


Journal of Computer Applications ›› 2025, Vol. 45 ›› Issue (9): 2949-2956.DOI: 10.11772/j.issn.1001-9081.2024081166
• Multimedia computing and computer simulation • Previous Articles
Received:2024-08-19
Revised:2024-11-28
Accepted:2024-12-10
Online:2025-02-17
Published:2025-09-10
Contact:
Liqun LIU
About author:LI Jin, born in 2001, M. S. candidate. Her research interests include deep learning, image fusion.
Supported by:
李进1, 刘立群2( )
)
通讯作者:
刘立群
作者简介:李进(2001—),女,江西抚州人,硕士研究生,主要研究方向:深度学习、图像融合
基金资助:CLC Number:
Jin LI, Liqun LIU. SAR and visible image fusion based on residual Swin Transformer[J]. Journal of Computer Applications, 2025, 45(9): 2949-2956.
李进, 刘立群. 基于残差Swin Transformer的SAR与可见光图像融合[J]. 《计算机应用》唯一官方网站, 2025, 45(9): 2949-2956.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2024081166
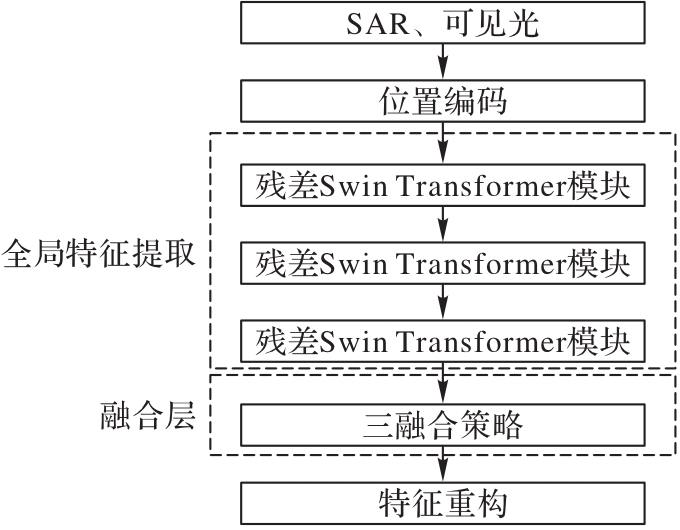
Fig. 1 Overall structure of proposed algorithm
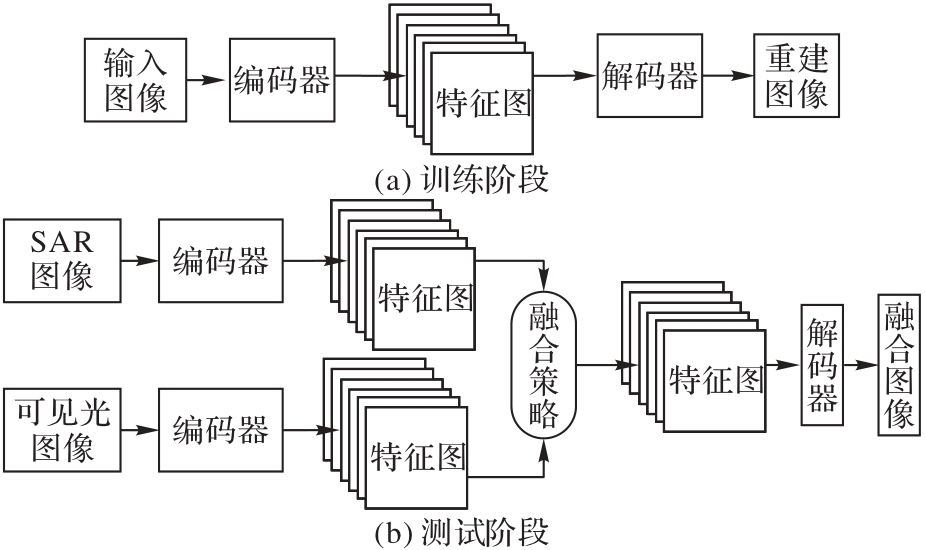
Fig. 2 Flows of training and testing phases

Fig. 3 Residual Swin Transformer module

Fig. 4 Weighted average flow of three fusion strategies
| a | b | c | AG | MI | SD | PSNR/dB | SF | EN |
|---|---|---|---|---|---|---|---|---|
| 0.05 | 0.05 | 0.9 | 13.26 | 2.32 | 49.22 | 55.51 | 26.74 | 4.79 |
| 0.10 | 0.10 | 0.8 | 12.40 | 1.98 | 47.68 | 54.72 | 26.55 | 4.37 |
| 0.15 | 0.15 | 0.7 | 12.63 | 2.72 | 48.85 | 56.21 | 28.45 | 5.77 |
| 12.04 | 2.78 | 49.53 | 56.84 | 30.31 | 6.18 | |||
| 0.25 | 0.25 | 0.5 | 10.48 | 2.64 | 49.66 | 53.92 | 27.90 | 5.54 |
| 0.30 | 0.30 | 0.4 | 9.74 | 2.36 | 44.34 | 52.44 | 25.36 | 5.11 |
| 0.35 | 0.35 | 0.3 | 8.65 | 1.57 | 44.60 | 50.47 | 24.10 | 4.86 |
| 0.40 | 0.40 | 0.2 | 7.36 | 1.62 | 42.05 | 48.33 | 25.08 | 3.95 |
| 0.45 | 0.45 | 0.1 | 6.95 | 1.79 | 40.84 | 47.70 | 23.52 | 4.06 |
Tab. 1 Test results of fusion strategy parameter settings
| a | b | c | AG | MI | SD | PSNR/dB | SF | EN |
|---|---|---|---|---|---|---|---|---|
| 0.05 | 0.05 | 0.9 | 13.26 | 2.32 | 49.22 | 55.51 | 26.74 | 4.79 |
| 0.10 | 0.10 | 0.8 | 12.40 | 1.98 | 47.68 | 54.72 | 26.55 | 4.37 |
| 0.15 | 0.15 | 0.7 | 12.63 | 2.72 | 48.85 | 56.21 | 28.45 | 5.77 |
| 12.04 | 2.78 | 49.53 | 56.84 | 30.31 | 6.18 | |||
| 0.25 | 0.25 | 0.5 | 10.48 | 2.64 | 49.66 | 53.92 | 27.90 | 5.54 |
| 0.30 | 0.30 | 0.4 | 9.74 | 2.36 | 44.34 | 52.44 | 25.36 | 5.11 |
| 0.35 | 0.35 | 0.3 | 8.65 | 1.57 | 44.60 | 50.47 | 24.10 | 4.86 |
