


Journal of Computer Applications ›› 2024, Vol. 44 ›› Issue (6): 1727-1733.DOI: 10.11772/j.issn.1001-9081.2023060847
Special Issue: CCF第38届中国计算机应用大会 (CCF NCCA 2023)
• The 38th CCF National Conference of Computer Applications (CCF NCCA 2023) • Previous Articles Next Articles
Xu LI1, Yulin HE1( ), Laizhong CUI1,2, Zhexue HUANG1,2, Fournier‑Viger PHILIPPE2
), Laizhong CUI1,2, Zhexue HUANG1,2, Fournier‑Viger PHILIPPE2
Received:2023-06-29
Revised:2023-08-21
Accepted:2023-08-23
Online:2023-09-11
Published:2024-06-10
Contact:
Yulin HE
About author:LI Xu, born in 1996, M. S., engineer. His research interests include distributed computation of big data, data mining, machine learning.Supported by:
李旭1, 何玉林1(), 崔来中1,2, 黄哲学1,2, PHILIPPE Fournier‑Viger2
通讯作者:
何玉林
作者简介:李旭(1996—),男,广东汕头人,工程师,硕士,CCF会员,主要研究方向:大数据分布式计算、数据挖掘、机器学习基金资助:CLC Number:
Xu LI, Yulin HE, Laizhong CUI, Zhexue HUANG, Fournier‑Viger PHILIPPE. Distributed observation point classifier for big data with random sample partition[J]. Journal of Computer Applications, 2024, 44(6): 1727-1733.
李旭, 何玉林, 崔来中, 黄哲学, PHILIPPE Fournier‑Viger. 基于大数据随机样本划分的分布式观测点分类器[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1727-1733.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2023060847
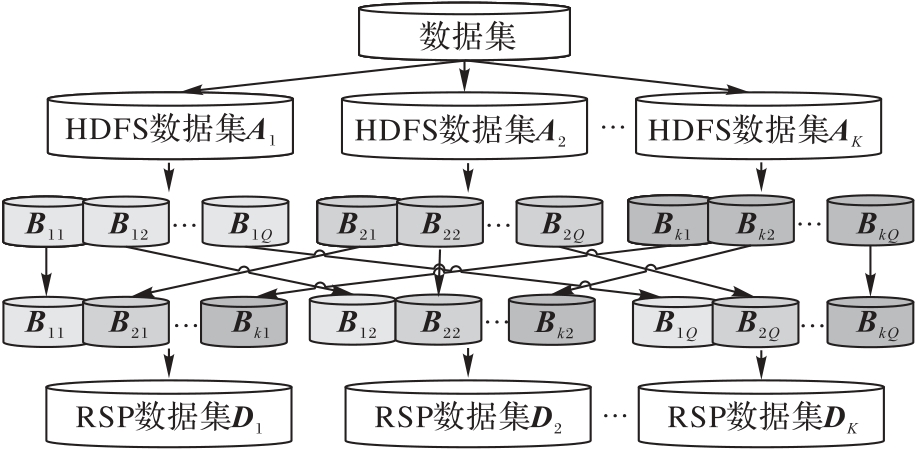
Fig.1 Generation process of RSP data blocks
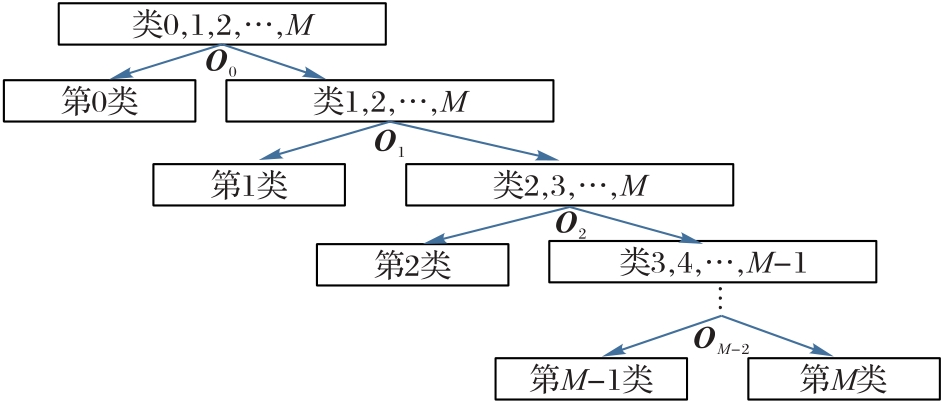
Fig.2 Construction schematic diagram of multi-class OPC
| 数据集 | 样本数 | 属性数 | 类别数 | 分块数 |
|---|---|---|---|---|
| Skin Segmentation | 245 057 | 3 | 2 | 50 |
| Census-Income | 299 285 | 40 | 2 | 50 |
| RLCP | 5 749 132 | 11 | 2 | 100 |
| HIGGS | 11 000 000 | 28 | 2 | 1 200 |
| 仿真数据集1 | 1 000 000 | 7 | 2 | 50 |
| 仿真数据集2 | 1 500 000 | 7 | 5 | 50 |
| 仿真数据集3 | 10 000 000 | 7 | 3 | 500 |
| 仿真数据集4 | 20 000 000 | 7 | 2 | 1 000 |
Tab.1 Information of experiment datasets
| 数据集 | 样本数 | 属性数 | 类别数 | 分块数 |
|---|---|---|---|---|
| Skin Segmentation | 245 057 | 3 | 2 | 50 |
| Census-Income | 299 285 | 40 | 2 | 50 |
| RLCP | 5 749 132 | 11 | 2 | 100 |
| HIGGS | 11 000 000 | 28 | 2 | 1 200 |
| 仿真数据集1 | 1 000 000 | 7 | 2 | 50 |
| 仿真数据集2 | 1 500 000 | 7 | 5 | 50 |
