


Journal of Computer Applications ›› 2024, Vol. 44 ›› Issue (7): 2192-2199.DOI: 10.11772/j.issn.1001-9081.2023070926
• Multimedia computing and computer simulation • Previous Articles Next Articles
Song XU1, Wenbo ZHANG1, Yifan WANG2( )
)
Received:2023-07-09
Revised:2023-10-11
Accepted:2023-10-13
Online:2023-10-26
Published:2024-07-10
Contact:
Yifan WANG
About author:XU Song, born in 2000, M. S. candidate. His research interests include video salient object detection, weakly supervised salient object detection.Supported by:
徐松1, 张文博1, 王一帆2()
通讯作者:
王一帆
作者简介:徐松(2000—),男,安徽宿州人,硕士研究生,主要研究方向:视频显著性目标检测、弱监督显著性目标检测;基金资助:CLC Number:
Song XU, Wenbo ZHANG, Yifan WANG. Lightweight video salient object detection network based on spatiotemporal information[J]. Journal of Computer Applications, 2024, 44(7): 2192-2199.
徐松, 张文博, 王一帆. 基于时空信息的轻量视频显著性目标检测网络[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2192-2199.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2023070926

Fig. 1 Structure comparison between proposed network and mainstream networks
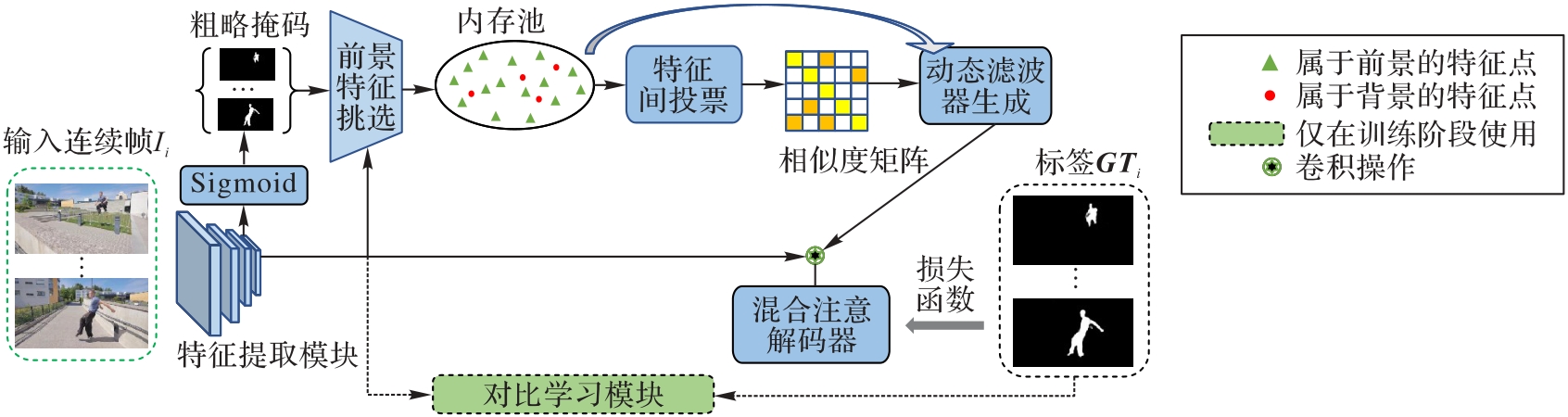
Fig. 2 Overall structure of proposed network
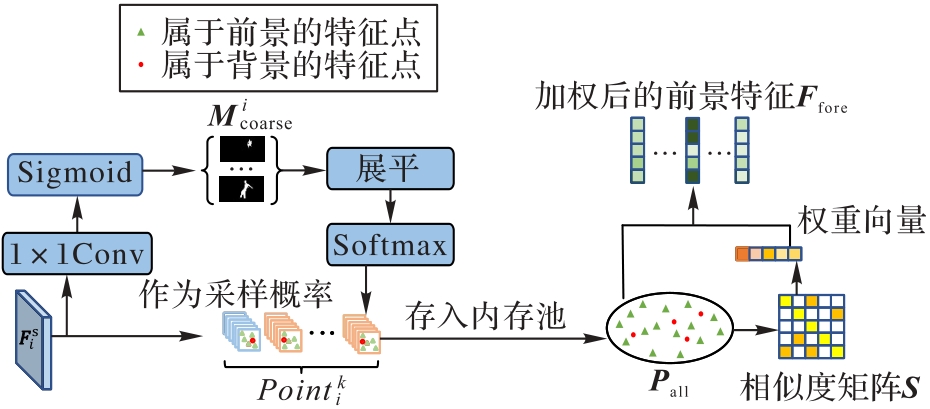
Fig. 3 Foreground feature selecting and voting module

Fig. 4 Mixed attention decoder
| 网络 | 骨干网络 | 光流 | CRF | DAVIS | DAVSOD | VOS | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| F-measure/% | S-measure/% | MAE | F-measure/% | S-measure/% | MAE | F-measure/% | S-measure/% | MAE | ||||
| SCOM[ | — | — | — | 78.30 | 83.20 | 0.048 | 46.40 | 59.90 | 0.220 | 69.00 | 71.20 | 0.162 |
| DLVS[ | — | — | — | 70.80 | 79.40 | 0.061 | 52.10 | 65.70 | 0.129 | 67.50 | 76.00 | 0.099 |
| PDB[ | ResNet50 | √ | √ | 85.50 | 88.20 | 0.028 | 57.20 | 69.80 | 0.116 | 74.20 | 81.80 | 0.078 |
| SSAV[ | ResNet50 | √ | √ | 86.10 | 89.30 | 0.028 | 60.30 | 72.40 | 0.090 | 74.20 | 81.90 | 0.073 |
| STFA[ | ResNet50 | √ | √ | 86.50 | 89.20 | 0.023 | 65.10 | 74.60 | 0.086 | 79.10 | 85.00 | 0.058 |
| CAS[ | ResNet50 | √ | √ | 86.00 | 87.30 | 0.032 | 60.80 | 69.90 | 0.086 | 77.40 | 80.80 | 0.051 |
| RCRNet[ | ResNet50 | √ | √ | 84.80 | 88.60 | 0.027 | 65.30 | 74.10 | 0.087 | 83.30 | 87.30 | 0.051 |
| MGA[ | ResNet50 | √ | √ | 89.20 | 91.20 | 0.022 | 65.60 | 75.10 | 0.081 | 73.50 | 79.20 | 0.075 |
| FSNet[ | ResNet50 | √ | √ | 90.70 | 92.00 | 0.020 | 68.50 | 77.30 | 0.072 | — | — | — |
| DCFNet[ | ResNet101 | × | × | 91.00 | 91.40 | 0.016 | 66.00 | 74.10 | 0.074 | 79.10 | 84.60 | 0.060 |
| PCSA[ | MobilenetV3 | × | × | 88.00 | 90.20 | 0.022 | 65.50 | 74.10 | 0.086 | 74.70 | 82.70 | 0.065 |
| 本文网络 | MobilenetV3 | × | × | 89.70 | 90.90 | 0.018 | 65.80 | 74.00 | 0.080 | 78.20 | 83.80 | 0.062 |
Tab. 1 Performance comparison of different networks on DAVIS, DAVSOD and VOS datasets
