


Journal of Computer Applications ›› 2026, Vol. 46 ›› Issue (1): 60-68.DOI: 10.11772/j.issn.1001-9081.2025010082
• Artificial intelligence • Previous Articles Next Articles
Xinran XIE1,2, Zhe CUI1,2( ), Rui CHEN1,2, Tailai PENG1,2, Dekun LIN1,2
), Rui CHEN1,2, Tailai PENG1,2, Dekun LIN1,2
Received:2025-01-21
Revised:2025-03-12
Accepted:2025-03-12
Online:2026-01-10
Published:2026-01-10
Contact:
Zhe CUI
About author:XIE Xinran, born in 1997, Ph. D. candidate. Her research interests include natural language processing, information retrieval.Supported by:
谢欣冉1,2, 崔喆1,2(), 陈睿1,2, 彭泰来1,2, 林德坤1,2
通讯作者:
崔喆
作者简介:谢欣冉(1997—),女,四川南充人,博士研究生,主要研究方向:自然语言处理、信息检索基金资助:CLC Number:
Xinran XIE, Zhe CUI, Rui CHEN, Tailai PENG, Dekun LIN. Zero-shot re-ranking method by large language model with hierarchical filtering and label semantic extension[J]. Journal of Computer Applications, 2026, 46(1): 60-68.
谢欣冉, 崔喆, 陈睿, 彭泰来, 林德坤. 基于层次过滤与标签语义扩展的大模型零样本重排序方法[J]. 《计算机应用》唯一官方网站, 2026, 46(1): 60-68.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2025010082

Fig. 1 Overall architecture of HFLS

Fig. 2 Example illustration of different forms of label definition
| 方法 | LLM calls | Batching | Inferences | Pro. tokens | Gen. tokens | Latency/s | NDCG@10/% |
|---|---|---|---|---|---|---|---|
| Pointwise.qg[ | √ | 100 | 15 115 | — | 1.70 | 54.11 | |
| Pointwise.yes_no[ | √ | 100 | 16 015 | — | 1.82 | 65.03 | |
| Pointwise.3Label[ | √ | 100 | 17 316 | — | 1.96 | 64.21 | |
| Pointwise.3Scale[ | √ | 100 | 16 416 | — | 1.87 | 58.51 | |
| Listwise.generation[ | — | 245 | 119 163 | 2 910 | 71.40 | 56.90 | |
| Pairwise.allpair[ | √ | 9 900 | 2 953 436 | 49 500 | 254.90 | 71.30 | |
| Pairwise.heapsort[ | — | 242 | 110 127 | 2 419 | 20.50 | 70.50 | |
| Pairwise.bubblesort[ | — | 887 | 400 367 | 8 870 | 75.10 | 68.30 | |
| Setwise.heapsort[ | — | 130 | 41 666 | 647 | 9.60 | 69.30 | |
| Setwise.bubblesort[ | — | 467 | 149 949 | 2 335 | 35.20 | 70.50 | |
| HFLS.full | √ | 300 | 73 447 | — | 8.70 | 70.03 | |
| HFLS.fusion | √ | 221 | 53 359 | — | 6.38 | 70.11 |
Tab. 1 Efficiency and effectiveness evaluation of different methods on TREC-DL2019 dataset
| 方法 | LLM calls | Batching | Inferences | Pro. tokens | Gen. tokens | Latency/s | NDCG@10/% |
|---|---|---|---|---|---|---|---|
| Pointwise.qg[ | √ | 100 | 15 115 | — | 1.70 | 54.11 | |
| Pointwise.yes_no[ | √ | 100 | 16 015 | — | 1.82 | 65.03 | |
| Pointwise.3Label[ | √ | 100 | 17 316 | — | 1.96 | 64.21 | |
| Pointwise.3Scale[ | √ | 100 | 16 416 | — | 1.87 | 58.51 | |
| Listwise.generation[ | — | 245 | 119 163 | 2 910 | 71.40 | 56.90 | |
| Pairwise.allpair[ | √ | 9 900 | 2 953 436 | 49 500 | 254.90 | 71.30 | |
| Pairwise.heapsort[ | — | 242 | 110 127 | 2 419 | 20.50 | 70.50 | |
| Pairwise.bubblesort[ | — | 887 | 400 367 | 8 870 | 75.10 | 68.30 | |
| Setwise.heapsort[ | — | 130 | 41 666 | 647 | 9.60 | 69.30 | |
