


Journal of Computer Applications ›› 2025, Vol. 45 ›› Issue (12): 3995-4003.DOI: 10.11772/j.issn.1001-9081.2024121866
• Multimedia computing and computer simulation • Previous Articles Next Articles
Yang DENG1,2, Tao ZHAO3, Kai SUN3, Tong TONG1,4, Qinquan GAO1,4( )
)
Received:2025-01-03
Revised:2025-03-18
Accepted:2025-03-20
Online:2025-04-03
Published:2025-12-10
Contact:
Qinquan GAO
About author:DENG Yang, born in 1998, M. S. candidate. Her research interests include computer vision, image processing.Supported by:
邓旸1,2, 赵涛3, 孙凯3, 童同1,4, 高钦泉1,4()
通讯作者:
高钦泉
作者简介:邓旸(1998—),女,福建三明人,硕士研究生,主要研究方向:计算机视觉、图像处理基金资助:CLC Number:
Yang DENG, Tao ZHAO, Kai SUN, Tong TONG, Qinquan GAO. No-reference image quality assessment algorithm based on saliency features and cross-attention mechanism[J]. Journal of Computer Applications, 2025, 45(12): 3995-4003.
邓旸, 赵涛, 孙凯, 童同, 高钦泉. 基于显著性特征与交叉注意力的无参考图像质量评价算法[J]. 《计算机应用》唯一官方网站, 2025, 45(12): 3995-4003.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2024121866
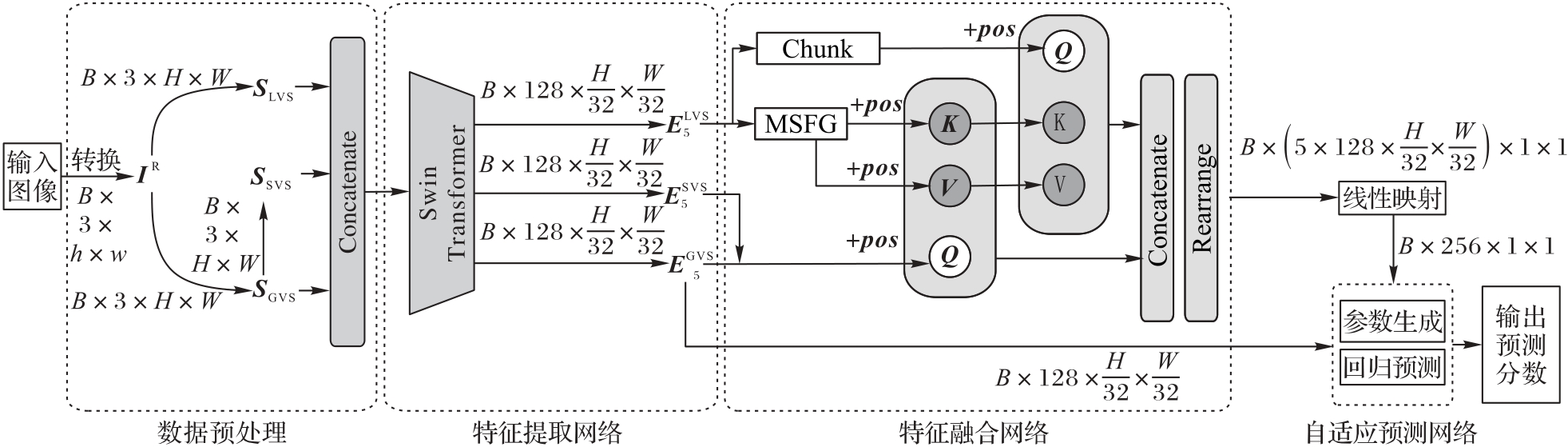
Fig. 1 Overall architecture of proposed algorithm
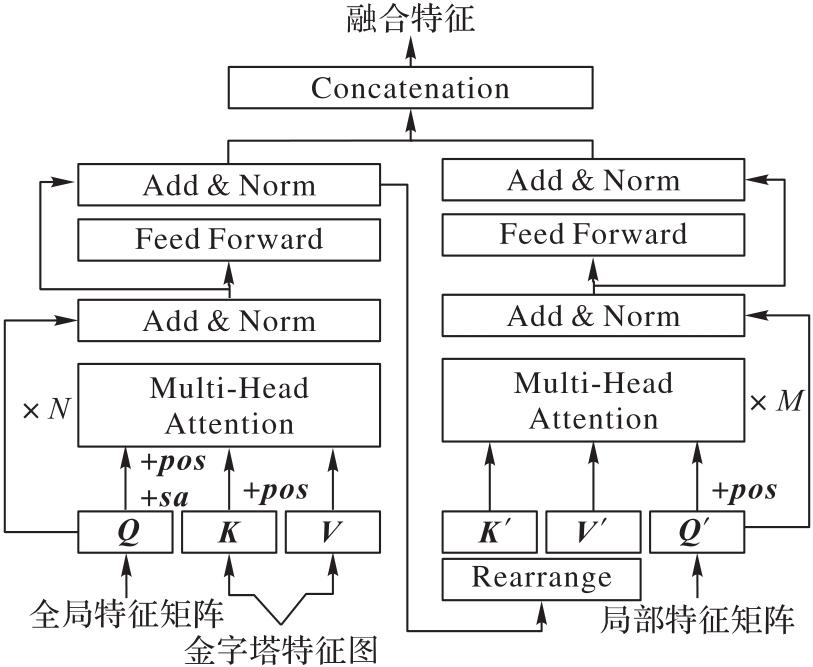
Fig. 2 Structure of FFN
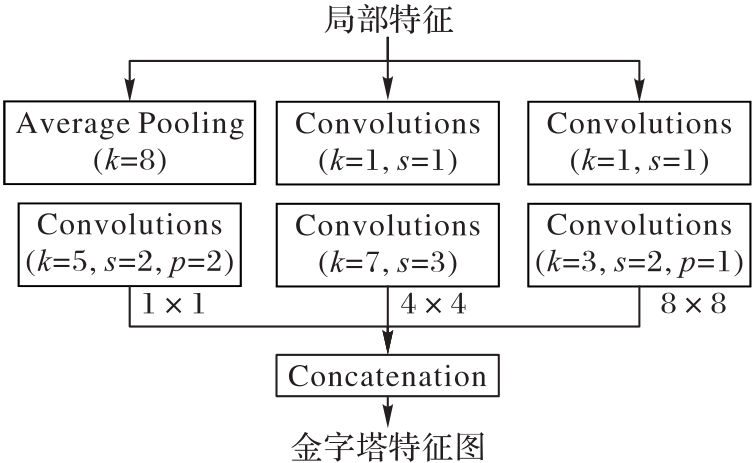
Fig. 3 Structure of MSFG module
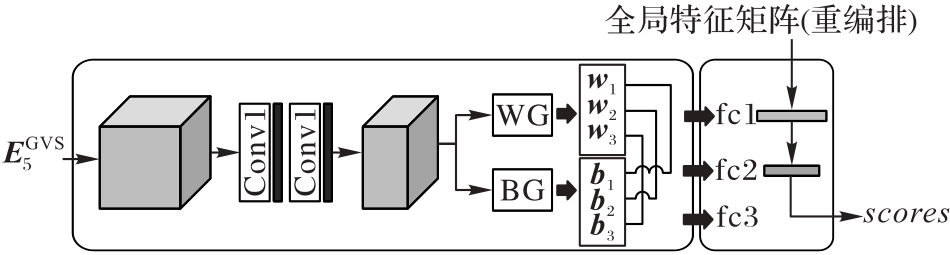
Fig. 4 Structure of APN
| 数据集 | 失真图像数 | 失真类型数 | 失真等级 | 评价方法 | 取值范围 |
|---|---|---|---|---|---|
| LIVE | 799 | 5 | 5~8 | DMOS | [0,100] |
| TID2013 | 3 000 | 24 | 5 | MOS | [0,9] |
| KADID | 10 125 | 25 | 5 | DMOS | [ |
| CLIVE | 1 162 | — | — | MOS | [0,100] |
| KonIQ | 10 073 | — | — | MOS | [ |
