


Journal of Computer Applications ›› 2025, Vol. 45 ›› Issue (3): 794-800.DOI: 10.11772/j.issn.1001-9081.2024091251
• Frontier research and typical applications of large models • Previous Articles Next Articles
Received:2024-09-05
Revised:2024-10-30
Accepted:2024-10-31
Online:2024-11-13
Published:2025-03-10
Contact:
Zhongqing WANG
About author:SHENG Kun, born in 2000, M. S. candidate. His research interests include natural language processing, synaesthesia metaphor.
Supported by:
盛坤, 王中卿( )
)
通讯作者:
王中卿
作者简介:盛坤(2000—),男,江苏扬州人,硕士研究生,CCF会员,主要研究方向:自然语言处理、通感隐喻
基金资助:CLC Number:
Kun SHENG, Zhongqing WANG. Synaesthesia metaphor analysis based on large language model and data augmentation[J]. Journal of Computer Applications, 2025, 45(3): 794-800.
盛坤, 王中卿. 基于大语言模型和数据增强的通感隐喻分析[J]. 《计算机应用》唯一官方网站, 2025, 45(3): 794-800.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2024091251
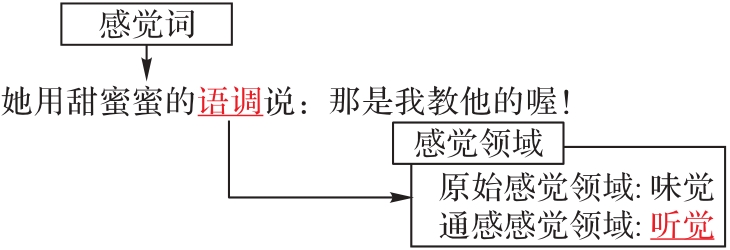
Fig. 1 Example of synesthesia analysis
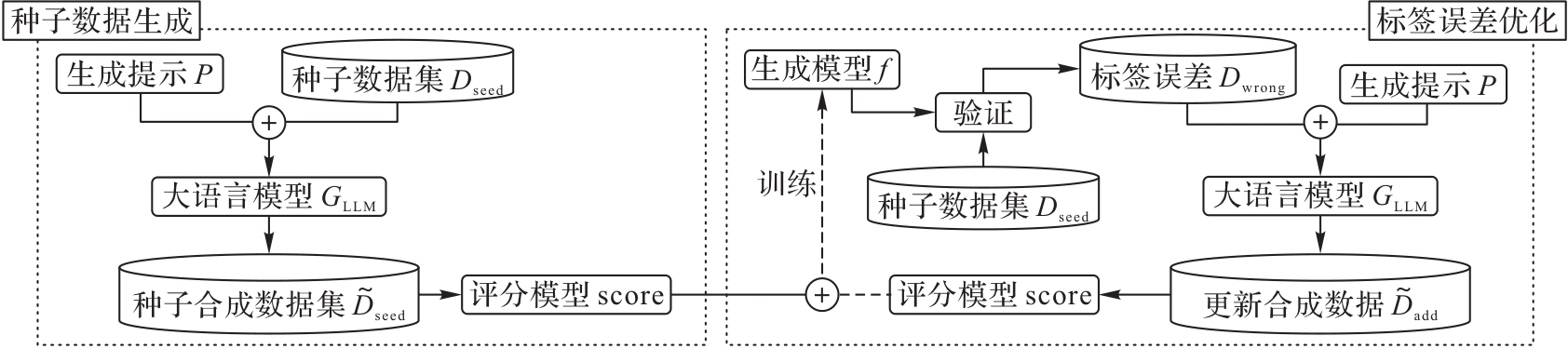
Fig. 2 Data augmentation framework based on large language model
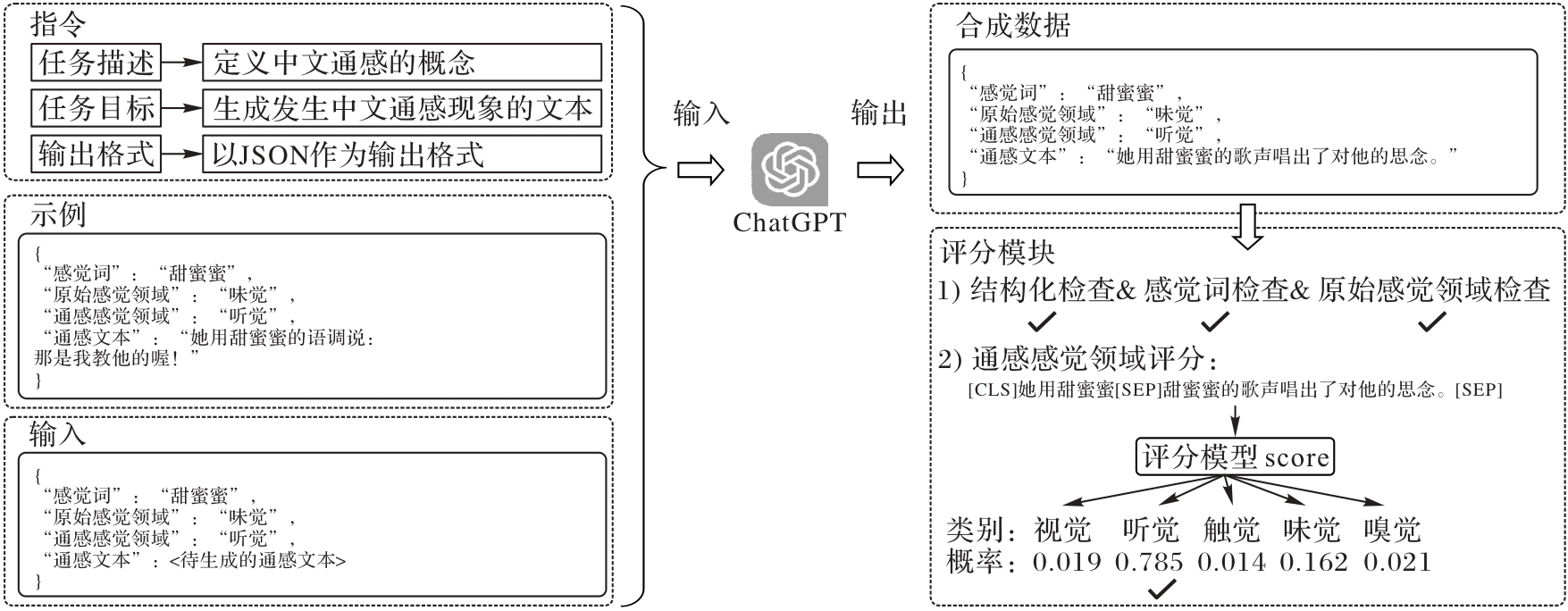
Fig. 3 Synthetic data generation and scoring
| 感觉词 | 总数 | 示例 |
|---|---|---|
| 视觉 | 92 | 清晰,苍老,透明 |
| 听觉 | 4 | 喧闹,和谐,吵 |
| 触觉 | 69 | 轻柔,尖锐,冰冷 |
| 味觉 | 20 | 苦,辛辣,甜美 |
| 嗅觉 | 2 | 香,臭 |
Tab. 1 Distribution of sensory words
| 感觉词 | 总数 | 示例 |
|---|---|---|
| 视觉 | 92 | 清晰,苍老,透明 |
| 听觉 | 4 | 喧闹,和谐,吵 |
| 触觉 | 69 | 轻柔,尖锐,冰冷 |
| 味觉 | 20 | 苦,辛辣,甜美 |
| 嗅觉 | 2 | 香,臭 |
| 参数 | 取值 |
|---|---|
| 学习率 | 10-4 |
| 批大小 | 16 |
| 优化器 | AdamW |
| 早停轮数 | 8 |
| 句子最大长度 | 256 |
| 标签最大长度 | 64 |
Tab. 2 Model parameter setting
| 参数 | 取值 |
|---|---|
| 学习率 | 10-4 |
| 批大小 | 16 |
| 优化器 | AdamW |
| 早停轮数 | 8 |
| 句子最大长度 | 256 |
| 标签最大长度 | 64 |
| 模型 | 感觉词 | 原始感觉领域 | 通感感觉领域 | 总体 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | P | R | F1 | P | R | F1 | |
| BERT | 70.1 | 67.7 | 68.9 | 82.4 | 82.5 | 82.4 | 83.7 | 82.1 | 82.9 | 65.4 | 60.4 | 62.8 |
| PF-BERT | 69.8 | 67.6 | 68.7 | 84.3 | 84.4 | 84.3 | 82.3 | 84.5 | 83.4 | 62.3 | 64.7 | 63.5 |
| T5 | 72.7 | 68.6 | 70.6 | 85.8 | 86.0 | 85.9 | 86.1 | 84.9 | 85.5 | 67.6 | 64.1 | 65.8 |
| LLaMA2 | 71.9 | 66.9 | 69.3 | 83.5 | 83.5 | 83.5 | 81.9 | 84.1 | 83.0 | 65.3 | 60.9 | 63.0 |
