


Journal of Computer Applications ›› 2025, Vol. 45 ›› Issue (5): 1379-1386.DOI: 10.11772/j.issn.1001-9081.2024060802
• China Conference on Data Mining 2024 (CCDM 2024) • Previous Articles
Pengyu CHEN1, Xiushan NIE1,2, Nanjun LI2,3, Tuo LI2,3
Received:2024-06-21
Revised:2024-07-19
Accepted:2024-07-23
Online:2024-08-19
Published:2025-05-10
Contact:
Xiushan NIE
About author:CHEN Pengyu, born in 2000, M. S. candidate. His research interests include computer vision.Supported by:陈鹏宇1, 聂秀山1,2, 李南君2,3, 李拓2,3
通讯作者:
聂秀山
作者简介:陈鹏宇(2000—),男,山东德州人,硕士研究生,CCF会员,主要研究方向:计算机视觉基金资助:CLC Number:
Pengyu CHEN, Xiushan NIE, Nanjun LI, Tuo LI. Semi-supervised video object segmentation method based on spatio-temporal decoupling and regional robustness enhancement[J]. Journal of Computer Applications, 2025, 45(5): 1379-1386.
陈鹏宇, 聂秀山, 李南君, 李拓. 基于时空解耦和区域鲁棒性增强的半监督视频目标分割方法[J]. 《计算机应用》唯一官方网站, 2025, 45(5): 1379-1386.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2024060802
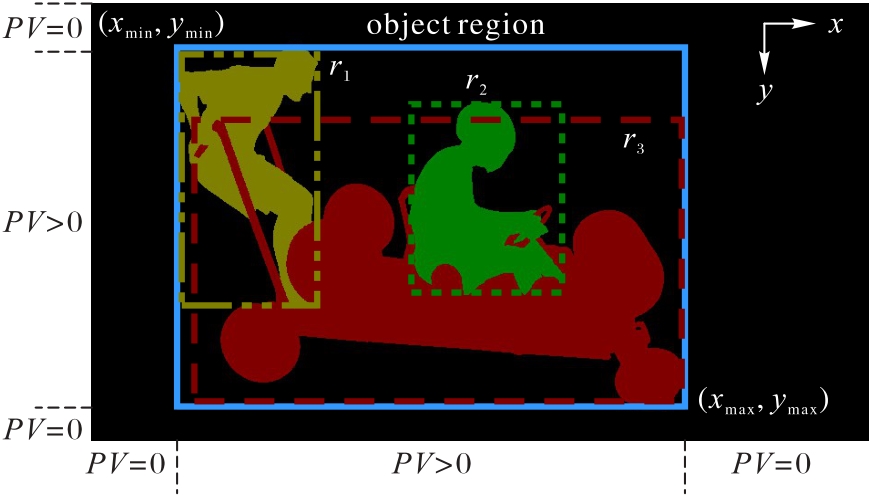
Fig. 1 Illustration of object region computation
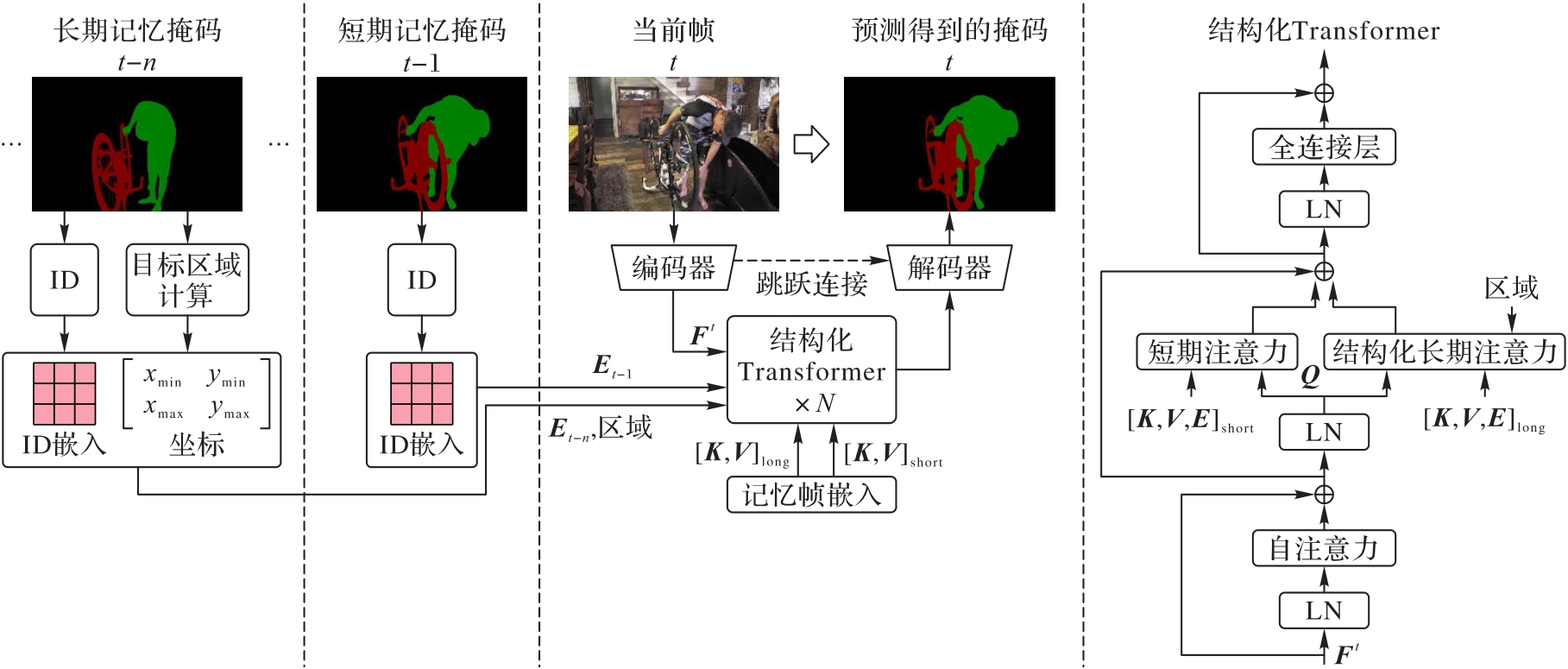
Fig. 2 Model structure of proposed method
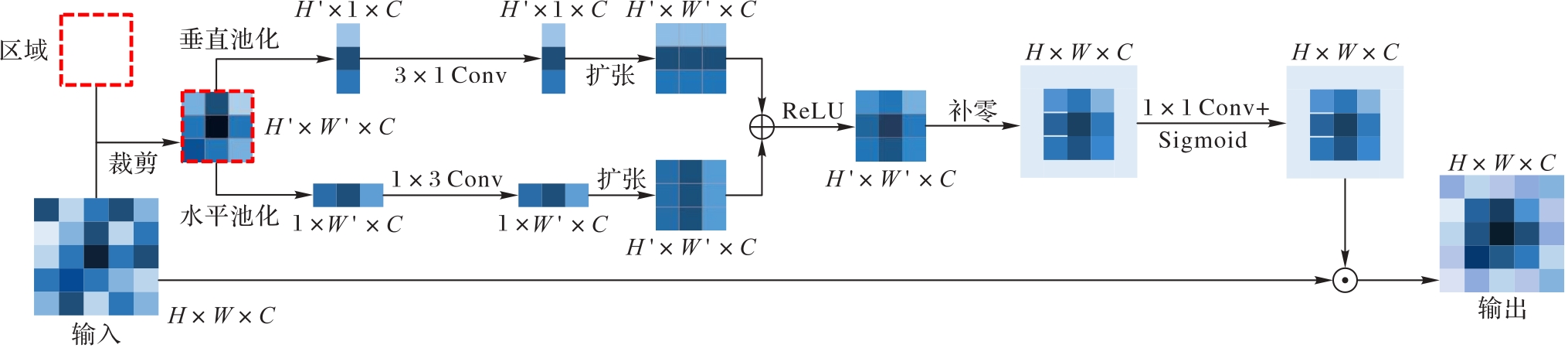
Fig. 3 Implementation details of RSA
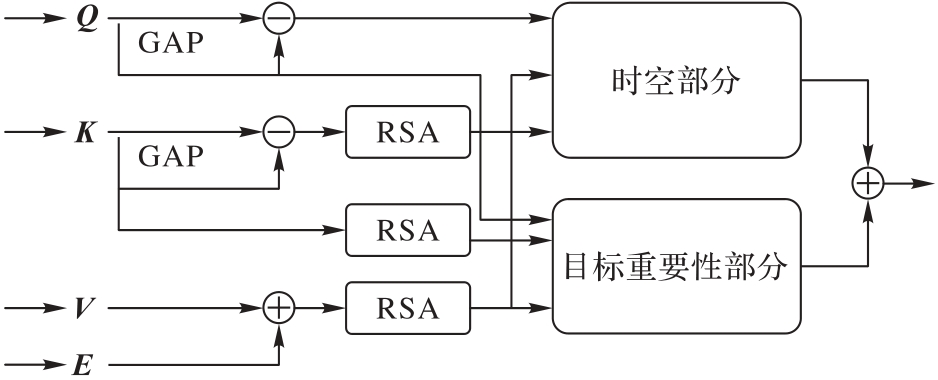
Fig. 4 Details of structural long-term attention
| 模型 | +S | J&F | J度量 | F度量 | FPS |
|---|---|---|---|---|---|
| LWL[ | 81.6 | 79.1 | 84.1 | 14.0 | |
| STM[ | √ | 81.8 | 79.2 | 84.3 | 6.3 |
| CFBI[ | 81.9 | 79.1 | 84.6 | 5.0 | |
| KMN[ | √ | 82.8 | 80.0 | 85.6 | |
| LCM[ | √ | 83.5 | 80.5 | 86.5 | 8.0 |
| MiVOS[ | √ | 84.5 | 81.7 | 87.4 | 11.2 |
| HMMN[ | √ | 84.7 | 81.9 | 87.5 | 9.6 |
| AOT[ | √ | 85.2 | 82.5 | 87.9 | 18.7 |
| AOT*[ | 79.9 | 77.1 | 82.8 | 15.3 | |
| STRSA | 81.6 | 78.6 | 84.5 | 6.6 |
Tab. 1 Performance comparison of different models on DAVIS 2017 validation set
| 模型 | +S | J&F | J度量 | F度量 | FPS |
|---|---|---|---|---|---|
| LWL[ | 81.6 | 79.1 | 84.1 | 14.0 | |
| STM[ | √ | 81.8 | 79.2 | 84.3 | 6.3 |
| CFBI[ | 81.9 | 79.1 | 84.6 | 5.0 | |
| KMN[ | √ | 82.8 | 80.0 | 85.6 | |
| LCM[ | √ | 83.5 | 80.5 | 86.5 | 8.0 |
| MiVOS[ | √ | 84.5 | 81.7 | 87.4 | 11.2 |
| HMMN[ | √ | 84.7 | 81.9 | 87.5 | 9.6 |
| AOT[ | √ | 85.2 | 82.5 | 87.9 | 18.7 |
| AOT*[ | 79.9 | 77.1 | 82.8 | 15.3 | |