| 仿真数据集3 | 10 000 000 | 7 | 3 | 500 |
| 仿真数据集4 | 20 000 000 | 7 | 2 | 1 000 |
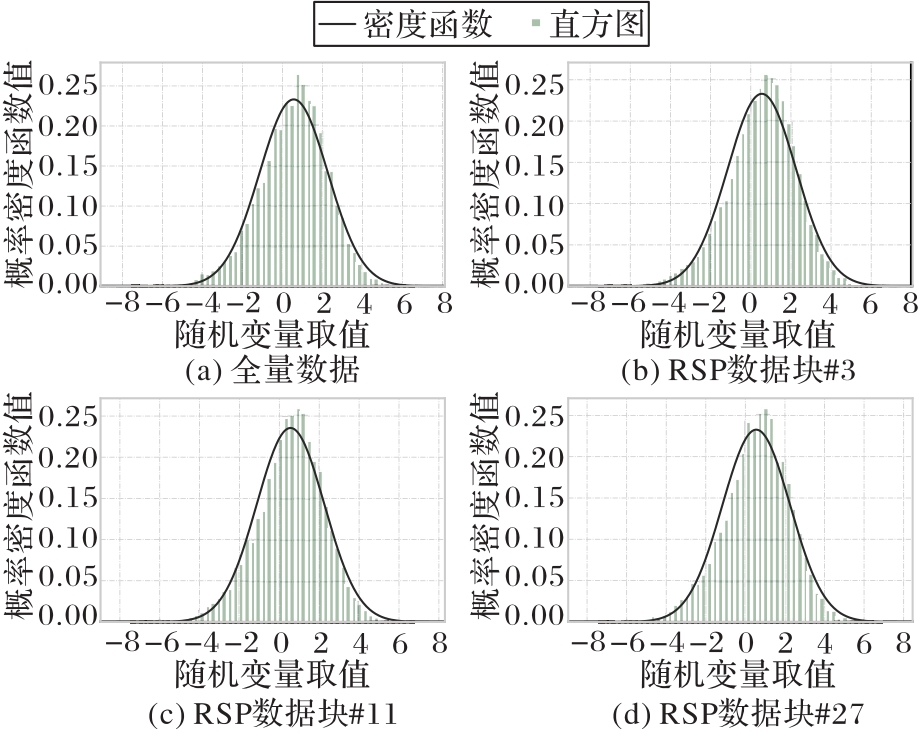
Fig. 3 Probability distribution consistency verification of different RSP data blocks

Fig. 4 Testing accuracies of single machine training and cluster training on eight datasets
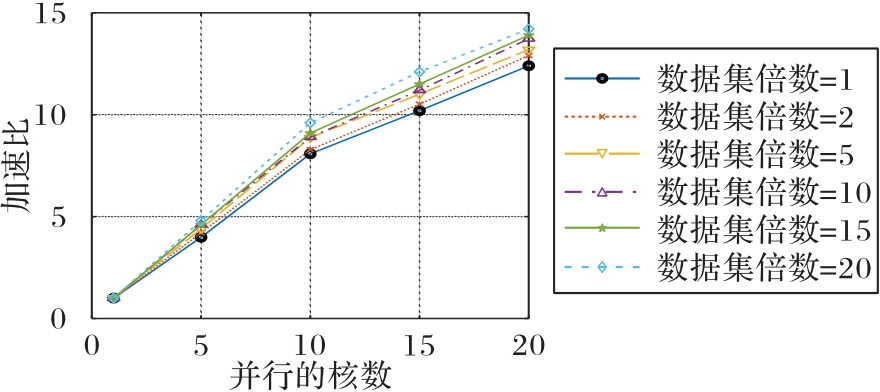
Fig.5 Speedup evaluation of DOPC
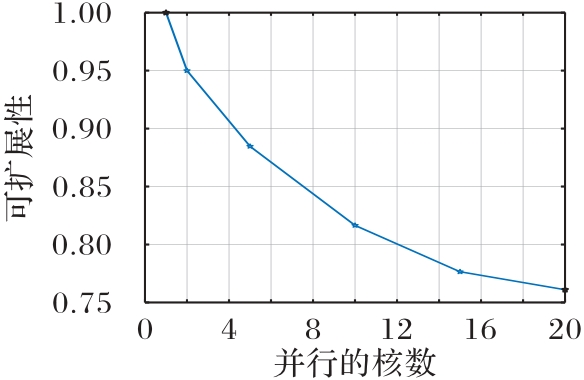
Fig.6 Scaleup evaluation of DOPC
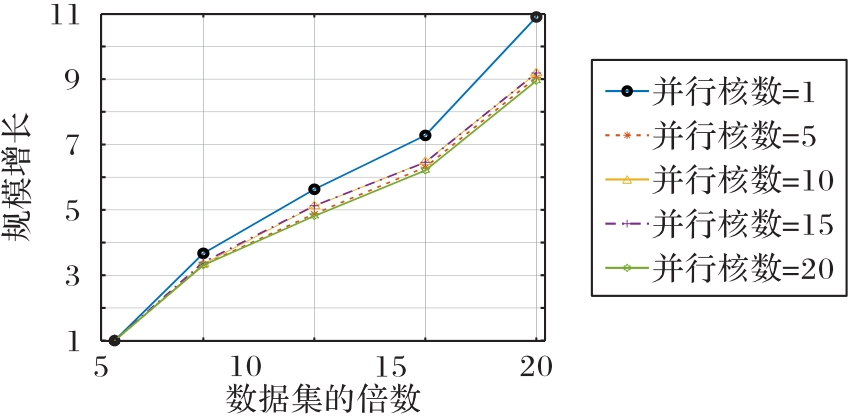
Fig.7 Sizeup evaluation of DOPC
| 数据集 | 单计算节点OPC | DOPC | ||
|---|---|---|---|---|
| 训练时间/s | 测试精度 | 训练时间/s | 测试精度 | |
| Skin Segmentation | 139.734±15.478 | 0.990±0.012 | 45.896±3.783 | 0.994±0.002 |
| Census-Income | 8 315.174±53.542 | 0.927±0.007 | 58.750±5.315 | 0.943±0.001 |
| RLCP | 1 625.486±89.263 | 0.959±0.003 | 230.218±4.172 | 0.984±0.002 |
| HIGGS | — | — | 14 267.521±318.905 | 0.601±0.005 |
| 仿真数据集1 | 26 125.715±131.297 | 0.951±0.021 | 458.760±21.142 | 0.963±0.003 |
| 仿真数据集2 | 42 512.142±236.364 | 0.800±0.013 | 1 339.028±30.513 | 0.821±0.016 |
| 仿真数据集3 | 259 341.914±714.381 | 0.852±0.035 | 7 015.188±214.275 | 0.877±0.018 |
| 仿真数据集4 | — | — | 8 720.214±227.164 | 0.950±0.002 |
Tab.2 Comparison of training time and testing accuracy between OPC and DOPC
| 数据集 | 单计算节点OPC | DOPC | ||
|---|---|---|---|---|
| 训练时间/s | 测试精度 | 训练时间/s | 测试精度 | |
| Skin Segmentation | 139.734±15.478 | 0.990±0.012 | 45.896±3.783 | 0.994±0.002 |
| Census-Income | 8 315.174±53.542 | 0.927±0.007 | 58.750±5.315 | 0.943±0.001 |
| RLCP | 1 625.486±89.263 | 0.959±0.003 | 230.218±4.172 | 0.984±0.002 |
| HIGGS | — | — | 14 267.521±318.905 | 0.601±0.005 |
| 仿真数据集1 | 26 125.715±131.297 | 0.951±0.021 | 458.760±21.142 | 0.963±0.003 |
| 仿真数据集2 | 42 512.142±236.364 | 0.800±0.013 | 1 339.028±30.513 | 0.821±0.016 |
| 仿真数据集3 | 259 341.914±714.381 | 0.852±0.035 | 7 015.188±214.275 | 0.877±0.018 |
| 仿真数据集4 | — | — | 8 720.214±227.164 | 0.950±0.002 |
| 数据集 | DOPC | NN-Spark | DT-Spark | KNN-Spark | NB-Spark |
|---|---|---|---|---|---|
| Skin Segmentation | 0.994±0.002 | 0.989±0.001 | 0.976±0.002 | 0.994±0.002 | 0.923±0.003 |
| Census-Income | 0.943±0.001 | 0.938±0.007 | 0.920±0.031 | 0.937±0.012 | 0.570±0.044 |
