


Journal of Computer Applications ›› 0, Vol. ›› Issue (): 1-6.DOI: 10.11772/j.issn.1001-9081.2024050667
• Artificial intelligence • Previous Articles Next Articles
Mengke CHEN1,2, Yun BIAN1( ), Yunhao LIANG1,2, Haiquan WANG1,2
), Yunhao LIANG1,2, Haiquan WANG1,2
Received:2024-05-27
Revised:2024-06-26
Accepted:2024-07-01
Online:2025-01-24
Published:2024-12-31
Contact:
Yun BIAN
陈孟科1,2, 边赟1(), 梁云浩1,2, 王海全1,2
通讯作者:
边赟
作者简介:陈孟科(1998—),男,四川巴中人,硕士研究生,主要研究方向:自然语言处理、大语言模型CLC Number:
Mengke CHEN, Yun BIAN, Yunhao LIANG, Haiquan WANG. WH-CoT: 6W2H-based chain-of-thought prompting framework on large language models[J]. Journal of Computer Applications, 0, (): 1-6.
陈孟科, 边赟, 梁云浩, 王海全. 基于6W2H的大语言模型思维链提示框架WH-CoT[J]. 《计算机应用》唯一官方网站, 0, (): 1-6.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2024050667
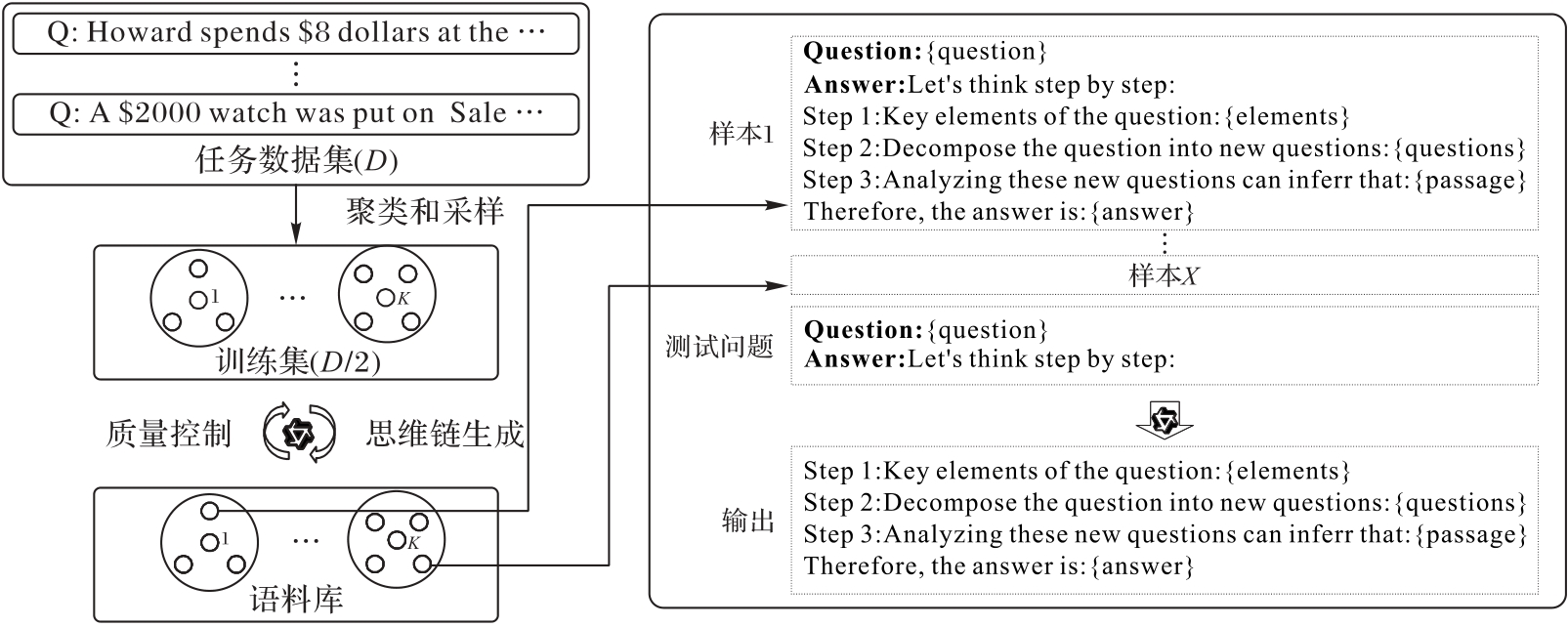
| 数据集 | 平均问题长度 | 平均答案长度 | 平均推理步骤数 |
|---|---|---|---|
| MSQ | 18.11 | 2.80 | 2.65 |
| Hotpot | 15.83 | 2.46 | 2.68 |
| 2Wiki | 11.98 | 2.41 | 2.47 |
| 数据集 | 平均问题长度 | 平均答案长度 | 平均推理步骤数 |
|---|---|---|---|
| MSQ | 18.11 | 2.80 | 2.65 |
| Hotpot | 15.83 | 2.46 | 2.68 |
| 2Wiki | 11.98 | 2.41 | 2.47 |
| 方法 | 准确率/% | ||||
|---|---|---|---|---|---|
| GSM8K | AQUA | SVAMP | 均值 | ||
| Zero-Shot | 70.00 | 40.62 | 56.66 | 55.76 | |
| Zero-Shot-CoT | 76.87 | 47.65 | 81.66 | 68.73 | |
| Manual-CoT | 78.75 | 54.68 | 70.00 | 67.81 | |
| WH-CoT | 79.38 | 59.37 | 77.50 | 72.08 | |
| 方法 | 准确率/% | ||||
|---|---|---|---|---|---|
| GSM8K | AQUA | SVAMP | 均值 | ||
| Zero-Shot | 70.00 | 40.62 | 56.66 | 55.76 | |
| Zero-Shot-CoT | 76.87 | 47.65 | 81.66 | 68.73 | |
| Manual-CoT | 78.75 | 54.68 | 70.00 | 67.81 | |
| WH-CoT | 79.38 | 59.37 | 77.50 | 72.08 | |
| 方法 | MSQ | Hotpot | 2Wiki | 总性能提升比 | ||||
|---|---|---|---|---|---|---|---|---|
| EM/% | F1/% | EM/% | F1/% | EM/% | F1/% | EM | F1 | |
| Zero-Shot | 0.83 | 1.97 | 8.33 | 18.65 | 11.67 | 16.05 | — | — |
| Zero-Shot-CoT | 2.50 | 7.15 | 14.17 | 21.23 | 5.83 | 7.39 | 1.54↑ | 1.90↑ |
| Manual-CoT | 1.67 | 5.04 | 5.00 | 10.37 | 22.50 | 25.51 | 0.79↑ | 1.15↑ |
| WH-CoT | 3.00 | 6.62 | 8.33 | 18.10 | 8.33 | 12.59 | 1.90↑ | 1.71↑ |
| 方法 | MSQ | Hotpot | 2Wiki | 总性能提升比 | ||||
|---|---|---|---|---|---|---|---|---|
| EM/% | F1/% | EM/% | F1/% | EM/% | F1/% | EM | F1 | |
