


Journal of Computer Applications ›› 2024, Vol. 44 ›› Issue (9): 2886-2892.DOI: 10.11772/j.issn.1001-9081.2023091269
• Multimedia computing and computer simulation • Previous Articles Next Articles
Zhiqiang ZHAO1,2( ), Peihong MA1, Xinhong HEI1,2
), Peihong MA1, Xinhong HEI1,2
Received:2023-09-18
Revised:2023-12-12
Accepted:2023-12-15
Online:2024-03-21
Published:2024-09-10
Contact:
Zhiqiang ZHAO
About author:MA Peihong, born in 1998, M. S. candidate. Her research interests include computer vision.Supported by:
赵志强1,2(), 马培红1, 黑新宏1,2
通讯作者:
赵志强
作者简介:马培红(1998—),女,河南郑州人,硕士研究生,主要研究方向:计算机视觉基金资助:CLC Number:
Zhiqiang ZHAO, Peihong MA, Xinhong HEI. Crowd counting method based on dual attention mechanism[J]. Journal of Computer Applications, 2024, 44(9): 2886-2892.
赵志强, 马培红, 黑新宏. 基于双重注意力机制的人群计数方法[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2886-2892.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2023091269
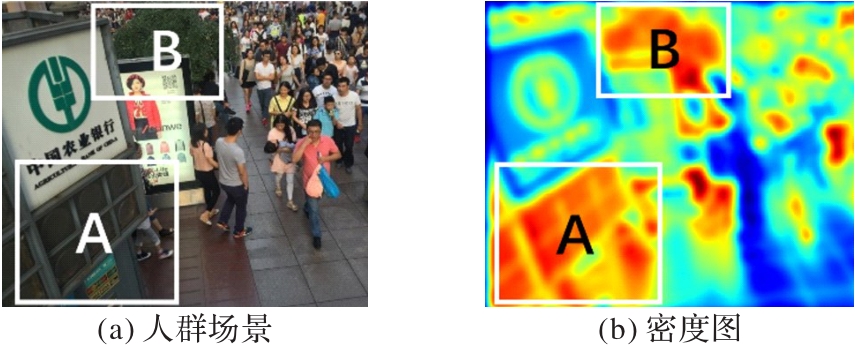
Fig. 1 Influence of complex background on crowd counting

Fig. 2 Network structure of DA-DCCNN
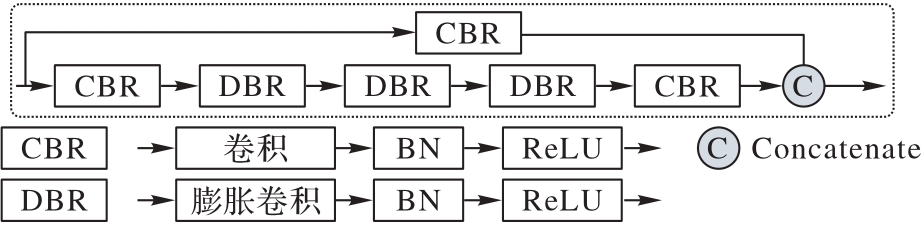
Fig. 3 Structure of DCM

Fig. 4 Structure of Head network
| 数据集 | 样本数 | 标注点数 | 分辨率 | 人群规模 |
|---|---|---|---|---|
| ShanghaiTech | 1 198 | 330 165 | 768×1 024 | 9~578 |
| UCF_CC_50 | 50 | 63 075 | 2 101×2 888 | 94~4 542 |
| UCF-QNRF | 1 535 | >125×104 | 2 013×2 902 | 49~12 865 |
Tab. 1 Detail information of three datasets
| 数据集 | 样本数 | 标注点数 | 分辨率 | 人群规模 |
|---|---|---|---|---|
| ShanghaiTech | 1 198 | 330 165 | 768×1 024 | 9~578 |
| UCF_CC_50 | 50 | 63 075 | 2 101×2 888 | 94~4 542 |
| UCF-QNRF | 1 535 | >125×104 | 2 013×2 902 | 49~12 865 |
| 数据集 | 方法 | MAE | RMSE |
|---|---|---|---|
| ShanghaiTech | HA-CNN | 62.9 | 94.9 |
| ADCrowdNet | 55.4 | 97.9 | |
| PCC Net | 73.5 | 124.0 | |
| LSC-CNN | 66.4 | 117.0 | |
| EPA | 60.9 | 91.6 | |
| Lw-Count | 69.7 | 100.5 | |
| CG-DRCN | 60.2 | 94.0 | |
| DA-DCCNN | 49.6 | 87.1 | |
| UCF_CC_50 | ACSCP | 291.0 | 404.6 |
| MRA-CNN | 240.8 | 352.6 | |
| RANet | 239.8 | 319.4 | |
| MBTTBF-SCFB | 233.1 | 300.9 | |
| PCC Net | 240.0 | 315.5 | |
| LSC-CNN | 225.6 | 302.7 | |
| SDS-CNN | 229.4 | 325.6 | |
| EPA | 250.1 | 342.7 | |
| Lw-Count | 239.3 | 307.6 | |
| HANet | 195.2 | 268.6 | |
| DA-DCCNN | 165.3 | 227.7 | |
| UCF-QNRF | RANet | 111.0 | 190.0 |
| MBTTBF-SCFB | 97.5 | 165.2 | |
| PCC Net | 246.4 | 247.1 | |
| LSC-CNN | 120.5 | 218.2 | |
| KDMG | 99.5 | 173.0 | |
| SDS-CNN | 115.2 | 175.7 | |
| Lw-Count | 149.7 | 238.4 | |
| HANet | 99.1 | 159.2 | |
| DA-DCCNN | 93.3 | 160.2 |
Tab. 2 Performance comparison on three datasets among different methods
| 数据集 | 方法 | MAE | RMSE |
|---|---|---|---|
| ShanghaiTech | HA-CNN | 62.9 | 94.9 |
| ADCrowdNet | 55.4 | 97.9 | |
| PCC Net | 73.5 | 124.0 | |
| LSC-CNN | 66.4 | 117.0 | |
| EPA | 60.9 | 91.6 | |
| Lw-Count | 69.7 | 100.5 | |
| CG-DRCN | 60.2 | 94.0 | |
| DA-DCCNN | 49.6 | 87.1 | |
| UCF_CC_50 | ACSCP | 291.0 | 404.6 |
| MRA-CNN | 240.8 | 352.6 | |
| RANet | 239.8 | 319.4 | |
| MBTTBF-SCFB | 233.1 | 300.9 | |
| PCC Net | 240.0 | 315.5 | |