| RLCP | 0.984±0.002 | 0.998±0.001 | 0.998±0.001 | 0.999±0.000 | 0.981±0.005 |
| HIGGS | 0.601±0.005 | 0.570±0.005 | 0.673±0.005 | 0.579±0.014 | 0.583±0.004 |
| 仿真数据集1 | 0.963±0.003 | 0.938±0.001 | 0.963±0.008 | 0.951±0.013 | 0.870±0.002 |
| 仿真数据集2 | 0.821±0.016 | 0.818±0.021 | 0.809±0.015 | 0.815±0.006 | 0.658±0.001 |
| 仿真数据集3 | 0.877±0.018 | 0.820±0.004 | 0.831±0.003 | 0.831±0.002 | 0.675±0.004 |
| 仿真数据集4 | 0.950±0.002 | 0.924±0.007 | 0.944±0.003 | 0.941±0.005 | 0.902±0.009 |
| 平均精度 | 0.891±0.006 | 0.874±0.005 | 0.889±0.008 | 0.880±0.006 | 0.770±0.009 |
Tab.3 Comparison of testing accuracy among DOPC, NN-Spark, DT-Spark, KNN-Spark and NB-Spark
| 数据集 | DOPC | NN-Spark | DT-Spark | KNN-Spark | NB-Spark |
|---|---|---|---|---|---|
| Skin Segmentation | 0.994±0.002 | 0.989±0.001 | 0.976±0.002 | 0.994±0.002 | 0.923±0.003 |
| Census-Income | 0.943±0.001 | 0.938±0.007 | 0.920±0.031 | 0.937±0.012 | 0.570±0.044 |
| RLCP | 0.984±0.002 | 0.998±0.001 | 0.998±0.001 | 0.999±0.000 | 0.981±0.005 |
| HIGGS | 0.601±0.005 | 0.570±0.005 | 0.673±0.005 | 0.579±0.014 | 0.583±0.004 |
| 仿真数据集1 | 0.963±0.003 | 0.938±0.001 | 0.963±0.008 | 0.951±0.013 | 0.870±0.002 |
| 仿真数据集2 | 0.821±0.016 | 0.818±0.021 | 0.809±0.015 | 0.815±0.006 | 0.658±0.001 |
| 仿真数据集3 | 0.877±0.018 | 0.820±0.004 | 0.831±0.003 | 0.831±0.002 | 0.675±0.004 |
| 仿真数据集4 | 0.950±0.002 | 0.924±0.007 | 0.944±0.003 | 0.941±0.005 | 0.902±0.009 |
| 平均精度 | 0.891±0.006 | 0.874±0.005 | 0.889±0.008 | 0.880±0.006 | 0.770±0.009 |
| 1 | 梅宏, 杜小勇, 金海, 等. 大数据技术前瞻[J]. 大数据, 2023, 9(1):1-20. |
| MEI H, DU X Y, JIN H, et al. Big data technologies forward-looking [J]. Big Data Research, 2023, 9(1):1-20. | |
| 2 | KARUN A K, CHITHARANJAN K. A review on hadoop: HDFS infrastructure extensions[C]// Proceedings of the 2013 IEEE Conference on Information & Communication Technologies. Piscataway: IEEE, 2013: 132-137. |
| 3 | DEAN J, GHEMAWAT S. MapReduce: a flexible data processing tool [J]. Communications of the ACM, 2010, 53(1): 72-77. |
| 4 | ZAHARIA M, XIN R S, WENDELL P, et al. Apache Spark: a unified engine for big data processing [J]. Communications of the ACM, 2016, 59(11): 56-65. |
