


Journal of Computer Applications ›› 2025, Vol. 45 ›› Issue (4): 1169-1176.DOI: 10.11772/j.issn.1001-9081.2024030336
• Artificial intelligence • Previous Articles Next Articles
Yiheng SUN1,2, Maofu LIU1,2( )
)
Received:2024-03-27
Revised:2024-07-06
Accepted:2024-07-11
Online:2024-08-30
Published:2025-04-10
Contact:
Maofu LIU
About author:SUN Yiheng, born in 2000, M. S. candidate. His research interests include natural language processing, information retrieval.
Supported by:
孙熠衡1,2, 刘茂福1,2()
通讯作者:
刘茂福
作者简介:孙熠衡(2000—),男,湖北安陆人,硕士研究生,CCF会员,主要研究方向:自然语言处理、信息检索
基金资助:CLC Number:
Yiheng SUN, Maofu LIU. Tender information extraction method based on prompt tuning of knowledge[J]. Journal of Computer Applications, 2025, 45(4): 1169-1176.
孙熠衡, 刘茂福. 基于知识提示微调的标书信息抽取方法[J]. 《计算机应用》唯一官方网站, 2025, 45(4): 1169-1176.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2024030336
| 提示 | ChatGLM-6B的回答 |
|---|---|
| 特定模式 | {"机构联系人":"北京大学" "机构联系电话":"吴老师" "机构名称":"北京大学"…} |
| 代理模式 | {实体类型名称列表: 机构联系人 机构联系电话 机构名称…} |
| 示例模式 | {"机构联系人": "华采招标集团有限公司" "机构联系电话": "010-63509799-8083" "机构名称": "北京大学"…} |
Tab. 1 Answers of ChatGLM-6B with different prompts
| 提示 | ChatGLM-6B的回答 |
|---|---|
| 特定模式 | {"机构联系人":"北京大学" "机构联系电话":"吴老师" "机构名称":"北京大学"…} |
| 代理模式 | {实体类型名称列表: 机构联系人 机构联系电话 机构名称…} |
| 示例模式 | {"机构联系人": "华采招标集团有限公司" "机构联系电话": "010-63509799-8083" "机构名称": "北京大学"…} |
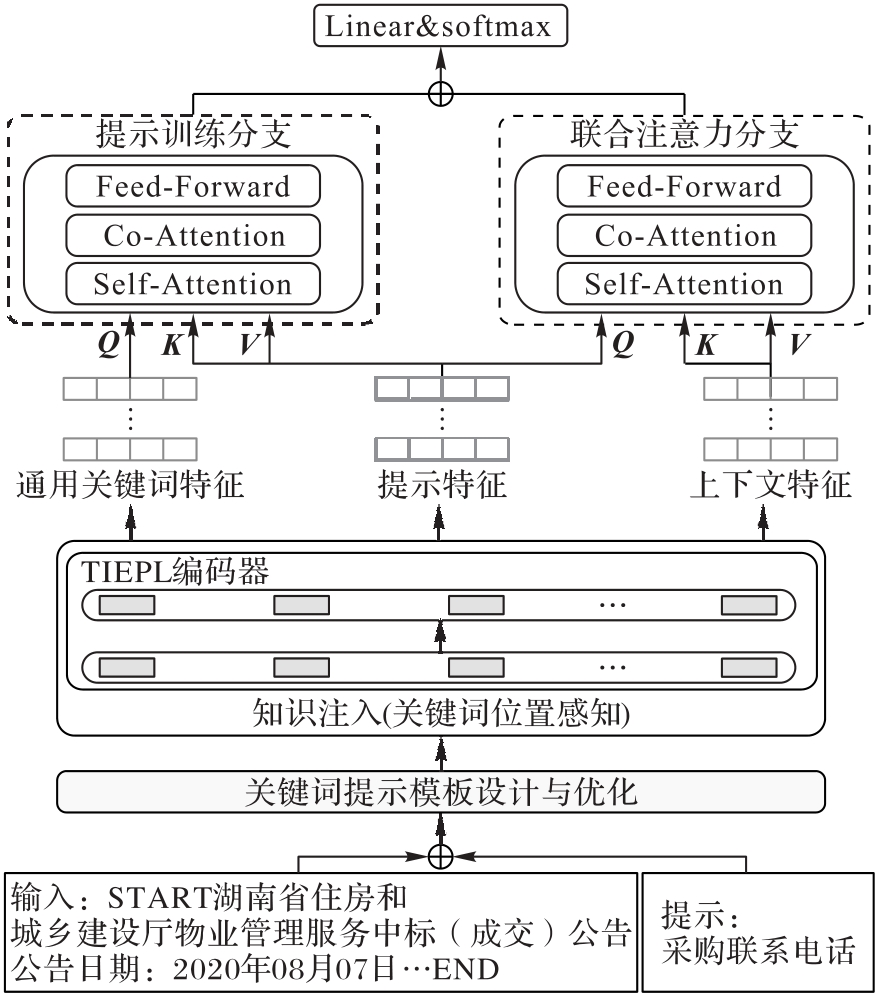
Fig. 1 Overall architecture of proposed method
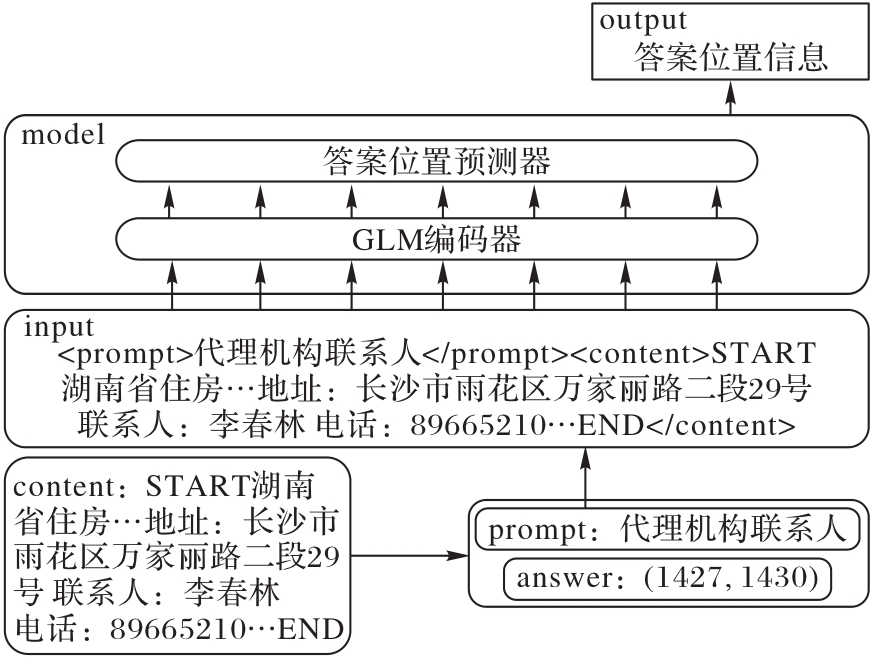
Fig. 2 Flow of domain knowledge injection method
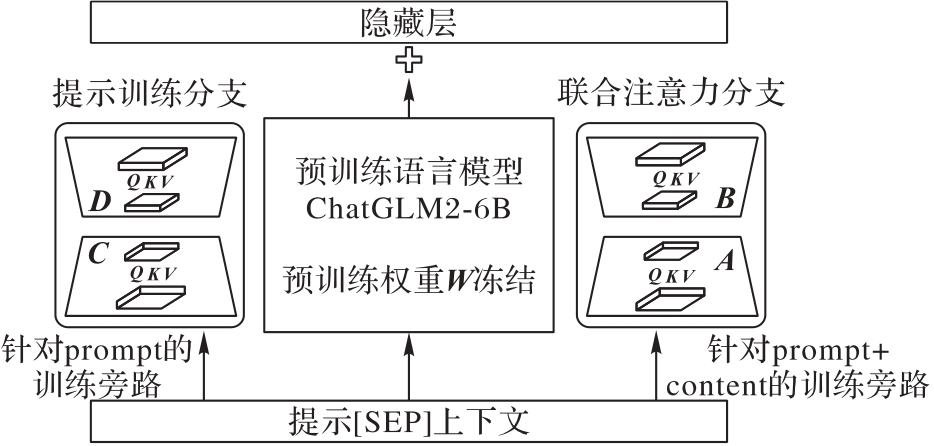
Fig. 3 Architecture of dual-bypass fine-tuning
| 名称 | 符号 | 示例 |
|---|---|---|
| 提示函数 | [X1] [Z] START [X2] END [X3] | |
| 提示 | 给定以下关于招中标的文段,我想要抽取出其中的[Z],只针对…START长沙理工大学洞庭湖多媒体沙盘及智能控制系统购置项目公开招标公告…END 4 276 800元 | |
| 错误填充 | 给定以下关于招中标的文段,我想要抽取出其中的中标价格,只针对…START长沙理工大学洞庭湖多媒体沙盘及智能控制系统购置项目公开招标公告…END 4 276 800元 | |
| 正确答案 | 给定以下关于招中标的文段,我想要抽取出其中的预算金额,只针对…START长沙理工大学洞庭湖多媒体沙盘及智能控制系统购置项目公开招标公告…END 4 276 800元 |
Tab. 2 Tender keyword prompt functions and related examples
| 名称 | 符号 | 示例 |
|---|---|---|
| 提示函数 | [X1] [Z] START [X2] END [X3] | |
