


Journal of Computer Applications ›› 2022, Vol. 42 ›› Issue (3): 757-763.DOI: 10.11772/j.issn.1001-9081.2021040857
Special Issue: 人工智能; 2021年中国计算机学会人工智能会议(CCFAI 2021)
• 2021 CCF Conference on Artificial Intelligence (CCFAI 2021) • Previous Articles Next Articles
Lu ZHANG, Chun FANG, Ming ZHU( )
)
Received:2021-05-25
Revised:2021-06-30
Accepted:2021-07-06
Online:2021-11-09
Published:2022-03-10
Contact:
Ming ZHU
About author:ZHANG Lu, born in 1996, M. S. candidate. His research interests include computer vision, deep learning.Supported by:
张璐, 方春, 祝铭()
通讯作者:
祝铭
作者简介:张璐(1996—),男,山东潍坊人,硕士研究生,主要研究方向:计算机视觉、深度学习基金资助:CLC Number:
Lu ZHANG, Chun FANG, Ming ZHU. Indoor fall detection algorithm based on Res2Net-YOLACT and fusion feature[J]. Journal of Computer Applications, 2022, 42(3): 757-763.
张璐, 方春, 祝铭. 基于Res2Net-YOLACT和融合特征的室内跌倒检测算法[J]. 《计算机应用》唯一官方网站, 2022, 42(3): 757-763.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2021040857

Fig.1 Network structure of Res2Net-YOLACT
| 网络层 | 卷积结构 | 卷积核 | 卷积步长 | 特征图大小 |
|---|---|---|---|---|
| 输入层 | — | — | — | 550×550 |
| Conv1 | — | 7×7@64 | 2 | 275×275 |
| Pool1 | Maxpool | 3×3@64 | 2 | 138×138 |
| L1 | Bottlenect (×3) | 1×1@64 3×3@64 3×3@64 3×3@64 1×1@256 | — | 138×138 |
| L2 | Bottlenect (×4) | 1×1@128 3×3@128 3×3@128 3×3@128 1×1@512 | — | 69×69 |
| L3 | Bottlenect (×6) | 1×1@256 3×3@256 3×3@256 3×3@256 1×1@1024 | — | 35×35 |
| L4 | Bottlenect (×3) | 1×1@512 3×3@512 3×3@512 3×3@512 1×1@2 048 | — | 18×18 |
Tab.1 Res2Net-50 backbone network for feature extraction
| 网络层 | 卷积结构 | 卷积核 | 卷积步长 | 特征图大小 |
|---|---|---|---|---|
| 输入层 | — | — | — | 550×550 |
| Conv1 | — | 7×7@64 | 2 | 275×275 |
| Pool1 | Maxpool | 3×3@64 | 2 | 138×138 |
| L1 | Bottlenect (×3) | 1×1@64 3×3@64 3×3@64 3×3@64 1×1@256 | — | 138×138 |
| L2 | Bottlenect (×4) | 1×1@128 3×3@128 3×3@128 3×3@128 1×1@512 | — | 69×69 |
| L3 | Bottlenect (×6) | 1×1@256 3×3@256 3×3@256 3×3@256 1×1@1024 | — | 35×35 |
| L4 | Bottlenect (×3) | 1×1@512 3×3@512 3×3@512 3×3@512 1×1@2 048 | — | 18×18 |

Fig.2 Overall flowchart of fall detection
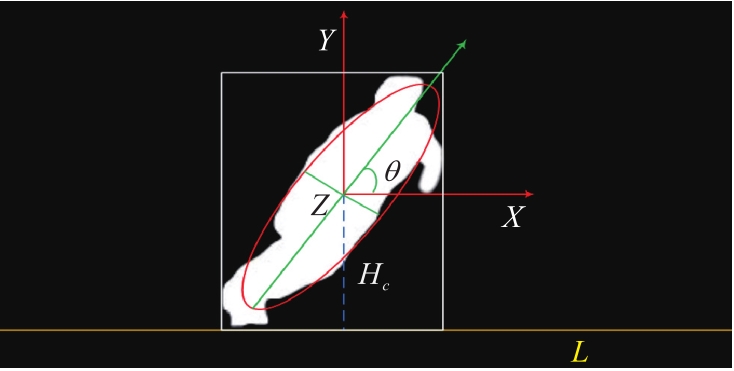
Fig.3 Ellipse fitting and key parameters of falling human body

Fig.4 Model structure of behavior classification
| 层数 | 输入尺寸 | 卷积核 | 池化 | 输出尺寸 |
|---|---|---|---|---|
| 输入层 | 30×30 | — | — | 30×30 |
| Conv1 | 30×30 | 3×3@32 | — | 28×28@32 |
| Pooling1 | 28×28 | — | Max pooling | 14×14@32 |
| Conv2 | 14×14 | 3×3@16 | — | 12×12@16 |
| Pooling2 | 12×12 | — | Max pooling | 6×6@16 |
| Conv3 | 6×6 | 3×3@8 | — | 4×4@8 |
| Pooling3 | 4×4 | — | Max pooling | 4×4@8 |
| FC | 4×4@8 | — | — | 1×128 |
