


Journal of Computer Applications ›› 2025, Vol. 45 ›› Issue (3): 685-696.DOI: 10.11772/j.issn.1001-9081.2025010128
• Frontier research and typical applications of large models • Next Articles
Xiaolin QIN1,2( ), Xu GU1,2, Dicheng LI1,2, Haiwen XU3
), Xu GU1,2, Dicheng LI1,2, Haiwen XU3
Received:2025-02-10
Revised:2025-02-17
Accepted:2025-02-19
Online:2025-02-27
Published:2025-03-10
Contact:
Xiaolin QIN
About author:GU Xu, born in 1998, Ph. D. candidate. His research interests include natural language processing, industry-specific large language models.Supported by:
秦小林1,2(), 古徐1,2, 李弟诚1,2, 徐海文3
通讯作者:
秦小林
作者简介:古徐(1998—),男,四川成都人,博士研究生,主要研究方向:自然语言处理、行业大模型基金资助:CLC Number:
Xiaolin QIN, Xu GU, Dicheng LI, Haiwen XU. Survey and prospect of large language models[J]. Journal of Computer Applications, 2025, 45(3): 685-696.
秦小林, 古徐, 李弟诚, 徐海文. 大语言模型综述与展望[J]. 《计算机应用》唯一官方网站, 2025, 45(3): 685-696.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2025010128

Fig. 1 Statistics of public LLMs’ parameters up to January 2025

Fig. 2 Comparison of different PLM architectures
| 架构 | 代表模型 | |
|---|---|---|
| 编码器架构 | BERT[ | |
| 编码器-解码器 | Flan-UL2[ | |
解码器 架构 | 因果解码器 | GPT系列[ |
| 前缀解码器 | PaLM[ | |
Tab. 1 Existing LLM architectures and models
| 架构 | 代表模型 | |
|---|---|---|
| 编码器架构 | BERT[ | |
| 编码器-解码器 | Flan-UL2[ | |
解码器 架构 | 因果解码器 | GPT系列[ |
| 前缀解码器 | PaLM[ | |
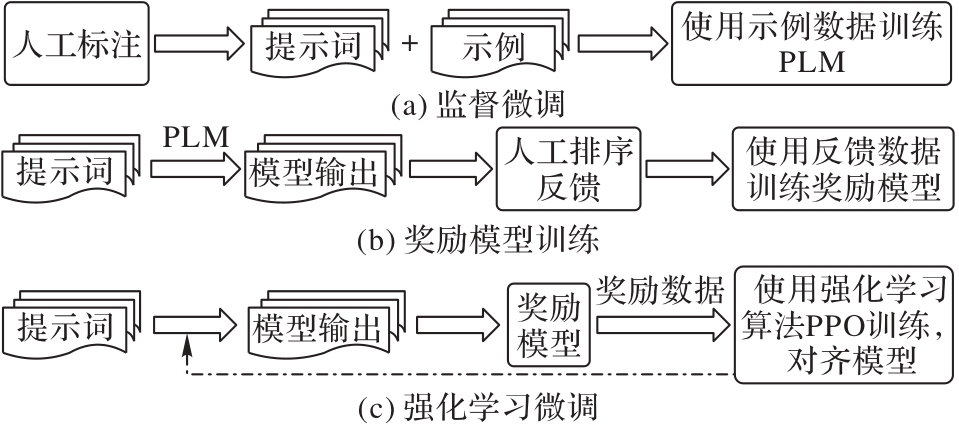
Fig. 3 Process of RLHF and other training strategies

Fig. 4 Statistics of LLM products’ comprehensive performance (up to January 2025)
| 模型 | 不同领域的准确率/% | ELO分数 | |
|---|---|---|---|
| SWE-bench Verified | AIME | Codeforces | |
| OpenAI o1-preview | 41.3 | 56.7 | 1 258 |
| Open AI o1 | 48.9 | 83.3 | 1 891 |
| Open AI o3 | 71.7 | 96.7 | 2 727 |
Tab. 2 Performance comparison results of OpenAI o1 and OpenAI o3
| 模型 | 不同领域的准确率/% | ELO分数 | |
|---|---|---|---|
| SWE-bench Verified | AIME | Codeforces | |
| OpenAI o1-preview | 41.3 | 56.7 | 1 258 |
| Open AI o1 | 48.9 | 83.3 | 1 891 |
| Open AI o3 | 71.7 | 96.7 | 2 727 |
| RAG框架 | 聚焦点 | 关键组件 | 应用场景 | 灵活性 | 集成难易度 | 开发者适用性 |
|---|---|---|---|---|---|---|
| Llamalndex | 语言模型与外部资源的深度集成 | 数据连接器、引擎、数据代理、索引管理等组件 | 语义搜索、文档索引等任务 | 专为数据索引与搜索优化,具备较高专注性 | 与数据源集成较为顺畅,数据源实时接入 | LLM数据增强,注重数据整理与搜索 |
| LangChain | 索引构建与检索优化 | 检索系统、数据索引机制等 | 上下文感知查询、数据处理任务等 | 技术简单易于构建,对复杂任务的扩展性相对不足 | 与各种数据源和服务的兼容性强,能够灵活应对集成需求 | 构建知识问答系统、文档搜索引擎及其他海量数据处理场景 |
| RAGflow | 智能文档解析和管理 | 智能文档解析系统、基于LLM的查询、文档上传与管理、多个处理模板 | 会计、人力资源、研究等行业应用的智能文档处理,基于证据的问答 | 高度定制化的文档处理,支持多种行业与角色的需求 | 易于集成文档上传和管理,支持多种文档格式及行业特定需求 | 开发智能文档处理系统并结合LLM查询 |
Tab. 3 Comparison of different RAG frameworks
| RAG框架 | 聚焦点 | 关键组件 | 应用场景 | 灵活性 | 集成难易度 | 开发者适用性 |
|---|---|---|---|---|---|---|
| Llamalndex | 语言模型与外部资源的深度集成 | 数据连接器、引擎、数据代理、索引管理等组件 | 语义搜索、文档索引等任务 | 专为数据索引与搜索优化,具备较高专注性 | 与数据源集成较为顺畅,数据源实时接入 | LLM数据增强,注重数据整理与搜索 |
| LangChain | 索引构建与检索优化 | 检索系统、数据索引机制等 | 上下文感知查询、数据处理任务等 | 技术简单易于构建,对复杂任务的扩展性相对不足 | 与各种数据源和服务的兼容性强,能够灵活应对集成需求 | 构建知识问答系统、文档搜索引擎及其他海量数据处理场景 |
| RAGflow | 智能文档解析和管理 | 智能文档解析系统、基于LLM的查询、文档上传与管理、多个处理模板 | 会计、人力资源、研究等行业应用的智能文档处理,基于证据的问答 | 高度定制化的文档处理,支持多种行业与角色的需求 | 易于集成文档上传和管理,支持多种文档格式及行业特定需求 | 开发智能文档处理系统并结合LLM查询 |