| STRSA | 81.6 | 78.6 | 84.5 | 6.6 |
| 方法 | +S | 总分 | 已知类 | 未知类 | ||
|---|---|---|---|---|---|---|
| J | F | J | F | |||
| STM[ | √ | 79.2 | 79.6 | 83.6 | 73.0 | 80.6 |
| KMN[ | √ | 80.0 | 80.4 | 84.5 | 73.8 | 81.4 |
| MiVOS[ | √ | 80.3 | 79.3 | 83.7 | 75.3 | 82.8 |
| LWL[ | √ | 81.0 | 79.6 | 83.8 | 76.4 | 84.2 |
| CFBI[ | 81.0 | 80.6 | 85.1 | 75.2 | 83.0 | |
| HMMN[ | √ | 82.5 | 81.7 | 86.1 | 77.3 | 85.0 |
| JITL[ | 82.8 | 80.8 | 84.8 | 79.0 | 86.6 | |
| AOT[ | √ | 85.3 | 83.9 | 88.8 | 79.9 | 88.5 |
| AOT*[ | 80.5 | 79.8 | 84.2 | 74.7 | 83.2 | |
| STRSA | 82.1 | 81.4 | 86.0 | 76.4 | 84.8 | |
Tab. 2 Performance comparison of different methods on YouTube-VOS 2019 validation set
| 方法 | +S | 总分 | 已知类 | 未知类 | ||
|---|---|---|---|---|---|---|
| J | F | J | F | |||
| STM[ | √ | 79.2 | 79.6 | 83.6 | 73.0 | 80.6 |
| KMN[ | √ | 80.0 | 80.4 | 84.5 | 73.8 | 81.4 |
| MiVOS[ | √ | 80.3 | 79.3 | 83.7 | 75.3 | 82.8 |
| LWL[ | √ | 81.0 | 79.6 | 83.8 | 76.4 | 84.2 |
| CFBI[ | 81.0 | 80.6 | 85.1 | 75.2 | 83.0 | |
| HMMN[ | √ | 82.5 | 81.7 | 86.1 | 77.3 | 85.0 |
| JITL[ | 82.8 | 80.8 | 84.8 | 79.0 | 86.6 | |
| AOT[ | √ | 85.3 | 83.9 | 88.8 | 79.9 | 88.5 |
| AOT*[ | 80.5 | 79.8 | 84.2 | 74.7 | 83.2 | |
| STRSA | 82.1 | 81.4 | 86.0 | 76.4 | 84.8 | |

Fig. 5 Visualization results on DAVIS 2017validation set
| 方法 | ST | RSA | 总分 | 已知类F度量 | 未知类F度量 |
|---|---|---|---|---|---|
| 基线 | 80.5 | 84.2 | 83.2 | ||
| V1 | √ | 81.3 | 84.7 | 84.1 | |
| STRSA | √ | √ | 82.1 | 86.0 | 84.8 |
Tab. 3 Ablation experimental results on YouTube-VOS 2019 validation set
| 方法 | ST | RSA | 总分 | 已知类F度量 | 未知类F度量 |
|---|---|---|---|---|---|
| 基线 | 80.5 | 84.2 | 83.2 | ||
| V1 | √ | 81.3 | 84.7 | 84.1 | |
| STRSA | √ | √ | 82.1 | 86.0 | 84.8 |
| 变体 | 目标区域 | SAP | J&F | J度量 | F度量 |
|---|---|---|---|---|---|
| V1 | √ | 76.5 | 73.8 | 79.1 | |
| V2 | √ | 78.8 | 76.4 | 81.1 | |
| RSA | √ | √ | 79.3 | 76.9 | 81.7 |
Tab. 4 Ablation experimental results of different settings in RSA module on DAVIS 2017 validation set
| 变体 | 目标区域 | SAP | J&F | J度量 | F度量 |
|---|---|---|---|---|---|
| V1 | √ | 76.5 | 73.8 | 79.1 | |
| V2 | √ | 78.8 | 76.4 | 81.1 | |
| RSA | √ | √ | 79.3 | 76.9 | 81.7 |
| 1 | COHEN I, MEDIONI G. Detecting and tracking moving objects for video surveillance[C]// Proceedings of the 1999 IEEE Computer Society Conference on Computer Vision and Pattern Recognition — Volume 2. Piscataway: IEEE, 1999, 2: 319-325. |
