


Journal of Computer Applications ›› 2025, Vol. 45 ›› Issue (2): 362-370.DOI: 10.11772/j.issn.1001-9081.2024020232
• Artificial intelligence • Previous Articles
Ming JIANG1,2, Linqin WANG1,2, Hua LAI1,2( ), Shengxiang GAO1,2
), Shengxiang GAO1,2
Received:2024-03-05
Revised:2024-04-17
Accepted:2024-04-25
Online:2025-02-24
Published:2025-02-10
Contact:
Hua LAI
About author:JIANG Ming, born in 1997, M. S. candidate. His research interests include information retrieval, text-to-speech.Supported by:
蒋铭1,2, 王琳钦1,2, 赖华1,2(), 高盛祥1,2
通讯作者:
赖华
作者简介:蒋铭(1997—),男,四川资阳人,硕士研究生,主要研究方向:信息检索、语音合成基金资助:CLC Number:
Ming JIANG, Linqin WANG, Hua LAI, Shengxiang GAO. End-to-end Vietnamese text normalization method based on editing constraints[J]. Journal of Computer Applications, 2025, 45(2): 362-370.
蒋铭, 王琳钦, 赖华, 高盛祥. 基于编辑约束的端到端越南语文本正则化方法[J]. 《计算机应用》唯一官方网站, 2025, 45(2): 362-370.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2024020232
| 含非标准词的文本 | 含可读词的文本 |
|---|---|
| Cho đến 27/9, châu Phi vẫn còn hơn 225 triệu người sống dưới mức độ nghèo | Cho đến ngày hai mươi bảy tháng chín, châu Phi vẫn còn hơn hai trăm hai mươi lăm triệu người sống dưới mức độ nghèo(截至9月27日,非洲仍有2.25亿人处于贫困线以下) |
| Trong ngày 2/3, Hơn 2/3 vẫn còn ở trường học | Trong ngày hai tháng ba, Hơn hai phần ba vẫn còn ở trường học(在3月2日,超过三分之二的人还在学校) |
| Ngày 5-1-2023, bình quân 4.7% GDP | Ngày năm tháng một năm hai không hai ba, bình quân bốn phẩy bảy phần trăm GDP(2023年1月5日,平均占国内生产总值的4.7%) |
Tab. 1 Vietnamese text normalization examples
| 含非标准词的文本 | 含可读词的文本 |
|---|---|
| Cho đến 27/9, châu Phi vẫn còn hơn 225 triệu người sống dưới mức độ nghèo | Cho đến ngày hai mươi bảy tháng chín, châu Phi vẫn còn hơn hai trăm hai mươi lăm triệu người sống dưới mức độ nghèo(截至9月27日,非洲仍有2.25亿人处于贫困线以下) |
| Trong ngày 2/3, Hơn 2/3 vẫn còn ở trường học | Trong ngày hai tháng ba, Hơn hai phần ba vẫn còn ở trường học(在3月2日,超过三分之二的人还在学校) |
| Ngày 5-1-2023, bình quân 4.7% GDP | Ngày năm tháng một năm hai không hai ba, bình quân bốn phẩy bảy phần trăm GDP(2023年1月5日,平均占国内生产总值的4.7%) |
| 类别 | 示例 | 非标准词数 | 句子平均长度(字符) |
|---|---|---|---|
| 数字 | 15,60.000,6 000,600.005,6,-100,10,06 | 24 343 | 120 |
| 日期 | 13/12/2021, 12.12.2021, 12-12-2021, 02/2021, 12-2021, 12/2021, 12.2021, 17/02, 13-12 | 3 640 | 116 |
| 时间 | 1h20,1:20,1:20:30,1h20p30s,1g20,11h-12h | 1 210 | 98 |
| 范围 | từ 2-3 ngày,Mất từ 7-8 tuần | 2 159 | 89 |
| 比分 | tỷ số 2-3,mùa giải 2018-2019 | 1 465 | 104 |
| 单位 | 100 kg,100 g,100 kg,10 km2,30℃ | 574 | 99 |
| 百分比 | 15%,50%,20-30% | 3 780 | 104 |
| 分数 | 24/7,tỷ lệ 2/3 | 1 479 | 99 |
| 版本 | CM 4.0,phiên bản Android 7.0,RTX3080 | 370 | 76 |
| 罗马数字 | Ⅰ, Ⅱ, Ⅲ, Ⅴ, Ⅵ, Ⅹ, Ⅺ, Ⅻ, | 480 | 87 |
| 电话 | 0977-1293-12, (+84)0966635412, 065.743.659, 0974 763 278 | 565 | 128 |
Tab. 2 Vietnamese non-standard word data distribution
| 类别 | 示例 | 非标准词数 | 句子平均长度(字符) |
|---|---|---|---|
