


Journal of Computer Applications ›› 2023, Vol. 43 ›› Issue (3): 936-942.DOI: 10.11772/j.issn.1001-9081.2022020210
Special Issue: 多媒体计算与计算机仿真
• Multimedia computing and computer simulation • Previous Articles Next Articles
Xuedong HE1, Shibin XUAN1,2( ), Kuan WANG1, Mengnan CHEN1
), Kuan WANG1, Mengnan CHEN1
Received:2022-02-24
Revised:2022-05-25
Accepted:2022-05-25
Online:2022-08-16
Published:2023-03-10
Contact:
Shibin XUAN
About author:HE Xuedong, born in 1997, M. S. candidate. His research interests include semantic segmentation, computer vision.Supported by:
何雪东1, 宣士斌1,2(), 王款1, 陈梦楠1
通讯作者:
宣士斌
作者简介:何雪东(1997—),男,吉林松原人,硕士研究生,CCF会员,主要研究方向:语义分割、计算机视觉基金资助:CLC Number:
Xuedong HE, Shibin XUAN, Kuan WANG, Mengnan CHEN. DeepLabV3+ image segmentation algorithm fusing cumulative distribution function and channel attention mechanism[J]. Journal of Computer Applications, 2023, 43(3): 936-942.
何雪东, 宣士斌, 王款, 陈梦楠. 融合累积分布函数和通道注意力机制的DeepLabV3+图像分割算法[J]. 《计算机应用》唯一官方网站, 2023, 43(3): 936-942.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2022020210
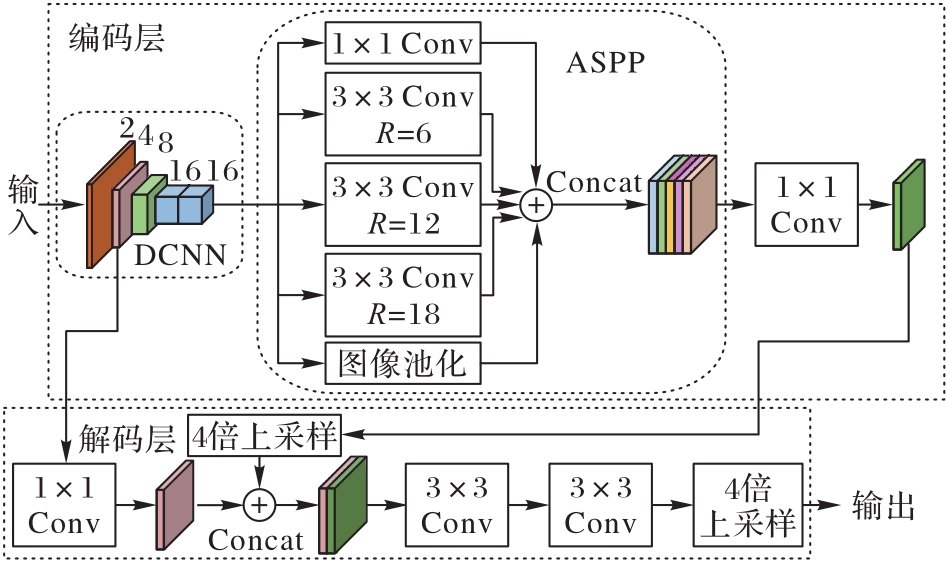
Fig.1 DeepLabV3+ network structure
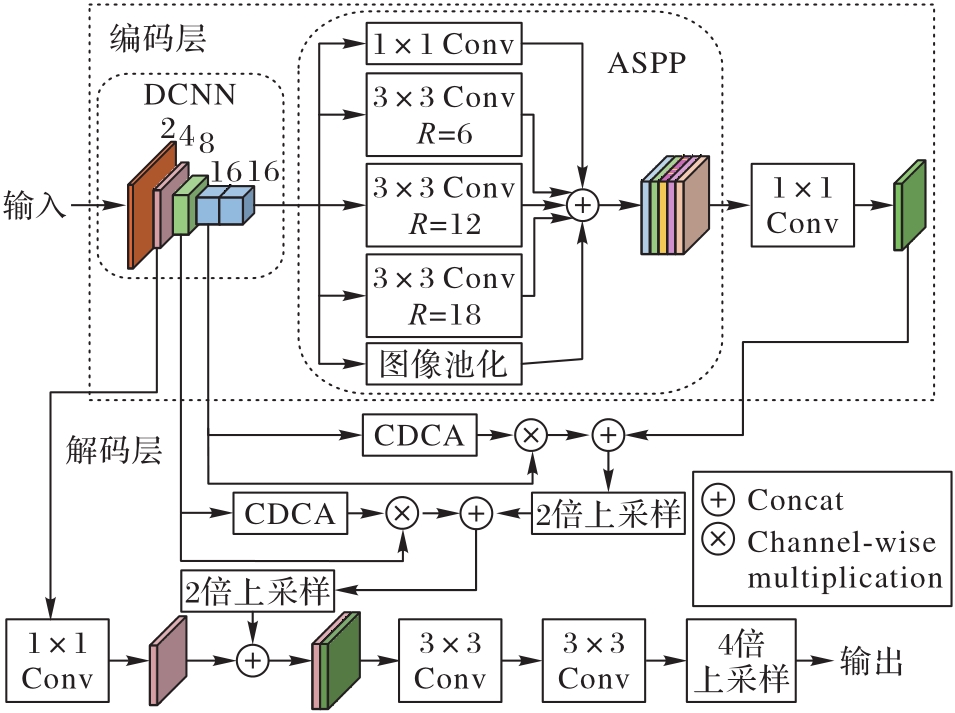
Fig.2 CDCA-DLV3+ network structure
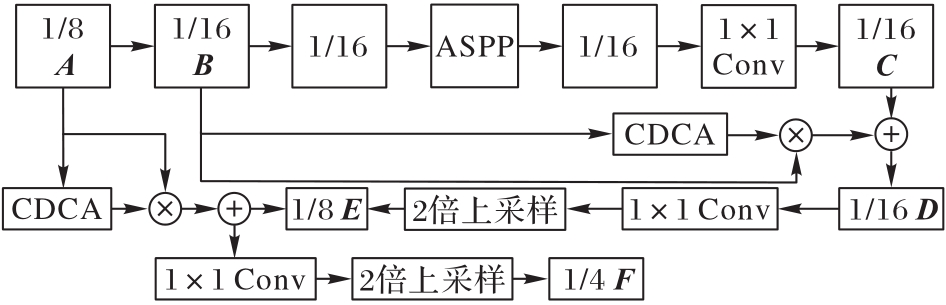
Fig.3 CDCA-DLV3+ network structure details

Fig.4 Structure of CDCA module

Fig.5 Feature pyramid network structure
| 软硬件配置 | 配置详情 |
|---|---|
| CPU | Intel Xeon Silver 4114 |
| 内存 | 256 GB |
| 显卡 | RTX 8000 |
| 操作系统 | Ubuntu 20.04 |
| CUDA | Cuda 11.4 |
| Python | Python 3.6 |
| Pytorch | Pytorch 1.8.1 |
Tab. 1 Machine software and hardware configuration
| 软硬件配置 | 配置详情 |
|---|---|
| CPU | Intel Xeon Silver 4114 |
| 内存 | 256 GB |
| 显卡 | RTX 8000 |
| 操作系统 | Ubuntu 20.04 |
| CUDA | Cuda 11.4 |
| Python | Python 3.6 |
| Pytorch | Pytorch 1.8.1 |
| 1/8 | 1/16 | ASPP空洞率 | mIoU/% | 浮点运算量/GFLOPs | 参数量/106 |
|---|---|---|---|---|---|
| — | — | (6,12,18) | 78.85 | 92.82 | 59.23 |
| | — | 79.30 | 93.66 | 59.43 | |
| — | | 79.02 | 108.44 | 60.94 | |
| | | 79.56 | 121.71 | 62.18 | |
| — | — | (4,8,12,16) | 79.14 | 98.03 | 64.02 |
| | — | 80.09 | 98.87 | 64.22 | |
| — | | 79.29 | 113.65 | 65.72 | |
| | | 79.80 | 126.92 | 66.96 |
Tab. 2 Influence of CDCA module and ASPP atrous rate on network
| 1/8 | 1/16 | ASPP空洞率 | mIoU/% | 浮点运算量/GFLOPs | 参数量/106 |
|---|---|---|---|---|---|
| — | — | (6,12,18) | 78.85 | 92.82 | 59.23 |
| | — | 79.30 | 93.66 | 59.43 | |
| — | | 79.02 | 108.44 | 60.94 | |
| | | 79.56 | 121.71 | 62.18 | |
| — | — | (4,8,12,16) | 79.14 | 98.03 | 64.02 |
| | — | 80.09 | 98.87 | 64.22 | |
| — | | 79.29 | 113.65 | 65.72 | |
| | | 79.80 | 126.92 | 66.96 |
