


Journal of Computer Applications ›› 2026, Vol. 46 ›› Issue (5): 1441-1449.DOI: 10.11772/j.issn.1001-9081.2025050716
• Artificial intelligence • Previous Articles
Qianfei WANG1, Yang LI2( ), Deyu LI1,3, Suge WANG1,3
), Deyu LI1,3, Suge WANG1,3
Received:2025-06-30
Revised:2025-07-23
Accepted:2025-07-31
Online:2025-09-15
Published:2026-05-10
Contact:
Yang LI
About author:WANG Qianfei, born in 1999, M. S. candidate. His research interests include data mining.Supported by:
王倩飞1, 李旸2(), 李德玉1,3, 王素格1,3
通讯作者:
李旸
作者简介:王倩飞(1999—),男,山西运城人,硕士研究生,主要研究方向:数据挖掘基金资助:CLC Number:
Qianfei WANG, Yang LI, Deyu LI, Suge WANG. Dual-channel feature fusion representation method for short-text clustering based on large language model[J]. Journal of Computer Applications, 2026, 46(5): 1441-1449.
王倩飞, 李旸, 李德玉, 王素格. 基于大语言模型的双通道特征融合表示的短文本聚类方法[J]. 《计算机应用》唯一官方网站, 2026, 46(5): 1441-1449.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2025050716
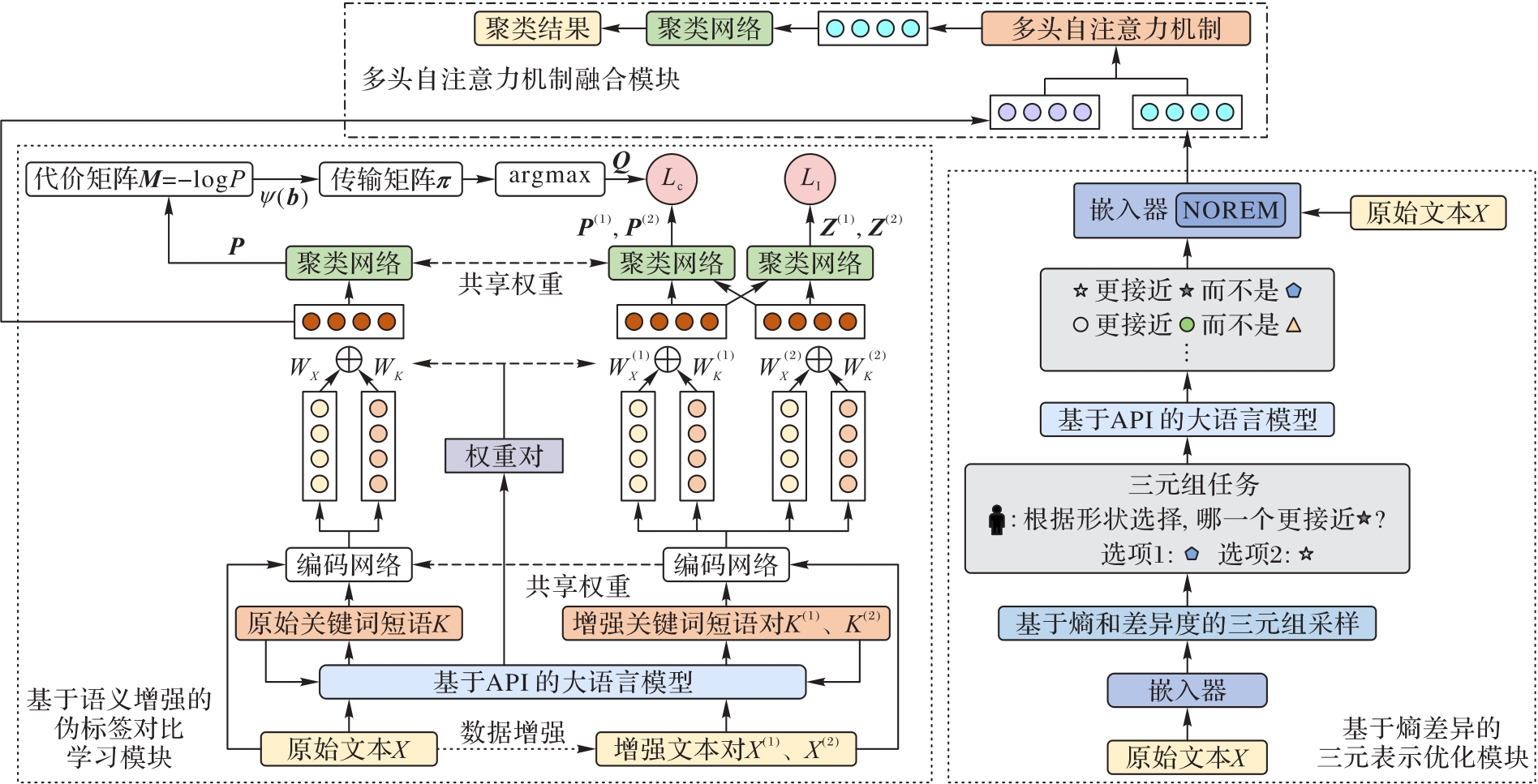
Fig. 1 DCFF model structure

Fig. 2 Noise-optimized reliability-enhanced mechanism
| 方法 | Tweet | AgNews | Biomedical | SearchSnippets | GoogleNews-TS | GoogleNews-T | GoogleNews-S | StackOverflow | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ACC | NMI | ACC | NMI | ACC | NMI | ACC | NMI | ACC | NMI | ACC | NMI | ACC | NMI | ACC | NMI | |
| K-means_IC | 66.54 | 84.84 | 66.30 | 42.03 | 40.44 | 32.16 | 63.84 | 42.03 | 79.81 | 92.91 | 68.88 | 83.55 | 74.48 | 88.53 | 74.96 | 70.27 |
| SCCL | 73.10 | 86.66 | 83.10 | 61.96 | 42.49 | 39.16 | 79.90 | 63.78 | 82.51 | 93.01 | 69.01 | 85.10 | 73.44 | 87.98 | 70.83 | 69.21 |
| CLUSTERLLM | 68.18 | 87.29 | 83.53 | 59.54 | 46.37 | 37.45 | 78.36 | 65.18 | 74.88 | 92.41 | 69.94 | 87.04 | 71.54 | 89.50 | 85.72 | 81.58 |
| RSTC | 75.20 | 87.35 | 84.24 | 62.45 | 48.40 | 40.12 | 80.10 | 69.74 | 83.27 | 93.15 | 72.27 | 87.39 | 79.32 | 89.40 | 83.30 | 74.11 |
| STSPL-SSC | 79.59 | 88.02 | 89.92 | 71.66 | 47.43 | 42.49 | 81.04 | 65.46 | 84.41 | 94.32 | 81.01 | 91.11 | 82.30 | 91.18 | 86.74 | 82.54 |
| MIST | 91.75 | 95.12 | 89.47 | 70.25 | 39.15 | 34.66 | 76.72 | 67.69 | 90.63 | 96.42 | 78.80 | 89.31 | 82.14 | 90.86 | 79.65 | 78.59 |
| DCFF | 92.83 | 95.78 | 91.61 | 71.43 | 49.32 | 44.83 | 83.60 | 73.20 | 91.75 | 96.88 | 84.20 | 93.15 | 84.47 | 91.72 | 87.80 | 81.46 |
Tab. 1 Comparison experimental results
| 方法 | Tweet | AgNews | Biomedical | SearchSnippets | GoogleNews-TS | GoogleNews-T | GoogleNews-S | StackOverflow | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ACC | NMI | ACC | NMI | ACC | NMI | ACC | NMI | ACC | NMI | ACC | NMI | ACC | NMI | ACC | NMI | |
