


Journal of Computer Applications ›› 2025, Vol. 45 ›› Issue (9): 2957-2965.DOI: 10.11772/j.issn.1001-9081.2025030268
• Multimedia computing and computer simulation • Previous Articles
Jinggang LYU, Shaorui PENG, Shuo GAO, Jin ZHOU( )
)
Received:2025-03-19
Revised:2025-05-31
Accepted:2025-06-06
Online:2025-06-25
Published:2025-09-10
Contact:
Jin ZHOU
About author:LYU Jinggang, born in 1977, Ph. D., associate professor. His research interests include speech signal processing, speech enhancement.Supported by:
吕景刚, 彭绍睿, 高硕, 周金()
通讯作者:
周金
作者简介:吕景刚(1977—),男,山东烟台人,副教授,博士,主要研究方向:语音信号处理、语音增强基金资助:CLC Number:
Jinggang LYU, Shaorui PENG, Shuo GAO, Jin ZHOU. Speech enhancement network driven by complex frequency attention and multi-scale frequency enhancement[J]. Journal of Computer Applications, 2025, 45(9): 2957-2965.
吕景刚, 彭绍睿, 高硕, 周金. 复频域注意力和多尺度频域增强驱动的语音增强网络[J]. 《计算机应用》唯一官方网站, 2025, 45(9): 2957-2965.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2025030268
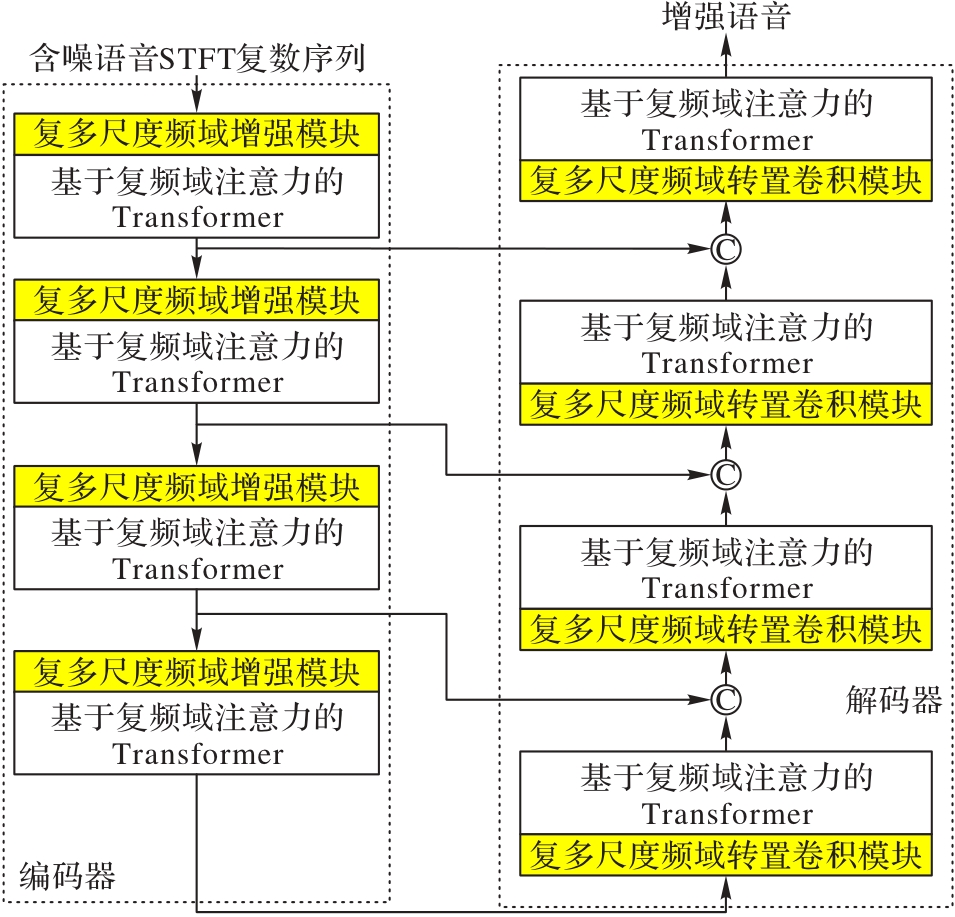
Fig. 1 Overall structure of CFAFE
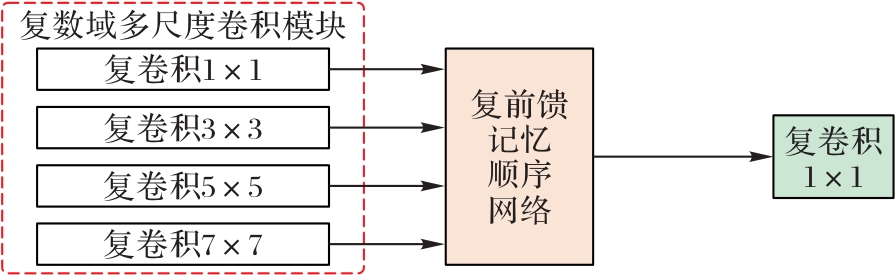
Fig. 2 Structure of CMSFE module
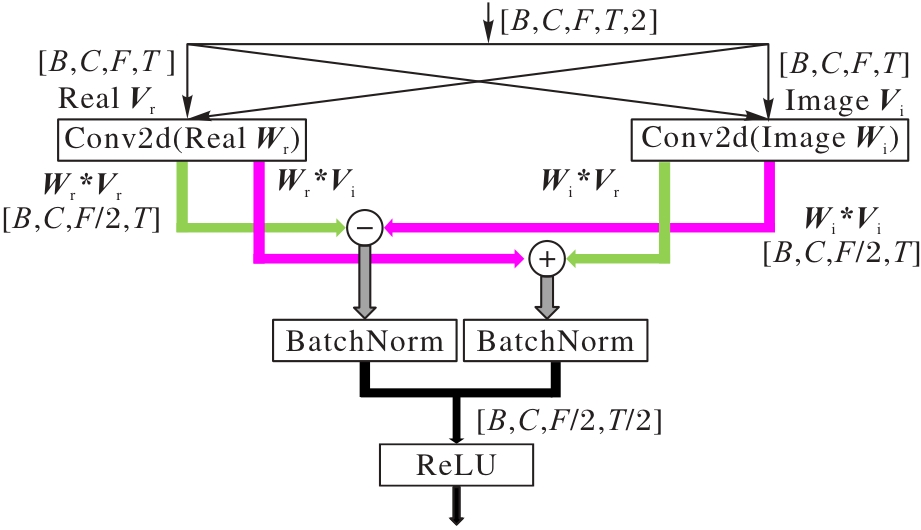
Fig. 3 Structure of complex convolution module
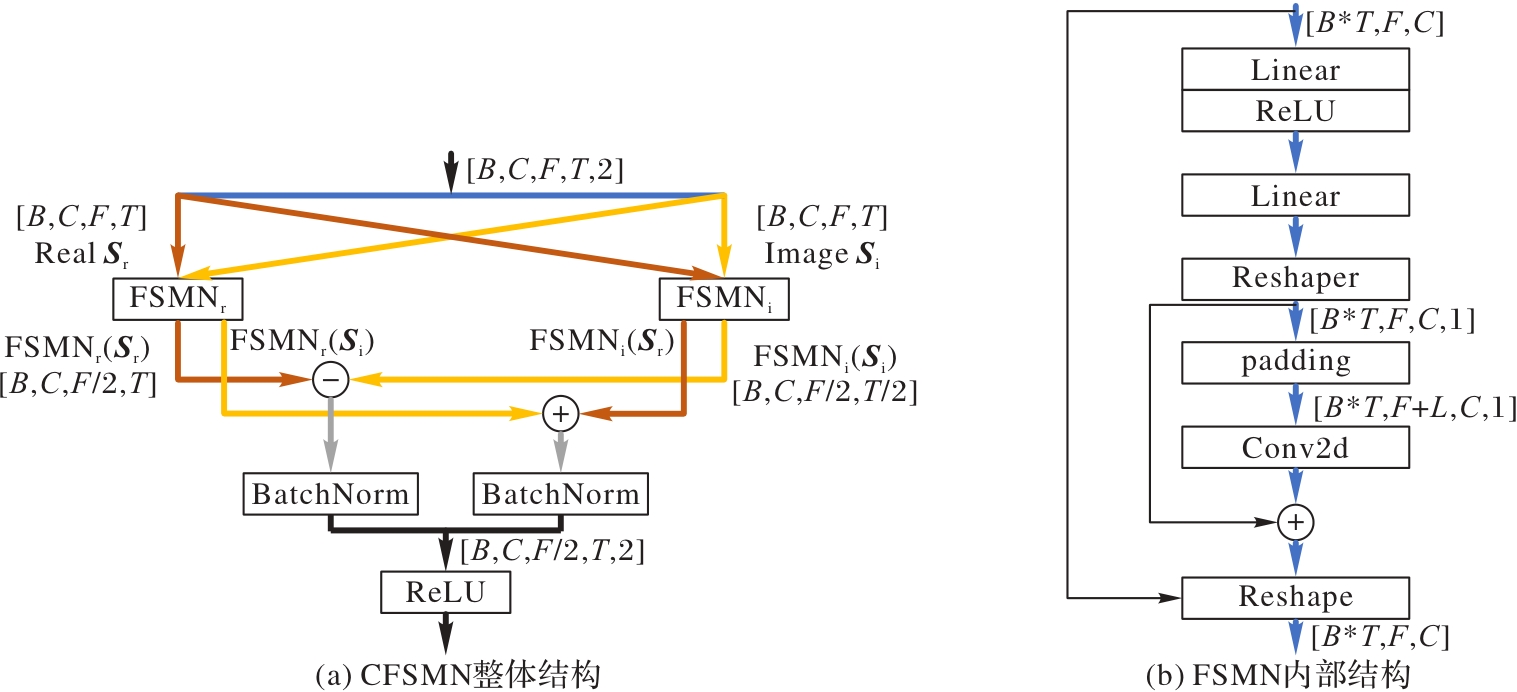
Fig. 4 Overall and inner structure of CFSMN
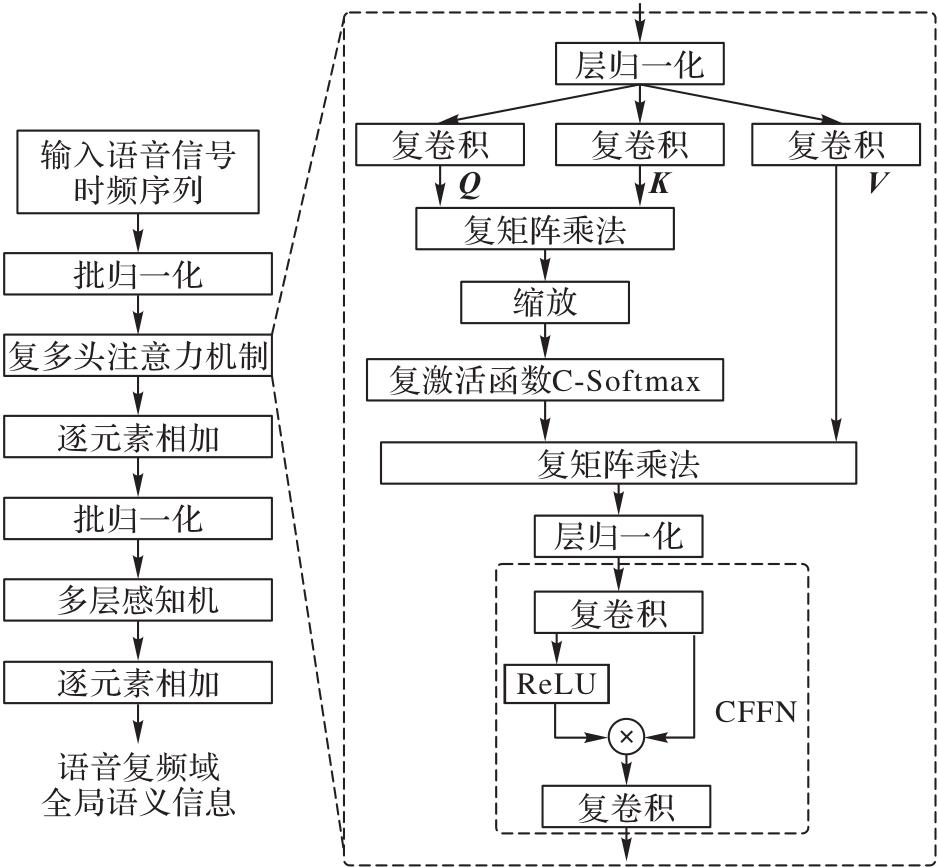
Fig. 5 Structure of CFDT
| 方法 | PESQ | CSIG | CBAK | COVL | STOI | 参数量/106 |
|---|---|---|---|---|---|---|
| Noisy | 1.97 | 3.34 | 2.43 | 2.63 | 0.91 | — |
| DCCRN[ | 2.64 | 3.92 | 2.59 | 3.33 | 0.94 | 3.7 |
| DCCRGAN [ | 2.83 | 3.94 | 3.50 | 3.35 | 0.94 | — |
| S-DCCRN [ | 2.84 | 4.03 | 2.97 | 3.43 | 0.94 | 2.3 |
| GCARN [ | 2.99 | 4.27 | 3.46 | 3.63 | 0.95 | 9.7 |
| CycleGAN-DCD[ | 2.90 | 4.24 | 3.57 | 3.49 | 0.94 | — |
| DBCRN[ | 3.14 | 4.07 | 3.68 | 3.62 | 0.95 | 8.3 |
| 去除CFSMN | 2.94 | 4.44 | 3.64 | 3.74 | 0.94 | 3.4 |
| 去除CFDT | 2.91 | 4.35 | 3.58 | 3.65 | 0.94 | 3.0 |
