


Journal of Computer Applications ›› 2025, Vol. 45 ›› Issue (12): 3947-3956.DOI: 10.11772/j.issn.1001-9081.2024111677
• Network and communications • Previous Articles Next Articles
Xiang KUANG1, Zhen MA2,3( ), Wanchun ZHU1, Zhi ZHANG1, Yunfei CUI1
), Wanchun ZHU1, Zhi ZHANG1, Yunfei CUI1
Received:2024-11-29
Revised:2025-03-29
Accepted:2025-03-31
Online:2025-04-08
Published:2025-12-10
Contact:
Zhen MA
About author:KUANG Xiang, born in 1991, lecturer. His research interests include network optimization,deep learning, system maintenance.Supported by:
况翔1, 马震2,3(), 朱万春1, 张智1, 崔云飞1
通讯作者:
马震
作者简介:况翔(1991—),男,贵州赫章人,讲师,主要研究方向:网络优化、深度学习、系统运维基金资助:CLC Number:
Xiang KUANG, Zhen MA, Wanchun ZHU, Zhi ZHANG, Yunfei CUI. Secure and reliable service function chain deployment based on encoder-decoder structured reinforcement learning[J]. Journal of Computer Applications, 2025, 45(12): 3947-3956.
况翔, 马震, 朱万春, 张智, 崔云飞. 基于编解码结构强化学习的安全可靠服务功能链部署[J]. 《计算机应用》唯一官方网站, 2025, 45(12): 3947-3956.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2024111677
| 符号 | 含义 | 符号 | 含义 |
|---|---|---|---|
| 物理网络p加权图 | SFC请求 | ||
| 网络节点集合 | 物理/SFC请求节点 | ||
| 网络链接集合 | 物理/SFC请求 | ||
| 物理节点 | SFC请求节点ni 资源 | ||
| 物理节点安全等级 | SFC请求 等级 | ||
| SFC请求i的时延 | 节点资源集合 |
Tab. 1 Explanation of main symbols
| 符号 | 含义 | 符号 | 含义 |
|---|---|---|---|
| 物理网络p加权图 | SFC请求 | ||
| 网络节点集合 | 物理/SFC请求节点 | ||
| 网络链接集合 | 物理/SFC请求 | ||
| 物理节点 | SFC请求节点ni 资源 | ||
| 物理节点安全等级 | SFC请求 等级 | ||
| SFC请求i的时延 | 节点资源集合 |
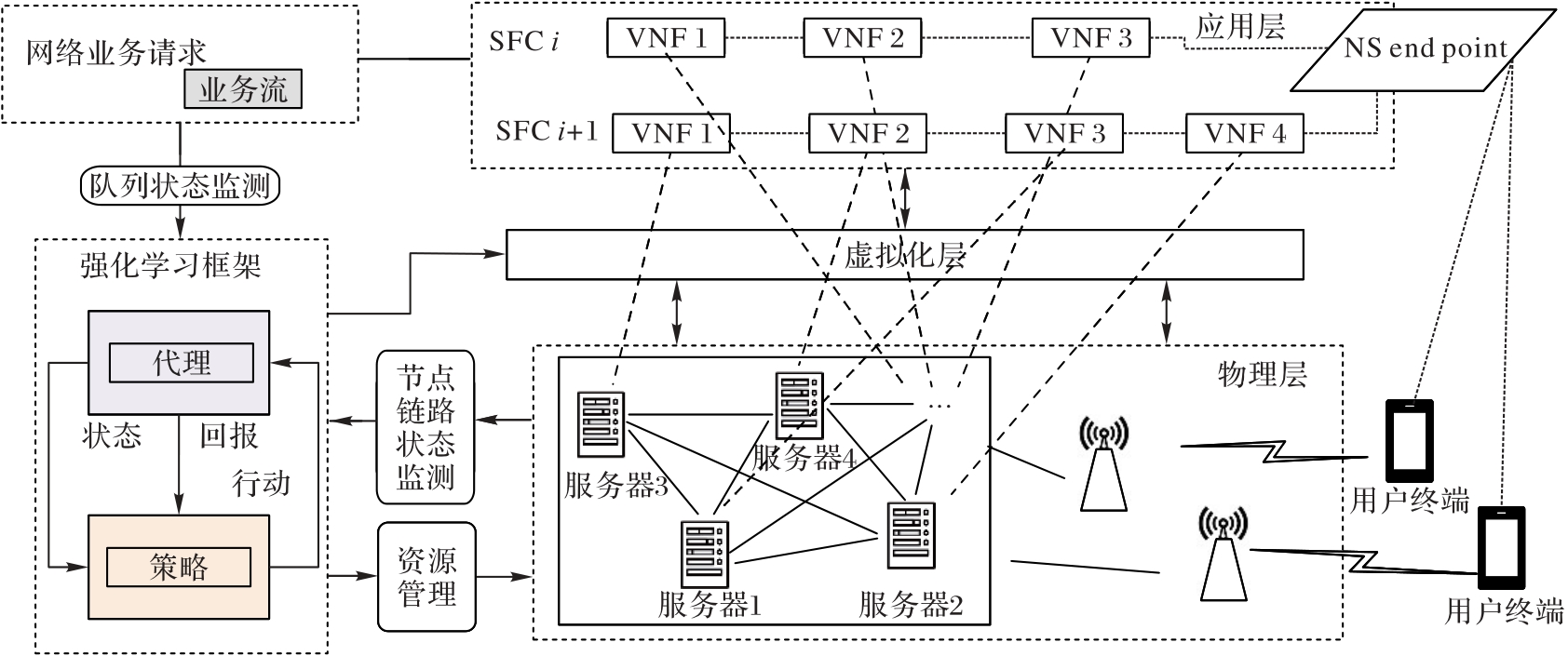
Fig. 1 Network scenario
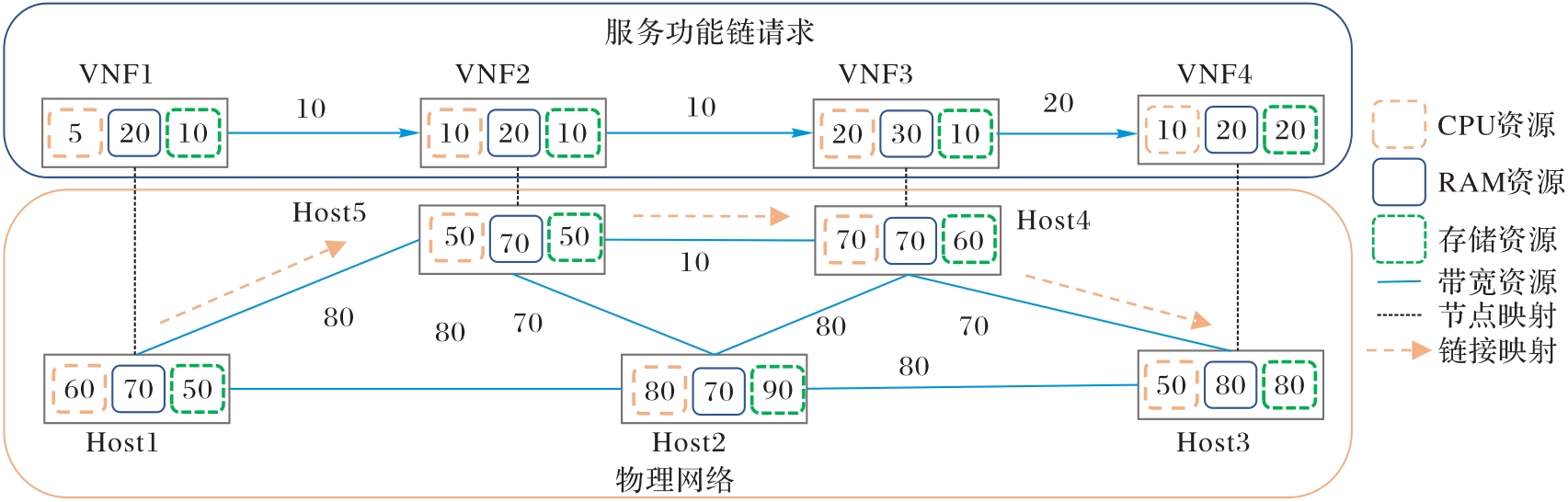