| K-means_IC | 66.54 | 84.84 | 66.30 | 42.03 | 40.44 | 32.16 | 63.84 | 42.03 | 79.81 | 92.91 | 68.88 | 83.55 | 74.48 | 88.53 | 74.96 | 70.27 |
| SCCL | 73.10 | 86.66 | 83.10 | 61.96 | 42.49 | 39.16 | 79.90 | 63.78 | 82.51 | 93.01 | 69.01 | 85.10 | 73.44 | 87.98 | 70.83 | 69.21 |
| CLUSTERLLM | 68.18 | 87.29 | 83.53 | 59.54 | 46.37 | 37.45 | 78.36 | 65.18 | 74.88 | 92.41 | 69.94 | 87.04 | 71.54 | 89.50 | 85.72 | 81.58 |
| RSTC | 75.20 | 87.35 | 84.24 | 62.45 | 48.40 | 40.12 | 80.10 | 69.74 | 83.27 | 93.15 | 72.27 | 87.39 | 79.32 | 89.40 | 83.30 | 74.11 |
| STSPL-SSC | 79.59 | 88.02 | 89.92 | 71.66 | 47.43 | 42.49 | 81.04 | 65.46 | 84.41 | 94.32 | 81.01 | 91.11 | 82.30 | 91.18 | 86.74 | 82.54 |
| MIST | 91.75 | 95.12 | 89.47 | 70.25 | 39.15 | 34.66 | 76.72 | 67.69 | 90.63 | 96.42 | 78.80 | 89.31 | 82.14 | 90.86 | 79.65 | 78.59 |
| DCFF | 92.83 | 95.78 | 91.61 | 71.43 | 49.32 | 44.83 | 83.60 | 73.20 | 91.75 | 96.88 | 84.20 | 93.15 | 84.47 | 91.72 | 87.80 | 81.46 |
| 模块 | Tweet | AgNews | Biomedical | SearchSnippets | GoogleNews-TS | GoogleNews-T | GoogleNews-S | StackOverflow | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ACC | NMI | ACC | NMI | ACC | NMI | ACC | NMI | ACC | NMI | ACC | NMI | ACC | NMI | ACC | NMI | |
| DCFF | 92.83 | 95.78 | 91.61 | 71.43 | 49.32 | 44.83 | 83.60 | 73.20 | 91.75 | 96.88 | 84.20 | 93.15 | 84.47 | 91.72 | 87.80 | 81.46 |
| -SE | 91.71 | 95.20 | 90.88 | 70.28 | 48.05 | 43.91 | 81.82 | 72.37 | 90.92 | 95.67 | 82.25 | 92.28 | 83.80 | 90.58 | 86.76 | 81.04 |
| -Difference | 91.42 | 94.72 | 90.56 | 70.83 | 47.47 | 44.34 | 82.83 | 72.85 | 91.28 | 95.89 | 82.65 | 92.33 | 83.51 | 90.73 | 87.13 | 80.67 |
| -Confidence | 91.96 | 94.55 | 90.61 | 69.80 | 48.61 | 44.00 | 83.35 | 71.79 | 90.63 | 96.43 | 83.46 | 92.81 | 82.85 | 90.45 | 86.55 | 80.65 |
| -AdvDenoise | 92.52 | 95.11 | 91.12 | 70.45 | 49.10 | 43.66 | 82.48 | 72.49 | 90.47 | 95.96 | 82.59 | 92.54 | 83.60 | 90.37 | 86.41 | 80.69 |
Tab. 2 Ablation experimental results
| 模块 | Tweet | AgNews | Biomedical | SearchSnippets | GoogleNews-TS | GoogleNews-T | GoogleNews-S | StackOverflow | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ACC | NMI | ACC | NMI | ACC | NMI | ACC | NMI | ACC | NMI | ACC | NMI | ACC | NMI | ACC | NMI | |
| DCFF | 92.83 | 95.78 | 91.61 | 71.43 | 49.32 | 44.83 | 83.60 | 73.20 | 91.75 | 96.88 | 84.20 | 93.15 | 84.47 | 91.72 | 87.80 | 81.46 |
| -SE | 91.71 | 95.20 | 90.88 | 70.28 | 48.05 | 43.91 | 81.82 | 72.37 | 90.92 | 95.67 | 82.25 | 92.28 | 83.80 | 90.58 | 86.76 | 81.04 |
| -Difference | 91.42 | 94.72 | 90.56 | 70.83 | 47.47 | 44.34 | 82.83 | 72.85 | 91.28 | 95.89 | 82.65 | 92.33 | 83.51 | 90.73 | 87.13 | 80.67 |
