


Journal of Computer Applications ›› 2024, Vol. 44 ›› Issue (10): 3067-3073.DOI: 10.11772/j.issn.1001-9081.2023101407
• Artificial intelligence • Previous Articles Next Articles
Received:2023-10-20
Revised:2024-02-19
Accepted:2024-02-21
Online:2024-10-15
Published:2024-10-10
Contact:
Yangsen ZHANG
About author:JIANG Yushan, born in 1999, M. S. candidate. Her research interests include natural language processing, fact-checking.
Supported by:
姜雨杉, 张仰森( )
)
通讯作者:
张仰森
作者简介:姜雨杉(1999—),女,黑龙江黑河人,硕士研究生,CCF会员,主要研究方向:自然语言处理、事实核查基金资助:CLC Number:
Yushan JIANG, Yangsen ZHANG. Large language model-driven stance-aware fact-checking[J]. Journal of Computer Applications, 2024, 44(10): 3067-3073.
姜雨杉, 张仰森. 大语言模型驱动的立场感知事实核查[J]. 《计算机应用》唯一官方网站, 2024, 44(10): 3067-3073.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2023101407

Fig. 1 LLM-SA framework structure
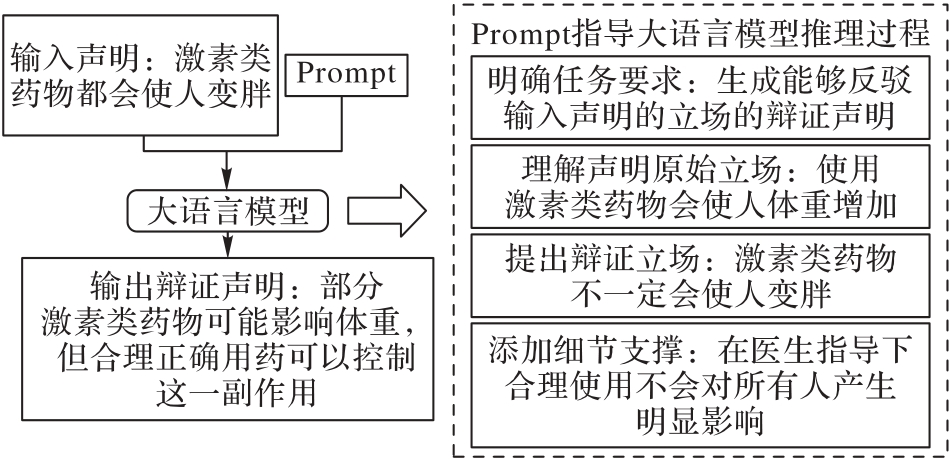
Fig. 2 Process of dialectical claim generation
| 数据划分 | 支持(SUP) | 反对(REF) | 证据不足(NEI) | 总数 |
|---|---|---|---|---|
| 总数 | 3 543 | 1 442 | 10 020 | |
| 训练集 | 2 877 | 776 | 88 052 | |
| 验证集 | 333 | 333 | 333 | 999 |
| 测试集 | 333 | 333 | 333 | 999 |
Tab. 1 Description of datasets
| 数据划分 | 支持(SUP) | 反对(REF) | 证据不足(NEI) | 总数 |
|---|---|---|---|---|
| 总数 | 3 543 | 1 442 | 10 020 | |
| 训练集 | 2 877 | 776 | 88 052 | |
| 验证集 | 333 | 333 | 333 | 999 |
| 测试集 | 333 | 333 | 333 | 999 |
| 参数 | 取值 | 参数 | 取值 |
|---|---|---|---|
| Batch Size | 32 | Pad_size | 512 |
| Learning rate | 5×10-5 | require_improvement | 1 000 |
| Num_epochs | 10 | Optimizer | AdamW |
Tab. 2 Experimental parameters setting
| 参数 | 取值 | 参数 | 取值 |
|---|---|---|---|
| Batch Size | 32 | Pad_size | 512 |
| Learning rate | 5×10-5 | require_improvement | 1 000 |
| Num_epochs | 10 | Optimizer | AdamW |
| 模型 | 验证集 | 测试集 | ||
|---|---|---|---|---|
| Micro F1 | Macro F1 | Micro F1 | Macro F1 | |
| ReRead | 71.79 | 69.98 | 71.24 | 69.52 |
| DeClarE | 69.72 | 68.81 | 70.26 | 69.59 |
| MAC | 67.97 | 66.63 | 68.77 | 67.70 |
| LisT5 | 70.57 | 68.96 | 70.62 | 69.76 |
| BERT | 72.07 | 70.80 | 70.97 | 69.57 |
| 本文模型 | 74.23 | 72.96 | 74.49 | 73.47 |
Tab. 3 Experimental result comparison of different models
| 模型 | 验证集 | 测试集 | ||
|---|---|---|---|---|
| Micro F1 | Macro F1 | Micro F1 | Macro F1 | |
| ReRead | 71.79 | 69.98 | 71.24 | 69.52 |
| DeClarE | 69.72 | 68.81 | 70.26 | 69.59 |
| MAC | 67.97 | 66.63 | 68.77 | 67.70 |
| LisT5 | 70.57 | 68.96 | 70.62 | 69.76 |
| BERT | 72.07 | 70.80 | 70.97 | 69.57 |
| 本文模型 | 74.23 | 72.96 | 74.49 | 73.47 |
| 模型 | 证据类型 | 抽取的证据 |
|---|---|---|
| BERT | 这个孩子白天夜里偷着玩手机,重度用眼,导致‘视网膜黄斑病变’从而失明。 | |
| 近日,一则“儿童白天黑夜玩手机重度用眼,导致视网膜黄斑变性从而失明”的消息在朋友圈疯传。 | ||
| 一条“女孩长时间玩手机导致视网膜黄斑病变从而失明”的消息在朋友圈热传。 | ||
| 而且黄斑病变是否会引发失明,还要看黄斑病变发展到什么程度。 | ||
| 一条“女孩长时间玩手机导致视网膜黄斑病变,从而 | ||
| 正文新闻专题正文:女孩玩手机导致视网膜黄斑病变? | ||
| LLM-SA | 正向证据 | 这个孩子白天夜里偷着玩手机,重度用眼,导致‘视网膜黄斑病变’从而失明。 |
| 近日,一则“儿童白天黑夜玩手机重度用眼,导致视网膜黄斑变性从而失明”的消息在朋友圈疯传。 | ||
| 一条“女孩长时间玩手机导致视网膜黄斑病变从而失明”的消息在朋友圈热传。 | ||
| 反向证据 | 而且黄斑病变是否会引发失明,还要看黄斑病变发展到什么程度。 | |
| 北京大学人民医院眼科主任医师于文贞在接受媒体采访时表示,在临床上自己尚未见到一例因为看手机而失明的患者。 | ||
