


Journal of Computer Applications ›› 2023, Vol. 43 ›› Issue (6): 1768-1778.DOI: 10.11772/j.issn.1001-9081.2022060944
Special Issue: CCF第37届中国计算机应用大会 (CCF NCCA 2022)
• The 37 CCF National Conference of Computer Applications (CCF NCCA 2022) • Previous Articles Next Articles
Yao LIU1( ), Xin TONG2, Yifeng CHEN2
), Xin TONG2, Yifeng CHEN2
Received:2022-06-29
Revised:2022-08-27
Accepted:2022-08-31
Online:2022-09-22
Published:2023-06-10
Contact:
Yao LIU
About author:TONG Xin, born in 1993, M. S. Her research interests include natural language processing, knowledge engineering.Supported by:
刘耀1(), 童昕2, 陈一风2
通讯作者:
刘耀
作者简介:刘耀(1972—),男,山东菏泽人,研究员,博士,CCF杰出会员,主要研究方向:自然语言处理、知识工程Email:liuy@istic.ac.cn基金资助:CLC Number:
Yao LIU, Xin TONG, Yifeng CHEN. Algorithm path self-assembling model for business requirements[J]. Journal of Computer Applications, 2023, 43(6): 1768-1778.
刘耀, 童昕, 陈一风. 面向业务需求的算法路径自组配模型[J]. 《计算机应用》唯一官方网站, 2023, 43(6): 1768-1778.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2022060944
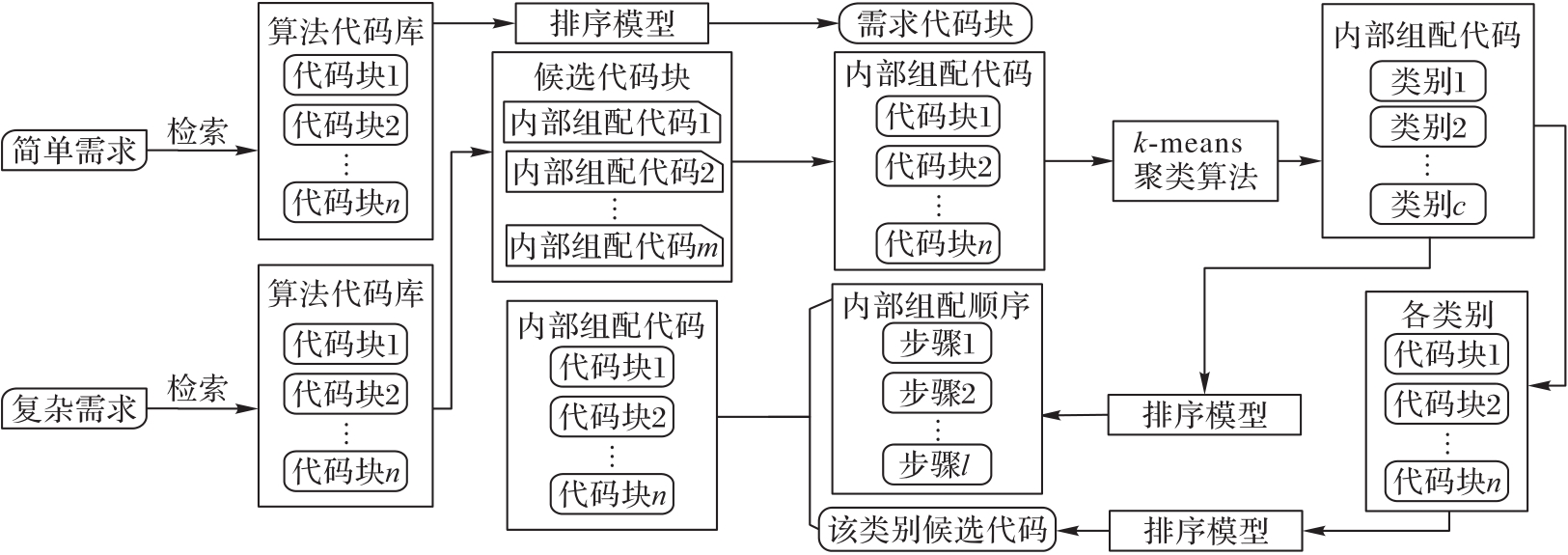
Fig. 1 Flow of algorithm path self-assembling model
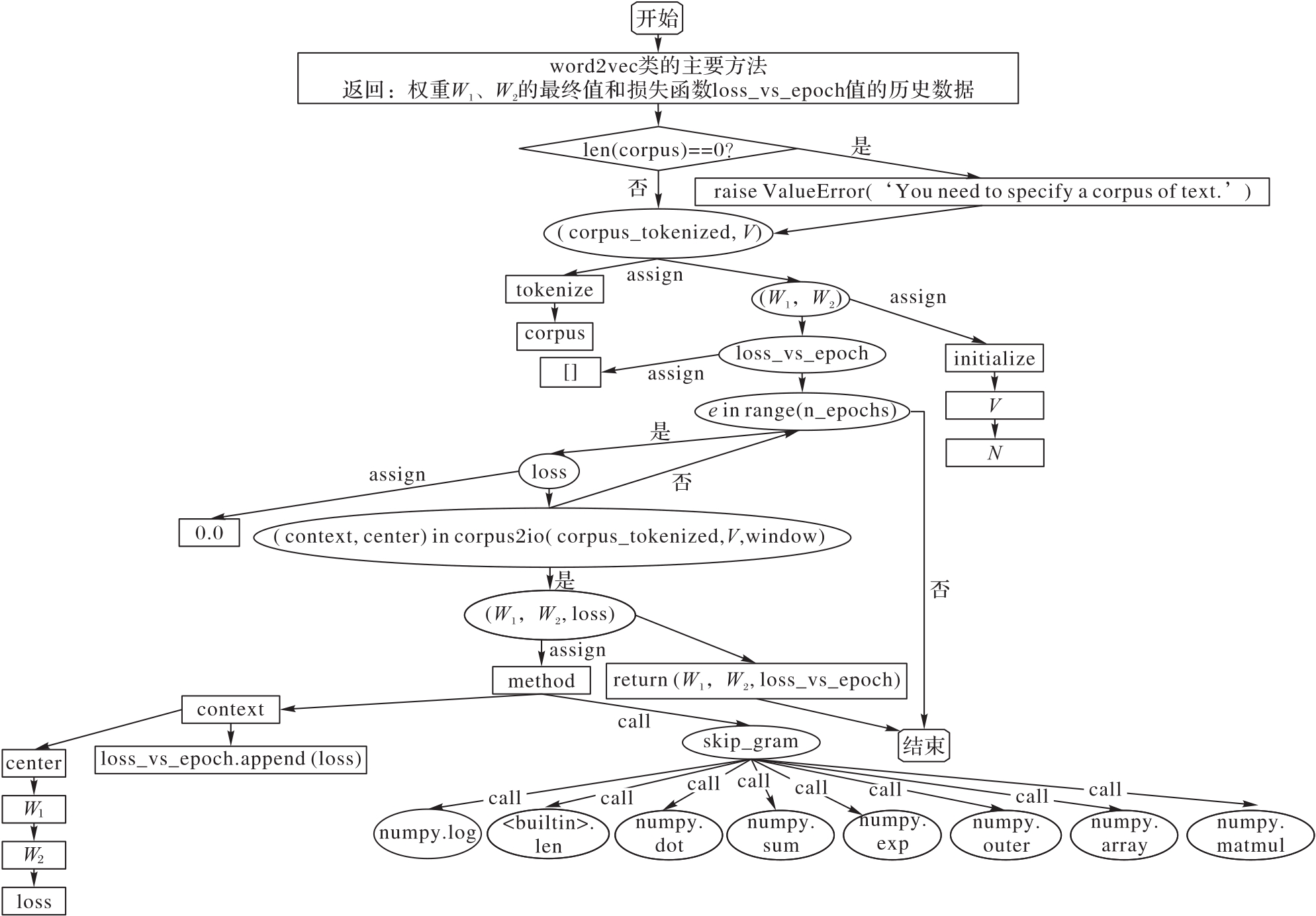
Fig. 2 Visualization of component structure of word2vec algorithm
| 算法组件结构 | 统计数据 | 算法组件结构 | 统计数据 |
|---|---|---|---|
| 图结构总数(算法组件数) | 424 | 总边数 | 10 584 |
| 节点特征维度 | 300 | 最大节点数 | 204 |
| 类别数 | 13 | 最大边数 | 231 |
| 总节点数 | 10 042 | 节点平均度 | 1.05 |
Tab.1 Results of algorithm component structure construction
| 算法组件结构 | 统计数据 | 算法组件结构 | 统计数据 |
|---|---|---|---|
| 图结构总数(算法组件数) | 424 | 总边数 | 10 584 |
| 节点特征维度 | 300 | 最大节点数 | 204 |
| 类别数 | 13 | 最大边数 | 231 |
| 总节点数 | 10 042 | 节点平均度 | 1.05 |
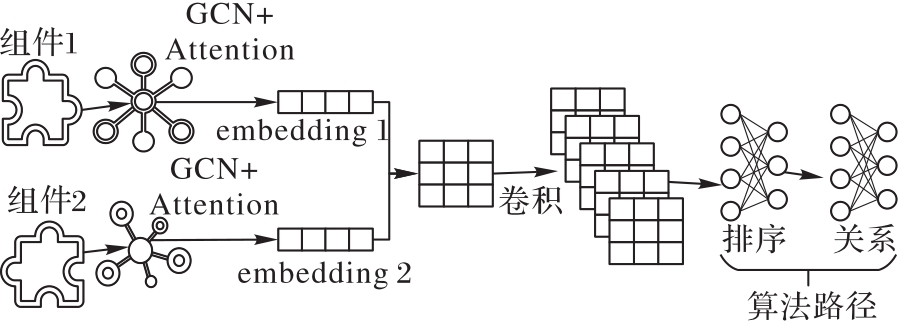
Fig. 3 Path discovery model
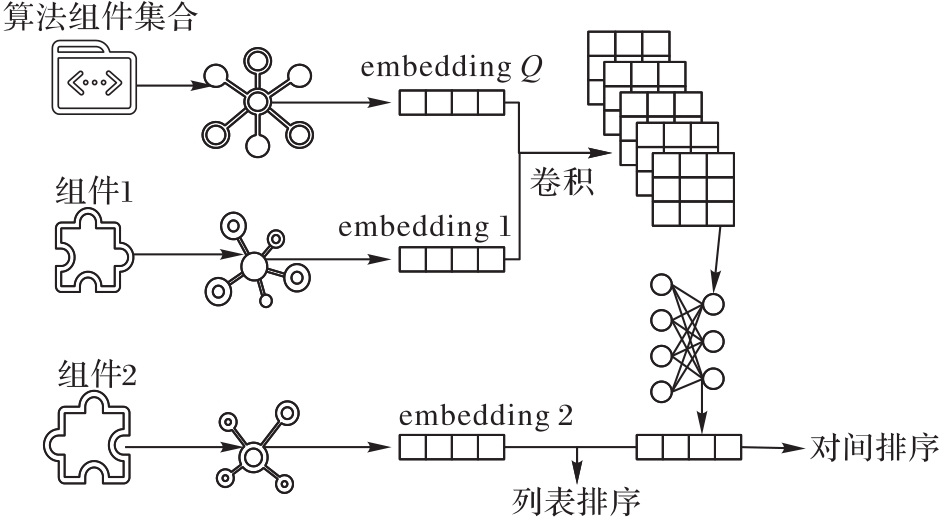
Fig. 4 Self-assembling model of algorithm path
| 源代码主题 | 组件数 | 组件主题 |
|---|---|---|
| TF-IDF#1 | 3 | 计算TF值 |
| 计算IDF值 | ||
| 计算TF-IDF值 | ||
| TF-IDF#2 | 5 | 添加文本 |
| 计算TF值 | ||
| 计算IDF值 | ||
| 计算TF-IDF值 | ||
| 词典排序 | ||
| TF-IDF#3 | 6 | 添加文档 |
| 构建字典 | ||
| 计算TF值 | ||
| 计算IDF值 | ||
| 计算TF-IDF值 | ||
| 词典排序 | ||
| TF-IDF#4 | 6 | 预处理 |
| 添加文本 | ||
| 构建字典 | ||
| 计算TF值 | ||
| 计算IDF值 | ||
| 计算TF-IDF值 | ||
| TF-IDF#5 | 5 | 预处理 |
| 构建词典 | ||
| 计算TF值 | ||
| 计算IDF值 | ||
| 计算TF-IDF值 |
Tab.2 Experimental data statistics
| 源代码主题 | 组件数 | 组件主题 |
|---|---|---|
| TF-IDF#1 | 3 | 计算TF值 |
| 计算IDF值 | ||