Fig. 5 Structure of Agent development framework

Fig. 6 Framework of perception for embodied Agents
| 1 | CHOMSKY N. Syntactic structures [M]. Berlin: De Gruyter Mouton, 1957: 8-29. |
| 2 | WEIZENBAUM J. ELIZA — a computer program for the study of natural language communication between man and machine [J]. Communications of the ACM, 1966, 9(1): 36-45. |
| 3 | MILLER G A. WordNet: a lexical database for English [J]. Communications of the ACM, 1995, 38(11): 39-41. |
| 4 | BRANTS T, POPAT A C, XU P, et al. Large language models in machine translation [C]// Proceedings of the 2007 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning. Stroudsburg: ACL, 2007: 858-867. |
| 5 | BERGER A L, DELLA PIETRA S A, DELLA PIETRA V J. A maximum entropy approach to natural language processing [J]. Computational Linguistics, 1996, 22(1): 39-71. |
| 6 | BENGIO Y, DUCHARME R, VINCENT P, et al. A neural probabilistic language model [J]. Journal of Machine Learning Research, 2003, 3: 1137-1155. |
| 7 | LIPTON Z C, BERKOWITZ J, ELKAN C. A critical review of recurrent neural networks for sequence learning [EB/OL]. [2024-08-01]. . |
| 8 | SCHMIDHUBER J, HOCHREITER S. Long short-term memory[J]. Neural Computation, 1997, 9(8): 1735-1780. |
| 9 | WU Y, SCHUSTER M, CHEN Z, et al. Google’s neural machine translation system: bridging the gap between human and machine translation [EB/OL]. [2024-03-02]. . |
| 10 | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2017: 6000-6010. |
| 11 | ZHOU Y, MURESANU A I, HAN Z, et al. Large language models are human-level prompt engineers [EB/OL]. [2024-08-23]. . |
| 12 | DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional Transformers for language understanding [C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Stroudsburg: ACL, 2019: 4171-4186. |
| 13 | RADFORD A, NARASIMHAN K, SALIMANS T, et al. Improving language understanding by generative pre-training [EB/OL]. [2024-10-01]. . |
| 14 | RADFORD A, WU J, CHILD R, et al. Language models are unsupervised multitask learners [EB/OL]. [2024-01-13]. . |
| 15 | BROWN T B, MANN B, RYDER N, et al. Language models are few-shot learners [C]// Proceedings of the 34th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2020: 1877-1901. |
| 16 | HUANG J, CHANG K C C. Towards reasoning in large language models: a survey [C]// Findings of the Association for Computational Linguistics: ACL 2023. Stroudsburg: ACL, 2023: 1049-1065. |
| 17 | WENG Y, ZHU M, XIA F, et al. Large language models are better reasoners with self-verification [C]// Findings of the Association for Computational Linguistics: EMNLP 2023. Stroudsburg: ACL, 2023: 2550-2575. |
| 18 | PENG K, DING L, ZHONG Q, et al. Towards making the most of ChatGPT for machine translation [C]// Findings of the Association for Computational Linguistics: EMNLP 2023. Stroudsburg: ACL, 2023: 5622-5633. |
| 19 | SHAILENDRA P, GHOSH R C, KUMAR R, et al. Survey of large language models for answering questions across various fields[C]// Proceedings of the 10th International Conference on Advanced Computing and Communication Systems. Piscataway: IEEE, 2024: 520-527. |
