


Journal of Computer Applications ›› 2024, Vol. 44 ›› Issue (9): 2893-2902.DOI: 10.11772/j.issn.1001-9081.2024040425
• Multimedia computing and computer simulation • Previous Articles Next Articles
Jieru JIA1,2,3( ), Jianchao YANG1,2,3, Shuorui ZHANG1,2,3, Tao YAN1,2,4,5, Bin CHEN4,5
), Jianchao YANG1,2,3, Shuorui ZHANG1,2,3, Tao YAN1,2,4,5, Bin CHEN4,5
Received:2024-04-09
Revised:2024-06-18
Accepted:2024-06-26
Online:2024-09-14
Published:2024-09-10
Contact:
Jieru JIA
About author:YANG Jianchao, born in 2001, M. S. candidate. His research interests include vision Transformer.Supported by:
贾洁茹1,2,3(), 杨建超1,2,3, 张硕蕊1,2,3, 闫涛1,2,4,5, 陈斌4,5
通讯作者:
贾洁茹
作者简介:杨建超(2001—),男,山西运城人,硕士研究生,主要研究方向:视觉Transformer基金资助:CLC Number:
Jieru JIA, Jianchao YANG, Shuorui ZHANG, Tao YAN, Bin CHEN. Unsupervised person re-identification based on self-distilled vision Transformer[J]. Journal of Computer Applications, 2024, 44(9): 2893-2902.
贾洁茹, 杨建超, 张硕蕊, 闫涛, 陈斌. 基于自蒸馏视觉Transformer的无监督行人重识别[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2893-2902.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2024040425
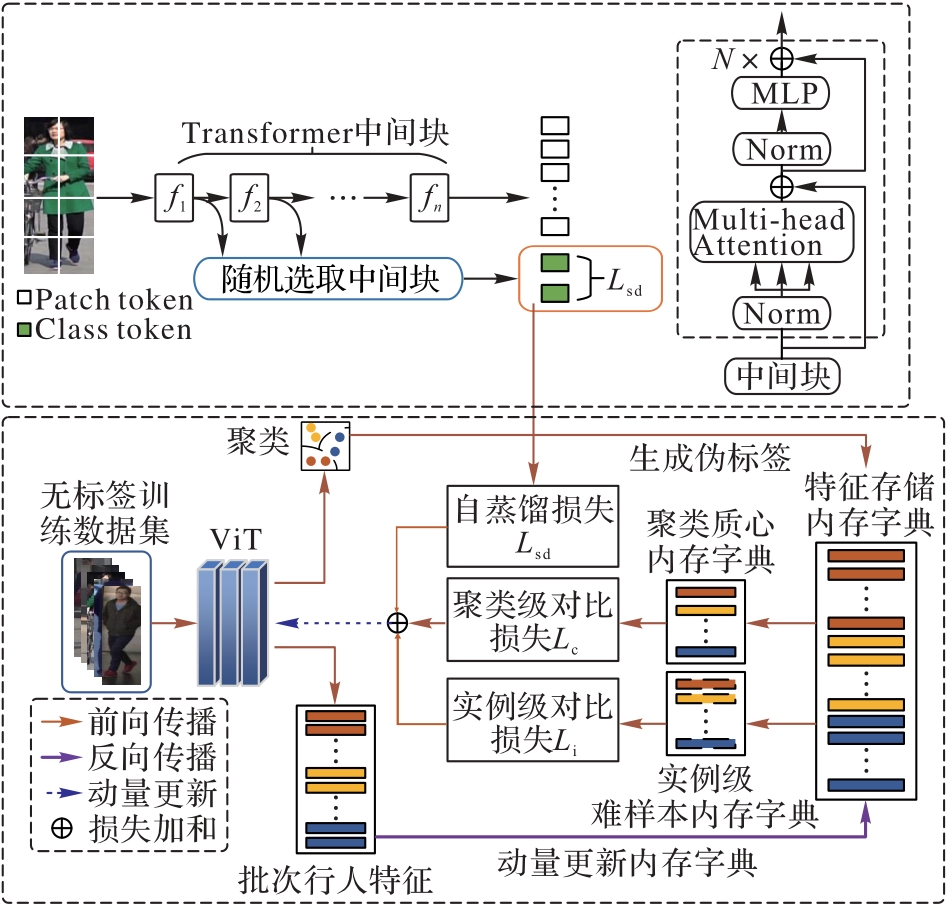
Fig. 1 Flow of proposed method
| 类别 | 方法 | Market-1501 | |||||
|---|---|---|---|---|---|---|---|
| backbone | 源域 | mAP | Rank-1 | Rank-5 | Rank-10 | ||
| UDA | MMCL | ResNet | Duke | 60.4 | 84.4 | 92.8 | 95.0 |
| UNRN | ResNet | MSMT17 | 75.6 | 89.3 | 95.8 | 97.5 | |
| SPCL | ResNet | MSMT17 | 77.5 | 89.7 | 96.1 | 97.6 | |
| USL | BUC | ResNet | None | 38.3 | 66.2 | 79.6 | 84.5 |
| SSL | ResNet | None | 37.8 | 71.7 | 83.8 | 87.4 | |
| MMCL | ResNet | None | 45.5 | 80.3 | 89.4 | 92.3 | |
| HCT | ResNet | None | 56.4 | 80.0 | 91.6 | 95.2 | |
| CycAs | ResNet | None | 64.8 | 84.8 | — | — | |
| UGA | ResNet | None | 70.3 | 87.2 | — | — | |
| SPCL | ResNet | None | 73.1 | 88.1 | 95.1 | 97.0 | |
| C-Contrast | ResNet | None | 82.1 | 92.3 | 96.7 | 97.9 | |
| HHCL | ResNet | None | 83.0 | 92.7 | |||
| TransReID-SSL | ViT-S | None | — | — | |||
| TransCL | ViT-S | None | 76.6 | 89.6 | 95.3 | — | |
| PSD | ViT-S | None | 80.1 | 92.0 | 97.2 | 98.5 | |
| 本文方法 | ViT-S | None | 89.4 | 95.0 | 98.0 | 98.7 | |
Tab. 1 Comparison results of different methods on Market-1501 dataset
| 类别 | 方法 | Market-1501 | |||||
|---|---|---|---|---|---|---|---|
| backbone | 源域 | mAP | Rank-1 | Rank-5 | Rank-10 | ||
| UDA | MMCL | ResNet | Duke | 60.4 | 84.4 | 92.8 | 95.0 |
| UNRN | ResNet | MSMT17 | 75.6 | 89.3 | 95.8 | 97.5 | |
| SPCL | ResNet | MSMT17 | 77.5 | 89.7 | 96.1 | 97.6 | |
| USL | BUC | ResNet | None | 38.3 | 66.2 | 79.6 | 84.5 |