| Zero-Shot | 0.83 | 1.97 | 8.33 | 18.65 | 11.67 | 16.05 | — | — |
| Zero-Shot-CoT | 2.50 | 7.15 | 14.17 | 21.23 | 5.83 | 7.39 | 1.54↑ | 1.90↑ |
| Manual-CoT | 1.67 | 5.04 | 5.00 | 10.37 | 22.50 | 25.51 | 0.79↑ | 1.15↑ |
| WH-CoT | 3.00 | 6.62 | 8.33 | 18.10 | 8.33 | 12.59 | 1.90↑ | 1.71↑ |
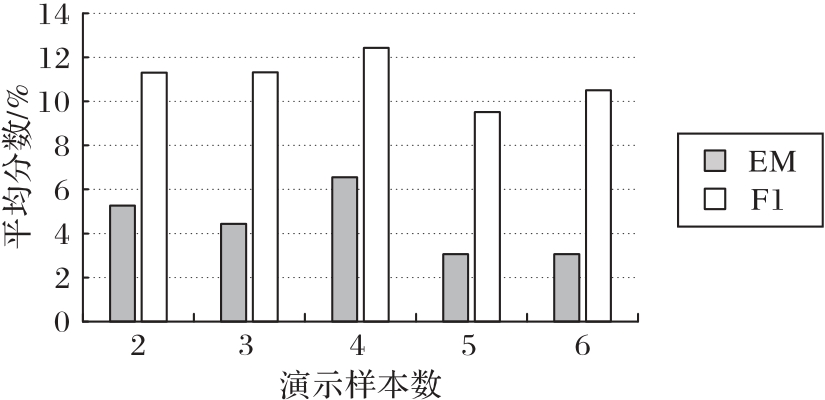
| 采样方式 | MSQ | Hotpot | 2Wiki | 均值 |
|---|---|---|---|---|
| 随机采样 | 0.00 | 4.17 | 6.67 | 3.61 |
| 簇内随机采样 | 1.67 | 5.83 | 5.00 | 4.16 |
| 相似性采样 | 0.83 | 4.17 | 6.67 | 3.89 |
| 自适应采样 | 3.00 | 8.33 | 8.33 | 6.55 |
| 采样方式 | MSQ | Hotpot | 2Wiki | 均值 |
|---|---|---|---|---|
| 随机采样 | 0.00 | 4.17 | 6.67 | 3.61 |
| 簇内随机采样 | 1.67 | 5.83 | 5.00 | 4.16 |
| 相似性采样 | 0.83 | 4.17 | 6.67 | 3.89 |
| 自适应采样 | 3.00 | 8.33 | 8.33 | 6.55 |
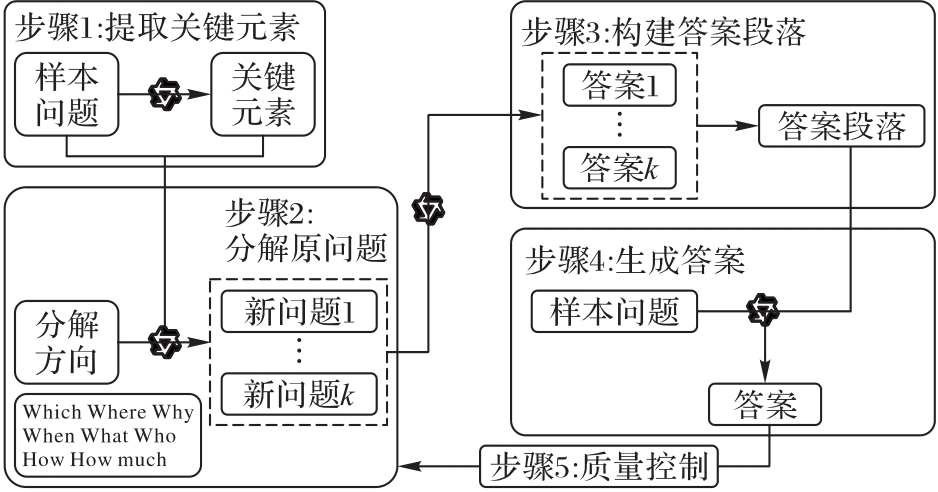
| 方法 | MSQ | Hotpot | 2Wiki | 总性能提升比 | ||||
|---|---|---|---|---|---|---|---|---|
| EM/% | F1/% | EM/% | F1/% | EM/% | F1/% | EM | F1 | |
| Zero-Shot | 0.83 | 2.84 | 5.83 | 13.54 | 4.12 | 7.75 | — | — |
| Zero-Shot-CoT | 2.50 | 10.47 | 15.00 | 27.81 | 13.33 | 21.33 | 1.97↑ | 2.34↑ |
| Manual-CoT | 0.83 | 4.76 | 12.50 | 20.36 | 26.67 | 29.50 | 0.77↑ | 0.89↑ |
| WH-CoT | 10.83 | 23.66 | 15.00 | 24.81 | 26.67 | 29.29 | 9.75↑ | 5.86↑ |
| 方法 | MSQ | Hotpot | 2Wiki | 总性能提升比 | ||||
|---|---|---|---|---|---|---|---|---|
| EM/% | F1/% | EM/% | F1/% | EM/% | F1/% | EM | F1 | |
| Zero-Shot | 0.83 | 2.84 | 5.83 | 13.54 | 4.12 | 7.75 | — | — |
| Zero-Shot-CoT | 2.50 | 10.47 | 15.00 | 27.81 | 13.33 | 21.33 | 1.97↑ | 2.34↑ |
| Manual-CoT | 0.83 | 4.76 | 12.50 | 20.36 | 26.67 | 29.50 | 0.77↑ | 0.89↑ |
| WH-CoT | 10.83 | 23.66 | 15.00 | 24.81 | 26.67 | 29.29 | 9.75↑ | 5.86↑ |
| 方法 | MSQ | Hotpot | 2Wiki | 总性能提升比 | ||||
|---|---|---|---|---|---|---|---|---|
| EM/% | F1/% | EM/% | F1/% | EM/% | F1/% | EM | F1 | |
| Zero-Shot | 0.83 | 2.01 | 3.33 | 11.77 | 5.00 | 13.68 | — | — |
| Zero-Shot-CoT | 0.83 | 4.90 | 10.00 | 17.57 | 19.17 | 23.33 | 0.61↑ | 1.22↑ |
| Manual-CoT | 2.50 | 5.85 | 7.50 | 11.48 | 16.67 | 21.09 | 1.93↑ | 1.47↑ |
| WH-CoT | 4.17 | 10.34 | 9.17 | 16.27 | 15.83 | 19.83 | 3.48↑ | 3.17↑ |
| 方法 | MSQ | Hotpot | 2Wiki | 总性能提升比 | ||||
|---|---|---|---|---|---|---|---|---|
| EM/% | F1/% | EM/% | F1/% | EM/% | F1/% | EM | F1 | |
