


《计算机应用》唯一官方网站 ›› 2023, Vol. 43 ›› Issue (9): 2707-2714.DOI: 10.11772/j.issn.1001-9081.2022091407
• 2022第10届CCF大数据学术会议 • 上一篇 下一篇
收稿日期:2022-09-06
修回日期:2022-10-27
接受日期:2022-11-07
发布日期:2023-09-10
出版日期:2023-09-10
通讯作者:
黄瑞章
作者简介:田悦霖(1997—),女,河北深州人,硕士研究生,CCF会员,主要研究方向:自然语言处理、文本挖掘、机器学习基金资助:
Yuelin TIAN1,2, Ruizhang HUANG1,2( ), Lina REN1,2
), Lina REN1,2
Received:2022-09-06
Revised:2022-10-27
Accepted:2022-11-07
Online:2023-09-10
Published:2023-09-10
Contact:
Ruizhang HUANG
About author:TIAN Yuelin, born in 1997, M. S. candidate. Her research interests include natural language processing, text mining, machine learning.Supported by:摘要:
从学者主页中提取的学者细粒度信息(如学者研究方向、教育经历等)在大规模专业人才库的创建等方面具有非常重要的应用价值。针对现有学者细粒度信息提取方法无法有效利用上下文语义联系的问题,提出一种融合局部语义特征的学者信息提取方法,利用局部范围文本的语义联系对学者主页进行细粒度信息抽取。首先,通过全词掩码中文预训练模型RoBERTa-wwm-ext学习通用语义表征;之后将通用语义表征中的目标句表征向量与局部相邻文本表征向量共同输入卷积神经网络(CNN)实现局部语义融合,从而获得更高维度的目标句表征向量;最终将目标句表征向量从高维度空间映射到低维度标签空间实现学者主页细粒度信息的抽取。实验结果表明,使用此融合局部语义特征的方法进行学者细粒度信息提取的宏平均F1值达到93.43%,与未融合局部语义的RoBERTa-wwm-ext-TextCNN方法相比提高了8.60个百分点,验证了所提方法在学者细粒度信息提取任务上的有效性。
中图分类号:
田悦霖, 黄瑞章, 任丽娜. 融合局部语义特征的学者细粒度信息提取方法[J]. 计算机应用, 2023, 43(9): 2707-2714.
Yuelin TIAN, Ruizhang HUANG, Lina REN. Scholar fine-grained information extraction method fused with local semantic features[J]. Journal of Computer Applications, 2023, 43(9): 2707-2714.

图1 模型体系结构
Fig. 1 Model architecture
| 掩码方式 | 示例 |
|---|---|
| 初始句 | 使用语言模型来预测下一个词的概率 |
| 典型mask方式 | 使用语言模型来预[M]下一个词的[M]率 |
| WWM方式 | 使用语言模型来[M][M]下一个词的[M][M] |
表1 掩码方式示例
Tab. 1 Examples of masking modes
| 掩码方式 | 示例 |
|---|---|
| 初始句 | 使用语言模型来预测下一个词的概率 |
| 典型mask方式 | 使用语言模型来预[M]下一个词的[M]率 |
| WWM方式 | 使用语言模型来[M][M]下一个词的[M][M] |
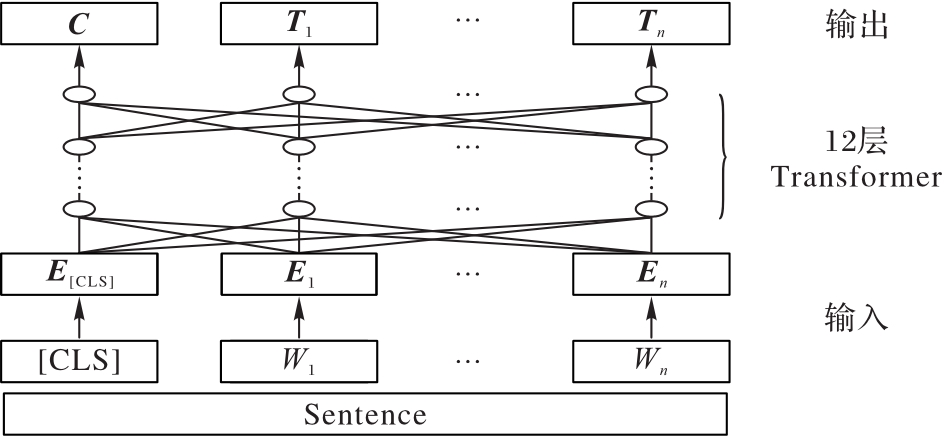
图2 RoBERTa-wwm-ext模型结构
Fig. 2 Structure of RoBERTa-wwm-ext model
| 标签 | 说明 | 举例 |
|---|---|---|
| base_info | 基本信息 | 姓名:xxx 职称:特任教授,博士生导师 |
| edu | 教育经历 | 2006 学士 北京邮电大学电信工程学院,北京,中国 通信工程 |
| work | 工作履历 | 讲师 天津大学 计算机科学与技术学院 2011.7~2014.6 |
| research | 研究方向 | 计算机视觉;计算机图形学 |
| achievement | 所获成就 | 已在主流的国际期刊和会议上发表SCI/EI论文120多篇,包括IEEE/ACMTrans.论文18篇,CCF A类论文22篇, B类论文17篇。 |
| publications | 学术论著 | Jing Zhang, Zhanpeng Fang, Wei Chen, and Jie Tang. Diffusion of "Following" Links in Microblogging Networks. IEEE Transaction on Knowledge and Data Engineering (TKDE), 2015, Volume 27, Issue 8, Pages 2093-2106. |
| projects | 科研项目 | 天津市应用基础与前沿技术研究计划(自然科学基金)青年项目 |