| 网络 | 骨干网络 | 光流 | CRF | DAVIS | DAVSOD | VOS | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| F-measure/% | S-measure/% | MAE | F-measure/% | S-measure/% | MAE | F-measure/% | S-measure/% | MAE | ||||
| SCOM[ | — | — | — | 78.30 | 83.20 | 0.048 | 46.40 | 59.90 | 0.220 | 69.00 | 71.20 | 0.162 |
| DLVS[ | — | — | — | 70.80 | 79.40 | 0.061 | 52.10 | 65.70 | 0.129 | 67.50 | 76.00 | 0.099 |
| PDB[ | ResNet50 | √ | √ | 85.50 | 88.20 | 0.028 | 57.20 | 69.80 | 0.116 | 74.20 | 81.80 | 0.078 |
| SSAV[ | ResNet50 | √ | √ | 86.10 | 89.30 | 0.028 | 60.30 | 72.40 | 0.090 | 74.20 | 81.90 | 0.073 |
| STFA[ | ResNet50 | √ | √ | 86.50 | 89.20 | 0.023 | 65.10 | 74.60 | 0.086 | 79.10 | 85.00 | 0.058 |
| CAS[ | ResNet50 | √ | √ | 86.00 | 87.30 | 0.032 | 60.80 | 69.90 | 0.086 | 77.40 | 80.80 | 0.051 |
| RCRNet[ | ResNet50 | √ | √ | 84.80 | 88.60 | 0.027 | 65.30 | 74.10 | 0.087 | 83.30 | 87.30 | 0.051 |
| MGA[ | ResNet50 | √ | √ | 89.20 | 91.20 | 0.022 | 65.60 | 75.10 | 0.081 | 73.50 | 79.20 | 0.075 |
| FSNet[ | ResNet50 | √ | √ | 90.70 | 92.00 | 0.020 | 68.50 | 77.30 | 0.072 | — | — | — |
| DCFNet[ | ResNet101 | × | × | 91.00 | 91.40 | 0.016 | 66.00 | 74.10 | 0.074 | 79.10 | 84.60 | 0.060 |
| PCSA[ | MobilenetV3 | × | × | 88.00 | 90.20 | 0.022 | 65.50 | 74.10 | 0.086 | 74.70 | 82.70 | 0.065 |
| 本文网络 | MobilenetV3 | × | × | 89.70 | 90.90 | 0.018 | 65.80 | 74.00 | 0.080 | 78.20 | 83.80 | 0.062 |
| 网络 | 参数量/106 | 推理时间/s |
|---|---|---|
| SSAV | 81.2 | 0.450 |
| AGNN | 82.3 | 0.550 |
| MGA | 254.0 | 0.290 |
| AnDiff[ | 79.3 | 0.360 |
| DCFNet | 274.0 | 0.036 |
| 本文网络 | 15.6 | 0.026 |
Tab. 2 Comparison of parameter quantity and inference time among different networks
| 网络 | 参数量/106 | 推理时间/s |
|---|---|---|
| SSAV | 81.2 | 0.450 |
| AGNN | 82.3 | 0.550 |
| MGA | 254.0 | 0.290 |
| AnDiff[ | 79.3 | 0.360 |
| DCFNet | 274.0 | 0.036 |
| 本文网络 | 15.6 | 0.026 |

Fig. 5 Visualization comparison of segmentation results by different networks
| 超参数K | F-measure/% | S-measure/% | MAE |
|---|---|---|---|
| 0 | 86.00 | 88.00 | 0.027 |
| 10 | 88.89 | 90.00 | 0.020 |
| 20 | 89.51 | 90.43 | 0.019 |
| 50 | 89.70 | 90.91 | 0.018 |
| 100 | 89.64 | 90.94 | 0.018 |
| 300 | 89.71 | 90.90 | 0.018 |
Tab. 3 Influence of hyper-parameter K on network performance
| 超参数K | F-measure/% | S-measure/% | MAE |
|---|---|---|---|
| 0 | 86.00 | 88.00 | 0.027 |
| 10 | 88.89 | 90.00 | 0.020 |
| 20 | 89.51 | 90.43 | 0.019 |
| 50 | 89.70 | 90.91 | 0.018 |
| 100 | 89.64 | 90.94 | 0.018 |
| 300 | 89.71 | 90.90 | 0.018 |
| 选点方式 | F-measure/% | S-measure/% | MAE |
|---|---|---|---|
| 阈值+等概率采样 | 89.06 | 90.22 | 0.019 |
| 自适应最大池化 | 88.89 | 90.00 | 0.020 |
| Softmax+置信度 | 89.70 | 90.91 | 0.018 |
Tab. 4 Influence of different selection methods on network performance
| 选点方式 | F-measure/% | S-measure/% | MAE |
|---|---|---|---|
| 阈值+等概率采样 | 89.06 | 90.22 | 0.019 |
| 自适应最大池化 | 88.89 | 90.00 | 0.020 |
| Softmax+置信度 | 89.70 | 90.91 | 0.018 |
| 是否进行投票 | F-measure/% | S-measure/% | MAE |
