


Journal of Computer Applications ›› 2025, Vol. 45 ›› Issue (4): 1025-1034.DOI: 10.11772/j.issn.1001-9081.2024030319
• Artificial intelligence • Next Articles
Lingmin HAN, Xianhong CHEN( ), Wenmeng XIONG
), Wenmeng XIONG
Received:2024-03-21
Revised:2024-05-20
Accepted:2024-05-27
Online:2024-06-18
Published:2025-04-10
Contact:
Xianhong CHEN
About author:HAN Lingmin, born in 1999, M. S. candidate. Her research interests include sentiment analysis, emotion recognition.Supported by:
韩令敏, 陈仙红(), 熊文梦
通讯作者:
陈仙红
作者简介:韩令敏(1999—),女,河北唐山人,硕士研究生,主要研究方向:情感分析、情感识别基金资助:CLC Number:
Lingmin HAN, Xianhong CHEN, Wenmeng XIONG. Review on bimodal emotion recognition based on speech and text[J]. Journal of Computer Applications, 2025, 45(4): 1025-1034.
韩令敏, 陈仙红, 熊文梦. 基于语音和文本的双模态情感识别综述[J]. 《计算机应用》唯一官方网站, 2025, 45(4): 1025-1034.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2024030319
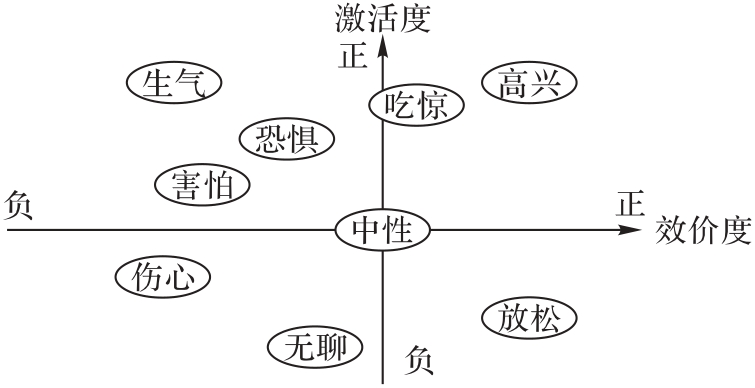
Fig. 1 Valence-Arousal dimension emotion space
| 数据库 | 规模 | 模态 | 类型 | 情感标注 |
|---|---|---|---|---|
| RAVDESS | 7 356个文件 | 图像、语音 | 表演型 | 平静、快乐、悲伤、愤怒、恐惧、惊讶、厌恶 |
| eNTERFACE’05 | 1 166个视频序列 | 图像、语音 | 引导型 | 愤怒、恐惧、惊讶、快乐、悲伤、厌恶 |
| CHEAVD | 2 322个句子 | 图像、语音 | 表演型 | 中性、生气、高兴、悲伤、担心、焦虑、惊讶、厌恶 |
| MELD | 1 433个对话 | 图像、语音、文本 | 表演型 | 愤怒、厌恶、恐惧、喜悦、中立、悲伤、惊讶和积极、消极、中性 |
| IEMOCAP | 10 039个句子 | 图像、语音、文本 | 表演型 | 中性、快乐、悲伤、愤怒、惊讶、恐惧、厌恶、沮丧、 兴奋和效价度、唤醒度、支配度 |
| CMU-MOSEI | 23 453个句子 | 图像、语音、文本 | 自发型 | 快乐、悲伤、愤怒、恐惧、厌烦、惊讶和积极、消极、中性 |
| SEMAINE | 150个句子 | 图像、语音 | 引导型 | 效价度、唤醒度、支配度、力量、强度 |
| Belfast | 298个视频片段 | 图像、语音 | 自发型 | 愤怒、厌恶、恐惧、高兴、中性、悲伤、惊讶 |
| VAM | 12 h数据 | 图像、语音 | 自发型 | 效价度、唤醒度、支配度 |
| RECOLA | 3.8 h数据 | 图像、语音、心电图、皮肤电信号 | 自发型 | 效价度、唤醒度、支配度、一致性、参与度、表现力、融洽度 |
Tab. 1 Common multi-modal emotion recognition databases
| 数据库 | 规模 | 模态 | 类型 | 情感标注 |
|---|---|---|---|---|
| RAVDESS | 7 356个文件 | 图像、语音 | 表演型 | 平静、快乐、悲伤、愤怒、恐惧、惊讶、厌恶 |
| eNTERFACE’05 | 1 166个视频序列 | 图像、语音 | 引导型 | 愤怒、恐惧、惊讶、快乐、悲伤、厌恶 |
| CHEAVD | 2 322个句子 | 图像、语音 | 表演型 | 中性、生气、高兴、悲伤、担心、焦虑、惊讶、厌恶 |
| MELD | 1 433个对话 | 图像、语音、文本 | 表演型 | 愤怒、厌恶、恐惧、喜悦、中立、悲伤、惊讶和积极、消极、中性 |
| IEMOCAP | 10 039个句子 | 图像、语音、文本 | 表演型 | 中性、快乐、悲伤、愤怒、惊讶、恐惧、厌恶、沮丧、 兴奋和效价度、唤醒度、支配度 |
| CMU-MOSEI | 23 453个句子 | 图像、语音、文本 | 自发型 | 快乐、悲伤、愤怒、恐惧、厌烦、惊讶和积极、消极、中性 |
| SEMAINE | 150个句子 | 图像、语音 | 引导型 | 效价度、唤醒度、支配度、力量、强度 |
| Belfast | 298个视频片段 | 图像、语音 | 自发型 | 愤怒、厌恶、恐惧、高兴、中性、悲伤、惊讶 |
| VAM | 12 h数据 | 图像、语音 | 自发型 | 效价度、唤醒度、支配度 |
| RECOLA | 3.8 h数据 | 图像、语音、心电图、皮肤电信号 | 自发型 | 效价度、唤醒度、支配度、一致性、参与度、表现力、融洽度 |
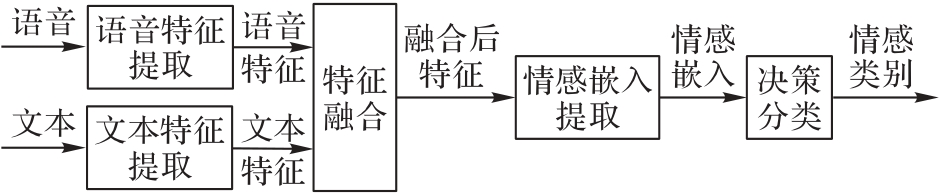
Fig. 2 Flow of feature level fusion

Fig. 3 Flow of decision level fusion

Fig. 4 Flow of model level fusion
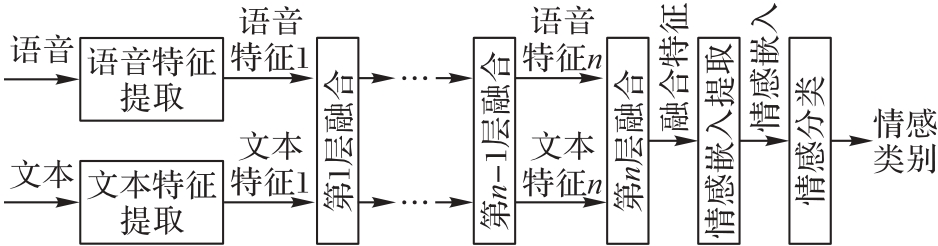
Fig. 5 Flow of multi-level fusion
| 文献 | 数据库 | 提取特征(方法/特征) | 融合方法 | 实验结果 |
|---|---|---|---|---|
| 文献[ | IEMOCAP | Librosa提取+BERT词向量 | 特征级融合 | WA=70.18% |
| 文献[ | IEMOCAP | MFCC特征+GloVe词向量 | 模型级融合 | UA=48.7%;WA=57.9% |
| 文献[ | IEMOCAP | OpenSMILE提取+BERT | 模型级融合 | UA=65.10% |
| 文献[ | IEMOCAP | OpenSMILE提取+RoBERTa | 多层次融合 | W-F1=68.46%;Acc=68.67% |
| 文献[ | IEMOCAP | 双向门控循环单元(Bidirectional Gated Recurrent Unit, Bi-GRU) | 多层次融合 | UA=70.71%;WA=72.75% |
| 文献[ | IEMOCAP | wav2vec 2.0、Mel语谱图等+SER转录文本 | 决策级融合 | UA=73.0%;WA=73.5% |