| FC | 1×128 | — | — | 1×64 |
| 输出层 | 1×64 | — | — | 1×4 |
Tab.2 Convolutional neural network parameters
| 层数 | 输入尺寸 | 卷积核 | 池化 | 输出尺寸 |
|---|---|---|---|---|
| 输入层 | 30×30 | — | — | 30×30 |
| Conv1 | 30×30 | 3×3@32 | — | 28×28@32 |
| Pooling1 | 28×28 | — | Max pooling | 14×14@32 |
| Conv2 | 14×14 | 3×3@16 | — | 12×12@16 |
| Pooling2 | 12×12 | — | Max pooling | 6×6@16 |
| Conv3 | 6×6 | 3×3@8 | — | 4×4@8 |
| Pooling3 | 4×4 | — | Max pooling | 4×4@8 |
| FC | 4×4@8 | — | — | 1×128 |
| FC | 1×128 | — | — | 1×64 |
| 输出层 | 1×64 | — | — | 1×4 |

Fig.5 Extraction results of different human poses
| 视频名称 | 视频大小 | 录制环境 | 包含的行为活动 |
|---|---|---|---|
| Video1 | 320×240 | 白天光照充足 | 站立、弯身、跌倒 |
| Video2 | 320×240 | 白天光照充足 | 站立、弯身、坐 |
| Video3 | 320×240 | 夜晚灯光(亮光) | 站立、弯身、跌倒 |
| Video4 | 320×240 | 夜晚灯光(亮光) | 站立、弯身、坐 |
| Video5 | 320×240 | 夜晚灯光(暗光) | 站立、弯身、跌倒 |
| Video6 | 320×240 | 夜晚灯光(暗光) | 站立、弯身、坐 |
Tab.3 Introduction of video information
| 视频名称 | 视频大小 | 录制环境 | 包含的行为活动 |
|---|---|---|---|
| Video1 | 320×240 | 白天光照充足 | 站立、弯身、跌倒 |
| Video2 | 320×240 | 白天光照充足 | 站立、弯身、坐 |
| Video3 | 320×240 | 夜晚灯光(亮光) | 站立、弯身、跌倒 |
| Video4 | 320×240 | 夜晚灯光(亮光) | 站立、弯身、坐 |
| Video5 | 320×240 | 夜晚灯光(暗光) | 站立、弯身、跌倒 |
| Video6 | 320×240 | 夜晚灯光(暗光) | 站立、弯身、坐 |

Fig.6 Comparison results of different human contour extraction algorithms
| 算法 | 视频名称 | Recall/% | Precision/% | F1/% | 速度/fps |
|---|---|---|---|---|---|
| GMM | Video1 | 88.43 | 34.56 | 49.70 | — |
| Video2 | 91.67 | 45.24 | 60.52 | ||
| Video3 | 79.21 | 37.86 | 51.23 | ||
| Video4 | 73.77 | 32.98 | 45.58 | ||
| Video5 | 88.18 | 40.17 | 55.20 | ||
| Video6 | 75.64 | 36.61 | 49.34 | ||
| 均值 | 82.82 | 37.90 | 52.00 | ||
| Codebook | Video1 | 78.34 | 48.34 | 59.79 | — |
| Video2 | 85.71 | 36.87 | 51.56 | ||
| Video3 | 76.81 | 38.57 | 51.35 | ||
| Video4 | 70.66 | 37.81 | 49.26 | ||
| Video5 | 82.19 | 40.18 | 53.97 | ||
| Video6 | 73.24 | 43.46 | 54.55 | ||
| 均值 | 77.83 | 40.35 | 53.16 | ||
| Mask RCNN | Video1 | 97.64 | 96.81 | 97.22 | ≈7 |
| Video2 | 98.33 | 95.33 | 96.80 | ||
| Video3 | 96.44 | 94.74 | 95.58 | ||
| Video4 | 96.14 | 96.83 | 96.48 | ||
| Video5 | 93.64 | 95.77 | 94.69 | ||
| Video6 | 94.87 | 94.45 | 94.66 | ||
| 均值 | 96.18 | 95.66 | 95.92 | ||
| YOLACT | Video1 | 97.11 | 96.17 | 96.63 | ≈24 |
| Video2 | 97.32 | 94.26 | 95.77 | ||
| Video3 | 94.65 | 95.17 | 94.91 | ||
| Video4 | 96.15 | 95.83 | 95.99 | ||
| Video5 | 93.12 | 94.31 | 93.71 | ||
| Video6 | 94.98 | 95.14 | 95.06 | ||
| 均值 | 95.56 | 95.15 | 95.35 | ||
| Res2Net-YOLACT | Video1 | 96.11 | 96.06 | 96.08 | ≈28 |
| Video2 | 97.27 | 94.43 | 95.83 | ||
| Video3 | 93.91 | 94.81 | 94.36 | ||
| Video4 | 95.91 | 96.03 | 95.97 | ||
| Video5 | 93.10 | 94.52 | 93.80 | ||
| Video6 | 94.66 | 94.48 | 94.57 | ||
| 均值 | 95.16 | 95.06 | 95.11 |
Tab.4 Quantitative comparison results of different human contour extraction algorithms
| 算法 | 视频名称 | Recall/% | Precision/% | F1/% | 速度/fps |
|---|---|---|---|---|---|
| GMM | Video1 | 88.43 | 34.56 | 49.70 | — |
| Video2 | 91.67 | 45.24 | 60.52 | ||
| Video3 | 79.21 | 37.86 | 51.23 | ||
| Video4 | 73.77 | 32.98 | 45.58 | ||
| Video5 | 88.18 | 40.17 | 55.20 | ||
| Video6 | 75.64 | 36.61 | 49.34 | ||
| 均值 | 82.82 | 37.90 | 52.00 | ||
| Codebook | Video1 | 78.34 | 48.34 | 59.79 | — |
| Video2 | 85.71 | 36.87 | 51.56 | ||
| Video3 | 76.81 | 38.57 | 51.35 | ||
| Video4 | 70.66 | 37.81 | 49.26 | ||
| Video5 | 82.19 | 40.18 | 53.97 | ||
| Video6 | 73.24 | 43.46 | 54.55 | ||
| 均值 | 77.83 | 40.35 | 53.16 | ||
| Mask RCNN | Video1 | 97.64 | 96.81 | 97.22 | ≈7 |
| Video2 | 98.33 | 95.33 | 96.80 | ||
| Video3 | 96.44 | 94.74 | 95.58 | ||
| Video4 | 96.14 | 96.83 | 96.48 | ||
| Video5 | 93.64 | 95.77 | 94.69 | ||
| Video6 | 94.87 | 94.45 | 94.66 | ||
| 均值 | 96.18 | 95.66 | 95.92 | ||
| YOLACT | Video1 | 97.11 | 96.17 | 96.63 | ≈24 |
| Video2 | 97.32 | 94.26 | 95.77 | ||
| Video3 | 94.65 | 95.17 | 94.91 | ||
| Video4 | 96.15 | 95.83 | 95.99 | ||
| Video5 | 93.12 | 94.31 | 93.71 | ||
| Video6 | 94.98 | 95.14 | 95.06 | ||
| 均值 | 95.56 | 95.15 | 95.35 | ||
| Res2Net-YOLACT | Video1 | 96.11 | 96.06 | 96.08 | ≈28 |
| Video2 | 97.27 | 94.43 | 95.83 | ||
| Video3 | 93.91 | 94.81 | 94.36 | ||
| Video4 | 95.91 | 96.03 | 95.97 | ||
| Video5 | 93.10 | 94.52 | 93.80 | ||
| Video6 | 94.66 | 94.48 | 94.57 | ||
| 均值 | 95.16 | 95.06 | 95.11 |

Fig.7 Accuracy comparison of three algorithms on test data
| 目标检测算法 | 跌倒检 测方法 | 跌倒检测帧数 | 误判 帧数 | 实际跌倒帧数 | 准确率/% | 误判率/% |
|---|---|---|---|---|---|---|
| Codebook | 阈值法 | 60 | 7 | 70 | 85.71 | 10.00 |
| GMM | 61 | 6 | 87.14 | 8.57 | ||
| Mask RCNN | 65 | 5 | 92.86 | 7.14 | ||
| YOLACT | 65 | 5 | 92.86 | 7.14 | ||
| Res2Net-YOLACT | 65 | 5 | 92.86 | 7.14 | ||
| Codebook | CNN 分类 | 61 | 4 | 70 | 87.14 | 5.71 |
| GMM | 62 | 3 | 88.57 | 4.29 | ||
| Mask RCNN | 66 | 2 | 94.29 | 2.86 | ||
| YOLACT | 67 | 2 | 95.71 | 2.86 | ||
| Res2Net-YOLACT | 67 | 2 | 95.71 | 2.86 | ||
| Codebook | 本文 算法 | 58 | 4 | 70 | 82.86 | 5.71 |
| GMM | 61 | 4 | 87.14 | 5.71 | ||
| Mask RCNN | 68 | 1 | 97.14 | 1.43 | ||
| YOLACT | 67 | 2 | 95.71 | 2.86 | ||
| Res2Net-YOLACT | 68 | 1 | 97.14 | 1.43 |
Tab.5 Comparison experiment of different fall detection algorithms