| 数字 | 15,60.000,6 000,600.005,6,-100,10,06 | 24 343 | 120 |
| 日期 | 13/12/2021, 12.12.2021, 12-12-2021, 02/2021, 12-2021, 12/2021, 12.2021, 17/02, 13-12 | 3 640 | 116 |
| 时间 | 1h20,1:20,1:20:30,1h20p30s,1g20,11h-12h | 1 210 | 98 |
| 范围 | từ 2-3 ngày,Mất từ 7-8 tuần | 2 159 | 89 |
| 比分 | tỷ số 2-3,mùa giải 2018-2019 | 1 465 | 104 |
| 单位 | 100 kg,100 g,100 kg,10 km2,30℃ | 574 | 99 |
| 百分比 | 15%,50%,20-30% | 3 780 | 104 |
| 分数 | 24/7,tỷ lệ 2/3 | 1 479 | 99 |
| 版本 | CM 4.0,phiên bản Android 7.0,RTX3080 | 370 | 76 |
| 罗马数字 | Ⅰ, Ⅱ, Ⅲ, Ⅴ, Ⅵ, Ⅹ, Ⅺ, Ⅻ, | 480 | 87 |
| 电话 | 0977-1293-12, (+84)0966635412, 065.743.659, 0974 763 278 | 565 | 128 |
| 标注前 | 标注后 | 对应目标序列 |
|---|---|---|
| 100 | 1 00 | một trăm (一百) |
| 152 | 1 00 5 0# 2 | một trăm năm mươi hai (一百五十二) |
| 2002 | 2 000 0## 2 | hai nghìn lẻ hai (两千零二) |
| 100000 | 1 00 000 | một trăm nghìn (十万) |
| 499.500 | 4 00 9 0# 9 000 5 00 | bốn trăm chín mươi chín nghìn năm trăm (四十九万九千五百) |
| 30-60% | 3 0 - 6 0 % | ba mươi đến sáu mươi phần trăm (百分之三十至六十) |
| 28-35 | 2 0# 8 - 3 0# 5 | hai mươi tám đến ba mươi lăm (二十八到三十五) |
| 27-1-2006 | 2 0# 7 - 1 - 2 0 0 6 | hai mươi bảy tháng một năm hai không không sáu (二零零六年一月二十七) |
| 10/1/2005 | 10 / 1 / 2 0 0 5 | mười tháng một năm hai không không năm (二零零五年一月十) |
Tab. 3 Comparison of Vietnamese data before and after labelling
| 标注前 | 标注后 | 对应目标序列 |
|---|---|---|
| 100 | 1 00 | một trăm (一百) |
| 152 | 1 00 5 0# 2 | một trăm năm mươi hai (一百五十二) |
| 2002 | 2 000 0## 2 | hai nghìn lẻ hai (两千零二) |
| 100000 | 1 00 000 | một trăm nghìn (十万) |
| 499.500 | 4 00 9 0# 9 000 5 00 | bốn trăm chín mươi chín nghìn năm trăm (四十九万九千五百) |
| 30-60% | 3 0 - 6 0 % | ba mươi đến sáu mươi phần trăm (百分之三十至六十) |
| 28-35 | 2 0# 8 - 3 0# 5 | hai mươi tám đến ba mươi lăm (二十八到三十五) |
| 27-1-2006 | 2 0# 7 - 1 - 2 0 0 6 | hai mươi bảy tháng một năm hai không không sáu (二零零六年一月二十七) |
| 10/1/2005 | 10 / 1 / 2 0 0 5 | mười tháng một năm hai không không năm (二零零五年一月十) |
| 越南语 | 标注词 | 越南语 | 标注词 | 越南语 | 标注词 |
|---|---|---|---|---|---|
| không (zero) | 0 | mười (ten) | 10 | bằng (equal) | = |
| lẻ (zero) | 0## | cộng (plus) | + | phẩy (decimal point) | , |
| linh (zero) | 0### | và (and) | & | phần trăm (percent) | % |
| một (one) | 1 | trừ (subtract) | - | giờ (hour) | h |
| hai (two) | 2 | Âm (subzero) | - | phút (minute) | p |
| ba (three) | 3 | độ (minus) | - | giây (second) | s |
| bốn/tư (four) | 4 | đến (to) | - | mươi (ten) | 0# |
| năm/lăm/nhăm (five) | 5 | nhân (times) | × | trăm (hundred) | 00 |
| sáu (six) | 6 | chia (divided) | / | nghìn (thousand) | 000 |
| bảy (seven) | 7 | phân (each) | / | vạn (ten thousand) | 0000 |
| tám (eight) | 8 | hoặc (or) | / | triệu (million) | 00# |
| chin (nine) | 9 | phần (fraction) | / |
Tab. 4 Vietnamese label word correspondence
| 越南语 | 标注词 | 越南语 | 标注词 | 越南语 | 标注词 |
|---|---|---|---|---|---|
| không (zero) | 0 | mười (ten) | 10 | bằng (equal) | = |
