


Journal of Computer Applications ›› 2026, Vol. 46 ›› Issue (5): 1408-1415.DOI: 10.11772/j.issn.1001-9081.2025050595
• Artificial intelligence • Previous Articles
Changzheng XING, Xin ZHENG( ), Di JIA, Junfeng LIANG
), Di JIA, Junfeng LIANG
Received:2025-06-03
Revised:2025-08-29
Accepted:2025-09-09
Online:2025-09-15
Published:2026-05-10
Contact:
Xin ZHENG
About author:XING Changzheng, born in 1967, Ph. D.,professor. His research interests include artificial intelligence, information processing.Supported by:
邢长征, 郑鑫(), 贾迪, 梁浚锋
通讯作者:
郑鑫
作者简介:邢长征(1967—),男,辽宁阜新人,教授,博士,CCF会员,主要研究方向:人工智能、信息处理基金资助:CLC Number:
Changzheng XING, Xin ZHENG, Di JIA, Junfeng LIANG. Improved DeepLabV3+ method based on adaptive attention and nested receptive field[J]. Journal of Computer Applications, 2026, 46(5): 1408-1415.
邢长征, 郑鑫, 贾迪, 梁浚锋. 基于自适应注意力与嵌套感受野改进DeepLabV3+方法[J]. 《计算机应用》唯一官方网站, 2026, 46(5): 1408-1415.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2025050595
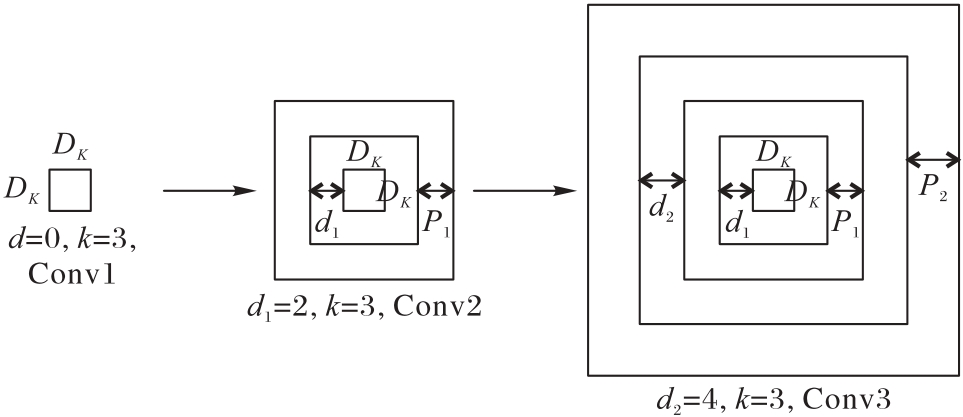
Fig. 1 Structure of filled nested receptive field based on convolution kernel
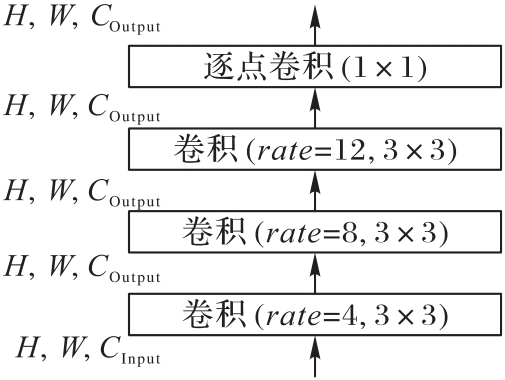
Fig. 2 ENRF module structure

Fig. 3 ACCA module structure based on class guidance and channel weighting
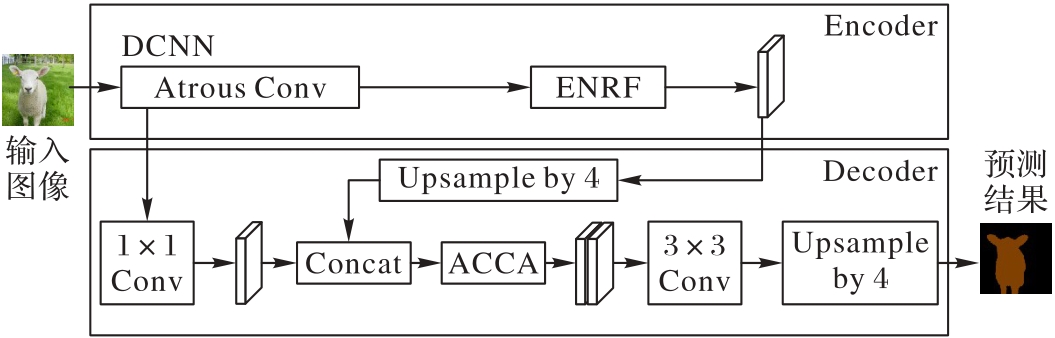
Fig. 4 Improved DeepLabV3+ structure with ENRF and ACCA
| 算法 | 骨干 | VOC 2012 | Cityscapes | ||||
|---|---|---|---|---|---|---|---|
| GFLOPs | Params/106 | mIoU | GFLOPs | Params/106 | mIoU | ||
| FCN8s | VGG16 | 1 843.42 | 134.36 | 0.428 8 | 1 953.42 | 134.36 | 0.431 0 |
| PSPNet | ResNet101 | 2 102.23 | 65.00 | 0.573 0 | 2 299.80 | 65.00 | 0.579 4 |
| UPerNet | Resnet50 | 1 464.55 | 126.58 | 0.546 0 | 1 583.99 | 126.58 | 0.551 1 |
| BiSeNet V2 | — | 58.68 | 49.00 | 0.586 7 | 55.36 | 49.00 | 0.592 5 |
| DFANet | — | 3.67 | 7.80 | 0.571 9 | 3.48 | 7.80 | 0.580 1 |
| DeepLabV3+ | MobileNetV2 | 15.89 | 6.00 | 0.596 6 | 5.66 | 6.00 | 0.602 8 |
| DeepLabV3+ENRF+ACCA | MobileNetV2 | 13.08 | 5.22 | 0.611 2 | 4.04 | 5.22 | 0.628 3 |
Tab. 1 Comparison of semantic segmentation performance of different algorithms on VOC 2012 and Cityscapes datasets
| 算法 | 骨干 | VOC 2012 | Cityscapes | ||||
|---|---|---|---|---|---|---|---|
| GFLOPs | Params/106 | mIoU | GFLOPs | Params/106 | mIoU | ||