| 计算TF-IDF值 | ||
| TF-IDF#2 | 5 | 添加文本 |
| 计算TF值 | ||
| 计算IDF值 | ||
| 计算TF-IDF值 | ||
| 词典排序 | ||
| TF-IDF#3 | 6 | 添加文档 |
| 构建字典 | ||
| 计算TF值 | ||
| 计算IDF值 | ||
| 计算TF-IDF值 | ||
| 词典排序 | ||
| TF-IDF#4 | 6 | 预处理 |
| 添加文本 | ||
| 构建字典 | ||
| 计算TF值 | ||
| 计算IDF值 | ||
| 计算TF-IDF值 | ||
| TF-IDF#5 | 5 | 预处理 |
| 构建词典 | ||
| 计算TF值 | ||
| 计算IDF值 | ||
| 计算TF-IDF值 |
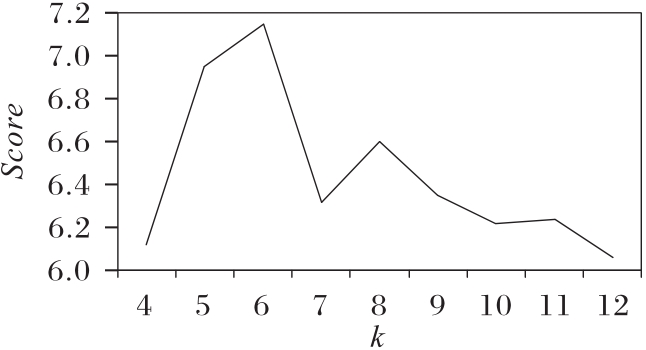
Fig.5 Influence of k on Score
| 类簇 | 算法组件 | 组件来源 |
|---|---|---|
| 0 | 计算TF值 | #5 |
| 计算TF值 | #3 | |
| 计算TF值 | #1 | |
| 计算TF值 | #4 | |
| 计算TF值 | #2 | |
| 构建词典 | #5 | |
| 构建字典 | #4 | |
| 计算IDF值 | #3 | |
| 构建字典 | #3 | |
| 1 | 添加文本 | #4 |
| 添加文本 | #2 | |
| 添加文档 | #3 | |
| 2 | 字典排序 | #2 |
| 字典排序 | #3 | |
| 3 | 预处理 | #4 |
| 预处理 | #5 | |
| 4 | 计算IDF值 | #1 |
| 计算IDF值 | #4 | |
| 计算IDF值 | #5 | |
| 5 | 计算TF-IDF值 | #2 |
| 计算TF-IDF值 | #3 | |
| 计算TF-IDF值 | #4 | |
| 计算TF-IDF值 | #1 | |
| 计算TF-IDF值 | #5 | |
| 计算IDF值 | #2 |
Tab.3 Component clustering results of TF-IDF algorithm
| 类簇 | 算法组件 | 组件来源 |
|---|---|---|
| 0 | 计算TF值 | #5 |
| 计算TF值 | #3 | |
| 计算TF值 | #1 | |
| 计算TF值 | #4 | |
| 计算TF值 | #2 | |
| 构建词典 | #5 | |
| 构建字典 | #4 | |
| 计算IDF值 | #3 | |
| 构建字典 | #3 | |
| 1 | 添加文本 | #4 |
| 添加文本 | #2 | |
| 添加文档 | #3 | |
| 2 | 字典排序 | #2 |
| 字典排序 | #3 | |
| 3 | 预处理 | #4 |
| 预处理 | #5 | |
| 4 | 计算IDF值 | #1 |
| 计算IDF值 | #4 | |
| 计算IDF值 | #5 | |
| 5 | 计算TF-IDF值 | #2 |
| 计算TF-IDF值 | #3 | |
| 计算TF-IDF值 | #4 | |
| 计算TF-IDF值 | #1 | |
| 计算TF-IDF值 | #5 | |
| 计算IDF值 | #2 |
| 参数 | 取值 | 说明 |
|---|---|---|
| filter1 | 128 | 第1层图卷积核 |
| filter2 | 64 | 第2层图卷积核 |
| filter3 | 64 | 第3层图卷积核 |
| conv_emb | 32 | 2D向量表示 |
| conv_filter | 3 | 2D卷积核 |
| proj_emb | 128 | 第1层全连接输出 |
| lr | 2E-5 | 初始学习率 |
| dropout | 0.2 | 随机dropout |
Tab.4 Initialization parameters for path discovery model
| 参数 | 取值 | 说明 |
|---|---|---|
| filter1 | 128 | 第1层图卷积核 |
| filter2 | 64 | 第2层图卷积核 |
| filter3 | 64 | 第3层图卷积核 |
| conv_emb | 32 | 2D向量表示 |
| conv_filter | 3 | 2D卷积核 |
| proj_emb | 128 | 第1层全连接输出 |
| lr | 2E-5 | 初始学习率 |
| dropout | 0.2 | 随机dropout |
| 算法组件名称 | 来源 | 路径概率 |
|---|---|---|
| 预处理 | #4 | N/A |
| 计算TF值 | #4 | 0.978 |
| 添加文本 | #4 | 0.983 |
| 计算TF-IDF值 | #4 | 0.984 |
| 计算IDF值 | #4 | 0.954 |
Tab.5 Results of path discovery among algorithm components
| 算法组件名称 | 来源 | 路径概率 |
|---|---|---|
| 预处理 | #4 | N/A |
| 计算TF值 | #4 | 0.978 |
| 添加文本 | #4 | 0.983 |