| 2 | 胡学敏,童秀迟,郭琳,等.基于深度视觉注意神经网络的端到端自动驾驶模型[J].计算机应用, 2020,40(7):1926-1931. |
| HU X M, TONG X C, GUO L, et al. End-to-end autonomous driving model based on deep visual attention neural network[J]. Journal of Computer Applications, 2020, 40(7): 1926-1931. | |
| 3 | CHAKRABORTY B, SARMA D, BHUYAN M K, et al. Review of constraints on vision‐based gesture recognition for human-computer interaction[J]. IET Computer Vision, 2018, 12(1): 3-15. |
| 4 | HU L, ZHANG P, ZHANG B, et al. Learning position and target consistency for memory-based video object segmentation[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 4142-4152. |
| 5 | LIANG Y, LI X, JAFARI N, et al. Video object segmentation with adaptive feature bank and uncertain-region refinement[C]// Proceedings of the 34th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2020: 3430-3441. |
| 6 | HU Y T, HUANG J B, SCHWING A G. VideoMatch: matching based video object segmentation[C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11212. Cham: Springer, 2018: 56-73. |
| 7 | YANG Z, WEI Y, YANG Y. Collaborative video object segmentation by foreground-background integration[C]// Proceedings of the 2020 European Conference on Computer Vision, LNCS 12350. Cham: Springer, 2020: 332-348. |
| 8 | PORTALÉS C, GIMENO J, SALVADOR A, et al. Mixed reality annotation of robotic-assisted surgery videos with real-time tracking and stereo matching[J]. Computers and Graphics, 2023, 110: 125-140. |
| 9 | CHENG H K, TAI Y-W, TANG C-K. Rethinking space-time networks with improved memory coverage for efficient video object segmentation[C]// Proceedings of the 35th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2021: 11781-11794. |
| 10 | OH S W, LEE J Y, XU N, et al. Video object segmentation using space-time memory networks[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 9225-9234. |
| 11 | WU Q, YANG T, WU W, et al. Scalable video object segmentation with simplified framework[C]// Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2023: 13833-13843. |
| 12 | YANG Z, WEI Y, YANG Y. Associating objects with transformers for video object segmentation[C]// Proceedings of the 35th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2021: 2491-2502. |