| 0.40 | 0.40 | 0.2 | 7.36 | 1.62 | 42.05 | 48.33 | 25.08 | 3.95 |
| 0.45 | 0.45 | 0.1 | 6.95 | 1.79 | 40.84 | 47.70 | 23.52 | 4.06 |

Fig. 5 Qualitative comparison results of different image fusion algorithms on SEN1-2 dataset
| 算法 | AG | MI | SD | PSNR/dB | SF | EN |
|---|---|---|---|---|---|---|
| IFCNN[ | 9.83 | 2.59 | 47.17 | 53.63 | 27.28 | 5.92 |
| GANMcC[ | 10.92 | 2.76 | 49.88 | 55.12 | 26.60 | 5.74 |
| MDLatLRR[ | 11.44 | 2.61 | 47.20 | 53.24 | 26.31 | 5.42 |
| Swinfuse[ | 12.68 | 2.62 | 49.36 | 56.79 | 30.29 | 6.08 |
| DSFusion[ | 13.32 | 2.74 | 47.27 | 60.33 | 29.64 | 5.89 |
| 本文算法 | 12.04 | 2.78 | 49.53 | 56.84 | 30.31 | 6.18 |
Tab. 2 Quantitative test results of different image fusion algorithms on SEN1-2 dataset
| 算法 | AG | MI | SD | PSNR/dB | SF | EN |
|---|---|---|---|---|---|---|
| IFCNN[ | 9.83 | 2.59 | 47.17 | 53.63 | 27.28 | 5.92 |
| GANMcC[ | 10.92 | 2.76 | 49.88 | 55.12 | 26.60 | 5.74 |
| MDLatLRR[ | 11.44 | 2.61 | 47.20 | 53.24 | 26.31 | 5.42 |
| Swinfuse[ | 12.68 | 2.62 | 49.36 | 56.79 | 30.29 | 6.08 |
| DSFusion[ | 13.32 | 2.74 | 47.27 | 60.33 | 29.64 | 5.89 |
| 本文算法 | 12.04 | 2.78 | 49.53 | 56.84 | 30.31 | 6.18 |

Fig. 6 Qualitative comparison results of different image fusion algorithms on QXS-SAROPT dataset
| 算法 | AG | MI | SD | PSNR/dB | SF | EN |
|---|---|---|---|---|---|---|
| IFCNN[ | 10.41 | 2.13 | 28.55 | 58.69 | 43.72 | 5.78 |
| GANMcC[ | 18.07 | 2.71 | 39.98 | 61.20 | 46.39 | 6.03 |
| MDLatLRR[ | 13.34 | 1.89 | 36.32 | 52.46 | 27.48 | 5.34 |
| Swinfuse[ | 22.19 | 2.04 | 57.71 | 58.83 | 28.95 | 5.95 |
| DSFusion[ | 20.48 | 2.44 | 40.72 | 59.78 | 47.33 | 6.11 |
| 本文算法 | 8.93 | 2.79 | 30.96 | 60.91 | 48.14 | 6.14 |
Tab. 3 Quantitative test results of different image fusion algorithms on QXS-SAROPT dataset
| 算法 | AG | MI | SD | PSNR/dB | SF | EN |
|---|---|---|---|---|---|---|
| IFCNN[ | 10.41 | 2.13 | 28.55 | 58.69 | 43.72 | 5.78 |
| GANMcC[ | 18.07 | 2.71 | 39.98 | 61.20 | 46.39 | 6.03 |
| MDLatLRR[ | 13.34 | 1.89 | 36.32 | 52.46 | 27.48 | 5.34 |
| Swinfuse[ | 22.19 | 2.04 | 57.71 | 58.83 | 28.95 | 5.95 |
| DSFusion[ | 20.48 | 2.44 | 40.72 | 59.78 | 47.33 | 6.11 |
| 本文算法 | 8.93 | 2.79 | 30.96 | 60.91 | 48.14 | 6.14 |

Fig. 7 Qualitative comparison results of different image fusion algorithms on OSdataset
| 算法 | AG | MI | SD | PSNR/dB | SF | EN |
|---|---|---|---|---|---|---|
| IFCNN[ | 9.54 | 2.43 | 24.77 | 44.28 | 34.61 | 5.04 |