| 文献[ | IEMOCAP | BN(BottleNeck)+Word2vec、 ANEW(Affective Norms for English Words) | 特征级融合 | UA=75.5%;WA=73.7% |
| 文献[ | IEMOCAP | HuBERT特征+MPNet特征 | 模型级融合 | UA=76.4%;WA=75.2% |
| 文献[ | MOSI | MFSC(log Mel-Frequency Spectral Coefficients)特征+Word2vec | 多层次融合 | UA=76.5%;WA=76.4% |
| 文献[ | CMU-MOSI | LSTM+BERT | 多层次融合 | F1-Score=77.7% |
| 文献[ | IEMOCAP | FBank特征+BERT词向量 | 多层次融合 | UA=79.7%;WA=77.9% |
| 文献[ | IEMOCAP | LLDs(Low-Level Descriptors)+Word2vec | 特征级融合 | UA=79.51%;WA=78.70% |
| 文献[ | IEMOCAP | wav2vec 2.0、Mel语谱图+RoBERTa-base | 特征级融合 | UA=80.5%;WA=81.2% |
| 文献[ | JTES | LLDs特征+BERT词向量 | 决策级融合 | 平均识别率=82.5% |
Tab. 2 Result statistics of different bimodal emotion recognition methods
| 文献 | 数据库 | 提取特征(方法/特征) | 融合方法 | 实验结果 |
|---|---|---|---|---|
| 文献[ | IEMOCAP | Librosa提取+BERT词向量 | 特征级融合 | WA=70.18% |
| 文献[ | IEMOCAP | MFCC特征+GloVe词向量 | 模型级融合 | UA=48.7%;WA=57.9% |
| 文献[ | IEMOCAP | OpenSMILE提取+BERT | 模型级融合 | UA=65.10% |
| 文献[ | IEMOCAP | OpenSMILE提取+RoBERTa | 多层次融合 | W-F1=68.46%;Acc=68.67% |
| 文献[ | IEMOCAP | 双向门控循环单元(Bidirectional Gated Recurrent Unit, Bi-GRU) | 多层次融合 | UA=70.71%;WA=72.75% |
| 文献[ | IEMOCAP | wav2vec 2.0、Mel语谱图等+SER转录文本 | 决策级融合 | UA=73.0%;WA=73.5% |
| 文献[ | IEMOCAP | BN(BottleNeck)+Word2vec、 ANEW(Affective Norms for English Words) | 特征级融合 | UA=75.5%;WA=73.7% |
| 文献[ | IEMOCAP | HuBERT特征+MPNet特征 | 模型级融合 | UA=76.4%;WA=75.2% |
| 文献[ | MOSI | MFSC(log Mel-Frequency Spectral Coefficients)特征+Word2vec | 多层次融合 | UA=76.5%;WA=76.4% |
| 文献[ | CMU-MOSI | LSTM+BERT | 多层次融合 | F1-Score=77.7% |
| 文献[ | IEMOCAP | FBank特征+BERT词向量 | 多层次融合 | UA=79.7%;WA=77.9% |
| 文献[ | IEMOCAP | LLDs(Low-Level Descriptors)+Word2vec | 特征级融合 | UA=79.51%;WA=78.70% |
| 文献[ | IEMOCAP | wav2vec 2.0、Mel语谱图+RoBERTa-base | 特征级融合 | UA=80.5%;WA=81.2% |
| 文献[ | JTES | LLDs特征+BERT词向量 | 决策级融合 | 平均识别率=82.5% |
| 1 | BEGAJ S, TOPAL A O, ALI M. Emotion recognition based on facial expressions using Convolutional Neural Network (CNN) [C]// Proceedings of the 2020 International Conference on Computing, Networking, Telecommunications and Engineering Sciences Applications. Piscataway: IEEE, 2020: 58-63. |
| 2 | 杨磊,赵红东,于快快. 基于多头注意力机制的端到端语音情感识别[J]. 计算机应用, 2022, 42(6):1869-1875. |
| YANG L, ZHAO H D, YU K K. End-to-end speech emotion recognition based on multi-head attention [J]. Journal of Computer Applications, 2022, 42(6): 1869-1875. | |
| 3 | 李路宝,陈田,任福继,等. 基于图神经网络和注意力的双模态情感识别方法[J]. 计算机应用, 2023, 43(3):700-705. |
| LI L B, CHEN T, REN F J, et al. Bimodal emotion recognition method based on graph neural network and attention [J]. Journal of Computer Applications, 2023, 43(3): 700-705. | |
| 4 | 潘莹. 情感识别综述[J]. 电脑知识与技术, 2018, 14(8):169-171. |
| PAN Y. Survey on emotion recognition [J]. Computer Knowledge and Technology, 2018, 14(8): 169-171. | |
| 5 | SRIKANTH S S, MANIKANTAN S, POSONIA A M, et al. Voice assistant with emotion recognition [C]// Proceedings of the 2023 International Conference on Circuit Power and Computing Technologies. Piscataway: IEEE, 2023: 799-804. |
| 6 | TAN L, YU K, LIN L, et al. Speech emotion recognition enhanced traffic efficiency solution for autonomous vehicles in a 5G-enabled space-air-ground integrated intelligent transportation system [J]. IEEE Transactions on Intelligent Transportation Systems, 2022, 23(3): 2830-2842. |