| 计算TF-IDF值 | #4 | 0.984 |
| 计算IDF值 | #4 | 0.954 |
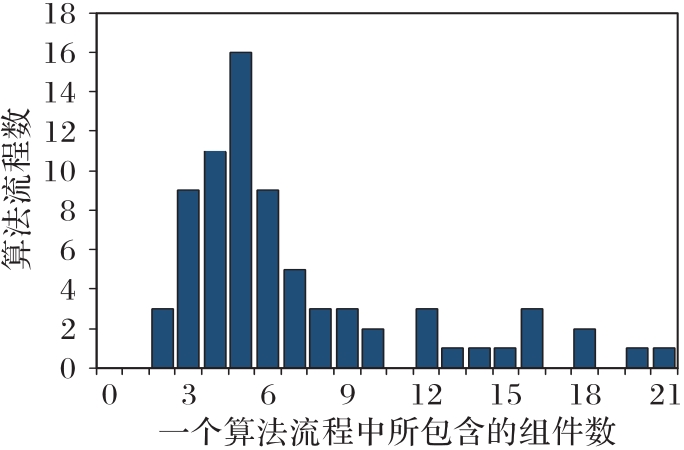
Fig. 6 Statistics of ranking datasets
| 参数 | 取值 | 说明 |
|---|---|---|
| filter1 | 384 | 第1层图卷积核 |
| filter2 | 256 | 第2层图卷积核 |
| filter3 | 256 | 第3层图卷积核 |
| conv_emb | 32 | 2D向量表示 |
| conv_filter | 3 | 2D卷积核 |
| lr | 2E-5 | 初始学习率 |
| dropout | 0.2 | 随机dropout |
Tab.6 Initialization parameters for path self-assembling model
| 参数 | 取值 | 说明 |
|---|---|---|
| filter1 | 384 | 第1层图卷积核 |
| filter2 | 256 | 第2层图卷积核 |
| filter3 | 256 | 第3层图卷积核 |
| conv_emb | 32 | 2D向量表示 |
| conv_filter | 3 | 2D卷积核 |
| lr | 2E-5 | 初始学习率 |
| dropout | 0.2 | 随机dropout |
| 组件1 | 组件2 | 得分 |
|---|---|---|
| 预处理 | 计算TF值 | 0.998 |
| 添加文件 | 5.99E-03 | |
| 计算TF-IDF值 | 0.999 | |
| 计算IDF值 | 0.998 | |
| 计算TF值 | 预处理 | 4.91E-6 |
| 添加文件 | 3.50E-4 | |
| 计算TF-IDF值 | 0.989 | |
| 计算IDF值 | 0.998 | |
| 添加文件 | 预处理 | 0.986 |
| 计算TF值 | 0.997 | |
| 计算TF-IDF值 | 0.993 | |
| 计算IDF值 | 0.994 | |
| 计算TF-IDF值 | 预处理 | 5.85E-5 |
| 计算TF值 | 7.44E-3 | |
| 添加文件 | 3.38E-4 | |
| 计算IDF值 | 1.15E-5 | |
| 计算IDF值 | 预处理 | 4.30E-4 |
| 计算TF值 | 6.64E-5 | |
| 添加文件 | 7.44E-3 | |
| 计算TF-IDF值 | 0.970 |
Tab.7 Ranking scores among pairs of algorithm components
| 组件1 | 组件2 | 得分 |
|---|---|---|
| 预处理 | 计算TF值 | 0.998 |
| 添加文件 | 5.99E-03 | |
| 计算TF-IDF值 | 0.999 | |
| 计算IDF值 | 0.998 | |
| 计算TF值 | 预处理 | 4.91E-6 |
| 添加文件 | 3.50E-4 | |
| 计算TF-IDF值 | 0.989 | |
| 计算IDF值 | 0.998 | |
| 添加文件 | 预处理 | 0.986 |
| 计算TF值 | 0.997 | |
| 计算TF-IDF值 | 0.993 | |
| 计算IDF值 | 0.994 | |
| 计算TF-IDF值 | 预处理 | 5.85E-5 |
| 计算TF值 | 7.44E-3 | |
| 添加文件 | 3.38E-4 | |
| 计算IDF值 | 1.15E-5 | |
| 计算IDF值 | 预处理 | 4.30E-4 |
| 计算TF值 | 6.64E-5 | |
| 添加文件 | 7.44E-3 | |
| 计算TF-IDF值 | 0.970 |
| 排序 | 组件 | 排序 | 组件 |
|---|---|---|---|
| 1 | 添加文件 | 4 | 计算IDF值 |
| 2 | 预处理 | 5 | 计算TF-IDF值 |
| 3 | 计算TF值 |
Tab.8 Component self-assembling results of TF-IDF algorithm
| 排序 | 组件 | 排序 | 组件 |
|---|---|---|---|
| 1 | 添加文件 | 4 | 计算IDF值 |
| 2 | 预处理 | 5 | 计算TF-IDF值 |
| 3 | 计算TF值 |
| 源代码主题 | 组件数 | 组件主题 |
|---|---|---|
| DecisionTree#1 | 7 | 读取txt |
| 计算信息熵 | ||
| 划分数据 | ||
| 计算信息增益 | ||
| ID3选择特征 | ||
| 多数决定叶子节点分类 | ||
| 生成树 | ||
| DecisionTree#2 | 6 | 多数选择分类 |
| 计算信息熵 | ||
| 计算信息增益 | ||
| 选择最优特征 | ||
| 划分数据 | ||
| 递归生成树 | ||
| DecisionTree#3 | 6 | 定义树结构 |
| 计算信息熵 | ||
| 多数表决确定叶子节点分类 | ||
| 计算信息增益 | ||
| 划分数据 | ||
| 递归计算树 | ||
| DecisionTree#4 | 8 | 定义树结构 |