| 模型 | mIoU/% | 浮点运算量/GFLOPs | 参数量/106 | 训练时间/h |
|---|---|---|---|---|
| DeepLabV2 | 76.35 | 75.40 | 61.41 | — |
| DeepLabV3 | 77.21 | 71.16 | 58.04 | — |
| DeepLabV3+ | 78.85 | 92.93 | 59.23 | 9.8 |
| 改进DeepLabV3+ | 79.97 | 99.53 | 64.65 | — |
| 模型1 | 79.30 | 93.66 | 59.43 | 10.0 |
| 模型2 | 80.09 | 98.87 | 64.22 | 11.2 |
Tab. 3 Comparison results of different models
| 模型 | mIoU/% | 浮点运算量/GFLOPs | 参数量/106 | 训练时间/h |
|---|---|---|---|---|
| DeepLabV2 | 76.35 | 75.40 | 61.41 | — |
| DeepLabV3 | 77.21 | 71.16 | 58.04 | — |
| DeepLabV3+ | 78.85 | 92.93 | 59.23 | 9.8 |
| 改进DeepLabV3+ | 79.97 | 99.53 | 64.65 | — |
| 模型1 | 79.30 | 93.66 | 59.43 | 10.0 |
| 模型2 | 80.09 | 98.87 | 64.22 | 11.2 |

Fig.6 Prediction graph comparison between Model 2 and DeepLabV3+ network on PASCAL dataset
| 模型 | mIoU |
|---|---|
| DeepLab V3+ | 79.09 |
| 模型1 | 79.68 |
| 模型2 | 80.11 |
Tab. 4 mIoU comparison on Cityscapes dataset
| 模型 | mIoU |
|---|---|
| DeepLab V3+ | 79.09 |
| 模型1 | 79.68 |
| 模型2 | 80.11 |
| 1 | YAN H T, ZHANG C, WU M. Lawin Transformer: improving semantic segmentation transformer with multi-scale representations via large window attention[EB/OL]. (2022-01-05) [2022-02-11].. 10.48550/arXiv.2201.01615 |
| 2 | 田萱,王亮,丁琪. 基于深度学习的图像语义分割方法综述[J]. 软件学报, 2019, 30(2):440-468. 10.13328/j.cnki.jos.005659 |
| TIAN X, WANG L, DING Q. Review of image semantic segmentation based on deep learning[J]. Journal of Software, 2019, 30(2): 440-468. 10.13328/j.cnki.jos.005659 | |
| 3 | 王龙飞,严春满. 道路场景语义分割综述[J]. 激光与光电子学进展, 2021, 58(12): No.1200002. 10.3788/lop202158.1200002 |
| WANG L F, YAN C M. Review on semantic segmentation of road scenes[J]. Laser and Optoelectronics Progress, 2021, 58(12): No.1200002. 10.3788/lop202158.1200002 | |
| 4 | PANELLA F, LIPANI A, BOEHM J. Semantic segmentation of cracks: data challenges and architecture[J]. Automation in Construction, 2022, 135: No.104110. 10.1016/j.autcon.2021.104110 |
| 5 | MINAEE S, BOYKOV Y, PORIKLI F, et al. Image segmentation using deep learning: a survey[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44(7): 3523-3542. |
| 6 | LONG J, SHELHAMER E, DARRELL T. Fully convolutional networks for semantic segmentation[C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2015: 3431-3440. 10.1109/cvpr.2015.7298965 |
| 7 | GUO M H, LIU Z N, MU T J, et al. Beyond self-attention: external attention using two linear layers for visual tasks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022(Early Access): 1-13. 10.1109/tpami.2022.3211006 |
| 8 | GUO M H, XU T X, LIU J J, et al. Attention mechanisms in computer vision: a survey[J]. Computational Visual Media, 2022, 8(3): 331-368. 10.1007/s41095-022-0271-y |