| 事实上,引起视网膜黄斑病变的因素有很多,与长时间玩手机并无必然联系。 |
Tab. 4 Evidence extracted by different models
| 模型 | 证据类型 | 抽取的证据 |
|---|---|---|
| BERT | 这个孩子白天夜里偷着玩手机,重度用眼,导致‘视网膜黄斑病变’从而失明。 | |
| 近日,一则“儿童白天黑夜玩手机重度用眼,导致视网膜黄斑变性从而失明”的消息在朋友圈疯传。 | ||
| 一条“女孩长时间玩手机导致视网膜黄斑病变从而失明”的消息在朋友圈热传。 | ||
| 而且黄斑病变是否会引发失明,还要看黄斑病变发展到什么程度。 | ||
| 一条“女孩长时间玩手机导致视网膜黄斑病变,从而 | ||
| 正文新闻专题正文:女孩玩手机导致视网膜黄斑病变? | ||
| LLM-SA | 正向证据 | 这个孩子白天夜里偷着玩手机,重度用眼,导致‘视网膜黄斑病变’从而失明。 |
| 近日,一则“儿童白天黑夜玩手机重度用眼,导致视网膜黄斑变性从而失明”的消息在朋友圈疯传。 | ||
| 一条“女孩长时间玩手机导致视网膜黄斑病变从而失明”的消息在朋友圈热传。 | ||
| 反向证据 | 而且黄斑病变是否会引发失明,还要看黄斑病变发展到什么程度。 | |
| 北京大学人民医院眼科主任医师于文贞在接受媒体采访时表示,在临床上自己尚未见到一例因为看手机而失明的患者。 | ||
| 事实上,引起视网膜黄斑病变的因素有很多,与长时间玩手机并无必然联系。 |
| 模型 | 验证集 | |
|---|---|---|
| Micro F1 | Macro F1 | |
| 本文模型 | 74.23 | 72.96 |
| -Content | 72.38 | 71.74 |
| -BERT | 73.81 | 72.64 |
| -Attention | 73.37 | 71.69 |
Tab. 5 Results of ablation experiments
| 模型 | 验证集 | |
|---|---|---|
| Micro F1 | Macro F1 | |
| 本文模型 | 74.23 | 72.96 |
| -Content | 72.38 | 71.74 |
| -BERT | 73.81 | 72.64 |
| -Attention | 73.37 | 71.69 |
| 1 | GUO Z, SCHLICHTKRULL M, VLACHOS A. A survey on automated fact-checking[J]. Transactions of the Association for Computational Linguistics, 2022, 10: 178-206. |
| 2 | AMAZEEN M A. Journalistic interventions: the structural factors affecting the global emergence of fact-checking[J]. Journalism, 2020, 21(1): 95-111. |
| 3 | ZHOU X, ZAFARANI R. A survey of fake news: fundamental theories, detection methods, and opportunities[J]. ACM Computing Surveys, 2020, 53(5): Article No. 109. |
| 4 | DIAS N, SIPPITT A. Researching fact checking: present limitations and future opportunities[J]. The Political Quarterly, 2020, 91(3): 605-613. |
| 5 | HARDALOV M, ARORA A, NAKOV P, et al. A survey on stance detection for mis- and disinformation identification[C]// Finding of the Association for Computational Linguistics: NAACL 2022. Stroudsburg: ACL, 2022: 1259-1277. |
| 6 | DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional transformers for language understanding[C] // Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Stroudsburg: ACL, 2018: 4171-4186. |
| 7 | FLORIDI L, CHIRIATTI M. GPT-3: its nature, scope, limits, and consequences[J]. Minds and Machines, 2020, 30: 681-694. |
| 8 | ZHOU Y, MURESANU A I, HAN Z, et al. Large language models are human-level prompt engineers [EB/OL]. [2023-09-29]. . |
| 9 | THORNE J, VLACHOS A, CHRISTODOULOPOULOS C, et al. FEVER: a large-scale dataset for fact extraction and verification[C]// Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg: ACL, 2018:809-819. |
| 10 | HU X, GUO Z, WU G, et al. CHEF: a pilot Chinese dataset for evidence-based fact-checking[C]// Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg: ACL, 2022: 3362-3376. |
| 11 | HU X, HONG Z, GUO Z, et al. Read it twice: towards faithfully interpretable fact verification by revisiting evidence[C]// Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2023: 2319-2323. |
| 12 | SOLEIMANI A, MONZ C, WORRING M. BERT for evidence retrieval and claim verification[C]// Proceedings of the 42nd European Conference on IR Research. Cham: Springer, 2020: 359-366. |