| MelBERT | 72.5 | 68.6 | 70.5 | 83.7 | 83.5 | 83.6 | 84.4 | 81.8 | 83.1 | 63.6 | 64.6 | 63.6 |
| Radical | 72.7 | 69.4 | 71.0 | 86.2 | 86.2 | 87.4 | 86.8 | 68.1 | 66.1 | 67.1 | ||
| GoldGen | 73.1 | 67.3 | 70.1 | 85.7 | 85.3 | 85.5 | 84.6 | 84.9 | 68.3 | 62.4 | 65.2 | |
| EDA | 85.4 | 85.4 | 85.4 | 65.8 | ||||||||
| CBERT | 73.6 | 68.4 | 70.9 | 85.7 | 86.0 | 86.4 | 85.8 | 86.1 | 66.2 | 67.2 | 66.7 | |
| 本文模型 | 74.4 | 70.7 | 72.5 | 87.0 | 86.8 | 86.9 | 87.5 | 86.7 | 87.1 | 70.8 | 68.5 | |
Tab. 3 Performance comparison of different models
| 模型 | 感觉词 | 原始感觉领域 | 通感感觉领域 | 总体 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | P | R | F1 | P | R | F1 | |
| BERT | 70.1 | 67.7 | 68.9 | 82.4 | 82.5 | 82.4 | 83.7 | 82.1 | 82.9 | 65.4 | 60.4 | 62.8 |
| PF-BERT | 69.8 | 67.6 | 68.7 | 84.3 | 84.4 | 84.3 | 82.3 | 84.5 | 83.4 | 62.3 | 64.7 | 63.5 |
| T5 | 72.7 | 68.6 | 70.6 | 85.8 | 86.0 | 85.9 | 86.1 | 84.9 | 85.5 | 67.6 | 64.1 | 65.8 |
| LLaMA2 | 71.9 | 66.9 | 69.3 | 83.5 | 83.5 | 83.5 | 81.9 | 84.1 | 83.0 | 65.3 | 60.9 | 63.0 |
| MelBERT | 72.5 | 68.6 | 70.5 | 83.7 | 83.5 | 83.6 | 84.4 | 81.8 | 83.1 | 63.6 | 64.6 | 63.6 |
| Radical | 72.7 | 69.4 | 71.0 | 86.2 | 86.2 | 87.4 | 86.8 | 68.1 | 66.1 | 67.1 | ||
| GoldGen | 73.1 | 67.3 | 70.1 | 85.7 | 85.3 | 85.5 | 84.6 | 84.9 | 68.3 | 62.4 | 65.2 | |
| EDA | 85.4 | 85.4 | 85.4 | 65.8 | ||||||||
| CBERT | 73.6 | 68.4 | 70.9 | 85.7 | 86.0 | 86.4 | 85.8 | 86.1 | 66.2 | 67.2 | 66.7 | |
| 本文模型 | 74.4 | 70.7 | 72.5 | 87.0 | 86.8 | 86.9 | 87.5 | 86.7 | 87.1 | 70.8 | 68.5 | |
| 模型 | 感觉词 | 原始感觉领域 | 通感感觉领域 | 总体评价 |
|---|---|---|---|---|
| 本文模型 | 72.5 | 87.1 | 68.5 | |
| -optimization | 70.8 | 85.9 | 66.7 | |
| -score | 87.0 | 86.1 | ||
| -optimization-score | 70.1 | 85.5 | 84.9 | 65.2 |
Tab. 4 Ablation experiment results
| 模型 | 感觉词 | 原始感觉领域 | 通感感觉领域 | 总体评价 |
|---|---|---|---|---|
| 本文模型 | 72.5 | 87.1 | 68.5 | |
| -optimization | 70.8 | 85.9 | 66.7 | |
| -score | 87.0 | 86.1 | ||
| -optimization-score | 70.1 | 85.5 | 84.9 | 65.2 |
| 类型 | 样本 | |
|---|---|---|
| 真实样本 | 梅蕙丝听了之后冷冷地说,是真的。 | |
| 评分模块 | 夜深了,窗外吹来一阵凉风,像是一首悠扬的悲伤之歌,让人感到心里一阵冷冷的寒意。 | × |
| 标签误差优化 | 寒风呼啸,耳边传来凄凉的呜咽声,犹如冷冷的低语。 | × |
| 扩充数据 | 李雅琪冷冷的声音传来:“闭嘴!不要再说了!” |
Tab. 5 Sample analysis
| 类型 | 样本 | |
|---|---|---|
| 真实样本 | 梅蕙丝听了之后冷冷地说,是真的。 | |