|---|---|---|---|
| 是 | 89.70 | 90.91 | 0.018 |
| 否 | 89.41 | 90.64 | 0.018 |
Tab. 5 Influence of foreground feature voting on network performance
| 是否进行投票 | F-measure/% | S-measure/% | MAE |
|---|---|---|---|
| 是 | 89.70 | 90.91 | 0.018 |
| 否 | 89.41 | 90.64 | 0.018 |
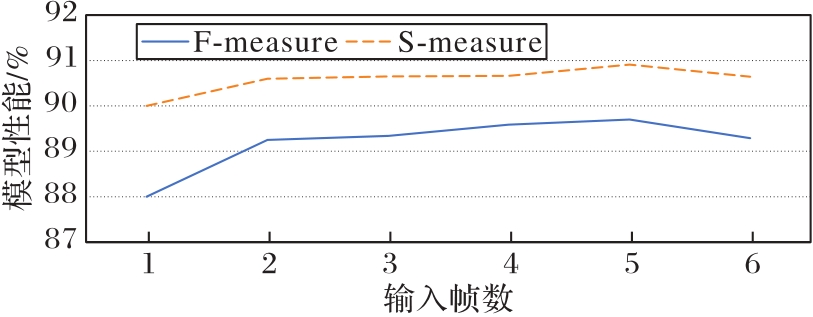
Fig. 6 Influence of input frames on network performance
| 融合方式 | F-measure/% | S-measure/% | MAE |
|---|---|---|---|
| 直接加 | 89.59 | 90.84 | 0.019 |
| 进行拼接 | 89.63 | 90.84 | 0.018 |
| 动态信息融合 | 89.70 | 90.91 | 0.018 |
Tab. 6 Influence of decoder stage feature fusion on network performance
| 融合方式 | F-measure/% | S-measure/% | MAE |
|---|---|---|---|
| 直接加 | 89.59 | 90.84 | 0.019 |
| 进行拼接 | 89.63 | 90.84 | 0.018 |
| 动态信息融合 | 89.70 | 90.91 | 0.018 |
| 1 | TAN M, PANG R, LE Q V. EfficientDet: scalable and efficient object detection [C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 10778-10787. |
| 2 | PAN Y, YAO T, LI H, et al. Video captioning with transferred semantic attributes [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 6504-6512. |
| 3 | JI W, YU S, WU J, et al. Learning calibrated medical image segmentation via multi-rater agreement modeling [C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 12336-12346. |
| 4 | ITTI L. Automatic foveation for video compression using a neurobiological model of visual attention [J]. IEEE Transactions on Image Processing, 2004, 13(10): 1304-1318. |
| 5 | HADIZADEH H, BAJIĆ I V. Saliency-aware video compression [J]. IEEE Transactions on Image Processing, 2014, 23(1): 19-33. |
| 6 | WU H, LI G, LUO X. Weighted attentional blocks for probabilistic object tracking [J]. The Visual Computer, 2014, 30: 229-243. |
| 7 | YAN P, LI G, XIE Y, et al. Semi-supervised video salient object detection using pseudo-labels [C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 7283-7292. |
| 8 | GU Y, WANG L, WANG Z, et al. Pyramid constrained self-attention network for fast video salient object detection [J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2020, 34(7): 10869-10876. |
| 9 | YANG Z, WANG Q, BERTINETTO L, et al. Anchor diffusion for unsupervised video object segmentation [C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 931-940. |
| 10 | YANG S, ZHANG L, QI J, et al. Learning motion-appearance co-attention for zero-shot video object segmentation [C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 1544-1553. |
| 11 | WANG W, LU X, SHEN J, et al. Zero-shot video object segmentation via attentive graph neural networks [C]// Proceedings of the 2019 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2019: 9236-9245. |
| 12 | YANG B, BENDER G, LE Q V, et al. CondConv: conditionally parameterized convolutions for efficient inference [C]// Proceedings of the 33rd International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2019: 1307-1318. |