| GANMcC[ | 10.23 | 2.36 | 25.41 | 46.01 | 38.85 | 5.57 |
| MDLatLRR[ | 11.80 | 2.48 | 27.86 | 48.69 | 37.35 | 4.84 |
| Swinfuse[ | 13.64 | 2.51 | 25.99 | 48.34 | 39.97 | 5.73 |
| DSFusion[ | 18.66 | 2.54 | 26.82 | 50.26 | 38.59 | 7.32 |
| 本文算法 | 10.37 | 2.56 | 27.83 | 50.88 | 40.13 | 5.22 |
Tab. 4 Quantitative test results of different image fusion algorithms on OSdataset
| 算法 | AG | MI | SD | PSNR/dB | SF | EN |
|---|---|---|---|---|---|---|
| IFCNN[ | 9.54 | 2.43 | 24.77 | 44.28 | 34.61 | 5.04 |
| GANMcC[ | 10.23 | 2.36 | 25.41 | 46.01 | 38.85 | 5.57 |
| MDLatLRR[ | 11.80 | 2.48 | 27.86 | 48.69 | 37.35 | 4.84 |
| Swinfuse[ | 13.64 | 2.51 | 25.99 | 48.34 | 39.97 | 5.73 |
| DSFusion[ | 18.66 | 2.54 | 26.82 | 50.26 | 38.59 | 7.32 |
| 本文算法 | 10.37 | 2.56 | 27.83 | 50.88 | 40.13 | 5.22 |

Fig. 8 Comparison of fusion results on SEN1-2 dataset

Fig. 9 Comparison of fusion results on QXS-SAROPT dataset

Fig. 10 Comparison of fusion results on OSdataset
| 融合策略 | AG | MI | SD | PSNR/dB | SF | EN |
|---|---|---|---|---|---|---|
| 策略1 | 14.52 | 2.58 | 48.29 | 55.97 | 31.26 | 6.75 |
| 策略2+3 | 15.54 | 2.42 | 47.83 | 55.86 | 27.86 | 6.14 |
| 策略1+2 | 14.31 | 2.62 | 48.59 | 56.04 | 28.63 | 6.91 |
| 策略1+3 | 15.76 | 2.61 | 48.11 | 55.75 | 29.98 | 6.87 |
| 本文算法 | 15.97 | 2.60 | 49.54 | 56.06 | 30.79 | 6.89 |
Tab. 5 Ablation experimental results of different fusion strategies on SEN1-2 dataset
| 融合策略 | AG | MI | SD | PSNR/dB | SF | EN |
|---|---|---|---|---|---|---|
| 策略1 | 14.52 | 2.58 | 48.29 | 55.97 | 31.26 | 6.75 |
| 策略2+3 | 15.54 | 2.42 | 47.83 | 55.86 | 27.86 | 6.14 |
| 策略1+2 | 14.31 | 2.62 | 48.59 | 56.04 | 28.63 | 6.91 |
| 策略1+3 | 15.76 | 2.61 | 48.11 | 55.75 | 29.98 | 6.87 |
| 本文算法 | 15.97 | 2.60 | 49.54 | 56.06 | 30.79 | 6.89 |
| 融合策略 | AG | MI | SD | PSNR/dB | SF | EN |
|---|---|---|---|---|---|---|
| 策略1 | 12.51 | 2.96 | 53.08 | 62.37 | 41.25 | 7.18 |
| 策略2+3 | 8.12 | 2.58 | 40.27 | 61.54 | 30.86 | 6.46 |
| 策略1+2 | 12.48 | 3.09 | 43.65 | 63.12 | 38.39 | 7.51 |
| 策略1+3 | 12.66 | 3.03 | 42.79 | 62.49 | 37.71 | 7.24 |
| 本文算法 | 8.83 | 3.14 | 40.94 | 63.59 | 31.87 | 7.42 |
Tab. 6 Ablation experimental results of different fusion strategies on QXS-SAROPT dataset
| 融合策略 | AG | MI | SD | PSNR/dB | SF | EN |
|---|---|---|---|---|---|---|
| 策略1 | 12.51 | 2.96 | 53.08 | 62.37 | 41.25 | 7.18 |
| 策略2+3 | 8.12 | 2.58 | 40.27 | 61.54 | 30.86 | 6.46 |