| CFAFE | 3.08 | 4.35 | 3.74 | 3.80 | 0.95 | 3.9 |
Tab. 1 Performance comparison of different methods on VoiceBank+Demand dataset
| 方法 | PESQ | CSIG | CBAK | COVL | STOI | 参数量/106 |
|---|---|---|---|---|---|---|
| Noisy | 1.97 | 3.34 | 2.43 | 2.63 | 0.91 | — |
| DCCRN[ | 2.64 | 3.92 | 2.59 | 3.33 | 0.94 | 3.7 |
| DCCRGAN [ | 2.83 | 3.94 | 3.50 | 3.35 | 0.94 | — |
| S-DCCRN [ | 2.84 | 4.03 | 2.97 | 3.43 | 0.94 | 2.3 |
| GCARN [ | 2.99 | 4.27 | 3.46 | 3.63 | 0.95 | 9.7 |
| CycleGAN-DCD[ | 2.90 | 4.24 | 3.57 | 3.49 | 0.94 | — |
| DBCRN[ | 3.14 | 4.07 | 3.68 | 3.62 | 0.95 | 8.3 |
| 去除CFSMN | 2.94 | 4.44 | 3.64 | 3.74 | 0.94 | 3.4 |
| 去除CFDT | 2.91 | 4.35 | 3.58 | 3.65 | 0.94 | 3.0 |
| CFAFE | 3.08 | 4.35 | 3.74 | 3.80 | 0.95 | 3.9 |
| 噪声类型 | 信噪比/dB | Noisy | DCCRN | CFAFE | 去除CFDT | ||||
|---|---|---|---|---|---|---|---|---|---|
| PESQ | STOI | PESQ | STOI | PESQ | STOI | PESQ | STOI | ||
| babble | -5 | 1.15 | 0.69 | 1.24 | 0.76 | 1.61 | 0.80 | 1.52 | 0.76 |
| 0 | 1.31 | 0.78 | 1.56 | 0.85 | 2.14 | 0.89 | 1.92 | 0.86 | |
| 5 | 1.60 | 0.86 | 2.00 | 0.91 | 2.69 | 0.94 | 2.43 | 0.92 | |
| buccaneer | -5 | 1.11 | 0.70 | 1.20 | 0.73 | 1.78 | 0.84 | 1.68 | 0.82 |
| 0 | 1.23 | 0.82 | 1.47 | 0.85 | 2.26 | 0.92 | 2.12 | 0.91 | |
| 5 | 1.46 | 0.90 | 2.03 | 0.94 | 2.77 | 0.96 | 2.54 | 0.95 | |
| destroyerengine | -5 | 1.19 | 0.77 | 1.34 | 0.78 | 2.11 | 0.90 | 1.99 | 0.88 |
| 0 | 1.36 | 0.87 | 1.67 | 0.90 | 2.63 | 0.94 | 2.49 | 0.94 | |
| 5 | 1.67 | 0.93 | 2.23 | 0.95 | 3.02 | 0.96 | 2.85 | 0.94 | |
| factory | -5 | 1.09 | 0.69 | 1.22 | 0.72 | 1.55 | 0.82 | 1.52 | 0.79 |
| 0 | 1.21 | 0.80 | 1.54 | 0.89 | 2.05 | 0.90 | 1.91 | 0.88 | |
| 5 | 1.46 | 0.89 | 2.07 | 0.94 | 2.71 | 0.95 | 2.43 | 0.94 | |
| volvo | -5 | 2.13 | 0.96 | 2.98 | 0.97 | 3.83 | 0.98 | 3.43 | 0.97 |
| 0 | 2.63 | 0.98 | 3.15 | 0.97 | 4.07 | 0.99 | 3.74 | 0.98 | |