| 5 | SLEEMAN IV W C, KRAWCZYK B. Multi-class imbalanced big data classification on Spark [J]. Knowledge-Based Systems, 2021, 212: 106598. |
| 6 | 黄哲学, 何玉林, 魏丞昊,等. 大数据随机样本划分模型及相关分析计算技术[J]. 数据采集与处理, 2019, 34(3): 373-385. |
| HUANG Z X, HE Y L, WEI C H, et al. Random sample partition data model and related technologies for big data analysis[J]. Journal of Data Acqusisition & Processing, 2019, 34(3): 373-385. | |
| 7 | SALLOUM S, HUANG J Z, HE Y. Random sample partition: a distributed data model for big data analysis [J]. IEEE Transactions on Industrial Informatics, 2019, 15(11): 5846-5854. |
| 8 | HE Y L, LI X, FOURNIER-VIGER P, et al. Observation points classifier ensemble for high-dimensional imbalanced classification[J]. CAAI Transactions on Intelligence Technology, 2023, 8(2): 500-517. |
| 9 | TRIGUERO I, PERALTA D, BACARDIT J, et al. MRPR: a MapReduce solution for prototype reduction in big data classification[J]. Neurocomputing, 2015, 150: 331-345. |
| 10 | MAILLO J, TRIGUERO I, HERRERA F. A MapReduce-based k-nearest neighbor approach for big data classification[C]// Proceedings of the 2015 IEEE Trustcom/BigDataSE/ISPA. Piscataway: IEEE, 2015: 167-172. |
| 11 | KUMAR M, RATH S K. Classification of microarray using MapReduce based proximal support vector machine classifier [J]. Knowledge-Based Systems, 2015, 89: 584-602. |
| 12 | SUYKENS J A K, VANDEWALLE J. Least squares support vector machine classifiers[J]. Neural Processing Letters, 1999, 9(3): 293-300. |
| 13 | BECHINI A, MARCELLONI F, SEGATORI A. A MapReduce solution for associative classification of big data[J]. Information Sciences, 2016, 332: 33-55. |
| 14 | LI H, WANG Y, ZHANG D, et al. PFP: parallel FP-Growth for query recommendation[C]// Proceedings of the 2008 ACM Conference on Recommender Systems. New York: ACM, 2008: 107-114. |
| 15 | 于苹苹,倪建成,姚彬修,等.基于Spark框架的高效KNN中文文本分类算法[J]. 计算机应用, 2016, 36(12): 3292-3297. |
| YU P P, NI J C, YAO B X, et al. Highly efficient Chinese text classification algorithm of KNN based on Spark framework[J]. Journal of Computer Applications, 2016, 36(12): 3292-3297. | |