| 7 | KYI A S S, LIN K Z. Detecting voice features for criminal case[C]// Proceedings of the 2019 International Conference on Advanced Information Technologies. Piscataway: IEEE, 2019: 212-216. |
| 8 | SUZUKI K, IGUCHI T, NAKAGAWA Y, et al. A multi-modal interaction robot based on emotion estimation method using physiological signals applied for elderly* [C]// Proceedings of the 32nd IEEE International Conference on Robot and Human Interactive Communication. Piscataway: IEEE, 2023: 2051-2057. |
| 9 | TANKO D, DOGAN S, DEMIR F B, et al. Shoelace pattern-based speech emotion recognition of the lecturers in distance education: ShoePat23 [J]. Applied Acoustics, 2022, 190: No.108637. |
| 10 | 陶建华,陈俊杰,李永伟. 语音情感识别综述[J]. 信号处理, 2023, 39(4):571-587. |
| TAO J H, CHEN J J, LI Y W. Review on speech emotion recognition [J]. Journal of Signal Processing, 2023, 39(4): 571-587. | |
| 11 | 高利军,薛雷. 语音情感识别综述[J]. 工业控制计算机, 2022, 35(10):115-116, 120. |
| GAO L J, XUE L. Overview of speech emotion recognition [J]. Industrial Control Computer, 2022, 35(10): 115-116, 120. | |
| 12 | KONANGI U M Y, KATREDDY V R, RASULA S K, et al. Emotion recognition through speech: a review [C]// Proceedings of the 2022 International Conference on Applied Artificial Intelligence and Computing. Piscataway: IEEE, 2022: 1150-1153. |
| 13 | BHOSALE S A, CHOUGULE S R. A review on face emotion recognition using EEG features and facial features [C]// Proceedings of the 1st International Conference on Cognitive Computing and Engineering Education. Piscataway: IEEE, 2023: 1-5. |
| 14 | 梅英,谭冠政,刘振焘. 基于视频图像的面部表情识别研究综述[J]. 湖南文理学院学报(自然科学版), 2016, 28(3):19-25. |
| MEI Y, TAN G Z, LIU Z T. Review on facial expression recognition based on video image [J]. Journal of Hunan University of Arts and Science (Science and Technology), 2016, 28(3): 19-25. | |
| 15 | 何俊,刘跃,何忠文. 多模态情感识别研究进展[J]. 计算机应用研究, 2018, 35(11):3201-3205. |
| HE J, LIU Y, HE Z W. Research progress of multimodal emotion recognition [J]. Application Research of Computers, 2018, 35(11): 3201-3205. | |
| 16 | 王传昱,李为相,陈震环. 基于语音和视频图像的多模态情感识别研究[J]. 计算机工程与应用, 2021, 57(23):163-170. |
| WANG C Y, LI W X, CHEN Z H. Research of multi-modal emotion recognition based on voice and video images [J]. Computer Engineering and Applications, 2021, 57(23): 163-170. | |
| 17 | EKMAN P. Facial expressions of emotion: new findings, new questions [J]. Psychological Science, 1992, 3(1): 34-38. |
| 18 | RUSSELL J A. A circumplex model of affect [J]. Journal of Personality and Social Psychology, 1980, 39(6): 1161-1178. |
| 19 | RUSSELL J A, MEHRABIAN A. Evidence for a three-factor theory of emotions [J]. Journal of Research in Personality, 1977, 11(3): 273-294. |
| 20 | LIVINGSTONE S R, RUSSO F A. The Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS): a dynamic, multimodal set of facial and vocal expressions in North American English [J]. PLoS ONE, 2018, 13(5): No.e0196391. |
| 21 | MARTIN O, KOTSIA I, MACQ B, et al. The eNTERFACE’ 05 audio-visual emotion database [C]// Proceedings of the 22nd International Conference on Data Engineering Workshops. Piscataway: IEEE, 2006: 8-8. |