| 提示 | 给定以下关于招中标的文段,我想要抽取出其中的[Z],只针对…START长沙理工大学洞庭湖多媒体沙盘及智能控制系统购置项目公开招标公告…END 4 276 800元 | |
| 错误填充 | 给定以下关于招中标的文段,我想要抽取出其中的中标价格,只针对…START长沙理工大学洞庭湖多媒体沙盘及智能控制系统购置项目公开招标公告…END 4 276 800元 | |
| 正确答案 | 给定以下关于招中标的文段,我想要抽取出其中的预算金额,只针对…START长沙理工大学洞庭湖多媒体沙盘及智能控制系统购置项目公开招标公告…END 4 276 800元 |
| 方法 | ROUGE-1 | ROUGE-2 | ROUGE-L | BLEU-4 |
|---|---|---|---|---|
| BERT | 65.54 | 15.50 | 65.54 | 34.36 |
| KnowLM | 75.01 | 15.04 | 75.00 | 39.96 |
| UIE | 78.14 | 20.66 | 78.13 | 44.09 |
| TIEPL | 79.27 | 25.63 | 79.18 | 48.80 |
Tab. 3 Comparison results of different models on tender inviting and winning dataset
| 方法 | ROUGE-1 | ROUGE-2 | ROUGE-L | BLEU-4 |
|---|---|---|---|---|
| BERT | 65.54 | 15.50 | 65.54 | 34.36 |
| KnowLM | 75.01 | 15.04 | 75.00 | 39.96 |
| UIE | 78.14 | 20.66 | 78.13 | 44.09 |
| TIEPL | 79.27 | 25.63 | 79.18 | 48.80 |
| 方法 | ROUGE-1 | ROUGE-2 | ROUGE-L | BLEU-4 |
|---|---|---|---|---|
| TIEPL-KI | 75.52 | 23.34 | 75.31 | 47.36 |
| TIEPL-PL | 76.23 | 24.65 | 76.34 | 47.82 |
| TIEPL-GK | 78.68 | 23.92 | 78.61 | 47.90 |
| TIEPL-RP | 44.27 | 3.25 | 44.23 | 11.87 |
| TIEPL | 79.27 | 25.63 | 79.18 | 48.80 |
Tab. 4 Results of ablation experiments
| 方法 | ROUGE-1 | ROUGE-2 | ROUGE-L | BLEU-4 |
|---|---|---|---|---|
| TIEPL-KI | 75.52 | 23.34 | 75.31 | 47.36 |
| TIEPL-PL | 76.23 | 24.65 | 76.34 | 47.82 |
| TIEPL-GK | 78.68 | 23.92 | 78.61 | 47.90 |
| TIEPL-RP | 44.27 | 3.25 | 44.23 | 11.87 |
| TIEPL | 79.27 | 25.63 | 79.18 | 48.80 |
| 方法 | ROUGE-1 | ROUGE-2 | ROUGE-L | BLEU-4 |
|---|---|---|---|---|
| BERT | 55.22 | 15.12 | 55.22 | 33.13 |
| KnowLM | 67.44 | 20.84 | 67.41 | 40.94 |
| UIE | 72.40 | 28.06 | 72.37 | 48.72 |
| TIEPL | 78.98 | 33.77 | 78.76 | 54.88 |
Tab. 5 Results of generalization experiments
| 方法 | ROUGE-1 | ROUGE-2 | ROUGE-L | BLEU-4 |
|---|---|---|---|---|
| BERT | 55.22 | 15.12 | 55.22 | 33.13 |
| KnowLM | 67.44 | 20.84 | 67.41 | 40.94 |
| UIE | 72.40 | 28.06 | 72.37 | 48.72 |
| TIEPL | 78.98 | 33.77 | 78.76 | 54.88 |
| 上下文 | 关键词 | 答案 | 模型 | 推理结果 |
|---|---|---|---|---|
…七、联系方式: 联系人:刘晓康、刘佩佩 联系电话:0631-5283790、0631-5283707 传真电话:0631-52883767 电子邮件:HDDL123@126.com 开户名称:威海宏达工程咨询有限公司 开户银行:建设银行威海分行… | 代理机构联系人 | 刘晓康、刘佩佩 | 本文模型 | 刘晓康、刘佩佩 |