| 9 | FAN M Y, LAI S Q, HUANG J S, et al. Rethinking BiSeNet for real-time semantic segmentation[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 9711-9720. 10.1109/cvpr46437.2021.00959 |
| 10 | HU J, SHEN L, SUN G. Squeeze-and-excitation networks[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 7132-7141. 10.1109/cvpr.2018.00745 |
| 11 | CHEN L C, PAPANDREOU G, KOKKINOS I, et al. Semantic image segmentation with deep convolutional nets and fully connected CRFs[EB/OL]. (2016-06-07) [2022-02-10].. 10.1109/tpami.2017.2699184 |
| 12 | CHEN L C, PAPANDREOU G, KOKKINOS I, et al. DeepLab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(4): 834-848. 10.1109/tpami.2017.2699184 |
| 13 | CHEN L C, PAPANDREOU G, SCHROFF F, et al. Rethinking atrous convolution for semantic image segmentation[EB/OL]. (2017-12-05) [2022-02-11].. 10.1007/978-3-030-01234-2_49 |
| 14 | CHEN L C, ZHU Y K, PAPANDREOU G, et al. Encoder-decoder with atrous separable convolution for semantic image segmentation[C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11211. Cham: Springer, 2018: 833-851. 10.1007/978-3-030-01234-2_49 |
| 15 | WANG Q L, WU B G, ZHU P F, et al. ECA-Net: efficient channel attention for deep convolutional neural networks[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 11531-11539. 10.1109/cvpr42600.2020.01155 |
| 16 | WOO S, PARK J, LEE J Y, et al. CBAM: convolutional block attention module[C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11211. Cham: Springer, 2018: 3-19. |
| 17 | 杨贞,彭小宝,朱强强,等. 基于Deeplab V3 plus的自适应注意力机制图像分割算法[J]. 计算机应用, 2022, 42(1):230-238. |
| YANG Z, PENG X B, ZHU Q Q, et al. Image segmentation algorithm with adaptive attention mechanism based on Deeplab V3 Plus[J]. Journal of Computer Applications, 2022, 42(1): 230-238. | |
| 18 | YU F, KOLTUN V, FUNKHOUSER T. Dilated residual networks[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 636-644. 10.1109/cvpr.2017.75 |
| 19 | 张蕊,李锦涛. 基于深度学习的场景分割算法研究综述[J]. 计算机研究与发展, 2020, 57(4):859-875. 10.7544/issn1000-1239.2020.20190513 |
| ZHANG R, LI J T. A survey on algorithm research of scene parsing based on deep learning[J]. Journal of Computer Research and Development, 2020, 57(4): 859-875. 10.7544/issn1000-1239.2020.20190513 | |
| 20 | HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 770-778. 10.1109/cvpr.2016.90 |
| 21 | HOWARD A G, ZHU M L, CHEN B, et al. MobileNets: efficient convolutional neural networks for mobile vision applications[EB/OL]. (2017-04-17) [2022-02-13].. 10.48550/arXiv.1704.04861 |
| 22 | SANDLER M, HOWARD A, ZHU M L, et al. MobileNetV2: inverted residuals and linear bottlenecks[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 4510-4520. 10.1109/cvpr.2018.00474 |