| 13 | DIBA A, SHARMA V, VAN GOOL L, et al. DynamoNet: dynamic action and motion network [C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 6191-6200. |
| 14 | ZHOU S, ZHANG J, PAN J, et al. Spatio-temporal filter adaptive network for video deblurring [C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 2482-2491. |
| 15 | HE J, DENG Z, QIAO Y. Dynamic multi-scale filters for semantic segmentation [C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 3561-3571. |
| 16 | PANG Y, ZHANG L, ZHAO X, et al. Hierarchical dynamic filtering network for RGB-D salient object detection [C]// Proceedings of the 16th European Conference on Computer Vision. Cham: Springer, 2020: 235-252. |
| 17 | YU S, XIAO J, ZHANG B, et al. Democracy does matter: comprehensive feature mining for co-salient object detection [C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 969-978. |
| 18 | ZHANG M, LIU J, WANG Y, et al. Dynamic context-sensitive filtering network for video salient object detection [C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 1533-1543. |
| 19 | CHEN Y, ZOU W, TANG Y, et al. SCOM: spatiotemporal constrained optimization for salient object detection [J]. IEEE Transactions on Image Processing, 2018, 27(7): 3345-3357. |
| 20 | WANG W, SHEN J, SHAO L. Video salient object detection via fully convolutional networks [J]. IEEE Transactions on Image Processing, 2017, 27(1): 38-49. |
| 21 | SONG H, WANG W, ZHAO S, et al. Pyramid dilated deeper ConvLSTM for video salient object detection [C]// Proceedings of the 15th European Conference on Computer Vision. Cham: Springer, 2018: 715-731. |
| 22 | FAN D-P, WANG W, CHENG M-M, et al. Shifting more attention to video salient object detection [C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 8546-8556. |
| 23 | CHEN C, WANG G, PENG C, et al. Exploring rich and efficient spatial temporal interactions for real-time video salient object detection [J]. IEEE Transactions on Image Processing, 2021, 30: 3995-4007. |
| 24 | JI Y, ZHANG H, JIE Z, et al. CASNet: a cross-attention Siamese network for video salient object detection [J]. IEEE Transactions on Neural Networks and Learning Systems, 2020, 32(6): 2676-2690. |
| 25 | LI H, CHEN G, LI G, et al. Motion guided attention for video salient object detection [C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 7273-7282. |
| 26 | JI G-P, FU K, WU Z, et al. Full-duplex strategy for video object segmentation [C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 4902-4913. |
| [1] | Xingyao YANG, Yu CHEN, Jiong YU, Zulian ZHANG, Jiaying CHEN, Dongxiao WANG. Recommendation model combining self-features and contrastive learning [J]. Journal of Computer Applications, 2024, 44(9): 2704-2710. |
| [2] | Shunyong LI, Shiyi LI, Rui XU, Xingwang ZHAO. Incomplete multi-view clustering algorithm based on self-attention fusion [J]. Journal of Computer Applications, 2024, 44(9): 2696-2703. |