| awards | 获得奖项 | 第三届由田机器视觉奖创新类第二名 |
| teaching | 教授课程 | 数字信号处理,本科生;计算摄像学,研究生 |
| social_service | 社会任职 | IEEE Trans. SMCB, IEEE Trans. Multimedia, Pattern RecognitionLetters, The Visual Computer等相关国际期刊的审稿人 |
| other | 其他内容 | 版权所有:西安交通大学 |
表2 学者主页的细粒度信息详解
Tab. 2 Detailed explanation of fine-grained information on scholar homepage
| 标签 | 说明 | 举例 |
|---|---|---|
| base_info | 基本信息 | 姓名:xxx 职称:特任教授,博士生导师 |
| edu | 教育经历 | 2006 学士 北京邮电大学电信工程学院,北京,中国 通信工程 |
| work | 工作履历 | 讲师 天津大学 计算机科学与技术学院 2011.7~2014.6 |
| research | 研究方向 | 计算机视觉;计算机图形学 |
| achievement | 所获成就 | 已在主流的国际期刊和会议上发表SCI/EI论文120多篇,包括IEEE/ACMTrans.论文18篇,CCF A类论文22篇, B类论文17篇。 |
| publications | 学术论著 | Jing Zhang, Zhanpeng Fang, Wei Chen, and Jie Tang. Diffusion of "Following" Links in Microblogging Networks. IEEE Transaction on Knowledge and Data Engineering (TKDE), 2015, Volume 27, Issue 8, Pages 2093-2106. |
| projects | 科研项目 | 天津市应用基础与前沿技术研究计划(自然科学基金)青年项目 |
| awards | 获得奖项 | 第三届由田机器视觉奖创新类第二名 |
| teaching | 教授课程 | 数字信号处理,本科生;计算摄像学,研究生 |
| social_service | 社会任职 | IEEE Trans. SMCB, IEEE Trans. Multimedia, Pattern RecognitionLetters, The Visual Computer等相关国际期刊的审稿人 |
| other | 其他内容 | 版权所有:西安交通大学 |
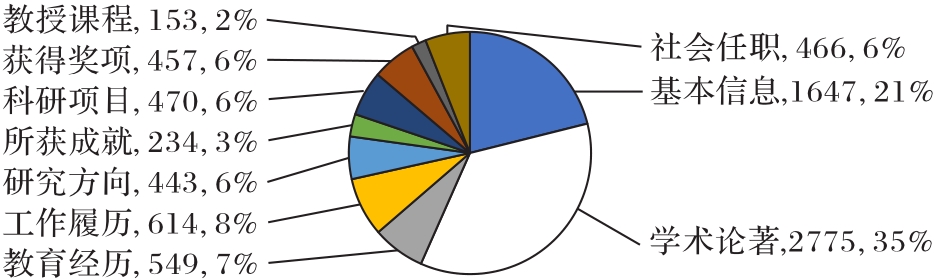
图3 学者主页的细粒度信息样本分布
Fig. 3 Samples distribution of scholar homepage fine-grained information
| 超参数 | 参数值 | 超参数 | 参数值 |
|---|---|---|---|
| TextLength | 100 | Hidden layer nodes of CNN | 256 |
| LearningRate | 1E-5 | BatchSize | 1 |
| Dropout | 0.15 | Epochs | 7~18 |
| CNN-KernelSize | 7 |
表3 超参数设置
Tab. 3 Hyperparameter setting
| 超参数 | 参数值 | 超参数 | 参数值 |
|---|---|---|---|
| TextLength | 100 | Hidden layer nodes of CNN | 256 |
| LearningRate | 1E-5 | BatchSize | 1 |
| Dropout | 0.15 | Epochs | 7~18 |
| CNN-KernelSize | 7 |
| 模型 | |||
|---|---|---|---|
| BERT | 83.87 | 82.46 | 82.89 |
| ELECTRA | 85.26 | 85.59 | 85.33 |
| RoBERTa | 87.35 | 84.82 | 85.93 |
| RoBERTa-TextCNN | 86.50 | 83.47 | 84.83 |
| Ours+ELECTRA-CNN | 93.16 | 92.83 | 92.96 |
| Ours+RoBERTa-CNN | 93.07 | 93.84 | 93.43 |
表4 学者信息提取结果对比 (%)
Tab. 4 Comparison of scholar information extraction results
| 模型 | |||
|---|---|---|---|
| BERT | 83.87 | 82.46 | 82.89 |
| ELECTRA | 85.26 | 85.59 | 85.33 |
| RoBERTa | 87.35 | 84.82 | 85.93 |
| RoBERTa-TextCNN | 86.50 | 83.47 | 84.83 |
| Ours+ELECTRA-CNN | 93.16 | 92.83 | 92.96 |
