


Journal of Computer Applications ›› 2025, Vol. 45 ›› Issue (10): 3170-3178.DOI: 10.11772/j.issn.1001-9081.2024101527
• Artificial intelligence • Previous Articles
Jiaqi YUAN1, Rong HUANG1,2( ), Aihua DONG1,2, Shubo ZHOU1,2, Hao LIU1,2
), Aihua DONG1,2, Shubo ZHOU1,2, Hao LIU1,2
Received:2024-10-15
Revised:2025-01-06
Accepted:2025-01-07
Online:2025-01-22
Published:2025-10-10
Contact:
Rong HUANG
About author:YUAN Jiaqi, born in 1999, M. S. candidate. His research interests include deep learning, human parsing.Supported by:
袁家奇1, 黄荣1,2(), 董爱华1,2, 周树波1,2, 刘浩1,2
通讯作者:
黄荣
作者简介:袁家奇(1999—),男,湖南常德人,硕士研究生,CCF会员,主要研究方向:深度学习、人体解析基金资助:CLC Number:
Jiaqi YUAN, Rong HUANG, Aihua DONG, Shubo ZHOU, Hao LIU. Human parsing method with aggregation of generalized contextual features[J]. Journal of Computer Applications, 2025, 45(10): 3170-3178.
袁家奇, 黄荣, 董爱华, 周树波, 刘浩. 聚合广义上下文特征的人体解析方法[J]. 《计算机应用》唯一官方网站, 2025, 45(10): 3170-3178.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2024101527

Fig. 1 Design motivation of RBAM and CSAM
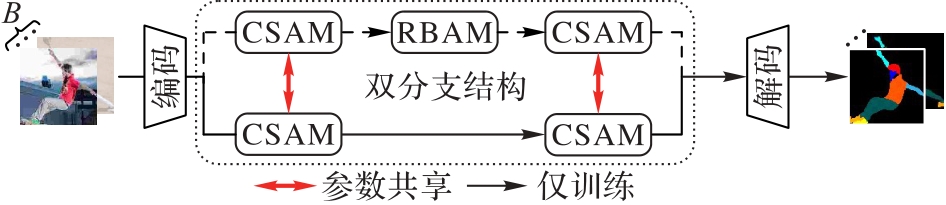
Fig. 2 Structure of generalized contextual features aggregation network
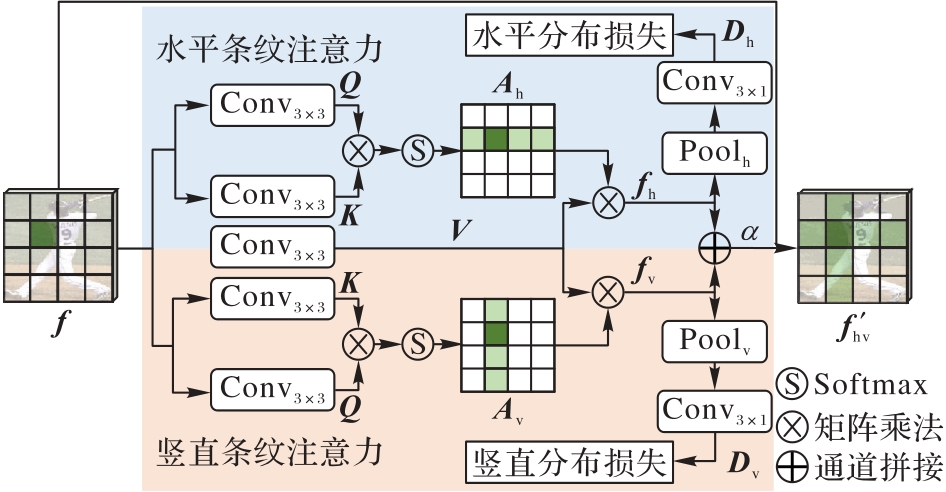
Fig. 3 Structure of cross-stripe attention module

Fig. 4 Structure of region-aware batch attention module
| 方法 | hat | hair | glove | glass | upper-clothes | dress | coat | socks | pants | j-suit | scarf |
|---|---|---|---|---|---|---|---|---|---|---|---|
| JPPNet[ | 63.55 | 70.20 | 36.16 | 23.48 | 68.15 | 31.42 | 55.65 | 44.56 | 72.19 | 28.39 | 18.76 |
| CE2P[ | 65.29 | 72.54 | 39.09 | 32.73 | 69.46 | 32.52 | 56.28 | 49.67 | 74.11 | 27.23 | 14.19 |
| PGEC[ | 66.36 | 72.83 | 40.76 | 32.85 | 69.93 | 33.78 | 56.48 | 48.86 | 74.51 | 28.20 | 25.16 |
| SNT[ | 66.90 | 72.20 | 42.70 | 32.30 | 70.10 | 33.80 | 57.50 | 48.90 | 75.20 | 32.50 | 19.40 |
| SMDC[ | 66.76 | 72.98 | 42.91 | 32.77 | 70.24 | 37.78 | 57.40 | 50.88 | 75.46 | 32.38 | 23.26 |
| CorrPM[ | 66.20 | 71.56 | 41.06 | 31.09 | 70.20 | 37.74 | 57.95 | 48.40 | 75.19 | 32.37 | 23.79 |
| GWNet[ | 69.23 | 45.03 | 35.22 | 72.89 | 36.94 | 61.05 | 51.45 | 76.82 | 39.20 | ||
| PARNet[ | 68.06 | 72.11 | 49.94 | 37.79 | 69.84 | 57.11 | 51.69 | 76.38 | 28.33 | 27.07 | |
| SCHP[ | 73.55 | 50.46 | 40.72 | 69.93 | 39.02 | 57.45 | 54.27 | 76.01 | 32.88 | 26.29 | |
| PRM[ | 70.83 | 74.22 | 40.02 | 38.52 | 53.64 | 78.51 | 32.51 | ||||
| CDGNet[ | 69.27 | 74.14 | 50.26 | 70.02 | 37.28 | 56.98 | 54.11 | 76.28 | 32.26 | 28.40 | |
| DTML[ | 68.07 | 73.86 | 43.62 | 34.27 | 75.23 | 56.63 | 66.34 | 49.56 | 43.45 | 30.78 | |
| 本文方法 | 69.80 | 74.36 | 50.30 | 41.68 | 70.33 | 38.21 | 58.18 | 77.20 | 32.19 | 29.35 | |
| 方法 | skirt | face | l-arm | r-arm | l-leg | r-leg | left-shos | r-shoe | background | 平均值 | |
