


Journal of Computer Applications ›› 2025, Vol. 45 ›› Issue (11): 3540-3546.DOI: 10.11772/j.issn.1001-9081.2024111561
• Artificial intelligence • Previous Articles
Huilin GUI, Kun YUE, Liang DUAN( )
)
Received:2024-11-04
Revised:2024-11-11
Accepted:2024-11-22
Online:2024-12-06
Published:2025-11-10
Contact:
Liang DUAN
About author:GUI Huilin, born in 1999, M. S. candidate. Her research interests include link prediction, knowledge engineering.Supported by:
贵慧琳, 岳昆, 段亮()
通讯作者:
段亮
作者简介:贵慧琳(1999—),女,湖南常德人,硕士研究生,主要研究方向:链接预测、知识工程基金资助:CLC Number:
Huilin GUI, Kun YUE, Liang DUAN. Multimodal knowledge graph link prediction method based on fusing image and textual information[J]. Journal of Computer Applications, 2025, 45(11): 3540-3546.
贵慧琳, 岳昆, 段亮. 融合图像与文本信息的多模态知识图谱链接预测方法[J]. 《计算机应用》唯一官方网站, 2025, 45(11): 3540-3546.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2024111561
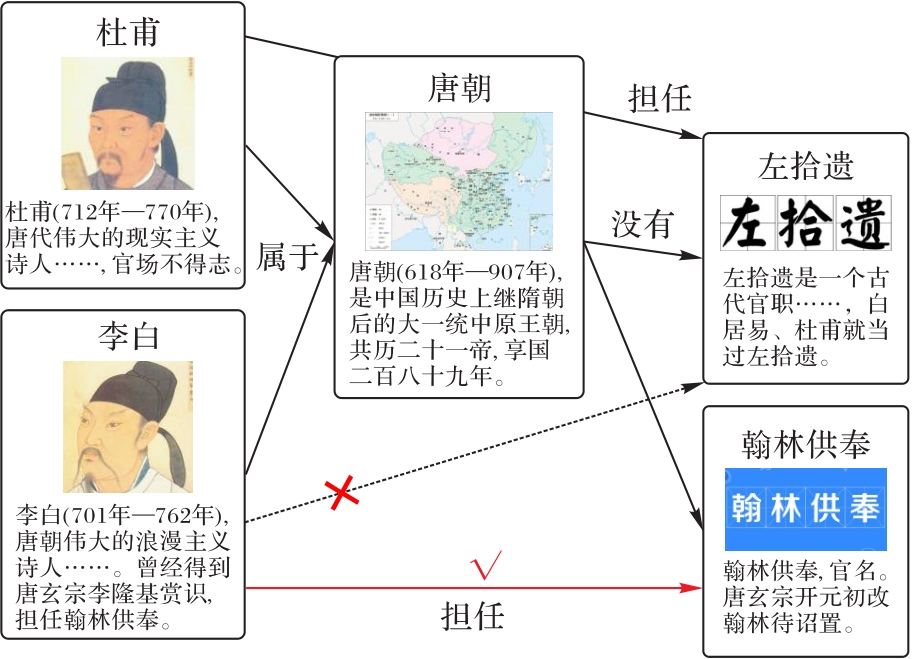
Fig. 1 Example of predicting links based on multimodal information
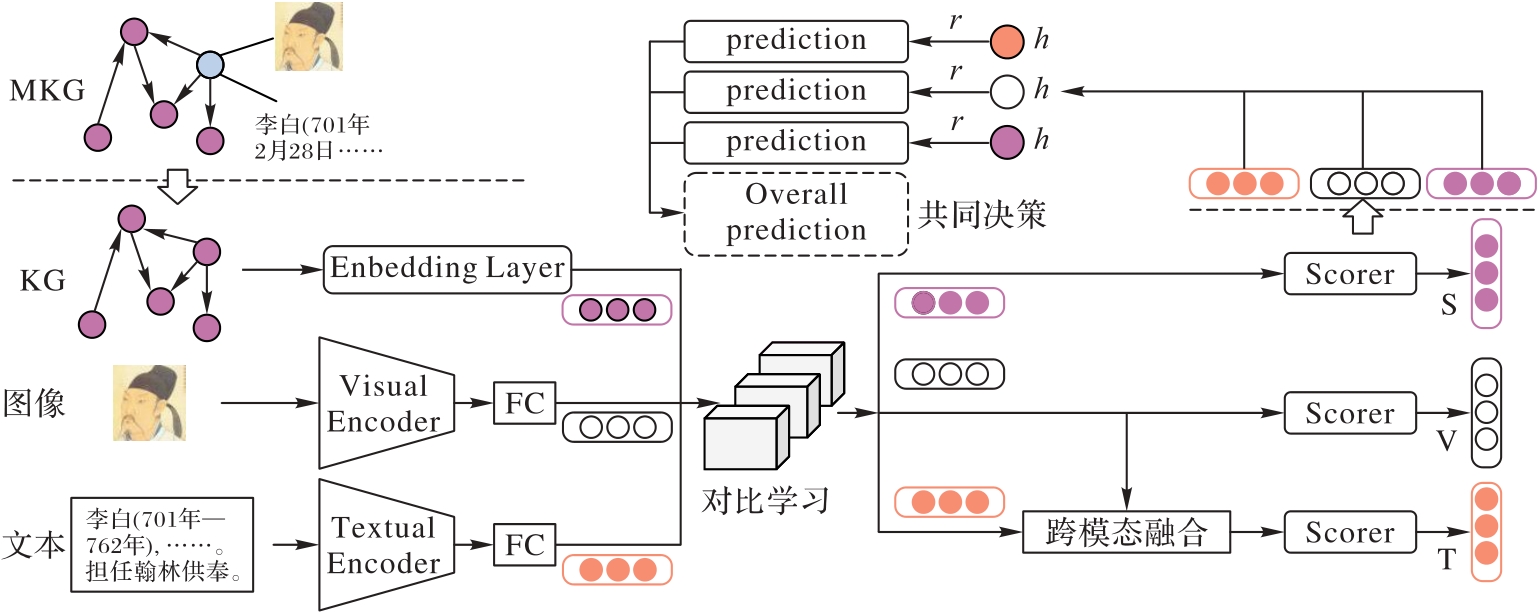
Fig. 2 FITILP framework

Fig. 3 Contrastive learning
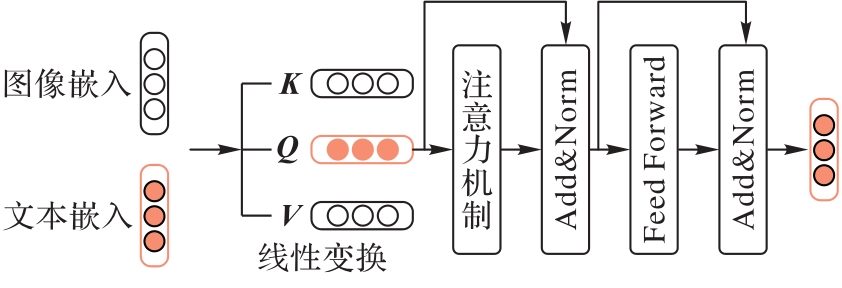
Fig. 4 Structure of cross-modal attention module
| 数据集 | 实体总数 | 关系总数 | 三元组 | 实体平均 三元组数 | |||
|---|---|---|---|---|---|---|---|
训练 集 | 验证 集 | 测试 集 | 总数 | ||||
| DB15K | 12 842 | 279 | 69 319 | 19 806 | 9 903 | 99 028 | 7.73 |
| FB15K-237 | 14 541 | 237 | 272 115 | 17 535 | 20 466 | 310 116 | 21.33 |
Tab. 1 Dataset statistics
| 数据集 | 实体总数 | 关系总数 | 三元组 | 实体平均 三元组数 | |||
|---|---|---|---|---|---|---|---|
训练 集 | 验证 集 | 测试 集 | 总数 | ||||
| DB15K | 12 842 | 279 | 69 319 | 19 806 | 9 903 | 99 028 | 7.73 |
| FB15K-237 | 14 541 | 237 | 272 115 | 17 535 | 20 466 | 310 116 | 21.33 |
| 参数 | 固定值 | 参数 | 固定值 |
|---|---|---|---|
| Epochs | 1 000 | Weight Decay | 0.001 |
| Learning Rate | 0.001 | Patience | 10 |
| Dropout | 0.2 | Early Stop | 5 |
Tab. 2 Parameter setting
| 参数 | 固定值 | 参数 | 固定值 |
|---|---|---|---|
| Epochs | 1 000 | Weight Decay | 0.001 |
| Learning Rate | 0.001 | Patience | 10 |
| Dropout | 0.2 | Early Stop | 5 |