| 20 | GU X, CHEN X, LU P, et al. AGCVT-prompt for sentiment classification: automatically generating chain of thought and verbalizer in prompt learning [J]. Engineering Applications of Artificial Intelligence, 2024, 132: No.107907. |
| 21 | OpenAI. GPT-4 technical report [R/OL]. [2024-07-12].. |
| 22 | LIU P, YUAN W, FU J, et al. Pre-train, prompt, and predict: a systematic survey of prompting methods in natural language processing[J]. ACM Computing Surveys, 2023, 55(9): No.195. |
| 23 | 张钦彤,王昱超,王鹤羲,等. 大语言模型微调技术的研究综述[J]. 计算机工程与应用, 2024, 60(17):17-33. |
| ZHANG Q T, WANG Y C, WANG H X, et al. Comprehensive review of large language model fine-tuning [J]. Computer Engineering and Applications, 2024, 60(17): 17-33. | |
| 24 | 罗锦钊,孙玉龙,钱增志,等. 人工智能大模型综述及展望 [J]. 无线电工程, 2023, 53(11): 2461-2472. |
| LUO J Z, SUN Y L, QIAN Z Z, et al. Overview and prospect of artificial intelligence large models [J]. Radio Engineering, 2023, 53(11): 2461-2472. | |
| 25 | 张俊,徐箭,许沛东,等. 人工智能大模型在电力系统运行控制中的应用综述及展望[J]. 武汉大学学报(工学版), 2023, 56(11):1368-1379. |
| ZHANG J, XU J, XU P D, et al. Review and prospect of application of artificial intelligence large model in power system operation control [J]. Engineering Journal of Wuhan University, 2023, 56(11): 1368-1379. | |
| 26 | 刘安平,金昕,胡国强. 人工智能大模型综述及金融应用展望[J]. 人工智能, 2023(2):29-40. |
| LIU A P, JIN X, HU G Q. Overview of large models of artificial Intelligence and their prospects of financial applications [J]. Artificial Intelligence View, 2023(2): 29-40. | |
| 27 | Team Qwen. Qwen2.5 technical report[R/OL]. [2025-01-13]. . |
| 28 | DeepSeek-AI. DeepSeek-V3 technical report [R/OL]. [2025-02-19]. . |
| 29 | JIANG A Q, SABLAYROLLES A, ROUX A, et al. Mixtral of experts [EB/OL]. [2024-10-24]. . |
| 30 | JIAO X, YIN Y, SHANG L, et al. TinyBERT: distilling BERT for natural language understanding [C]// Findings of the Association for Computational Linguistics: EMNLP 2020. Stroudsburg: ACL, 2020: 4163-4174. |
| 31 | BAI H, ZHANG W, HOU L, et al. BinaryBERT: pushing the limit of BERT quantization [C]// Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Stroudsburg: ACL, 2021: 4334-4348. |
| 32 | LAN Z, CHEN M, GOODMAN S, et al. ALBERT: a lite BERT for self-supervised learning of language representations [EB/OL]. [2024-04-23]. . |
| 33 | SHAZEER N. GLU variants improve transformer[EB/OL]. [2024-03-14]. . |
| 34 | WARNER B, CHAFFIN A, CLAVIÉ B, et al. Smarter, better, faster, longer: a modern bidirectional encoder for fast, memory efficient, and long context finetuning and inference [EB/OL]. [2024-12-25]. . |
| 35 | SU J, AHMED M, LU Y, et al. Roformer: enhanced Transformer with rotary position embedding [J]. Neurocomputing, 2024, 568: No.127063. |
| 36 | DAO T. FlashAttention-2: faster attention with better parallelism and work partitioning [EB/OL]. [2024-11-07]. . |
| 37 | TAY Y, DEHGHANI M, TRAN V Q, et al. UL2: unifying language learning paradigms [EB/OL]. [2024-06-03]. . |
| 38 | RAFFEL C, SHAZEER N, ROBERTS A, et al. Exploring the limits of transfer learning with a unified text-to-text Transformer[J]. Journal of Machine Learning Research, 2020, 21: 1-67. |