| JPPNet[ | 25.14 | 73.36 | 61.97 | 63.88 | 58.21 | 57.99 | 44.02 | 44.09 | 86.26 | 51.37 | |
| CE2P[ | 22.51 | 75.50 | 65.14 | 66.59 | 60.10 | 58.59 | 46.63 | 46.12 | 87.67 | 53.10 | |
| PGEC[ | 26.52 | 75.34 | 65.69 | 67.33 | 59.36 | 58.82 | 47.77 | 47.78 | 87.74 | 54.30 | |
| SNT[ | 27.40 | 74.90 | 65.80 | 68.10 | 60.03 | 59.80 | 47.60 | 48.10 | 88.20 | 54.70 | |
| SMDC[ | 27.74 | 75.98 | 65.81 | 68.09 | 60.30 | 59.87 | 47.61 | 47.89 | 55.21 | 55.21 | |
| CorrPM[ | 29.23 | 74.36 | 66.53 | 68.61 | 62.80 | 62.81 | 49.03 | 49.82 | 87.77 | 55.33 | |
| GWNet[ | 34.01 | 76.21 | 66.89 | 68.68 | 60.16 | 60.72 | 48.01 | 48.33 | 88.50 | 57.26 | |
| PARNet[ | 29.81 | 75.79 | 70.06 | 71.84 | 70.22 | 68.92 | 57.24 | 57.68 | 88.06 | 58.39 | |
| SCHP[ | 31.68 | 76.19 | 68.65 | 70.92 | 67.28 | 66.56 | 55.76 | 56.50 | 88.36 | 58.62 | |
| PRM[ | 77.26 | 68.52 | 68.92 | 62.32 | 61.35 | 49.64 | 49.75 | 58.86 | |||
| CDGNet[ | 30.56 | 76.54 | 71.54 | 68.83 | 68.00 | 58.41 | 88.52 | ||||
| DTML[ | 38.29 | 76.45 | 67.21 | 68.80 | 62.32 | 62.22 | 49.37 | 50.19 | 89.11 | 59.02 | |
| 本文方法 | 30.50 | 70.55 | 58.13 | 88.71 | 59.45 |
Tab. 1 Quantitative results comparison of per-class IoU of different methods on LIP validation set
| 方法 | hat | hair | glove | glass | upper-clothes | dress | coat | socks | pants | j-suit | scarf |
|---|---|---|---|---|---|---|---|---|---|---|---|
| JPPNet[ | 63.55 | 70.20 | 36.16 | 23.48 | 68.15 | 31.42 | 55.65 | 44.56 | 72.19 | 28.39 | 18.76 |
| CE2P[ | 65.29 | 72.54 | 39.09 | 32.73 | 69.46 | 32.52 | 56.28 | 49.67 | 74.11 | 27.23 | 14.19 |
| PGEC[ | 66.36 | 72.83 | 40.76 | 32.85 | 69.93 | 33.78 | 56.48 | 48.86 | 74.51 | 28.20 | 25.16 |
| SNT[ | 66.90 | 72.20 | 42.70 | 32.30 | 70.10 | 33.80 | 57.50 | 48.90 | 75.20 | 32.50 | 19.40 |
| SMDC[ | 66.76 | 72.98 | 42.91 | 32.77 | 70.24 | 37.78 | 57.40 | 50.88 | 75.46 | 32.38 | 23.26 |
| CorrPM[ | 66.20 | 71.56 | 41.06 | 31.09 | 70.20 | 37.74 | 57.95 | 48.40 | 75.19 | 32.37 | 23.79 |
| GWNet[ | 69.23 | 45.03 | 35.22 | 72.89 | 36.94 | 61.05 | 51.45 | 76.82 | 39.20 | ||
| PARNet[ | 68.06 | 72.11 | 49.94 | 37.79 | 69.84 | 57.11 | 51.69 | 76.38 | 28.33 | 27.07 | |
| SCHP[ | 73.55 | 50.46 | 40.72 | 69.93 | 39.02 | 57.45 | 54.27 | 76.01 | 32.88 | 26.29 | |
| PRM[ | 70.83 | 74.22 | 40.02 | 38.52 | 53.64 | 78.51 | 32.51 | ||||
| CDGNet[ | 69.27 | 74.14 | 50.26 | 70.02 | 37.28 | 56.98 | 54.11 | 76.28 | 32.26 | 28.40 | |
| DTML[ | 68.07 | 73.86 | 43.62 | 34.27 | 75.23 | 56.63 | 66.34 | 49.56 | 43.45 | 30.78 | |
| 本文方法 | 69.80 | 74.36 | 50.30 | 41.68 | 70.33 | 38.21 | 58.18 | 77.20 | 32.19 | 29.35 | |
| 方法 | skirt | face | l-arm | r-arm | l-leg | r-leg | left-shos | r-shoe | background | 平均值 | |
| JPPNet[ | 25.14 | 73.36 | 61.97 | 63.88 | 58.21 | 57.99 | 44.02 | 44.09 | 86.26 | 51.37 | |