| Ours+RoBERTa-CNN | 93.07 | 93.84 | 93.43 |
| 样本类别 | P/% | R/% | F1/% | support |
|---|---|---|---|---|
| 宏平均 | 93.07 | 93.84 | 93.43 | 44 193 |
| base_info | 95.06 | 95.12 | 95.09 | 3 454 |
| edu | 96.30 | 97.15 | 96.72 | 1 038 |
| work | 92.89 | 95.23 | 94.02 | 1 318 |
| research | 88.97 | 91.94 | 90.41 | 900 |
| achievement | 83.14 | 83.43 | 83.24 | 529 |
| publications | 98.39 | 98.18 | 98.28 | 6 019 |
| projects | 95.60 | 94.50 | 95.01 | 1 327 |
| awards | 93.88 | 95.18 | 94.01 | 890 |
| teaching | 88.34 | 89.70 | 88.89 | 316 |
| social_service | 93.59 | 93.42 | 93.48 | 750 |
| other | 98.68 | 98.42 | 98.55 | 27 652 |
表5 学者主页细粒度信息提取结果 (%)
Tab. 5 Fine-grained information extraction results of scholar homepage
| 样本类别 | P/% | R/% | F1/% | support |
|---|---|---|---|---|
| 宏平均 | 93.07 | 93.84 | 93.43 | 44 193 |
| base_info | 95.06 | 95.12 | 95.09 | 3 454 |
| edu | 96.30 | 97.15 | 96.72 | 1 038 |
| work | 92.89 | 95.23 | 94.02 | 1 318 |
| research | 88.97 | 91.94 | 90.41 | 900 |
| achievement | 83.14 | 83.43 | 83.24 | 529 |
| publications | 98.39 | 98.18 | 98.28 | 6 019 |
| projects | 95.60 | 94.50 | 95.01 | 1 327 |
| awards | 93.88 | 95.18 | 94.01 | 890 |
| teaching | 88.34 | 89.70 | 88.89 | 316 |
| social_service | 93.59 | 93.42 | 93.48 | 750 |
| other | 98.68 | 98.42 | 98.55 | 27 652 |
| kernel_size | kernel_size | ||
|---|---|---|---|
| 1 | 84.23 | 11 | 92.99 |
| 3 | 91.01 | 13 | 93.03 |
| 5 | 92.40 | 15 | 92.54 |
| 7 | 92.71 | 17 | 92.48 |
| 9 | 92.34 | 19 | 92.67 |
表6 感受野大小与模型效果间的关系
Tab. 6 Relationship between receptive field size and model effect
| kernel_size | kernel_size | ||
|---|---|---|---|
| 1 | 84.23 | 11 | 92.99 |
| 3 | 91.01 | 13 | 93.03 |
| 5 | 92.40 | 15 | 92.54 |
| 7 | 92.71 | 17 | 92.48 |
| 9 | 92.34 | 19 | 92.67 |
| 模型 | |||
|---|---|---|---|
| No-pooling | 93.68 | 91.79 | 92.71 |
| +maxpooling | 93.22 | 92.01 | 92.58 |
| +avgpooling | 93.49 | 91.44 | 92.39 |
表7 池化层效果对比 (%)
Tab. 7 Effect comparison of pooling layer
| 模型 | |||
|---|---|---|---|
| No-pooling | 93.68 | 91.79 | 92.71 |
| +maxpooling | 93.22 | 92.01 | 92.58 |
| +avgpooling | 93.49 | 91.44 | 92.39 |
| 模型 | 数据集 | |||
|---|---|---|---|---|
RoBERTa- TextCNN | waimai_10k | 90.32 | 89.70 | 90.00 |
| NLPCC2014 | 48.56 | 61.06 | 53.03 | |
| toutiaonews38w | 82.85 | 82.81 | 82.83 | |
Ours+ RoBERTa-CNN | waimai_10k | 90.40 | 89.82 | 90.09 |