| BERT | 无 | |||
| UIE | 无 | |||
| KnowLM | 无 |
Tab. 6 Case of contextual reasoning
| 上下文 | 关键词 | 答案 | 模型 | 推理结果 |
|---|---|---|---|---|
…七、联系方式: 联系人:刘晓康、刘佩佩 联系电话:0631-5283790、0631-5283707 传真电话:0631-52883767 电子邮件:HDDL123@126.com 开户名称:威海宏达工程咨询有限公司 开户银行:建设银行威海分行… | 代理机构联系人 | 刘晓康、刘佩佩 | 本文模型 | 刘晓康、刘佩佩 |
| BERT | 无 | |||
| UIE | 无 | |||
| KnowLM | 无 |
| 上下文 | 关键词 | 答案 | 模型 | 推理结果 |
|---|---|---|---|---|
综合得分 备注 1 正星科技股份有限公司 11.5000000 11.50 合格 满足要求 93.11 入围候选人 2 北京恒合信业技术股份有限公司 11.6300000 11.63 合格 满足要求 91.54 入围候选人 3 郑州永邦测控技术有限公司 11.9000000 11.90 合格 满足要求 89.19 入围候选人… | 供应商名称 | 正星科技股份有限公司, 北京恒合信业技术股份有限公司, 郑州永邦测控技术有限公司, 湖南九维环保科技有限公司, 江苏法利沃环保科技有限公司 | 本文模型 | 正星科技 股份有限公司 |
| BERT | 无 | |||
| UIE | 无 | |||
| KnowLM | 无 |
Tab. 7 Case of table displacement and disorder
| 上下文 | 关键词 | 答案 | 模型 | 推理结果 |
|---|---|---|---|---|
综合得分 备注 1 正星科技股份有限公司 11.5000000 11.50 合格 满足要求 93.11 入围候选人 2 北京恒合信业技术股份有限公司 11.6300000 11.63 合格 满足要求 91.54 入围候选人 3 郑州永邦测控技术有限公司 11.9000000 11.90 合格 满足要求 89.19 入围候选人… | 供应商名称 | 正星科技股份有限公司, 北京恒合信业技术股份有限公司, 郑州永邦测控技术有限公司, 湖南九维环保科技有限公司, 江苏法利沃环保科技有限公司 | 本文模型 | 正星科技 股份有限公司 |
| BERT | 无 | |||
| UIE | 无 | |||
| KnowLM | 无 |
| 1 | LIU P, YUAN W, FU J, et al. Pre-train, prompt, and predict: a systematic survey of prompting methods in natural language processing [J]. ACM Computing Surveys, 2023, 55(9): No.195. |
| 2 | DU Z, QIAN Y, LIU X, et al. GLM: general language model pretraining with autoregressive blank infilling [C]// Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2022: 320-335. |
| 3 | 李冬梅,张扬,李东远,等. 实体关系抽取方法研究综述[J]. 计算机研究与发展, 2020, 57(7): 1424-1448. |
| LI D M, ZHANG Y, LI D Y, et al. Review of entity relation extraction methods [J]. Journal of Computer Research and Development, 2020, 57(7): 1424-1448. | |
| 4 | ZHENG S, WANG F, BAO H, et al. Joint extraction of entities and relations based on a novel tagging scheme [C]// Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics(Volume 1: Long Papers). Stroudsburg: ACL, 2017: 1227-1236. |
| 5 | GRISHMAN R. Twenty-five years of information extraction [J]. Natural Language Engineering, 2019, 25(6): 677-692. |
| 6 | ZHAO W X, ZHOU K, LI J, et al. A survey of large language models [EB/OL]. [2024-11-20]. . |
| 7 | WANG C, LIU X, CHEN Z, et al. DeepStruct: pretraining of language models for structure prediction [C]// Findings of the Association for Computational Linguistics: ACL 2022. Stroudsburg: ACL, 2022: 803-823. |
| 8 | GAN C, ZHANG Q, MORI T. GIELLM: Japanese general information extraction large language model utilizing mutual reinforcement effect [EB/OL]. [2024-02-21]. . |
| 9 | JIMÉNEZ GUTIÉRREZ B, McNEAL N, WASHINGTON C, et al. Thinking about GPT-3 in-context learning for biomedical IE? think again [C]// Findings of the Association for Computational Linguistics: EMNLP 2022. Stroudsburg: ACL, 2022: 4497-4512. |
| 10 | WAN Z, CHENG F, MAO Z, et al. GPT-RE: in-context learning for relation extraction using large language models [C]// Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2023: 3534-3547. |
| 11 | KOJIMA T, GU S S, REID M, et al. Large language models are zero-shot reasoners [C]// Proceedings of the 36th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2022: 22199-22213. |
| 12 | WANG X, ZHOU W, ZU C, et al. InstructUIE: multi-task instruction tuning for unified information extraction [EB/OL]. [2024-01-03]. . |
| 13 | LOU J, LU Y, DAI D, et al. Universal information extraction as unified semantic matching [C]// Proceedings of the 37th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2023: 13318-13326. |
| 14 | BI Z, ZHANG N, XUE Y, et al. OceanGPT: a large language model for ocean science tasks [C]// Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2024: 3357-3372. |
| 15 | WEI X, CUI X, CHENG N, et al. ChatIE: zero-shot information extraction via chatting with ChatGPT [EB/OL]. [2024-10-13].. |
| 16 | ITO T, NAKAGAWA S. Tender document analyzer with the combination of supervised learning and LLM-based improver [C]// Companion Proceedings of the ACM Web Conference 2024. New York: ACM, 2024: 995-998. |
| 17 | LEVY O, SEO M, CHOI E, et al. Zero-shot relation extraction via reading comprehension [C]// Proceedings of the 21st Conference on Computational Natural Language Learning. Stroudsburg: ACL, 2017: 333-342. |
