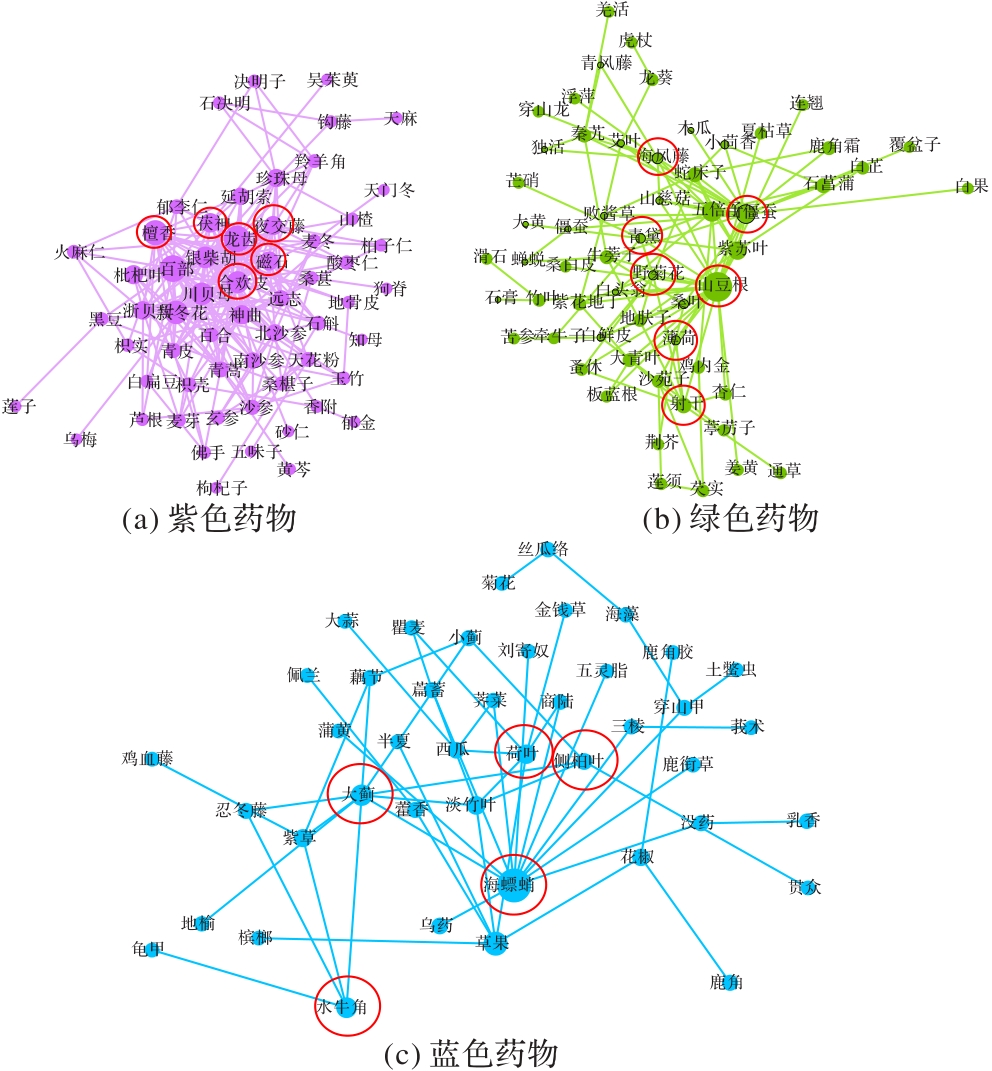
Journal of Computer Applications ›› 0, Vol. ›› Issue (): 50-54.DOI: 10.11772/j.issn.1001-9081.2024040472
• Artificial intelligence • Previous Articles Next Articles
Deyang KONG1,2,3, Yun ZHANG1,2,3( ), Weiguang WANG4, Zijie CHEN4, Yongguo LIU1,2,3
), Weiguang WANG4, Zijie CHEN4, Yongguo LIU1,2,3
孔德阳1,2,3, 张云1,2,3(), 王维广4, 陈子杰4, 刘勇国1,2,3