| 方法 | DB15K | FB15K-237 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| MR | MRR | Hits@1/% | Hits@10/% | Hits@100/% | MR | MRR | Hits@1/% | Hits@10/% | Hits@100/% | |
| TransE[ | 1 152.65 | 0.157 | 8.77 | 30.06 | 50.74 | 415.47 | 0.164 | 10.41 | 28.27 | 58.67 |
| MKGRL-MS(TransE) | 1 318.57 | 0.127 | 7.72 | 22.23 | 43.57 | 489.22 | 0.147 | 9.67 | 24.34 | 53.63 |
| FITILP(TransE) | 748.33 | 0.223 | 12.72 | 41.43 | 64.75 | 316.37 | 0.188 | 11.91 | 33.35 | 65.23 |
| TransH[ | 1 435.51 | 0.158 | 10.29 | 26.41 | 45.60 | 664.41 | 0.115 | 6.41 | 21.60 | 48.53 |
| MKGRL-MS(TransH) | 1 313.03 | 0.129 | 7.97 | 22.15 | 43.65 | 483.16 | 0.147 | 9.59 | 24.35 | 54.20 |
| FITILP(TransH) | 879.65 | 0.168 | 10.53 | 34.02 | 59.99 | 407.61 | 0.154 | 10.51 | 29.25 | 62.35 |
| IKRL[ | 973.73 | 0.152 | 7.58 | 30.65 | 53.09 | 426.69 | 0.173 | 11.11 | 29.31 | 58.60 |
| MKGR[ | 908.27 | 0.147 | 6.65 | 31.56 | 55.70 | 386.69 | 0.173 | 10.36 | 30.50 | 61.46 |
| TransAE[ | 856.98 | 0.169 | 9.60 | 32.55 | 57.05 | 352.81 | 0.175 | 11.16 | 30.49 | 61.24 |
Tab. 3 Performance comparison of FITILP and baseline methods
| 方法 | DB15K | FB15K-237 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| MR | MRR | Hits@1/% | Hits@10/% | Hits@100/% | MR | MRR | Hits@1/% | Hits@10/% | Hits@100/% | |
| TransE[ | 1 152.65 | 0.157 | 8.77 | 30.06 | 50.74 | 415.47 | 0.164 | 10.41 | 28.27 | 58.67 |
| MKGRL-MS(TransE) | 1 318.57 | 0.127 | 7.72 | 22.23 | 43.57 | 489.22 | 0.147 | 9.67 | 24.34 | 53.63 |
| FITILP(TransE) | 748.33 | 0.223 | 12.72 | 41.43 | 64.75 | 316.37 | 0.188 | 11.91 | 33.35 | 65.23 |
| TransH[ | 1 435.51 | 0.158 | 10.29 | 26.41 | 45.60 | 664.41 | 0.115 | 6.41 | 21.60 | 48.53 |
| MKGRL-MS(TransH) | 1 313.03 | 0.129 | 7.97 | 22.15 | 43.65 | 483.16 | 0.147 | 9.59 | 24.35 | 54.20 |
| FITILP(TransH) | 879.65 | 0.168 | 10.53 | 34.02 | 59.99 | 407.61 | 0.154 | 10.51 | 29.25 | 62.35 |
| IKRL[ | 973.73 | 0.152 | 7.58 | 30.65 | 53.09 | 426.69 | 0.173 | 11.11 | 29.31 | 58.60 |
| MKGR[ | 908.27 | 0.147 | 6.65 | 31.56 | 55.70 | 386.69 | 0.173 | 10.36 | 30.50 | 61.46 |