| lẻ (zero) | 0## | cộng (plus) | + | phẩy (decimal point) | , |
| linh (zero) | 0### | và (and) | & | phần trăm (percent) | % |
| một (one) | 1 | trừ (subtract) | - | giờ (hour) | h |
| hai (two) | 2 | Âm (subzero) | - | phút (minute) | p |
| ba (three) | 3 | độ (minus) | - | giây (second) | s |
| bốn/tư (four) | 4 | đến (to) | - | mươi (ten) | 0# |
| năm/lăm/nhăm (five) | 5 | nhân (times) | × | trăm (hundred) | 00 |
| sáu (six) | 6 | chia (divided) | / | nghìn (thousand) | 000 |
| bảy (seven) | 7 | phân (each) | / | vạn (ten thousand) | 0000 |
| tám (eight) | 8 | hoặc (or) | / | triệu (million) | 00# |
| chin (nine) | 9 | phần (fraction) | / |
| 分类 | 示例 | 结构 | 列表 |
|---|---|---|---|
| Time | 1h20 | mm_h_mm | [“1”,“h”,“20”] |
| 1:20 | mm_:_mm | [“1”,“:”,“20”] | |
| 1:20:30 | mm_:_mm_:_mm | [“1”,“:”,“20”,“:”,“30”] | |
| 1h20p30s | mm_h_mm_mm_s | [“1”,“h”,“20”,“p”,“30”, “s”] | |
| 11’ | mm_’ | [“11”,“ ’ ”] | |
| 1g20’ | mm_g_mm_’ | [“1”,“g”,“20”,“ ’ ”] | |
| 12h-13h | mm_h_-_mm_h | [“12”,“h”,“-”,“13”,“h”] | |
| Full date | 13/12/2021 | mm_/_mm_/_dddd | [“13”,“/”,“12”,“/”,“2021”] |
| 13.12.2021 | mm_._mm_._dddd | [“13”,“.”,“12”,“.”,“2021”] | |
| 13-12-2021 | mm_-_mm_-_dddd | [“13”,“-”,“12”,“-”,“2021”] | |
| 1-2/3/2021 | mm_-_mm_/_mm_/_dddd | [“1”,“-”,“2”,“/”,“3”,“/”,“2021”] | |
| 8/9-10/9/2021 | mm_/_mm_-_mm_/_mm_/_dddd | [“8”,“/”,“9”,“-”,“10”,“/”,“9”,“/”,“2021”] | |
Day and month | 17/02 | mm_/_mm | [“17”,“/”,“02”] |
| 13-12 | mm_-_mm | [“13”,“/”,“12”] | |
| 13.12 | mm_._mm | [“13”,“.”,“12”] | |
Month and year | 02/2021 | mm_/_dddd | [“02”,“/”,“2021”] |
| 12-2021 | mm_-_dddd | [“12”,“-”,“2021”] | |
| 12.2021 | mm_._dddd | [“12”,“.”,“2021”] | |
| Number | 12.570.000 | mmm_._mmm_._mmm | [“12”,“.”,“570”,“.”,“000”] |
| 70.000 | mmm_._mmm | [“70”,“.”,“000”] | |
| -100 | -_m… | [“-”,“100”] | |
| 32,17 | m…_,_d… | [“32”,“,”,“17”] | |
| Percent | 20% | mm_% | [“20”,“%”] |
| 13,005% | m…_,_d…_% | [“13”,“,”,“005”,“%”] | |
| 20-30% | mm_-_mm_% | [“20”,“-”,“30”,“%”] | |
| Score | 2-3 | mmm_-_mmm | [“2”,“-”,“3”] |
| Range | 2-3 | mmm_-_mmm | [“2”,“-”,“3”] |
| Fraction | 2/3 | mmm/mmm | [“2”,“/”,“3”] |
| Measurement | 100 kg/g | m…_kg/g | [“100”,“kg”] |
| 100 GB | m…_GB | [“100”,“GB”] | |
| 100 km/dm/cm/m/km2… | m…_km/dm/cm/m/km2… | [“100”,“km”] | |
| 30℃ | mmm_℃ | [“30”,“℃”] | |
| 2$/¥… | m…_$/¥… | [“2”,“$”] | |
| 1000VNĐ/USD/GDP… | m…_VNĐ/USD/GDP… | [“1000”,“VNĐ”] | |
| 1000đồng/đ | m…_đồng/đ | [“1000”,“đồng”] |
Tab. 5 Vietnamese non-standard words regular matching relationship
| 分类 | 示例 | 结构 | 列表 |
|---|---|---|---|
| Time | 1h20 | mm_h_mm | [“1”,“h”,“20”] |
| 1:20 | mm_:_mm | [“1”,“:”,“20”] | |
| 1:20:30 | mm_:_mm_:_mm | [“1”,“:”,“20”,“:”,“30”] | |
| 1h20p30s | mm_h_mm_mm_s | [“1”,“h”,“20”,“p”,“30”, “s”] | |
| 11’ | mm_’ | [“11”,“ ’ ”] | |
| 1g20’ | mm_g_mm_’ | [“1”,“g”,“20”,“ ’ ”] | |
| 12h-13h | mm_h_-_mm_h | [“12”,“h”,“-”,“13”,“h”] | |