| Zero-Shot | 0.83 | 2.01 | 3.33 | 11.77 | 5.00 | 13.68 | — | — |
| Zero-Shot-CoT | 0.83 | 4.90 | 10.00 | 17.57 | 19.17 | 23.33 | 0.61↑ | 1.22↑ |
| Manual-CoT | 2.50 | 5.85 | 7.50 | 11.48 | 16.67 | 21.09 | 1.93↑ | 1.47↑ |
| WH-CoT | 4.17 | 10.34 | 9.17 | 16.27 | 15.83 | 19.83 | 3.48↑ | 3.17↑ |
| 1 | BROWN T, MANN B, RYDER N, et al. Language models are few-shot learners[C]// Proceedings of the 34th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2020: 1877-1901. |
| 2 | CHOWDHERY A, NARANG S, DEVLIN J, et al. PaLM: scaling language modeling with pathways[J]. Journal of Machine Learning Research, 2023, 24: 1-113. |
| 3 | WEI J, WANG X, SCHUURMANS D, et al. Chain-of-thought prompting elicits reasoning in large language models[C]// Proceedings of the 36th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2022: 24824-24837. |
| 4 | KOJIMA T, GU S S, REID M, et al. Large language models are zero-shot reasoners[C]// Proceedings of the 36th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2022: 22199-22213. |
| 5 | WANG X, WEI J, SCHUURMANS D, et al. Self-consistency improves chain of thought reasoning in language models[EB/OL]. [2024-01-11].. |
| 6 | WANG J, LI J, ZHAO H. Self-prompted chain-of-thought on large language models for open-domain multi-hop reasoning[C]// Findings of the Association for Computational Linguistics: EMNLP 2023. Stroudsburg: ACL, 2023: 2717-2731. |
| 7 | WEI J, TAY Y, BOMMASANI R, et al. Emergent abilities of large language models[EB/OL].[2024-03-27]. . |
| 8 | COBBE K, KOSARAJU V, BAVARIAN M, et al. Training verifiers to solve math word problems[EB/OL]. [2024-03-05]. . |
| 9 | LING W, YOGATAMA D, DYER C, et al. Program induction by rationale generation: learning to solve and explain algebraic word problems[C]// Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2017: 158-167. |
| 10 | PATEL A, BHATTAMISHRA S, GOYAL N. Are NLP models really able to solve simple math word problems?[C]// Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg: ACL, 2021: 2080-2094. |
| 11 | TRIVEDI H, BALASUBRAMANIAN N, KHOT T, et al. MuSiQue: multi-hop questions via single-hop question composition[J]. Transactions of the Association for Computational Linguistics, 2022, 10: 539-554. |