| 39 | LEWIS M, LIU Y, GOYAL N, et al. BART: denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension [C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2020: 7871-7880. |
| 40 | XUE L, CONSTANT N, ROBERTS A, et al. mT5: a massively multilingual pre-trained Text-to-Text Transformer [C]// Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics. Stroudsburg: ACL, 2021: 483-498. |
| 41 | Workshop BigScience. BLOOM: a 176B-parameter open-access multilingual language model [EB/OL]. [2024-09-04]. . |
| 42 | ZHANG S, ROLLER S, GOYAL N, et al. OPT: open pre-trained Transformer language models [EB/OL]. [2024-05-01]. . |
| 43 | RAE J W, BORGEAUD S, CAI T, et al. Scaling language models: methods, analysis & insights from training gopher [EB/OL]. [2024-11-03]. . |
| 44 | TOUVRON H, LAVRIL T, IZACARD G, et al. LLaMA: open and efficient foundation language models [EB/OL]. [2024-12-22]. . |
| 45 | Team GLM. ChatGLM: a family of large language models from GLM-130B to GLM-4 all tools [EB/OL]. [2024-09-13]. . |
| 46 | YANG A, XIAO B, WANG B, et al. Baichuan 2: open large-scale language models [EB/OL]. [2024-02-01]. . |
| 47 | CHOWDHERY A, NARANG S, DEVLIN J, et al. PaLM: scaling language modeling with pathways [J]. Journal of Machine Learning Research, 2023, 24: 1-113. |
| 48 | DU Z, QIAN Y, LIU X, et al. GLM: general language model pretraining with autoregressive blank infilling [C]// Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2022: 320-335. |
| 49 | KINGMA D P, BA L J. Adam: a method for stochastic optimization [EB/OL]. [2024-05-05]. . |
| 50 | LOSHCHILOV I, HUTTER F. Decoupled weight decay regularization [EB/OL]. [2023-11-01]. . |
| 51 | SHAZEER N, STERN M. Adafactor: adaptive learning rates with sublinear memory cost [C]// Proceedings of the 35th International Conference on Machine Learning. New York: JMLR.org, 2018: 4596-4604. |
| 52 | ZHENG Q, XIA X, ZOU X, et al. CodeGeeX: a pre-trained model for code generation with multilingual benchmarking on HumanEval-X [C]// Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. New York: ACM, 2023: 5673-5684. |
| 53 | RASLEY J, RAJBHANDARI S, RUWASE O, et al. DeepSpeed: system optimizations enable training deep learning models with over 100 billion parameters [C]// Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2020: 3505-3506. |
| 54 | MICIKEVICIUS P, NARANG S, ALBEN J, et al. Mixed precision training [EB/OL]. [2024-08-17]. . |
| 55 | DETTMERS T, LEWIS M, BELKADA Y, et al. LLM.int8(): 8-bit matrix multiplication for transformers at scale [C]// Proceedings of the 36th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2022: 30318-30332. |
| 56 | MiniMax. MiniMax-01: scaling foundation models with lightning attention [EB/OL]. [2025-02-11]. . |
| 57 | WEI J, TAY Y, BOMMASANI R, et al. Emergent abilities of large language models [EB/OL]. [2024-03-23]. . |
| 58 | TAO C, HOU L, ZHANG W, et al. Compression of generative pre-trained language models via quantization [C]// Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2022: 4821-4836. |
| 59 | JACOBS R A, JORDAN M I, NOWLAN S J, et al. Adaptive mixtures of local experts [J]. Neural Computation, 1991, 3(1): 79-87. |