| 22 | LI Y, TAO J, CHAO L, et al. CHEAVD: a Chinese natural emotional audio-visual database [J]. Journal of Ambient Intelligence and Humanized Computing, 2017, 8(6): 913-924. |
| 23 | PORIA S, HAZARIKA D, MAJUMDER N, et al. MELD: a multimodal multi-party dataset for emotion recognition in conversations [C]// Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2019: 527-536. |
| 24 | DOUGLAS-COWIE E, COWIE R, SCHRÖDER M. A new emotion database: considerations, sources and scope [C]// Proceedings of the ITRW on Speech and Emotion 2000. [S.l.]: International Speech Communication Association, 2000: 39-44. |
| 25 | BUSSO C, BULUT M, LEE C C, et al. IEMOCAP: interactive emotional dyadic motion capture database [J]. Language Resources and Evaluation, 2008, 42(4): 335-359. |
| 26 | BAGHER ZADEH A, LIANG P P, PORIA S, et al. Multimodal language analysis in the wild: CMU-MOSEI dataset and interpretable dynamic fusion graph [C]// Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2018: 2236-2246. |
| 27 | McKEOWN G, VALSTAR M F, COWIE R, et al. The SEMAINE corpus of emotionally coloured character interactions [C]// Proceedings of the 2010 IEEE International Conference on Multimedia and Expo. Piscataway: IEEE, 2010: 1079-1084. |
| 28 | GRIMM M, KROSCHEL K, NARAYANAN S. The Vera am Mittag German audio-visual emotional speech database [C]// Proceedings of the 2008 IEEE International Conference on Multimedia and Expo. Piscataway: IEEE, 2008: 865-868. |
| 29 | RINGEVAL F, SONDEREGGER A, SAUER J, et al. Introducing the RECOLA multimodal corpus of remote collaborative and affective interactions [C]// Proceedings of the 10th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition. Piscataway: IEEE, 2013: 1-8. |
| 30 | LeCUN Y, BOSER B, DENKER J S, et al. Backpropagation applied to handwritten zip code recognition [J]. Neural Computation, 1989, 1(4): 541-551. |
| 31 | ELMAN J L. Finding structure in time [J]. Cognitive Science, 1990, 14(2): 179-211. |
| 32 | HOCHREITER S, SCHMIDHUBER J. Long short-term memory[J]. Neural Computation, 1997, 9(8): 1735-1780. |
| 33 | SCHNEIDER S, BAEVSKI A, COLLOBERT R, et al. wav2vec: Unsupervised pre-training for speech recognition [C]// Proceedings of the INTERSPEECH 2019. [S.l.]: International Speech Communication Association, 2019: 3465-3469. |
| 34 | BAEVSKI A, ZHOU H, MOHAMED A, et al. wav2vec 2.0: A framework for self-supervised learning of speech representations[C]// Proceedings of the 34th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2020: 12449-12460. |
| 35 | HSU W N, BOLTE B, TSAI Y H H, et al. HuBERT: self-supervised speech representation learning by masked prediction of hidden units [J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2021, 29: 3451-3460. |
| 36 | CHEN S, WANG C, CHEN Z, et al. WavLM: large-scale self-supervised pre-training for full stack speech processing [J]. IEEE Journal of Selected Topics in Signal Processing, 2022, 16(6): 1505-1518. |
| 37 | LIANG H, SUN X, SUN Y, et al. Text feature extraction based on deep learning: a review [J]. EURASIP Journal on Wireless Communications and Networking, 2017, 2017: No.211. |
| 38 | 刘颖,艾豪,张伟东. 基于深度学习的多模态情感识别综述[J]. 西安邮电大学学报, 2022, 27(1):60-71. |