| 13 | JIANG K, PRADEEP R, LIN J. Exploring listwise evidence reasoning with T5 for fact verification[C]// Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 2: Short Papers). Stroudsburg: ACL, 2021: 402-410. |
| 14 | FAJCIK M, MOTLICEK P, SMRZ P. Claim-Dissector: an interpretable fact-checking system with joint re-ranking and veracity prediction[C]// Proceedings of the 2023 Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2023: 10184-10205. |
| 15 | KOTONYA N, TONI F. Explainable automated fact-checking: a survey[C]// Proceedings of the 28th International Conference on Computational Linguistics.[S.l.]: International Committee on Computational Linguistics, 2020: 5430-5443. |
| 16 | RAY P P. ChatGPT: a comprehensive review on background, applications, key challenges, bias, ethics, limitations and future scope[J]. Internet of Things and Cyber-Physical Systems, 2023, 3:121-154. |
| 17 | LIU P, YUAN W, FU J, et al. Pre-train, prompt, and predict: a systematic survey of prompting methods in natural language processing[J]. ACM Computing Surveys, 2023, 55(9): Article No. 195. |
| 18 | KUMARA P, SAHU S K. SIM-BERT: speech intelligence model using NLP-BERT with improved accuracy[M]// Artificial Intelligence and Speech Technology. [S.l.]: CRC Press, 2021: 439. |
| 19 | 刘玮, 彭鑫, 李超, 等. 立场分析研究综述[J]. 中文信息学报, 2020, 34(12): 1-8. |
| LIU W, PENG X, LI C, et al. A survey on stance detection[J]. Journal of Chinese Information Processing, 2020, 34(12): 1-8. | |
| 20 | SHENG Q, CAO J, ZHANG X, et al. Zoom out and observe: news environment perception for fake news detection[C]// Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2022: 4543-4556. |
| 21 | BEKOULIS G, PAPAGIANNOPOULOU C, DELIGIANNIS N. A review on fact extraction and verification[J]. ACM Computing Surveys, 2021, 55(1): Article No. 12. |
| 22 | WANG X, CHEN G, QIAN G, et al. Large-scale multi-modal pre-trained models: a comprehensive survey[J]. Machine Intelligence Research, 2023, 20: 447-482. |
| 23 | LI J, WANG X, TU Z, et al. On the diversity of multi-head attention[J]. Neurocomputing, 2021, 454: 14-24. |
| 24 | NIU Z, ZHONG G, YU H. A review on the attention mechanism of deep learning[J]. Neurocomputing, 2021, 452: 48-62. |
| 25 | TAKAHASHI K, YAMAMOTO K, KUCHIBA A, et al. Confidence interval for micro-averaged F1 and macro-averaged F1 scores[J]. Applied Intelligence, 2022, 52(5): 4961-4972. |
| 26 | VO N, LEE K. Hierarchical multi-head attentive network for evidence-aware fake news detection[C]// Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics. Stroudsburg: ACL, 2021:965-975. |
| 27 | POPAT K, MUKHERJEE S, YATES A, et al. DeClarE: debunking fake news and false claims using evidence-aware deep learning[C]// Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2018: 22-32. |
| 28 | ZHANG Z, HAN X, LIU Z, et al. ERNIE: enhanced language representation with informative entities[C]// Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2019:1441-1451. |
