


Journal of Computer Applications ›› 2025, Vol. 45 ›› Issue (1): 40-47.DOI: 10.11772/j.issn.1001-9081.2023111699
• Artificial intelligence • Previous Articles Next Articles
Xueqiang LYU1, Tao WANG1, Xindong YOU1( ), Ge XU2
), Ge XU2
Received:2023-12-06
Revised:2024-05-11
Accepted:2024-05-20
Online:2024-07-25
Published:2025-01-10
Contact:
Xindong YOU
About author:LYU Xueqiang, born in 1970, Ph. D., professor. His research interests include natural language processing.Supported by:
吕学强1, 王涛1, 游新冬1(), 徐戈2
通讯作者:
游新冬
作者简介:吕学强(1970—),男,辽宁抚顺人,教授,博士,CCF高级会员,主要研究方向:自然语言处理;基金资助:CLC Number:
Xueqiang LYU, Tao WANG, Xindong YOU, Ge XU. HTLR: named entity recognition framework with hierarchical fusion of multi-knowledge[J]. Journal of Computer Applications, 2025, 45(1): 40-47.
吕学强, 王涛, 游新冬, 徐戈. 层次融合多元知识的命名实体识别框架——HTLR[J]. 《计算机应用》唯一官方网站, 2025, 45(1): 40-47.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2023111699
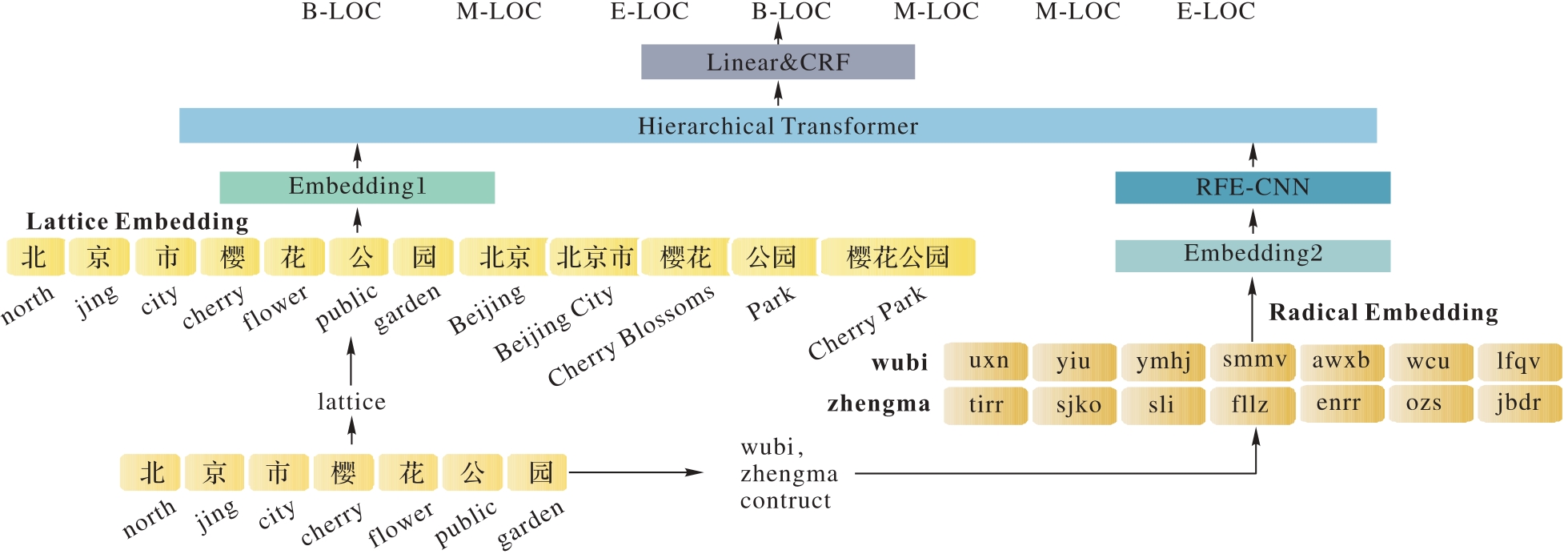
Fig. 1 Structure of HTLR model
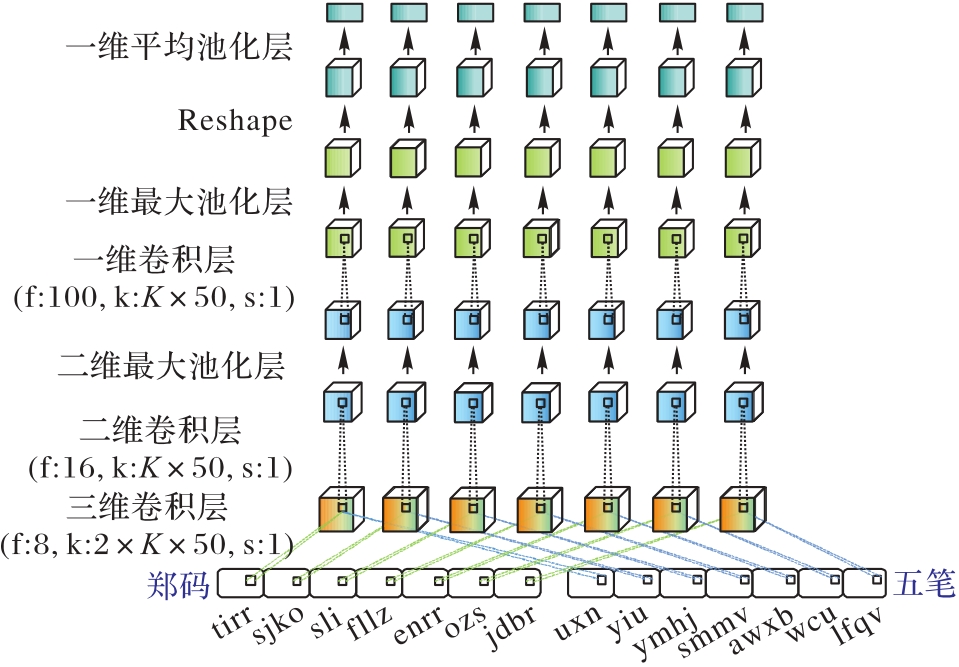
Fig. 2 Structure of RFE-CNN module
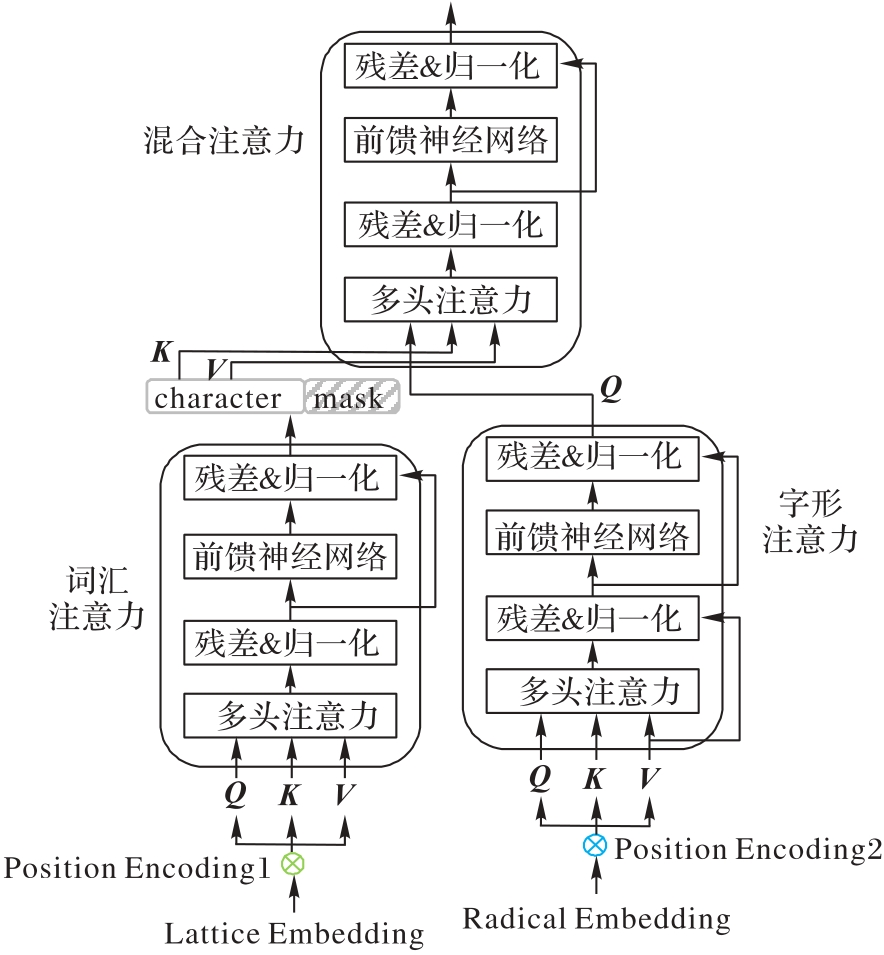
Fig. 3 Structure of Hierarchical Transformer model
| 数据集 | 类型 | 训练集 | 验证集 | 测试集 |
|---|---|---|---|---|
| Resume[ | 数据 | 3 800 | 460 | 480 |
| 实体 | 13 400 | 1 500 | 1 630 | |
| OntoNotes4.0[ | 数据 | 15 700 | 4 300 | 4 300 |
| 实体 | 13 400 | 6 950 | 7 700 | |
| Weibo[ | 数据 | 1 350 | 270 | 270 |
| 实体 | 1 890 | 390 | 420 | |
| MSRA[ | 数据 | 46 360 | — | 4 300 |
| 实体 | 74 700 | — | 6 200 |
Tab. 1 Dataset description
| 数据集 | 类型 | 训练集 | 验证集 | 测试集 |
|---|---|---|---|---|
| Resume[ | 数据 | 3 800 | 460 | 480 |
| 实体 | 13 400 | 1 500 | 1 630 | |
| OntoNotes4.0[ | 数据 | 15 700 | 4 300 | 4 300 |
| 实体 | 13 400 | 6 950 | 7 700 | |
| Weibo[ | 数据 | 1 350 | 270 | 270 |
| 实体 | 1 890 | 390 | 420 | |
| MSRA[ | 数据 | 46 360 | — | 4 300 |
| 实体 | 74 700 | — | 6 200 |
| 参数 | 设置 | 参数 | 设置 |
|---|---|---|---|
| Batch Size | 16 | Dropout rate | 0.15 |
| Learning rate1 | 0.000 03 | Max len | 512 |
| Learning rate2 | 0.001 |
Tab. 2 Experimental parameters setting
| 参数 | 设置 | 参数 | 设置 |
|---|---|---|---|