| Setwise.bubblesort[ | — | 467 | 149 949 | 2 335 | 35.20 | 70.50 | |
| HFLS.full | √ | 300 | 73 447 | — | 8.70 | 70.03 | |
| HFLS.fusion | √ | 221 | 53 359 | — | 6.38 | 70.11 |
| 方法 | TREC-DL2019 | TREC-DL2020 | Covid | Touche | DBPedia | News | Signal | 均值 |
|---|---|---|---|---|---|---|---|---|
| BM25 | 50.58 | 47.96 | 59.47 | 44.22 | 31.80 | 39.52 | 33.05 | 43.80 |
| Pointwise.qg[ | 54.11 | 54.14 | 67.91 | 21.78 | 30.89 | 42.09 | 30.21 | 43.01 |
| Pointwise.yes_no[ | 65.03 | 63.55 | 69.65 | 26.92 | 27.34 | 41.36 | 29.75 | 46.23 |
| Pointwise.3Label[ | 64.21 | 62.05 | 71.73 | 27.06 | 38.53 | 44.98 | 29.44 | 48.29 |
| Pointwise.3Scale[ | 58.51 | 54.38 | 72.83 | 21.50 | 37.76 | 47.07 | 27.58 | 45.66 |
| HFLS.keywords | 69.96 | 63.80 | 76.52 | 28.38 | 43.15 | 46.99 | 31.88 | 51.53 |
| HFLS.topics | 69.63 | 64.56 | 77.09 | 30.11 | 42.97 | 46.75 | 31.96 | 51.87 |
| HFLS.domain | 68.97 | 64.82 | 78.03 | 30.11 | 43.91 | 45.98 | 31.41 | 51.89 |
| HFLS.full | 70.03 | 64.15 | 78.52 | 30.67 | 43.78 | 47.02 | 32.42 | 52.34 |
| HFLS.fusion | 70.11 | 63.96 | 78.71 | 30.79 | 43.61 | 47.20 | 32.53 | 52.44 |
Tab. 2 Comparison of NDCG@10 across seven datasets using different methods
| 方法 | TREC-DL2019 | TREC-DL2020 | Covid | Touche | DBPedia | News | Signal | 均值 |
|---|---|---|---|---|---|---|---|---|
| BM25 | 50.58 | 47.96 | 59.47 | 44.22 | 31.80 | 39.52 | 33.05 | 43.80 |
| Pointwise.qg[ | 54.11 | 54.14 | 67.91 | 21.78 | 30.89 | 42.09 | 30.21 | 43.01 |
| Pointwise.yes_no[ | 65.03 | 63.55 | 69.65 | 26.92 | 27.34 | 41.36 | 29.75 | 46.23 |
| Pointwise.3Label[ | 64.21 | 62.05 | 71.73 | 27.06 | 38.53 | 44.98 | 29.44 | 48.29 |
| Pointwise.3Scale[ | 58.51 | 54.38 | 72.83 | 21.50 | 37.76 | 47.07 | 27.58 | 45.66 |
| HFLS.keywords | 69.96 | 63.80 | 76.52 | 28.38 | 43.15 | 46.99 | 31.88 | 51.53 |
| HFLS.topics | 69.63 | 64.56 | 77.09 | 30.11 | 42.97 | 46.75 | 31.96 | 51.87 |
| HFLS.domain | 68.97 | 64.82 | 78.03 | 30.11 | 43.91 | 45.98 | 31.41 | 51.89 |
| HFLS.full | 70.03 | 64.15 | 78.52 | 30.67 | 43.78 | 47.02 | 32.42 | 52.34 |
| HFLS.fusion | 70.11 | 63.96 | 78.71 | 30.79 | 43.61 | 47.20 | 32.53 | 52.44 |

Fig. 3 Impact of category count on performance
| 大语言模型 | 方法 | NDCG@10 | NDCG@5 | NDCG@1 |
|---|---|---|---|---|
| — | BM25 | 59.47 | 63.24 | 68.00 |
| FLAN-T5-large (783M) | 3Label | 70.94 | 72.74 | 74.00 |
| HFLS | 75.19 | 79.05 | 78.00 | |
| FLAN-T5-xl (3B) | 3Label | 71.73 | 75.00 | 73.00 |
| HFLS | 78.71 | 80.31 | 82.00 | |
| Llama3.2-3B-Instruct | 3Label | 69.09 | 71.19 | 70.00 |
| HFLS | 75.35 | 78.34 | 76.00 | |
| Qwen2.5-3B-Instruct | 3Label | 75.04 | 76.59 | 81.00 |
| HFLS | 83.12 | 88.06 | 90.00 |
Tab. 3 Re-ranking results of Covid-19 dataset by different LLMs
| 大语言模型 | 方法 | NDCG@10 | NDCG@5 | NDCG@1 |
|---|---|---|---|---|
| — | BM25 | 59.47 | 63.24 | 68.00 |
| FLAN-T5-large (783M) | 3Label | 70.94 | 72.74 | 74.00 |
| HFLS | 75.19 | 79.05 | 78.00 | |
| FLAN-T5-xl (3B) | 3Label | 71.73 | 75.00 | 73.00 |