| 60 | FEDUS W, ZOPH B, SHAZEER N. Switch Transformers: scaling to trillion parameter models with simple and efficient sparsity [J]. Journal of Machine Learning Research, 2022, 23: 1-39. |
| 61 | SCHULMAN J, WOLSKI F, DHARIWAL P, et al. Proximal policy optimization algorithms [EB/OL]. [2024-06-01]. . |
| 62 | STIENNON N, OUYANG L, WU J, et al. Learning to summarize from human feedback [C]// Proceedings of the 34th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2020: 3008-3021. |
| 63 | LIU X, ZHENG Y, DU Z, et al. GPT understands, too [J]. AI Open, 2024, 5: 208-215. |
| 64 | SCHICK T, SCHÜTZE H. Exploiting cloze-questions for few-shot text classification and natural language inference [C]// Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume. Stroudsburg: ACL, 2021: 255-269. |
| 65 | LI X L, LIANG P. Prefix-tuning: optimizing continuous prompts for generation [C]// Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Stroudsburg: ACL, 2021: 4582-4597. |
| 66 | KAPLAN J, McCANDLISH S, HENIGHAN T, et al. Scaling laws for neural language models [EB/OL]. [2024-05-14]. . |
| 67 | HOFFMANN J, BORGEAUD S, MENSCH A, et al. Training compute-optimal large language models [C]// Proceedings of the 36th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2022: 30016-30030. |
| 68 | DeepSeek-AI. DeepSeek-R1: incentivizing reasoning capability in LLMs via reinforcement learning [EB/OL]. [2025-02-07]. . |
| 69 | ROMAN R S, ADI Y, DELEFORGE A, et al. From discrete tokens to high-fidelity audio using multi-band diffusion [C]// Proceedings of the 37th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2023: 1526-1538. |
| 70 | ZIV A, GAT I, LE LAN G, et al. Masked audio generation using a single non-autoregressive Transformer [EB/OL]. [2024-09-01].. |
| 71 | SCHNEIDER S, BAEVSKI A, COLLOBERT R, et al. Wav2Vec: unsupervised pre-training for speech recognition [C]// Proceedings of the INTERSPEECH 2019. [S.l.]: International Speech Communication Association, 2019: 3465-3469. |
| 72 | CHUNG Y A, ZHANG Y, HAN W, et al. w2v-BERT: combining contrastive learning and masked language modeling for self-supervised speech pre-training [C]// Proceedings of the 2021 IEEE Automatic Speech Recognition and Understanding Workshop. Piscataway: IEEE, 2021: 244-250. |
| 73 | JIN M, WEN Q, LIANG Y, et al. Large models for time series and spatio-temporal data: a survey and outlook [EB/OL]. [2024-01-24]. . |
| 74 | YANG C H H, TSAI Y Y, CHEN P Y. Voice2Series: reprogramming acoustic models for time series classification [C]// Proceedings of the 38th International Conference on Machine Learning. JMLR.org, 2021: 11808-11819. |
| 75 | YUE Z, WANG Y, DUAN J, et al. TS2Vec: towards universal representation of time series [C]// Proceedings of the 36th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2022: 8980-8987. |
| 76 | VAYYAT M, KASI J, BHATTACHARYA A, et al. CLUDA: contrastive learning in unsupervised domain adaptation for semantic segmentation [EB/OL]. [2024-11-21]. . |
| 77 | BROOKS T, PEEBLES B, HOLMES C, et al. Video generation models as world simulators [EB/OL]. [2024-07-21]. . |