| 定义节点结构 | ||
| 计算信息熵 | ||
| 计算信息增益 | ||
| 选择最优特征 | ||
| 多数决定分类 | ||
| 划分数据 | ||
| 递归计算树 |
Tab. 9 Component statistics of decision tree algorithm
| 源代码主题 | 组件数 | 组件主题 |
|---|---|---|
| DecisionTree#1 | 7 | 读取txt |
| 计算信息熵 | ||
| 划分数据 | ||
| 计算信息增益 | ||
| ID3选择特征 | ||
| 多数决定叶子节点分类 | ||
| 生成树 | ||
| DecisionTree#2 | 6 | 多数选择分类 |
| 计算信息熵 | ||
| 计算信息增益 | ||
| 选择最优特征 | ||
| 划分数据 | ||
| 递归生成树 | ||
| DecisionTree#3 | 6 | 定义树结构 |
| 计算信息熵 | ||
| 多数表决确定叶子节点分类 | ||
| 计算信息增益 | ||
| 划分数据 | ||
| 递归计算树 | ||
| DecisionTree#4 | 8 | 定义树结构 |
| 定义节点结构 | ||
| 计算信息熵 | ||
| 计算信息增益 | ||
| 选择最优特征 | ||
| 多数决定分类 | ||
| 划分数据 | ||
| 递归计算树 |
| 方法 | query1 | query2 | query3 |
|---|---|---|---|
| BM25+word2vec | 0.113 | 0.21 | 0.10 |
| word2vec | 0.500 | 0.56 | 0.41 |
| 本文方法 | 0.800 | 0.80 | 0.65 |
Tab.10 Comparative experiment results on retrieval based on different representation methods
| 方法 | query1 | query2 | query3 |
|---|---|---|---|
| BM25+word2vec | 0.113 | 0.21 | 0.10 |
| word2vec | 0.500 | 0.56 | 0.41 |
| 本文方法 | 0.800 | 0.80 | 0.65 |
| 1 | HAEFLIGER S, von KROGH G, SPAETH S. Code reuse in open source software [J]. Management Science, 2008, 54(1): 180-193. 10.1287/mnsc.1070.0748 |
| 2 | LIN Y, XING Z C, XUE Y X, et al. Detecting differences across multiple instances of code clones[C]// Proceedings of the 36th International Conference on Software Engineering. New York: ACM, 2014: 164-174. 10.1145/2568225.2568298 |
| 3 | LIN Y, MENG G Z, XUE Y X, et al. Mining implicit design templates for actionable code reuse[C]// Proceedings of the 32nd IEEE/ACM International Conference on Automated Software Engineering. Piscataway: IEEE, 2017: 394-404. 10.1109/ase.2017.8115652 |
| 4 | 彭鑫,陈驰,林云. 基于上下文的智能化代码复用推荐[J]. 大数据, 2021, 7(1):37-47. 10.11959/j.issn.2096-0271.2021003 |
| PENG X, CHEN C, LIN Y. Context-based intelligent recommendation for code reuse[J]. Big Data Research, 2021, 7(1): 37-47. 10.11959/j.issn.2096-0271.2021003 | |
| 5 | HINDLE A, BARR E T, GABEL M, et al. On the naturalness of software [J]. Communications of the ACM, 2016, 59(5): 122-131. 10.1145/2902362 |
| 6 | ALLAMANIS M, SUTTON C. Mining source code repositories at massive scale using language modeling [C]// Proceedings of the 10th Working Conference on Mining Software Repositories. Piscataway: IEEE, 2013: 207-216. 10.1109/msr.2013.6624029 |