| CE2P[ | 22.51 | 75.50 | 65.14 | 66.59 | 60.10 | 58.59 | 46.63 | 46.12 | 87.67 | 53.10 | |
| PGEC[ | 26.52 | 75.34 | 65.69 | 67.33 | 59.36 | 58.82 | 47.77 | 47.78 | 87.74 | 54.30 | |
| SNT[ | 27.40 | 74.90 | 65.80 | 68.10 | 60.03 | 59.80 | 47.60 | 48.10 | 88.20 | 54.70 | |
| SMDC[ | 27.74 | 75.98 | 65.81 | 68.09 | 60.30 | 59.87 | 47.61 | 47.89 | 55.21 | 55.21 | |
| CorrPM[ | 29.23 | 74.36 | 66.53 | 68.61 | 62.80 | 62.81 | 49.03 | 49.82 | 87.77 | 55.33 | |
| GWNet[ | 34.01 | 76.21 | 66.89 | 68.68 | 60.16 | 60.72 | 48.01 | 48.33 | 88.50 | 57.26 | |
| PARNet[ | 29.81 | 75.79 | 70.06 | 71.84 | 70.22 | 68.92 | 57.24 | 57.68 | 88.06 | 58.39 | |
| SCHP[ | 31.68 | 76.19 | 68.65 | 70.92 | 67.28 | 66.56 | 55.76 | 56.50 | 88.36 | 58.62 | |
| PRM[ | 77.26 | 68.52 | 68.92 | 62.32 | 61.35 | 49.64 | 49.75 | 58.86 | |||
| CDGNet[ | 30.56 | 76.54 | 71.54 | 68.83 | 68.00 | 58.41 | 88.52 | ||||
| DTML[ | 38.29 | 76.45 | 67.21 | 68.80 | 62.32 | 62.22 | 49.37 | 50.19 | 89.11 | 59.02 | |
| 本文方法 | 30.50 | 70.55 | 58.13 | 88.71 | 59.45 |
| 方法 | 像素准确率 | 平均精度 | mIoU |
|---|---|---|---|
| CE2P[ | 87.37 | 63.20 | 53.10 |
| PGEC[ | 87.50 | 65.66 | 54.30 |
| SNT[ | 88.05 | 66.42 | 54.73 |
| SMDC[ | 88.12 | 66.53 | 55.21 |
| CorrPM[ | 87.68 | 67.21 | 55.33 |
| PARNet[ | 88.01 | 58.39 | |
| SCHP[ | 88.15 | 72.76 | 58.62 |
| CDGNet[ | 70.02 | ||
| 本文方法 | 88.66 | 71.13 | 59.45 |
Tab. 2 Comparison of quantitative results on LIP validation set
| 方法 | 像素准确率 | 平均精度 | mIoU |
|---|---|---|---|
| CE2P[ | 87.37 | 63.20 | 53.10 |
| PGEC[ | 87.50 | 65.66 | 54.30 |
| SNT[ | 88.05 | 66.42 | 54.73 |
| SMDC[ | 88.12 | 66.53 | 55.21 |
| CorrPM[ | 87.68 | 67.21 | 55.33 |
| PARNet[ | 88.01 | 58.39 | |
| SCHP[ | 88.15 | 72.76 | 58.62 |
| CDGNet[ | 70.02 | ||
| 本文方法 | 88.66 | 71.13 | 59.45 |
| 方法 | 像素准确率 | 平均精度 | 召回率 |
|---|---|---|---|
| CoCNN[ | 96.02 | 84.59 | 77.66 |
| TGPNet[ | 96.45 | 83.36 | 80.22 |
| CNIF[ | 96.26 | 84.62 | 86.41 |
| PARNet[ | 96.41 | 86.00 | 86.44 |
| PGEC[ | 97.03 | 86.61 | 84.31 |
| CorrPM[ | 97.12 | 89.18 | 83.93 |
| CDGNet[ | 87.46 | ||
| 本文方法 | 97.98 | 87.43 |
Tab. 3 Comparison of quantitative results on ATR validation set
| 方法 | 像素准确率 | 平均精度 | 召回率 |
|---|---|---|---|
| CoCNN[ | 96.02 | 84.59 | 77.66 |
| TGPNet[ | 96.45 | 83.36 | 80.22 |
| CNIF[ | 96.26 | 84.62 | 86.41 |
| PARNet[ | 96.41 | 86.00 | 86.44 |
| PGEC[ | 97.03 | 86.61 | 84.31 |
| CorrPM[ | 97.12 | 89.18 | 83.93 |
| CDGNet[ | 87.46 | ||
| 本文方法 | 97.98 | 87.43 |

Fig. 5 Comparison of qualitative results on LIP dataset
| CSAM×1 | CSAM×2 | RBAM | BAM | mIoU |
|---|---|---|---|---|
| 56.92 | ||||
| √ | 58.16 | |||
| √ | 59.23 | |||
| √ | 58.12 | |||
| √ | √ | 59.45 | ||
| √ | √ | 59.30 |
Tab. 4 Ablation experimental results of each component on LIP dataset