| SSL | ResNet | None | 37.8 | 71.7 | 83.8 | 87.4 | |
| MMCL | ResNet | None | 45.5 | 80.3 | 89.4 | 92.3 | |
| HCT | ResNet | None | 56.4 | 80.0 | 91.6 | 95.2 | |
| CycAs | ResNet | None | 64.8 | 84.8 | — | — | |
| UGA | ResNet | None | 70.3 | 87.2 | — | — | |
| SPCL | ResNet | None | 73.1 | 88.1 | 95.1 | 97.0 | |
| C-Contrast | ResNet | None | 82.1 | 92.3 | 96.7 | 97.9 | |
| HHCL | ResNet | None | 83.0 | 92.7 | |||
| TransReID-SSL | ViT-S | None | — | — | |||
| TransCL | ViT-S | None | 76.6 | 89.6 | 95.3 | — | |
| PSD | ViT-S | None | 80.1 | 92.0 | 97.2 | 98.5 | |
| 本文方法 | ViT-S | None | 89.4 | 95.0 | 98.0 | 98.7 | |
| 方法 | MSMT17 | ||||||
|---|---|---|---|---|---|---|---|
| backbone | 源域 | mAP | Rank-1 | Rank-5 | Rank-10 | ||
| UDA | ECN | ResNet | Duke | 10.2 | 30.2 | 41.5 | 46.8 |
| UNRN | ResNet | Market-1501 | 24.0 | 50.1 | 63.5 | 69.3 | |
| SPCL | ResNet | Market-1501 | 26.8 | 53.7 | 65.0 | 69.8 | |
| USL | MMCL | ResNet | None | 11.2 | 35.4 | 44.8 | 49.8 |
| TAUDL | ResNet | None | 12.5 | 28.4 | — | — | |
| CycAs | ResNet | None | 26.7 | 50.1 | — | — | |
| UGA | ResNet | None | 21.7 | 49.5 | — | — | |
| SPCL | ResNet | None | 19.1 | 42.3 | 55.6 | 61.2 | |
| C-Contrast | ResNet | None | 27.6 | 56.0 | |||
| HHCL | ResNet | None | 26.3 | 52.3 | 64.2 | 69.6 | |
| TransReID-SSL | ViT-S | None | — | — | |||
| TransCL | ViT-S | None | 19.2 | 39.1 | 50.4 | — | |
| PSD | ViT-S | None | 38.4 | 61.7 | 70.2 | 73.4 | |
| 本文方法 | ViT-S | None | 44.3 | 69.5 | 74.1 | 78.2 | |
Tab. 2 Comparison results of different methods on MSMT17 dataset
| 方法 | MSMT17 | ||||||
|---|---|---|---|---|---|---|---|
| backbone | 源域 | mAP | Rank-1 | Rank-5 | Rank-10 | ||
| UDA | ECN | ResNet | Duke | 10.2 | 30.2 | 41.5 | 46.8 |
| UNRN | ResNet | Market-1501 | 24.0 | 50.1 | 63.5 | 69.3 | |
| SPCL | ResNet | Market-1501 | 26.8 | 53.7 | 65.0 | 69.8 | |
| USL | MMCL | ResNet | None | 11.2 | 35.4 | 44.8 | 49.8 |
| TAUDL | ResNet | None | 12.5 | 28.4 | — | — | |
| CycAs | ResNet | None | 26.7 | 50.1 | — | — | |
| UGA | ResNet | None | 21.7 | 49.5 | — | — | |
| SPCL | ResNet | None | 19.1 | 42.3 | 55.6 | 61.2 | |
| C-Contrast | ResNet | None | 27.6 | 56.0 | |||
| HHCL | ResNet | None | 26.3 | 52.3 | 64.2 | 69.6 | |
| TransReID-SSL | ViT-S | None | — | — | |||
| TransCL | ViT-S | None | 19.2 | 39.1 | 50.4 | — | |
| PSD | ViT-S | None | 38.4 | 61.7 | 70.2 | 73.4 | |
| 本文方法 | ViT-S | None | 44.3 | 69.5 | 74.1 | 78.2 | |
| 模型 | Market-1501 | MSMT17 | ||
|---|---|---|---|---|
| mAP | Rank-1 | mAP | Rank-1 | |
| ViT-Baseline | 88.2 | 94.2 | 40.9 | 66.4 |
| ViT+SD[0,5] | 88.4 | 94.5 | 41.7 | 66.9 |