| 7 | NGUYEN A T, HILTON M, CODOBAN M, et al. API code recommendation using statistical learning from fine-grained changes[C]// Proceedings of the 24th ACM SIGSOFT International Symposium on Foundations of Software Engineering. New York: ACM, 2016: 511-522. 10.1145/2950290.2950333 |
| 8 | TU Z P, SU Z D, DEVANBU P. On the localness of software [C]// Proceedings of the 22nd ACM SIGSOFT International Symposium on Foundations of Software Engineering. New York: ACM, 2014: 269-280. 10.1145/2635868.2635875 |
| 9 | NGUYEN T T, NGUYEN A T, NGUYEN H A, et al. A statistical semantic language model for source code[C]// Proceedings of the 9th Joint Meeting on Foundations of Software Engineering Conference and the ACM SIGSOFT Symposium on the Foundations of Software Engineering. New York: ACM, 2013: 532-542. 10.1145/2491411.2491458 |
| 10 | RAYCHEV V, VECHEV M, YAHAV E. Code completion with statistical language models[C]// Proceedings of the 35th ACM SIGPLAN Conference on Programming Language Design and Implementation. New York: ACM, 2014: 419-428. 10.1145/2594291.2594321 |
| 11 | DAM H K, TRAN T, PHAM T. A deep language model for software code[EB/OL]. (2016-08-09) [2022-01-02].. |
| 12 | WHITE M, VENDOME C, LINARES-VÁSQUEZ M, et al. Toward deep learning software repositories [C]// Proceedings of the 12th Working Conference on Mining Software Repositories. Piscataway: IEEE, 2015: 334-345. 10.1109/msr.2015.38 |
| 13 | NGUYEN A T, NGUYEN T D, PHAN H D, et al. A deep neural network language model with contexts for source code[C]// Proceedings of the IEEE 25th International Conference on Software Analysis, Evolution and Reengineering. Piscataway: IEEE, 2018: 323-334. 10.1109/saner.2018.8330220 |
| 14 | CHEN C, PENG X, XING Z C, et al. Holistic combination of structural and textual code information for context based API recommendation [J]. IEEE Transactions on Software Engineering, 2022, 48(8): 2987-3009. 10.1109/tse.2021.3074309 |
| 15 | BUNEL R, DESMAISON A, KUMAR M P, et al. Learning to superoptimize programs[EB/OL]. (2017-06-28) [2022-01-02].. |
| 16 | SCHKUFZA E, SHARMA R, AIKEN A. Stochastic superoptimization[J]. ACM SIGARCH Computer Architecture News, 2013, 48(4): 305-316. 10.1145/2499368.2451150 |
| 17 | ALLAMANIS M, BARR E T, DEVANBU P, et al. A survey of machine learning for big code and naturalness[J]. ACM Computing Surveys, 2018, 51(4): No.81. 10.1145/3212695 |