| LSC-CNN | 225.6 | 302.7 | |
| SDS-CNN | 229.4 | 325.6 | |
| EPA | 250.1 | 342.7 | |
| Lw-Count | 239.3 | 307.6 | |
| HANet | 195.2 | 268.6 | |
| DA-DCCNN | 165.3 | 227.7 | |
| UCF-QNRF | RANet | 111.0 | 190.0 |
| MBTTBF-SCFB | 97.5 | 165.2 | |
| PCC Net | 246.4 | 247.1 | |
| LSC-CNN | 120.5 | 218.2 | |
| KDMG | 99.5 | 173.0 | |
| SDS-CNN | 115.2 | 175.7 | |
| Lw-Count | 149.7 | 238.4 | |
| HANet | 99.1 | 159.2 | |
| DA-DCCNN | 93.3 | 160.2 |

Fig. 5 Visualization examples of predicted density map for DA-DCCNN
| 组合序号 | 方法 | MAE | RMSE |
|---|---|---|---|
| ① | VGG | 81.2 | 119.4 |
| ② | VGG+DCM | 60.7 | 95.4 |
| ③ | VGG+CAM | 79.0 | 114.9 |
| ④ | VGG+SAM | 75.3 | 109.7 |
| ⑤ | VGG+DAM | 69.1 | 98.1 |
| ⑥ | VGG+DCM+CAM | 58.3 | 92.1 |
| ⑦ | VGG+DCM+SAM | 53.2 | 90.8 |
| ⑧ | DA-DCCNN | 49.6 | 87.1 |
Tab. 3 Experimental results over combinations of various modules
| 组合序号 | 方法 | MAE | RMSE |
|---|---|---|---|
| ① | VGG | 81.2 | 119.4 |
| ② | VGG+DCM | 60.7 | 95.4 |
| ③ | VGG+CAM | 79.0 | 114.9 |
| ④ | VGG+SAM | 75.3 | 109.7 |
| ⑤ | VGG+DAM | 69.1 | 98.1 |
| ⑥ | VGG+DCM+CAM | 58.3 | 92.1 |
| ⑦ | VGG+DCM+SAM | 53.2 | 90.8 |
| ⑧ | DA-DCCNN | 49.6 | 87.1 |
| λ | MAE | RMSE | λ | MAE | RMSE |
|---|---|---|---|---|---|
| 0 | 54.3 | 94.2 | 10-4 | 49.6 | 87.1 |
| 10-5 | 53.2 | 92.1 | 10-3 | 50.1 | 90.1 |
Tab. 4 Influence of different λ on performance of DA-DCCNN
| λ | MAE | RMSE | λ | MAE | RMSE |
|---|---|---|---|---|---|
| 0 | 54.3 | 94.2 | 10-4 | 49.6 | 87.1 |
| 10-5 | 53.2 | 92.1 | 10-3 | 50.1 | 90.1 |
| σ | MAE | RMSE |
|---|---|---|
| 0.001 | 73.4 | 112.6 |
| 0.010 | 56.4 | 96.2 |
| 0.100 | 52.8 | 90.1 |
| 0.200 | 49.6 | 87.1 |
| 0.300 | 51.3 | 90.7 |
Tab. 5 Influence of different σ on performance of DA-DCCNN
| σ | MAE | RMSE |
|---|---|---|
| 0.001 | 73.4 | 112.6 |
| 0.010 | 56.4 | 96.2 |
| 0.100 | 52.8 | 90.1 |
| 0.200 | 49.6 | 87.1 |
| 0.300 | 51.3 | 90.7 |
| t | MAE | RMSE |
|---|---|---|
| 0.000 1 | 54.6 | 97.3 |
| 0.001 0 | 49.6 | 87.1 |
| 0.005 0 | 53.8 | 89.5 |
| 0.010 0 | 57.7 | 96.4 |
| 0.100 0 | 58.3 | 95.6 |
Tab. 6 Influence of different t on performance of DA-DCCNN
| t | MAE | RMSE |
|---|---|---|
| 0.000 1 | 54.6 | 97.3 |
| 0.001 0 | 49.6 | 87.1 |
| 0.005 0 | 53.8 | 89.5 |
| 0.010 0 | 57.7 | 96.4 |
| 0.100 0 | 58.3 | 95.6 |
| 1 | 余鹰,朱慧琳,钱进,等. 基于深度学习的人群计数研究综述[J]. 计算机研究与发展, 2021, 58(12):2724-2747. |
| YU Y, ZHU H L, QIAN J, et al. Survey on deep learning based crowd counting [J]. Journal of Computer Research and Development, 2021, 58(12): 2724-2747. | |
| 2 | KHAN M A, MENOUAR H, HAMILA R. Revisiting crowd counting: state-of-the-art, trends, and future perspectives [J]. Image and Vision Computing, 2023, 129: 104597. |
| 3 | 覃勋辉, 王修飞, 周曦,等. 多种人群密度场景下的人群计数[J]. 中国图象图形学报, 2013, 18(4): 392-398. |
| QIN X H, WANG X F, ZHOU X, et al. Counting people in various crowed density scenes using support vector regression [J]. Journal of Image and Graphics, 2013, 18(4): 392-398. | |
| 4 | RYAN D, DENMAN S, SRIDHARAN S, et al. An evaluation of crowd counting methods, features and regression models [J]. Computer Vision and Image Understanding, 2015, 130: 1-17. |
