


Journal of Computer Applications ›› 2024, Vol. 44 ›› Issue (11): 3623-3628.DOI: 10.11772/j.issn.1001-9081.2023101538
• Frontier and comprehensive applications • Previous Articles Next Articles
Yu WANG( ), Zhihui GUAN, Yuanpeng LI
), Zhihui GUAN, Yuanpeng LI
Received:2023-11-10
Revised:2024-02-05
Accepted:2024-02-06
Online:2024-03-25
Published:2024-11-10
Contact:
Yu WANG
About author:GUAN Zhihui, born in 1998, M. S. candidate. Her research interests include reinforcement learning, pursuit decision-making.Supported by:
王昱(), 关智慧, 李远鹏
通讯作者:
王昱
作者简介:关智慧(1998—),女,山东济宁人,硕士研究生,主要研究方向:强化学习、追击决策基金资助:CLC Number:
Yu WANG, Zhihui GUAN, Yuanpeng LI. Distributed UAV cluster pursuit decision-making based on trajectory prediction and MADDPG[J]. Journal of Computer Applications, 2024, 44(11): 3623-3628.
王昱, 关智慧, 李远鹏. 基于轨迹预测和分布式MADDPG的无人机集群追击决策[J]. 《计算机应用》唯一官方网站, 2024, 44(11): 3623-3628.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2023101538
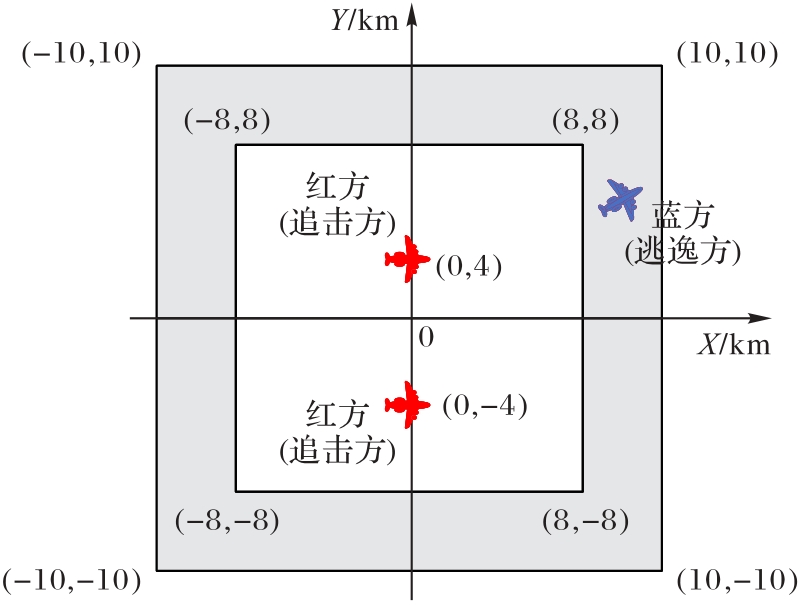
Fig. 1 Two vs. one UAV cluster pursuit scenario setting
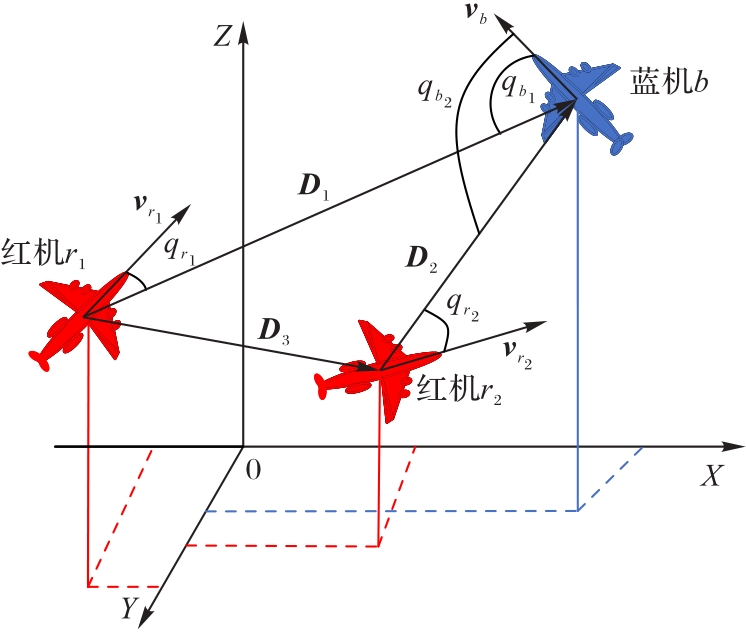
Fig. 2 UAV close-range air combat model
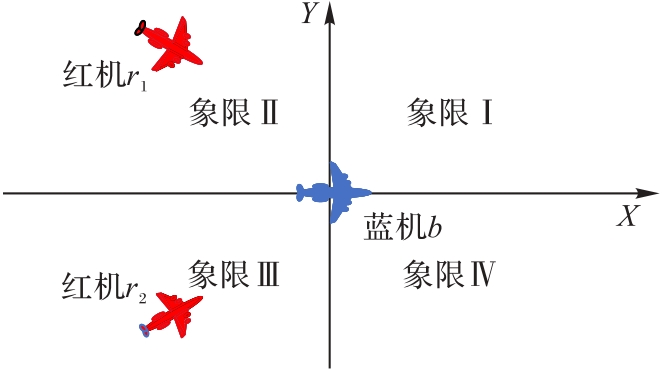
Fig. 3 Schematic diagram of combat airspace division
| r1位置 | r2位置 | |||
|---|---|---|---|---|
| 象限Ⅰ | 象限Ⅱ | 象限Ⅲ | 象限Ⅳ | |
| 象限Ⅰ | 转向象限Ⅰ | 转向象限Ⅳ | 转向象限Ⅳ | 转向象限Ⅲ |
| 象限Ⅱ | 转向象限Ⅳ | 不变 | 不变 | 转向象限Ⅰ |
| 象限Ⅲ | 转向象限Ⅳ | 不变 | 不变 | 转向象限Ⅰ |
| 象限Ⅳ | 转向象限Ⅲ | 转向象限Ⅰ | 转向象限Ⅰ | 转向象限Ⅰ |
Tab. 1 Escape strategy of blue UAV
| r1位置 | r2位置 | |||
|---|---|---|---|---|
| 象限Ⅰ | 象限Ⅱ | 象限Ⅲ | 象限Ⅳ | |
| 象限Ⅰ | 转向象限Ⅰ | 转向象限Ⅳ | 转向象限Ⅳ | 转向象限Ⅲ |
| 象限Ⅱ | 转向象限Ⅳ | 不变 | 不变 | 转向象限Ⅰ |
| 象限Ⅲ | 转向象限Ⅳ | 不变 | 不变 | 转向象限Ⅰ |
| 象限Ⅳ | 转向象限Ⅲ | 转向象限Ⅰ | 转向象限Ⅰ | 转向象限Ⅰ |

Fig. 4 Structure of MADDPG algorithm

Fig. 5 Structure of TP-MADDPG algorithm
| 敌机初始位置 | 模型选择 | 敌机初始位置 | 模型选择 |
|---|---|---|---|