| LIU Y, AI H, ZHANG W D. A survey of multimodal emotion recognition based on deep learning [J]. Journal of Xi’an University of Posts and Telecommunications, 2022, 27(1): 60-71. | |
| 39 | PENNINGTON J, SOCHER R, MANNING C D. GloVe: global vectors for word representation [C]// Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2014: 1532-1543. |
| 40 | PETERS M E, NEUMANN M, IYYER M, et al. Deep contextualized word representations [C]// Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers). Stroudsburg: ACL, 2018: 2227-2237. |
| 41 | DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional Transformers for language understanding [C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Stroudsburg: ACL, 2019: 4171-4186. |
| 42 | 何俊,张彩庆,李小珍,等. 面向深度学习的多模态融合技术研究综述[J]. 计算机工程, 2020, 46(5):1-11. |
| HE J, ZHANG C Q, LI X Z, et al. Survey of research on multimodal fusion technology for deep learning [J]. Computer Engineering, 2020, 46(5): 1-11. | |
| 43 | HOU M, ZHANG Z, LIU C, et al. Semantic alignment network for multi-modal emotion recognition [J]. IEEE Transactions on Circuits and Systems for Video Technology, 2023, 33(9): 5318-5329. |
| 44 | BOKADE G U, KANPHADE R D. Secure multimodal biometric authentication using Face, Palmprint and Ear: a feature level fusion approach [C]// Proceedings of the 10th International Conference on Computing, Communication and Networking Technologies. Piscataway: IEEE, 2019: 1-5. |
| 45 | CAI L, LIAO Z, ZHOU S, et al. Visual question answering combining multi-modal feature fusion and multi-attention mechanism [C]// Proceedings of the IEEE 2nd International Conference on Big Data, Artificial Intelligence and Internet of Things Engineering. Piscataway: IEEE, 2021: 1035-1039. |
| 46 | DU X, YANG J, XIE X. Multimodal emotion recognition based on feature fusion and residual connection [C]// Proceedings of the IEEE 2nd International Conference on Electrical Engineering, Big Data and Algorithms. Piscataway: IEEE, 2023: 373-377. |
| 47 | KIM E, SHIN J W. DNN-based emotion recognition based on bottleneck acoustic features and lexical features [C]// Proceedings of the 2019 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2019: 6720-6724. |
| 48 | LI F, LUO J, LIU W. Speech emotion recognition using multi-modal feature fusion network [C]// Proceedings of the IEEE 6th International Conference on Pattern Recognition and Artificial Intelligence. Piscataway: IEEE, 2023: 884-888. |
| 49 | DEVI D V R, RAO K N. Decision level fusion schemes for a Multimodal Biometric System using local and global wavelet features [C]// Proceedings of the 2020 IEEE International Conference on Electronics, Computing and Communication Technologies. Piscataway: IEEE, 2020: 1-6. |
| 50 | CHEN Y, JIA Z, HIROTA K, et al. A multimodal emotion perception model based on context-aware decision-level fusion[C]// Proceedings of the 41st Chinese Control Conference. Piscataway: IEEE, 2022: 7332-7337. |
| 51 | SATO K, KISHI K, KOSAKA T. Speech emotion recognition by late fusion of linguistic and acoustic features using deep learning models [C]// Proceedings of the 2023 Asia Pacific Signal and Information Processing Association Annual Summit and Conference. Piscataway: IEEE, 2023: 1013-1018. |