| [3] | Yunchuan HUANG, Yongquan JIANG, Juntao HUANG, Yan YANG. Molecular toxicity prediction based on meta graph isomorphism network [J]. Journal of Computer Applications, 2024, 44(9): 2964-2969. |
| [4] | Jing QIN, Zhiguang QIN, Fali LI, Yueheng PENG. Diagnosis of major depressive disorder based on probabilistic sparse self-attention neural network [J]. Journal of Computer Applications, 2024, 44(9): 2970-2974. |
| [5] | Xiyuan WANG, Zhancheng ZHANG, Shaokang XU, Baocheng ZHANG, Xiaoqing LUO, Fuyuan HU. Unsupervised cross-domain transfer network for 3D/2D registration in surgical navigation [J]. Journal of Computer Applications, 2024, 44(9): 2911-2918. |
| [6] | Liting LI, Bei HUA, Ruozhou HE, Kuang XU. Multivariate time series prediction model based on decoupled attention mechanism [J]. Journal of Computer Applications, 2024, 44(9): 2732-2738. |
| [7] | Yexin PAN, Zhe YANG. Optimization model for small object detection based on multi-level feature bidirectional fusion [J]. Journal of Computer Applications, 2024, 44(9): 2871-2877. |
| [8] | Zhiqiang ZHAO, Peihong MA, Xinhong HEI. Crowd counting method based on dual attention mechanism [J]. Journal of Computer Applications, 2024, 44(9): 2886-2892. |
| [9] | Kaipeng XUE, Tao XU, Chunjie LIAO. Multimodal sentiment analysis network with self-supervision and multi-layer cross attention [J]. Journal of Computer Applications, 2024, 44(8): 2387-2392. |
| [10] | Pengqi GAO, Heming HUANG, Yonghong FAN. Fusion of coordinate and multi-head attention mechanisms for interactive speech emotion recognition [J]. Journal of Computer Applications, 2024, 44(8): 2400-2406. |
| [11] | Yuhan LIU, Genlin JI, Hongping ZHANG. Video pedestrian anomaly detection method based on skeleton graph and mixed attention [J]. Journal of Computer Applications, 2024, 44(8): 2551-2557. |
| [12] | Zhonghua LI, Yunqi BAI, Xuejin WANG, Leilei HUANG, Chujun LIN, Shiyu LIAO. Low illumination face detection based on image enhancement [J]. Journal of Computer Applications, 2024, 44(8): 2588-2594. |
| [13] | Shangbin MO, Wenjun WANG, Ling DONG, Shengxiang GAO, Zhengtao YU. Single-channel speech enhancement based on multi-channel information aggregation and collaborative decoding [J]. Journal of Computer Applications, 2024, 44(8): 2611-2617. |
| [14] | Yanjie GU, Yingjun ZHANG, Xiaoqian LIU, Wei ZHOU, Wei SUN. Traffic flow forecasting via spatial-temporal multi-graph fusion [J]. Journal of Computer Applications, 2024, 44(8): 2618-2625. |
| [15] | Qianhong SHI, Yan YANG, Yongquan JIANG, Xiaocao OUYANG, Wubo FAN, Qiang CHEN, Tao JIANG, Yuan LI. Multi-granularity abrupt change fitting network for air quality prediction [J]. Journal of Computer Applications, 2024, 44(8): 2643-2650. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||