| 18 | ALLAMANIS M, BROCKSCHMIDT M. SmartPaste: learning to adapt source code [EB/OL]. (2017-05-22) [2022-01-02].. |
| 19 | NOBRE R, MARTINS L G A, CARDOSO J M P. A graph-based iterative compiler pass selection and phase ordering approach [J]. ACM SIGPLAN Notices, 2016, 51(5): 21-30. 10.1145/2980930.2907959 |
| 20 | PARK E, CAVAZOS J, ALVAREZ M A. Using graph-based program characterization for predictive modeling [C]// Proceedings of the 10th International Symposium on Code Generation and Optimization. New York: ACM, 2012: 196-206. 10.1145/2259016.2259042 |
| 21 | XU X J, LIU C, FENG Q, et al. Neural network-based graph embedding for cross-platform binary code similarity detection [C]// Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security. New York: ACM, 2017: 363-376. 10.1145/3133956.3134018 |
| 22 | BIELIK P, RAYCHEV V, VECHEV M. PHOG: probabilistic model for code[C]// Proceedings of the 33rd International Conference on Machine Learning. New York: JMLR.org, 2016: 2933-2942. |
| 23 | ALON U, ZILBERSTEIN M, LEVY O, et al. A general path-based representation for predicting program properties[J]. ACM SIGPLAN Notices, 2018, 53(4): 404-419. 10.1145/3296979.3192412 |
| 24 | BAXTER I D, YAHIN A, MOURA L, et al. Clone detection using abstract syntax trees[C]// Proceedings of the 1998 International Conference on Software Maintenance. Piscataway: IEEE, 1998: 368-377. |
| 25 | ZETTLEMOYER L, COLLINS M. Online learning of relaxed CCG grammars for parsing to logical form [C]// Proceedings of the 2007 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning. Stroudsburg, PA: ACL, 2007: 678-687. |
| 26 | KAMIYA T, KUSUMOTO S, INOUE K. CCFinder: a multilinguistic token-based code clone detection system for large scale source code[J]. IEEE Transactions on Software Engineering, 2002, 28(7): 654-670. 10.1109/tse.2002.1019480 |
| 27 | SAJNANI H, SAINI V, SVAJLENKO J, et al. SourcererCC: scaling code clone detection to big-code [C]// Proceedings of the IEEE/ACM 38th International Conference on Software Engineering. New York: ACM, 2016: 1157-1168. 10.1145/2884781.2884877 |
| 28 | DEERWESTER S, DUMAIS S T, FURNAS G W, et al. Indexing by latent semantic analysis [J]. Journal of the American Society for Information Science, 1990, 41(6): 391-407. 10.1002/(sici)1097-4571(199009)41:6<391::aid-asi1>3.0.co;2-9 |