| Full date | 13/12/2021 | mm_/_mm_/_dddd | [“13”,“/”,“12”,“/”,“2021”] |
| 13.12.2021 | mm_._mm_._dddd | [“13”,“.”,“12”,“.”,“2021”] | |
| 13-12-2021 | mm_-_mm_-_dddd | [“13”,“-”,“12”,“-”,“2021”] | |
| 1-2/3/2021 | mm_-_mm_/_mm_/_dddd | [“1”,“-”,“2”,“/”,“3”,“/”,“2021”] | |
| 8/9-10/9/2021 | mm_/_mm_-_mm_/_mm_/_dddd | [“8”,“/”,“9”,“-”,“10”,“/”,“9”,“/”,“2021”] | |
Day and month | 17/02 | mm_/_mm | [“17”,“/”,“02”] |
| 13-12 | mm_-_mm | [“13”,“/”,“12”] | |
| 13.12 | mm_._mm | [“13”,“.”,“12”] | |
Month and year | 02/2021 | mm_/_dddd | [“02”,“/”,“2021”] |
| 12-2021 | mm_-_dddd | [“12”,“-”,“2021”] | |
| 12.2021 | mm_._dddd | [“12”,“.”,“2021”] | |
| Number | 12.570.000 | mmm_._mmm_._mmm | [“12”,“.”,“570”,“.”,“000”] |
| 70.000 | mmm_._mmm | [“70”,“.”,“000”] | |
| -100 | -_m… | [“-”,“100”] | |
| 32,17 | m…_,_d… | [“32”,“,”,“17”] | |
| Percent | 20% | mm_% | [“20”,“%”] |
| 13,005% | m…_,_d…_% | [“13”,“,”,“005”,“%”] | |
| 20-30% | mm_-_mm_% | [“20”,“-”,“30”,“%”] | |
| Score | 2-3 | mmm_-_mmm | [“2”,“-”,“3”] |
| Range | 2-3 | mmm_-_mmm | [“2”,“-”,“3”] |
| Fraction | 2/3 | mmm/mmm | [“2”,“/”,“3”] |
| Measurement | 100 kg/g | m…_kg/g | [“100”,“kg”] |
| 100 GB | m…_GB | [“100”,“GB”] | |
| 100 km/dm/cm/m/km2… | m…_km/dm/cm/m/km2… | [“100”,“km”] | |
| 30℃ | mmm_℃ | [“30”,“℃”] | |
| 2$/¥… | m…_$/¥… | [“2”,“$”] | |
| 1000VNĐ/USD/GDP… | m…_VNĐ/USD/GDP… | [“1000”,“VNĐ”] | |
| 1000đồng/đ | m…_đồng/đ | [“1000”,“đồng”] |

Fig.1 Principle of label vector generation
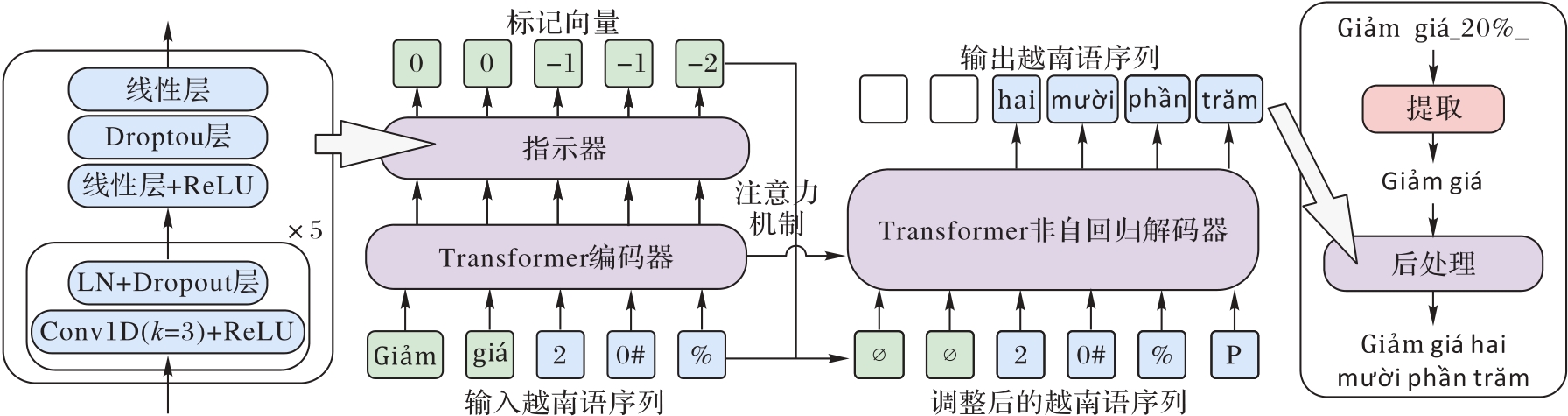
Fig.2 Proposed model structure
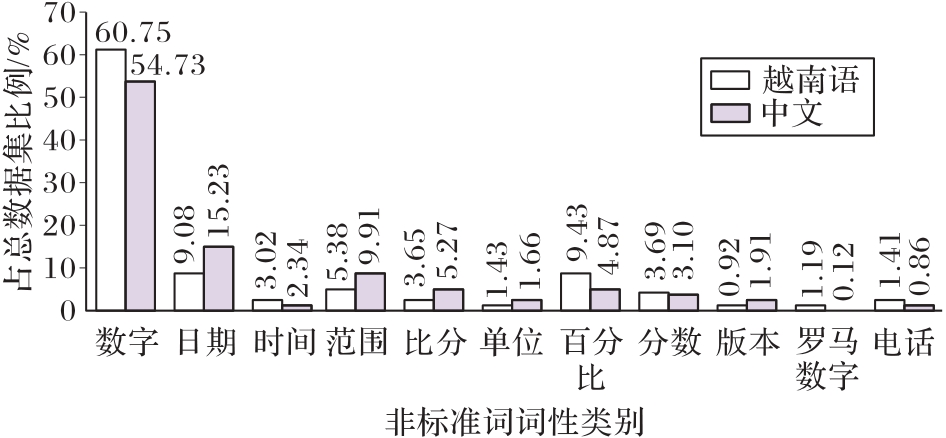
Fig.3 Non-standard word part of speech distribution
| 数据集 | 训练方式 | 精准率 | 召回率 | F1值 | SER |
|---|---|---|---|---|---|
| 越南语 | FastCorrect+Unlabeled data | 73.43 | 70.57 | 71.97 | 85.62 |
| FastCorrect+Label data | 93.64 | 90.84 | 92.22 | 29.57 | |
| FastCorrect+Label data+Improved editing algorithm | 94.85 | 91.59 | 93.20 | 16.47 | |
| FastCorrect+Label data+Abbreviation dictionary | 94.21 | 91.94 | 93.06 | 14.18 | |
| FastCorrect+Label data+Modified tag vector | 96.48 | 94.29 | 95.37 | 11.57 | |
| FastCorrect+Label data+Abbreviation dictionary+Improved editing algorithm+Modified tag vector | 97.14 | 94.86 | 95.99 | 7.23 | |
| 中文 | FastCorrect+Unlabeled data | 70.03 | 67.83 | 68.91 | 81.56 |
| FastCorrect+Label data | 88.16 | 86.04 | 87.09 | 26.57 | |
| FastCorrect+Label data+Improved editing algorithm | 95.06 | 92.10 | 93.56 | 13.24 | |
| FastCorrect+Label data+Abbreviation dictionary | 91.54 | 88.79 | 90.14 | 18.95 | |
| FastCorrect+Label data+Modified tag vector | 94.66 | 92.72 | 93.68 | 16.57 | |
| FastCorrect+Label data+Abbreviation dictionary+Improved editing algorithm+Modified tag vector | 96.27 | 94.22 | 95.23 | 8.96 |
Tab. 6 Evaluation indicators of six training methods
| 数据集 | 训练方式 | 精准率 | 召回率 | F1值 | SER |
|---|---|---|---|---|---|