| 策略1+2 | 12.48 | 3.09 | 43.65 | 63.12 | 38.39 | 7.51 |
| 策略1+3 | 12.66 | 3.03 | 42.79 | 62.49 | 37.71 | 7.24 |
| 本文算法 | 8.83 | 3.14 | 40.94 | 63.59 | 31.87 | 7.42 |
| 融合策略 | AG | MI | SD | PSNR/dB | SF | EN |
|---|---|---|---|---|---|---|
| 策略1 | 7.72 | 2.46 | 42.45 | 37.64 | 21.10 | 3.67 |
| 策略2+3 | 7.65 | 2.61 | 40.99 | 38.09 | 22.34 | 3.44 |
| 策略1+2 | 9.96 | 3.53 | 45.12 | 42.90 | 23.50 | 4.65 |
| 策略1+3 | 9.35 | 3.67 | 43.66 | 42.17 | 26.44 | 5.28 |
| 本文算法 | 10.68 | 3.85 | 46.10 | 42.33 | 25.76 | 5.54 |
Tab. 7 Ablation experimental results of different fusion strategies on OSdataset
| 融合策略 | AG | MI | SD | PSNR/dB | SF | EN |
|---|---|---|---|---|---|---|
| 策略1 | 7.72 | 2.46 | 42.45 | 37.64 | 21.10 | 3.67 |
| 策略2+3 | 7.65 | 2.61 | 40.99 | 38.09 | 22.34 | 3.44 |
| 策略1+2 | 9.96 | 3.53 | 45.12 | 42.90 | 23.50 | 4.65 |
| 策略1+3 | 9.35 | 3.67 | 43.66 | 42.17 | 26.44 | 5.28 |
| 本文算法 | 10.68 | 3.85 | 46.10 | 42.33 | 25.76 | 5.54 |
| [1] | HUANG S, ZHANG X, WANG C, et al. Two-step fusion method for generating 1 km seamless multi-layer soil moisture with high accuracy in the Qinghai-Tibet plateau [J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2023, 197: 346-363. |
| [2] | GU Y, WANG Y, WU Y, et al. Novel 3D photosynthetic traits derived from the fusion of UAV LiDAR point cloud and multispectral imagery in wheat [J]. Remote Sensing of Environment, 2024, 311: No.114244. |
| [3] | 邢庆宝. 基于深度学习的SAR与可见光图像融合算法研究[D]. 南昌:南昌大学, 2023:22-24. |
| XING Q B. Research on deep learning-based SAR and visible light image fusion algorithm[D]. Nanchang: Nanchang University, 2023: 22-24. | |
| [4] | LIU J, DIAN R, LI S, et al. SGFusion: a saliency guided deep-learning framework for pixel-level image fusion [J]. Information Fusion, 2023, 91: 205-214. |
| [5] | 周涛,刘珊,董雅丽,等. 多尺度变换像素级医学图像融合:研究进展、应用和挑战[J]. 中国图象图形学报, 2021, 26(9):2094-2110. |
| ZHOU T, LIU S, DONG Y L, et al. Research on pixel-level image fusion based on multi-scale transformation: progress application and challenges [J]. Journal of Image and Graphics, 2021, 26(9): 2094-2110. | |
| [6] | 徐景余,包妮沙,郎洁双,等.优化稀疏表示的迷彩伪装目标高光谱识别方法研究[J].光谱学与光谱分析,2024,44(12):3534-3542. |
| XU J Y, BAO N S, LANG J S, et al. A hyperspectral recognition method for camouflaged targets based on background dictionary sparse representation [J]. Spectroscopy and Spectral Analysis, 2024,44(12):3534-3542. | |