Fig. 2 Example of deploying an SFC request (Host represents a certain type of host on server)
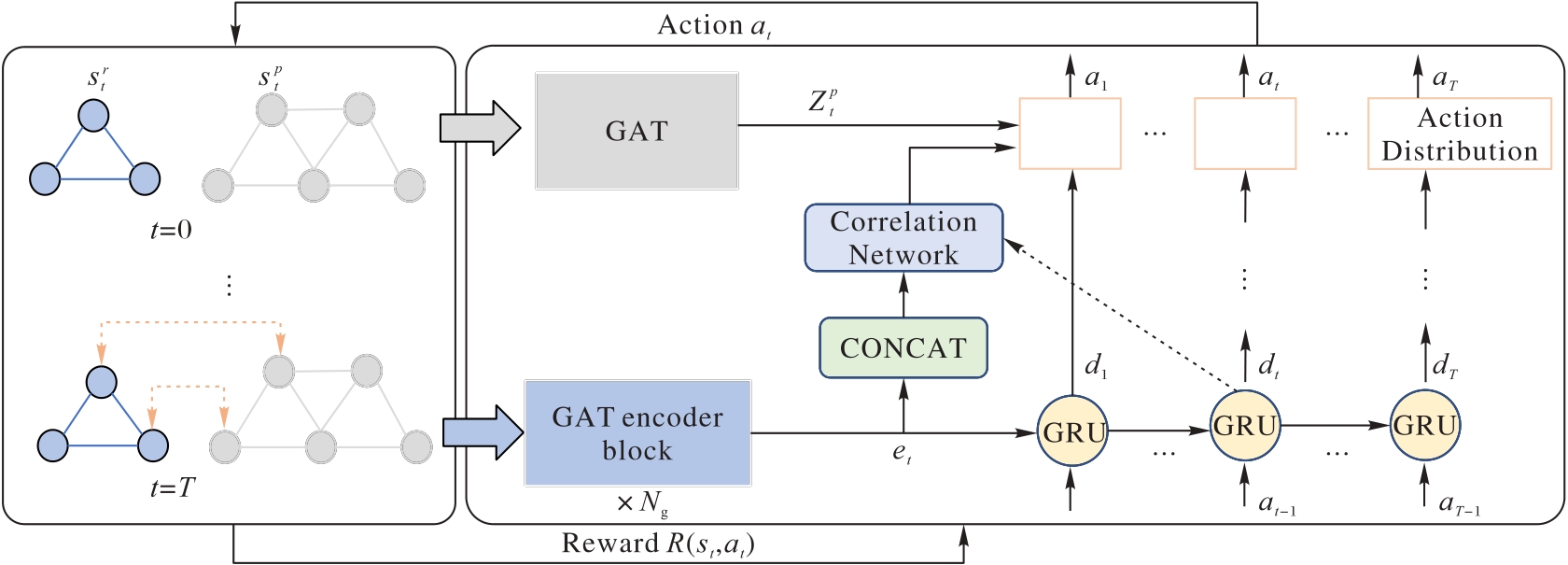
Fig. 3 Architecture of deep reinforcement learning SFC deployment method based on GAT-GRU encoder-decoder
| 仿真参数 | 设置值 | 仿真参数 | 设置值 |
|---|---|---|---|
| 批量大小 | 128 | 奖励系数 | 0.125 |
| 资源的单价 | 0.001 | 折扣因子 | 0.93 |
| 带宽的单价 | 0.001 | 演员网络学习能力 | 0.000 25 |
| 演员网络数 | 4 | 评论家网络学习能力 | 0.000 5 |
Tab.2 Training parameter setting of ED-DRL
| 仿真参数 | 设置值 | 仿真参数 | 设置值 |
|---|---|---|---|
| 批量大小 | 128 | 奖励系数 | 0.125 |
| 资源的单价 | 0.001 | 折扣因子 | 0.93 |
| 带宽的单价 | 0.001 | 演员网络学习能力 | 0.000 25 |
| 演员网络数 | 4 | 评论家网络学习能力 | 0.000 5 |
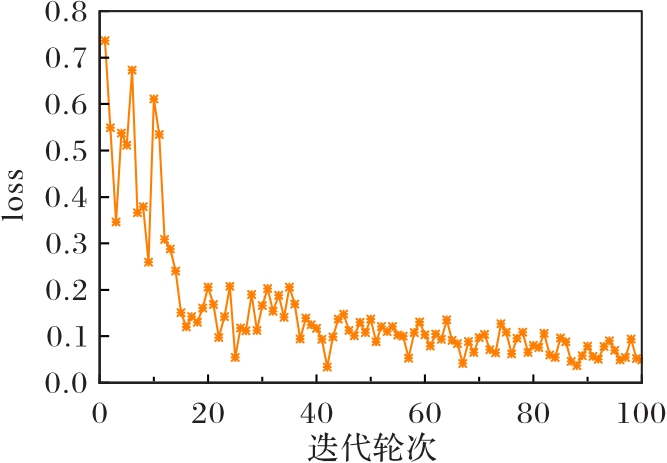
Fig. 4 Loss change during training process
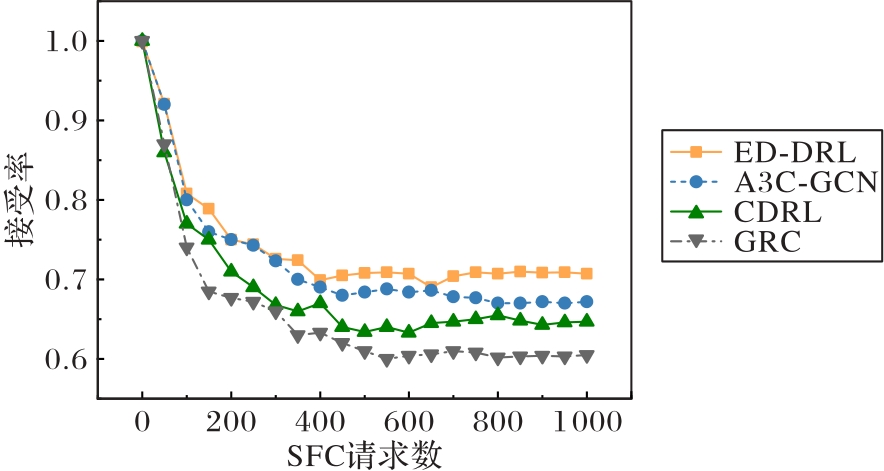
Fig. 5 Acceptance ratios of different SFC request quantities
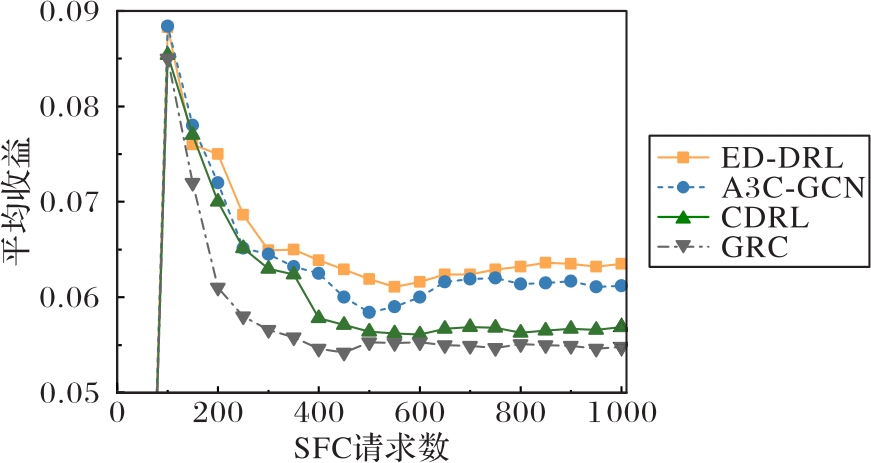
Fig.6 Average revenues under different SFC request quantities
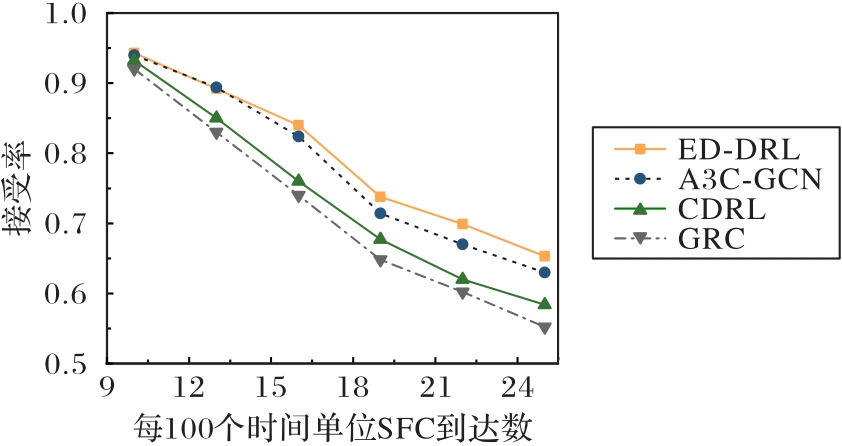
Fig. 7 Acceptance rates under different arrival rates
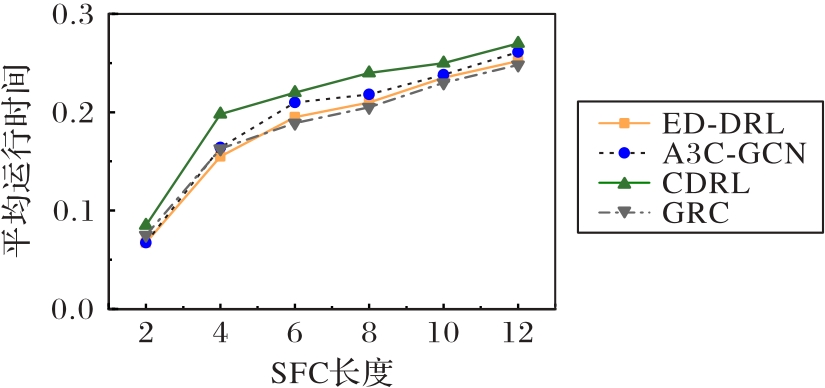
Fig.8 Average running time under different SFC lengths
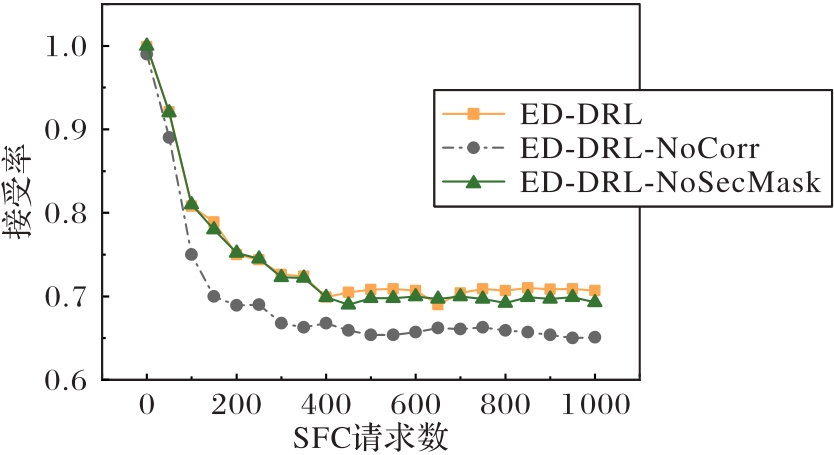
Fig.9 Acceptance rates of different SFC request quantities in ablation experiments
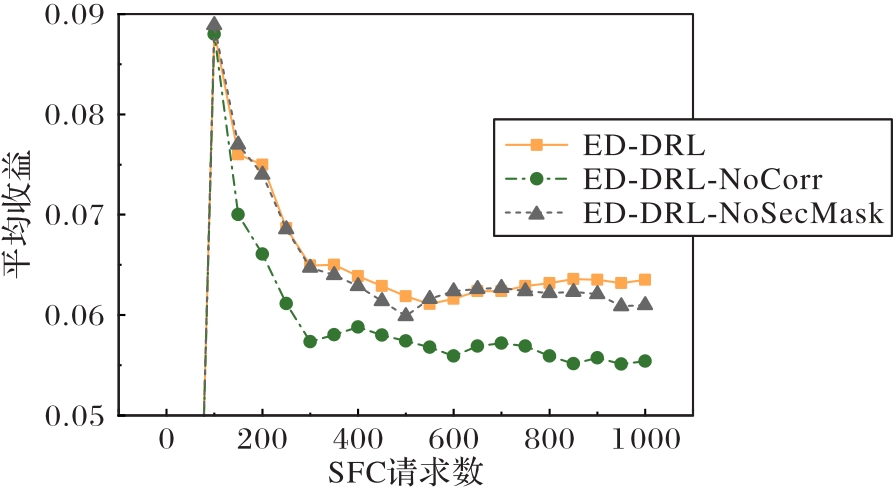
Fig.10 Average revenues under different SFC request quantities in ablation experiments
| [1] | 乔文欣,卢昱,刘益岑,等. 空天地协同的边缘云服务功能链动态编排方法[J]. 西安电子科技大学学报, 2022, 49(2): 79-88. |
| QIAO W X, LU Y, LIU Y C, et al. Dynamic scheduling method for service function chains in space air terrestrial aided edge cloud networks[J]. Journal of Xidian University, 2022, 49(2): 79-88. | |