| 18 | SHIN T, RAZEGHI Y, LOGAN R L, Ⅳ, et al. AutoPrompt: eliciting knowledge from language models with automatically generated prompts [C]// Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2020: 4222-4235. |
| 19 | CHEN X, ZHANG N, XIE X, et al. KnowPrompt: knowledge-aware prompt-tuning with synergistic optimization for relation extraction [C]// Proceedings of the ACM Web Conference 2022. New York: ACM, 2022: 2778-2788. |
| 20 | 孙焕良,王思懿,刘俊岭,等. 社交媒体数据中水灾事件求助信息提取模型[J]. 计算机应用, 2024, 44(8):2437-2445. |
| SUN H L, WANG S Y, LIU J L, et al. Help-seeking information extraction model for flood event in social media data [J]. Journal of Computer Applications, 2024, 44(8):2437-2445. | |
| 21 | JIANG Z, XU F F, ARAKI J, et al. How can we know what language models know? [J]. Transactions of the Association for Computational Linguistics, 2020, 8: 423-438. |
| 22 | HAVIV A, BERANT J, GLOBERSON A. BERTese: learning to speak to BERT [C]// Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume. Stroudsburg: ACL, 2021: 3618-3623. |
| 23 | LI X L, LIANG P. Prefix-tuning: optimizing continuous prompts for generation [C]// Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Stroudsburg: ACL, 2021: 4582-4597. |
| 24 | ZHONG Z, FRIEDMAN D, CHEN D. Factual probing is [MASK]: learning vs. learning to recall [C]// Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg: ACL, 2021: 5017-5033. |
| 25 | 李龚林,范一晨,米宇舰,等. 动态微调的模型集成算法Bagging-DyFAS[J]. 计算机应用, 2023, 43(S2): 28-33. |
| LI G L, FAN Y C, MI Y J, et al. Bagging-DyFAS: model ensemble algorithm with dynamic fine-tuning [J]. Journal of Computer Applications, 2023, 43(S2): 28-33. | |
| 26 | HU E J, SHEN Y, WALLIS P, et al. LoRA: low-rank adaptation of large language models [EB/OL]. [2024-01-20]. . |
| 27 | LIU X, JI K, FU Y, et al. P-Tuning: prompt tuning can be comparable to fine-tuning across scales and tasks [C]// Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). Stroudsburg: ACL, 2022: 61-68. |
| 28 | FU P, ZHANG Y, WANG H, et al. Revisiting the knowledge injection frameworks [C]// Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2023: 10983-10997. |