| Batch Size | 16 | Dropout rate | 0.15 |
| Learning rate1 | 0.000 03 | Max len | 512 |
| Learning rate2 | 0.001 |
| 模型 | Resume | OntoNotes4.0 | MSRA | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 精确率 | 召回率 | F1值 | 精确率 | 召回率 | F1值 | 精确率 | 召回率 | F1值 | 精确率 | 召回率 | F1值 | |
| BiLSTM | — | — | 56.75 | — | — | 94.41 | — | — | 71.81 | — | — | 91.87 |
| Lattice_LSTM | 53.04 | 62.25 | 58.79 | 94.81 | 94.11 | 94.46 | 76.35 | 71.56 | 73.88 | 93.57 | 92.79 | 93.18 |
| FLAT | — | — | 60.32 | — | — | 95.45 | — | — | 76.45 | — | — | 94.12 |
| BERT | — | — | 68.20 | — | — | 95.53 | — | — | 80.14 | — | — | 94.95 |
| GlyNN | — | — | 69.20 | — | — | 95.66 | — | — | — | — | — | 95.21 |
| SoftLexicon | 59.68 | 62.22 | 61.42 | 95.30 | 95.77 | 95.53 | 77.13 | 75.22 | 76.16 | 94.73 | 93.40 | 94.06 |
| NFLAT | 59.10 | 63.16 | 61.94 | 95.63 | 95.22 | 95.58 | 75.17 | 79.37 | 77.21 | 94.92 | 94.19 | 94.55 |
| ChatGPT | — | — | 70.10 | — | — | 95.70 | — | — | 69.40 | — | — | 90.10 |
| MCL | — | — | 68.17 | — | — | 95.96 | — | — | 78.59 | — | — | 94.40 |
| HTLR | 70.82 | 71.97 | 71.37 | 96.22 | 96.59 | 96.33 | 81.62 | 85.82 | 83.66 | 96.28 | 96.35 | 96.31 |
Tab. 3 Experimental results on different datasets
| 模型 | Resume | OntoNotes4.0 | MSRA | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 精确率 | 召回率 | F1值 | 精确率 | 召回率 | F1值 | 精确率 | 召回率 | F1值 | 精确率 | 召回率 | F1值 | |
| BiLSTM | — | — | 56.75 | — | — | 94.41 | — | — | 71.81 | — | — | 91.87 |
| Lattice_LSTM | 53.04 | 62.25 | 58.79 | 94.81 | 94.11 | 94.46 | 76.35 | 71.56 | 73.88 | 93.57 | 92.79 | 93.18 |
| FLAT | — | — | 60.32 | — | — | 95.45 | — | — | 76.45 | — | — | 94.12 |
| BERT | — | — | 68.20 | — | — | 95.53 | — | — | 80.14 | — | — | 94.95 |
| GlyNN | — | — | 69.20 | — | — | 95.66 | — | — | — | — | — | 95.21 |
| SoftLexicon | 59.68 | 62.22 | 61.42 | 95.30 | 95.77 | 95.53 | 77.13 | 75.22 | 76.16 | 94.73 | 93.40 | 94.06 |
| NFLAT | 59.10 | 63.16 | 61.94 | 95.63 | 95.22 | 95.58 | 75.17 | 79.37 | 77.21 | 94.92 | 94.19 | 94.55 |
| ChatGPT | — | — | 70.10 | — | — | 95.70 | — | — | 69.40 | — | — | 90.10 |
| MCL | — | — | 68.17 | — | — | 95.96 | — | — | 78.59 | — | — | 94.40 |