| FCN8s | VGG16 | 1 843.42 | 134.36 | 0.428 8 | 1 953.42 | 134.36 | 0.431 0 |
| PSPNet | ResNet101 | 2 102.23 | 65.00 | 0.573 0 | 2 299.80 | 65.00 | 0.579 4 |
| UPerNet | Resnet50 | 1 464.55 | 126.58 | 0.546 0 | 1 583.99 | 126.58 | 0.551 1 |
| BiSeNet V2 | — | 58.68 | 49.00 | 0.586 7 | 55.36 | 49.00 | 0.592 5 |
| DFANet | — | 3.67 | 7.80 | 0.571 9 | 3.48 | 7.80 | 0.580 1 |
| DeepLabV3+ | MobileNetV2 | 15.89 | 6.00 | 0.596 6 | 5.66 | 6.00 | 0.602 8 |
| DeepLabV3+ENRF+ACCA | MobileNetV2 | 13.08 | 5.22 | 0.611 2 | 4.04 | 5.22 | 0.628 3 |
| 算法 | 骨干 | GTX 1050 | GTX 1660 Ti | ||
|---|---|---|---|---|---|
| 推理时间/ms | 内存占用/MB | 推理时间/ms | 内存占用/MB | ||
| FCN8s | VGG16 | 1.834 0 | 2 678.086 0 | 0.946 4 | 3 488.108 6 |
| PSPNet | ResNet101 | 10.045 0 | 4 557.440 3 | 1.002 0 | 4 557.440 8 |
| UPerNet | Resnet50 | 1.956 6 | 2 131.594 8 | 0.658 6 | 3 235.591 5 |
| DeepLabV3+ | MobileNetV2 | 0.394 4 | 811.024 5 | 0.091 4 | 1 953.716 8 |
| DeepLabV3+ENRF+ACCA | MobileNetV2 | 0.287 0 | 809.990 3 | 0.088 0 | 1 950.961 3 |
Tab. 2 Performance comparison of lightweight models on VOC 2012 Dataset
| 算法 | 骨干 | GTX 1050 | GTX 1660 Ti | ||
|---|---|---|---|---|---|
| 推理时间/ms | 内存占用/MB | 推理时间/ms | 内存占用/MB | ||
| FCN8s | VGG16 | 1.834 0 | 2 678.086 0 | 0.946 4 | 3 488.108 6 |
| PSPNet | ResNet101 | 10.045 0 | 4 557.440 3 | 1.002 0 | 4 557.440 8 |
| UPerNet | Resnet50 | 1.956 6 | 2 131.594 8 | 0.658 6 | 3 235.591 5 |
| DeepLabV3+ | MobileNetV2 | 0.394 4 | 811.024 5 | 0.091 4 | 1 953.716 8 |
| DeepLabV3+ENRF+ACCA | MobileNetV2 | 0.287 0 | 809.990 3 | 0.088 0 | 1 950.961 3 |

Fig. 5 Visual comparison of segmentation results of different model on VOC 2012 dataset
| 算法 | 骨干 | VOC 2012 | Cityscapes | ||||
|---|---|---|---|---|---|---|---|
| GFLOPs | Params/106 | mIoU | GFLOPs | Params/106 | mIoU | ||
| DeepLabV3+ ACCA | MobileNetV2 | 16.78 | 6.38 | 0.602 3 | 5.98 | 6.38 | 0.617 2 |
| DeepLabV3+ ENRF | MobileNetV2 | 12.64 | 5.84 | 0.582 2 | 3.64 | 5.84 | 0.596 3 |
| DeepLabV3+ | Xception | 40.56 | 37.05 | 0.631 7 | 10.70 | 37.05 | 0.623 2 |
| DeepLabV3+ENRF+ACCA | Xception | 34.89 | 28.48 | 0.649 8 | 9.40 | 28.48 | 0.631 1 |
| DeepLabV3+ | ResNet101 | 66.74 | 58.75 | 0.692 0 | 15.34 | 58.75 | 0.673 1 |
| DeepLabV3+ENRF+ACCA | ResNet101 | 58.85 | 49.19 | 0.708 4 | 14.28 | 49.19 | 0.695 1 |