| -Confidence | 91.96 | 94.55 | 90.61 | 69.80 | 48.61 | 44.00 | 83.35 | 71.79 | 90.63 | 96.43 | 83.46 | 92.81 | 82.85 | 90.45 | 86.55 | 80.65 |
| -AdvDenoise | 92.52 | 95.11 | 91.12 | 70.45 | 49.10 | 43.66 | 82.48 | 72.49 | 90.47 | 95.96 | 82.59 | 92.54 | 83.60 | 90.37 | 86.41 | 80.69 |
| 融合方法 | ACC | NMI |
|---|---|---|
| 相加 | 81.71 | 79.79 |
| 拼接 | 81.84 | 80.11 |
| 最大池化 | 82.37 | 79.94 |
| 多头自注意力机制 | 83.19 | 81.05 |
Tab. 3 Experimental results for different fusion methods
| 融合方法 | ACC | NMI |
|---|---|---|
| 相加 | 81.71 | 79.79 |
| 拼接 | 81.84 | 80.11 |
| 最大池化 | 82.37 | 79.94 |
| 多头自注意力机制 | 83.19 | 81.05 |
| 头数 | ACC/% | NMI/% | 头数 | ACC/% | NMI/% |
|---|---|---|---|---|---|
| 2 | 80.78 | 79.68 | 16 | 81.46 | 79.13 |
| 4 | 82.24 | 80.21 | 32 | 82.71 | 80.80 |
| 8 | 83.19 | 81.05 |
Tab. 4 Experimental results with varying attention heads
| 头数 | ACC/% | NMI/% | 头数 | ACC/% | NMI/% |
|---|---|---|---|---|---|
| 2 | 80.78 | 79.68 | 16 | 81.46 | 79.13 |
| 4 | 82.24 | 80.21 | 32 | 82.71 | 80.80 |
| 8 | 83.19 | 81.05 |
| λ | ACC/% | NMI/% | λ | ACC/% | NMI/% |
|---|---|---|---|---|---|
| 0.0 | 82.10 | 80.29 | 1.5 | 81.60 | 79.50 |
| 0.5 | 81.20 | 79.30 | 2.0 | 79.90 | 77.20 |
| 1.0 | 83.19 | 81.05 |
Tab. 5 Impact of hyperparameter λ on model performance
| λ | ACC/% | NMI/% | λ | ACC/% | NMI/% |
|---|---|---|---|---|---|
| 0.0 | 82.10 | 80.29 | 1.5 | 81.60 | 79.50 |
| 0.5 | 81.20 | 79.30 | 2.0 | 79.90 | 77.20 |
| 1.0 | 83.19 | 81.05 |
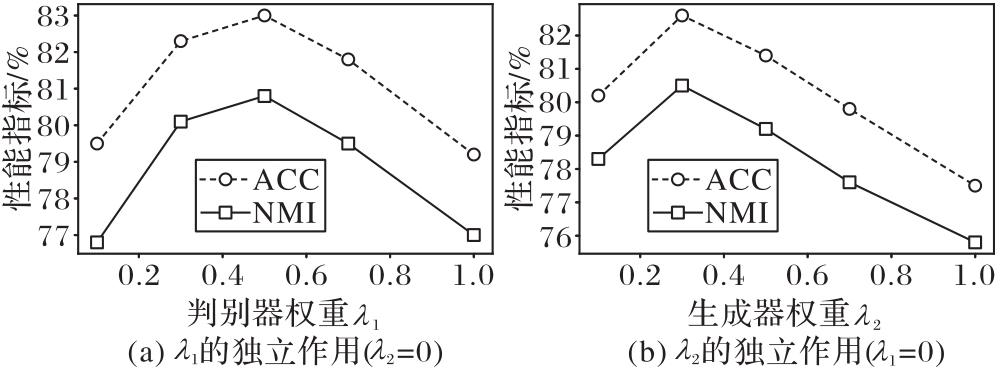
Fig. 3 Single-parameter preliminary search
| ACC/% | NMI/% | ACC/% | NMI/% | ACC/% | NMI/% | |
|---|---|---|---|---|---|---|
| 0.4 | 82.50 | 80.20 | 82.90 | 80.60 | 82.30 | 79.90 |
| 0.5 | 82.80 | 80.50 | 83.19 | 81.05 | 82.70 | 80.30 |
| 0.6 | 82.20 | 79.80 | 82.60 | 80.20 | 81.90 | 79.50 |
Tab. 6 Experimental results of grid search
| ACC/% | NMI/% | ACC/% | NMI/% | ACC/% | NMI/% | |
|---|---|---|---|---|---|---|
| 0.4 | 82.50 | 80.20 | 82.90 | 80.60 | 82.30 | 79.90 |
| 0.5 | 82.80 | 80.50 | 83.19 | 81.05 | 82.70 | 80.30 |
| 0.6 | 82.20 | 79.80 | 82.60 | 80.20 | 81.90 | 79.50 |
| [1] | LIU W, SU J, CHEN C, et al. Leveraging distribution alignment via Stein path for cross-domain cold-start recommendation[C]// Proceedings of the 35th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2021: 19223-19234. |
| [2] | STIEGLITZ S, MIRBABAIE M, ROSS B, et al. Social media analytics — challenges in topic discovery, data collection, and data preparation[J]. International Journal of Information Management, 2018, 39: 156-168. |
| [3] | LI J, SHAO H, SUN D, et al. Unsupervised belief representation learning with information-theoretic variational graph auto-encoders[C]// Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2022: 1728-1738. |