| 5 | 2.95 | 0.99 | 3.61 | 0.99 | 4.19 | 0.99 | 4.15 | 0.99 | |
| white | -5 | 1.06 | 0.78 | 1.17 | 0.86 | 1.93 | 0.88 | 1.72 | 0.86 |
| 0 | 1.13 | 0.87 | 1.51 | 0.89 | 2.51 | 0.94 | 2.29 | 0.93 | |
| 5 | 1.30 | 0.94 | 1.91 | 0.95 | 2.96 | 0.96 | 2.84 | 0.96 | |
Tab. 2 Comparison experiment results under different signal-to-noise ratios and different noises
| 噪声类型 | 信噪比/dB | Noisy | DCCRN | CFAFE | 去除CFDT | ||||
|---|---|---|---|---|---|---|---|---|---|
| PESQ | STOI | PESQ | STOI | PESQ | STOI | PESQ | STOI | ||
| babble | -5 | 1.15 | 0.69 | 1.24 | 0.76 | 1.61 | 0.80 | 1.52 | 0.76 |
| 0 | 1.31 | 0.78 | 1.56 | 0.85 | 2.14 | 0.89 | 1.92 | 0.86 | |
| 5 | 1.60 | 0.86 | 2.00 | 0.91 | 2.69 | 0.94 | 2.43 | 0.92 | |
| buccaneer | -5 | 1.11 | 0.70 | 1.20 | 0.73 | 1.78 | 0.84 | 1.68 | 0.82 |
| 0 | 1.23 | 0.82 | 1.47 | 0.85 | 2.26 | 0.92 | 2.12 | 0.91 | |
| 5 | 1.46 | 0.90 | 2.03 | 0.94 | 2.77 | 0.96 | 2.54 | 0.95 | |
| destroyerengine | -5 | 1.19 | 0.77 | 1.34 | 0.78 | 2.11 | 0.90 | 1.99 | 0.88 |
| 0 | 1.36 | 0.87 | 1.67 | 0.90 | 2.63 | 0.94 | 2.49 | 0.94 | |
| 5 | 1.67 | 0.93 | 2.23 | 0.95 | 3.02 | 0.96 | 2.85 | 0.94 | |
| factory | -5 | 1.09 | 0.69 | 1.22 | 0.72 | 1.55 | 0.82 | 1.52 | 0.79 |
| 0 | 1.21 | 0.80 | 1.54 | 0.89 | 2.05 | 0.90 | 1.91 | 0.88 | |
| 5 | 1.46 | 0.89 | 2.07 | 0.94 | 2.71 | 0.95 | 2.43 | 0.94 | |
| volvo | -5 | 2.13 | 0.96 | 2.98 | 0.97 | 3.83 | 0.98 | 3.43 | 0.97 |
| 0 | 2.63 | 0.98 | 3.15 | 0.97 | 4.07 | 0.99 | 3.74 | 0.98 | |
| 5 | 2.95 | 0.99 | 3.61 | 0.99 | 4.19 | 0.99 | 4.15 | 0.99 | |
| white | -5 | 1.06 | 0.78 | 1.17 | 0.86 | 1.93 | 0.88 | 1.72 | 0.86 |
| 0 | 1.13 | 0.87 | 1.51 | 0.89 | 2.51 | 0.94 | 2.29 | 0.93 | |
| 5 | 1.30 | 0.94 | 1.91 | 0.95 | 2.96 | 0.96 | 2.84 | 0.96 | |

Fig. 6 Comparison of spectrograms of different models under babble noise
| [1] | 蔡汉添,袁波涛. 一种基于听觉掩蔽模型的语音增强算法[J]. 通信学报, 2002, 23(8): 93-98. |