| NLPCC2014 | 52.13 | 59.48 | 55.17 | |
| toutiaonews38w | 82.84 | 82.82 | 82.83 |
表8 不同数据集上不同模型的通用性实验结果对比 (%)
Tab. 8 Experimental results of universality of different models on different datasets
| 模型 | 数据集 | |||
|---|---|---|---|---|
RoBERTa- TextCNN | waimai_10k | 90.32 | 89.70 | 90.00 |
| NLPCC2014 | 48.56 | 61.06 | 53.03 | |
| toutiaonews38w | 82.85 | 82.81 | 82.83 | |
Ours+ RoBERTa-CNN | waimai_10k | 90.40 | 89.82 | 90.09 |
| NLPCC2014 | 52.13 | 59.48 | 55.17 | |
| toutiaonews38w | 82.84 | 82.82 | 82.83 |
| 1 | Miniwatts Marketing Group. World Internet usage and population statistics 2022 year-Q1 estimates [EB/OL]. [2022-06-20]. ,%209.9%20%25%20%205% 20more%20rows%20. |
| 2 | CHANG C H, KAYED M, GIRGIS M R, et al. A survey of Web information extraction systems[J]. IEEE Transactions on Knowledge and Data Engineering, 2006, 18(10): 1411-1428. 10.1109/tkde.2006.152 |
| 3 | KARLSSON C, HAMMARFELT B. David Audretsch — a bibliometric portrait of a distinguished entrepreneurship scholar[M]// LEHMANN E K, KEILBACH M. From Industrial Organization to Entrepreneurship: A Tribute to David B. Audretsch. Cham: Springer, 2019: 169-192. 10.1007/978-3-030-25237-3_18 |
| 4 | CHEN Z X, DING J P, ZHOU Z G, et al. Application of association rule mining in talent introduction analysis[J]. Science Journal of Applied Mathematics and Statistics, 2019, 7(3): 45-50. 10.11648/j.sjams.20190703.13 |
| 5 | 孙玉涛,张艺蕾. 海外人才引进计划提升了我国大学科研产出吗?——以“211”工程大学化学学科为例[J]. 科研管理, 2021, 42(10):20-27. |
| SUN Y T, ZHANG Y L. Does Overseas Talent-Attracting Program increase the research output of Chinese universities? — a study by taking the chemistry discipline of the universities of the "211 Project"[J]. Science Research Management, 2021, 42(10): 20-27. | |
| 6 | CUI Y M, CHE W X, LIU T, et al. Pre-training with whole word masking for Chinese BERT[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2021, 29: 3504-3514. 10.1109/taslp.2021.3124365 |
| 7 | SAID W, HASSAN M M, FAWZY A M. Smart search methods in expert database systems[J]. International Journals SSRG, 2018, 66(1): 24-29. 10.14445/22315381/ijett-v66p205 |
| 8 | SUN F, SONG D D, LIAO L J. DOM based content extraction via text density[C]// Proceedings of the 34th International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2011: 245-254. 10.1145/2009916.2009952 |