Tab. 3 Semantic segmentation performance comparison of ablation experiments on VOC 2012 dataset
| 算法 | 骨干 | VOC 2012 | Cityscapes | ||||
|---|---|---|---|---|---|---|---|
| GFLOPs | Params/106 | mIoU | GFLOPs | Params/106 | mIoU | ||
| DeepLabV3+ ACCA | MobileNetV2 | 16.78 | 6.38 | 0.602 3 | 5.98 | 6.38 | 0.617 2 |
| DeepLabV3+ ENRF | MobileNetV2 | 12.64 | 5.84 | 0.582 2 | 3.64 | 5.84 | 0.596 3 |
| DeepLabV3+ | Xception | 40.56 | 37.05 | 0.631 7 | 10.70 | 37.05 | 0.623 2 |
| DeepLabV3+ENRF+ACCA | Xception | 34.89 | 28.48 | 0.649 8 | 9.40 | 28.48 | 0.631 1 |
| DeepLabV3+ | ResNet101 | 66.74 | 58.75 | 0.692 0 | 15.34 | 58.75 | 0.673 1 |
| DeepLabV3+ENRF+ACCA | ResNet101 | 58.85 | 49.19 | 0.708 4 | 14.28 | 49.19 | 0.695 1 |
| 算法 | 骨干 | GTX 1050 | GTX 1660 Ti | ||
|---|---|---|---|---|---|
| 推理时间/ms | 内存占用/MB | 推理时间/ms | 内存占用/MB | ||
| DeepLabV3+ ACCA | MobileNetV2 | 0.425 8 | 812.208 6 | 0.098 9 | 1 954.867 2 |
| DeepLabV3+ | Xception | 0.765 4 | 1 234.495 3 | 0.236 8 | 2 160.974 8 |
| DeepLabV3+ | ResNet101 | 1.050 1 | 1 197.440 1 | 0.385 0 | 2 423.231 0 |
| DeepLabV3+ENRF+ACCA | Xception | 0.656 2 | 1 213.571 2 | 0.215 8 | 2 123.925 6 |
| DeepLabV3+ENRF+ACCA | ResNet101 | 0.960 9 | 1 182.038 1 | 0.343 6 | 2 386.553 9 |
Tab. 4 Performance comparison of ablation experiments for lightweight models on VOC 2012 dataset
| 算法 | 骨干 | GTX 1050 | GTX 1660 Ti | ||
|---|---|---|---|---|---|
| 推理时间/ms | 内存占用/MB | 推理时间/ms | 内存占用/MB | ||
| DeepLabV3+ ACCA | MobileNetV2 | 0.425 8 | 812.208 6 | 0.098 9 | 1 954.867 2 |
| DeepLabV3+ | Xception | 0.765 4 | 1 234.495 3 | 0.236 8 | 2 160.974 8 |
| DeepLabV3+ | ResNet101 | 1.050 1 | 1 197.440 1 | 0.385 0 | 2 423.231 0 |
| DeepLabV3+ENRF+ACCA | Xception | 0.656 2 | 1 213.571 2 | 0.215 8 | 2 123.925 6 |
| DeepLabV3+ENRF+ACCA | ResNet101 | 0.960 9 | 1 182.038 1 | 0.343 6 | 2 386.553 9 |
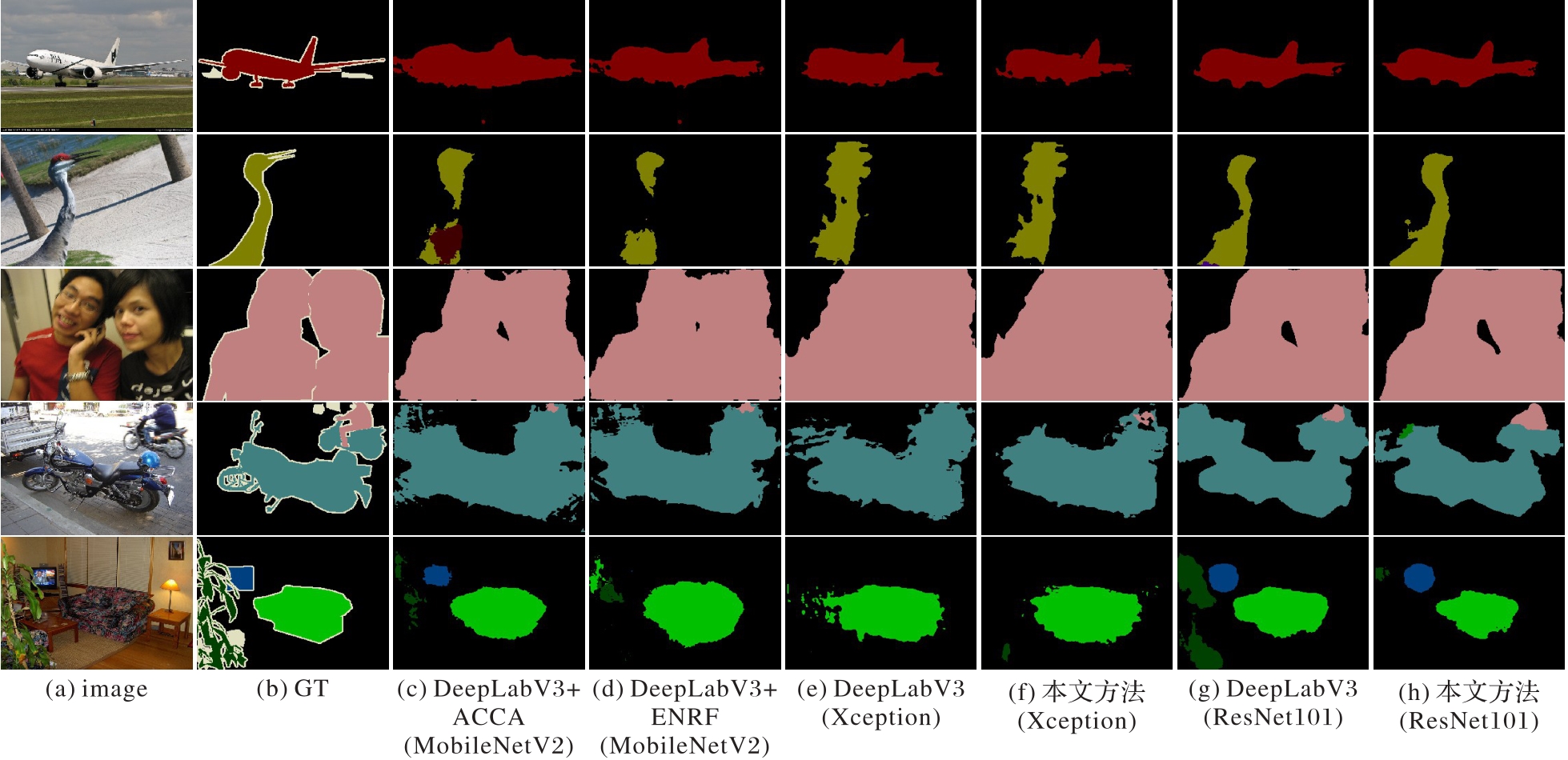
Fig. 6 Visual comparison of segmentation results for ablation experiments on VOC 2012 dataset
| [1] | 王碧瑶,韩毅,崔航滨,等.基于图像的道路语义分割检测方法[J].山东大学学报(工学版),2023,53(5):37-47. |
| WANG B Y, HAN Y, CUI H B, et al. Road semantic segmentation detection method based on image[J]. Journal of Shandong University (Engineering Science), 2023, 53(5): 37-47. | |