| HTLR | 70.82 | 71.97 | 71.37 | 96.22 | 96.59 | 96.33 | 81.62 | 85.82 | 83.66 | 96.28 | 96.35 | 96.31 |
| 模型 | Resume | OntoNotes4.0 | MSRA | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 精确率 | 召回率 | F1值 | 精确率 | 召回率 | F1值 | 精确率 | 召回率 | F1值 | 精确率 | 召回率 | F1值 | |
| BERT | — | — | 68.20 | — | — | 95.53 | — | — | 80.14 | — | — | 94.95 |
| FLAT+BERT | — | — | 68.55 | — | — | 95.86 | — | — | 81.82 | — | — | 96.09 |
| Radical | 70.46 | 71.18 | 70.81 | 95.20 | 96.12 | 95.66 | 81.56 | 84.97 | 83.21 | 95.57 | 95.60 | 95.58 |
| Mix_Attention | 70.28 | 70.44 | 70.34 | 94.80 | 94.96 | 95.48 | 81.95 | 84.04 | 82.97 | 95.39 | 95.49 | 95.44 |
| Wubi | 70.66 | 71.58 | 71.11 | 94.79 | 96.40 | 95.63 | 81.59 | 85.50 | 83.50 | 96.12 | 95.60 | 95.85 |
| Zhengma | 71.29 | 70.93 | 71.09 | 95.37 | 96.07 | 95.72 | 82.22 | 84.82 | 83.48 | 95.64 | 95.74 | 95.69 |
| RFE-CNN | 70.68 | 71.02 | 70.80 | 95.08 | 96.15 | 95.61 | 81.31 | 85.28 | 83.23 | 95.74 | 95.43 | 95.58 |
| HTLR | 70.82 | 71.97 | 71.37 | 96.22 | 96.59 | 96.33 | 81.62 | 85.82 | 83.66 | 96.28 | 96.35 | 96.31 |
Tab. 4 Ablation experimental results on different datasets
| 模型 | Resume | OntoNotes4.0 | MSRA | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 精确率 | 召回率 | F1值 | 精确率 | 召回率 | F1值 | 精确率 | 召回率 | F1值 | 精确率 | 召回率 | F1值 | |
| BERT | — | — | 68.20 | — | — | 95.53 | — | — | 80.14 | — | — | 94.95 |
| FLAT+BERT | — | — | 68.55 | — | — | 95.86 | — | — | 81.82 | — | — | 96.09 |
| Radical | 70.46 | 71.18 | 70.81 | 95.20 | 96.12 | 95.66 | 81.56 | 84.97 | 83.21 | 95.57 | 95.60 | 95.58 |
| Mix_Attention | 70.28 | 70.44 | 70.34 | 94.80 | 94.96 | 95.48 | 81.95 | 84.04 | 82.97 | 95.39 | 95.49 | 95.44 |
| Wubi | 70.66 | 71.58 | 71.11 | 94.79 | 96.40 | 95.63 | 81.59 | 85.50 | 83.50 | 96.12 | 95.60 | 95.85 |
| Zhengma | 71.29 | 70.93 | 71.09 | 95.37 | 96.07 | 95.72 | 82.22 | 84.82 | 83.48 | 95.64 | 95.74 | 95.69 |
| RFE-CNN | 70.68 | 71.02 | 70.80 | 95.08 | 96.15 | 95.61 | 81.31 | 85.28 | 83.23 | 95.74 | 95.43 | 95.58 |
| HTLR | 70.82 | 71.97 | 71.37 | 96.22 | 96.59 | 96.33 | 81.62 | 85.82 | 83.66 | 96.28 | 96.35 | 96.31 |