| 13 | YIN M, YAO Z, CAO Y, et al. Disentangled non-local neural networks[C]// Proceedings of the 2020 European Conference on Computer Vision, LNCS 12360. Cham: Springer, 2020: 191-207. |
| 14 | CHENG H K, Y-W TAIO, TANG C-K. Modular interactive video object segmentation: interaction-to-mask, propagation and difference-aware fusion[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 5555-5564. |
| 15 | PONT-TUSET J, PERAZZI F, CAELLES S, et al. The 2017 DAVIS challenge on video object segmentation[EB/OL]. [2024-01-11]. . |
| 16 | XU N, YANG L, FAN Y, et al. YouTube-VOS: a large-scale video object segmentation benchmark[EB/OL]. [2024-01-15]. . |
| 17 | K-K MAMINIS, CCELLES S, CHEN Y H, et al. Video object segmentation without temporal information[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019, 41(6): 1515-1530. |
| 18 | VENTURA C, BELLVER M, GIRBAU A, et al. RVOS: end-to-end recurrent network for video object segmentation[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 5272-5281. |
| 19 | LIN H, QI X, JIA J. AGSS-VOS: attention guided single-shot video object segmentation[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 3948-3956. |
| 20 | CAELLES S, K-K MANINIS, PONT-TUSET J, et al. One-shot video object segmentation[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 5320-5329. |
| 21 | ZHANG Y, WU Z, PENG H, et al. A transductive approach for video object segmentation[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 6947-6956. |
| 22 | KUMA A, IRSOY O, ONDRUSKA P, et al. Ask me anything: dynamic memory networks for natural language processing[C]// Proceedings of the 33rd International Conference on Machine Learning. New York: ACM, 2016: 1378-1387. |
| 23 | BHAT G, LAWIN F J, DANELLJAN M, et al. Learning what to learn for video object segmentation[C]// Proceedings of the 16th European Conference on Computer Vision, LNCS 12347. Cham: Springer, 2020: 777-794. |
| 24 | SEONG H, HYUN J, KIM E. Kernelized memory network for video object segmentation[C]// Proceedings of the 2020 European Conference on Computer Vision, LNCS 12367. Cham: Springer, 2020: 629-645. |