| [2] | ZHUANG W, YE Q, LYU F, et al. SDN/NFV-empowered future IoV with enhanced communication, computing, and caching[J]. Proceedings of the IEEE, 2020, 108(2): 274-291. |
| [3] | 畅海峰,嵩天,杨雅婷. NFV中单节点启发式资源分配方法[J]. 计算机工程与应用, 2020, 56(11): 105-111. |
| CHANG H F, SONG T, YANG Y T. Heuristic method of resource allocation on single node in NFV[J]. Computer Engineering and Applications, 2020, 56(11): 105-111. | |
| [4] | YAO H, MA S, WANG J, et al. A continuous-decision virtual network embedding scheme relying on reinforcement learning[J]. IEEE Transactions on Network and Service Management, 2020, 17(2): 864-875. |
| [5] | FISCHER A, BOTERO J F, BECK M T, et al. Virtual network embedding: a survey[J]. IEEE Communications Surveys and Tutorials, 2013, 15(4): 1888-1906. |
| [6] | YANG L, ZHANG Y, ZHENG G, et al. Policy optimization with stochastic mirror descent[C]// Proceedings of the 36th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2022: 8823-8831. |
| [7] | 梁俊斌,黄少东,吴旭,等. 绿色移动边缘网络中可靠的虚拟网络功能部署技术研究[J]. 计算机应用研究, 2023, 40(12): 3521-3528, 3538. |
| LIANG J B, HUANG S D, WU X, et al. Research on reliable virtual network function deployment technology mobile edge networks[J]. Application Research of Computers, 2023, 40(12): 3521-3528, 3538. | |
| [8] | ZHU Y, AMMAR M. Algorithms for assigning substrate network resources to virtual network components[C]// Proceedings of the 25th IEEE International Conference on Computer Communications. Piscataway: IEEE, 2006: 1-12. |