| 23 | HOWARD A, SANDLER M, CHEN B, et al. Searching for MobileNetV3[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 1314-1324. 10.1109/iccv.2019.00140 |
| 24 | CHOLLET F. Xception: deep learning with depthwise separable convolutions[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 1800-1807. 10.1109/cvpr.2017.195 |
| 25 | SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[EB/OL]. (2015-04-10) [2021-12-20].. |
| 26 | 程晓悦,赵龙章,胡穹,等. 基于膨胀卷积平滑及轻型上采样的实时语义分割[J]. 激光与光电子学进展, 2020, 57(2): No.021017. 10.3788/lop57.021017 |
| CHENG X Y, ZHAO L Z, HU Q, et al. Real-time semantic segmentation based on dilated convolution smoothing and lightweight up-sampling[J]. Laser and Optoelectronics Progress, 2020, 57(2): No.021017. 10.3788/lop57.021017 | |
| 27 | HE K M, ZHANG X Y, REN S Q, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(9): 1904-1916. 10.1109/tpami.2015.2389824 |
| 28 | 徐聪,王丽. 基于改进DeepLabv3+网络的图像语义分割方法[J]. 激光与光电子学进展, 2021, 58(16): No.1610008. 10.3788/lop202158.1610008 |
| XU C, WANG L. Image semantic segmentation method based on improved DeepLabv3+ network[J]. Laser and Optoelectronics Progress, 2021, 58(16): No.1610008. 10.3788/lop202158.1610008 | |
| 29 | LIN T Y, DOLLÁR P, GIRSHICK R, et al. Feature pyramid networks for object detection[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 936-944. 10.1109/cvpr.2017.106 |
| 30 | EVERINGHAM M, ESLAMI S M A, VAN GOOL L, et al. The PASCAL visual object classes challenge: a retrospective[J]. International Journal of Computer Vision, 2015, 111(1): 98-136. 10.1007/s11263-014-0733-5 |
| 31 | CORDTS M, OMRAN M, RAMOS S, et al. The Cityscapes dataset for semantic urban scene understanding[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 3213-3223. 10.1109/cvpr.2016.350 |
| 32 | OpenMMLab. MMSegmentation[CP/OL]. [2021-10-10].. |
| 33 | XIE E Z, WANG W H, YU Z D, et al. SegFormer: simple and efficient design for semantic segmentation with Transformers[EB/OL]. (2021-10-28) [2022-02-12].. |
| [1] | Yexin PAN, Zhe YANG. Optimization model for small object detection based on multi-level feature bidirectional fusion [J]. Journal of Computer Applications, 2024, 44(9): 2871-2877. |
| [2] | Yunchuan HUANG, Yongquan JIANG, Juntao HUANG, Yan YANG. Molecular toxicity prediction based on meta graph isomorphism network [J]. Journal of Computer Applications, 2024, 44(9): 2964-2969. |
| [3] | Jing QIN, Zhiguang QIN, Fali LI, Yueheng PENG. Diagnosis of major depressive disorder based on probabilistic sparse self-attention neural network [J]. Journal of Computer Applications, 2024, 44(9): 2970-2974. |