| [2] | 刘云翔,管钎汛,石艳娇.基于语义分割的复杂驾驶场景障碍物检测[J].计算机仿真,2023,40(12):167-171. |
| LIU Y X, GUAN Q X, SHI Y J. Obstacle detection in complex driving scenarios based on semantic segmentation[J]. Computer Simulation, 2023, 40(12): 167-171. | |
| [3] | 宋建丽,吕晓琪,谷宇.语义流引导采样结合注意力机制的脑肿瘤图像分割[J].光学精密工程,2024,32(4):565-577. |
| SONG J L, LYU X Q, GU Y. Brain tumor image segmentation based on semantic flow guided sampling and attention mechanism[J]. Optics and Precision Engineering, 2024, 32(4): 565-577. | |
| [4] | 汪华登,王雪馨,黎兵兵,等.GZMH:用于有丝分裂细胞核检测和分割的乳腺癌病理图像数据集[J].中国图象图形学报,2024,29(3):608-619. |
| WANG H D, WANG X X, LI B B, et al. GZMH: a dataset of breast cancer pathological images for mitosis nuclei detection and segmentation[J]. Journal of Image and Graphics, 2024, 29(3): 608-619. | |
| [5] | 王雅丽.基于改进Swin-Unet腹部多器官图像分割方法研究[J].现代计算机,2023,29(3):81-84. |
| WANG Y L. Research on abdominal multi organ image segmentation based on improved Swin-Unet[J]. Modern Computer, 2023, 29(3): 81-84. | |
| [6] | 彭明,丁汉泽,刘艳芳,等.解耦融合机制的金属表面缺陷小样本分割网络[J].闽南师范大学学报(自然科学版),2024,37(3): 57-70. |
| PENG M, DING H Z, LIU Y F, et al. Decoupling fusion mechanism-based network for metal surface defect few-shot segmentation[J]. Journal of Minnan Normal University (Natural Science), 2024, 37(3): 57-70. | |
| [7] | LONG J, SHELHAMER E, DARRELL T. Fully convolutional networks for semantic segmentation[C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2015: 3431-3440. |
| [8] | YEGNANARAYANA B. Artificial neural networks[M]. Delhi: PHI Learning Pvt. Ltd., 2004: 1-2. |
| [9] | RONNEBERGER O, FISCHER P, BROX T. U-Net: convolutional networks for biomedical image segmentation[C]// Proceedings of the 2015 Medical Image Computing and Computer-Assisted Intervention, LNCS 9351. Cham: Springer, 2015: 234-241. |
| [10] | ZHAO H, SHI J, QI X, et al. Pyramid scene parsing network[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 6230-6239. |
| [11] | CHEN L C, PAPANDREOU G, KOKKINOS I, et al. DeepLab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(4): 834-848. |
| [12] | KRÄHENBÜHL P, KOLTUN V. Efficient inference in fully connected CRFs with Gaussian edge potentials[C]// Proceedings of the 25th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2011: 109-117. |