| [9] | 许道强,邹云峰,邓君华,等. 面向NUMA架构的虚拟网络功能部署技术研究[J]. 计算机工程与应用, 2019, 55(21): 115-121, 157. |
| XU D Q, ZOU Y F, DENG J H, et al. Research on virtual network function chain deployment for NUMAS systems[J]. Computer Engineering and Applications, 2019, 55(21): 115-121, 157. | |
| [10] | CAO H, YANG L, LIU Z, et al. Exact solutions of VNE: a survey[J]. China Communications, 2016, 13(6): 48-62. |
| [11] | SUN Q, LU P, LU W, et al. Forecast-assisted NFV service chain deployment based on affiliation-aware vNF placement[C]// Proceedings of the 2016 IEEE Global Communications Conference. Piscataway: IEEE, 2016: 1-6. |
| [12] | YU M, YI Y, REXFORD J, et al. Rethinking virtual network embedding: Substrate support for path splitting and migration[J]. ACM SIGCOMM Computer Communication Review, 2008, 38(2): 17-29. |
| [13] | CHENG X, SU S, ZHANG Z, et al. Virtual network embedding through topology-aware node ranking[J]. ACM SIGCOMM Computer Communication Review, 2011, 41(2): 38-47. |
| [14] | JIN P, FEI X, ZHANG Q, et al. Latency-aware VNF chain deployment with efficient resource reuse at network edge[C]// Proceedings of the 2020 IEEE Conference on Computer Communications. Piscataway: IEEE, 2020: 267-276. |
| [15] | FAN W, XIAO F, LV M, et al. Node essentiality assessment and distributed collaborative virtual network embedding in datacenters[J]. IEEE Transactions on Parallel and Distributed Systems, 2023, 34(4): 1265-1280. |
| [16] | ZHANG P, YAO H, LIU Y. Virtual network embedding based on computing, network, and storage resource constraints[J]. IEEE Internet of Things Journal, 2018, 5(5): 3298-3304. |