| 29 | BLEI D M, NG A Y, JORDAN M I. Latent Dirichlet allocation[J]. Journal of Machine Learning Research, 2003, 3: 993-1022. |
| 30 | TAIRAS R, GRAY J. An information retrieval process to aid in the analysis of code clones[J]. Empirical Software Engineering, 2009, 14(1): 33-56. 10.1007/s10664-008-9089-1 |
| 31 | LIU Y X, POSHYVANYK D, FERENC R, et al. Modeling class cohesion as mixtures of latent topics [C]// Proceedings of the 2009 IEEE International Conference on Software Maintenance. Piscataway: IEEE, 2009: 233-242. 10.1109/icsm.2009.5306318 |
| 32 | PANE J F, RATANAMAHATANA C A, MYERS B A. Studying the language and structure in non-programmers’ solutions to programming problems[J]. International Journal of Human-Computer Studies, 2001, 54(2): 237-264. 10.1006/ijhc.2000.0410 |
| 33 | SALIS V, SOTIROPOULOS T, LOURIDAS P, et al. PyCG: practical call graph generation in Python [C]// Proceedings of the IEEE/ACM 43rd International Conference on Software Engineering. Piscataway: IEEE, 2021: 1646-1657. 10.1109/icse43902.2021.00146 |
| 34 | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2017: 6000-6010. |
| 35 | DETTMERS T, MINERVINI P, STENETORP P, et al. Convolutional 2D knowledge graph embeddings [C]// Proceedings of the 32nd AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2018: 1811-1818. 10.1609/aaai.v32i1.11573 |
| 36 | CAO Z, QIN T, LIU T Y, et al. Learning to rank: from pairwise approach to listwise approach[C]// Proceedings of the 24th International Conference on Machine Learning. New York: ACM, 2007: 129-136. 10.1145/1273496.1273513 |
| [1] | Qi SHUAI, Hairui WANG, Guifu ZHU. Chinese story ending generation model based on bidirectional contrastive training [J]. Journal of Computer Applications, 2024, 44(9): 2683-2688. |
| [2] | Quanmei ZHANG, Runping HUANG, Fei TENG, Haibo ZHANG, Nan ZHOU. Automatic international classification of disease coding method incorporating heterogeneous information [J]. Journal of Computer Applications, 2024, 44(8): 2476-2482. |
| [3] | Youren YU, Yangsen ZHANG, Yuru JIANG, Gaijuan HUANG. Chinese named entity recognition model incorporating multi-granularity linguistic knowledge and hierarchical information [J]. Journal of Computer Applications, 2024, 44(6): 1706-1712. |
