 | 68.5 |
| Base+S | 82.9 | 69.3 | 83.5 | 73.9 |
| Base+S+D | 90.4 | 78.8 | 91.8 | 74.2 |
| Base+S+D(CAM) | 91.1 | 81.4 | 92.7 | 78.6 |
Tab. 5 Performance of some key detection objects on real vehicle platform
| 方法 | AP | |||
|---|---|---|---|---|
| 汽车 | 公交 | 行人 | 卡车 | |
| Base | 73.2 | 66.4 | 78.8 | 68.5 |
| Base+S | 82.9 | 69.3 | 83.5 | 73.9 |
| Base+S+D | 90.4 | 78.8 | 91.8 | 74.2 |
| Base+S+D(CAM) | 91.1 | 81.4 | 92.7 | 78.6 |
| Baseline | SBSF | DBSF | CAM | mAP/% | NDS/% |
|---|---|---|---|---|---|
| √ | 68.3 | 71.1 | |||
| √ | √ | 69.5 | 71.7 | ||
| √ | √ | 68.9 | 71.4 | ||
| √ | √ | √ | 70.6 | 72.2 | |
| √ | √ | 68.5 | 71.1 | ||
| √ | √ | √ | √ | 71.3 | 72.5 |
Tab. 6 Ablation studies for various modules on nuScenes validation set
| Baseline | SBSF | DBSF | CAM | mAP/% | NDS/% |
|---|---|---|---|---|---|
| √ | 68.3 | 71.1 | |||
| √ | √ | 69.5 | 71.7 | ||
| √ | √ | 68.9 | 71.4 | ||
| √ | √ | √ | 70.6 | 72.2 | |
| √ | √ | 68.5 | 71.1 | ||
| √ | √ | √ | √ | 71.3 | 72.5 |
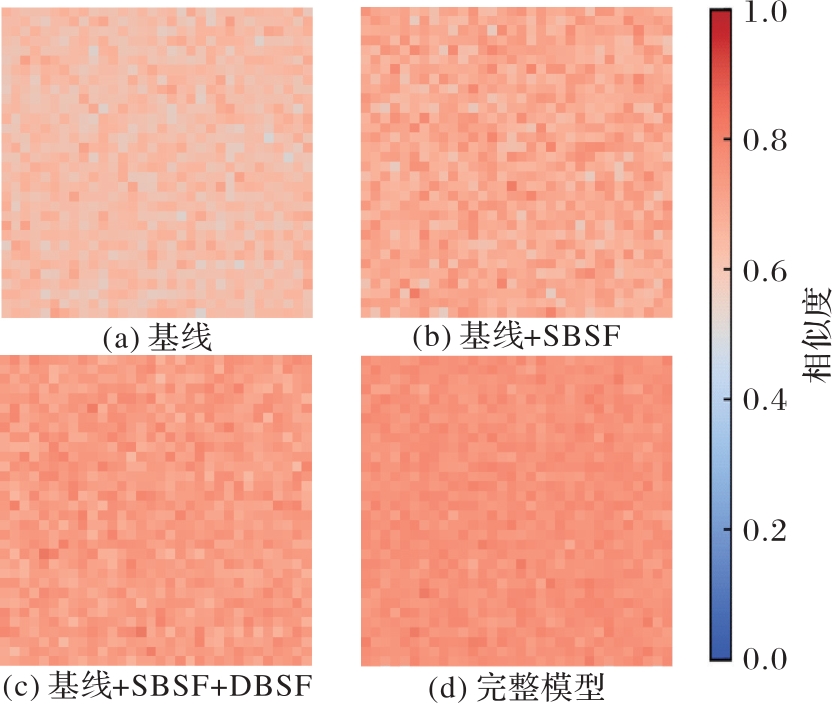
Fig. 10 Comparison of feature similarity heatmaps
| SBSF | DBSF | 层数 | mAP/% | NDS/% |
|---|---|---|---|---|
| √ | 1 | 68.7 | 71.3 | |
| √ | 2 | 69.5 | 71.7 | |
| √ | 3 | 69.2 | 71.4 | |
| √ | 4 | 68.6 | 71.2 | |
| √ | √ | 1 | 70.4 | 71.9 |
| √ | √ | 2 | 71.3 | 72.5 |
| √ | √ | 3 | 70.9 | 72.3 |
| √ | √ | 4 | 69.7 | 71.7 |
Tab. 7 Effect of layer number setting of VSS blocks in SBSF and DBSF
| SBSF | DBSF | 层数 | mAP/% | NDS/% |
|---|---|---|---|---|
| √ | 1 | 68.7 | 71.3 | |
| √ | 2 | 69.5 | 71.7 | |
| √ | 3 | 69.2 | 71.4 | |
| √ | 4 | 68.6 | 71.2 | |
| √ | √ | 1 | 70.4 | 71.9 |
| √ | √ | 2 | 71.3 | 72.5 |
| √ | √ | 3 | 70.9 | 72.3 |
| √ | √ | 4 | 69.7 | 71.7 |
| [1] | 孙逊,冯睿锋,陈彦如. 基于深度与实例分割融合的单目3D目标检测方法[J]. 计算机应用, 2024, 44(7): 2208-2215. |
| SUN X, FENG R F, CHEN Y R. Monocular 3D object detection method integrating depth and instance segmentation[J]. Journal of Computer Applications, 2024, 44(7): 2208-2215. | |
| [2] | 周静,胡怡宇,胡成玉,等. 基于点云补全和多分辨Transformer的弱感知目标检测方法[J]. 计算机应用, 2023, 43(7): 2155-2165. |
| ZHOU J, HU Y Y, HU C Y, et al. Weakly perceived object detection method based on point cloud completion and multi-resolution Transformer[J]. Journal of Computer Applications, 2023, 43(7): 2155-2165. | |
| [3] | LIANG M, YANG B, WANG S, et al. Deep continuous fusion for multi-sensor 3D object detection[C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11220. Cham: Springer, 2018: 663-678. |
| [4] | 李学钊,王伟,薛冰. 基于梯度算子和注意力的多模态融合目标检测[J]. 仪器仪表学报, 2024, 45(11): 224-232. |
| LI X Z, WANG W, XUE B. Multi-modal fusion object detection based on gradient operator and attention[J]. Chinese Journal of Scientific Instrument, 2024, 45(11): 224-232. | |
| [5] | LIU Z, TANG H, AMINI A, et al. BEVFusion: multi-task multi-sensor fusion with unified bird's-eye view representation[C]// Proceedings of the 2023 IEEE International Conference on Robotics and Automation. Piscataway: IEEE, 2023: 2774-2781. |
| [6] | LIANG T, XIE H, YU K, et al. BEVFusion: a simple and robust LiDAR-camera fusion framework[C]// Proceedings of the 36th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2022: 10421-10434. |