| 1 | CHEN Y, XU L, LIU K, et al. Event extraction via dynamic multi-pooling convolutional neural networks [C]// Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Stroudsburg: ACL, 2015: 167-176. |
| 2 | DIEFENBACH D, LOPEZ V, SINGH K, et al. Core techniques of question answering systems over knowledge bases: a survey[J]. Knowledge And Information Systems, 2018, 55(3): 529-569. |
| 3 | ZHOU Q, YANG N, WEI F, et al. Neural question generation from text: a preliminary study [C]// Proceedings of the 2017 CCF International Conference on Natural Language Processing and Chinese Computing, LNCS 10619. Cham: Springer, 2018: 662-671. |
| 4 | LE P, TITOV I. Improving entity linking by modeling latent relations between mentions [C]// Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2018: 1595-1604. |
| 5 | HOU F, WANG R, HE J, et al. Improving entity linking through semantic reinforced entity embeddings [C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2020: 6843-6848. |
| 6 | ZENG G, ZANG C, XIAO B, et al. CRFs-based Chinese named entity recognition with improved tag set [C]// Proceedings of the 2009 WRI World Congress on Computer Science and Information Engineering. Piscataway: IEEE, 2009: 519-522. |
| 7 | 雷景生,剌凯俊,杨胜英,等. 基于上下文语义增强的实体关系联合抽取[J]. 计算机应用, 2023, 43(5): 1438-1444. |
| LEI J S, LA K J, YANG S Y, et al. Joint entity and relation extraction based on contextual semantic enhancement[J]. Journal of Computer Applications, 2023, 43(5): 1438-1444. | |
| 8 | 徐关友,冯伟森. 基于Transformer的Python命名实体识别模型[J]. 计算机应用, 2022, 42(9): 2693-2700. |
| XU G Y, FENG W S. Python named entity recognition model based on Transformer[J]. Journal of Computer Applications, 2022, 42(9): 2693-2700. | |
| 9 | HEARST M A, DUMAIS S T, OSUNA E, et al. Support vector machines[J]. IEEE Intelligent Systems, 1998, 13(4): 18-28. |
| 10 | SONG C H, LAWRIE D, FININ T, et al. Improving neural named entity recognition with gazetteers [C]// Proceedings of the 33rd International FLAIRS Conference. Palo Alto: AAAI Press, 2020: 1-8. |