| 象限Ⅰ | TP-MADDPG Ⅰ | 象限Ⅲ | TP-MADDPG Ⅲ |
| 象限Ⅱ | TP-MADDPG Ⅱ | 象限Ⅳ | TP-MADDPG Ⅳ |
Tab. 2 Model selection mechanism
| 敌机初始位置 | 模型选择 | 敌机初始位置 | 模型选择 |
|---|---|---|---|
| 象限Ⅰ | TP-MADDPG Ⅰ | 象限Ⅲ | TP-MADDPG Ⅲ |
| 象限Ⅱ | TP-MADDPG Ⅱ | 象限Ⅳ | TP-MADDPG Ⅳ |

Fig. 6 Structure of TP-DMADDPG algorithm
| 参数 | 符号 | 取值 |
|---|---|---|
| Critic网络奖励衰减因子 | 0.99 | |
| Actor、Critic网络软更新参数 | 0.99 | |
| 训练次数 | M | 100 |
| 红方无人机数 | N | 2 |
| 最大对战时间 | T | 200 |
| Actor网络学习率 | 0.001 | |
| Critic网络学习率 | 0.001 | |
| 每次训练从经验池抽取的样本数 | B | 100 |
Tab. 3 Algorithm parameter details
| 参数 | 符号 | 取值 |
|---|---|---|
| Critic网络奖励衰减因子 | 0.99 | |
| Actor、Critic网络软更新参数 | 0.99 | |
| 训练次数 | M | 100 |
| 红方无人机数 | N | 2 |
| 最大对战时间 | T | 200 |
| Actor网络学习率 | 0.001 | |
| Critic网络学习率 | 0.001 | |
| 每次训练从经验池抽取的样本数 | B | 100 |
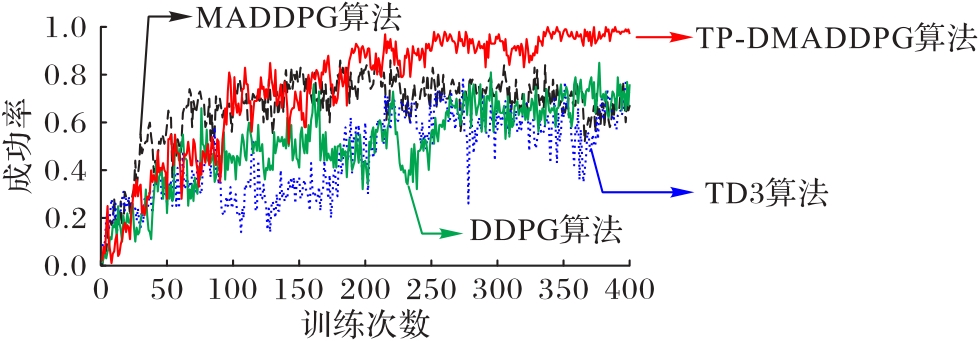
Fig. 7 Training curves of four algorithms

Fig. 8 Comparison of pursuit success rates of four algorithms with complete information
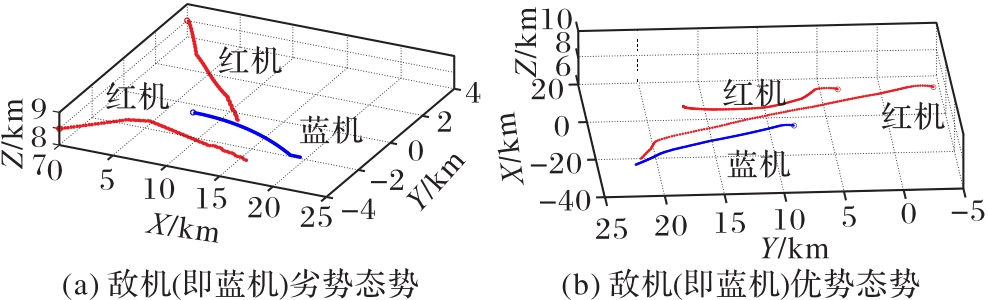
Fig. 9 Pursuit scenarios of TP-DMADDPG algorithm with complete information
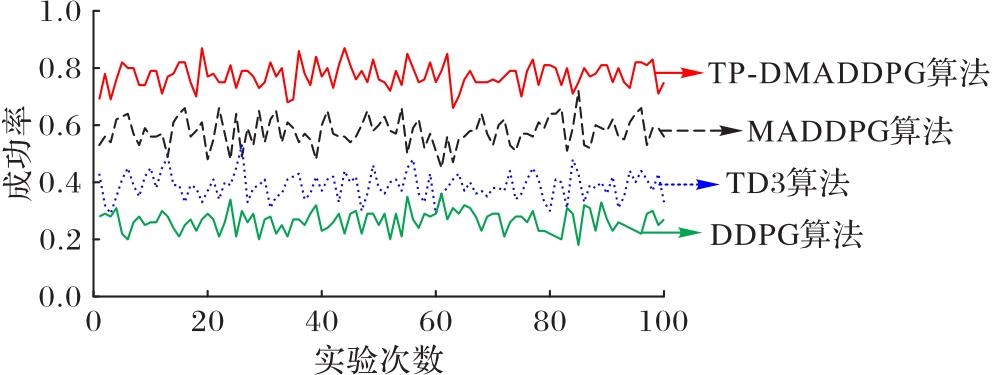
Fig. 10 Comparison of pursuit success rates of four algorithms with incomplete information
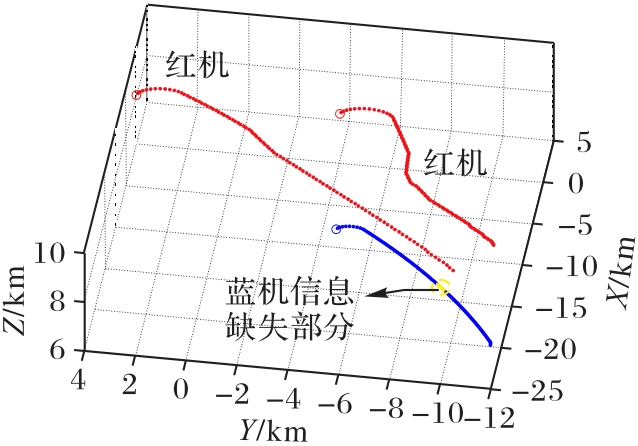
Fig. 11 Pursuit scenario of TP-DMADDPG algorithm with incomplete information
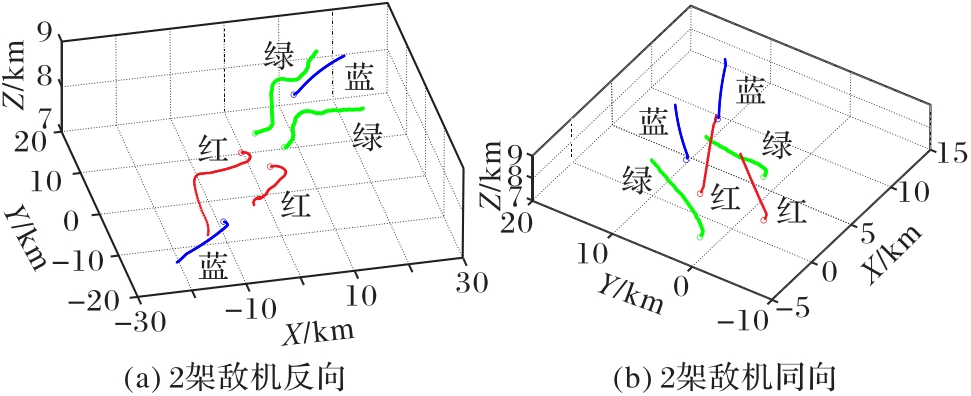
Fig. 12 Four vs. two UAV cluster pursuit scenarios simulation
| 1 | 刘雷,刘大卫,王晓光,等.无人机集群与反无人机集群发展现状及展望[J].航空学报,2022,43(S1):No.726908. |
| LIU L, LIU D W, WANG X G, et al. Development status and outlook of UAV clusters and anti-UAV clusters[J]. Acta Aeronautica et Astronautica Sinica, 2022, 43(S1): No.726908. | |
| 2 | 周新民,吴佳晖,贾圣德,等.无人机空战决策技术研究进展[J].国防科技,2021,42(3):33-41. |
| ZHOU X M, WU J H, JIA S D, et al. Progress in research on combat decision-making technology in UAVs[J]. National Defense Technology, 2021, 42(3): 33-41. | |
