


Journal of Computer Applications ›› 2025, Vol. 45 ›› Issue (7): 2325-2332.DOI: 10.11772/j.issn.1001-9081.2024070961
• Multimedia computing and computer simulation • Previous Articles Next Articles
Haoyu LIU1, Pengwei KONG2, Yaoli WANG3( ), Qing CHANG3
), Qing CHANG3
Received:2024-07-10
Revised:2024-09-13
Accepted:2024-09-26
Online:2025-07-10
Published:2025-07-10
Contact:
Yaoli WANG
About author:LIU Haoyu, born in 1999, M. S. candidate. His research interests include computer vision, object detection, object tracking.Supported by:
刘皓宇1, 孔鹏伟2, 王耀力3(), 常青3
通讯作者:
王耀力
作者简介:刘皓宇(1999—),男,陕西宝鸡人,硕士研究生,主要研究方向:计算机视觉、目标检测、目标跟踪基金资助:CLC Number:
Haoyu LIU, Pengwei KONG, Yaoli WANG, Qing CHANG. Pedestrian detection algorithm based on multi-view information[J]. Journal of Computer Applications, 2025, 45(7): 2325-2332.
刘皓宇, 孔鹏伟, 王耀力, 常青. 基于多视角信息的行人检测算法[J]. 《计算机应用》唯一官方网站, 2025, 45(7): 2325-2332.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2024070961
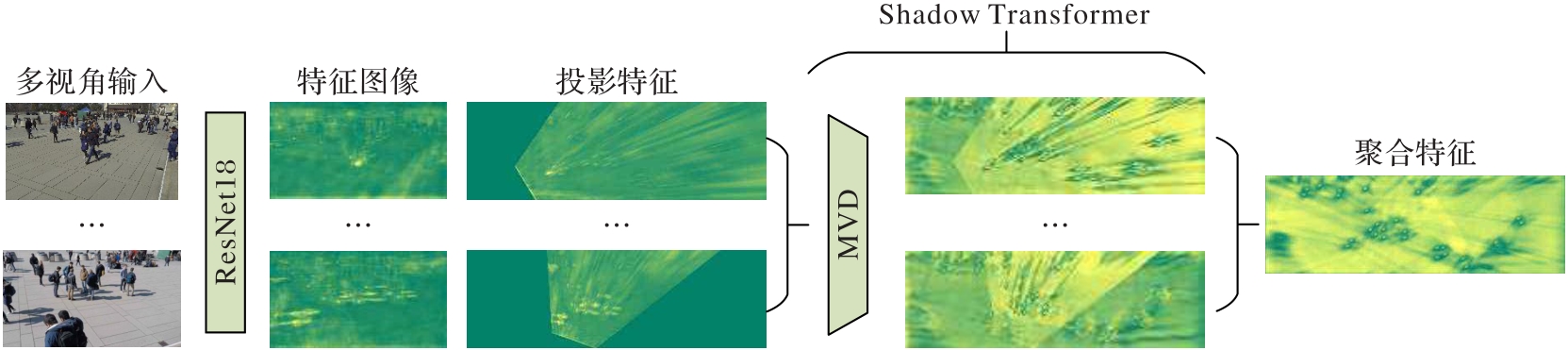
Fig. 1 Flow of MVDeTr algorithm
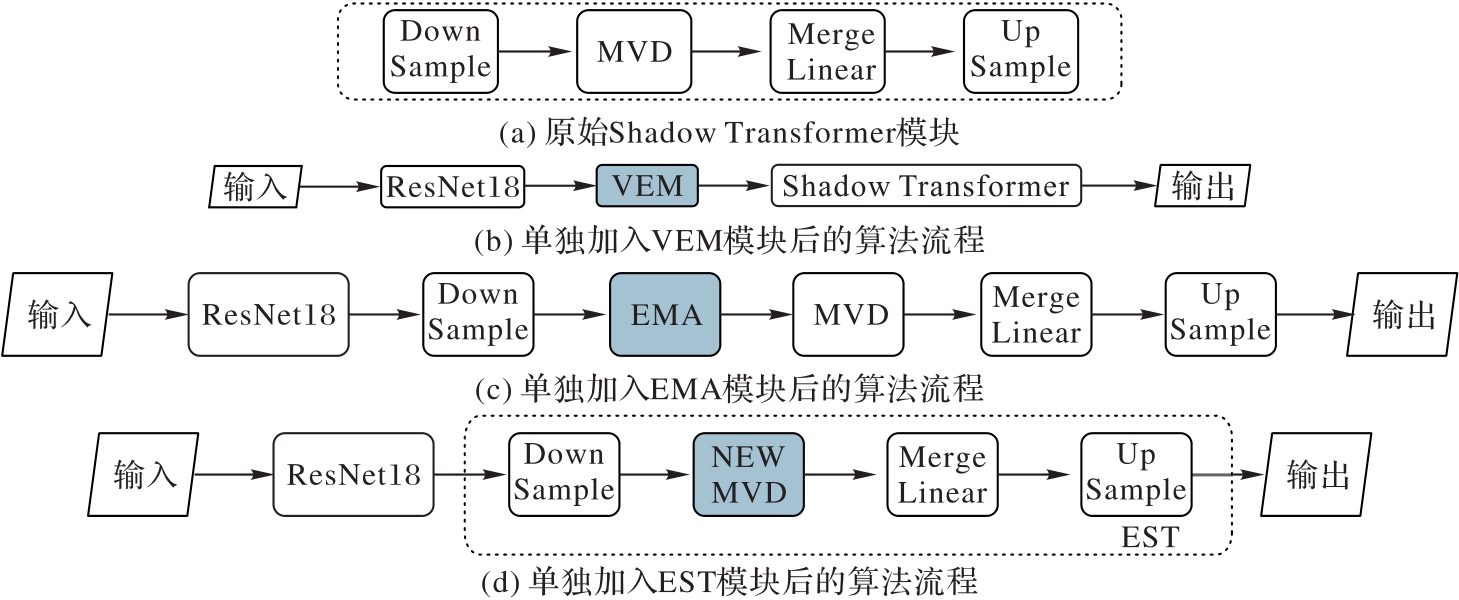
Fig. 2 Algorithm flow after introducing different modules
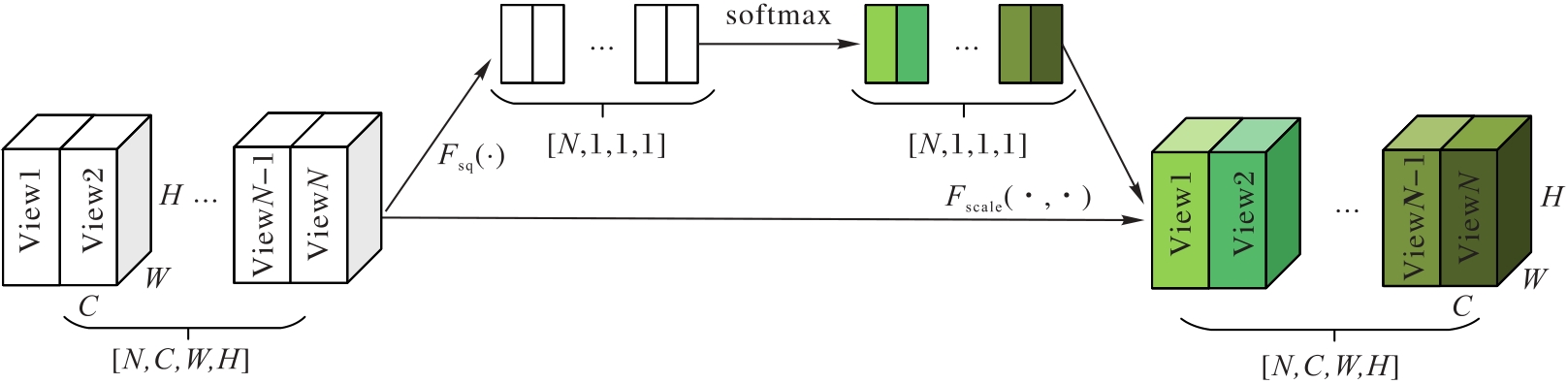
Fig. 3 VEM composition
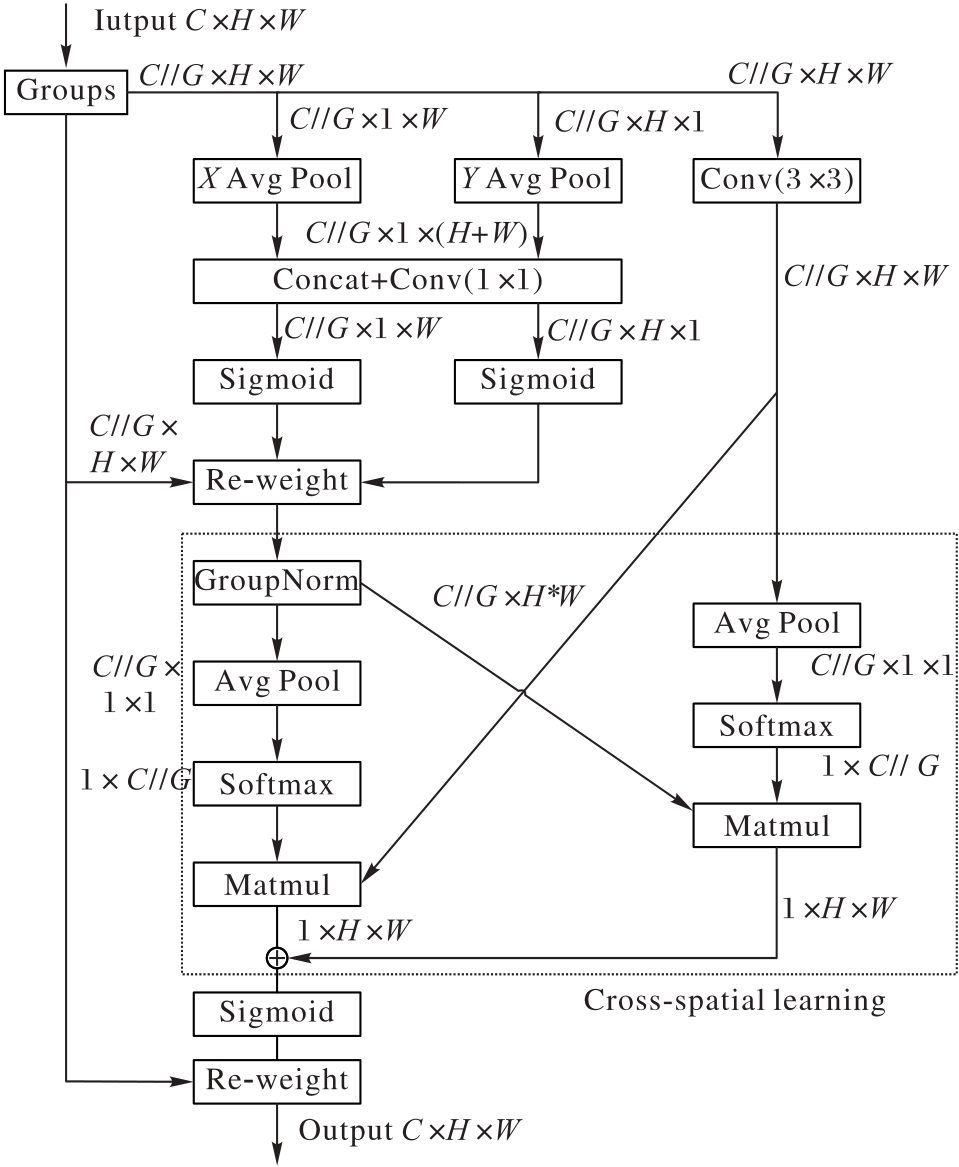
Fig. 4 Structure of EMA module
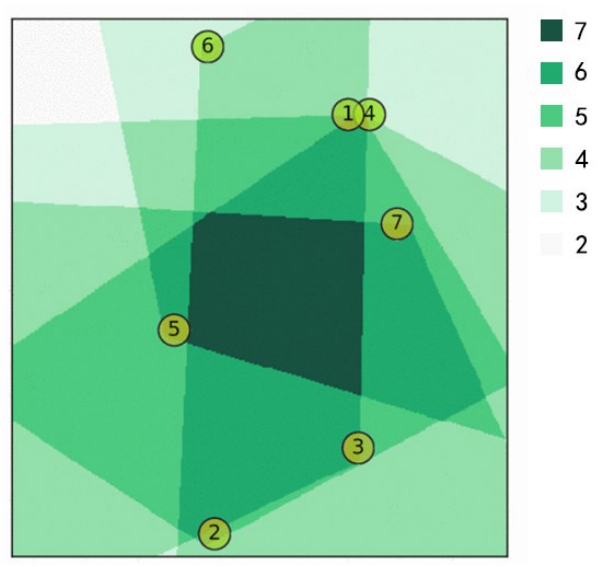
Fig. 5 Overlap among cameras’ fields of view (top view)[18]
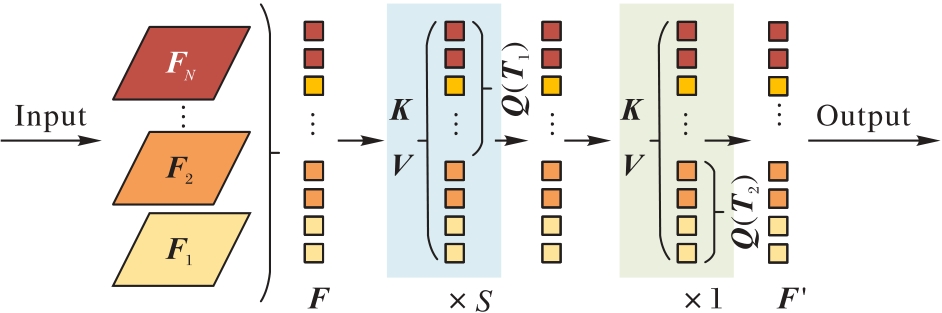
Fig. 6 Structure of EST module
| 名称 | 参数/版本 |
|---|---|
| CPU | Intel Xeon Gold 6230R CPU @ 2.10 GHz |
| GPU | NVIDIA RTX 3090 24G |
| 操作系统 | Ubuntu 18.04 |
| 编程语言 | Python 3.8 |
| 深度学习框架 | PyTorch 1.11 |
Tab. 1 Experimental environment configuration
| 名称 | 参数/版本 |
|---|---|
| CPU | Intel Xeon Gold 6230R CPU @ 2.10 GHz |
| GPU | NVIDIA RTX 3090 24G |
| 操作系统 | Ubuntu 18.04 |
| 编程语言 | Python 3.8 |
| 深度学习框架 | PyTorch 1.11 |
| 对比算法 | MODA | 召回率 |