| 11 | JIANG B, WU Z, KARIMI H R. A distributed dynamic event-triggered mechanism to HMM-based observer design for H∞ sliding mode control of Markov jump systems[J]. Automatica, 2022, 142: No.110357. |
| 12 | DONG C, ZHANG J, ZONG C, et al. Character-based LSTM-CRF with radical-level features for Chinese named entity recognition [C]// Proceedings of the 5th CCF Conference on Natural Language Processing and Chinese Computing Conference and 24th International Conference on Computer Processing of Oriental Languages, LNCS 10102. Cham: Springer, 2016: 239-250. |
| 13 | HUANG Z, XU W, YU K. Bidirectional LSTM-CRF models for sequence tagging[EB/OL]. [2023-07-24]. . |
| 14 | WU F, LIU J, WU C, et al. Neural Chinese named entity recognition via CNN-LSTM-CRF and joint training with word segmentation [C]// Proceedings of the 2019 World Wide Web Conference. New York: ACM, 2019: 3342-3348. |
| 15 | ZHANG Y, YANG J. Chinese NER using lattice LSTM [C]// Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2018: 1554-1564. |
| 16 | DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional Transformers for language understanding [C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Stroudsburg: ACL, 2019: 4171-4186. |
| 17 | ZHU Y, WANG G. CAN-NER: convolutional attention network for Chinese named entity recognition [C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Stroudsburg: ACL, 2019: 3384-3393. |
| 18 | GUI T, ZOU Y, ZHANG Q, et al. A lexicon-based graph neural network for Chinese NER [C]// Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Stroudsburg: ACL, 2019: 1040-1050. |
| 19 | LI X, YAN H, QIU X, et al. FLAT: Chinese NER using flat-lattice Transformer [C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2020: 6836-6842. |
| 20 | MA R, PENG M, ZHANG Q, et al. Simplify the usage of lexicon in Chinese NER [C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistic. Stroudsburg: ACL, 2020: 5951-5960. |
| 21 | SONG C H, SEHANOBISH A. Using Chinese glyphs for named entity recognition (student abstract) [C]// Proceedings of the 34th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2020: 13921-13922. |