| 3 | 王炫,王维嘉,宋科璞,等.基于进化式专家系统树的无人机空战决策技术[J].兵工自动化,2019,38(1):42-47. |
| WANG X, WANG W J, SONG K P, et al. UAV air combat decision based on evolutionary expert system tree[J]. Ordnance Industry Automation, 2019, 38(1): 42-47. | |
| 4 | 杨建峰,肖和业,李亮,等.基于模糊聚类和专家评分机制的无人机多层次模块划分方法[J].系统工程与电子技术,2022,44(8): 2530-2539. |
| YANG J F, XIAO H Y, LI L, et al. Multi-level module partition method of UAV based on fuzzy clustering and expert scoring mechanism[J]. Systems Engineering and Electronics, 2022, 44(8): 2530-2539. | |
| 5 | 张涛,于雷,周中良,等.基于变权重伪并行遗传算法的空战机动决策[J].飞行力学,2012,30(5):470-474. |
| ZHANG T, YU L, ZHOU Z L, et al. Decision-making for air combat maneuvering based on variable weight pseudo-parallel genetic algorithm[J]. Flight Dynamics, 2012, 30(5): 470-474. | |
| 6 | HU T, HU J, ZHAO C, et al. Autonomous decision making of UAV in short-range air combat based on DQN aided by expert knowledge[C]// Proceedings of 2022 International Conference on Autonomous Unmanned Systems, LNEE 1010. Singapore: Springer, 2023: 1661-1670. |
| 7 | YANG Q, ZHENG J, SHEN G, et al. Maneuver decision of UAV in short-range air combat based on deep reinforcement learning[J]. IEEE Access, 2020, 8: 363-378. |
| 8 | 王克亮,侯中喜,高显忠.基于深度确定性策略梯度算法的无人机追击方法[C]// 第三十九届中国控制会议论文集.沈阳:中国自动化学会,2020:7982-7987. |
| WANG K L, HOU Z X, GAO X Z. Deep deterministic policy gradient based UAV pursuit strategy[C]// Proceedings of the 39th China Control Conference. Shenyang: Chinese Association of Automation, 2020: 7982-7987. | |
| 9 | 张耀中,许佳林,姚康佳,等.基于DDPG算法的无人机集群追击任务[J].航空学报,2020,41(10):No.32400. |
| ZHANG Y Z, XU J L, YAO K J, et al. Pursuit missions for UAV swarms based on DDPG algorithm[J]. Acta Aeronautica et Astronautica Sinica, 2020, 41(10): No.32400. | |
| 10 | 李永丰,吕永玺,史静平,等.深度确定性策略梯度和预测相结合的无人机空战决策研究[J].西北工业大学学报,2023,41(1):56-64. |