| 52 | ZHAO Y, CAO X, LIN J, et al. Multimodal affective states recognition based on multiscale CNNs and biologically inspired decision fusion model [J]. IEEE Transactions on Affective Computing, 2023, 14(2): 1391-1403. |
| 53 | HAN H, XIANG M, LIAN C, et al. A multimodal deep neural network for ECG and PCG classification with multimodal fusion[C]// Proceedings of the 13th International Conference on Information Science and Technology. Piscataway: IEEE, 2023: 124-128. |
| 54 | HUANG J, TAO J, LIU B, et al. Multimodal Transformer fusion for continuous emotion recognition [C]// Proceedings of the 2020 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2020: 3507-3511. |
| 55 | WANG S, MA Y, DING Y. Exploring complementary features in multi-modal speech emotion recognition [C]// Proceedings of the 2023 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2023: 1-5. |
| 56 | ZHU X, WU J, ZHU L. RGB-D saliency detection based on cross-modal and multi-scale feature fusion [C]// Proceedings of the 34th Chinese Control and Decision Conference. Piscataway: IEEE, 2022: 6154-6160. |
| 57 | ZHANG J, WANG Q, HAN Y. Multi-modal fusion with multi-level attention for visual dialog [J]. Information Processing and Management, 2020, 57: No.102152. |
| 58 | WANG Y. Efficient audio-visual speaker recognition via deep multi-modal feature fusion [C]// Proceedings of the 17th International Conference on Computational Intelligence and Security. Piscataway: IEEE, 2021: 99-103. |
| 59 | GU Y, YANG K, FU S, et al. Multimodal affective analysis using hierarchical attention strategy with word-level alignment [C]// Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2018: 2225-2235. |
| 60 | 李牧,杨宇恒,柯熙政. 基于混合特征提取与跨模态特征预测融合的情感识别模型[J]. 计算机应用, 2024, 44(1):86-93. |
| LI M, YANG Y H, KE X Z. Emotion recognition model based on hybrid-Mel Gama frequency cross-attention transformer modal [J]. Journal of Computer Applications, 2024, 44(1): 86-93. | |
| 61 | HUNT E B, MARIN J, STONE P J. Experiments in induction[M]. New York: Academic Press, 1996. |
| 62 | BREIMAN L. Random forests [J]. Machine Learning, 2001, 45(1): 5-32. |
| 63 | CORTES C, VAPNIK V. Support-vector networks [J]. Machine Learning, 1995, 20(3): 273-297. |
| 64 | COVER T, HART P. Nearest neighbor pattern classification [J]. IEEE Transactions on Information Theory, 1967, 13(1): 21-27. |
| 65 | McCULLOCH W S, PITTS W. A logical calculus of the ideas immanent in nervous activity [J]. Bulletin of Mathematical Biophysics, 1943, 5: 115-133. |
| 66 | 冯亚琴,沈凌洁,胡婷婷,等. 利用语音与文本特征融合改善语音情感识别[J]. 数据采集与处理, 2019, 34(4):625-631. |
| FENG Y Q, SHEN L J, HU T T, et al. Using speech and text features fusion to improve speech emotion recognition [J]. Journal of Data Acquisition and Processing, 2019, 34(4): 625-631. | |
| 67 | 顾煜,金赟,马勇,等. 基于声学和文本特征的多模态情感识别[J]. 数据采集与处理, 2022, 37(6):1353-1362. |
| GU Y, JIN Y, MA Y, et al. Multimodal emotion recognition based on acoustic and lexical features [J]. Journal of Data Acquisition and Processing, 2022, 37(6): 1353-1362. | |