| 29 | SU J, AHMED M, LU Y, et al. RoFormer: enhanced transformer with rotary position embedding [J]. Neurocomputing, 2024, 568: No.127063. |
| 30 | 涂飞明,刘茂福,夏旭,等. 基于BERT的阅读理解式标书文本信息抽取方法[J]. 武汉大学学报(理学版), 2022, 68(3): 311-316. |
| TU F M, LIU M F, XIA X, et al. BERT-based method for bidding text information extraction via reading comprehension [J]. Journal of Wuhan University(Natural Science Edition), 2022, 68(3): 311-316. | |
| 31 | LIN C Y. ROUGE: a package for automatic evaluation of summaries [C]// Proceedings of the ACL-04 Workshop: Text Summarization Branches Out. Stroudsburg: ACL, 2004: 74-81. |
| 32 | PAPINENI K, ROUKOS S, WARD T, et al. BLEU: a method for automatic evaluation of machine translation [C]// Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2002: 311-318. |
| 33 | LU Y, LIU Q, DAI D, et al. Unified structure generation for universal information extraction [C]// Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2022: 5755-5772. |
| [1] | Peng CAO, Guangqi WEN, Jinzhu YANG, Gang CHEN, Xinyi LIU, Xuechun JI. Efficient fine-tuning method of large language models for test case generation [J]. Journal of Computer Applications, 2025, 45(3): 725-731. |
| [2] | Xuefei ZHANG, Liping ZHANG, Sheng YAN, Min HOU, Yubo ZHAO. Personalized learning recommendation in collaboration of knowledge graph and large language model [J]. Journal of Computer Applications, 2025, 45(3): 773-784. |
| [3] | Chenwei SUN, Junli HOU, Xianggen LIU, Jiancheng LYU. Large language model prompt generation method for engineering drawing understanding [J]. Journal of Computer Applications, 2025, 45(3): 801-807. |
| [4] | Yanmin DONG, Jiajia LIN, Zheng ZHANG, Cheng CHENG, Jinze WU, Shijin WANG, Zhenya HUANG, Qi LIU, Enhong CHEN. Design and practice of intelligent tutoring algorithm based on personalized student capability perception [J]. Journal of Computer Applications, 2025, 45(3): 765-772. |
| [5] | Can MA, Ruizhang HUANG, Lina REN, Ruina BAI, Yaoyao WU. Chinese spelling correction method based on LLM with multiple inputs [J]. Journal of Computer Applications, 2025, 45(3): 849-855. |