| ViT+SD[ | 88.9 | 94.9 | 42.4 | 67.6 |
| ViT+SD[all blocks] | 89.4 | 95.0 | 44.3 | 69.5 |
Tab. 3 Comparison results of different block selection strategies
| 模型 | Market-1501 | MSMT17 | ||
|---|---|---|---|---|
| mAP | Rank-1 | mAP | Rank-1 | |
| ViT-Baseline | 88.2 | 94.2 | 40.9 | 66.4 |
| ViT+SD[0,5] | 88.4 | 94.5 | 41.7 | 66.9 |
| ViT+SD[ | 88.9 | 94.9 | 42.4 | 67.6 |
| ViT+SD[all blocks] | 89.4 | 95.0 | 44.3 | 69.5 |
| 参数 | Market-1501 | MSMT17 | ||
|---|---|---|---|---|
| mAP/% | Rank-1/% | mAP/% | Rank-1/% | |
| 1.0 | 88.6 | 94.1 | 43.9 | 69.0 |
| 2.0 | 88.9 | 94.4 | 43.1 | 68.8 |
| 3.0 | 89.4 | 95.0 | 44.3 | 69.5 |
| 4.0 | 89.0 | 94.8 | 43.0 | 68.1 |
Tab. 4 Influence of temperature parameter on model precision
| 参数 | Market-1501 | MSMT17 | ||
|---|---|---|---|---|
| mAP/% | Rank-1/% | mAP/% | Rank-1/% | |
| 1.0 | 88.6 | 94.1 | 43.9 | 69.0 |
| 2.0 | 88.9 | 94.4 | 43.1 | 68.8 |
| 3.0 | 89.4 | 95.0 | 44.3 | 69.5 |
| 4.0 | 89.0 | 94.8 | 43.0 | 68.1 |
| 参数 | Market-1501 | MSMT17 | ||
|---|---|---|---|---|
| mAP/% | Rank-1/% | mAP/% | Rank-1/% | |
| 0.0 | 88.2 | 94.2 | 40.9 | 66.4 |
| 0.1 | 89.0 | 94.5 | 41.2 | 67.0 |
| 0.2 | 89.1 | 94.8 | 41.8 | 67.2 |
| 0.3 | 89.0 | 94.6 | 42.6 | 67.8 |
| 0.4 | 89.0 | 94.4 | 43.8 | 68.7 |
| 0.5 | 89.4 | 95.0 | 44.3 | 69.5 |
| 0.6 | 89.2 | 94.4 | 43.0 | 68.1 |
| 0.7 | 89.3 | 94.4 | 42.8 | 68.0 |
| 0.8 | 89.2 | 94.6 | 42.4 | 67.7 |
| 0.9 | 89.2 | 94.3 | 41.8 | 67.3 |
| 1.0 | 89.0 | 94.3 | 41.5 | 67.0 |
Tab. 5 Influence of loss weight on model precision
| 参数 | Market-1501 | MSMT17 | ||
|---|---|---|---|---|
| mAP/% | Rank-1/% | mAP/% | Rank-1/% | |
| 0.0 | 88.2 | 94.2 | 40.9 | 66.4 |
| 0.1 | 89.0 | 94.5 | 41.2 | 67.0 |
| 0.2 | 89.1 | 94.8 | 41.8 | 67.2 |
| 0.3 | 89.0 | 94.6 | 42.6 | 67.8 |
| 0.4 | 89.0 | 94.4 | 43.8 | 68.7 |
| 0.5 | 89.4 | 95.0 | 44.3 | 69.5 |
| 0.6 | 89.2 | 94.4 | 43.0 | 68.1 |
| 0.7 | 89.3 | 94.4 | 42.8 | 68.0 |
| 0.8 | 89.2 | 94.6 | 42.4 | 67.7 |
| 0.9 | 89.2 | 94.3 | 41.8 | 67.3 |
| 1.0 | 89.0 | 94.3 | 41.5 | 67.0 |
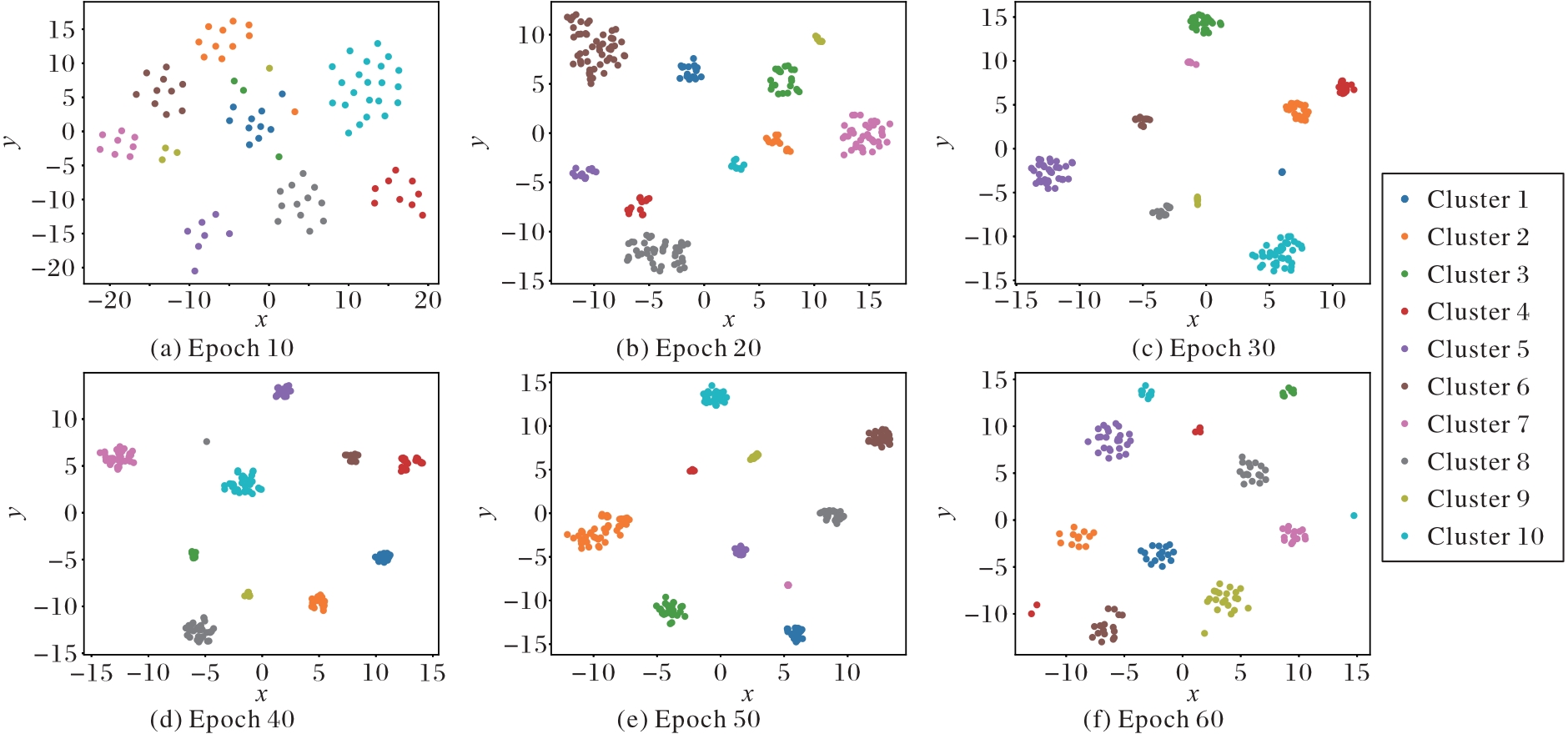
Fig. 2 t-SNE visualization results of model trained by baseline method
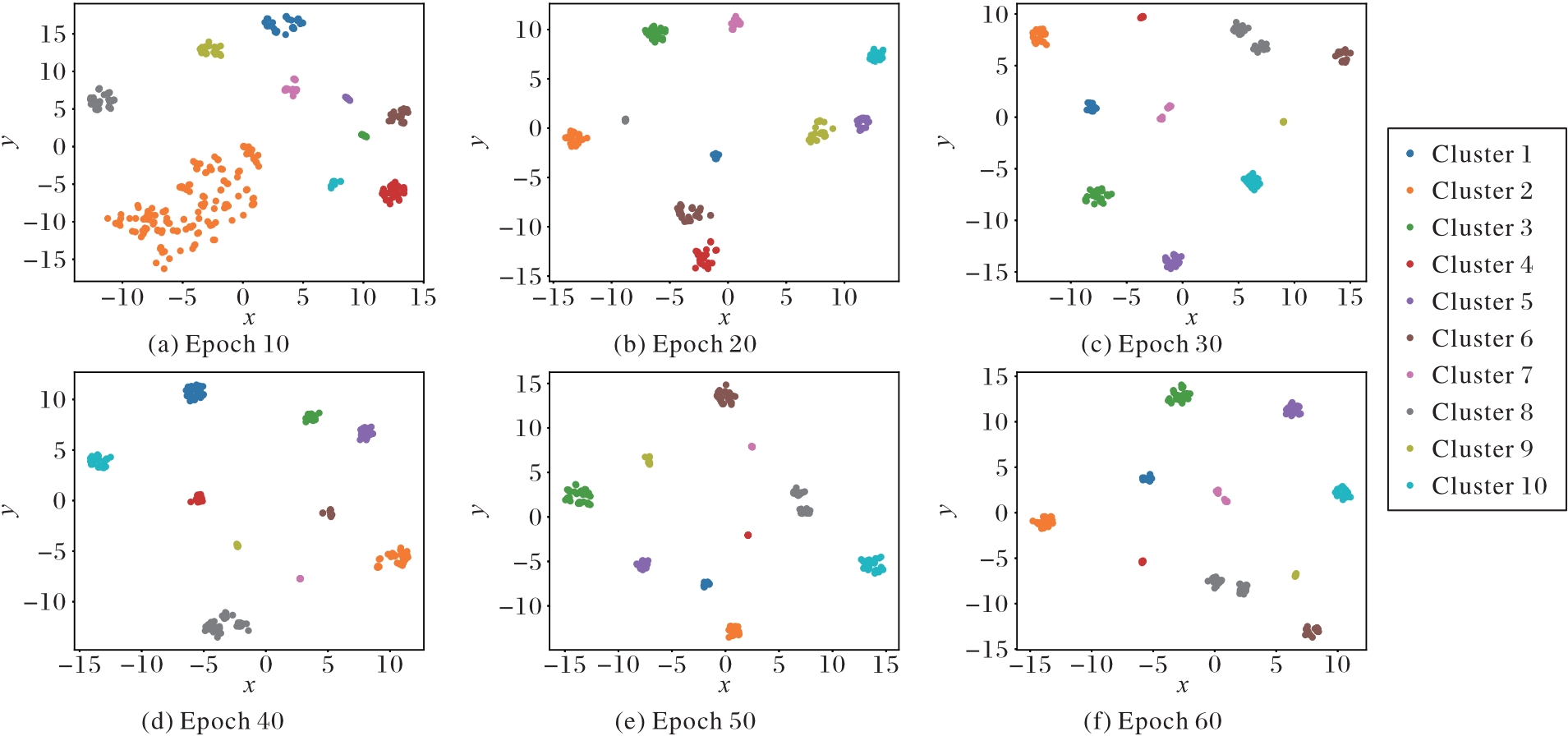
Fig. 3 t-SNE visualization results of model trained by proposed method

Fig. 4 Retrieval visualization results of proposed method

Fig. 5 Heatmap visualization results of different methods
| 1 | 何嘉明,杨巨成,吴超,等. 基于多模态图卷积神经网络的行人重识别方法[J]. 计算机应用, 2023, 43(7): 2182-2189. |
| HE J M, YANG J C, WU C, et al. Person re-identification method based on multi-modal graph convolutional neural network [J]. Journal of Computer Applications, 2023, 43(7): 2182-2189. | |