| HFLS | 78.71 | 80.31 | 82.00 | |
| Llama3.2-3B-Instruct | 3Label | 69.09 | 71.19 | 70.00 |
| HFLS | 75.35 | 78.34 | 76.00 | |
| Qwen2.5-3B-Instruct | 3Label | 75.04 | 76.59 | 81.00 |
| HFLS | 83.12 | 88.06 | 90.00 |
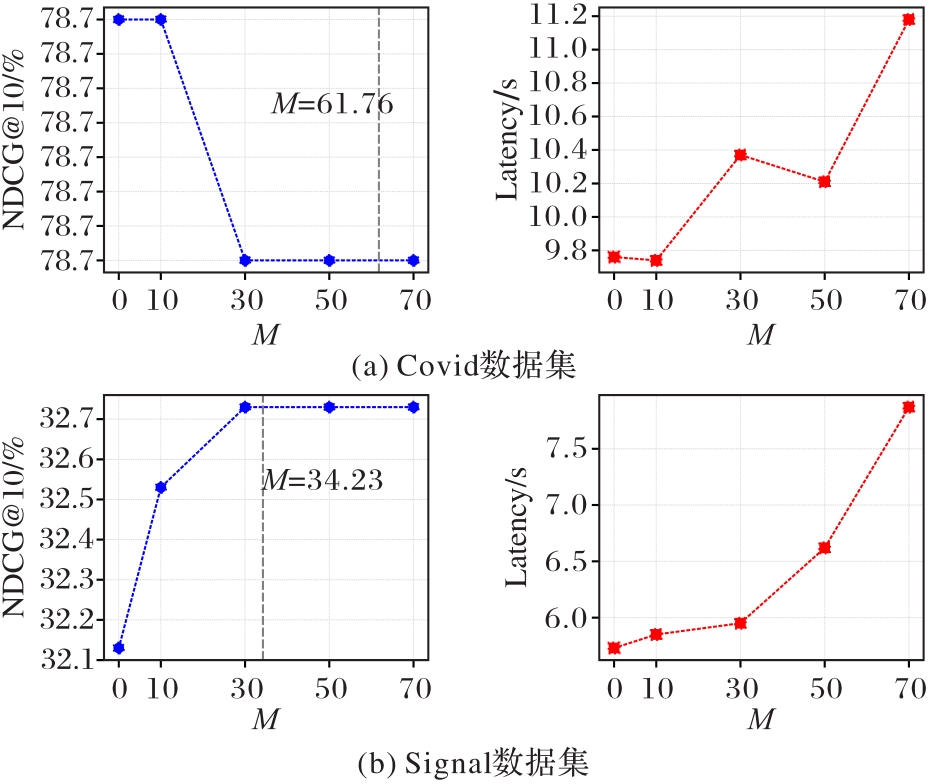
Fig. 4 Impact of different values of M on ranking effect and efficiency
| [1] | BROWN T B, MANN B, RYDER N, et al. Language models are few-shot learners [C]// Proceedings of the 34th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2020: 1877-1901. |
| [2] | ZHU Y, YUAN H, WANG S, et al. Large language models for information retrieval: a survey [EB/OL]. [2024-06-20]. . |
| [3] | 赵征宇,罗景,涂新辉.基于多粒度语义融合的信息检索方法[J].计算机应用, 2024, 44(6): 1775-1780. |
| ZHAO Z Y, LUO J, TU X H. Information retrieval method based on multi-granularity semantic fusion [J]. Journal of Computer Applications, 2024, 44(6): 1775-1780. | |
| [4] | LIN J, NOGUEIRA R, YATES A. Pretrained Transformers for text ranking: BERT and beyond [M]. San Rafael, CA: Morgan & Claypool Publishers, 2021. |
| [5] | LIANG P, BOMMASANI R, LEE T, et al. Holistic evaluation of language models [EB/OL]. [2024-06-20]. . |
| [6] | ZHUANG H, QIN Z, HUI K, et al. Beyond yes and no: improving zero-shot LLM rankers via scoring fine-grained relevance labels [C]// Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Short Papers). Stroudsburg: ACL, 2024: 358-370. |
| [7] | SACHAN D S, LEWIS M, JOSHI M, et al. Improving passage retrieval with zero-shot question generation [C]// Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2022: 3781-3797. |
| [8] | ZHUANG S, LIU B, KOOPMAN B, et al. Open-source large language models are strong zero-shot query likelihood models for document ranking [C]// Findings of the Association for Computational Linguistics: EMNLP 2023. Stroudsburg: ACL, 2023: 8807-8817. |
| [9] | QIN Z, JAGERMAN R, HUI K, et al. Large language models are effective text rankers with pairwise ranking prompting [C]// Findings of the Association for Computational Linguistics: NAACL 2024. Stroudsburg: ACL, 2024: 1504-1518. |
| [10] | LUO J, CHEN X, HE B, et al. PRP-Graph: pairwise ranking prompting to LLMs with graph aggregation for effective text re-ranking [C]// Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2024: 5766-5776. |
| [11] | ZHUANG S, ZHUANG H, KOOPMAN B, et al. A Setwise approach for effective and highly efficient zero-shot ranking with large language models [C]// Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2024: 38-47. |
| [12] | MA X, ZHANG X, PRADEEP R, et al. Zero-shot listwise document reranking with a large language model [EB/OL]. [2024-07-20]. . |
| [13] | SUN W, YAN L, MA X, et al. Is ChatGPT good at search? investigating large language models as re-ranking agents [C]// Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2023: 14918-14937. |