| CAI H T, YUAN B T. A speech enhancement algorithm based on masking properties of human auditory system [J]. Journal on Communications, 2002, 23(8): 93-98. | |
| [2] | WANG Y, BROOKES M. Model-based speech enhancement in the modulation domain [J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2018, 26(3): 580-594. |
| [3] | ALMAJAI I, MILNER B. Visually derived wiener filters for speech enhancement [J]. IEEE Transactions on Audio, Speech, and Language Processing, 2011, 19(6):1642-1651. |
| [4] | 蓝天,彭川,李森,等. 单声道语音降噪与去混响研究综述[J]. 计算机研究与发展, 2020, 57(5): 928-953. |
| LAN T, PENG C, LI S, et al. An overview of monaural speech denoising and dereverberation research [J]. Journal of Computer Research and Development, 2020, 57(5):928-953. | |
| [5] | KRAWCZYK-BECKER M, GERKMANN T. Fundamental frequency informed speech enhancement in a flexible statistical framework [J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2016, 24(5): 940-951. |
| [6] | WOHLMAYR M, STARK M, PERNKOPF F. A probabilistic interaction model for multipitch tracking with factorial hidden Markov models [J]. IEEE Transactions on Audio, Speech, and Language Processing, 2011, 19(4):799-810. |
| [7] | MING J, SRINIVASAN R, CROOKES D. A corpus-based approach to speech enhancement from nonstationary noise [J]. IEEE Transactions on Audio, Speech, and Language Processing, 2011, 19(4):822-836. |
| [8] | PANDEY A, WANG D. TCNN: temporal convolutional neural network for real-time speech enhancement in the time domain [C]// Proceedings of the 2019 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2019: 6875-6879. |
| [9] | LI A, LIU W, ZHENG C, et al. Two heads are better than one: a two-stage complex spectral mapping approach for monaural speech enhancement [J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2021, 29: 1829-1843. |