| 12 | YANG Z, QI P, ZHANG S, et al. HotpotQA: a dataset for diverse, explainable multi-hop question answering[C]// Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2018: 2369-2380. |
| 13 | HO X, DUONG NGUYEN A K, SUGAWARA S, et al. Constructing a multi-hop QA dataset for comprehensive evaluation of reasoning steps[C]// Proceedings of the 28th International Conference on Computational Linguistics. [S.l.]: International Committee on Computational Linguistics, 2020: 6609-6625. |
| 14 | 大岛祥誉. 麦肯锡思考工具[M]. 朱悦玮,译. 北京:北京时代华文书局, 2023:154-157. |
| 15 | CHAKMA K, DAS A, DEBBARMA S. Deep semantic role labeling for tweets using 5W1H: Who, What, When, Where, Why and How[J]. Computación y Sistemas, 2019, 23(3): 751-763. |
| 16 | 姜天笑.浅谈科技查新工作中的5W1H分析法[J].情报探索,2011(5):96-97. |
| 17 | CHAKMA K, DAS A. A 5W1H based annotation scheme for semantic role labeling of English tweets [J]. Computación y Sistemas, 2018, 22(3): 747-755. |
| 18 | DAS A, BANDYAOPADHYAY S, GAMBÄCK B. The 5W structure for sentiment summarization-visualization-tracking[C]// Proceedings of the 2012 International Conference on Computational Linguistics and Intelligent Text Processing, LNCS 7181. Berlin: Springer, 2012: 540-555. |
| 19 | PARTON K, McKEOWN K R, COYNE R, et al . Who, what, when, where, why? comparing multiple approaches to the cross-lingual 5W task[C]// Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP. Stroudsburg: ACL, 2009: 423-431. |
| 20 | VASWANI A, SHAZEER NRMAR N, et al. Attention is all you need[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2017: 6000-6010. |
| 21 | DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional transformers for language understanding[C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Stroudsburg: ACL, 2019: 4171-4186. |
| 22 | LIU P, YUAN W, FU J, et al. Pre-train, prompt, and predict: a systematic survey of prompting methods in natural language processing[J]. ACM Computing Surveys, 2023, 55(9): No.195. |
| 23 | RAE J W, BORGEAUD S, CAI T, et al. Scaling language models: methods, analysis & insights from training Gopher[EB/OL]. [2024-02-21]. . |
| 24 | ZELIKMAN E, WU Y, MU J, et al. STaR: self-taught reasoner bootstrapping reasoning with reasoning[C]// Proceedings of the 36th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2022: 15476-15488. |