|---|---|---|
| MVDeTr | 91.5 | 94.0 |
| MVDeTr-SE | 92.2 | 95.5 |
| MVDeTr-ECA | 92.4 | 95.2 |
| MVDeTr-CA | 92.7 | 95.5 |
| MVDeTr-EMA | 93.2 | 95.9 |
Tab. 2 Performance comparison of different attention mechanisms
| 对比算法 | MODA | 召回率 |
|---|---|---|
| MVDeTr | 91.5 | 94.0 |
| MVDeTr-SE | 92.2 | 95.5 |
| MVDeTr-ECA | 92.4 | 95.2 |
| MVDeTr-CA | 92.7 | 95.5 |
| MVDeTr-EMA | 93.2 | 95.9 |
| 对比项 | 浮点运算量/GFLOPs | 浮点运算量减少比率/% | 时间/s | 时间减少比率/% |
|---|---|---|---|---|
| Shadow Transformer | 75.7 | — | 1.336 | — |
| EST (A:5 B:2) | 51.0 | 32.6 | 1.089 | 18.5 |
| EST (A:4 B:3) | 47.2 | 37.6 | 1.033 | 22.7 |
| EST (A:3 B:4) | 43.6 | 42.4 | 0.985 | 26.3 |
Tab. 3 Computation cost and time comparison of different view partitioning strategies
| 对比项 | 浮点运算量/GFLOPs | 浮点运算量减少比率/% | 时间/s | 时间减少比率/% |
|---|---|---|---|---|
| Shadow Transformer | 75.7 | — | 1.336 | — |
| EST (A:5 B:2) | 51.0 | 32.6 | 1.089 | 18.5 |
| EST (A:4 B:3) | 47.2 | 37.6 | 1.033 | 22.7 |
| EST (A:3 B:4) | 43.6 | 42.4 | 0.985 | 26.3 |
| 实验 | VEM | EMA | EST | MODA | MODP | Precision | Recall |
|---|---|---|---|---|---|---|---|
| 基线算法 | 91.5 | 82.1 | 97.4 | 94.0 | |||
| 实验1 | 93.0 | 82.4 | 97.3 | 95.6 | |||
| 实验2 | 93.2 | 82.4 | 97.2 | 95.9 | |||
| 实验3 | 93.4 | 82.9 | 97.3 | 96.1 | |||
| 实验4([A:B=5:2]) | 93.3 | 82.7 | 97.4 | 95.8 | |||
| 实验5([A:B=4:3]) | 93.0 | 82.3 | 97.3 | 95.6 |
Tab. 4 Results of ablation experiments
| 实验 | VEM | EMA | EST | MODA | MODP | Precision | Recall |
|---|---|---|---|---|---|---|---|
| 基线算法 | 91.5 | 82.1 | 97.4 | 94.0 | |||
| 实验1 | 93.0 | 82.4 | 97.3 | 95.6 | |||
| 实验2 | 93.2 | 82.4 | 97.2 | 95.9 | |||
| 实验3 | 93.4 | 82.9 | 97.3 | 96.1 | |||
| 实验4([A:B=5:2]) | 93.3 | 82.7 | 97.4 | 95.8 | |||
| 实验5([A:B=4:3]) | 93.0 | 82.3 | 97.3 | 95.6 |
| 算法 | Wildtrack | MultiviewX | ||||||
|---|---|---|---|---|---|---|---|---|