| 25 | SEONG H, OH S W, LEE J-Y, et al. Hierarchical memory matching network for video object segmentation[C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 12869-12878. |
| 26 | LIANG S, SHEN X, HUANG J, et al. Video object segmentation with dynamic memory networks and adaptive object alignment[C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 8045-8054. |
| 27 | HOU W, QIN Z, XI X, et al. Learning disentangled representation for self-supervised video object segmentation[J]. Neurocomputing, 2022, 481: 270-280. |
| 28 | VASWANI A, SHAZEER N, PARAMAR N, et al. Attention is all you need[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2017: 6000-6010. |
| 29 | YANG Y, WEI H, SUN Z, et al. S2OSC: a holistic semi-supervised approach for open set classification[J]. ACM Transactions on Knowledge Discovery from Data, 2022, 16(2): No.34. |
| 30 | DUKE B, AHMED A, WOLF C, et al. SSTVOS: sparse spatiotemporal Transformers for video object segmentation[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 5908-5917. |
| 31 | MAO Y, WANG N, ZHOU W, et al. Joint inductive and transductive learning for video object segmentation[C]//Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 9650-9659. |
| 32 | LIN T-Y, DOLLÁR P, GIRSHICK R, et al. Feature pyramid networks for object detection[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 936-944. |
| 33 | HE K, GKIOXARI G, DOLLÁR P, et al. Mask R-CNN[C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2017: 2980-2988. |
| [1] | Dingmu YANG, Longqiang NI, Jing LIANG, Zhaoyuan QIU, Yongzhen ZHANG, Zhiqiang QI. Protocol conversion method based on semantic similarity [J]. Journal of Computer Applications, 2025, 45(4): 1263-1270. |
| [2] | Baohua YUAN, Jialu CHEN, Huan WANG. Medical image segmentation network integrating multi-scale semantics and parallel double-branch [J]. Journal of Computer Applications, 2025, 45(3): 988-995. |
| [3] | Yalun WANG, Yangsen ZHANG, Siwen ZHU. Headline generation model with position embedding for knowledge reasoning [J]. Journal of Computer Applications, 2025, 45(2): 345-353. |
| [4] | Jietao LIANG, Bing LUO, Lanhui FU, Qingling CHANG, Nannan LI, Ningbo YI, Qi FENG, Xin HE, Fuqin DENG. Point cloud registration method based on coordinate geometric sampling [J]. Journal of Computer Applications, 2025, 45(1): 214-222. |