| 68 | ZHAO Z, GAO T, WANG H, et al. SWRR: feature map classifier based on sliding window attention and high-response feature reuse for multimodal emotion recognition [C]// Proceedings of the INTERSPEECH 2023. [S.l.]: International Speech Communication Association, 2023: 2433-2437. |
| 69 | 史爱武,蔡润. 结合多种注意力机制的多模态情感识别方法[J]. 软件导刊, 2023, 22(10):105-109. |
| SHI A W, CAI R. Multimodal emotion recognition method combining multiple attention mechanisms [J]. Software Guide, 2023, 22(10): 105-109. | |
| 70 | PATAMIA R A, JIN W, ACHEAMPONG K N, et al. Transformer based multimodal speech emotion recognition with improved neural networks [C]// Proceedings of the IEEE 2nd International Conference on Pattern Recognition and Machine Learning. Piscataway: IEEE, 2021: 195-203. |
| 71 | LEE Y, YOON S, JUNG K. Multimodal speech emotion recognition using cross attention with aligned audio and text [C]// Proceedings of the INTERSPEECH 2020. [S.l.]: International Speech Communication Association, 2020: 2717-2721. |
| 72 | PEPINO L, RIERA P, FERRER L, et al. Fusion approaches for emotion recognition from speech using acoustic and text-based features [C]// Proceedings of the 2020 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2020: 6484-6488. |
| 73 | LI J, WANG X, LIU Y, et al. CFN-ESA: a cross-modal fusion network with emotion-shift awareness for dialogue emotion recognition [J]. IEEE Transactions on Affective Computing, 2024, 15(4): 1919-1933. |
| 74 | MAKIUCHI M R, UTO K, SHINODA K. Multimodal emotion recognition with high-level speech and text features [C]// Proceedings of the 2021 IEEE Automatic Speech Recognition and Understanding Workshop. Piscataway: IEEE, 2021: 350-357. |
| 75 | SUN H, CHEN Y W, LIN L. TensorFormer: a tensor-based multimodal transformer for multimodal sentiment analysis and depression detection [J]. IEEE Transactions on Affective Computing, 2023, 14(4): 2776-2786. |
| 76 | AUDEBERT N, LE SAUX B, LEFÈVRE S. Beyond RGB: very high resolution urban remote sensing with multimodal deep networks [J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2018, 140: 20-32. |
| 77 | WÖLLMER M, WENINGER F, KNAUP T, et al. YouTube movie reviews: sentiment analysis in an audio-visual context [J]. IEEE Intelligent Systems, 2013, 28(3): 46-53. |
| 78 | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2017: 6000-6010. |
| 79 | MOU L, ZHAO Y, ZHOU C, et al. Driver emotion recognition with a hybrid attentional multimodal fusion framework [J]. IEEE Transactions on Affective Computing, 2023, 14(4): 2970-2981. |
| 80 | GAO Y, FU Y, SUN M, et al. Multi-modal hierarchical empathetic framework for social robots with affective body control[J]. IEEE Transactions on Affective Computing, 2024, 15(3): 16210-1633. |
| 81 | SANTOSA J, ISHIZUKA K, HASHIMOTO T. Large language model-based emotional speech annotation using context and acoustic feature for speech emotion recognition [C]// Proceedings of the 2024 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2024: 11026-11030. |
| 82 | BOSCH E, LE HOUCQ CORBÍ R, IHME K, et al. Frustration recognition using spatio temporal data: a novel dataset and GCN model to recognize in-vehicle frustration [J]. IEEE Transactions on Affective Computing, 2023, 14(4): 2864-2875. |