| [13] | CHEN L C, ZHU Y, PAPANDREOU G, et al. Encoder-decoder with atrous separable convolution for semantic image segmentation[C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11211. Cham: Springer, 2018: 833-851. |
| [14] | LIU R, TAO F, LIU X, et al. RAANet: a residual ASPP with attention framework for semantic segmentation of high-resolution remote sensing images[J]. Remote Sensing, 2022, 14(13): No.3109. |
| [15] | SUN X, ZHANG Y, CHEN C, et al. High-order paired-ASPP for deep semantic segmentation networks[J]. Information Sciences, 2023, 646: No.119364. |
| [16] | XI Y, LI S, XU Z, et al. LapUNet: a novel approach to monocular depth estimation using dynamic Laplacian residual U‑shape networks[J]. Scientific Reports, 2024, 14: No.23544. |
| [17] | DING P, QIAN H, ZHOU Y, et al. Real-time efficient semantic segmentation network based on improved ASPP and parallel fusion module in complex scenes[J]. Journal of Real-Time Image Processing, 2023, 20(3): No.41. |
| [18] | LI Y, YUAN G, WEN Y, et al. EfficientFormer: Vision Transformers at MobileNet speed[C]// Proceedings of the 36th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2022: 12934-12949. |
| [19] | LIDA T, KOMATSU T, KANEDA K, et al. Visual explanation generation based on lambda attention branch networks[C]// Proceedings of the 2022 Asian Conference on Computer Vision, LNCS 13842. Cham: Springer, 2023: 475-490. |
| [20] | SHAKER A, MAAZ M, RASHEED H, et al. SwiftFormer: efficient additive attention for Transformer-based real-time mobile vision applications[C]// Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2023: 17379-17390. |
| [21] | FENG X, DU H, FAN H, et al. SEFormer: structure embedding Transformer for 3D object detection[C]// Proceedings of the 37th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2023: 632-640. |
| [22] | HENDRYCKS D, GIMPEL K. Gaussian Error Linear Units (GELUs)[EB/OL]. [2025-04-11].. |
| [23] | EVERINGHAM M, ESLAMI S M A, VAN GOOL L, et al. The PASCAL visual object classes challenge: a retrospective[J]. International Journal of Computer Vision, 2015, 111(1): 98-136. |
| [24] | CORDTS M, OMRAN M, RAMOS S, et al. The Cityscapes dataset for semantic urban scene understanding[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 3213-3223. |