| [10] | GAO T, DU J, XU Y, et al. Improving deep neural network based speech enhancement in low SNR environments [C]// Proceedings of the 2015 International Conference on Latent Variable Analysis and Signal Separation, LNCS 9237. Cham: Springer, 2015: 75-82. |
| [11] | YIN D, LUO C, XIONG Z, et al. PHASEN: a phase-and-harmonics-aware speech enhancement network [C]// Proceedings of the 34th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2020: 9458-9465. |
| [12] | LEE J, KANG H G. Two-stage refinement of magnitude and complex spectra for real-time speech enhancement [J]. IEEE Signal Processing Letters, 2022, 29: 2188-2192. |
| [13] | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2017: 6000-6010. |
| [14] | WANG K, HE B, ZHU W P. TSTNN: two-stage Transformer based neural network for speech enhancement in the time domain[C]// Proceedings of the 2021 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2021: 7098-7102. |
| [15] | YU G, LI A, WANG H, et al. DBT-Net: dual-branch federative magnitude and phase estimation with attention-in-attention Transformer for monaural speech enhancement [J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2022, 30: 2629-2644. |
| [16] | ZHANG Q, SONG Q, NI Z, et al. Time-frequency attention for monaural speech enhancement [C]// Proceedings of the 2022 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2022: 7852-7856. |
| [17] | 张天骐,罗庆予,张慧芝,等. 复谱映射下融合高效Transformer的语音增强方法[J]. 信号处理, 2024, 40(2): 406-416. |
| ZHANG T Q, LUO Q Y, ZHANG H Z, et al. Speech enhancement method based on complex spectrum mapping with efficient Transformer [J]. Journal of Signal Processing, 2024, 40(2): 406-416. | |
| [18] | HU Y, LIU Y, LV S, et al. DCCRN: deep complex convolution recurrent network for phase-aware speech enhancement [C]// Proceedings of the INTERSPEECH 2020. [S.l.]: International Speech Communication Association, 2020: 2472-2476. |
| [19] | ZHANG S, LEI M, YAN Z, et al. Deep-FSMN for large vocabulary continuous speech recognition [C]// Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2018: 5869-5873. |