| [5] | Liehong REN, Lyuwen HUANG, Xu TIAN, Fei DUAN. Multivariate long-term series forecasting method with DFT-based frequency-sensitive dual-branch Transformer [J]. Journal of Computer Applications, 2024, 44(9): 2739-2746. |
| [6] | Jiepo FANG, Chongben TAO. Hybrid internet of vehicles intrusion detection system for zero-day attacks [J]. Journal of Computer Applications, 2024, 44(9): 2763-2769. |
| [7] | Yunchuan HUANG, Yongquan JIANG, Juntao HUANG, Yan YANG. Molecular toxicity prediction based on meta graph isomorphism network [J]. Journal of Computer Applications, 2024, 44(9): 2964-2969. |
| [8] | Xin YANG, Xueni CHEN, Chunjiang WU, Shijie ZHOU. Short-term traffic flow prediction of urban highway based on variant residual model and Transformer [J]. Journal of Computer Applications, 2024, 44(9): 2947-2951. |
| [9] | Jinjin LI, Guoming SANG, Yijia ZHANG. Multi-domain fake news detection model enhanced by APK-CNN and Transformer [J]. Journal of Computer Applications, 2024, 44(9): 2674-2682. |
| [10] | Jieru JIA, Jianchao YANG, Shuorui ZHANG, Tao YAN, Bin CHEN. Unsupervised person re-identification based on self-distilled vision Transformer [J]. Journal of Computer Applications, 2024, 44(9): 2893-2902. |
| [11] | Yingjun ZHANG, Niuniu LI, Binhong XIE, Rui ZHANG, Wangdong LU. Semi-supervised object detection framework guided by curriculum learning [J]. Journal of Computer Applications, 2024, 44(8): 2326-2333. |
| [12] | Yuwei DING, Hongbo SHI, Jie LI, Min LIANG. Image denoising network based on local and global feature decoupling [J]. Journal of Computer Applications, 2024, 44(8): 2571-2579. |
| [13] | Kaili DENG, Weibo WEI, Zhenkuan PAN. Industrial defect detection method with improved masked autoencoder [J]. Journal of Computer Applications, 2024, 44(8): 2595-2603. |
| [14] | Fan YANG, Yao ZOU, Mingzhi ZHU, Zhenwei MA, Dawei CHENG, Changjun JIANG. Credit card fraud detection model based on graph attention Transformation neural network [J]. Journal of Computer Applications, 2024, 44(8): 2634-2642. |
| [15] | Dahai LI, Zhonghua WANG, Zhendong WANG. Dual-branch low-light image enhancement network combining spatial and frequency domain information [J]. Journal of Computer Applications, 2024, 44(7): 2175-2182. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||