| [17] | DEHURY C K, SAHOO P K. DYVINE: fitness-based dynamic virtual network embedding in cloud computing[J]. IEEE Journal on Selected Areas in Communications, 2019, 37(5): 1029-1045. |
| [18] | XIAO Y, ZHANG Q, LIU F, et al. NFVdeep: adaptive online service function chain deployment with deep reinforcement learning[C]// Proceedings of the IEEE/ACM 27th International Symposium on Quality of Service. New York: ACM, 2019: No.21. |
| [19] | 王晓,唐伦,贺小雨,等. 基于深度强化学习的服务功能链多维资源优化[J]. 计算机工程与应用, 2021, 57(4): 68-76. |
| WANG X, TANG L, HE X Y, et al. Multi-dimensional resource optimization of service function chain based on deep reinforcement learning[J]. Computer Engineering and Applications, 2021, 57(4): 68-76. | |
| [20] | SOLOZABAL R, CEBERIO J, SANCHOYERTO A, et al. Virtual network function placement optimization with deep reinforcement learning[J]. IEEE Journal on Selected Areas in Communications, 2020, 38(2): 292-303. |
| [21] | WANG T, FAN Q, LI X, et al. DRL-SFCP: adaptive service function chains placement with deep reinforcement learning[C]// Proceedings of the 2021 IEEE International Conference on Communications. Piscataway: IEEE, 2021: 1-6. |
| [22] | ZHANG P, SU Y, WANG J, et al. Reinforcement learning assisted bandwidth aware virtual network resource allocation[J]. IEEE Transactions on Network and Service Management, 2022, 19(4): 4111-4123. |
| [23] | ZHANG X, CUI L, TSO F P, et al. Dapper: deploying service function chains in the programmable data plane via deep reinforcement learning[J]. IEEE Transactions on Services Computing, 2023, 16(4): 2532-2544. |