| 22 | XUAN Z, BAO R, JIANG S. FGN: fusion glyph network for Chinese named entity recognition [C]// Proceedings of the 2020 China Conference on Knowledge Graph and Semantic Computing. Singapore: Springer, 2021: 28-40. |
| 23 | ZHANG S, QINN Y, WEN J, et al. Word segmentation and named entity recognition [C]// Proceedings of the 5th SIGHAN Workshop on Chinese Language Processing. Stroudsburg: ACL, 2006: 158-161. |
| 24 | PENG N, DREDZE M. Named entity recognition for Chinese social media with jointly trained embeddings [C]// Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2015: 548-554. |
| 25 | WEISCHEDEL R, PALMER M, MARCUS M, et al. OntoNotes release 4.0: LDC2011T03[DS/OL]. [2023-09-14].. |
| 26 | WU S, SONG X, FENG Z, et al. NFLAT: non-flat-lattice Transformer for Chinese named entity recognition [EB/OL]. [2023-07-24].. |
| 27 | ZHAO S, WANG C, HU M, et al. MCL: multi-granularity contrastive learning framework for Chinese NER [J]. AAAI Technical Track on Speech & Natural Language Processing, 2023, 37(11), 14011-14019. |
| [1] | Qi SHUAI, Hairui WANG, Guifu ZHU. Chinese story ending generation model based on bidirectional contrastive training [J]. Journal of Computer Applications, 2024, 44(9): 2683-2688. |
| [2] | Jie WU, Ansi ZHANG, Maodong WU, Yizong ZHANG, Congbao WANG. Overview of research and application of knowledge graph in equipment fault diagnosis [J]. Journal of Computer Applications, 2024, 44(9): 2651-2659. |
| [3] | Quanmei ZHANG, Runping HUANG, Fei TENG, Haibo ZHANG, Nan ZHOU. Automatic international classification of disease coding method incorporating heterogeneous information [J]. Journal of Computer Applications, 2024, 44(8): 2476-2482. |
| [4] | Huanliang SUN, Siyi WANG, Junling LIU, Jingke XU. Help-seeking information extraction model for flood event in social media data [J]. Journal of Computer Applications, 2024, 44(8): 2437-2445. |
| [5] | Youren YU, Yangsen ZHANG, Yuru JIANG, Gaijuan HUANG. Chinese named entity recognition model incorporating multi-granularity linguistic knowledge and hierarchical information [J]. Journal of Computer Applications, 2024, 44(6): 1706-1712. |