| 2 | 陈代丽,许国良. 基于注意力机制学习域内变化的跨域行人重识别方法[J]. 计算机应用, 2022, 42(5): 1391-1397. |
| CHEN D L, XU G L. Cross-domain person re-identification method based on attention mechanism with learning intra-domain variance [J]. Journal of Computer Applications, 2022, 42(5): 1391-1397. | |
| 3 | 姚英茂,姜晓燕. 基于图卷积网络与自注意力图池化的视频行人重识别方法[J]. 计算机应用, 2023, 43(3): 728-735. |
| YAO Y M, JIANG X Y. Video-based person re-identification method based on graph convolution network and self-attention graph pooling[J]. Journal of Computer Applications, 2023, 43(3): 728-735. | |
| 4 | PENG J, JIANG G, WANG H. Adaptive memorization with group labels for unsupervised person re-identification [J]. IEEE Transactions on Circuits and Systems for Video Technology, 2023, 33(10): 5802-5813. |
| 5 | CHEN F, WANG N, TANG J, et al. Unsupervised person re-identification via multi-domain joint learning [J]. Pattern Recognition, 2023, 138: No.109369. |
| 6 | LAN L, TENG X, ZHANG J, et al. Learning to purification for unsupervised person re-identification [J]. IEEE Transactions on Image Processing, 2023, 32: 3338-3353. |
| 7 | FAN H, ZHENG L, YAN C, et al. Unsupervised person re-identification: clustering and fine-tuning [J]. ACM Transactions on Multimedia Computing, Communications, and Applications, 2018, 14(4): No.83. |
| 8 | HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 770-778. |
| 9 | LLOYD S. Least squares quantization in PCM [J]. IEEE Transactions on Information Theory, 1982, 28(2): 129-137. |
| 10 | ESTER M, KRIEGEL H P, SANDER J, et al. A density-based algorithm for discovering clusters in large spatial databases with noise [C]// Proceedings of the 2nd International Conference on Knowledge Discovery and Data Mining. Palo Alto: AAAI Press, 1996: 226-231. |
| 11 | DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16x16 words: Transformers for image recognition at scale[EB/OL]. (2021-06-03) [2023-06-13]. . |
| 12 | FU Y, WEI Y, WANG G, et al. Self-similarity grouping: a simple unsupervised cross domain adaptation approach for person re-identification [C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 6111-6120. |
| 13 | GE Y, CHEN D, LI H. Mutual mean-teaching: pseudo label refinery for unsupervised domain adaptation on person re-identification [EB/OL]. (2020-01-30) [2023-05-12]. . |
| 14 | GE Y, ZHU F, CHEN D, et al. Self-paced contrastive learning with hybrid memory for domain adaptive object re-ID [C]// Proceedings of the 34th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2020: 11309-11321. |