| 9 | SONG D D, SUN F, LIAO L J. A hybrid approach for content extraction with text density and visual importance of DOM nodes[J]. Knowledge and Information Systems, 2015, 42(1): 75-96. 10.1007/s10115-013-0687-x |
| 10 | FANG Y X, XIE X Q, ZHANG X F, et al. STEM: a suffix tree-based method for Web data records extraction[J]. Knowledge and Information Systems, 2018, 55(2): 305-331. 10.1007/s10115-017-1062-0 |
| 11 | YU X, JIN Z P. Web content information extraction based on DOM tree and statistical information[C]// Proceedings of the IEEE 17th International Conference on Communication Technology. Piscataway: IEEE, 2017: 1308-1311. 10.1109/icct.2017.8359846 |
| 12 | WANG R J, ZHANG Y S, HOU Z Y, et al. Webpage text extraction algorithm based on text block density and tag path features[C]// Proceedings of the SPIE 12330, 2022 International Conference on Cyber Security, Artificial Intelligence, and Digital Economy. Bellingham, WA: SPIE, 2022: No.123301G. 10.1117/12.2646343 |
| 13 | BARDUCCI A, IANNACCONE S, LA GATTA V, et al. An end-to-end framework for information extraction from Italian resumes[J]. Expert Systems with Applications, 2022, 210: No.118487. 10.1016/j.eswa.2022.118487 |
| 14 | YU B W, DU J P, SHAO Y X. Web page content extraction based on multi-feature fusion[EB/OL]. [2022-06-16]. . |
| 15 | CAI D, YU S P, WEN J R, et al. VIPS: a vision-based page segmentation algorithm: MSR-TR-2003-79[R/OL]. (2003-11-01) [2022-07-23].. |
| 16 | ZELENY J, BURGET R, ZENDULKA J. Box clustering segmentation: a new method for vision-based web page preprocessing[J]. Information Processing and Management, 2017, 53(3): 735-750. 10.1016/j.ipm.2017.02.002 |
| 17 | PU J C, LIU J, WANG J. A vision-based approach for Deep Web form extraction[C]// Proceedings of the 2017 International Conference on Future Information Technology/ 2017 International Conference on Multimedia and Ubiquitous Engineering, LNEE 448. Singapore: Springer, 2017: 696-702. 10.1007/978-981-10-5041-1_111 |
| 18 | 陈晓雷. 自适应Web数据抽取技术研究[D]. 沈阳:辽宁大学, 2016:1-7. |
| CHEN X L. Research on technique of self-adaptive Web data extraction[D]. Shenyang: Liaoning University, 2016:1-7. | |
| 19 | PATNAIK S K, BABU C N, BHAVE M. Intelligent and adaptive Web data extraction system using convolutional and long short-term memory deep learning networks[J]. Big Data Mining and Analytics, 2021, 4(4): 279-297. 10.26599/bdma.2021.9020012 |