| [1] | Qi SHUAI, Hairui WANG, Guifu ZHU. Chinese story ending generation model based on bidirectional contrastive training [J]. Journal of Computer Applications, 2024, 44(9): 2683-2688. |
| [2] | Pengqi GAO, Heming HUANG, Yonghong FAN. Fusion of coordinate and multi-head attention mechanisms for interactive speech emotion recognition [J]. Journal of Computer Applications, 2024, 44(8): 2400-2406. |
| [3] | Quanmei ZHANG, Runping HUANG, Fei TENG, Haibo ZHANG, Nan ZHOU. Automatic international classification of disease coding method incorporating heterogeneous information [J]. Journal of Computer Applications, 2024, 44(8): 2476-2482. |
| [4] | Youren YU, Yangsen ZHANG, Yuru JIANG, Gaijuan HUANG. Chinese named entity recognition model incorporating multi-granularity linguistic knowledge and hierarchical information [J]. Journal of Computer Applications, 2024, 44(6): 1706-1712. |
| [5] | Yuemei XU, Ling HU, Jiayi ZHAO, Wanze DU, Wenqing WANG. Technology application prospects and risk challenges of large language models [J]. Journal of Computer Applications, 2024, 44(6): 1655-1662. |
| [6] | Longtao GAO, Nana LI. Aspect sentiment triplet extraction based on aspect-aware attention enhancement [J]. Journal of Computer Applications, 2024, 44(4): 1049-1057. |
| [7] | Xianfeng YANG, Yilei TANG, Ziqiang LI. Aspect-level sentiment analysis model based on alternating‑attention mechanism and graph convolutional network [J]. Journal of Computer Applications, 2024, 44(4): 1058-1064. |
| [8] | Baoshan YANG, Zhi YANG, Xingyuan CHEN, Bing HAN, Xuehui DU. Analysis of consistency between sensitive behavior and privacy policy of Android applications [J]. Journal of Computer Applications, 2024, 44(3): 788-796. |
| [9] | Kaitian WANG, Qing YE, Chunlei CHENG. Classification method for traditional Chinese medicine electronic medical records based on heterogeneous graph representation [J]. Journal of Computer Applications, 2024, 44(2): 411-417. |
| [10] | Chenghao FENG, Zhenping XIE, Bowen DING. Selective generation method of test cases for Chinese text error correction software [J]. Journal of Computer Applications, 2024, 44(1): 101-112. |
| [11] | Xinyue ZHANG, Rong LIU, Chiyu WEI, Ke FANG. Aspect-based sentiment analysis method with integrating prompt knowledge [J]. Journal of Computer Applications, 2023, 43(9): 2753-2759. |
| [12] | Xiaomin ZHOU, Fei TENG, Yi ZHANG. Automatic international classification of diseases coding model based on meta-network [J]. Journal of Computer Applications, 2023, 43(9): 2721-2726. |
| [13] | Zexi JIN, Lei LI, Ji LIU. Transfer learning model based on improved domain separation network [J]. Journal of Computer Applications, 2023, 43(8): 2382-2389. |
| [14] | Yao LIU, Xin TONG, Yifeng CHEN. Algorithm path self-assembling model for business requirements [J]. Journal of Computer Applications, 2023, 43(6): 1768-1778. |
| [15] | Kai ZHANG, Zhengchu QIN, Yue LIU, Xinyi QIN. Multi-learning behavior collaborated knowledge tracing model [J]. Journal of Computer Applications, 2023, 43(5): 1422-1429. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||