| 目标检测算法 | 跌倒检 测方法 | 跌倒检测帧数 | 误判 帧数 | 实际跌倒帧数 | 准确率/% | 误判率/% |
|---|---|---|---|---|---|---|
| Codebook | 阈值法 | 60 | 7 | 70 | 85.71 | 10.00 |
| GMM | 61 | 6 | 87.14 | 8.57 | ||
| Mask RCNN | 65 | 5 | 92.86 | 7.14 | ||
| YOLACT | 65 | 5 | 92.86 | 7.14 | ||
| Res2Net-YOLACT | 65 | 5 | 92.86 | 7.14 | ||
| Codebook | CNN 分类 | 61 | 4 | 70 | 87.14 | 5.71 |
| GMM | 62 | 3 | 88.57 | 4.29 | ||
| Mask RCNN | 66 | 2 | 94.29 | 2.86 | ||
| YOLACT | 67 | 2 | 95.71 | 2.86 | ||
| Res2Net-YOLACT | 67 | 2 | 95.71 | 2.86 | ||
| Codebook | 本文 算法 | 58 | 4 | 70 | 82.86 | 5.71 |
| GMM | 61 | 4 | 87.14 | 5.71 | ||
| Mask RCNN | 68 | 1 | 97.14 | 1.43 | ||
| YOLACT | 67 | 2 | 95.71 | 2.86 | ||
| Res2Net-YOLACT | 68 | 1 | 97.14 | 1.43 |
| 光照 | 跌倒检 测帧数 | 误判 帧数 | 实际跌 倒帧数 | 准确率/% | 误判率/% |
|---|---|---|---|---|---|
| 正常光 | 66 | 0 | 68 | 97.06 | 0.00 |
| 干扰光 | 70 | 2 | 73 | 95.89 | 2.74 |
| 正常光 | 69 | 1 | 71 | 97.18 | 1.41 |
| 干扰光 | 68 | 0 | 70 | 97.14 | 0.00 |
| 正常光 | 62 | 1 | 65 | 95.38 | 1.54 |
| 干扰光 | 64 | 0 | 67 | 95.52 | 0.00 |
| 正常光 | 72 | 2 | 74 | 97.30 | 2.70 |
| 干扰光 | 67 | 1 | 70 | 95.71 | 1.43 |
| 正常光 | 60 | 1 | 63 | 95.24 | 1.59 |
| 干扰光 | 58 | 0 | 60 | 96.67 | 0.00 |
Tab.6 Comparison result with light interference
| 光照 | 跌倒检 测帧数 | 误判 帧数 | 实际跌 倒帧数 | 准确率/% | 误判率/% |
|---|---|---|---|---|---|
| 正常光 | 66 | 0 | 68 | 97.06 | 0.00 |
| 干扰光 | 70 | 2 | 73 | 95.89 | 2.74 |
| 正常光 | 69 | 1 | 71 | 97.18 | 1.41 |
| 干扰光 | 68 | 0 | 70 | 97.14 | 0.00 |
| 正常光 | 62 | 1 | 65 | 95.38 | 1.54 |
| 干扰光 | 64 | 0 | 67 | 95.52 | 0.00 |
| 正常光 | 72 | 2 | 74 | 97.30 | 2.70 |
| 干扰光 | 67 | 1 | 70 | 95.71 | 1.43 |
| 正常光 | 60 | 1 | 63 | 95.24 | 1.59 |
| 干扰光 | 58 | 0 | 60 | 96.67 | 0.00 |
| 活动 | 视频片段数 | 检测结果 | |
|---|---|---|---|
| 跌倒数 | 非跌倒数 | ||
| 行走 | 100 | 0 | 100 |
| 坐起 | 100 | 3 | 97 |
| 下弯 | 100 | 3 | 97 |
| 躺 | 100 | 2 | 98 |
| 跌倒 | 100 | 97 | 3 |
Tab.7 Detection results of the proposed fall detection algorithm
| 活动 | 视频片段数 | 检测结果 | |
|---|---|---|---|
| 跌倒数 | 非跌倒数 | ||
| 行走 | 100 | 0 | 100 |
| 坐起 | 100 | 3 | 97 |
| 下弯 | 100 | 3 | 97 |
| 躺 | 100 | 2 | 98 |
| 跌倒 | 100 | 97 | 3 |
| 1 | 丁志宏, 杜书然, 王明鑫. 我国城市老年人跌倒状况及其影响因素研究[J]. 人口与发展, 2018, 24(4):120-128. |
| DING Z H, DU S R, WANG M X. Research on the falls and its risk factors among the urban aged in China[J]. Population and Development, 2018, 24(4):120-128. | |
| 2 | 师昉, 李福亮, 张思佳, 等. 中国老年跌倒研究的现状与对策[J]. 中国康复, 2018, 33(3):246-248. 10.3870/zgkf.2018.03.021 |
| SHI F, LI F L, ZHANG S J, et al. The status quo and countermeasures of research on elderly falls in China[J]. Chinese Journal of Rehabilitation, 2018, 33(3):246-248. 10.3870/zgkf.2018.03.021 | |