| [4] | DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional Transformers for language understanding[C]// Proceedings of the 2019 Conference of the North American chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Stroudsburg: ACL, 2019: 4171-4186. |
| [5] | LIU Z, LIN W, SHI Y, et al. A robustly optimized BERT pre-training approach with post-training[C]// Proceedings of the 20th Chinese National Conference on Computational Linguistics. Beijing: Chinese Information Processing Society of China, 2021: 1218-1227. |
| [6] | RAFFEL C, SHAZEER N, ROBERTS A, et al. Exploring the limits of transfer learning with a unified text-to-text Transformer[J]. Journal of Machine Learning Research, 2020, 21: 1-67. |
| [7] | GAO T, YAO X, CHEN D. SimCSE: simple contrastive learning of sentence embeddings[C]// Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2021: 6894-6910. |
| [8] | RADFORD A, NARASIMHAN K, SALIMANS T, et al. Improving language understanding by generative pre-training[EB/OL]. [2025-03-11].. |
| [9] | BEN-DAVID S, BLITZER J, CRAMMER K, et al. A theory of learning from different domains[J]. Machine Learning, 2010, 79(1/2): 151-175. |
| [10] | GURURANGAN S, MARASOVIĆ A, SWAYAMDIPTA S, et al. Don't stop pretraining: adapt language models to domains and tasks[C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2020: 8342-8360. |
| [11] | SCHICK T, SCHÜTZE H. Exploiting cloze-questions for few-shot text classification and natural language inference[C]// Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics : Main Volume. Stroudsburg: ACL, 2021: 255-269. |
| [12] | LESTER B, AL-RFOU R, CONSTANT N. The power of scale for parameter-efficient prompt tuning[C]// Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2021: 3045-3059. |
| [13] | DU L, DING X, LIU T, et al. Learning event graph knowledge for abductive reasoning[C]// Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Stroudsburg: ACL, 2021: 5181-5190. |
| [14] | PETERSEN H, POON J. Enhancing short text clustering with small external repositories[C]// Proceedings of the 9th Australasian Data Mining Conference. Ballarat: Australian Computer Society, 2011: 79-90. |
| [15] | FANG H, XIE P. An end-to-end contrastive self-supervised learning framework for language understanding[J]. Transactions of the Association for Computational Linguistics, 2022, 10: 1324-1340. |
| [16] | REIMERS N, GUREVYCH I. Sentence-BERT: sentence embeddings using Siamese BERT-networks[C]// Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Stroudsburg: ACL, 2019: 3982-3992. |