| 15 | DAI Z, WANG G, YUAN W, et al. Cluster contrast for unsupervised person re-identification [C]// Proceedings of the 2022 Asian Conference on Computer Vision, LNCS 13846. Cham: Springer, 2023: 319-337. |
| 16 | HU Z, ZHU C, HE G. Hard-sample guided hybrid contrast learning for unsupervised person re-identification [C]// Proceedings of the 7th IEEE International Conference on Network Intelligence and Digital Content. Piscataway: IEEE, 2021: 91-95. |
| 17 | LAI S, CHAI Z, WEI X. Transformer meets part model: adaptive part division for person re-identification [C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision Workshops. Piscataway: IEEE, 2021: 4133-4140. |
| 18 | SUN Y, ZHENG L, YANG Y, et al. Beyond part models: person retrieval with refined part pooling (and a strong convolutional baseline) [C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11208. Cham: Springer, 2018: 501-518. |
| 19 | WANG G, YUAN Y, CHEN X, et al. Learning discriminative features with multiple granularities for person re-identification[C]// Proceedings of the 26th ACM International Conference on Multimedia. New York: ACM, 2018: 274-282. |
| 20 | ZHANG G, ZHANG P, QI J, et al. HAT: hierarchical aggregation Transformers for person re-identification [C]// Proceedings of the 29th ACM International Conference on Multimedia. New York: ACM, 2021: 516-525. |
| 21 | LI Y, HE J, ZHANG T, et al. Diverse part discovery: occluded person re-identification with part-aware Transformer [C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 2897-2906. |
| 22 | HE S, LUO H, WANG P, et al. TransReID: Transformer-based object re-identification [C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 14993-15002. |
| 23 | LIAO S, SHAO L. TransMatcher: deep image matching through Transformers for generalizable person re-identification [C]// Proceedings of the 35th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2021: 1992-2003. |
| 24 | NI H, LI Y, GAO L, et al. Part-aware Transformer for generalizable person re-identification [C]// Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2023: 11246-11255. |
| 25 | ZHU K, GUO H, ZHANG S, et al. AAformer: auto-aligned Transformer for person re-identification [J]. IEEE Transactions on Circuits and Systems for Video Technology, 2023(Early Access): 1-11. |
| 26 | LUO H, WANG P, XU Y, et al. Self-supervised pre-training for Transformer-based person re-identification [EB/OL]. (2021-11-23) [2023-06-13]. . |
| 27 | KRIZHEVSKY A, SUTSKEVER I, HINTON G E. ImageNet classification with deep convolutional neural networks [C]// Proceedings of the 25th International Conference on Neural Information Processing Systems — Volume 1. Red Hook: Curran Associates Inc., 2012: 1097-1105. |