| CSAM×1 | CSAM×2 | RBAM | BAM | mIoU |
|---|---|---|---|---|
| 56.92 | ||||
| √ | 58.16 | |||
| √ | 59.23 | |||
| √ | 58.12 | |||
| √ | √ | 59.45 | ||
| √ | √ | 59.30 |
| 方法 | 浮点运算数/GFLOPs | mIoU/% |
|---|---|---|
| NL | 0.710 22 | 59.01 |
| CSAM×1 | 0.297 40 | 58.16 |
| CSAM×2 | 0.594 79 | 59.23 |
Tab. 5 Comparison of computational complexity between CSAM and global attention mechanism
| 方法 | 浮点运算数/GFLOPs | mIoU/% |
|---|---|---|
| NL | 0.710 22 | 59.01 |
| CSAM×1 | 0.297 40 | 58.16 |
| CSAM×2 | 0.594 79 | 59.23 |

Fig. 6 Visualization of weights for cross-stripe attention and its extended global attention

Fig. 7 Visualization of region-aware batch attention weights
| [1] | 高明达,孙玉宝,刘青山,等. 联合姿态先验的人体精确解析双分支网络模型[J]. 软件学报, 2020, 31(7): 1959-1968. |
| GAO M D, SUN Y B, LIU Q S, et al. Posture prior driven double-branch network model for accurate human parsing[J]. Journal of Software, 2020, 31(7): 1959-1968. | |
| [2] | 甘霖,刘骊,刘利军,等. 结合边缘轮廓和姿态特征的人体精确解析模型[J]. 计算机辅助设计与图形学学报, 2021, 33(9): 1428-1439. |
| GAN L, LIU L, LIU L J, et al. Accurate human parsing model by edge contour and pose feature[J]. Journal of Computer-Aided Design and Computer Graphics, 2021, 33(9): 1428-1439. | |
| [3] | 张宇,温光照,米思娅,等. 基于深度学习的二维人体姿态估计综述[J]. 软件学报, 2022, 33(11): 4173-4191. |
| ZHANG Y, WEN G Z, MI S Y, et al. Overview on 2D human pose estimation based on deep learning[J]. Journal of Software, 2022, 33(11): 4173-4191. | |
| [4] | ZHU T, KARLSSON P, BREGLER C. SimPose: effectively learning DensePose and surface normals of people from simulated data[C]// Proceedings of the 2020 European Conference on Computer Vision, LNCS 12374. Cham: Springer, 2020:225-242. |
| [5] | ZHU K, GUO H, LIU Z, et al. Identity-guided human semantic parsing for person re-identification[C]// Proceedings of the 2020 European Conference on Computer Vision, LNCS 12348. Cham: Springer, 2020: 346-363. |
| [6] | 邵晓雯,帅惠,刘青山. 融合属性特征的行人重识别方法[J]. 自动化学报, 2022, 48(2): 564-571. |
| SHAO X W, SHU H, LIU Q S. Person re-identification based on fused attribute features[J]. Acta Automatica Sinica, 2022, 48(2): 564-571. | |
| [7] | XIE Z, HUANG Z, DONG X, et al. GP-VTON: towards general purpose virtual try-on via collaborative local-flow global-parsing learning[C]// Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2023: 23550-23559. |
| [8] | 谭泽霖,白静. 二维图像虚拟试衣技术综述[J]. 计算机工程与应用, 2023, 59(15): 17-26. |
| TAN Z L, BAI J. Survey of two-dimensional image virtual try-on technology[J]. Computer Engineering and Applications, 2023, 59(15): 17-26. | |
| [9] | ZHANG L, RAO A, AGRAWALA M. Adding conditional control to text-to-image diffusion models[C]// Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2023: 3813-3824. |
| [10] | 田萱,王亮,丁琪. 基于深度学习的图像语义分割方法综述[J]. 软件学报, 2019, 30(2): 440-468. |