| 16 | 夏宁霞, 苏一丹, 覃希. 一种高效的K-medoids聚类算法[J]. 计算机应用研究, 2010, 27(12): 4517-4519. |
| XIA N X, SU Y D, QIN X. Efficient K-medoids clustering algorithm[J]. Application Research of Computers, 2010, 27(12): 4517-4519. | |
| 17 | RAMÍREZ-GALLEGO S, KRAWCZYK B, GARCÍA S, et al. Nearest neighbor classification for high-speed big data streams using Spark[J]. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2017, 47(10): 2727-2739. |
| 18 | 刘牧雷,徐菲菲.基于Spark的大数据三枝决策分类方法[J]. 上海电力学院学报, 2018, 34(5): 483-490. |
| LIU M L, XU F F. Processing big data with three way decision based on Spark [J]. Journal of Shanghai University of Electric Power, 2018, 34(5): 483-490. | |
| 19 | YAO Y. The superiority of three-way decisions in probabilistic rough set models [J]. Information Sciences, 2011, 181(6): 1080-1096. |
| 20 | LIU P, ZHAO H, TENG J, et al. Parallel naive Bayes algorithm for large-scale Chinese text classification based on Spark[J]. Journal of Central South University, 2019, 26(1): 1-12. |
| 21 | ALI A H, ABDULLAH M Z. A parallel grid optimization of SVM hyperparameter for big data classification using Spark Radoop [J]. Karbala International Journal of Modern Science, 2020, 6(1): 3. |
| 22 | KENNEDY J, EBERHART R. Particle swarm optimization [C]// Proceedings of the 1995 International Conference on Neural Networks. Piscataway: IEEE, 1995, 4: 1942-1948. |
| 23 | HE Q, SHANG T, ZHUANG F, et al. Parallel extreme learning machine for regression based on MapReduce[J]. Neurocomputing, 2013, 102: 52-58. |
| [1] | Ruixuan NI, Miao CAI, Baoliu YE. DFS-Cache: memory-efficient and persistent client cache for distributed file systems [J]. Journal of Computer Applications, 2024, 44(4): 1172-1180. |
| [2] | GOU Zi'an, ZHANG Xiao, WU Dongnan, WANG Yanqiu. Log analysis and workload characteristic extraction in distributed storage system [J]. Journal of Computer Applications, 2020, 40(9): 2586-2593. |
| [3] | DONG Cong, ZHANG Xiao, CHENG Wendi, SHI Jia. Performance optimization of distributed file system based on new type storage devices [J]. Journal of Computer Applications, 2020, 40(12): 3594-3603. |