| [17] | OUYANG X, WANG Y, LI Q, et al. Leverage heterogeneous graph neural networks for short-text conceptualization[C]// Proceedings of the 2023 Chinese National Conference on Social Media Processing, CCIS 1945. Singapore: Springer, 2024: 90-103. |
| [18] | CAI L, SONG Y, LIU T, et al. A hybrid BERT model that incorporates label semantics via adjustive attention for multi-label text classification[J]. IEEE Access, 2020, 8: 152183-152192. |
| [19] | ZHANG X, ZHAO J, LeCUN Y. Character-level convolutional networks for text classification[C]// Proceedings of the 29th International Conference on Neural Information Processing Systems — Volume 1. Cambridge: MIT Press, 2015: 649-657. |
| [20] | CONNEAU A, KIELA D, SCHWENK H, et al. Supervised learning of universal sentence representations from natural language inference data[C]// Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2017: 670-680. |
| [21] | CAO K, WEI C, GAIDON A, et al. Learning imbalanced datasets with label-distribution-aware margin loss[C]// Proceedings of the 33rd International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2019: 1567-1578. |
| [22] | ZHANG Y, WANG Z, SHANG J. ClusterLLM: large language models as a guide for text clustering[C]// Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2023: 13903-13920. |
| [23] | XU J, XU B, WANG P, et al. Self-taught convolutional neural networks for short text clustering[J]. Neural Networks, 2017, 88: 22-31. |
| [24] | HADIFAR A, STERCKX L, DEMEESTER T, et al. A self-training approach for short text clustering[C]// Proceedings of the 4th Workshop on Representation Learning for NLP. Stroudsburg: ACL, 2019: 194-199. |
| [25] | HACOHEN-KERNER Y, MILLER D, YIGAL Y. The influence of preprocessing on text classification using a bag-of-words representation[J]. PLoS ONE, 2020, 15(5): No.e0232525. |
| [26] | RAKIB M R H, ZEH N, JANKOWSKA M, et al. Enhancement of short text clustering by iterative classification[C]// Proceedings of the 2020 International Conference on Applications of Natural Language to Information Systems, LNCS 12089. Cham: Springer, 2020: 105-117. |
| [27] | ZHANG D, NAN F, WEI X, et al. Supporting clustering with contrastive learning[C]// Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg: ACL, 2021: 5419-5430. |
| [28] | KAMTHAWEE K, UDOMCHAROENCHAIKIT C, NUTANONG S. MIST: mutual information maximization for short text clustering[C]// Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2024: 11309-11324. |
| [29] | CUTURI M. Sinkhorn distances: lightspeed computation of optimal transport[C]// Proceedings of the 27th International Conference on Neural Information Processing Systems — Volume 2. Red Hook: Curran Associates Inc., 2013: 2292-2300. |