| TIAN X, WANG L, DING Q. Review of image semantic segmentation based on deep learning[J]. Journal of Software, 2019, 30(2): 440-468. | |
| [11] | 罗会兰,张云. 基于深度网络的图像语义分割综述[J]. 电子学报, 2019, 47(10): 2211-2220. |
| LUO H L, ZHANG Y. A survey of image semantic segmentation based on deep network[J]. Acta Electronica Sinica, 2019, 47(10): 2211-2220. | |
| [12] | YUAN Y, CHEN X, WANG J. Object-contextual representations for semantic segmentation[C]// Proceedings of the 16th European Conference on Computer Vision, LNCS 12351. Cham: Springer, 2020:173-190. |
| [13] | JI R, DU D, ZHANG L, et al. Learning semantic neural tree for human parsing[C]// Proceedings of the 16th European Conference on Computer Vision, LNCS 12358. Cham: Springer, 2020:205-221. |
| [14] | WANG W, ZHU H, DAI J, et al. Hierarchical human parsing with typed part-relation reasoning[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 8926-8936. |
| [15] | WANG W, ZHANG Z, QI S, et al. Learning compositional neural information fusion for human parsing[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 5702-5712. |
| [16] | LIU Y, ZHANG S, YANG J, et al. Hierarchical information passing based noise-tolerant hybrid learning for semi-supervised human parsing[C]// Proceedings of the 35th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2021: 2207-2215. |
| [17] | ZHANG X, CHEN Y, TANG M, et al. Grammar-induced wavelet network for human parsing[J]. IEEE Transactions on Image Processing, 2022, 31: 4502-4514. |
| [18] | YANG B, YU C, YU J G, et al. Pose-guided hierarchical semantic decomposition and composition for human parsing[J]. IEEE Transactions on Cybernetics, 2023, 53(3): 1641-1652. |
| [19] | ZHANG X, CHEN Y, ZHU B, et al. Part-aware context network for human parsing[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 8968-8977. |
| [20] | LI T, LIANG Z, ZHAO S, et al. Self-learning with rectification strategy for human parsing[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 9260-9269. |
| [21] | HE H, ZHANG J, ZHANG Q, et al. Grapy-ML: graph pyramid mutual learning for cross-dataset human parsing[C]// Proceedings of the 34th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2020:10949-10956. |
| [22] | ZHANG X, CHEN Y, TANG M, et al. Human parsing with part-aware relation modeling[J]. IEEE Transactions on Multimedia, 2023, 25: 2601-2612. |
| [23] | YANG J, WANG C, LI Z, et al. Semantic human parsing via scalable semantic transfer over multiple label domains[C]// Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2023: 19424-19433. |
| [24] | LIU K, CHOI O, WANG J, et al. CDGNet: class distribution guided network for human parsing[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 4463-4472. |