| [20] | ZHAO S, MA B, WATCHARASUPAT K N, et al. FRCRN: boosting feature representation using frequency recurrence for monaural speech enhancement [C]// Proceedings of the 2022 IEEE International Conference on Acoustics, Speech, and Signal Processing. Piscataway: IEEE, 2022: 9281-9285. |
| [21] | HAN K, WANG Y, CHEN H, et al. A survey on Vision Transformer [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(1): 87-110. |
| [22] | VEAUX C, YAMAGISHI J, KING S. The voice bank corpus: design, collection and data analysis of a large regional accent speech database [C]// Proceedings of the 2013 International Conference of the Oriental COCOSDA held jointly with 2013 Conference on Asian Spoken Language Research and Evaluation. Piscataway: IEEE, 2013: 1-4. |
| [23] | THIEMANN J, ITO N, VINCENT E. The diverse environments multi-channel acoustic noise database: a database of multichannel environmental noise recordings [J]. The Journal of the Acoustical Society of America, 2013, 133(S5): No.4806631. |
| [24] | GAROFOLO J S, LAMEL L F, FISHER W M, et al. DARPA TIMIT acoustic-phonetic continuous speech corpus CD-ROM: NISTIR 4930 [R/OL]. [2024-12-14]. . |
| [25] | VARGA A, STEENEKEN H J M. Assessment for automatic speech recognition: Ⅱ. NOISEX-92: a database and an experiment to study the effect of additive noise on speech recognition systems [J]. Speech Communication, 1993, 12(3): 247-251. |
| [26] | HUANG H X, WU R J, HUANG J, et al. DCCRGAN: deep complex convolution recurrent generator adversarial network for speech enhancement [C]// Proceedings of the 2022 International Symposium on Electrical, Electronics and Information Engineering. Piscataway: IEEE, 2022: 30-35. |
| [27] | LV S, FU Y, XING M, et al. S-DCCRN: super wide band DCCRN with learnable complex feature for speech enhancement[C]// Proceedings of the 2022 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2022: 7767-7771. |