| TransAE[ | 856.98 | 0.169 | 9.60 | 32.55 | 57.05 | 352.81 | 0.175 | 11.16 | 30.49 | 61.24 |
| 模型 | DB15K | FB15K-237 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| MR | MRR | Hits@1/% | Hits@10/% | Hits@100/% | MR | MRR | Hits@1/% | Hits@10/% | Hits@100/% | |
| FITILP (w/o T) | 970.00 | 0.162 | 9.52 | 30.02 | 52.77 | 383.25 | 0.172 | 10.90 | 29.58 | 59.53 |
| FITILP (w/o CL) | 844.03 | 0.195 | 10.86 | 36.94 | 59.46 | 354.07 | 0.177 | 11.07 | 31.24 | 61.91 |
| FITILP (w/o F) | 768.43 | 0.203 | 11.57 | 38.96 | 60.63 | 339.24 | 0.185 | 11.58 | 32.57 | 63.26 |
| FITILP (w/o V) | 761.12 | 0.203 | 11.36 | 39.22 | 62.04 | 347.93 | 0.184 | 11.70 | 31.98 | 62.48 |
| FITILP (TransE) | 748.33 | 0.223 | 12.72 | 41.43 | 64.75 | 316.37 | 0.188 | 11.91 | 33.35 | 65.23 |
Tab. 4 Ablation experiments
| 模型 | DB15K | FB15K-237 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| MR | MRR | Hits@1/% | Hits@10/% | Hits@100/% | MR | MRR | Hits@1/% | Hits@10/% | Hits@100/% | |
| FITILP (w/o T) | 970.00 | 0.162 | 9.52 | 30.02 | 52.77 | 383.25 | 0.172 | 10.90 | 29.58 | 59.53 |
| FITILP (w/o CL) | 844.03 | 0.195 | 10.86 | 36.94 | 59.46 | 354.07 | 0.177 | 11.07 | 31.24 | 61.91 |
| FITILP (w/o F) | 768.43 | 0.203 | 11.57 | 38.96 | 60.63 | 339.24 | 0.185 | 11.58 | 32.57 | 63.26 |
| FITILP (w/o V) | 761.12 | 0.203 | 11.36 | 39.22 | 62.04 | 347.93 | 0.184 | 11.70 | 31.98 | 62.48 |
| FITILP (TransE) | 748.33 | 0.223 | 12.72 | 41.43 | 64.75 | 316.37 | 0.188 | 11.91 | 33.35 | 65.23 |
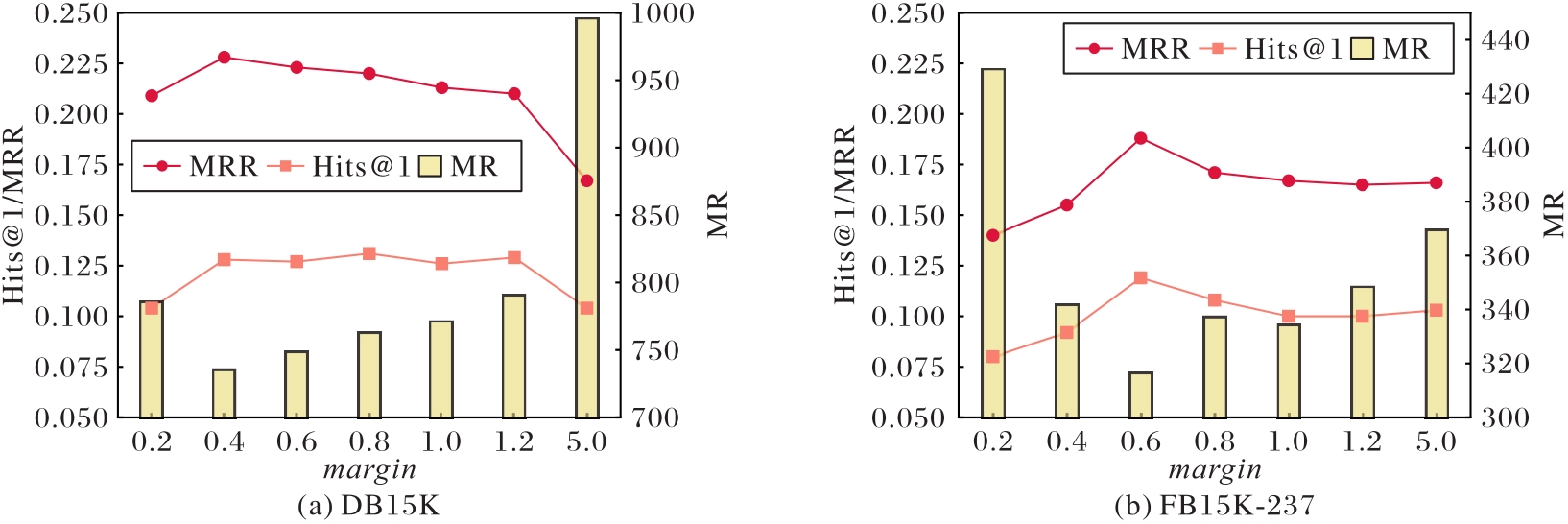
Fig. 5 Impact of different margin value on performance
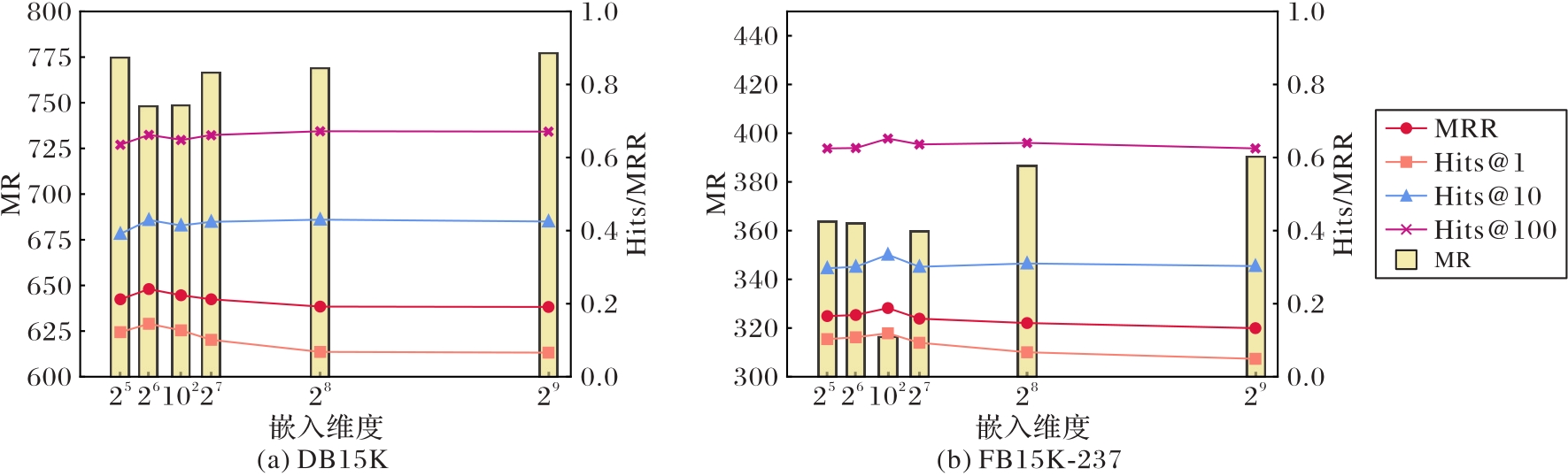
Fig. 6 Impact of different embedding dimension on performance
| [1] | DING Y, YU J, LIU B, et al. MuKEA: multimodal knowledge extraction and accumulation for knowledge-based visual question answering[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 5079-5088. |
| [2] | LI A, HAN C, XING X, et al. KGSCS — a smart care system for elderly with geriatric chronic diseases: a knowledge graph approach[J]. BMC Medical Informatics and Decision Making, 2024, 24: No.73. |