| [24] | KIPF T N, WELLING M. Semi-supervised classification with graph convolutional networks[EB/OL]. [2024-11-11]. . |
| [25] | MNIH V M, BADIA A P, MIRZA M, et al. Asynchronous methods for deep reinforcement learning[C]// Proceedings of the 33rd International Conference on Machine Learning. New York: JMLR.org, 2016: 1928-1937. |
| [26] | 朱子怡,张建辉,曾俊杰,等. 基于深度强化学习的安全感知服务功能链部署方法[J/OL]. 计算机科学 [2024-11-23].. |
| ZHU Z Y, ZHANG J H, ZENG J J, et al. Security-aware service function chain deployment method based on deep reinforcement learning [J/OL]. Computer Science [2024-11-23].. | |
| [27] | ZENG J, DING D, KANG K, et al. Adaptive DRL-based virtual machine consolidation in energy-efficient cloud data center[J]. IEEE Transactions on Parallel and Distributed Systems, 2022, 33(11): 2991-3002. |
| [28] | VELIČKOVIĆ P, CUCURULL G, CASANOVA A, et al. Graph attention networks[EB/OL]. [2024-11-11]. . |
| [29] | HE N, YANG S, LI F, et al. Leveraging deep reinforcement learning with attention mechanism for virtual network function placement and routing[J]. IEEE Transactions on Parallel and Distributed Systems, 2023, 34(4): 1186-1201. |
| [30] | WAXMAN B M. Routing of multipoint connections[J]. IEEE Journal on Selected Areas in Communications, 1988, 6(9): 1617-1622. |
| [31] | GONG L, WEN Y, ZHU Z, et al. Toward profit-seeking virtual network embedding algorithm via global resource capacity[C]// Proceedings of the 2014 IEEE Conference on Computer Communications. Piscataway: IEEE, 2014: 1-9. |