| [28] | ZHOU L, GAO Y, WANG Z, et al. Complex spectral mapping with attention based convolution recurrent neural network for speech enhancement [EB/OL]. [2024-12-22]. . |
| [29] | YU G, WANG Y, WANG H, et al. A two-stage complex network using cycle-consistent generative adversarial networks for speech enhancement [J]. Speech Communication, 2021, 134: 42-54. |
| [30] | LI Y, SUN M, ZHANG X. Scale-aware dual-branch complex convolutional recurrent network for monaural speech enhancement[J]. Computer Speech and Language, 2024, 86: No.101618. |
| [1] | Yiming LIANG, Jing FAN, Wenze CHAI. Multi-scale feature fusion sentiment classification based on bidirectional cross attention [J]. Journal of Computer Applications, 2025, 45(9): 2773-2782. |
| [2] | Jin LI, Liqun LIU. SAR and visible image fusion based on residual Swin Transformer [J]. Journal of Computer Applications, 2025, 45(9): 2949-2956. |
| [3] | Xiang WANG, Zhixiang CHEN, Guojun MAO. Multivariate time series prediction method combining local and global correlation [J]. Journal of Computer Applications, 2025, 45(9): 2806-2816. |
| [4] | Li LI, Han SONG, Peihe LIU, Hanlin CHEN. Named entity recognition for sensitive information based on data augmentation and residual networks [J]. Journal of Computer Applications, 2025, 45(9): 2790-2797. |
| [5] | Jin ZHOU, Yuzhi LI, Xu ZHANG, Shuo GAO, Li ZHANG, Jiachuan SHENG. Modulation recognition network for complex electromagnetic environments [J]. Journal of Computer Applications, 2025, 45(8): 2672-2682. |
| [6] | Jing WANG, Jiaxing LIU, Wanying SONG, Jiaxing XUE, Wenxin DING. Few-shot skin image classification model based on spatial transformer network and feature distribution calibration [J]. Journal of Computer Applications, 2025, 45(8): 2720-2726. |