| 20 | 梅雪,程学旗,郭岩,等. 一种全自动生成网页信息抽取Wrapper的方法[J]. 中文信息学报, 2008, 22(1):22-29. 10.3969/j.issn.1003-0077.2008.01.004 |
| MEI X, CHENG X Q, GUO Y, et al. Fully automatic wrapper generation for Web information extraction[J]. Journal of Chinese Information Processing, 2008, 22(1):22-29. 10.3969/j.issn.1003-0077.2008.01.004 | |
| 21 | 顾韵华,高原,高宝,等. 基于模板和领域本体的Deep Web信息抽取研究[J]. 计算机工程与设计, 2014, 35(1):327-332. 10.3969/j.issn.1000-7024.2014.01.061 |
| GU Y H, GAO Y, GAO B, et al. Research on Deep Web information extraction based on template and domain ontology[J]. Computer Engineering and Design, 2014, 35(1): 327-332. 10.3969/j.issn.1000-7024.2014.01.061 | |
| 22 | 郭少华,郭岩,李海燕,等. 可扩展的网页关键信息抽取研究[J]. 中文信息学报, 2015, 29(1):97-103. 10.3969/j.issn.1003-0077.2015.01.013 |
| GUO S H, GUO Y, LI H Y, et al. Research on extensible web key information extraction[J]. Journal of Chinese Information Processing, 2015, 29(1): 97-103. 10.3969/j.issn.1003-0077.2015.01.013 | |
| 23 | LI J, LU Y M, ZHANG X. Extracting news information based on webpage segmentation and parsing DOM tree reversely[C]// Proceedings of the 2014 International Conference on Trustworthy Computing and Services, CCIS 520. Berlin: Springer, 2015: 48-55. 10.1007/978-3-662-47401-3_7 |
| 24 | 张秋颖,傅洛伊,王新兵. 基于BERT-BiLSTM-CRF的学者主页信息抽取[J]. 计算机应用研究, 2020, 37(S1):47-49. |
| ZHANG Q Y, FU L Y, WANG X B. Scholar homepage information extraction based on BERT-BiLSTM-CRF[J]. Application Research of Computers, 2020, 37(S1):47-49. | |
| 25 | ZHOU Y C, SHENG Y, VO N, et al. Simplified DOM trees for transferable attribute extraction from the web[EB/OL]. (2021-01-07) [2022-06-17].. 10.1145/3488560.3498424 |
| 26 | WANG Q F, FANG Y, RAVULA A, et al. WebFormer: the Web-page transformer for structure information extraction[C]// Proceedings of the ACM Web Conference 2022. New York: ACM, 2022: 3124-3133. 10.1145/3485447.3512032 |
| 27 | PUTRA EKA PRISMANA G L. Automatic Web news content extraction[J]. Journal Research of Social, Science, Economics, and Management, 2022, 1(7): 785-794. 10.36418/jrssem.v1i7.107 |
| 28 | ALARTE J, SILVA J. HybEx: a hybrid tool for template extraction[C]// Companion Proceedings of the Web Conference 2022. New York: ACM, 2022: 205-209. 10.1145/3487553.3524242 |