| [4] | Xiyuan WANG, Zhancheng ZHANG, Shaokang XU, Baocheng ZHANG, Xiaoqing LUO, Fuyuan HU. Unsupervised cross-domain transfer network for 3D/2D registration in surgical navigation [J]. Journal of Computer Applications, 2024, 44(9): 2911-2918. |
| [5] | Shunyong LI, Shiyi LI, Rui XU, Xingwang ZHAO. Incomplete multi-view clustering algorithm based on self-attention fusion [J]. Journal of Computer Applications, 2024, 44(9): 2696-2703. |
| [6] | Yuhan LIU, Genlin JI, Hongping ZHANG. Video pedestrian anomaly detection method based on skeleton graph and mixed attention [J]. Journal of Computer Applications, 2024, 44(8): 2551-2557. |
| [7] | Yanjie GU, Yingjun ZHANG, Xiaoqian LIU, Wei ZHOU, Wei SUN. Traffic flow forecasting via spatial-temporal multi-graph fusion [J]. Journal of Computer Applications, 2024, 44(8): 2618-2625. |
| [8] | Qianhong SHI, Yan YANG, Yongquan JIANG, Xiaocao OUYANG, Wubo FAN, Qiang CHEN, Tao JIANG, Yuan LI. Multi-granularity abrupt change fitting network for air quality prediction [J]. Journal of Computer Applications, 2024, 44(8): 2643-2650. |
| [9] | Zheng WU, Zhiyou CHENG, Zhentian WANG, Chuanjian WANG, Sheng WANG, Hui XU. Deep learning-based classification of head movement amplitude during patient anaesthesia resuscitation [J]. Journal of Computer Applications, 2024, 44(7): 2258-2263. |
| [10] | Huanhuan LI, Tianqiang HUANG, Xuemei DING, Haifeng LUO, Liqing HUANG. Public traffic demand prediction based on multi-scale spatial-temporal graph convolutional network [J]. Journal of Computer Applications, 2024, 44(7): 2065-2072. |
| [11] | Zhi ZHANG, Xin LI, Naifu YE, Kaixi HU. DKP: defending against model stealing attacks based on dark knowledge protection [J]. Journal of Computer Applications, 2024, 44(7): 2080-2086. |
| [12] | Yiqun ZHAO, Zhiyu ZHANG, Xue DONG. Anisotropic travel time computation method based on dense residual connection physical information neural networks [J]. Journal of Computer Applications, 2024, 44(7): 2310-2318. |
| [13] | Song XU, Wenbo ZHANG, Yifan WANG. Lightweight video salient object detection network based on spatiotemporal information [J]. Journal of Computer Applications, 2024, 44(7): 2192-2199. |
| [14] | Xun SUN, Ruifeng FENG, Yanru CHEN. Monocular 3D object detection method integrating depth and instance segmentation [J]. Journal of Computer Applications, 2024, 44(7): 2208-2215. |
| [15] | Yajuan ZHAO, Fanjun MENG, Xingjian XU. Review of online education learner knowledge tracing [J]. Journal of Computer Applications, 2024, 44(6): 1683-1698. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||