| 78 | DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16x16 words: Transformers for image recognition at scale[EB/OL]. [2024-08-11]. . |
| 79 | RADFORD A, KIM J W, HALLACY C, et al. Learning transferable visual models from natural language supervision [C]// Proceedings of the 38th International Conference on Machine Learning. New York: JMLR.org, 2021: 8748-8763. |
| 80 | ZHAI X, MUSTAFA B, KOLESNIKOV A, et al. Sigmoid loss for language image pre-training [C]// Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2023: 11941-11952. |
| 81 | CHEN X, WANG X, BEYER L, et al. PaLI-3 vision language models: smaller, faster, stronger [EB/OL]. [2024-08-24].. |
| 82 | XU L, LI A, ZHU L, et al. SuperCLUE: a comprehensive Chinese large language model benchmark [EB/OL]. [2025-01-08]. . |
| 83 | Team Kimi. Kimi k 1.5: scaling reinforcement learning with LLMs[R/OL]. [2025-02-12]. . |
| 84 | SANH V, DEBUT L, CHAUMOND J, et al. DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter[EB/OL]. [2024-08-23]. . |
| 85 | TAMBE T, HOOPER C, PENTECOST L, et al. EdgeBERT: sentence-level energy optimizations for latency-aware multi-task NLP inference [C]// Proceedings of the 54th Annual IEEE/ACM International Symposium on Microarchitecture. New York: ACM, 2021: 830-844. |
| 86 | GULATI A, QIN J, CHIU C C, et al. Conformer: convolution-augmented Transformer for speech recognition [C]// Proceedings of the INTERSPEECH 2020. [S.l.]: International Speech Communication Association, 2020: 5036-5040. |
| 87 | TAN M, LE Q V. EfficientNet: rethinking model scaling for convolutional neural networks [C]// Proceedings of the 36th International Conference on Machine Learning. New York: JMLR.org, 2019: 6105-6114. |
| 88 | WANG L, MA C, FENG X, et al. A survey on large language model based autonomous agents [J]. Frontiers of Computer Science, 2024, 18(6): No.186345. |
| 89 | XI Z, CHEN W, GUO X, et al. The rise and potential of large language model based agents: a survey [J]. SCIENCE CHINA Information Sciences, 2025, 68(2): No.121101. |
| 90 | LI L, XIAO J, CHEN G, et al. Zero-shot visual relation detection via composite visual cues from large language models [C]// Proceedings of the 37th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2023: 50105-50116. |
| 91 | LI H, HAO Y, ZHAI Y, et al. The Hitchhiker’s guide to program analysis: a journey with large language models [EB/OL]. [2024-09-06]. . |
| 92 | LIN B Y, FU Y, YANG K, et al. SwiftSage: a generative agent with fast and slow thinking for complex interactive tasks [C]// Proceedings of the 37th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2023: 23813-23825. |
| 93 | MANDI Z, JAIN S, SONG S. RoCo: dialectic multi-robot collaboration with large language models [C]// Proceedings of the 2024 IEEE International Conference on Robotics and Automation. Piscataway: IEEE, 2024: 286-299. |
| 94 | ZHANG C, YANG K, HU S, et al. ProAgent: building proactive cooperative agents with large language models [C]// Proceedings of the 38th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2024: 17591-17599. |