| [30] | KOBAYASHI S. Contextual augmentation: data augmentation by words with paradigmatic relations[C]// Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers). Stroudsburg: ACL, 2018: 452-457. |
| [31] | ASANO Y M, RUPPRECHT C, VEDALDI A. Self-labelling via simultaneous clustering and representation learning[EB/OL]. [2025-04-09].. |
| [32] | VAN DER MAATEN L, HINTON G. Visualizing data using t-SNE[J]. Journal of Machine Learning Research, 2008, 9: 2579-2605. |
| [33] | SU H, SHI W, KASAI J, et al. One embedder, any task: instruction-finetuned text embeddings[C]// Findings of the Association for Computational Linguistics: ACL 2023. Stroudsburg: ACL, 2023: 1102-1121. |
| [34] | NI J, QU C, LU J, et al. Large dual encoders are generalizable retrievers[C]// Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2022: 9844-9855. |
| [35] | YIN J, WANG J. A model-based approach for text clustering with outlier detection[C]// Proceedings of the IEEE 32nd International Conference on Data Engineering. Piscataway: IEEE, 2016: 625-636. |
| [36] | PHAN X H, NGUYEN L M, HORIGUCHI S. Learning to classify short and sparse text & web with hidden topics from large-scale data collections[C]// Proceedings of the 17th International Conference on World Wide Web. New York: ACM, 2008: 91-100. |
| [37] | RABINER L. Combinatorial optimization: algorithms and complexity[J]. IEEE Transactions on Acoustics, Speech, and Signal Processing, 1984, 32(6): 1258-1259. |
| [38] | ZHENG X, HU M, LIU W, et al. Robust representation learning with reliable pseudo-labels generation via self-adaptive optimal transport for short text clustering[C]// Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2023: 10493-10507. |
| [39] | NIE W, DENG L, LIU C B, et al. STSPL-SSC: semi-supervised few-shot short text clustering with semantic text similarity optimized pseudo-labels[C]// Findings of the Association for Computational Linguistics: ACL 2024. Stroudsburg: ACL, 2024: 12174-12185. |
| [1] | Jiali ZHENG, Gang ZHOU, Jing CHEN, Shunhang LI. Adaptive multi-feature fusion detection method for AI-generated text [J]. Journal of Computer Applications, 2026, 46(5): 1433-1440. |
| [2] | Xiaoyu WANG, Xin LI, Di XUE, Zhangtao JIANG, Wei WANG, Yanjun XIAO. Vulnerability classification framework for video surveillance network security based on large language models [J]. Journal of Computer Applications, 2026, 46(4): 1158-1170. |
| [3] | Kaizhou SHI, Xuan HE, Guoyi HOU, Gen LI, Shuanggao LI, Xiang HUANG. Airborne product metrological traceability knowledge graph construction method based on large language models [J]. Journal of Computer Applications, 2026, 46(4): 1086-1095. |
