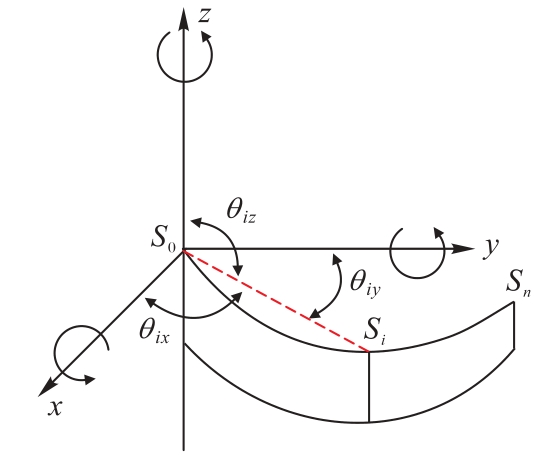
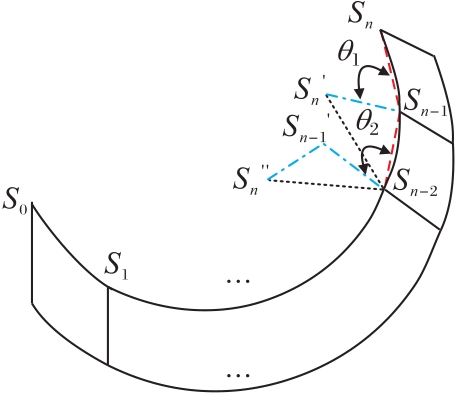
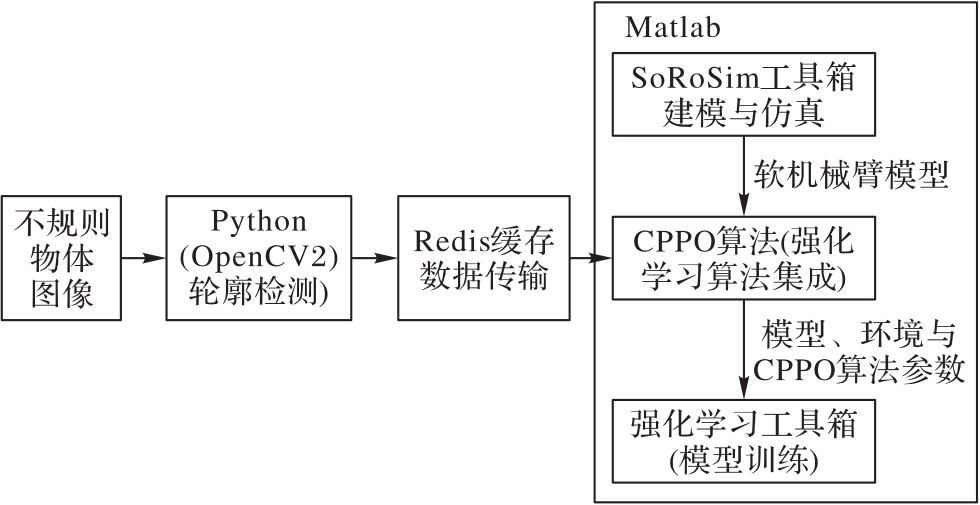
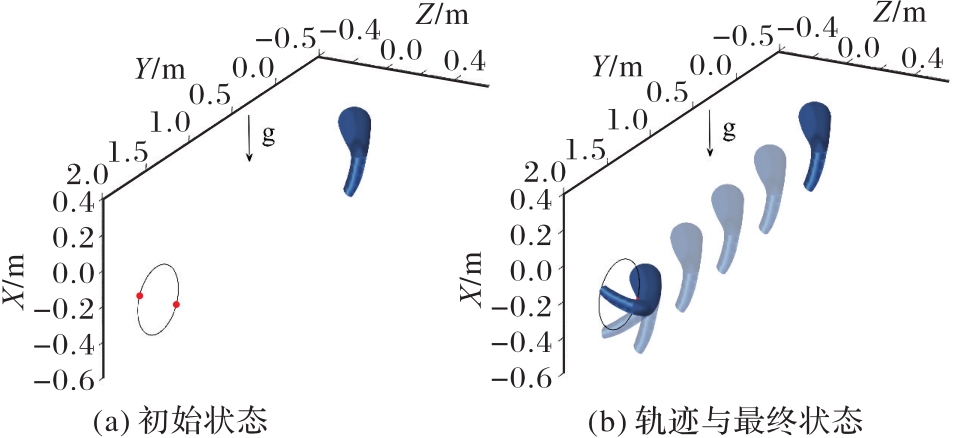
| 1 |
GU S, HOLLY E, LILLICRAP T, et al. Deep reinforcement learning for robotic manipulation with asynchronous off-policy updates[C]// Proceedings of the 2017 IEEE International Conference on Robotics and Automation. Piscataway: IEEE, 2017: 3389-3396.
|
| 2 |
RAJESWARAN A, KUMAR V, GUPTA A, et al. Learning complex dexterous manipulation with deep reinforcement learning and demonstrations[EB/OL]. [2024-03-05]..
|
| 3 |
DEISENROTH M P, NEUMANN G, PETERS J. A survey on policy search for robotics[J]. Foundations and Trends in Robotics, 2013, 2(1/2): 1-142.
|
| 4 |
DEISENROTH M P, RASMUSSEN C E. PILCO: a model-based and data-efficient approach to policy search[C]// Proceedings of the 28th International Conference on Machine Learning. Madison, WI: Omnipress, 2011: 465-472.
|
| 5 |
LEVINE S, ABBEEL P. Learning neural network policies with guided policy search under unknown dynamics[C]// Proceedings of the 27th International Conference on Neural Information Processing Systems — Volume 1. Cambridge: MIT Press, 2014: 1071-1079.
|
| 6 |
CHEBOTAR Y, KALAKRISHNAN M, YAHYA A, et al. Path integral guided policy search[C]// Proceedings of the 2017 IEEE International Conference on Robotics and Automation. Piscataway: IEEE, 2017: 3381-3388.
|
| 7 |
LEVINE S, PASTOR P, KRIZHEVSKY A, et al. Learning hand-eye coordination for robotic grasping with deep learning and large-scale data collection[J]. The International Journal of Robotics Research, 2018, 37(4/5): 421-436.
|
| 8 |
KALASHNIKOV D, IRPAN A, PASTOR P, et al. Scalable deep reinforcement learning for vision-based robotic manipulation[C]// Proceedings of the 2nd Conference on Robot Learning. New York: JMLR.org, 2018: 651-673.
|
| 9 |
QUILLEN D, JANG E, NACHUM O, et al. Deep reinforcement learning for vision-based robotic grasping: a simulated comparative evaluation of off-policy methods[C]// Proceedings of the 2018 IEEE International Conference on Robotics and Automation. Piscataway: IEEE, 2018: 6284-6291.
|
| 10 |
MARTÍN-MARTÍN R, LEE M A, GARDNER R, et al. Variable impedance control in end-effector space: an action space for reinforcement learning in contact-rich tasks[C]// Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems. Piscataway: IEEE, 2019: 1010-1017.
|
| 11 |
LENZ I, LEE H, SAXENA A. Deep learning for detecting robotic grasps[J]. The International Journal of Robotics Research, 2015, 34(4/5): 705-724.
|
| 12 |
VIERECK U, TEN PAS A, SAENKO K, et al. Learning a visuomotor controller for real world robotic grasping using simulated depth images[C]// Proceedings of the 1st Annual Conference on Robot Learning. New York: JMLR.org, 2017: 291-300.
|
| 13 |
SONG S, ZENG A, LEE J, et al. Grasping in the wild: learning 6DoF closed-loop grasping from low-cost demonstrations[J]. IEEE Robotics and Automation Letters, 2020, 5(3): 4978-4985.
|
| 14 |
SMITH L, KEW J C, PENG X B, et al. Legged robots that keep on learning: fine-tuning locomotion policies in the real world[C]// Proceedings of the 2022 IEEE International Conference on Robotics and Automation. Piscataway: IEEE, 2022: 1593-1599.
|
| 15 |
TRIVEDI D, LOTFI A, RAHN C D. Geometrically exact models for soft robotic manipulators[J]. IEEE Transactions on Robotics, 2008, 24(4): 773-780.
|
| 16 |
PAI D K. STRANDS: interactive simulation of thin solids using Cosserat models[J]. Computer Graphics Forum, 2002, 21(3): 347-352.
|
| 17 |
RENDA F, GIORGIO-SERCHI F, BOYER F, et al. Modelling cephalopod-inspired pulsed-jet locomotion for underwater soft robots[J]. Bioinspiration and Biomimetics, 2015, 10(5): No.055005.
|
| 18 |
RENDA F, GIORGIO-SERCHI F, BOYER F, et al. A unified multi-soft-body dynamic model for underwater soft robots[J]. The International Journal of Robotics Research, 2018, 37(6): 648-666.
|
| 19 |
DAS R, BABU S P M, VISENTIN F, et al. An earthworm-like modular soft robot for locomotion in multi-terrain environments[J]. Scientific Reports volume, 2023, 13: No.1571.
|
| 20 |
WANG X, KANG H, ZHOU H, et al. Development and evaluation of a robust soft robotic gripper for apple harvesting[J]. Computers and Electronics in Agriculture, 2023, 204: No.107552.
|
| 21 |
YOON Y, PARK H, LEE J, et al. Bioinspired untethered soft robot with pumpless phase change soft actuators by bidirectional thermoelectrics[J]. Chemical Engineering Journal, 2023, 451(Pt 3): No.138794.
|
| 22 |
DURIEZ C. Control of elastic soft robots based on real-time finite element method[C]// Proceedings of the 2013 IEEE International Conference on Robotics and Automation. Piscataway: IEEE, 2013: 3982-3987.
|
| 23 |
BARTLETT N W, TOLLEY M T, OVERVELDE J T B, et al. A 3D-printed, functionally graded soft robot powered by combustion[J]. Science, 2015, 349(6244):161-165.
|
| 24 |
POLYGERINOS P, WANG Z, OVERVELDE J T B, et al. Modeling of soft fiber-reinforced bending actuators[J]. IEEE Transactions on Robotics, 2015, 31(3): 778-789.
|
| 25 |
THURUTHEL T G, FALOTICO E, MANTI M, et al. Learning closed loop kinematic controllers for continuum manipulators in unstructured environments[J]. Soft Robotics, 2017, 4(3):285-296.
|
| 26 |
SCHULMAN J, WOLSKI F, DHARIWAL P, et al. Proximal policy optimization algorithms[EB/OL]. [2024-01-22]..
|
| 27 |
HASEGAWA S, YAMAGUCHI N, OKADA K, et al. Online acquisition of close-range proximity sensor models for precise object grasping and verification[J]. IEEE Robotics and Automation Letters, 2020, 5(4): 5993-6000.
|
| 28 |
VECERIK M, HESTER T, SCHOLZ J, et al. Leveraging demonstrations for deep reinforcement learning on robotics problems with sparse rewards[EB/OL].[2024-04-11]..
|
| 29 |
OneOneLiu, GGCNN Cornell grasp dataset[DS/OL]. [2023-12-05]..
|


 )
)