| [7] | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2017: 6000-6010. |
| [8] | WEI M, LI J, KANG H, et al. BEV-CFKT: a LiDAR-camera cross-modality-interaction fusion and knowledge transfer framework with transformer for BEV 3D object detection[J]. Neurocomputing, 2024, 582: No.127527. |
| [9] | GU A, GOEL K, RÉ C. Efficiently modeling long sequences with structured state spaces[EB/OL]. [2025-03-13].. |
| [10] | LIU Y, TIAN Y J, ZHAO Y Z, et al. VMamba: visual state space model[EB/OL]. [2025-03-13].. |
| [11] | ZHOU M H, LI T Y, QIAO C F, et al. DMM: disparity-guided multispectral mamba for oriented object detection in remote sensing[EB/OL]. [2025-03-13].. |
| [12] | CAESAR H, BANKITI V, LANG A H, et al. nuScenes: a multimodal dataset for autonomous driving[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 11618-11628. |
| [13] | SUN P, KRETZSCHMAR H, DOTIWALLA X, et al. Scalability in perception for autonomous driving: Waymo Open Dataset[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 2443-2451. |
| [14] | OpenMMLab. MMDetection 3D: OpenMMLab next-generation platform for general 3D object detection[EB/OL]. [2024-12-02].. |
| [15] | LIU Z, LIN Y T, CAO Y, et al. Swin Transformer: hierarchical Vision Transformer using shifted windows[C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 9992-10002. |
| [16] | YAN Y, MAO Y, LI B. SECOND: sparsely embedded convolutional detection[J]. Sensors, 2018, 18(10): No.3337. |
| [17] | KINGMA D P, BA J L. Adam: a method for stochastic optimization[EB/OL]. [2025-03-13].. |
| [18] | LANG A H, VORA S, CAESAR H, et al. PointPillars: fast encoders for object detection from point clouds[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 12689-12697. |
| [19] | YIN T, ZHOU X, KRÄHENBÜHL P. Center-based 3D object detection and tracking[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 11779-11788. |
| [20] | BAI X, HU Z, ZHU X, et al. TransFusion: robust LiDAR-camera fusion for 3D object detection with transformers[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 1080-1089. |
| [21] | YIN T, ZHOU X, KRÄHENBÜHL P. Multimodal virtual point 3D detection[C]// Proceedings of the 35th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2021: 16494-16507. |
| [22] | WANG C, MA C, ZHU M, et al. PointAugmenting: cross-modal augmentation for 3D object detection[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 11789-11798. |
| [23] | CAI Q, PAN Y, YAO T, et al. ObjectFusion: multi-modal 3D object detection with object-centric fusion[C]// Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2023: 18021-18030. |
| [24] | YOO J H, KIM Y, KIM J, et al. 3D-CVF: generating joint camera and lidar features using cross-view spatial feature fusion for 3D object detection[C]// Proceedings of the 2020 European Conference on Computer Vision, LNCS 12372. Cham: Springer, 2020: 720-736. |
| [25] | SHI S, GUO C, JIANG L, et al. PV-RCNN: point-voxel feature set abstraction for 3D object detection[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 10526-10535. |