| [7] | LI X, LEI L, SUN Y, et al. Multimodal bilinear fusion network with second-order attention based channel selection for land cover classification [J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2020, 13: 1011-1026. |
| [8] | YE Y, LIU W, ZHOU L, et al. An unsupervised SAR and optical image fusion network based on structure-texture decomposition [J]. IEEE Geoscience and Remote Sensing Letters, 2022, 19: No.4028305. |
| [9] | KONG Y, HONG F, LEUNG H, et al. A fusion method of optical image and SAR image based on dense-UGAN and Gram-Schmidt transformation [J]. Remote Sensing, 2021, 13(21): No.4274. |
| [10] | YIN H, XIAO J. Laplacian pyramid generative adversarial network for infrared and visible image fusion [J]. IEEE Signal Processing Letters, 2022, 29: 1988-1992. |
| [11] | DOSOVISKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16x16 words: Transformers for image recognition at scale[EB/OL]. [2024-08-27]. . |
| [12] | HU L, SU S, ZUO Z, et al. A visible and synthetic aperture radar image fusion algorithm based on a Transformer and a convolutional neural network [J]. Electronics, 2024, 13(12): No.2365. |
| [13] | LIU Z, LIN Y, CAO Y, et al. Swin Transformer: hierarchical Vision Transformer using shifted windows [C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 9992-10002. |
| [14] | ZHOU H, LIU Q, WANG Y. PanFormer: a Transformer based model for pan-sharpening [C]// Proceedings of the 2022 IEEE International Geoscience and Remote Sensing Symposium. Piscataway: IEEE, 2022: 1-6. |
| [15] | 范文盛,刘帆,李明. 基于双分支U形Transformer的遥感图像融合[J]. 光子学报, 2023, 52(4): No.0428002. |
| FAN W S, LIU F, LI M. Remote sensing image fusion based on two-branch U-shaped Transformer [J]. Acta Photonica Sinica, 2023, 52(4): No.0428002. | |
| [16] | LI S, WANG G, ZHANG H, et al. SDRSwin: a residual Swin Transformer network with saliency detection for infrared and visible image fusion [J]. Remote Sensing, 2023, 15(18): No.4467. |
| [17] | 李碧草,卢佳熙,刘洲峰,等. 基于Swin Transformer和混合特征聚合的红外与可见光图像融合方法[J]. 红外技术, 2023, 45(7): 721-731. |
| LI B C, LU J X, LIU Z F, et al. Infrared and visible light image fusion method based on Swin Transformer and hybrid feature aggregation [J]. Infrared Technology, 2023, 45(7): 721-731. | |
| [18] | LUO Y, LUO Z. Infrared and visible image fusion algorithm based on improved residual Swin Transformer and Sobel operators [J]. IEEE Access, 2024, 12: 82134-82145. |