| [25] | CHEN L, GU L, ZHENG D, et al. Frequency-adaptive dilated convolution for semantic segmentation[C]// Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2024: 3414-3425. |
| [26] | WANG W, DAI J, CHEN Z, et al. InternImage: exploring large-scale vision foundation models with deformable convolutions[C]// Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2023: 14408-14419. |
| [27] | ZHAO H, SHI J, QI X, et al. Pyramid scene parsing network[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 6230-6239. |
| [28] | CHEN Y, ROHRBACH M, YAN Z, et al. Graph-based global reasoning networks[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 433-442. |
| [29] | XIE E, WANG W, YU Z, et al. SegFormer: simple and efficient design for semantic segmentation with Transformers[C]// Proceedings of the 35th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2021: 12077-12090. |
| [30] | ZHENG S, LU J, ZHAO H, et al. Rethinking semantic segmentation from a sequence-to-sequence perspective with Transformers[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 6877-6886. |
| [31] | HUANG Z, WANG X, HUANG L, et al. CCNet: criss-cross attention for semantic segmentation[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 603-612. |
| [32] | DONG X, BAO J, CHEN D, et al. CSWin Transformer: a general vision Transformer backbone with cross-shaped windows[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 12114-12124. |
| [33] | LIU Z, LIN Y, CAO Y, et al. Swin Transformer: hierarchical vision Transformer using shifted windows[C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 9992-10002. |
| [34] | CHENG B, MISRA I, SCHWING A G, et al. Masked-attention mask Transformer for universal image segmentation[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 1280-1289. |
| [35] | JIN Z, YU D, YUAN Z, et al. MCIBI++: soft mining contextual information beyond image for semantic segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(5): 5988-6005. |
| [36] | ZHANG Z, SU C, ZHENG L, et al. Correlating edge, pose with parsing[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 8897-8906. |
| [37] | ZHOU Y, MOK P Y. A pose-aware global representation network for human parsing[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2023, 33(4): 1710-1724. |
| [38] | RUAN T, LIU T, HUANG Z, et al. Devil in the details: towards accurate single and multiple human parsing[C]// Proceedings of the 33rd AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2019: 4814-4821. |
| [39] | ZHANG S, QI G J, CAO X, et al. Human parsing with pyramidical gather-excite context[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2021, 31(3): 1016-1030. |