| 95 | KANG Y, KIM J. ChatMOF: an autonomous AI system for predicting and generating metal-organic frameworks [J]. Nature Communications, 2024, 15: No.4705. |
| 96 | CHEN P L, CHANG C S. InterAct: exploring the potentials of ChatGPT as a cooperative agent [EB/OL]. [2024-03-11]. . |
| 97 | SHI J, ZHAO J, WANG Y, et al. CGMI: configurable general multi-agent interaction framework [EB/OL]. [2024-02-21].. |
| 98 | ZHOU W, JIANG Y E, LI L, et al. Agents: an open-source framework for autonomous language agents [EB/OL]. [2024-01-22]. . |
| 99 | LIU Y, CHEN W, BAI Y, et al. Aligning cyber space with physical world: a comprehensive survey on embodied AI [EB/OL]. [2024-12-01]. . |
| 100 | DUAN J, YU S, TAN H L, et al. A survey of embodied AI: from simulators to research tasks [J]. IEEE Transactions on Emerging Topics in Computational Intelligence, 2022, 6(2): 230-244. |
| 101 | PFEIFER R, BONGARD J. How the body shapes the way we think: a new view of intelligence [M]. Cambridge: MIT Press, 2006. |
| 102 | ZHU Z, MA X, CHEN Y, et al. 3D-VisTA: pre-trained Transformer for 3D vision and text alignment [C]// Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2023: 2899-2909. |
| 103 | YANG Y, SUN F Y, WEIHS L, et al. Holodeck: language guided generation of 3D embodied AI environments [C]// Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2024: 16277-16287. |
| 104 | YAN C, QU D, XU D, et al. GS-SLAM: dense visual SLAM with 3D Gaussian splatting [C]// Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2024: 19595-19604. |
| 105 | WU X, JIANG L, WANG P S, et al. Point Transformer V3: simpler faster stronger [C]// Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2024: 4840-4851. |
| 106 | CAI W, HUANG S, CHENG G, et al. Bridging zero-shot object navigation and foundation models through pixel-guided navigation skill [C]// Proceedings of the 2024 IEEE International Conference on Robotics and Automation. Piscataway: IEEE, 2024: 5228-5234. |
| 107 | WU Y, CHENG X, ZHANG R, et al. EDA: explicit text-decoupling and dense alignment for 3D visual grounding [C]// Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2023: 19231-19242. |
| 108 | WANG T, MAO X, ZHU C, et al. EmbodiedScan: a holistic multi-modal 3D perception suite towards embodied AI [C]// Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2024: 19757-19767. |
| 109 | GE Y, TANG Y, XU J, et al. BEHAVIOR Vision Suite: customizable dataset generation via simulation [C]// Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2024: 22401-22412. |
| 110 | GAN C, SCHWARTZ J, ALTER S, et al. ThreeDWorld: a platform for interactive multi-modal physical simulation [EB/OL]. [2024-03-23]. . |
| 111 | CHEN J, LIN B, XU R, et al. MapGPT: map-guided prompting with adaptive path planning for vision-and-language navigation[C]// Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2024: 9796-9810. |
| [1] | Jing WANG, Xuming FANG. Intelligent joint power and channel allocation algorithm for Wi-Fi7 multi-link integrated communication and sensing [J]. Journal of Computer Applications, 2025, 45(2): 563-570. |