| [19] | WANG Z, CHEN Y, SHAO W, et al. Swinfuse: a residual Swin Transformer fusion network for infrared and visible images [J]. IEEE Transactions on Instrumentation and Measurement, 2022, 71: No.5016412. |
| [20] | SCHMITT M, HUGHES L H, ZHU X X. The SEN1-2 dataset for deep learning in SAR-optical data fusion [J]. SPRS Annals of the Photogrammetry, Remote Sensing and Spatial Information Sciences, 2018, Ⅳ-1: 141-146. |
| [21] | HUANG M, XU Y, QIAN L, et al. The QXS-SAROPT dataset for deep learning in SAR-optical data fusion [EB/OL]. [2024-05-21]. . |
| [22] | XIANG Y, TAO R, WANG F, et al. Automatic registration of optical and SAR images via improved phase congruency model [J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2020, 13: 5847-5861. |
| [23] | ZHANG Y, LIU Y, SUN P, et al. IFCNN: a general image fusion framework based on convolutional neural network [J]. Information Fusion, 2020, 54:99-118. |
| [24] | MA J, ZHANG H, SHAO Z, et al. GANMcC: a generative adversarial network with multiclassification constraints for infrared and visible image fusion [J]. IEEE Transactions on Instrumentation and Measurement, 2021, 70: No.5005014. |
| [25] | LI H, WU X, KITTLER J. MDLatLRR: a novel decomposition method for infrared and visible image fusion [J]. IEEE Transactions on Image Processing, 2020, 29:4733-4746. |
| [26] | LIU K, LI M, CHEN C, et al. DSFusion: infrared and visible image fusion method combining detail and scene information [J]. Pattern Recognition, 2024, 154: No.110633. |
| [1] | Yiming LIANG, Jing FAN, Wenze CHAI. Multi-scale feature fusion sentiment classification based on bidirectional cross attention [J]. Journal of Computer Applications, 2025, 45(9): 2773-2782. |
| [2] | Hongjun ZHANG, Gaojun PAN, Hao YE, Yubin LU, Yiheng MIAO. Multi-source heterogeneous data analysis method combining deep learning and tensor decomposition [J]. Journal of Computer Applications, 2025, 45(9): 2838-2847. |
| [3] | Bing YIN, Zhenhua LING, Yin LIN, Changfeng XI, Ying LIU. Emotion recognition method compatible with missing modal reasoning [J]. Journal of Computer Applications, 2025, 45(9): 2764-2772. |
| [4] | Li LI, Han SONG, Peihe LIU, Hanlin CHEN. Named entity recognition for sensitive information based on data augmentation and residual networks [J]. Journal of Computer Applications, 2025, 45(9): 2790-2797. |