| 评分模块 | 夜深了,窗外吹来一阵凉风,像是一首悠扬的悲伤之歌,让人感到心里一阵冷冷的寒意。 | × |
| 标签误差优化 | 寒风呼啸,耳边传来凄凉的呜咽声,犹如冷冷的低语。 | × |
| 扩充数据 | 李雅琪冷冷的声音传来:“闭嘴!不要再说了!” |
| 1 | ONDISH P, COHEN D, LUCAS K W, et al. The resonance of metaphor: evidence for Latino preferences for metaphor and analogy[J]. Personality and Social Psychology Bulletin, 2019, 45(11): 1531-1548. |
| 2 | KÖVECSES Z. Metaphor: a practical introduction [M]. 2nd ed. New York: Oxford University Press, 2010. |
| 3 | LAKOFF G, JOHNSON M. Metaphors we live by [M]. Chicago: University of Chicago Press, 2008. |
| 4 | 徐盛桓. 隐喻研究认识论的前提性批判——“假物说”与“指事说”的理论意蕴[J]. 外语教学,2018,39(2):1-6. |
| XU S H. Premised criticism of metaphor epistemology: understanding one kind of thing in terms of another and experiencing one kind of event in terms of another [J]. Foreign Language Education, 2018, 39(2): 1-6. | |
| 5 | TÜRKER R, ZHANG L, KOUTRAKI M, et al. Knowledge-based short text categorization using entity and category embedding [C]// Proceedings of the 2019 European Semantic Web Conference, LNCS 11503. Cham: Springer, 2019: 346-362. |
| 6 | ZHANG X, WU B. Short text classification based on feature extension using the n-gram model [C]// Proceedings of the 12th International Conference on Fuzzy Systems and Knowledge Discovery. Piscataway: IEEE, 2015: 710-716. |
| 7 | SHAMS R. Semi-supervised classification for natural language processing [EB/OL]. [2024-06-13]. . |
| 8 | RADFORD A, NARASIMHAN K, SALIMANS T, et al. Improving language understanding by generative pre-training [EB/OL]. [2024-08-11]. . |
| 9 | PURI R, SPRING R, SHOEYBI M, et al. Training question answering models from synthetic data [C]// Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2020: 5811-5826. |
| 10 | ULLMANN S. The principles of semantics [M]. 2nd ed. Oxford: Basil Blackwell & Mott, 1957. |
| 11 | STRIK LIEVERS F. Synaesthesia: a corpus-based study of cross-modal directionality [J]. Functions of Language, 2015, 22(1): 69-95. |
| 12 | ZHAO Q, HUANG C R, LONG Y. Synaesthesia in Chinese: a corpus-based study on gustatory adjectives in Mandarin [J]. Linguistics, 2018, 56(5): 1167-1194. |
| 13 | ZHONG Y, AHRENS K. “Prickly voice” or “smelly voice”? comprehending novel synaesthetic metaphors [C]// Proceedings of the 35th Pacific Asia Conference on Language, Information and Computation. Stroudsburg: ACL, 2021: 71-79. |