| [40] | LIU Y, WANG C, LU M, et al. From simple to complex scenes: learning robust feature representations for accurate human parsing[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024, 46(8): 5449-5462. |
| [41] | HOU Z, YU B, WANG C, et al. BatchFormerV2: exploring sample relationships for dense representation learning[EB/OL]. [2023-05-30].. |
| [42] | LIANG X, GONG K, SHEN X, et al. Look into person: joint body parsing & pose estimation network and a new benchmark[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019, 41(4): 871-885. |
| [43] | LIANG X, XU C, SHEN X, et al. Human parsing with contextualized convolutional neural network[C]// Proceedings of the 2015 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2015: 1386-1394. |
| [44] | HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 770-778. |
| [45] | LI P, XU Y, WEI Y, et al. Self-correction for human parsing[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44(6): 3260-3271. |
| [46] | LUO X, SU Z, GUO J, et al. Trusted guidance pyramid network for human parsing[C]// Proceedings of the 26th ACM International Conference on Multimedia. New York: ACM, 2018: 654-662. |
| [1] | Pengfei ZHANG, Litao HAN, Hengjian FENG, Hongmei LI. Point cloud semantic segmentation based on attention mechanism and global feature optimization [J]. Journal of Computer Applications, 2024, 44(4): 1086-1092. |
| [2] | Keyi FU, Gaocai WANG, Man WU. Few-shot object detection method based on improved region proposal network and feature aggregation [J]. Journal of Computer Applications, 2024, 44(12): 3790-3797. |
| [3] | Xueyu HUANG, Huaiyu HE, Huimin LIN, Jinshui CHEN. Classification and recognition method of copper alloy metallograph based on feature aggregation [J]. Journal of Computer Applications, 2023, 43(8): 2593-2601. |
| [4] | Xin ZHAO, Qianqian ZHU, Cong ZHAO, Jialing WU. Segmentation of breast nodules in ultrasound images based on multi-scale and cross-spatial fusion [J]. Journal of Computer Applications, 2023, 43(11): 3599-3606. |
| [5] | HE Hansen, SUN Guozi. Fake news content detection model based on feature aggregation [J]. Journal of Computer Applications, 2020, 40(8): 2189-2193. |
| [6] | GUO Mingxiang, SONG Quanjun, XU Zhannan, DONG Jun, XIE Chengjun. Human behavior recognition algorithm based on three-dimensional residual dense network [J]. Journal of Computer Applications, 2019, 39(12): 3482-3489. |
| [7] | CHEN Hongyu, DENG Dexiang, YAN Jia, FAN Ci'en. Image retrieval algorithm based on saliency semantic region weighting [J]. Journal of Computer Applications, 2019, 39(1): 136-142. |
| [8] | GUO Chuanlei, HE Jia. Improved single shot multibox detector based on the transposed convolution [J]. Journal of Computer Applications, 2018, 38(10): 2833-2838. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||