| [1] | Xingyao YANG, Zheng QI, Jiong YU, Zulian ZHANG, Shuai MA, Hongtao SHEN. Session-based recommendation model based on time-aware and space-enhanced dual channel graph neural network [J]. Journal of Computer Applications, 2026, 46(1): 104-112. |
| [2] | Lijin YAO, Di ZHANG, Piyu ZHOU, Zhijian QU, Haipeng WANG. Transformer and gated recurrent unit-based de novo sequencing algorithm for phosphopeptides [J]. Journal of Computer Applications, 2026, 46(1): 297-304. |
| [3] | Shuo ZHANG, Guokai SUN, Yuan ZHUANG, Xiaoyu FENG, Jingzhi WANG. Dynamic detection method of eclipse attacks for blockchain node analysis [J]. Journal of Computer Applications, 2025, 45(8): 2428-2436. |
| [4] | Kaile YU, Jiajun LIAO, Jiali MAO, Xiaopeng HUANG. Multi-objective optimization of steel logistics vehicle-cargo matching under multiple constraints [J]. Journal of Computer Applications, 2025, 45(8): 2477-2483. |
| [5] | Tianyu XUE, Aiping LI, Liguo DUAN. Vehicular edge computing scheme with task offloading and resource optimization [J]. Journal of Computer Applications, 2025, 45(6): 1766-1775. |
| [6] | Pengcheng XU, Lei HE, Chuan LI, Weiqi QIAN, Tun ZHAO. Deep symbolic regression method based on Transformer [J]. Journal of Computer Applications, 2025, 45(5): 1455-1463. |
| [7] | Jiaxin LI, Site MO. Power work order classification in substation area based on MiniRBT-LSTM-GAT and label smoothing [J]. Journal of Computer Applications, 2025, 45(4): 1356-1362. |
| [8] | Jing WANG, Xuming FANG. Intelligent joint power and channel allocation algorithm for Wi-Fi7 multi-link integrated communication and sensing [J]. Journal of Computer Applications, 2025, 45(2): 563-570. |