| [3] | ZHAO X, FAN W, LIU H, et al. Multi-type urban crime prediction[C]// Proceedings of the 36th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2022: 4388-4396. |
| [4] | BORDES A, USUNIER N, GARCIA-DURÁN A, et al. Translating embeddings for modeling multi-relational data[C]// Proceedings of the 27th International Conference on Neural Information Processing Systems — Volume 2. Red Hook: Curran Associates Inc., 2013: 2787-2795. |
| [5] | 王春雷,王肖,刘凯.多模态知识图谱表示学习综述[J].计算机应用, 2024, 44(1): 1-15. |
| WANG C L, WANG X, LIU K. Multimodal knowledge graph representation learning: a review[J]. Journal of Computer Applications, 2024, 44(1): 1-15. | |
| [6] | LE-KHAC P H, HEALY G, SMEATON A F. Contrastive representation learning: a framework and review[J]. IEEE Access, 2020, 8: 193907-193934. |
| [7] | WANG Z, ZHANG J, FENG J, et al. Knowledge graph embedding by translating on hyperplanes[C]// Proceedings of the 28th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2014: 1112-1119. |
| [8] | SUN Z, DENG Z H, NIE J Y, et al. RotatE: knowledge graph embedding by relational rotation in complex space[EB/OL]. [2024-01-13].. |
| [9] | NAYYERI M, CIL G M, VAHDATI S, et al. Trans4E: link prediction on scholarly knowledge graphs[J]. Neurocomputing, 2021, 461: 530-542. |
| [10] | YANG B, YIH W T, HE X, et al. Embedding entities and relations for learning and inference in knowledge bases[EB/OL]. [2024-03-16].. |
| [11] | BALAŽEVIĆ I, ALLEN C, HOSPEDALES T M. Tucker: tensor factorization for knowledge graph completion[C]// Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Stroudsburg: ACL, 2019: 5185-5194. |
| [12] | DETTMERS T, MINERVINI P, STENETORP P, et al. Convolutional 2D knowledge graph embeddings[C]// Proceedings of the 32nd AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2018: 1811-1818. |
| [13] | NGUYEN D Q, NGUYEN T D, NGUYEN D Q, et al. A novel embedding model for knowledge base completion based on convolutional neural network[C]// Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers). Stroudsburg: ACL, 2018: 327-333. |