| [1] | Tianyu LIU, Ye TAO, Chaofeng LU, Jiawang LIU. Novel speaker identification framework based on narrative unit and reliable label [J]. Journal of Computer Applications, 2025, 45(4): 1190-1198. |
| [2] | Liqin WANG, Zhilei GENG, Yingshuang LI, Yongfeng DONG, Meng BIAN. Open-world knowledge reasoning model based on path and enhanced triplet text [J]. Journal of Computer Applications, 2025, 45(4): 1177-1183. |
| [3] | Haitao SUN, Jiayu LIN, Zuhong LIANG, Jie GUO. Data augmentation technique incorporating label confusion for Chinese text classification [J]. Journal of Computer Applications, 2025, 45(4): 1113-1119. |
| [4] | Junxiu AN, Linwang YANG, Yuan LIU. Unsupervised text style transfer based on semantic perception of proximity [J]. Journal of Computer Applications, 2025, 45(4): 1139-1147. |
| [5] | Jiaxin LI, Site MO. Power work order classification in substation area based on MiniRBT-LSTM-GAT and label smoothing [J]. Journal of Computer Applications, 2025, 45(4): 1356-1362. |
| [6] | Yanping ZHANG, Meifang CHEN, Changhai TIAN, Zibo YI, Wenpeng HU, Wei LUO, Zhunchen LUO. Multi-strategy retrieval-augmented generation method for military domain knowledge question answering systems [J]. Journal of Computer Applications, 2025, 45(3): 746-754. |
| [7] | Chaofeng LU, Ye TAO, Lianqing WEN, Fei MENG, Xiugong QIN, Yongjie DU, Yunlong TIAN. Speaker-emotion voice conversion method with limited corpus based on large language model and pre-trained model [J]. Journal of Computer Applications, 2025, 45(3): 815-822. |
| [8] | Qijian CAI, Wei TAN. Semantic graph enhanced multi-modal recommendation algorithm [J]. Journal of Computer Applications, 2025, 45(2): 421-427. |
| [9] | Ming JIANG, Linqin WANG, Hua LAI, Shengxiang GAO. End-to-end Vietnamese text normalization method based on editing constraints [J]. Journal of Computer Applications, 2025, 45(2): 362-370. |
| [10] | Qiang FU, Zhenping XU, Wenxing SHENG, Qing YE. End-to-end Chinese speech recognition method with byte-level byte pair encoding [J]. Journal of Computer Applications, 2025, 45(1): 318-324. |
| [11] | Shang LIU, Yuwei ZHOU, Rao DAI, Linfang DONG, Meng LIU. Small target detection algorithm in remote sensing images integrating attention and contextual information [J]. Journal of Computer Applications, 2025, 45(1): 292-300. |
| [12] | Jialin ZHANG, Qinghua REN, Qirong MAO. Speaker verification system utilizing global-local feature dependency for anti-spoofing [J]. Journal of Computer Applications, 2025, 45(1): 308-317. |
| [13] | Ying HUANG, Jiayu YANG, Jiahao JIN, Bangrui WAN. Siamese mixed information fusion algorithm for RGBT tracking [J]. Journal of Computer Applications, 2024, 44(9): 2878-2885. |
| [14] | Yuxin HUANG, Jialong XU, Zhengtao YU, Shukai HOU, Jiaqi ZHOU. Unsupervised text sentiment transfer method based on generation prompt [J]. Journal of Computer Applications, 2024, 44(9): 2667-2673. |
| [15] | Xianglan WU, Yang XIAO, Mengying LIU, Mingming LIU. Text-to-SQL model based on semantic enhanced schema linking [J]. Journal of Computer Applications, 2024, 44(9): 2689-2695. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||