| [6] | Jing HE, Yang SHEN, Runfeng XIE. Recognition and optimization of hallucination phenomena in large language models [J]. Journal of Computer Applications, 2025, 45(3): 709-714. |
| [7] | Xiaolin QIN, Xu GU, Dicheng LI, Haiwen XU. Survey and prospect of large language models [J]. Journal of Computer Applications, 2025, 45(3): 685-696. |
| [8] | Chengzhe YUAN, Guohua CHEN, Dingding LI, Yuan ZHU, Ronghua LIN, Hao ZHONG, Yong TANG. ScholatGPT: a large language model for academic social networks and its intelligent applications [J]. Journal of Computer Applications, 2025, 45(3): 755-764. |
| [9] | Yuemei XU, Yuqi YE, Xueyi HE. Bias challenges of large language models: identification, evaluation, and mitigation [J]. Journal of Computer Applications, 2025, 45(3): 697-708. |
| [10] | Yan YANG, Feng YE, Dong XU, Xuejie ZHANG, Jin XU. Construction of digital twin water conservancy knowledge graph integrating large language model and prompt learning [J]. Journal of Computer Applications, 2025, 45(3): 785-793. |
| [11] | Bin LI, Min LIN, Siriguleng, Yingjie GAO, Yurong WANG, Shujun ZHANG. Joint entity-relation extraction method for ancient Chinese books based on prompt learning and global pointer network [J]. Journal of Computer Applications, 2025, 45(1): 75-81. |
| [12] | Xindong YOU, Yingzi WEN, Xinpeng SHE, Xueqiang LYU. Triplet extraction method for mine electromechanical equipment field [J]. Journal of Computer Applications, 2024, 44(7): 2026-2033. |
| [13] | Xinyan YU, Cheng ZENG, Qian WANG, Peng HE, Xiaoyu DING. Few-shot news topic classification method based on knowledge enhancement and prompt learning [J]. Journal of Computer Applications, 2024, 44(6): 1767-1774. |
| [14] | Yuemei XU, Ling HU, Jiayi ZHAO, Wanze DU, Wenqing WANG. Technology application prospects and risk challenges of large language models [J]. Journal of Computer Applications, 2024, 44(6): 1655-1662. |
| [15] | Junfeng SHEN, Xingchen ZHOU, Can TANG. Dual-channel sentiment analysis model based on improved prompt learning method [J]. Journal of Computer Applications, 2024, 44(6): 1796-1806. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||