| MODA | MODP | Precision | Recall | MODA | MODP | Precision | Recall | |
| RCNN&clustering | 11.3 | 18.4 | 68.0 | 43.0 | 18.7 | 46.4 | 63.5 | 43.9 |
| DeepMCD | 67.8 | 64.2 | 85.0 | 82.0 | 70.0 | 73.0 | 85.7 | 83.3 |
| Deep-Occlusion | 74.1 | 53.8 | 95.0 | 80.0 | 75.2 | 54.7 | 97.8 | 80.2 |
| UMPD | 76.6 | 61.2 | 90.1 | 86.0 | 67.5 | 79.4 | 93.4 | 72.6 |
| MVDet | 88.2 | 75.7 | 94.7 | 93.6 | 83.9 | 79.6 | 96.8 | 86.7 |
| SHOT | 90.2 | 76.5 | 96.1 | 94.0 | 88.3 | 82.0 | 96.6 | 91.5 |
| DEMVDet | 90.7 | 75.9 | 95.5 | 95.2 | 89.5 | 81.5 | 98.2 | 93.2 |
| MVDeTr | 91.5 | 82.1 | 97.4 | 94.0 | 93.7 | 91.3 | 99.5 | 94.2 |
| VEM+EMA | 93.4 | 82.9 | 97.3 | 96.1 | 94.3 | 92.0 | 99.3 | 95.0 |
| VEM+EMA+EST | 93.3 | 82.7 | 97.4 | 95.8 | 94.2 | 91.8 | 99.4 | 94.8 |
Tab. 5 Comparison experimental results of different algorithms
| 算法 | Wildtrack | MultiviewX | ||||||
|---|---|---|---|---|---|---|---|---|
| MODA | MODP | Precision | Recall | MODA | MODP | Precision | Recall | |
| RCNN&clustering | 11.3 | 18.4 | 68.0 | 43.0 | 18.7 | 46.4 | 63.5 | 43.9 |
| DeepMCD | 67.8 | 64.2 | 85.0 | 82.0 | 70.0 | 73.0 | 85.7 | 83.3 |
| Deep-Occlusion | 74.1 | 53.8 | 95.0 | 80.0 | 75.2 | 54.7 | 97.8 | 80.2 |
| UMPD | 76.6 | 61.2 | 90.1 | 86.0 | 67.5 | 79.4 | 93.4 | 72.6 |
| MVDet | 88.2 | 75.7 | 94.7 | 93.6 | 83.9 | 79.6 | 96.8 | 86.7 |
| SHOT | 90.2 | 76.5 | 96.1 | 94.0 | 88.3 | 82.0 | 96.6 | 91.5 |
| DEMVDet | 90.7 | 75.9 | 95.5 | 95.2 | 89.5 | 81.5 | 98.2 | 93.2 |
| MVDeTr | 91.5 | 82.1 | 97.4 | 94.0 | 93.7 | 91.3 | 99.5 | 94.2 |
| VEM+EMA | 93.4 | 82.9 | 97.3 | 96.1 | 94.3 | 92.0 | 99.3 | 95.0 |
| VEM+EMA+EST | 93.3 | 82.7 | 97.4 | 95.8 | 94.2 | 91.8 | 99.4 | 94.8 |

Fig. 7 Comparison of detection results between proposed algorithm and MVDeTr algorithm

Fig. 8 Detection results of proposed algorithm on MultiviewX dataset