| [4] | Longtao GAO, Nana LI. Aspect sentiment triplet extraction based on aspect-aware attention enhancement [J]. Journal of Computer Applications, 2024, 44(4): 1049-1057. |
| [5] | Xianfeng YANG, Yilei TANG, Ziqiang LI. Aspect-level sentiment analysis model based on alternating‑attention mechanism and graph convolutional network [J]. Journal of Computer Applications, 2024, 44(4): 1058-1064. |
| [6] | Baoshan YANG, Zhi YANG, Xingyuan CHEN, Bing HAN, Xuehui DU. Analysis of consistency between sensitive behavior and privacy policy of Android applications [J]. Journal of Computer Applications, 2024, 44(3): 788-796. |
| [7] | Kaitian WANG, Qing YE, Chunlei CHENG. Classification method for traditional Chinese medicine electronic medical records based on heterogeneous graph representation [J]. Journal of Computer Applications, 2024, 44(2): 411-417. |
| [8] | Yushan JIANG, Yangsen ZHANG. Large language model-driven stance-aware fact-checking [J]. Journal of Computer Applications, 2024, 44(10): 3067-3073. |
| [9] | Chenghao FENG, Zhenping XIE, Bowen DING. Selective generation method of test cases for Chinese text error correction software [J]. Journal of Computer Applications, 2024, 44(1): 101-112. |
| [10] | Xinyue ZHANG, Rong LIU, Chiyu WEI, Ke FANG. Aspect-based sentiment analysis method with integrating prompt knowledge [J]. Journal of Computer Applications, 2023, 43(9): 2753-2759. |
| [11] | Xiaomin ZHOU, Fei TENG, Yi ZHANG. Automatic international classification of diseases coding model based on meta-network [J]. Journal of Computer Applications, 2023, 43(9): 2721-2726. |
| [12] | Zexi JIN, Lei LI, Ji LIU. Transfer learning model based on improved domain separation network [J]. Journal of Computer Applications, 2023, 43(8): 2382-2389. |
| [13] | Ming XU, Linhao LI, Qiaoling QI, Liqin WANG. Abductive reasoning model based on attention balance list [J]. Journal of Computer Applications, 2023, 43(2): 349-355. |
| [14] | Xingbin LIAO, Xiaolin QIN, Siqi ZHANG, Yangge QIAN. Review of interactive machine translation [J]. Journal of Computer Applications, 2023, 43(2): 329-334. |
| [15] | Jianle CAO, Nana LI. Semantically enhanced sentiment classification model based on multi-level attention [J]. Journal of Computer Applications, 2023, 43(12): 3703-3710. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||