| [7] | Haifeng WU, Liqing TAO, Yusheng CHENG. Partial label regression algorithm integrating feature attention and residual connection [J]. Journal of Computer Applications, 2025, 45(8): 2530-2536. |
| [8] | Chao JING, Yutao QUAN, Yan CHEN. Improved multi-layer perceptron and attention model-based power consumption prediction algorithm [J]. Journal of Computer Applications, 2025, 45(8): 2646-2655. |
| [9] | Jinhao LIN, Chuan LUO, Tianrui LI, Hongmei CHEN. Thoracic disease classification method based on cross-scale attention network [J]. Journal of Computer Applications, 2025, 45(8): 2712-2719. |
| [10] | Chen LIANG, Yisen WANG, Qiang WEI, Jiang DU. Source code vulnerability detection method based on Transformer-GCN [J]. Journal of Computer Applications, 2025, 45(7): 2296-2303. |
| [11] | Yongpeng TAO, Shiqi BAI, Zhengwen ZHOU. Neural architecture search for multi-tissue segmentation using convolutional and transformer-based networks in glioma segmentation [J]. Journal of Computer Applications, 2025, 45(7): 2378-2386. |
| [12] | Haoyu LIU, Pengwei KONG, Yaoli WANG, Qing CHANG. Pedestrian detection algorithm based on multi-view information [J]. Journal of Computer Applications, 2025, 45(7): 2325-2332. |
| [13] | Xiaoqiang ZHAO, Yongyong LIU, Yongyong HUI, Kai LIU. Batch process quality prediction model using improved time-domain convolutional network with multi-head self-attention mechanism [J]. Journal of Computer Applications, 2025, 45(7): 2245-2252. |
| [14] | Huibin WANG, Zhan’ao HU, Jie HU, Yuanwei XU, Bo WEN. Time series forecasting model based on segmented attention mechanism [J]. Journal of Computer Applications, 2025, 45(7): 2262-2268. |
| [15] | Yihan WANG, Chong LU, Zhongyuan CHEN. Multimodal sentiment analysis model with cross-modal text information enhancement [J]. Journal of Computer Applications, 2025, 45(7): 2237-2244. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||