| [1] | 耿艺宁,刘帅师,刘泰廷,等.基于计算机视觉的行人检测技术综述[J].计算机应用,2021, 41(S1): 43-50. |
| GENG Y N, LIU S S, LIU T T, et al. Survey of pedestrian detection technology based on computer vision [J]. Journal of Computer Applications, 2021, 41(S1): 43-50. | |
| [2] | FLEURET F, BERCLAZ J, LENGAGNE R, et al. Multicamera people tracking with a probabilistic occupancy map [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2008, 30(2): 267-282. |
| [3] | BAQUÉ P, FLEURET F, FUA P. Deep occlusion reasoning for multi-camera multi-target detection [C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2017: 271-279. |
| [4] | 陈丽,马楠,逄桂林,等.多视角数据融合的特征平衡YOLOv3行人检测研究[J].智能系统学报,2021, 16(1): 57-65. |
| CHEN L, MA N, PANG G L, et al. Research on multi-view data fusion and balanced YOLOv3 for pedestrian detection [J]. CAAI Transactions on Intelligent Systems, 2021, 16(1): 57-65. | |
| [5] | HOU Y, ZHENG L, GOULD S. Multiview detection with feature perspective transformation [C]// Proceedings of the 2020 European Conference on Computer Vision, LNCS 12352. Cham: Springer, 2020: 1-18. |
| [6] | HOU Y, ZHENG L. Multiview detection with shadow transformer (and view-coherent data augmentation) [C]// Proceedings of the 29th ACM International Conference on Multimedia. New York: ACM, 2021: 1673-1682. |
| [7] | LIU M, ZHU C, REN S, et al. Unsupervised multi-view pedestrian detection [C]// Proceedings of the 32nd ACM International Conference on Multimedia. New York: ACM, 2024: 1034-1042. |
| [8] | 叶洪滨,林政宽,程红举.基于多相机特征融合的行人检测算法[J].北京邮电大学学报,2023, 46(5): 66-71. |
| YE H B, LIN Z K, CHENG H J. Pedestrian detection algorithm based on multi-camera feature fusion [J]. Journal of Beijing University of Posts and Telecommunications, 2023, 46(5): 66-71. | |
| [9] | HOU Y, LENG X, GEDEON T, et al. Optimizing camera configurations for multi-view pedestrian detection [EB/OL]. [2024-06-10]. . |