| 28 | FU D, CHEN D, BAO J, et al. Unsupervised pre-training for person re-identification [C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 14745-14754. |
| 29 | TAO Y, ZHANG J, CHEN T, et al. Transformer-based contrastive learning for unsupervised person re-identification [C]// Proceedings of the 2022 International Joint Conference on Neural Networks. Piscataway: IEEE, 2022: 1-9. |
| 30 | D’ASCOLI S, TOUVRON H, LEAVITT M L, et al. ConViT: improving vision Transformers with soft convolutional inductive biases [C]// Proceedings of the 38th International Conference on Machine Learning. New York: JMLR.org, 2021: 2286-2296. |
| 31 | SUKHBAATAR S, GRAVE E, BOJANOWSKI P, et al. Adaptive attention span in Transformers [C]// Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2019: 331-335. |
| 32 | TOUVRON H, CORD M, DOUZE M, et al. Training data-efficient image Transformers & distillation through attention [C]// Proceedings of the 38th International Conference on Machine Learning. New York: JMLR.org, 2021: 10347-10357. |
| 33 | HINTON G, VINYALS O, DEAN J. Distilling the knowledge in a neural network [EB/OL]. (2015-03-09) [2023-07-09]. . |
| 34 | ZHANG L, SONG J, GAO A, et al. Be your own teacher: improve the performance of convolutional neural networks via self distillation [C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 3712-3721. |
| 35 | YUN S, PARK J, LEE K, et al. Regularizing class-wise predictions via self-knowledge distillation [C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 13873-13882. |
| 36 | WANG Y, LI H, CHAU L P, et al. Embracing the dark knowledge: domain generalization using regularized knowledge distillation [C]// Proceedings of the 29th ACM International Conference on Multimedia. New York: ACM, 2021: 2595-2604. |
| 37 | SULTANA M, NASEER M, KHAN M H, et al. Self-distilled vision Transformer for domain generalization [C]// Proceedings of the 2022 Asian Conference on Computer Vision, LNCS 13842. Cham: Springer, 2023: 273-290. |
| 38 | CHEN X, FAN H, GIRSHICK R, et al. Improved baselines with momentum contrastive learning [EB/OL]. (2020-03-09) [2024-03-23]. . |
| 39 | ZHENG L, SHEN L, TIAN L, et al. Scalable person re-identification: a benchmark [C]// Proceedings of the 2015 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2015: 1116-1124. |
| 40 | WEI L, ZHANG S, GAO W, et al. Person transfer GAN to bridge domain gap for person re-identification [C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 79-88. |