| [6] | Longtao GAO, Nana LI. Aspect sentiment triplet extraction based on aspect-aware attention enhancement [J]. Journal of Computer Applications, 2024, 44(4): 1049-1057. |
| [7] | Xianfeng YANG, Yilei TANG, Ziqiang LI. Aspect-level sentiment analysis model based on alternating‑attention mechanism and graph convolutional network [J]. Journal of Computer Applications, 2024, 44(4): 1058-1064. |
| [8] | Yongfeng DONG, Jiaming BAI, Liqin WANG, Xu WANG. Chinese named entity recognition combining prior knowledge and glyph features [J]. Journal of Computer Applications, 2024, 44(3): 702-708. |
| [9] | Baoshan YANG, Zhi YANG, Xingyuan CHEN, Bing HAN, Xuehui DU. Analysis of consistency between sensitive behavior and privacy policy of Android applications [J]. Journal of Computer Applications, 2024, 44(3): 788-796. |
| [10] | Kaitian WANG, Qing YE, Chunlei CHENG. Classification method for traditional Chinese medicine electronic medical records based on heterogeneous graph representation [J]. Journal of Computer Applications, 2024, 44(2): 411-417. |
| [11] | Yushan JIANG, Yangsen ZHANG. Large language model-driven stance-aware fact-checking [J]. Journal of Computer Applications, 2024, 44(10): 3067-3073. |
| [12] | Chenghao FENG, Zhenping XIE, Bowen DING. Selective generation method of test cases for Chinese text error correction software [J]. Journal of Computer Applications, 2024, 44(1): 101-112. |
| [13] | Xinyue ZHANG, Rong LIU, Chiyu WEI, Ke FANG. Aspect-based sentiment analysis method with integrating prompt knowledge [J]. Journal of Computer Applications, 2023, 43(9): 2753-2759. |
| [14] | Xiaomin ZHOU, Fei TENG, Yi ZHANG. Automatic international classification of diseases coding model based on meta-network [J]. Journal of Computer Applications, 2023, 43(9): 2721-2726. |
| [15] | Xiaoyan ZHANG, Zhengyu DUAN. Cross-lingual zero-resource named entity recognition model based on sentence-level generative adversarial network [J]. Journal of Computer Applications, 2023, 43(8): 2406-2411. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||