| 3 | SANTOS G, ENDO P, MONTEIRO K, et al. Accelerometer-based human fall detection using convolutional neural networks[J]. Sensors, 2019, 19(7):1644. 10.3390/s19071644 |
| 4 | CLEMENTE J, SONG W Z, VALERO M, et al. Indoor person identification and fall detection through non-intrusive floor seismic sensing[C]// Proceedings of the 2019 IEEE International Conference on Smart Computing. Piscataway: IEEE, 2019: 417-424. 10.1109/smartcomp.2019.00081 |
| 5 | EZATZADEH S, KEYVANPOUR M R. ViFa: an analytical framework for vision-based fall detection in a surveillance environment[J]. Multimedia Tools and Applications, 2019, 78(18): 25515-25537. 10.1007/s11042-019-7720-3 |
| 6 | LU X, XU C, WANG L, et al. Improved background subtraction method for detecting moving objects based on GMM[J]. IEEE Transactions on Electrical and Electronic Engineering, 2018, 13(11): 1540-1550. 10.1002/tee.22718 |
| 7 | KRUNGKAEW R, KUSAKUNNIRAN W. Foreground segmentation in a video by using a novel dynamic codebook[C]// Proceedings of the 2016 13th International Conference on Electrical Engineering/Electronics, Computer, Telecommunications and Information Technology. Piscataway: IEEE, 2016:1-6. 10.1109/ecticon.2016.7561253 |
| 8 | HE B, YU S. An improved background subtraction method based on ViBe[C]// Proceedings of the 7th Chinese Conference on Pattern Recognition. Cham: Springer, 2016: 356-368. 10.1007/978-981-10-3002-4_30 |
| 9 | MIN W, WEI L, HAN Q, et al. Human fall detection based on motion tracking and shape aspect ratio[J]. International Journal of Multimedia and Ubiquitous Engineering, 2016, 11(10): 1-14. 10.14257/ijmue.2016.11.10.01 |
| 10 | VAIDEHI V, GANAPATHY K, MOHAN K, et al. Video based automatic fall detection in indoor environment[C]// Proceedings of the 2011 International Conference on Recent Trends in Information Technology. Piscataway: IEEE, 2011: 1016-1020. 10.1109/icrtit.2011.5972252 |
| 11 | LIN C, WANG S, HONG J, et al. Vision-based fall detection through shape features[C]// Proceedings of the 2016 IEEE 2nd International Conference on Multimedia Big Data. Piscataway: IEEE, 2016: 237-240. 10.1109/bigmm.2016.22 |
| 12 | MIRMAHBOUB B, SAMAVI S, KARIMI N, et al. Automatic monocular system for human fall detection based on variations in silhouette area[J]. IEEE Transactions on Biomedical Engineering, 2013, 60(2):427-436. 10.1109/tbme.2012.2228262 |
| 13 | TRA K, PHAM T V. Human fall detection based on adaptive background mixture model and HMM[C]// Proceedings of the 2013 International Conference on Advanced Technologies for Communications. Piscataway: IEEE, 2013:95-100. 10.1109/atc.2013.6698085 |