| [5] | Jing WANG, Jiaxing LIU, Wanying SONG, Jiaxing XUE, Wenxin DING. Few-shot skin image classification model based on spatial transformer network and feature distribution calibration [J]. Journal of Computer Applications, 2025, 45(8): 2720-2726. |
| [6] | Yanhua LIAO, Yuanxia YAN, Wenlin PAN. Multi-target detection algorithm for traffic intersection images based on YOLOv9 [J]. Journal of Computer Applications, 2025, 45(8): 2555-2565. |
| [7] | Jin ZHOU, Yuzhi LI, Xu ZHANG, Shuo GAO, Li ZHANG, Jiachuan SHENG. Modulation recognition network for complex electromagnetic environments [J]. Journal of Computer Applications, 2025, 45(8): 2672-2682. |
| [8] | Lina GE, Mingyu WANG, Lei TIAN. Review of research on efficiency of federated learning [J]. Journal of Computer Applications, 2025, 45(8): 2387-2398. |
| [9] | Peng PENG, Ziting CAI, Wenling LIU, Caihua CHEN, Wei ZENG, Baolai HUANG. Speech emotion recognition method based on hybrid Siamese network with CNN and bidirectional GRU [J]. Journal of Computer Applications, 2025, 45(8): 2515-2521. |
| [10] | Shuo ZHANG, Guokai SUN, Yuan ZHUANG, Xiaoyu FENG, Jingzhi WANG. Dynamic detection method of eclipse attacks for blockchain node analysis [J]. Journal of Computer Applications, 2025, 45(8): 2428-2436. |
| [11] | Yongpeng TAO, Shiqi BAI, Zhengwen ZHOU. Neural architecture search for multi-tissue segmentation using convolutional and transformer-based networks in glioma segmentation [J]. Journal of Computer Applications, 2025, 45(7): 2378-2386. |
| [12] | Jinxian SUO, Liping ZHANG, Sheng YAN, Dongqi WANG, Yawen ZHANG. Review of interpretable deep knowledge tracing methods [J]. Journal of Computer Applications, 2025, 45(7): 2043-2055. |
| [13] | Haoyu LIU, Pengwei KONG, Yaoli WANG, Qing CHANG. Pedestrian detection algorithm based on multi-view information [J]. Journal of Computer Applications, 2025, 45(7): 2325-2332. |
| [14] | Zhenzhou WANG, Fangfang GUO, Jingfang SU, He SU, Jianchao WANG. Robustness optimization method of visual model for intelligent inspection [J]. Journal of Computer Applications, 2025, 45(7): 2361-2368. |
| [15] | Qiaoling QI, Xiaoxiao WANG, Qianqian ZHANG, Peng WANG, Yongfeng DONG. Label noise adaptive learning algorithm based on meta-learning [J]. Journal of Computer Applications, 2025, 45(7): 2113-2122. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||