| 5 | KOK V J, LIM M K, CHAN C S. Crowd behavior analysis: a review where physics meets biology [J]. Neurocomputing, 2016, 177: 342-362. |
| 6 | POUYANFAR S, SADIQ S, YAN Y, et al. A survey on deep learning: algorithms, techniques, and applications [J]. ACM Computing Surveys, 2018, 51(5): No. 92. |
| 7 | ALZUBAIDI L, ZHANG J, HUMAIDI A J, et al. Review of deep learning: concepts, CNN architectures, challenges, applications, future directions [J]. Journal of Big Data, 2021, 8(1): No. 53. |
| 8 | PTAK B, PIECZYŃSKI D, PIECHOCKI M, et al. On-board crowd counting and density estimation using low altitude unmanned aerial vehicles: looking beyond beating the benchmark [J]. Remote Sensing, 2022, 14(10): 2288. |
| 9 | DELUSSU R, PUTZU L, FUMERA G. Scene-specific crowd counting using synthetic training images [J]. Pattern Recognition, 2022, 124: 108484. |
| 10 | FU M, XU P, LI X, et al. Fast crowd density estimation with convolutional neural networks [J]. Engineering Applications of Artificial Intelligence, 2015, 43: 81-88. |
| 11 | STEWART R, ANDRILUKA M, NG A Y. End-to-end people detection in crowded scenes [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 2325-2333. |
| 12 | LI W, LI H, QU Q, et al. HeadNet: an end-to-end adaptive relational network for head detection [J]. IEEE Transactions on Circuits and Systems for Video Technology, 2020, 30(2): 482-494. |
| 13 | ZHANG Y, ZHOU D, CHEN S, et al. Single-image crowd counting via multi-column convolutional neural network [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 589-597. |
| 14 | LI Y, ZHANG X, CHEN D. CSRNet: dilated convolutional neural networks for understanding the highly congested scenes[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 1091-1100. |
| 15 | CAO X, WANG Z, ZHAO Y, et al. Scale aggregation network for accurate and efficient crowd counting [C]// Proceedings of the 15th European Conference on Computer Vision. Cham: Springer, 2018: 757-773. |
| 16 | VARIOR R R, SHUAI B, TIGHE J, et al. Multi-scale attention network for crowd counting [EB/OL]. [2023-02-19]. . |
| 17 | SINSAGI V A, PATEL V M. HA-CNN: hierarchical attention-based crowd counting network [J]. IEEE Transactions on Image Processing, 2019, 29: 323-335. |
| 18 | LIU N, LONG Y, ZOU C, et al. ADCrowdNet: an attention-injective deformable convolutional network for crowd understanding[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 3220-3229. |
| 19 | SHANG C, AI H, BAI B. End-to-end crowd counting via joint learning local and global count [C]// Proceedings of the 2016 IEEE International Conference on Image Processing. Piscataway: IEEE, 2016: 1215-1219. |
| 20 | LIU W, SALZMANN M, FUA P. Context-aware crowd counting[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 5094-5103. |
| 21 | SHI M, YANG Z, XU C, et al. Revisiting perspective information for efficient crowd counting [C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 7271-7280. |
| 22 | YAN Z, ZHANG R, ZHANG H, et al. Crowd counting via perspective-guided fractional-dilation convolution [J]. IEEE Transactions on Multimedia, 2021, 24: 2633-2647. |