| 14 | YU M, GONG L, KOLLIAS S. Computer vision based fall detection by a convolutional neural network[C]// Proceedings of the 19th ACM International Conference on Multimodal Interaction. New York: ACM, 2017: 416-420. 10.1145/3136755.3136802 |
| 15 | KHAN M A, SHARIF M, AKRAM T, et al. Hand-crafted and deep convolutional neural network features fusion and selection strategy: an application to intelligent human action recognition[J]. Applied Soft Computing, 2019, 87:105986. 10.1016/j.asoc.2019.105986 |
| 16 | BOLYA D, ZHOU C, XIAO F, et al. YOLACT: real-time instance segmentation[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 9157-9166. 10.1109/iccv.2019.00925 |
| 17 | HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 770-778. 10.1109/cvpr.2016.90 |
| 18 | GAO S, CHENG M, ZHAO K, et al. Res2Net: a new multi-scale backbone architecture[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019, 43(2): 652-662 . |
| 19 | LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot multibox detector[C]// Proceedings of the 2016 European Conference on Computer Vision. Cham: Springer, 2016: 21-37. 10.1007/978-3-319-46448-0_2 |
| 20 | YU M, YU Y, RHUMA A, et al. An online one class support vector machine-based person-specific fall detection system for monitoring an elderly individual in a room environment[J]. IEEE Journal of Biomedical & Health Informatics, 2013, 17(6):1002-1014. 10.1109/jbhi.2013.2274479 |
| 21 | YAO G, LEI T, ZHONG J. A review of convolutional-neural-network-based action recognition[J]. Pattern Recognition Letters, 2018, 118:14-22. 10.1016/j.patrec.2018.05.018 |
| 22 | TAN C, SUN F, KONG T, et al. A survey on deep transfer learning[C]// Proceedings of the 27th International Conference on Artificial Neural Networks. Cham: Springer, 2018:270-279. 10.1007/978-3-030-01424-7_27 |
| 23 | FENG Q, GAO C, WANG L, et al. Spatio-temporal fall event detection in complex scenes using attention guided LSTM[J]. Pattern Recognition Letters, 2020, 130: 242-249. 10.1016/j.patrec.2018.08.031 |
| [1] | Yun LI, Fuyou WANG, Peiguang JING, Su WANG, Ao XIAO. Uncertainty-based frame associated short video event detection method [J]. Journal of Computer Applications, 2024, 44(9): 2903-2910. |
| [2] | Hong CHEN, Bing QI, Haibo JIN, Cong WU, Li’ang ZHANG. Class-imbalanced traffic abnormal detection based on 1D-CNN and BiGRU [J]. Journal of Computer Applications, 2024, 44(8): 2493-2499. |