| 25 | PRESS O, ZHANG M, MIN S, et al. Measuring and narrowing the compositionality gap in language models[C]// Findings of the Association for Computational Linguistics: EMNLP 2023. Stroudsburg: ACL, 2023: 5687-5711. |
| 26 | ZHANG Z, ZHANG A, LI M, et al. Automatic chain of thought prompting in large language models[EB/OL]. [2024-01-06]. . |
| 27 | AGRAWAL S, ZHOU C, LEWIS M, et al. In-context examples selection for machine translation[C]// Proceedings of the Findings of Association for Computational Linguistics: ACL 2023. Stroudsburg: ACL, 2023: 8857-8873. |
| 28 | YE J, WU Z, FENG J, et al. Compositional exemplars for in-context learning[C]// Proceedings of the 40th International Conference on Machine Learning. New York: JMLR.org, 2023: 39818-39833. |
| 29 | REIMERS N, GUREVYCH I. Sentence-BERT: sentence embeddings using Siamese BERT-networks[C]// Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Stroudsburg: ACL, 2019: 3982-3992. |
| 30 | ZHOU D, SCHÄRLI N, HOU L, et al. Least-to-most prompting enables complex reasoning in large language models[EB/OL]. [2024-03-28]. . |
| 31 | BAI J, BAI S, CHU Y, et al. QWEN technical report[EB/OL]. [2024-02-28]. . |
| [1] | Jiali ZHENG, Gang ZHOU, Jing CHEN, Shunhang LI. Adaptive multi-feature fusion detection method for AI-generated text [J]. Journal of Computer Applications, 2026, 46(5): 1433-1440. |
| [2] | Qianfei WANG, Yang LI, Deyu LI, Suge WANG. Dual-channel feature fusion representation method for short-text clustering based on large language model [J]. Journal of Computer Applications, 2026, 46(5): 1441-1449. |
| [3] | Xing SHENG, Sunxian WENG, Kuosong CHEN, Zhongping WANG, Ruifeng REN, Yong LIU. Deep learning-based patent value evaluation for power grid enterprises [J]. Journal of Computer Applications, 2026, 46(5): 1468-1474. |
| [4] | Yongbing ZHANG, Lirong YAN, Xiaofen TANG. Progressive dual-stage modality interaction for single-domain generalized object detection [J]. Journal of Computer Applications, 2026, 46(4): 1264-1274. |
| [5] | Xiaoyu WANG, Xin LI, Di XUE, Zhangtao JIANG, Wei WANG, Yanjun XIAO. Vulnerability classification framework for video surveillance network security based on large language models [J]. Journal of Computer Applications, 2026, 46(4): 1158-1170. |
