《计算机应用》唯一官方网站 ›› 2021, Vol. 41 ›› Issue (11): 3145-3150.DOI: 10.11772/j.issn.1001-9081.2020122039
所属专题: 人工智能
李灿1,2,3, 杨雅婷1,2,3, 马玉鹏1,2,3( ), 董瑞1,2,3
), 董瑞1,2,3
Can LI1,2,3, Yating YANG1,2,3, Yupeng MA1,2,3(), Rui DONG1,2,3
摘要:
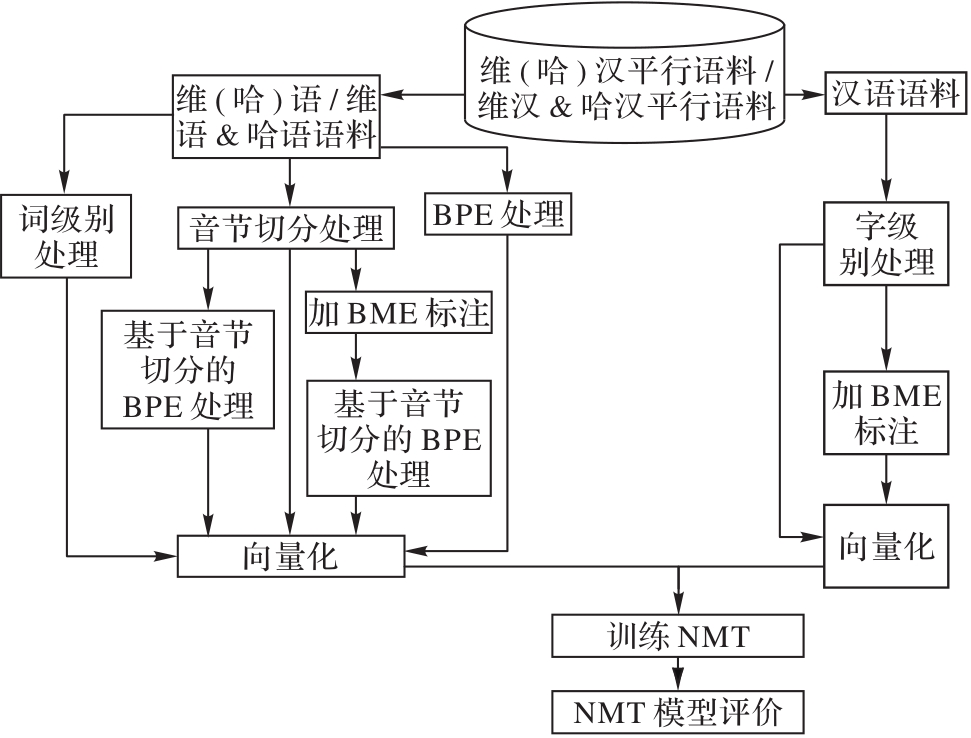
针对低资源语言机器翻译任务上一直存在的标注数据资源匮乏问题,提出了基于语种相似性挖掘的神经机器翻译语料库扩充方法。首先,将维吾尔语和哈萨克语作为相似语言对并将其语料进行混合;然后,对混合后的语料分别进行字节对编码(BPE)处理、音节切分处理以及基于音节切分的BPE处理,从而深度挖掘哈语和维语的相似性;最后,引入“开始-中部-结束(BME)”序列标注方法对语料中已切分完成的音节进行标注,以消除音节输入所带来的一些歧义。在CWMT2015维汉平行语料和哈汉平行语料上的实验结果表明,所提方法相较于不进行特殊语料处理以及BPE语料处理训练所得普通模型在维吾尔语-汉语翻译上的双语评估替补(BLEU)值分别提升了9.66、4.55,在哈萨克语-汉语翻译上的BLEU值分别提升了9.44、4.36。所提方案实现了维语和哈语到汉语的跨语言神经机器翻译,提升了维吾尔语-汉语和哈萨克语-汉语机器翻译的翻译质量,可应用于维语和哈语的语料处理。
中图分类号: