


Journal of Computer Applications ›› 2025, Vol. 45 ›› Issue (6): 2025-2033.DOI: 10.11772/j.issn.1001-9081.2024050724
• Multimedia computing and computer simulation • Previous Articles
Yuan SONG1, Xin CHEN1, Yarong LI1, Yongwei LI2, Yang LIU1, Zhen ZHAO1
Received:2024-06-03
Revised:2025-01-08
Accepted:2025-01-10
Online:2025-01-14
Published:2025-06-10
Contact:
Yang LIU
About author:SONG Yuan, born in 2000, M. S. candidate. Her research interests include speech separation.Supported by:宋源1, 陈锌1, 李亚荣1, 李永伟2, 刘扬1, 赵振1
通讯作者:
刘扬
作者简介:宋源(2000—),女,河南驻马店人,硕士研究生,主要研究方向:语音分离基金资助:CLC Number:
Yuan SONG, Xin CHEN, Yarong LI, Yongwei LI, Yang LIU, Zhen ZHAO. Single-channel speech separation model based on auditory modulation Siamese network[J]. Journal of Computer Applications, 2025, 45(6): 2025-2033.
宋源, 陈锌, 李亚荣, 李永伟, 刘扬, 赵振. 基于听觉调制孪生网络的单通道语音分离模型[J]. 《计算机应用》唯一官方网站, 2025, 45(6): 2025-2033.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2024050724

Fig. 1 Framework of single-channel speech separation model based on auditory modulation Siamese network
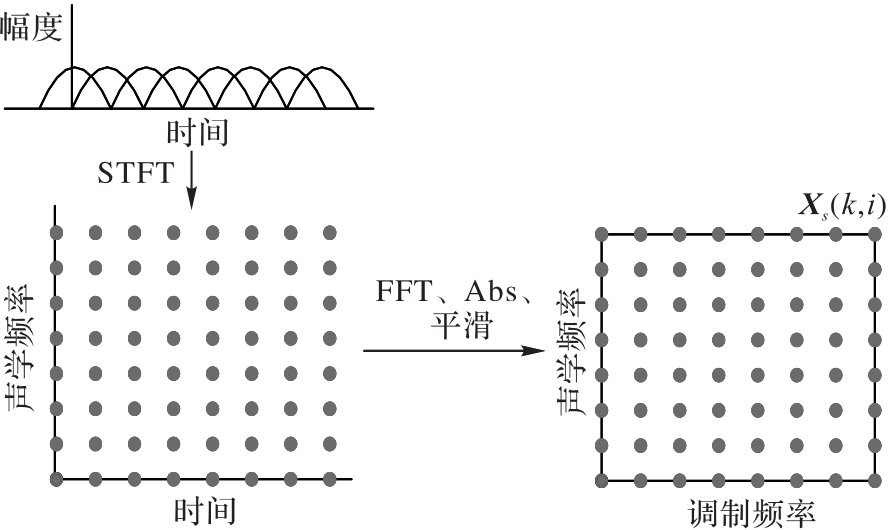
Fig. 2 Calculation process of modulation amplitude spectrum
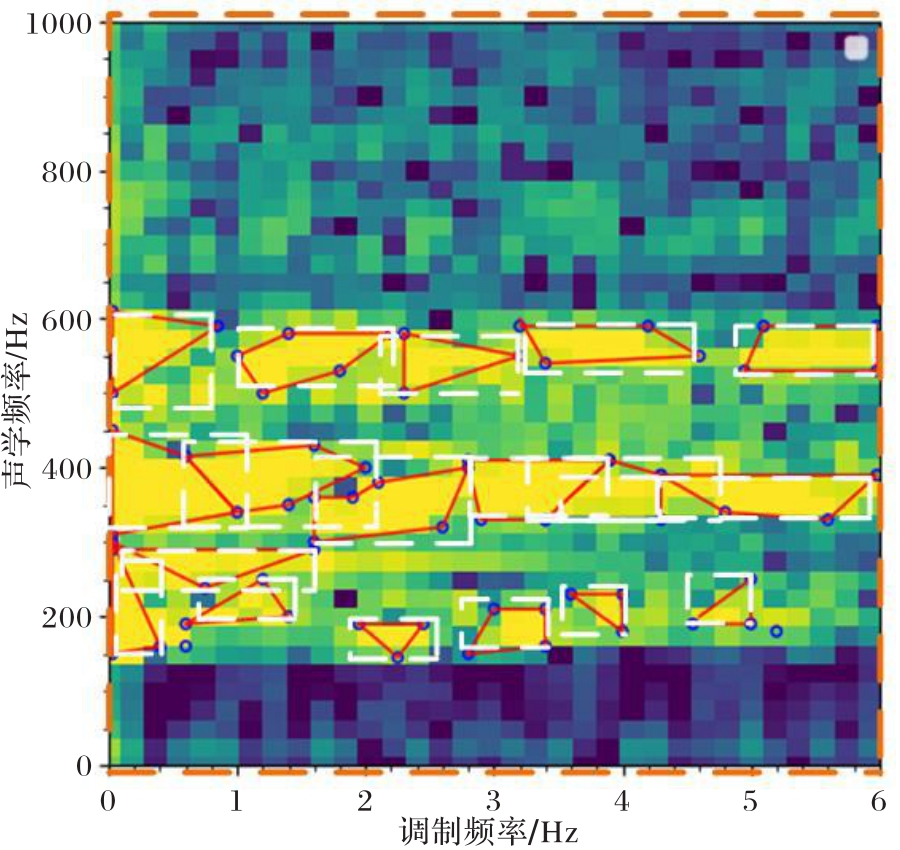
Fig. 3 Results of amplitude spectrum speech segment generation

Fig. 4 Siamese neural network based on co-attention mechanism
| 数据集 | 语音分离模型 | PESQ | SDRi/dB | SI-SDRi/dB |
|---|---|---|---|---|
| WSJ0-2mix | NMF-LSTM | 2.08 | 6.34 | — |
| uPIT-LSTM | 2.11 | 7.00 | 7.43 | |
| TasNet-LSTM | 2.84 | 8.00 | 8.20 | |
| DPCL | 3.05 | 7.93 | 5.80 | |
| Chimera | 3.21 | 8.35 | 7.00 | |
| Wave-U-Net | 3.32 | 8.67 | 9.02 | |
| Wave-U-Net+SAM+ASPP | 3.42 | 9.16 | 9.25 | |
| Group+Conquer | 3.44 | 9.23 | 9.21 | |
| DDDTCWT | 3.46 | 9.25 | 9.24 | |
| 本文模型 | 3.58 | 9.89 | 9.96 | |
| WSJ0-3mix | NMF-LSTM | 1.93 | 4.31 | — |
| uPIT-LSTM | 2.01 | 5.05 | — | |
| TasNet-LSTM | 2.53 | 5.26 | 5.64 | |
| DPCL | 2.95 | 5.93 | 6.08 | |
| Chimera | 3.02 | 6.17 | 6.05 | |
| Wave-U-Net | 3.10 | 6.23 | 7.21 | |
| Wave-U-Net+SAM+ASPP | 3.24 | 6.30 | 7.45 | |
| Group+Conquer | 3.20 | 6.22 | 7.43 | |
| DDDTCWT | 3.25 | 6.41 | 7.46 | |
| 本文模型 | 3.35 | 6.84 | 8.02 |
Tab. 1 Results of comparison experiments on different datasets
| 数据集 | 语音分离模型 | PESQ | SDRi/dB | SI-SDRi/dB |
|---|---|---|---|---|
| WSJ0-2mix | NMF-LSTM | 2.08 | 6.34 | — |
| uPIT-LSTM | 2.11 | 7.00 | 7.43 | |
| TasNet-LSTM | 2.84 | 8.00 | 8.20 | |
| DPCL | 3.05 | 7.93 | 5.80 | |
| Chimera | 3.21 | 8.35 | 7.00 | |
| Wave-U-Net | 3.32 | 8.67 | 9.02 | |
| Wave-U-Net+SAM+ASPP | 3.42 | 9.16 | 9.25 | |
| Group+Conquer | 3.44 | 9.23 | 9.21 | |
| DDDTCWT | 3.46 | 9.25 | 9.24 | |
| 本文模型 | 3.58 | 9.89 | 9.96 | |
| WSJ0-3mix | NMF-LSTM | 1.93 | 4.31 | — |
| uPIT-LSTM | 2.01 | 5.05 | — | |
| TasNet-LSTM | 2.53 | 5.26 | 5.64 | |
| DPCL | 2.95 | 5.93 | 6.08 | |
| Chimera | 3.02 | 6.17 | 6.05 | |
| Wave-U-Net | 3.10 | 6.23 | 7.21 | |
| Wave-U-Net+SAM+ASPP | 3.24 | 6.30 | 7.45 | |
| Group+Conquer | 3.20 | 6.22 | 7.43 | |
| DDDTCWT | 3.25 | 6.41 | 7.46 | |
| 本文模型 | 3.35 | 6.84 | 8.02 |
| 语音分离模型 | MOS | |||
|---|---|---|---|---|
| S1 | S2 | S3 | S4 | |
| NMF-LSTM | 3.41 | 3.53 | 3.32 | 3.40 |
| uPIT-LSTM | 3.32 | 3.53 | 3.41 | 3.32 |
| TasNet-LSTM | 3.40 | 3.44 | 3.30 | 3.52 |
| DPCL | 3.20 | 3.66 | 3.51 | 3.41 |
| Chimera | 3.63 | 3.81 | 3.70 | 3.83 |
| Wave-U-Net | 3.82 | 3.73 | 3.61 | 3.94 |
| Wave-U-Net+SAM+ASPP | 3.91 | 4.02 | 3.92 | 3.83 |
| Group+Conquer | 3.90 | 3.98 | 3.84 | 4.00 |
| DDDTCWT | 3.93 | 4.00 | 4.03 | 3.90 |
| 本文模型 | 4.18 | 4.25 | 4.33 | 4.05 |
Tab.2 MOS scoring
| 语音分离模型 | MOS | |||
|---|---|---|---|---|
| S1 | S2 | S3 | S4 | |
| NMF-LSTM | 3.41 | 3.53 | 3.32 | 3.40 |
| uPIT-LSTM | 3.32 | 3.53 | 3.41 | 3.32 |
| TasNet-LSTM | 3.40 | 3.44 | 3.30 | 3.52 |
| DPCL | 3.20 | 3.66 | 3.51 | 3.41 |
| Chimera | 3.63 | 3.81 | 3.70 | 3.83 |
| Wave-U-Net | 3.82 | 3.73 | 3.61 | 3.94 |
| Wave-U-Net+SAM+ASPP | 3.91 | 4.02 | 3.92 | 3.83 |
| Group+Conquer | 3.90 | 3.98 | 3.84 | 4.00 |
| DDDTCWT | 3.93 | 4.00 | 4.03 | 3.90 |
| 本文模型 | 4.18 | 4.25 | 4.33 | 4.05 |
| 消融实验组 | PESQ | SDRi/dB | SI-SDRi/dB |
|---|---|---|---|
| A | 3.58 | 9.89 | 9.96 |
| B | 3.51 | 9.62 | 9.73 |
| C | 2.98 | 8.14 | 8.33 |
| D | 3.46 | 9.56 | 9.54 |
| E | 3.06 | 8.82 | 8.75 |
| F | 3.47 | 9.25 | 8.91 |
| G | 3.34 | 8.80 | 8.56 |
Tab.3 Results of ablation experiments
| 消融实验组 | PESQ | SDRi/dB | SI-SDRi/dB |
|---|---|---|---|
| A | 3.58 | 9.89 | 9.96 |
| B | 3.51 | 9.62 | 9.73 |
| C | 2.98 | 8.14 | 8.33 |
| D | 3.46 | 9.56 | 9.54 |
| E | 3.06 | 8.82 | 8.75 |
| F | 3.47 | 9.25 | 8.91 |
| G | 3.34 | 8.80 | 8.56 |
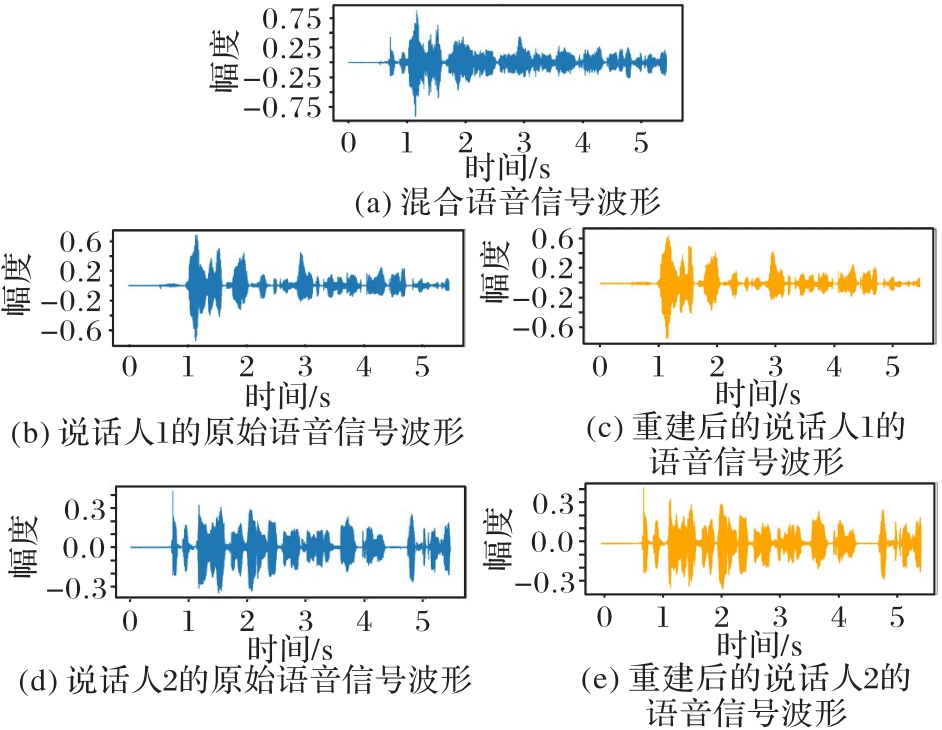
Fig. 5 Comparison of waveforms before and after speech separation

Fig. 6 Comparison of modulation spectrograms before and after speech separation
| 1 | SHAMMA S A. Speech processing in the auditory system Ⅱ: lateral inhibition and the central processing of speech evoked activity in the auditory nerve[J]. The Journal of the Acoustical Society of America, 1985, 78(5): 1622-1632. |
| 2 | ROUAT J. Computational auditory scene analysis: principles, algorithms, and applications (Wang, D. and Brown, G.J., Eds.; 2006) [Book review][J]. IEEE Transactions on Neural Networks, 2008, 19(1): 199-199. |
| 3 | ZEREMDINI J, MESSAOUD M A BEN, BOUZID A. A comparison of several Computational Auditory Scene Analysis (CASA) techniques for monaural speech segregation[J]. Brain Informatics, 2015, 2(3): 155-166. |
| 4 | SHAO Y, SRINIVASAN S, JIN Z, et al. A computational auditory scene analysis system for speech segregation and robust speech recognition[J]. Computer Speech and Language, 2010, 24(1): 77-93. |
| 5 | CARDOSO J F. Source separation using higher order moments[C]// Proceedings of the 1989 International Conference on Acoustics, Speech, and Signal Processing — Volume 4. Piscataway: IEEE, 1989: 2109-2112. |
| 6 | LEE D D, SEUNG H S. Learning the parts of objects by non-negative matrix factorization[J]. Nature, 1999, 401(6755): 788-791. |
| 7 | CHOI S, CICHOCKI A, PARK H M, et al. Blind source separation and independent component analysis: a review[J]. Neural Information Processing — Letters and Reviews, 2005, 6(1): 1-57. |
| 8 | STONE J V. Independent component analysis: a tutorial introduction[M]. Cambridge: MIT Press, 2004. |
| 9 | THARWAT A. Independent component analysis: an introduction[J]. Applied Computing and Informatics, 2021, 17(2): 222-249. |
| 10 | GANNOT S, VINCENT E, MARKOVICH-GOLAN S, et al. A consolidated perspective on multimicrophone speech enhancement and source separation[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2017, 25(4): 692-730. |
| 11 | EPHRAIM Y, MALAH D. Speech enhancement using a minimum-mean square error short-time spectral amplitude estimator[J]. IEEE Transactions on Acoustics, Speech, and Signal Processing, 1984, 32(6): 1109-1121. |
| 12 | SLOCK D T M. A survey of convergence results on the least mean square algorithm[J]. IEEE Transactions on Signal Processing, 1993, 41(12): 2960-2988. |
| 13 | BENESTY J, CHEN J, HUANG Y, et al. Pearson correlation coefficient-based adaptive noise cancellation algorithms for improved speech recognition[J]. IEEE Transactions on Audio, Speech, and Language Processing, 2018, 26(5): 984-998. |
| 14 | MINIPRIYA T M, RAJAVEL R. Review of ideal binary and ratio mask estimation techniques for monaural speech separation[C]// Proceedings of the 4th International Conference on Advances in Electrical, Electronics, Information, Communication and Bio-Informatics. Piscataway: IEEE, 2018: 1-5. |
| 15 | KOLBÆK M, YU D, TAN Z H, et al. Multitalker speech separation with utterance-level permutation invariant training of deep recurrent neural networks[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2017, 25(10): 1901-1913. |
| 16 | KOLBÆK M, YU D, TAN Z H, et al. Joint separation and denoising of noisy multi-talker speech using recurrent neural networks and permutation invariant training[C]// Proceedings of the IEEE 27th International Workshop on Machine Learning for Signal Processing. Piscataway: IEEE, 2017: 1-6. |
| 17 | YU D, KOLBÆK M, TAN Z H, et al. Permutation invariant training of deep models for speaker-independent multi-talker speech separation[C]// Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2017: 241-245. |
| 18 | XU C, RAO W, XIAO X, et al. Single channel speech separation with constrained utterance level permutation invariant training using grid LSTM[C]// Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2018: 6-10. |
| 19 | MIN E, GUO X, LIU Q, et al. A survey of clustering with deep learning: from the perspective of network architecture[J]. IEEE Access, 2018, 6: 39501-39514. |
| 20 | CHEN Z, LUO Y, MESGARANI N. Deep attractor network for single-microphone speaker separation[C]// Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2017: 246-250. |
| 21 | LUO Y, CHEN Z, MESGARANI N. Speaker-independent speech separation with deep attractor network[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2018, 26(4): 787-796. |
| 22 | 关文博. 基于孪生神经网络与深度聚类融合的语音分离研究[D]. 青岛:青岛科技大学, 2023. |
| GUAN W B. Research on speech separation based on fusion of Siamese neural network and deep clustering[D]. Qingdao: Qingdao University of Science and Technology, 2023. | |
| 23 | KAMBLE M R, TAK H, PATIL H A. Amplitude and frequency modulation-based features for detection of replay spoof speech[J]. Speech Communication, 2020, 125: 114-127. |
| 24 | MSONDA P, UYMAZ S A, KARAAĞAÇ S S. Spatial pyramid pooling in deep convolutional networks for automatic tuberculosis diagnosis[J]. Traitement du Signal, 2020, 37(6): 1075-1084. |
| 25 | QIAN C, GAO J, SHAO X, et al. Bearing fault diagnosis method based on improved deep residual Siamese neural network[J]. Insight — Non-Destructive Testing and Condition Monitoring, 2024, 66(3): 174-181. |
| 26 | STÖTER F R, LIUTKUS A, ITO N. The 2018 signal separation evaluation campaign[C]// Proceedings of the 2018 International Conference on Latent Variable Analysis and Signal Separation LNCS 10891. Cham: Springer, 2018: 293-305. |
| 27 | 葛宛营. 基于非负矩阵分解和深度聚类的语音分离研究[D]. 重庆:重庆邮电大学, 2020. |
| GE W Y. Study on speech separation based on non-negative matrix factorization and deep clustering[D]. Chongqing: Chongqing University of Posts and Telecommunications, 2020. | |
| 28 | LUO Y, MESGARANI N. Conv-TasNet: surpassing ideal time-frequency magnitude masking for speech separation[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2019, 27(8): 1256-1266. |
| 29 | WANG Z Q, LE ROUX J, HERSHEY J R. Alternative objective functions for deep clustering[C]// Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2018: 686-690. |
| 30 | LUO Y, CHEN Z, HERSHEY J R, et al. Deep clustering and conventional networks for music separation: stronger together[C]// Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2017: 61-65. |
| 31 | STOLLER D, EWERT S, DIXON S. Wave-U-Net: a multi-scale neural network for end-to-end audio source separation[C]// Proceedings of the 19th International Society for Music Information Retrieval Conference. [S.l.]: International Society for Music Information Retrieval, 2018: 334-340. |
| 32 | LAN C, JIANG J, ZHANG L, et al. Blind source separation based on improved Wave-U-Net network[J]. IEEE Access, 2023, 11: 125951-125958. |
| 33 | YEN Y F, SHUAI H H. Group-and-conquer for multi-speaker single-channel speech separation[C]// Proceedings of the 33rd Wireless and Optical Communications Conference. Piscataway: IEEE, 2024: 165-169. |
| 34 | HOSSAIN M I, RAHIM M A, HOSSAIN M N. Single-channel speech separation based on double-density dual-tree CWT and SNMF[J]. Annals of Emerging Technologies in Computing, 2024, 8(1): 1-12. |
| 35 | FU J, XIE Q, MENG D, et al. Rotation equivariant proximal operator for deep unfolding methods in image restoration[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024, 46(10): 6577-6593. |
| [1] | Wu XIONG, Congjun CAO, Xuefang SONG, Yunlong SHAO, Xusheng WANG. Handwriting identification method based on multi-scale mixed domain attention mechanism [J]. Journal of Computer Applications, 2024, 44(7): 2225-2232. |
| [2] | Ziwen SUN, Lizhi QIAN, Chuandong YANG, Yibo GAO, Qingyang LU, Guanglin YUAN. Survey of visual object tracking methods based on Transformer [J]. Journal of Computer Applications, 2024, 44(5): 1644-1654. |
| [3] | Zhiwen JING, Yujia ZHANG, Boting SUN, Hao GUO. Two-stage recommendation algorithm of Siamese graph convolutional neural network [J]. Journal of Computer Applications, 2024, 44(2): 469-476. |
| [4] | Chenhui CUI, Suzhen LIN, Dawei LI, Xiaofei LU, Jie WU. Infrared dim small target tracking method based on Siamese network and Transformer [J]. Journal of Computer Applications, 2024, 44(2): 563-571. |
| [5] | Junjian JIANG, Dawei LIU, Yifan LIU, Yougui REN, Zhibin ZHAO. Few-shot object detection algorithm based on Siamese network [J]. Journal of Computer Applications, 2023, 43(8): 2325-2329. |
| [6] | Yuanlong ZHAO, Yugang SHAN, Jie YUAN, Kangdi ZHAO. Object tracking based on instance segmentation and Pythagorean fuzzy decision-making [J]. Journal of Computer Applications, 2023, 43(6): 1930-1937. |
| [7] | Mengting WANG, Wenzhong YANG, Yongzhi WU. Survey of single target tracking algorithms based on Siamese network [J]. Journal of Computer Applications, 2023, 43(3): 661-673. |
| [8] | Qi WANG, Hang LEI, Xupeng WANG. Deep face verification under pose interference [J]. Journal of Computer Applications, 2023, 43(2): 595-600. |
| [9] | Haitao GONG, Zhihua CHEN, Bin SHENG, Bingyan ZHU. SiamTrans: tiny object tracking algorithm based on Siamese network and Transformer [J]. Journal of Computer Applications, 2023, 43(12): 3733-3739. |
| [10] | Yi ZHUANG, Haitao ZHAO. Proposal-based aggregation network for single object tracking in 3D point cloud [J]. Journal of Computer Applications, 2022, 42(5): 1407-1416. |
| [11] | Wenqiu ZHU, Guang ZOU, Zhigao ZENG. Object tracking algorithm with hierarchical features and hybrid attention [J]. Journal of Computer Applications, 2022, 42(3): 833-843. |
| [12] | JI Zhangjian, REN Xingwang. Object tracking algorithm of fully-convolutional Siamese networks with rotation and scale estimation [J]. Journal of Computer Applications, 2021, 41(9): 2705-2711. |
| [13] | ZHONG Sha, HUANG Yuqing. Specified object tracking of unmanned aerial vehicle based on Siamese region proposal network [J]. Journal of Computer Applications, 2021, 41(2): 523-529. |
| [14] | Haojie LOU, Yuanlin ZHENG, Kaiyang LIAO, Hao LEI, Jia LI. Defect target detection for printed matter based on Siamese-YOLOv4 [J]. Journal of Computer Applications, 2021, 41(11): 3206-3212. |
| [15] | LI Ziqiang, WANG Zhengyong, CHEN Honggang, LI Linyi, HE Xiaohai. Video abnormal behavior detection based on dual prediction model of appearance and motion features [J]. Journal of Computer Applications, 2021, 41(10): 2997-3003. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||