| [4] | Haoyang ZHANG, Liping ZHANG, Sheng YAN, Na LI, Xuefei ZHANG. Review of large language model methods for knowledge graph completion [J]. Journal of Computer Applications, 2026, 46(3): 683-695. |
| [5] | Bin SHEN, Xiaoning CHEN, Hua CHENG, Yiquan FANG, Huifeng WANG. Intelligent undergraduate teaching evaluation system based on large language models [J]. Journal of Computer Applications, 2026, 46(3): 993-1003. |
| [6] | Enkang XI, Jing FAN, Yadong JIN, Hua DONG, Hao YU, Yihang SUN. Review of threats faced by federated learning in privacy and security field [J]. Journal of Computer Applications, 2026, 46(3): 798-808. |
| [7] | Yiming HUANG, Xihua ZOU, Guo DENG, Di ZHENG. Pre-answering and retrieval filtering: dual-stage optimization method for RAG-based question-answering systems [J]. Journal of Computer Applications, 2026, 46(3): 696-707. |
| [8] | Dingjia WU, Zhe CUI. MG-SQL: SQL generation framework with enhanced schema linking and multi-generator collaboration [J]. Journal of Computer Applications, 2026, 46(3): 723-731. |
| [9] | Rilong WANG, Zhenping LI, Xiaosong LI, Qiang GAO, Ya HE, Yong ZHONG, Yingxiao ZHAO. Multi-Agent collaborative knowledge reasoning framework [J]. Journal of Computer Applications, 2026, 46(3): 708-714. |
| [10] | Fei GAO, Dong CHEN, Dixing BIAN, Wenqiang FAN, Qidong LIU, Pei LYU, Chaoyang ZHANG, Mingliang XU. Multistage coupled decision-making framework for researcher redeployment after discipline revocation [J]. Journal of Computer Applications, 2026, 46(2): 416-426. |
| [11] | Hu LUO, Mingshu ZHANG. Rumor detection method based on cross-modal attention mechanism and contrastive learning [J]. Journal of Computer Applications, 2026, 46(2): 361-367. |
| [12] | Yixin LIU, Xianggen LIU, Wen LIU, Hongbo DENG, Ziye ZHANG, Hua MU. Benchmark dataset for retrieval-augmented generation on long documents [J]. Journal of Computer Applications, 2026, 46(2): 386-394. |
| [13] | Xinran XIE, Zhe CUI, Rui CHEN, Tailai PENG, Dekun LIN. Zero-shot re-ranking method by large language model with hierarchical filtering and label semantic extension [J]. Journal of Computer Applications, 2026, 46(1): 60-68. |
| [14] | Yi LIN, Bing XIA, Yong WANG, Shunda MENG, Juchong LIU, Shuqin ZHANG. AI-Agent based method for hidden RESTful API discovery and vulnerability detection [J]. Journal of Computer Applications, 2026, 46(1): 135-143. |
| [15] | Xiang WANG, Zhixiang CHEN, Guojun MAO. Multivariate time series prediction method combining local and global correlation [J]. Journal of Computer Applications, 2025, 45(9): 2806-2816. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||