| [3] | Yangyi GAO, Tao LEI, Xiaogang DU, Suiyong LI, Yingbo WANG, Chongdan MIN. Crowd counting and locating method based on pixel distance map and four-dimensional dynamic convolutional network [J]. Journal of Computer Applications, 2024, 44(7): 2233-2242. |
| [4] | Dongwei WANG, Baichen LIU, Zhi HAN, Yanmei WANG, Yandong TANG. Deep network compression method based on low-rank decomposition and vector quantization [J]. Journal of Computer Applications, 2024, 44(7): 1987-1994. |
| [5] | Mengyuan HUANG, Kan CHANG, Mingyang LING, Xinjie WEI, Tuanfa QIN. Progressive enhancement algorithm for low-light images based on layer guidance [J]. Journal of Computer Applications, 2024, 44(6): 1911-1919. |
| [6] | Jianjing LI, Guanfeng LI, Feizhou QIN, Weijun LI. Multi-relation approximate reasoning model based on uncertain knowledge graph embedding [J]. Journal of Computer Applications, 2024, 44(6): 1751-1759. |
| [7] | Min SUN, Qian CHENG, Xining DING. CBAM-CGRU-SVM based malware detection method for Android [J]. Journal of Computer Applications, 2024, 44(5): 1539-1545. |
| [8] | Wenshuo GAO, Xiaoyun CHEN. Point cloud classification network based on node structure [J]. Journal of Computer Applications, 2024, 44(5): 1471-1478. |
| [9] | Jie WANG, Hua MENG. Image classification algorithm based on overall topological structure of point cloud [J]. Journal of Computer Applications, 2024, 44(4): 1107-1113. |
| [10] | Tianhua CHEN, Jiaxuan ZHU, Jie YIN. Bird recognition algorithm based on attention mechanism [J]. Journal of Computer Applications, 2024, 44(4): 1114-1120. |
| [11] | Lijun XU, Hui LI, Zuyang LIU, Kansong CHEN, Weixuan MA. 3D-GA-Unet: MRI image segmentation algorithm for glioma based on 3D-Ghost CNN [J]. Journal of Computer Applications, 2024, 44(4): 1294-1302. |
| [12] | Ruifeng HOU, Pengcheng ZHANG, Liyuan ZHANG, Zhiguo GUI, Yi LIU, Haowen ZHANG, Shubin WANG. Iterative denoising network based on total variation regular term expansion [J]. Journal of Computer Applications, 2024, 44(3): 916-921. |
| [13] | Jingxian ZHOU, Xina LI. UAV detection and recognition based on improved convolutional neural network and radio frequency fingerprint [J]. Journal of Computer Applications, 2024, 44(3): 876-882. |
| [14] | Yongfeng DONG, Jiaming BAI, Liqin WANG, Xu WANG. Chinese named entity recognition combining prior knowledge and glyph features [J]. Journal of Computer Applications, 2024, 44(3): 702-708. |
| [15] | Rui ZHANG, Siqi SONG, Jing HU, Yongmei ZHANG, Yanfeng CHAI. Performance evaluation of industry-university-research based on statistics and adaptive ParNet [J]. Journal of Computer Applications, 2024, 44(2): 628-637. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||