| 越南语 | FastCorrect+Unlabeled data | 73.43 | 70.57 | 71.97 | 85.62 |
| FastCorrect+Label data | 93.64 | 90.84 | 92.22 | 29.57 | |
| FastCorrect+Label data+Improved editing algorithm | 94.85 | 91.59 | 93.20 | 16.47 | |
| FastCorrect+Label data+Abbreviation dictionary | 94.21 | 91.94 | 93.06 | 14.18 | |
| FastCorrect+Label data+Modified tag vector | 96.48 | 94.29 | 95.37 | 11.57 | |
| FastCorrect+Label data+Abbreviation dictionary+Improved editing algorithm+Modified tag vector | 97.14 | 94.86 | 95.99 | 7.23 | |
| 中文 | FastCorrect+Unlabeled data | 70.03 | 67.83 | 68.91 | 81.56 |
| FastCorrect+Label data | 88.16 | 86.04 | 87.09 | 26.57 | |
| FastCorrect+Label data+Improved editing algorithm | 95.06 | 92.10 | 93.56 | 13.24 | |
| FastCorrect+Label data+Abbreviation dictionary | 91.54 | 88.79 | 90.14 | 18.95 | |
| FastCorrect+Label data+Modified tag vector | 94.66 | 92.72 | 93.68 | 16.57 | |
| FastCorrect+Label data+Abbreviation dictionary+Improved editing algorithm+Modified tag vector | 96.27 | 94.22 | 95.23 | 8.96 |
| 不同训练方式 | 准确率 |
|---|---|
| FastCorrect+Unlabeled data | 31.79 |
| FastCorrect+Label data | 83.79 |
| FastCorrect+Label data+Improved editing algorithm | 84.80 |
| FastCorrect+Label data+Abbreviation dictionary | 84.35 |
| FastCorrect+Label data+Modified tag vector | 90.39 |
| FastCorrect+Label data+Abbreviation dictionary+ Improved editing algorithm+Modified tag vector | 91.50 |
Tab. 7 Prediction accuracies of indicators tag vector
| 不同训练方式 | 准确率 |
|---|---|
| FastCorrect+Unlabeled data | 31.79 |
| FastCorrect+Label data | 83.79 |
| FastCorrect+Label data+Improved editing algorithm | 84.80 |
| FastCorrect+Label data+Abbreviation dictionary | 84.35 |
| FastCorrect+Label data+Modified tag vector | 90.39 |
| FastCorrect+Label data+Abbreviation dictionary+ Improved editing algorithm+Modified tag vector | 91.50 |
| 类别 | 越南语 | 汉语 | ||||
|---|---|---|---|---|---|---|
| 精准率 | 召回率 | F1值 | 精准率 | 召回率 | F1值 | |
| 数字 | 0.968 9 | 0.974 6 | 0.971 7 | 0.956 8 | 0.973 4 | 0.965 0 |
| 日期 | 0.908 3 | 0.959 3 | 0.933 1 | 0.930 6 | 0.926 7 | 0.928 7 |
| 时间 | 0.944 8 | 0.968 1 | 0.956 3 | 0.937 7 | 0.957 2 | 0.947 4 |
| 范围 | 0.922 1 | 0.857 2 | 0.888 5 | 0.909 3 | 0.926 8 | 0.918 0 |
| 比分 | 0.900 9 | 0.835 7 | 0.867 1 | 0.829 0 | 0.947 8 | 0.884 4 |
| 单位 | 0.839 4 | 0.968 9 | 0.899 5 | 0.847 4 | 0.904 5 | 0.875 0 |
| 百分比 | 0.859 4 | 0.963 7 | 0.908 6 | 0.805 5 | 0.960 0 | 0.876 0 |
| 分数 | 0.841 7 | 0.947 0 | 0.891 3 | 0.788 4 | 0.937 8 | 0.856 6 |
| 版本 | 0.985 0 | 0.991 7 | 0.988 3 | 0.933 7 | 0.995 8 | 0.963 8 |
| 罗马数字 | 0.994 8 | 1.000 0 | 0.997 4 | 0.970 7 | 0.997 8 | 0.984 1 |
| 电话 | 0.988 9 | 0.993 7 | 0.991 3 | 0.971 8 | 0.991 0 | 0.981 3 |
Tab. 8 Evaluation indicators of main experiment under different non-standard words
| 类别 | 越南语 | 汉语 | ||||
|---|---|---|---|---|---|---|
| 精准率 | 召回率 | F1值 | 精准率 | 召回率 | F1值 | |
| 数字 | 0.968 9 | 0.974 6 | 0.971 7 | 0.956 8 | 0.973 4 | 0.965 0 |