| 41 | WANG D, ZHANG S. Unsupervised person re-identification via multi-label classification [C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 10978-10987. |
| 42 | ZHENG K, LAN C, ZENG W, et al. Exploiting sample uncertainty for domain adaptive person re-identification [C]// Proceedings of the 35th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2021: 3538-3546. |
| 43 | LIN Y, DONG X, ZHENG L, et al. A bottom-up clustering approach to unsupervised person re-identification [C]// Proceedings of the 33rd AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2019: 8738-8745. |
| 44 | LIN Y, XIE L, WU Y, et al. Unsupervised person re-identification via softened similarity learning [C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 3387-3396. |
| 45 | ZENG K, NING M, WANG Y, et al. Hierarchical clustering with hard-batch triplet loss for person re-identification [C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 13654-13662. |
| 46 | WANG Z, ZHANG J, ZHENG L, et al. CycAs: self-supervised cycle association for learning re-identifiable descriptions [C]// Proceedings of the 2020 European Conference on Computer Vision, LNCS 12356. Cham: Springer, 2020: 72-88. |
| 47 | WU J, LIU H, YANG Y, et al. Unsupervised graph association for person re-identification [C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 8320-8329. |
| 48 | ZHONG Z, ZHENG L, LUO Z, et al. Invariance matters: exemplar memory for domain adaptive person re-identification[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 598-607. |
| 49 | LI M, ZHU X, GONG S. Unsupervised person re-identification by deep learning tracklet association [C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11208. Cham: Springer, 2018: 772-788. |
| 50 | VAN DER MAATEN L, HINTON G. Visualizing data using t-SNE[J]. Journal of Machine Learning Research, 2008, 9: 2579-2605. |
| 51 | SELVARAJU R R, COGSWELL M, DAS A, et al. Grad-CAM: visual explanations from deep networks via gradient-based localization [C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2017: 618-626. |
| [1] | Yubo ZHAO, Liping ZHANG, Sheng YAN, Min HOU, Mao GAO. Relation extraction between discipline knowledge entities based on improved piecewise convolutional neural network and knowledge distillation [J]. Journal of Computer Applications, 2024, 44(8): 2421-2429. |
| [2] | Cui WANG, Miaolei DENG, Dexian ZHANG, Lei LI, Xiaoyan YANG. Review of end-to-end person search algorithms based on images [J]. Journal of Computer Applications, 2024, 44(8): 2544-2550. |
| [3] | Xiawuji, Heming HUANG, Gengzangcuomao, Yutao FAN. Survey of extractive text summarization based on unsupervised learning and supervised learning [J]. Journal of Computer Applications, 2024, 44(4): 1035-1048. |