| [2] | Xueqiang LYU, Tao WANG, Xindong YOU, Ge XU. HTLR: named entity recognition framework with hierarchical fusion of multi-knowledge [J]. Journal of Computer Applications, 2025, 45(1): 40-47. |
| [3] | Qi SHUAI, Hairui WANG, Guifu ZHU. Chinese story ending generation model based on bidirectional contrastive training [J]. Journal of Computer Applications, 2024, 44(9): 2683-2688. |
| [4] | Quanmei ZHANG, Runping HUANG, Fei TENG, Haibo ZHANG, Nan ZHOU. Automatic international classification of disease coding method incorporating heterogeneous information [J]. Journal of Computer Applications, 2024, 44(8): 2476-2482. |
| [5] | Youren YU, Yangsen ZHANG, Yuru JIANG, Gaijuan HUANG. Chinese named entity recognition model incorporating multi-granularity linguistic knowledge and hierarchical information [J]. Journal of Computer Applications, 2024, 44(6): 1706-1712. |
| [6] | Yuemei XU, Ling HU, Jiayi ZHAO, Wanze DU, Wenqing WANG. Technology application prospects and risk challenges of large language models [J]. Journal of Computer Applications, 2024, 44(6): 1655-1662. |
| [7] | Xiaofang LIU, Jun ZHANG. Probability-driven dynamic multiobjective evolutionary optimization for multi-agent cooperative scheduling [J]. Journal of Computer Applications, 2024, 44(5): 1372-1377. |
| [8] | Longtao GAO, Nana LI. Aspect sentiment triplet extraction based on aspect-aware attention enhancement [J]. Journal of Computer Applications, 2024, 44(4): 1049-1057. |
| [9] | Xianfeng YANG, Yilei TANG, Ziqiang LI. Aspect-level sentiment analysis model based on alternating‑attention mechanism and graph convolutional network [J]. Journal of Computer Applications, 2024, 44(4): 1058-1064. |
| [10] | Baoshan YANG, Zhi YANG, Xingyuan CHEN, Bing HAN, Xuehui DU. Analysis of consistency between sensitive behavior and privacy policy of Android applications [J]. Journal of Computer Applications, 2024, 44(3): 788-796. |
| [11] | Zhaojun TANG, Meiyan XIA, Hua ZHANG, Ting XIE. Fixed-time consensus of dynamic event-triggered multi-agent systems [J]. Journal of Computer Applications, 2024, 44(3): 960-965. |
| [12] | Kaitian WANG, Qing YE, Chunlei CHENG. Classification method for traditional Chinese medicine electronic medical records based on heterogeneous graph representation [J]. Journal of Computer Applications, 2024, 44(2): 411-417. |
| [13] | Fuqin DENG, Huifeng GUAN, Chaoen TAN, Lanhui FU, Hongmin WANG, Tinlun LAM, Jianmin ZHANG. Multi-robot reinforcement learning path planning method based on request-response communication mechanism and local attention mechanism [J]. Journal of Computer Applications, 2024, 44(2): 432-438. |
| [14] | Fuqin DENG, Chaoen TAN, Junwei LI, Jiaming ZHONG, Lanhui FU, Jianmin ZHANG, Hongmin WANG, Nannan LI, Bingchun JIANG, Tin Lun LAM. Conflict-based search algorithm for large-scale warehousing environment [J]. Journal of Computer Applications, 2024, 44(12): 3854-3860. |
| [15] | Yu WANG, Zhihui GUAN, Yuanpeng LI. Distributed UAV cluster pursuit decision-making based on trajectory prediction and MADDPG [J]. Journal of Computer Applications, 2024, 44(11): 3623-3628. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||