| 日期 | 0.908 3 | 0.959 3 | 0.933 1 | 0.930 6 | 0.926 7 | 0.928 7 |
| 时间 | 0.944 8 | 0.968 1 | 0.956 3 | 0.937 7 | 0.957 2 | 0.947 4 |
| 范围 | 0.922 1 | 0.857 2 | 0.888 5 | 0.909 3 | 0.926 8 | 0.918 0 |
| 比分 | 0.900 9 | 0.835 7 | 0.867 1 | 0.829 0 | 0.947 8 | 0.884 4 |
| 单位 | 0.839 4 | 0.968 9 | 0.899 5 | 0.847 4 | 0.904 5 | 0.875 0 |
| 百分比 | 0.859 4 | 0.963 7 | 0.908 6 | 0.805 5 | 0.960 0 | 0.876 0 |
| 分数 | 0.841 7 | 0.947 0 | 0.891 3 | 0.788 4 | 0.937 8 | 0.856 6 |
| 版本 | 0.985 0 | 0.991 7 | 0.988 3 | 0.933 7 | 0.995 8 | 0.963 8 |
| 罗马数字 | 0.994 8 | 1.000 0 | 0.997 4 | 0.970 7 | 0.997 8 | 0.984 1 |
| 电话 | 0.988 9 | 0.993 7 | 0.991 3 | 0.971 8 | 0.991 0 | 0.981 3 |
| 模型 | 准确率 | F1值 |
|---|---|---|
| Rule-based | 85.37 | 85.02 |
| RNN(Sequence generation) | 58.37 | 55.75 |
| BERT-BiGRU-CRF | 86.64 | 83.61 |
| g2pM+normalization | 91.41 | 88.39 |
| Transformer encoder | 93.57 | 92.08 |
| WFST+LM | 95.85 | 93.77 |
| 本文模型 | 97.14 | 95.99 |
Tab. 9 Comparison of experimental results of proposed model and different baseline models
| 模型 | 准确率 | F1值 |
|---|---|---|
| Rule-based | 85.37 | 85.02 |
| RNN(Sequence generation) | 58.37 | 55.75 |
| BERT-BiGRU-CRF | 86.64 | 83.61 |
| g2pM+normalization | 91.41 | 88.39 |
| Transformer encoder | 93.57 | 92.08 |
| WFST+LM | 95.85 | 93.77 |
| 本文模型 | 97.14 | 95.99 |
| 1 | NGUYEN T T T, PHAM T T, TRAN D D. A method for Vietnamese text normalization to improve the quality of speech synthesis[C]// Proceedings of the 1st Symposium on Information and Communication Technology. New York: ACM, 2010:78-85. |
| 2 | SPROAT R, BLACK A W, CHEN S, et al. Normalization of non-standard words[J]. Computer Speech and Language, 2001, 15(3):287-333. |
| 3 | 贾玉祥,黄德智,刘武,等. 中文语音合成中的文本正则化研究[J]. 中文信息学报, 2008, 22(5):45-50, 55. |
| JIA Y X, HUANG D Z, LIU W, et al. Text normalization in Chinese text-to-speech system[J]. Journal of Chinese Information Processing, 2008, 22(5):45-50, 55. | |
| 4 | DINH T A, PHI T L, PHAN D H. A study of text normalization in Vietnamese for text-to-speech system[C]// Proceedings of the 2012 International Conference on Speech Database and Assessments. Piscataway: IEEE, 2012: 285-290. |
| 5 | SIGURÐARDÓTTIR H S, NIKULÁSDÓTTIR A B, GUÐNASON J. Creating data in Icelandic for text normalization[C]// Proceedings of the 23rd Nordic Conference on Computational Linguistics. Linköping: Linköping University Electronic Press, 2021:404-412. |
| 6 | TRANG N T T, BACH D X, TUNG N X. A hybrid method for Vietnamese text normalization[C]// Proceedings of the 3rd International Conference on Natural Language Processing and Information Retrieval. New York: ACM, 2019: 104-109. |
| 7 | SPROAT R, JAITLY N. RNN approaches to text normalization: a challenge[EB/OL]. [2024-04-14].. |
| 8 | PO J H, STAHLBERG F, WU K, et al. Transformer-based models of text normalization for speech applications[EB/OL]. [2024-04-14].. |