| [6] | Kaizhou SHI, Xuan HE, Guoyi HOU, Gen LI, Shuanggao LI, Xiang HUANG. Airborne product metrological traceability knowledge graph construction method based on large language models [J]. Journal of Computer Applications, 2026, 46(4): 1086-1095. |
| [7] | Haoxuan CHEN, Peichang YE, Lei LIU, Chengming LIU, Wenhua HU. Survey of automated code edit suggestion [J]. Journal of Computer Applications, 2026, 46(4): 1227-1237. |
| [8] | Rilong WANG, Zhenping LI, Xiaosong LI, Qiang GAO, Ya HE, Yong ZHONG, Yingxiao ZHAO. Multi-Agent collaborative knowledge reasoning framework [J]. Journal of Computer Applications, 2026, 46(3): 708-714. |
| [9] | Haoyang ZHANG, Liping ZHANG, Sheng YAN, Na LI, Xuefei ZHANG. Review of large language model methods for knowledge graph completion [J]. Journal of Computer Applications, 2026, 46(3): 683-695. |
| [10] | Bin SHEN, Xiaoning CHEN, Hua CHENG, Yiquan FANG, Huifeng WANG. Intelligent undergraduate teaching evaluation system based on large language models [J]. Journal of Computer Applications, 2026, 46(3): 993-1003. |
| [11] | Enkang XI, Jing FAN, Yadong JIN, Hua DONG, Hao YU, Yihang SUN. Review of threats faced by federated learning in privacy and security field [J]. Journal of Computer Applications, 2026, 46(3): 798-808. |
| [12] | Yiming HUANG, Xihua ZOU, Guo DENG, Di ZHENG. Pre-answering and retrieval filtering: dual-stage optimization method for RAG-based question-answering systems [J]. Journal of Computer Applications, 2026, 46(3): 696-707. |
| [13] | Dingjia WU, Zhe CUI. MG-SQL: SQL generation framework with enhanced schema linking and multi-generator collaboration [J]. Journal of Computer Applications, 2026, 46(3): 723-731. |
| [14] | Fei GAO, Dong CHEN, Dixing BIAN, Wenqiang FAN, Qidong LIU, Pei LYU, Chaoyang ZHANG, Mingliang XU. Multistage coupled decision-making framework for researcher redeployment after discipline revocation [J]. Journal of Computer Applications, 2026, 46(2): 416-426. |
| [15] | Xinran XIE, Zhe CUI, Rui CHEN, Tailai PENG, Dekun LIN. Zero-shot re-ranking method by large language model with hierarchical filtering and label semantic extension [J]. Journal of Computer Applications, 2026, 46(1): 60-68. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||