| [10] | OUYANG D, HE S, ZHANG G, et al. Efficient multi-scale attention module with cross-spatial learning [C]// Proceedings of the 2023 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2023: 1-5. |
| [11] | HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 770-7783. |
| [12] | LAW H, DENG J. CornerNet: detecting objects as paired keypoints [C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11218. Cham: Springer, 2018: 765-781. |
| [13] | ZHOU X, WANG D, KRÄHENBÜHL P. Objects as points [EB/OL]. [2024-06-10]. . |
| [14] | CARION N, MASSA F, SYNNAEVE G, et al. End-to-end object detection with transformers [C]// Proceedings of the 2020 European Conference on Computer Vision, LNCS 12346. Cham: Springer, 2020: 213-229. |
| [15] | ZHU X, SU W, LU L, et al. Deformable DETR: deformable Transformers for end-to-end object detection [EB/OL]. [2024-06-10]. . |
| [16] | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2017: 6000-6010. |
| [17] | HU J, SHEN L, SUN G. Squeeze-and-excitation networks [C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 7132-7141. |
| [18] | CHAVDAROVA T, BAQUÉ P, BOUQUET S, et al. WILDTRACK: a multi-camera HD dataset for dense unscripted pedestrian detection [C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 5030-5039. |
| [19] | LI F, ZENG A, LIU S, et al. Lite DETR: an interleaved multi-scale encoder for efficient DETR [C]// Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2023: 18558-18567. |
| [20] | HOU Q, ZHOU D, FENG J. Coordinate attention for efficient mobile network design [C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 13708-13717. |
| [21] | WANG Q, WU B, ZHU P, et al. ECA-Net: efficient channel attention for deep convolutional neural networks [C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 11531-11539. |