| [4] | CHEN Bo, HE Lianyue, YAN Weiwei, XU Zhaomiao, XU Jun. Portable operating system interface of UNIX compatibility technology in mass small distributed file system [J]. Journal of Computer Applications, 2018, 38(5): 1389-1392. |
| [5] | LI Qiang, LIU Xiaofeng. Load balancing strategy of cloud storage based on Hopfield neural network [J]. Journal of Computer Applications, 2017, 37(8): 2214-2217. |
| [6] | YANG Junjie, LIAO Zhuofan, FENG Chaochao. Survey on big data storage framework and algorithm [J]. Journal of Computer Applications, 2016, 36(9): 2465-2471. |
| [7] | LIU Qing, FU Yinjin, NI Guiqiang, MEI Jianmin. Distributed deduplication storage system based on Hadoop platform [J]. Journal of Computer Applications, 2016, 36(2): 330-335. |
| [8] | WU Jinbo, SONG Jie, ZHANG Li, BAO Yubin. Probery: probability-based data query system for big data [J]. Journal of Computer Applications, 2016, 36(1): 8-12. |
| [9] | SHAO Tian, CHEN Guangsheng, JING Weipeng. Cut-GAR: solution to determine cut-off point in cloud storage system [J]. Journal of Computer Applications, 2015, 35(9): 2497-2502. |
| [10] | YANG Wenhui, LI Guoqiang, MIAO Fang. Metadata management mechanism of massive spatial data storage [J]. Journal of Computer Applications, 2015, 35(5): 1276-1279. |
| [11] | ZHENG Kai, ZHU Lin, CHEN Youguang. Load balancing cloud storage algorithm based on Kademlia [J]. Journal of Computer Applications, 2015, 35(3): 643-647. |
| [12] | WANG Zhengying, YU Jiong, YING Changtian, LU Liang. Energy-efficient strategy of distributed file system based on data block clustering storage [J]. Journal of Computer Applications, 2015, 35(2): 378-382. |
| [13] | CHEN Jirong LE Jiajin. Programming model based on MapReduce for importing big table into HDFS [J]. Journal of Computer Applications, 2013, 33(09): 2486-2489. |
| [14] | ZHU Yuanyuan WANG Xiaojing. HDFS optimization program based on GE coding [J]. Journal of Computer Applications, 2013, 33(03): 730-733. |
| [15] | CHEN Dongxiao WANG Peng. Distributed storage solution based on parity coding [J]. Journal of Computer Applications, 2013, 33(01): 211-214. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||