| 14 | STRIK LIEVERS F, HUANG C R. A lexicon of perception for the identification of synaesthetic metaphors in corpora [C]// Proceedings of the 10th International Conference on Language Resources and Evaluation. Paris: European Language Resources Association, 2016: 2270-2277. |
| 15 | JIANG X, ZHAO Q, LONG Y, et al. Chinese synesthesia detection: new dataset and models [C]// Findings of the Annual Meeting of the Association for Computational Linguistics: ACL 2022. Stroudsburg: ACL, 2022: 3877-3887. |
| 16 | WEI J, ZOU K. EDA: easy data augmentation techniques for boosting performance on text classification tasks [C]// Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Stroudsburg: ACL, 2019: 6382-6388. |
| 17 | WU X, LV S, ZANG L, et al. Conditional BERT contextual augmentation [C]// Proceedings of the 2019 International Conference on Computational Science, LNCS 11539. Cham: Springer, 2019: 84-95. |
| 18 | ANABY-TAVOR A, CARMELI B, GOLDBRAICH E, et al. Do not have enough data? Deep learning to the rescue! [C]// Proceedings of the 34th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2020: 7383-7390. |
| 19 | KUMAR V, CHOUDHARY A, CHO E. Data augmentation using pre-trained Transformer models [C]// Proceedings of the 2nd Workshop on Life-long Learning for Spoken Language Systems. Stroudsburg: ACL, 2020: 18-26. |
| 20 | EDWARDS A, USHIO A, CAMACHO-COLLADOS J, et al. Guiding generative language models for data augmentation in few-shot text classification [C]// Proceedings of the 4th Workshop on Data Science with Human-in-the-Loop (Language Advances). Stroudsburg: ACL, 2022: 51-63. |
| 21 | YANG Y, MALAVIYA C, FERNANDEZ J, et al. Generative data augmentation for commonsense reasoning [C]// Findings of the Association for Computational Linguistics: EMNLP 2020. Stroudsburg: ACL, 2020: 1008-1025. |
| 22 | BROWN T B, MANN B, RYDER N, et al. Language models are few-shot learners [EB/OL]. [2024-04-23]. . |
| 23 | DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional Transformers for language understanding [C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Stroudsburg: ACL, 2019: 4171-4186. |