| [14] | NOGUEIRA R, YANG W, CHO K, et al. Multi-stage document ranking with BERT [EB/OL]. [2024-07-20]. . |
| [15] | DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional transformers for language understanding [C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long and Short Papers). Stroudsburg: ACL, 2019: 4171-4186. |
| [16] | NOGUEIRA R, JIANG Z, PRADEEP R, et al. Document ranking with a pretrained sequence-to-sequence model [C]// Findings of the Association for Computational Linguistics: EMNLP 2020. Stroudsburg: ACL, 2020: 708-718. |
| [17] | RAFFEL C, SHAZEER N, ROBERTS A, et al. Exploring the limits of transfer learning with a unified text-to-text transformer [J]. Journal of Machine Learning Research, 2020, 21: 1-67. |
| [18] | ZHUANG H, QIN Z, JAGERMAN R, et al. RankT5: fine-tuning T5 for text ranking with ranking losses [C]// Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2023: 2308-2313. |
| [19] | MA X, WANG L, YANG N, et al. Fine-tuning LLaMA for multi-stage text retrieval [C]// Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2024: 2421-2425. |
| [20] | SAHOO P, SINGH A K, SAHA S, et al. A systematic survey of prompt engineering in large language models: techniques and applications [EB/OL]. [2023-05-06]. . |
| [21] | ROBERTSON S, ZARAGOZA H. The probabilistic relevance framework: BM25 and beyond [J]. Foundations and Trends in Information Retrieval, 2009, 3(4): 333-389. |
| [22] | OpenAI. Hello GPT-4o [EB/OL]. [2024-06-20]. . |
| [23] | HUANG C W, CHEN Y N. InstUPR: instruction-based unsupervised passage reranking with large language models [EB/OL]. [2024-07-01]. . |
| [24] | CRASWELL N, MITRA B, YILMAZ E, et al. Overview of the TREC 2019 deep learning track [EB/OL]. [2024-06-02]. . |
| [25] | CRASWELL N, MITRA B, YILMAZ E, et al. Overview of the TREC 2020 deep learning track [EB/OL]. [2024-05-12]. . |
| [26] | THAKUR N, REIMERS N, RÜCKLÉ A, et al. BEIR: a heterogeneous benchmark for zero-shot evaluation of information retrieval models [EB/OL]. [2024-06-22]. . |
| [27] | LIN J, MA X, LIN S C, et al. Pyserini: a Python toolkit for reproducible information retrieval research with sparse and dense representations [C]// Proceedings of the 44th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2021: 2356-2362. |
| [28] | CHUANG H W, HOU L, LONGPRE S, et al. Scaling instruction-finetuned language models [J]. Journal of Machine Learning Research, 2024, 25: 1-53. |
| [29] | Team Llama. The Llama 3 herd of models [EB/OL]. [2024-11-23]. . |
| [30] | Team Qwen. Qwen2 technical report [EB/OL]. [2024-09-10]. . |
| [1] | Yi LIN, Bing XIA, Yong WANG, Shunda MENG, Juchong LIU, Shuqin ZHANG. AI-Agent based method for hidden RESTful API discovery and vulnerability detection [J]. Journal of Computer Applications, 2026, 46(1): 135-143. |
| [2] | Binbin ZHANG, Yongbin QIN, Ruizhang HUANG, Yanping CHEN. Judgment document summarization method combining large language model and dynamic prompts [J]. Journal of Computer Applications, 2025, 45(9): 2783-2789. |