| [9] | Huahua WANG, Liang HUANG, Jiajie CHEN, Jiening FANG. Dynamic allocation algorithm for multi-beam subcarriers of low orbit satellites based on deep reinforcement learning [J]. Journal of Computer Applications, 2025, 45(2): 571-577. |
| [10] | Jun ZENG, Yinghua TONG, Defang WANG. Anomaly detection method based on cumulative probability fluctuation and automated clustering [J]. Journal of Computer Applications, 2025, 45(12): 3864-3871. |
| [11] | Haoxiang XU, Dunhui YU, Yichen DENG, Kui XIAO. Knowledge graph constrained question answering model based on hierarchical reinforcement learning [J]. Journal of Computer Applications, 2025, 45(12): 3764-3770. |
| [12] | Chengyi WANG, Lei XU, Jinyin CHEN, Hongjun QIU. Cyber anti-mapping method based on adaptive perturbation [J]. Journal of Computer Applications, 2025, 45(12): 3896-3908. |
| [13] | Xiaojuan CHEN, Wei ZHANG. Task allocation of unmanned aerial vehicle for rural last-mile delivery based on reinforcement learning [J]. Journal of Computer Applications, 2025, 45(12): 4055-4063. |
| [14] | Lin WEI, Shihao ZHANG, Mengyang HE. Workflow task optimization and energy-efficient offloading method for computing power network [J]. Journal of Computer Applications, 2025, 45(12): 3916-3924. |
| [15] | Lin WEI, Jinyang LI, Yajie WANG, Mengyang HE. Highly reliable matching method based on multi-dimensional resource measurement and rescheduling in computing power network [J]. Journal of Computer Applications, 2025, 45(11): 3632-3641. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||