| LI Y F, LYU Y X, SHI J P, et al. UAV's air combat decision-making based on deep deterministic policy gradient and prediction[J]. Journal of Northwestern Polytechnic University, 2023, 41(1): 56-64. | |
| 11 | 李波,越凯强,甘志刚,等.基于MADDPG的多无人机协同任务决策[J].宇航学报,2021,42(6):757-765. |
| LI B, YUE K Q, GAN Z G, et al. Multi-UAV cooperative autonomous navigation based on multi-agent deep deterministic policy gradient[J]. Journal of Astronautics, 2021, 42(6): 757-765. | |
| 12 | 符小卫,王辉,徐哲.基于DE-MADDPG的多无人机协同追捕策略[J].航空学报,2022,43(5):No.325311. |
| FU X W, WANG H, XU Z. Cooperative pursuit strategy for multi-UAVs based on DE‑MADDPG algorithm[J]. Acta Aeronautica et Astronautica Sinica, 2022, 43(5): No.325311. | |
| 13 | 孙彧,徐越,潘宣宏,等.基于后验经验回放的MADDPG算法[J].指挥信息系统与技术,2021,12(6):78-84. |
| SUN Y, XU Y, PAN X H, et al. Muti-Agent Deep Deterministic Policy Gradient (MADDPG) algorithm based on Hindsight Experience Replay (HER)[J]. Command Information System and Technology, 2021, 12(6): 78-84. | |
| 14 | 刘峰,魏瑞轩,丁超,等.面向多机协同的Att-MADDPG围捕控制方法设计[J].空军工程大学学报(自然科学版),2021,22(3):9-14. |
| LIU F, WEI R X, DING C, et al. Design of Att-MADDPG hunting control method for multi-UAV cooperation[J]. Journal of Air Force Engineering University (Natural Science Edition), 2021, 22(3): 9-14. | |
| 15 | ZHANG Y, LI Y, LI K, et al. Intelligent prediction method for updraft of UAV that is based on LSTM network[J]. IEEE Transactions on Cognitive and Developmental Systems, 2023, 15(2): 464-475. |
| 16 | YAO B, ZHONG Q, CUI H, et al. LSTM-based vehicle trajectory prediction using UAV aerial data[C]// Proceedings of the 2023 KES-STS International Symposium, SIST 356. Singapore: Springer, 2023: 13-21. |
| 17 | SHAHID S, ZHEN Z, JAVAID U, et al. Offense-defense distributed decision making for swarm vs. swarm confrontation while attacking the aircraft carriers[J]. Drones, 2022, 6(10): No.271. |