| 23 | WANG X, LV R, ZHAO Y, et al. Multi-scale context aggregation network with attention-guided for crowd counting [C]// Proceedings of the 2020 15th IEEE International Conference on Signal Processing. Piscataway: IEEE, 2020, 1: 240-245. |
| 24 | ZHANG C, LI H, WANG X, et al. Cross-scene crowd counting via deep convolutional neural networks [C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2015: 833-841. |
| 25 | IDREES H, TAYYAB M, ATHREY K, et al. Composition loss for counting, density map estimation and localization in dense crowds [C]// Proceedings of the 15th European Conference on Computer Vision. Cham: Springer, 2018: 544-559. |
| 26 | GAO J, WANG Q, LI X. PCC Net: perspective crowd counting via spatial convolutional network [J]. IEEE Transactions on Circuits and Systems for Video Technology, 2020, 30(10): 3846-3498. |
| 27 | SAM D B, PERI S V, SUNDARARAMAN M N, et al. Locate, size and count: accurately resolving people in dense crowds via detection [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021, 43(8): 2739-2751. |
| 28 | YANG Y, LI G, DU D, et al. Embedding perspective analysis into multi-column convolutional neural network for crow counting [J]. IEEE Transactions on Image Processing, 2020, 30: 1395-1407. |
| 29 | LIU Y, GAO G, SHI H, et al. Lw-Count: an effective lightweight encoding-decoding crowd counting network [J]. IEEE Transactions on Circuits and Systems for Video Technology, 2022, 32(10): 6821-6834. |
| 30 | SINDAGI V A, YASARLA R, PATEL V M. JHU-CROWD++: large-scale crowd counting dataset and a benchmark method [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44(5): 2594-2609. |
| 31 | SHEN Z, XU Y, NI B, et al. Crowd counting via adversarial cross-scale consistency pursuit [C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 5245-5254. |
| 32 | ZHANG Y, ZHOU C, CHANG F, et al. Multi-resolution attention convolutional neural network for crowd counting [J]. Neurocomputing, 2019, 329: 144-152. |
| 33 | SINDAGI V A, PATEL V M. Multi-level bottom-top and top-bottom feature fusion for crowd counting [C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 1002-1012. |
| 34 | WANG F, SANG J, WU Z, et al. Hybrid attention network based on progressive embedding scale-context for crowd counting [J]. Information Sciences, 2022, 591: 306-318. |
| 35 | ZHANG A, SHEN J, XIAO Z, et al. Relational attention network for crowd counting [C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 6787-6796. |
| 36 | KHAN S D, BASALAMAH S. Sparse to dense scale prediction for crowd counting in high density crowds [J]. Arabian Journal of Science and Engineering, 2021, 46: 3051-3065. |
| 37 | WAN J, WANG Q, CHAN A B. Kernel-based density map generation for dense object counting [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44(3): 1357-1370. |
| [1] | Chunxue ZHANG, Liqing QIU, Cheng’ai SUN, Caixia JING. Purchase behavior prediction model based on two-stage dynamic interest recognition [J]. Journal of Computer Applications, 2024, 44(8): 2365-2371. |