| [14] | XIE R, LIU Z, JIA J, et al. Representation learning of knowledge graphs with entity descriptions[C]// Proceedings of the 30th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2016: 2659-2665. |
| [15] | XIE R, LIU Z, LUAN H, et al. Image-embodied knowledge representation learning[C]// Proceedings of the 26th International Joint Conference on Artificial Intelligence. California: IJCAI.org, 2017: 3140-3146. |
| [16] | MOUSSELLY-SERGIEH H, BOTSCHEN T, GUREVYCH I, et al. A multimodal translation-based approach for knowledge graph representation learning[C]// Proceedings of the 7th Joint Conference on Lexical and Computational Semantics. Stroudsburg: ACL, 2018: 225-234. |
| [17] | WANG Z, LI L, LI Q, et al. Multimodal data enhanced representation learning for knowledge graphs[C]// Proceedings of the 2019 International Joint Conference on Neural Networks. Piscataway: IEEE, 2019: 1-8. |
| [18] | LU X, WANG L, JIANG Z, et al. MMKRL: a robust embedding approach for multi-modal knowledge graph representation learning[J]. Applied Intelligence, 2022, 52(7): 7480-7497. |
| [19] | WANG E, YU Q, CHEN Y, et al. Multi-modal knowledge graphs representation learning via multi-headed self-attention[J]. Information Fusion, 2022, 88: 78-85. |
| [20] | ZHAI H, LV X, HOU Z, et al. MLSFF: multi-level structural features fusion for multi-modal knowledge graph completion[J]. Mathematical Biosciences and Engineering, 2023, 20(8): 14096-14116. |
| [21] | ZHANG Y, FANG Q, QIAN S, et al. Multi-modal multi-relational feature aggregation network for medical knowledge representation learning[C]// Proceedings of the 28th ACM International Conference on Multimedia. New York: ACM, 2020: 3956-3965. |
| [22] | KIPF T N, WELLING M. Semi-supervised classification with graph convolutional networks[EB/OL]. [2024-04-27].. |
| [23] | FANG Q, ZHANG X, HU J, et al. Contrastive multi-modal knowledge graph representation learning[J]. IEEE Transactions on Knowledge and Data Engineering, 2023, 35(9): 8983-8996. |