| 24 | RAFFEL C, SHAZEER N, ROBERTS A, et al. Exploring the limits of transfer learning with a unified text-to-text Transformer[J]. Journal of Machine Learning Research, 2020, 21: 1-67. |
| 25 | TANG D, QIN B, FENG X, et al. Effective LSTMs for target-dependent sentiment classification [C]// Proceedings of the 26th International Conference on Computational Linguistics: Technical Papers. Stroudsburg: ACL, 2016: 3298-3307. |
| 26 | LAFFERTY J D, McCALLUM A, PEREIRA F C N. Conditional random fields: probabilistic models for segmenting and labeling sequence data [C]// Proceedings of the 18th International Conference on Machine Learning. San Francisco: Morgan Kaufmann Publishers Inc., 2001: 282-289. |
| 27 | TOUVRON H, MARTIN L, STONE K, et al. LLaMA 2: open foundation and fine-tuned chat models [EB/OL]. [2024-04-29].. |
| 28 | HU E, SHEN Y, WALLIS P, et al. LoRA: low-rank adaptation of large language models [EB/OL]. [2024-04-24]. . |
| 29 | SU C, FUKUMOTO F, HUANG X, et al. DeepMet: a reading comprehension paradigm for token-level metaphor detection [C]// Proceedings of the 2nd Workshop on Figurative Language Processing. Stroudsburg: ACL, 2020: 30-39. |
| 30 | CHRISTOPHER C D, SCHÜTZE H. Foundations of statistical natural language processing [M]. Cambridge: MIT Press, 1999. |
| [1] | Yanmin DONG, Jiajia LIN, Zheng ZHANG, Cheng CHENG, Jinze WU, Shijin WANG, Zhenya HUANG, Qi LIU, Enhong CHEN. Design and practice of intelligent tutoring algorithm based on personalized student capability perception [J]. Journal of Computer Applications, 2025, 45(3): 765-772. |
| [2] | Xuefei ZHANG, Liping ZHANG, Sheng YAN, Min HOU, Yubo ZHAO. Personalized learning recommendation in collaboration of knowledge graph and large language model [J]. Journal of Computer Applications, 2025, 45(3): 773-784. |
| [3] | Jing HE, Yang SHEN, Runfeng XIE. Recognition and optimization of hallucination phenomena in large language models [J]. Journal of Computer Applications, 2025, 45(3): 709-714. |
| [4] | Yuemei XU, Yuqi YE, Xueyi HE. Bias challenges of large language models: identification, evaluation, and mitigation [J]. Journal of Computer Applications, 2025, 45(3): 697-708. |