| [22] | XU Y, LIU X, LIU Y, et al. Multi-view people tracking via hierarchical trajectory composition [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 4256-4265. |
| [23] | CHAVDAROVA T, FLEURET F. Deep multi-camera people detection [C]// Proceedings of the 16th IEEE International Conference on Machine Learning and Applications. Piscataway: IEEE, 2017: 848-853. |
| [24] | SONG L, WU J, YANG M, et al. Stacked homography transformations for multi-view pedestrian detection [C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 6029-6037. |
| [1] | Wei ZHANG, Jiaxiang NIU, Jichao MA, Qiongxia SHEN. Chinese spelling correction model ReLM enhanced with deep semantic features [J]. Journal of Computer Applications, 2025, 45(8): 2484-2490. |
| [2] | Haifeng WU, Liqing TAO, Yusheng CHENG. Partial label regression algorithm integrating feature attention and residual connection [J]. Journal of Computer Applications, 2025, 45(8): 2530-2536. |
| [3] | Chao JING, Yutao QUAN, Yan CHEN. Improved multi-layer perceptron and attention model-based power consumption prediction algorithm [J]. Journal of Computer Applications, 2025, 45(8): 2646-2655. |
| [4] | Jinhao LIN, Chuan LUO, Tianrui LI, Hongmei CHEN. Thoracic disease classification method based on cross-scale attention network [J]. Journal of Computer Applications, 2025, 45(8): 2712-2719. |
| [5] | Jin ZHOU, Yuzhi LI, Xu ZHANG, Shuo GAO, Li ZHANG, Jiachuan SHENG. Modulation recognition network for complex electromagnetic environments [J]. Journal of Computer Applications, 2025, 45(8): 2672-2682. |
| [6] | Chen LIANG, Yisen WANG, Qiang WEI, Jiang DU. Source code vulnerability detection method based on Transformer-GCN [J]. Journal of Computer Applications, 2025, 45(7): 2296-2303. |
| [7] | Yihan WANG, Chong LU, Zhongyuan CHEN. Multimodal sentiment analysis model with cross-modal text information enhancement [J]. Journal of Computer Applications, 2025, 45(7): 2237-2244. |