| [3] | Tao FENG, Chen LIU. Dual-stage prompt tuning method for automated preference alignment [J]. Journal of Computer Applications, 2025, 45(8): 2442-2447. |
| [4] | Yuyang SUN, Minjie ZHANG, Jie HU. Zero-shot dialogue state tracking domain transfer model based on semantic prefix-tuning [J]. Journal of Computer Applications, 2025, 45(7): 2221-2228. |
| [5] | Yiheng SUN, Maofu LIU. Tender information extraction method based on prompt tuning of knowledge [J]. Journal of Computer Applications, 2025, 45(4): 1169-1176. |
| [6] | Jing HE, Yang SHEN, Runfeng XIE. Recognition and optimization of hallucination phenomena in large language models [J]. Journal of Computer Applications, 2025, 45(3): 709-714. |
| [7] | Xiaolin QIN, Xu GU, Dicheng LI, Haiwen XU. Survey and prospect of large language models [J]. Journal of Computer Applications, 2025, 45(3): 685-696. |
| [8] | Chengzhe YUAN, Guohua CHEN, Dingding LI, Yuan ZHU, Ronghua LIN, Hao ZHONG, Yong TANG. ScholatGPT: a large language model for academic social networks and its intelligent applications [J]. Journal of Computer Applications, 2025, 45(3): 755-764. |
| [9] | Yuemei XU, Yuqi YE, Xueyi HE. Bias challenges of large language models: identification, evaluation, and mitigation [J]. Journal of Computer Applications, 2025, 45(3): 697-708. |
| [10] | Yan YANG, Feng YE, Dong XU, Xuejie ZHANG, Jin XU. Construction of digital twin water conservancy knowledge graph integrating large language model and prompt learning [J]. Journal of Computer Applications, 2025, 45(3): 785-793. |
| [11] | Yanping ZHANG, Meifang CHEN, Changhai TIAN, Zibo YI, Wenpeng HU, Wei LUO, Zhunchen LUO. Multi-strategy retrieval-augmented generation method for military domain knowledge question answering systems [J]. Journal of Computer Applications, 2025, 45(3): 746-754. |
| [12] | Peng CAO, Guangqi WEN, Jinzhu YANG, Gang CHEN, Xinyi LIU, Xuechun JI. Efficient fine-tuning method of large language models for test case generation [J]. Journal of Computer Applications, 2025, 45(3): 725-731. |
| [13] | Xuefei ZHANG, Liping ZHANG, Sheng YAN, Min HOU, Yubo ZHAO. Personalized learning recommendation in collaboration of knowledge graph and large language model [J]. Journal of Computer Applications, 2025, 45(3): 773-784. |
| [14] | Chenwei SUN, Junli HOU, Xianggen LIU, Jiancheng LYU. Large language model prompt generation method for engineering drawing understanding [J]. Journal of Computer Applications, 2025, 45(3): 801-807. |
| [15] | Yanmin DONG, Jiajia LIN, Zheng ZHANG, Cheng CHENG, Jinze WU, Shijin WANG, Zhenya HUANG, Qi LIU, Enhong CHEN. Design and practice of intelligent tutoring algorithm based on personalized student capability perception [J]. Journal of Computer Applications, 2025, 45(3): 765-772. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||