| [24] | LI X, ZHAO X, XU J, et al. IMF: interactive multimodal fusion model for link prediction[C]// Proceedings of the ACM Web Conference 2023. New York: ACM, 2023: 2572-2580. |
| [25] | HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 770-778. |
| [26] | DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional Transformers for language understanding[C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Stroudsburg: ACL, 2019: 4171-4186. |
| [27] | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]// Proceedings of the 31th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2017: 6000-6010. |
| [28] | LIU Y, LI H, GARCIA-DURAN A, et al. MMKG: multi-modal knowledge graphs[C]// Proceedings of the 2019 European Semantic Web Conference, LNCS 11503. Cham: Springer, 2019: 459-474. |
| [1] | Jin XIE, Surong CHU, Yan QIANG, Juanjuan ZHAO, Hua ZHANG, Yong GAO. Dual-branch distribution consistency contrastive learning model for hard negative sample identification in chest X-rays [J]. Journal of Computer Applications, 2025, 45(7): 2369-2377. |
| [2] | Wenjing YAN, Ruidong WANG, Min ZUO, Qingchuan ZHANG. Recipe recommendation model based on hierarchical learning of flavor embedding heterogeneous graph [J]. Journal of Computer Applications, 2025, 45(6): 1869-1878. |
| [3] | Renjie TIAN, Mingli JING, Long JIAO, Fei WANG. Recommendation algorithm of graph contrastive learning based on hybrid negative sampling [J]. Journal of Computer Applications, 2025, 45(4): 1053-1060. |
| [4] | Jintao FAN, Yanping CHEN, Caiwei YANG, Chuan LIN. Nested named entity recognition by contrastive learning with boundary information [J]. Journal of Computer Applications, 2025, 45(10): 3111-3120. |
| [5] | Jiong WANG, Taotao TANG, Caiyan JIA. PAGCL: positive augmentation graph contrastive learning recommendation method without negative sampling [J]. Journal of Computer Applications, 2024, 44(5): 1485-1492. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||