| 9 | SPROAT R, JAITLY N. An RNN model of text normalization[C]// Proceedings of the INTERSPEECH 2017. [S.l.]: International Speech Communication Association, 2017:754-758. |
| 10 | ZHANG H, SPROAT R, NG A H, et al. Neural models of text normalization for speech applications[J]. Computational Linguistics, 2019, 45(2):293-337. |
| 11 | PARK K, LEE S. g2pM: a neural grapheme-to-phoneme conversion package for mandarin Chinese based on a new open benchmark dataset[C]// Proceedings of the INTERSPEECH 2020. [S.l.]: International Speech Communication Association, 2020: 1723-1727. |
| 12 | 王剑,姜林,王琳钦,等. 基于BiLSTM的低资源老挝语文本正则化任务[J]. 计算机工程与科学, 2023, 45(7): 1292-1299. |
| WANG J, JIANG L, WANG L Q, et al. A low-resource Lao text regularization task based on BiLSTM[J]. Computer Engineering and Science, 2023, 45(7): 1292-1299. | |
| 13 | DANG H T, VUONG T H Y, PHAN X H. Non-standard Vietnamese word detection and normalization for text-to-speech[C]// Proceedings of the 14th International Conference on Knowledge and Systems Engineering. Piscataway: IEEE, 2022:1-6. |
| 14 | BAKHTURINA E, ZHANG Y, GINSBURG B. Shallow fusion of weighted finite-state transducer and language model for text normalization[C]// Proceedings of the INTERSPEECH 2022. [S.l.]: International Speech Communication Association, 2022: 491-495. |
| 15 | DAI W, SONG C, LI X, et al. An end-to-end Chinese text normalization model based on rule-guided flat-lattice transformer[C]// Proceedings of the 2022 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2022:7122-7126. |
| 16 | TYAGI S, BONAFONTE A, LORENZO-TRUEBA J, et al. Proteno: text normalization with limited data for fast deployment in text to speech systems[C]// Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies: Industry Papers. Stroudsburg: ACL, 2021: 72-79. |
| 17 | LENG Y, TAN X, ZHU L, et al. FastCorrect: fast error correction with edit alignment for automatic speech recognition[C]// Proceedings of the 35th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2021:21708-21719. |
| 18 | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2017: 6000-6010. |
| 19 | OTT M, EDUNOV S, BAEVSKI A, et al. fairseq: a fast, extensible toolkit for sequence modeling[C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics (Demonstrations). Stroudsburg: ACL, 2019: 48-53. |
| 20 | BA J L, KIROS J R, HINTON G E, et al. Layer normalization[EB/OL]. [2024-04-14].. |
| 21 | GU J, BRADBURY J, XIONG C, et al. Non-autoregressive neural machine translation[EB/OL]. [2024-04-14].. |
| 22 | SONG X C, WU D, WU Z, et al. TrimTail: low-latency streaming ASR with simple but effective spectrogram-level length penalty[C]// Proceedings of the 2023 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2023:1-5. |
| [1] | Shengxiang GAO, Zhe HOU, Zhengtao YU, Hua LAI. Chinese-Vietnamese neural machine translation model incorporating entity translation [J]. Journal of Computer Applications, 2025, 45(1): 69-74. |