| [4] | Rong HUANG, Junjie SONG, Shubo ZHOU, Hao LIU. Image aesthetic quality evaluation method based on self-supervised vision Transformer [J]. Journal of Computer Applications, 2024, 44(4): 1269-1276. |
| [5] | Zongze JIA, Pengfei GAO, Yinglong MA, Xiaofeng LIU, Haixin XIA. Multi-feature fusion attention-based hierarchical classification method for dialogue act [J]. Journal of Computer Applications, 2024, 44(3): 715-721. |
| [6] | Xue LI, Guangle YAO, Honghui WANG, Jun LI, Haoran ZHOU, Shaoze YE. Remote sensing image classification based on sample incremental learning [J]. Journal of Computer Applications, 2024, 44(3): 732-736. |
| [7] | Rui JIANG, Wei LIU, Cheng CHEN, Tao LU. Asymmetric unsupervised end-to-end image deraining network [J]. Journal of Computer Applications, 2024, 44(3): 922-930. |
| [8] | Yuxin HUANG, Yiwang HUANG, Hui HUANG. Meta label correction method based on shallow network predictions [J]. Journal of Computer Applications, 2024, 44(11): 3364-3370. |
| [9] | Pei ZHAO, Yan QIAO, Rongyao HU, Xinyu YUAN, Minyue LI, Benchu ZHANG. Multivariate time series anomaly detection based on multi-domain feature extraction [J]. Journal of Computer Applications, 2024, 44(11): 3419-3426. |
| [10] | Nengbing HU, Biao CAI, Xu LI, Danhua CAO. Graph classification method based on graph pooling contrast learning [J]. Journal of Computer Applications, 2024, 44(11): 3327-3334. |
| [11] | Fu LIN, Jiasheng SHI, Ze GAO, Zunkang CHU, Qiongmin MA, Haiyan YU, Weixiong RAO. Physical system simulation based on deep representation learning for 3D geometric features [J]. Journal of Computer Applications, 2024, 44(11): 3548-3555. |
| [12] | Wen ZHOU, Yuzhang CHEN, Zhiyuan WEN, Shiqi WANG. Fish image classification based on positional overlapping patch embedding and multi-scale channel interactive attention [J]. Journal of Computer Applications, 2024, 44(10): 3209-3216. |
| [13] | Xujian ZHAO, Hanglin LI. Deep neural network compression algorithm based on hybrid mechanism [J]. Journal of Computer Applications, 2023, 43(9): 2686-2691. |
| [14] | Zhangjian JI, Ming ZHANG, Zilong WANG. High-precision object detection algorithm based on improved VarifocalNet [J]. Journal of Computer Applications, 2023, 43(7): 2147-2154. |
| [15] | Menglin HUANG, Lei DUAN, Yuanhao ZHANG, Peiyan WANG, Renhao LI. Prompt learning based unsupervised relation extraction model [J]. Journal of Computer Applications, 2023, 43(7): 2010-2016. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||