| [25] | XIAO T, LIU Y, ZHOU B, et al. Unified perceptual parsing for scene understanding[C]// Proceedings of the 2018 European Conference on Computer Vision. Berlin: Springer, 2018: 418-434. |
| [26] | YU C, GAO C, WANG J, et al. BiSeNet V2: bilateral network with guided aggregation for real-time semantic segmentation[J]. International Journal of Computer Vision, 2021, 129: 3051-3068. |
| [27] | LI H, XIONG P, FAN H, et al. Dfanet: Deep feature aggregation for real-time semantic segmentation[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 9522-9531. |
| [28] | CHOLLET F. Xception: deep learning with depthwise separable convolutions[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 1800-1807. |
| [29] | HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]// Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 770-778. |
| [1] | Ping HUANG, Qing LI, Haifeng QIU, Chengsi WANG, Anzi HUANG, Xiang ZHANG. Real-time face blurring method based on head skeleton point detection [J]. Journal of Computer Applications, 2026, 46(2): 596-603. |
| [2] | Ning CAO, Xin WEN, Yanrong HAO, Rui CAO. Lightweight motor imagery electroencephalogram decoding neural network with multi-domain feature fusion [J]. Journal of Computer Applications, 2026, 46(1): 289-296. |
| [3] | Yun ZHANG, Shuying WANG, Qing ZHENG, Haizhu ZHANG. Lightweight algorithm of 3D mesh model for preserving detailed geometric features [J]. Journal of Computer Applications, 2023, 43(4): 1226-1232. |
| [4] | Xuedong HE, Shibin XUAN, Kuan WANG, Mengnan CHEN. DeepLabV3+ image segmentation algorithm fusing cumulative distribution function and channel attention mechanism [J]. Journal of Computer Applications, 2023, 43(3): 936-942. |
| [5] | Xiaofei JI, Kexin ZHANG, Lirong TANG. Book spine segmentation algorithm based on improved DeepLabv3+ network [J]. Journal of Computer Applications, 2023, 43(12): 3927-3932. |
| [6] | LIN Leping, LI Sanfeng, OUYANG Ning. Multi-pose feature fusion generative adversarial network based face reconstruction method [J]. Journal of Computer Applications, 2020, 40(10): 2856-2862. |
| [7] | DaiZhong LUO WenYun ZHAO. Approach of feature dependency modeling for software product line [J]. Journal of Computer Applications, 2008, 28(9): 2349-2352. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||