| [2] | Qiang FU, Zhenping XU, Wenxing SHENG, Qing YE. End-to-end Chinese speech recognition method with byte-level byte pair encoding [J]. Journal of Computer Applications, 2025, 45(1): 318-324. |
| [3] | Zhihao WU, Ziqiu CHI, Ting XIAO, Zhe WANG. Meta-learning adaption for few-shot text-to-speech [J]. Journal of Computer Applications, 2024, 44(5): 1629-1635. |
| [4] | Hua LAI, Tong SUN, Wenjun WANG, Zhengtao YU, Shengxiang GAO, Ling DONG. Text punctuation restoration for Vietnamese speech recognition with multimodal features [J]. Journal of Computer Applications, 2024, 44(2): 418-423. |
| [5] | Cong LIU, Genshun WAN, Jianqing GAO, Zhonghua FU. End-to-end speech recognition method based on prosodic features [J]. Journal of Computer Applications, 2023, 43(2): 380-384. |
| [6] | Lei YANG, Hongdong ZHAO, Kuaikuai YU. End-to-end speech emotion recognition based on multi-head attention [J]. Journal of Computer Applications, 2022, 42(6): 1869-1875. |
| [7] | JIA Chengxun, LAI Hua, YU Zhengtao, WEN Yonghua, YU Zhiqiang. Chinese-Vietnamese pseudo-parallel corpus generation based on monolingual language model [J]. Journal of Computer Applications, 2021, 41(6): 1652-1658. |
| [8] | GUO Shuai, SU Yang. Encrypted traffic classification method based on data stream [J]. Journal of Computer Applications, 2021, 41(5): 1386-1391. |
| [9] | Yate FENG, Yimin WEN. Vietnamese scene text detection based on modified Mask R-CNN [J]. Journal of Computer Applications, 2021, 41(12): 3551-3557. |
| [10] | WU Saisai, LIANG Xiaohe, XIE Nengfu, ZHOU Ailian, HAO Xinning. Annotation method for joint extraction of domain-oriented entities and relations [J]. Journal of Computer Applications, 2021, 41(10): 2858-2863. |
| [11] | HU Xuemin, TONG Xiuchi, GUO Lin, ZHANG Ruohan, KONG Li. End-to-end autonomous driving model based on deep visual attention neural network [J]. Journal of Computer Applications, 2020, 40(7): 1926-1931. |
| [12] | CHEN Xiukai, LU Zhihua, ZHOU Yu. Speech separation algorithm based on convolutional encoder decoder and gated recurrent unit [J]. Journal of Computer Applications, 2020, 40(7): 2137-2141. |
| [13] | WANG Jian, TANG Shan, HUANG Yuxin, YU Zhengtao. Chinese-Vietnamese bilingual multi-document news opinion sentence recognition based on sentence association graph [J]. Journal of Computer Applications, 2020, 40(10): 2845-2849. |
| [14] | JIA Yongchao, HE Xiaowei, ZHENG Zhonglong. Object tracking algorithm combining re-detection mechanism and convolutional regression network [J]. Journal of Computer Applications, 2019, 39(8): 2247-2251. |
| [15] | QIU Zeyu, QU Dan, ZHANG Lianhai. End-to-end speech synthesis based on WaveNet [J]. Journal of Computer Applications, 2019, 39(5): 1325-1329. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||