| [8] | Yuelan ZHANG, Jing SU, Hangyu ZHAO, Baili YANG. Multi-view knowledge-aware and interactive distillation recommendation algorithm [J]. Journal of Computer Applications, 2025, 45(7): 2211-2220. |
| [9] | Xiaoqiang ZHAO, Yongyong LIU, Yongyong HUI, Kai LIU. Batch process quality prediction model using improved time-domain convolutional network with multi-head self-attention mechanism [J]. Journal of Computer Applications, 2025, 45(7): 2245-2252. |
| [10] | Huibin WANG, Zhan’ao HU, Jie HU, Yuanwei XU, Bo WEN. Time series forecasting model based on segmented attention mechanism [J]. Journal of Computer Applications, 2025, 45(7): 2262-2268. |
| [11] | Weigang LI, Xinyi LI, Yongqiang WANG, Yuntao ZHAO. Point cloud classification and segmentation method based on adaptive dynamic graph convolution and parameter-free attention [J]. Journal of Computer Applications, 2025, 45(6): 1980-1986. |
| [12] | Haijie WANG, Guangxin ZHANG, Hai SHI, Shu CHEN. Document-level relation extraction based on entity representation enhancement [J]. Journal of Computer Applications, 2025, 45(6): 1809-1816. |
| [13] | Yuan SONG, Xin CHEN, Yarong LI, Yongwei LI, Yang LIU, Zhen ZHAO. Single-channel speech separation model based on auditory modulation Siamese network [J]. Journal of Computer Applications, 2025, 45(6): 2025-2033. |
| [14] | Sheping ZHAI, Yan HUANG, Qing YANG, Rui YANG. Multi-view entity alignment combining triples and text attributes [J]. Journal of Computer Applications, 2025, 45(6): 1793-1800. |
| [15] | Xiang WANG, Qianqian CUI, Xiaoming ZHANG, Jianchao WANG, Zhenzhou WANG, Jialin SONG. Wireless capsule endoscopy image classification model based on improved ConvNeXt [J]. Journal of Computer Applications, 2025, 45(6): 2016-2024. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||