| [26] | LI X, MA T, HOU Y, et al. LoGoNet: towards accurate 3D object detection with local-to-global cross-modal fusion[C]// Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2023: 17524-17534. |
| [1] | Haiyang PENG, Weixing JI, Fawang LIU. Blockchain-based data notarization model for autonomous driving simulation testing [J]. Journal of Computer Applications, 2025, 45(8): 2421-2427. |
| [2] | Chengzhi YAN, Ying CHEN, Kai ZHONG, Han GAO. 3D object detection algorithm based on multi-scale network and axial attention [J]. Journal of Computer Applications, 2025, 45(8): 2537-2545. |
| [3] | Chuanhao ZHANG, Xiaohan TU, Xuehui GU, Bo XUAN. LiDAR-camera 3D object detection based on multi-modal information mutual guidance and supplementation [J]. Journal of Computer Applications, 2025, 45(3): 946-952. |
| [4] | Xun SUN, Ruifeng FENG, Yanru CHEN. Monocular 3D object detection method integrating depth and instance segmentation [J]. Journal of Computer Applications, 2024, 44(7): 2208-2215. |
| [5] | Yaping DENG, Yingjiang LI. Review of YOLO algorithm and its applications to object detection in autonomous driving scenes [J]. Journal of Computer Applications, 2024, 44(6): 1949-1958. |
| [6] | Chao GE, Jiabin ZHANG, Lei WANG, Zhixin LUN. Trajectory planning for autonomous vehicles based on model predictive control [J]. Journal of Computer Applications, 2024, 44(6): 1959-1964. |
| [7] | LI Chao, LAN Hai, WEI Xian. Attention-based object detection with millimeter wave radar-lidar fusion [J]. Journal of Computer Applications, 2021, 41(7): 2137-2144. |
| [8] | PEI Yiyao, GUO Huiming, ZHANG Danpu, CHEN Wenbo. Robust 3D object detection method based on localization uncertainty [J]. Journal of Computer Applications, 2021, 41(10): 2979-2984. |
| [9] | PENG Yuhui, ZHENG Weihong, ZHANG Jianfeng. Deep learning-based on-road obstacle detection method [J]. Journal of Computer Applications, 2020, 40(8): 2428-2433. |
| [10] | LIU Dan, WU Yajuan, LUO Nanchao, ZHENG Bochuan. Object detection of Gaussian-YOLO v3 implanting attention and feature intertwine modules [J]. Journal of Computer Applications, 2020, 40(8): 2225-2230. |
| [11] | HU Xuemin, TONG Xiuchi, GUO Lin, ZHANG Ruohan, KONG Li. End-to-end autonomous driving model based on deep visual attention neural network [J]. Journal of Computer Applications, 2020, 40(7): 1926-1931. |
| [12] | HU Xuemin, CHENG Yu, CHEN Guowen, ZHANG Ruohan, TONG Xiuchi. Motion planning for autonomous driving with directional navigation based on deep spatio-temporal Q-network [J]. Journal of Computer Applications, 2020, 40(7): 1919-1925. |
| [13] | BAI Liyun, HU Xuemin, SONG Sheng, TONG Xiuchi, ZHANG Ruohan. Motion planning model based on deep cascaded neural network for autonomous driving [J]. Journal of Computer Applications, 2019, 39(10): 2870-2875. |
| [14] | ZHOU Huizi, HU Xuemin, CHEN Long, TIAN Mei, XIONG Dou. Dynamic path planning for autonomous driving with avoidance of obstacles [J]. Journal of Computer Applications, 2017, 37(3): 883-888. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||