| 18 | LI D, YANG P, LIU Z, et al. Fault diagnosis for distributed UAVs formation based on unknown input observer[C]// Proceedings of the 2019 Chinese Control Conference. Piscataway: IEEE, 2019: 4996- 5001. |
| [1] | Hailin XIAO, Tianyi HUANG, Qiuxiang DAI, Yuejun ZHANG, Zhongshan ZHANG. Safe reinforcement learning method for decision making of autonomous lane changing based on trajectory prediction [J]. Journal of Computer Applications, 2024, 44(9): 2958-2963. |
| [2] | Haodong HE, Hao FU, Qiang WANG, Shuai ZHOU, Wei LIU. Multi-robot path following and formation based on deep reinforcement learning [J]. Journal of Computer Applications, 2024, 44(8): 2626-2633. |
| [3] | Yi ZHOU, Hua GAO, Yongshen TIAN. Proximal policy optimization algorithm based on clipping optimization and policy guidance [J]. Journal of Computer Applications, 2024, 44(8): 2334-2341. |
| [4] | Tian MA, Runtao XI, Jiahao LYU, Yijie ZENG, Jiayi YANG, Jiehui ZHANG. Mobile robot 3D space path planning method based on deep reinforcement learning [J]. Journal of Computer Applications, 2024, 44(7): 2055-2064. |
| [5] | Runze TIAN, Yulong ZHOU, Hong ZHU, Gang XUE. Local information based path selection algorithm for service migration [J]. Journal of Computer Applications, 2024, 44(7): 2168-2174. |
| [6] | Xiaofang LIU, Jun ZHANG. Probability-driven dynamic multiobjective evolutionary optimization for multi-agent cooperative scheduling [J]. Journal of Computer Applications, 2024, 44(5): 1372-1377. |
| [7] | Xiaoyan ZHAO, Wei HAN, Junna ZHANG, Peiyan YUAN. Collaborative offloading strategy in internet of vehicles based on asynchronous deep reinforcement learning [J]. Journal of Computer Applications, 2024, 44(5): 1501-1510. |