| [5] | Yan YANG, Feng YE, Dong XU, Xuejie ZHANG, Jin XU. Construction of digital twin water conservancy knowledge graph integrating large language model and prompt learning [J]. Journal of Computer Applications, 2025, 45(3): 785-793. |
| [6] | Peng CAO, Guangqi WEN, Jinzhu YANG, Gang CHEN, Xinyi LIU, Xuechun JI. Efficient fine-tuning method of large language models for test case generation [J]. Journal of Computer Applications, 2025, 45(3): 725-731. |
| [7] | Xiaolin QIN, Xu GU, Dicheng LI, Haiwen XU. Survey and prospect of large language models [J]. Journal of Computer Applications, 2025, 45(3): 685-696. |
| [8] | Chengzhe YUAN, Guohua CHEN, Dingding LI, Yuan ZHU, Ronghua LIN, Hao ZHONG, Yong TANG. ScholatGPT: a large language model for academic social networks and its intelligent applications [J]. Journal of Computer Applications, 2025, 45(3): 755-764. |
| [9] | Ying YANG, Xiaoyan HAO, Dan YU, Yao MA, Yongle CHEN. Graph data generation approach for graph neural network model extraction attacks [J]. Journal of Computer Applications, 2024, 44(8): 2483-2492. |
| [10] | Huanliang SUN, Siyi WANG, Junling LIU, Jingke XU. Help-seeking information extraction model for flood event in social media data [J]. Journal of Computer Applications, 2024, 44(8): 2437-2445. |
| [11] | Yuemei XU, Ling HU, Jiayi ZHAO, Wanze DU, Wenqing WANG. Technology application prospects and risk challenges of large language models [J]. Journal of Computer Applications, 2024, 44(6): 1655-1662. |
| [12] | Yushan JIANG, Yangsen ZHANG. Large language model-driven stance-aware fact-checking [J]. Journal of Computer Applications, 2024, 44(10): 3067-3073. |
| [13] | Yinjiang CAI, Guangjun XU, Xibo MA. Data enhancement method for drugs under graph-structured representation [J]. Journal of Computer Applications, 2023, 43(4): 1136-1141. |
| [14] | Xiaohan YANG, Guosheng HAO, Xiehua ZHANG, Zihao YANG. Collaborative filtering algorithm based on collaborative training and Boosting [J]. Journal of Computer Applications, 2023, 43(10): 3136-3141. |
| [15] | CHEN Guihui, YI Xin, LI Zhongbing, QIAN Jiren, CHEN Wu. Third-party construction target detection in aerial images of pipeline inspection based on improved YOLOv2 and transfer learning [J]. Journal of Computer Applications, 2020, 40(4): 1062-1068. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||