| 29 | DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional transformers for language understanding[C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Stroudsburg, PA: ACL, 2019: 4171-4186. 10.18653/v1/n18-2 |
| 30 | CUI Y M, CHE W X, LIU T, et al. Revisiting pre-trained models for Chinese natural language processing[C]// Findings of the Association for Computational Linguistics: EMNLP 2020. Stroudsburg, PA: ACL, 2020: 657-668. 10.18653/v1/2020.findings-emnlp.58 |
| 31 | ZHANG Y, WALLACE B. A sensitivity analysis of (and practitioners' guide to) convolutional neural networks for sentence classification[C]// Proceedings of the 8th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). [S.l.]: Asian Federation of Natural Language Processing, 2017: 253-263. 10.18653/v1/d16-1076 |
| 32 | XU Z. RoBERTa-wwm-ext fine-tuning for Chinese text classification[EB/OL]. (2021-02-24) [2022-05-13].. |
| [1] | 张心月, 刘蓉, 魏驰宇, 方可. 融合提示知识的方面级情感分析方法[J]. 《计算机应用》唯一官方网站, 2023, 43(9): 2753-2759. |
| [2] | 于碧辉, 蔡兴业, 魏靖烜. 基于提示学习的小样本文本分类方法[J]. 《计算机应用》唯一官方网站, 2023, 43(9): 2735-2740. |
| [3] | 张小艳, 段正宇. 基于句级别GAN的跨语言零资源命名实体识别模型[J]. 《计算机应用》唯一官方网站, 2023, 43(8): 2406-2411. |
| [4] | 王彬, 向甜, 吕艺东, 王晓帆. 基于NSGA‑Ⅱ的自适应多尺度特征通道分组优化算法[J]. 《计算机应用》唯一官方网站, 2023, 43(5): 1401-1408. |
| [5] | 石利锋, 倪郑威. 基于槽位相关信息提取的对话状态追踪模型[J]. 《计算机应用》唯一官方网站, 2023, 43(5): 1430-1437. |
| [6] | 王先兰, 周金坤, 穆楠, 王晨. 基于多任务联合学习的跨视角地理定位方法[J]. 《计算机应用》唯一官方网站, 2023, 43(5): 1625-1635. |
| [7] | 王惠茹, 李秀红, 李哲, 马春明, 任泽裕, 杨丹. 多模态预训练模型综述[J]. 《计算机应用》唯一官方网站, 2023, 43(4): 991-1004. |
| [8] | 高榕, 沈加伟, 邵雄凯, 吴歆韵. 基于Fastformer和自监督对比学习的实例分割算法[J]. 《计算机应用》唯一官方网站, 2023, 43(4): 1062-1070. |
| [9] | 葛孟婷, 万鸣华. 基于近邻监督局部不变鲁棒主成分分析的特征提取模型[J]. 《计算机应用》唯一官方网站, 2023, 43(4): 1013-1020. |
| [10] | 杨有, 张汝荟, 许鹏程, 康慷, 翟浩. 面向民国档案印章分割的改进U-Net[J]. 《计算机应用》唯一官方网站, 2023, 43(3): 943-948. |
| [11] | 李海丰, 张凡, 朴敏楠, 王怀超, 李南莎, 桂仲成. 基于通道和空间注意力的机场道面地下目标自动检测[J]. 《计算机应用》唯一官方网站, 2023, 43(3): 930-935. |
| [12] | 贾晴, 王来花, 王伟胜. 基于独立循环神经网络与变分自编码网络的视频帧异常检测[J]. 《计算机应用》唯一官方网站, 2023, 43(2): 507-513. |
| [13] | 胡婕, 陈晓茜, 张龑. 基于池化和特征组合增强BERT的答案选择模型[J]. 《计算机应用》唯一官方网站, 2023, 43(2): 365-373. |
| [14] | 徐铭, 李林昊, 齐巧玲, 王利琴. 基于注意力平衡列表的溯因推理模型[J]. 《计算机应用》唯一官方网站, 2023, 43(2): 349-355. |
| [15] | 胡婕, 胡燕, 刘梦赤, 张龑. 基于知识库实体增强BERT模型的中文命名实体识别[J]. 《计算机应用》唯一官方网站, 2022, 42(9): 2680-2685. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||