| [8] | Rui TANG, Chuanlin PANG, Ruizhi ZHANG, Chuan LIU, Shibo YUE. DDPG-based resource allocation in D2D communication-empowered cellular network [J]. Journal of Computer Applications, 2024, 44(5): 1562-1569. |
| [9] | Fatang CHEN, Miao HUANG, Yufeng JIN. Resource allocation algorithm for low earth orbit satellites oriented to user demand [J]. Journal of Computer Applications, 2024, 44(4): 1242-1247. |
| [10] | Xintong QIN, Zhengyu SONG, Tianwei HOU, Feiyue WANG, Xin SUN, Wei LI. Channel access and resource allocation algorithm for adaptive p-persistent mobile ad hoc network [J]. Journal of Computer Applications, 2024, 44(3): 863-868. |
| [11] | Zhaojun TANG, Meiyan XIA, Hua ZHANG, Ting XIE. Fixed-time consensus of dynamic event-triggered multi-agent systems [J]. Journal of Computer Applications, 2024, 44(3): 960-965. |
| [12] | Fuqin DENG, Huifeng GUAN, Chaoen TAN, Lanhui FU, Hongmin WANG, Tinlun LAM, Jianmin ZHANG. Multi-robot reinforcement learning path planning method based on request-response communication mechanism and local attention mechanism [J]. Journal of Computer Applications, 2024, 44(2): 432-438. |
| [13] | Yuanchao LI, Chongben TAO, Chen WANG. Gait control method based on maximum entropy deep reinforcement learning for biped robot [J]. Journal of Computer Applications, 2024, 44(2): 445-451. |
| [14] | Ziyang SONG, Junhuai LI, Huaijun WANG, Xin SU, Lei YU. Path planning algorithm of manipulator based on path imitation and SAC reinforcement learning [J]. Journal of Computer Applications, 2024, 44(2): 439-444. |
| [15] | Fuqin DENG, Chaoen TAN, Junwei LI, Jiaming ZHONG, Lanhui FU, Jianmin ZHANG, Hongmin WANG, Nannan LI, Bingchun JIANG, Tin Lun LAM. Conflict-based search algorithm for large-scale warehousing environment [J]. Journal of Computer Applications, 2024, 44(12): 3854-3860. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||