| [2] | Wei LI, Xiaorong ZHANG, Peng CHEN, Qing LI, Changqing ZHANG. Crowd counting algorithm with multi-scale fusion based on normal inverse Gamma distribution [J]. Journal of Computer Applications, 2024, 44(7): 2243-2249. |
| [3] | Yangyi GAO, Tao LEI, Xiaogang DU, Suiyong LI, Yingbo WANG, Chongdan MIN. Crowd counting and locating method based on pixel distance map and four-dimensional dynamic convolutional network [J]. Journal of Computer Applications, 2024, 44(7): 2233-2242. |
| [4] | Jun FENG, Jiankang BI, Yiru HUO, Jiakuan LI. PIPNet: lightweight asphalt pavement crack image segmentation network [J]. Journal of Computer Applications, 2024, 44(5): 1520-1526. |
| [5] | Xinyuan YOU, Heng WANG. Monaural speech enhancement based on gated dilated convolutional recurrent network [J]. Journal of Computer Applications, 2024, 44(4): 1317-1324. |
| [6] | Lin WANG, Jingliang LIU, Wuwei WANG. Small target detection method in UAV images based on fusion of dilated convolution and Transformer [J]. Journal of Computer Applications, 2024, 44(11): 3595-3602. |
| [7] | Yu ZENG, Yang ZHANG, Shang ZENG, Maoli FU, Qixue HE, Linlong ZENG. Time series prediction algorithm based on multi-scale gated dilated convolutional network [J]. Journal of Computer Applications, 2024, 44(11): 3427-3434. |
| [8] | Meijia LIANG, Xinwu LIU, Xiaopeng HU. Small target detection algorithm for train operating environment image based on improved YOLOv3 [J]. Journal of Computer Applications, 2023, 43(8): 2611-2618. |
| [9] | Hui LIU, Linyu ZHANG, Fugang WANG, Rujin HE. Object detection algorithm based on attention mechanism and context information [J]. Journal of Computer Applications, 2023, 43(5): 1557-1564. |
| [10] | Jiadong LI, Danpu ZHANG, Yaqiong FAN, Jianfeng YANG. Lightweight ship target detection algorithm based on improved YOLOv5 [J]. Journal of Computer Applications, 2023, 43(3): 923-929. |
| [11] | Yi ZHANG, Yongrong SUN, Kedong ZHAO, Hua LI, Qinghua ZENG. Joint detection and tracking algorithm of target in aerial refueling scenes [J]. Journal of Computer Applications, 2022, 42(9): 2893-2899. |
| [12] | Juan WANG, Xuliang YUAN, Minghu WU, Liquan GUO, Zishan LIU. Real-time semantic segmentation method based on squeezing and refining network [J]. Journal of Computer Applications, 2022, 42(7): 1993-2000. |
| [13] | Tingwei QIN, Pengcheng ZHAO, Pinle QIN, Jianchao ZENG, Rui CHAI, Yongqi HUANG. Point cloud registration algorithm based on residual attention mechanism [J]. Journal of Computer Applications, 2022, 42(7): 2184-2191. |
| [14] | Xiaopeng YU, Ruhan HE, Jin HUANG, Junjie ZHANG, Xinrong HU. Knowledge graph embedding model based on improved Inception structure [J]. Journal of Computer Applications, 2022, 42(4): 1065-1071. |
| [15] | Pengwei LIU, Yuan GAO, Pinle QIN, Zhe YIN, Lifang WANG. Medical MRI image super-resolution reconstruction based on multi-receptive field generative adversarial network [J]. Journal of Computer Applications, 2022, 42(3): 938-945. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||