| SPAQ | 11 125 | — | — | MOS | [0,100] |
Tab. 1 Information summary of IQA datasets
| 数据集 | 失真图像数 | 失真类型数 | 失真等级 | 评价方法 | 取值范围 |
|---|---|---|---|---|---|
| LIVE | 799 | 5 | 5~8 | DMOS | [0,100] |
| TID2013 | 3 000 | 24 | 5 | MOS | [0,9] |
| KADID | 10 125 | 25 | 5 | DMOS | [ |
| CLIVE | 1 162 | — | — | MOS | [0,100] |
| KonIQ | 10 073 | — | — | MOS | [ |
| SPAQ | 11 125 | — | — | MOS | [0,100] |
| 算法类型 | 算法 | LIVE | TID2013 | KADID | |||
|---|---|---|---|---|---|---|---|
| SRCC | PLCC | SRCC | PLCC | SRCC | PLCC | ||
| 数据驱动 | IL-NIQE | 0.887 | 0.894 | 0.521 | 0.648 | 0.565 | 0.611 |
| BRISQUE | 0.939 | 0.935 | 0.604 | 0.694 | 0.528 | 0.567 | |
| DB-CNN | 0.968 | 0.971 | 0.816 | 0.865 | 0.816 | 0.865 | |
| P2P-BM | 0.959 | 0.958 | 0.862 | 0.856 | 0.840 | 0.849 | |
| MetaIQA | 0.960 | 0.959 | 0.856 | 0.868 | 0.762 | 0.775 | |
| HyperIQA | 0.962 | 0.966 | 0.840 | 0.858 | 0.859 | 0.845 | |
| UNIQUE | 0.969 | 0.968 | — | — | 0.878 | 0.876 | |
| ARNIQA | 0.966 | 0.970 | 0.880 | 0.901 | 0.908 | 0.912 | |
| DSMix | 0.974 | 0.974 | |||||
| 视觉注意驱动 | TRIQ | 0.949 | 0.965 | 0.846 | 0.858 | 0.850 | 0.855 |
| TReS | 0.968 | 0.969 | 0.883 | 0.863 | 0.858 | 0.859 | |
| ADTRS | 0.972 | 0.878 | 0.897 | — | — | ||
| 本文算法 | 0.969 | 0.945 | 0.952 | 0.952 | 0.955 | ||
Tab. 2 Comparison of performance of different algorithms on synthetic distortion datasets
| 算法类型 | 算法 | LIVE | TID2013 | KADID | |||
|---|---|---|---|---|---|---|---|
| SRCC | PLCC | SRCC | PLCC | SRCC | PLCC | ||
| 数据驱动 | IL-NIQE | 0.887 | 0.894 | 0.521 | 0.648 | 0.565 | 0.611 |
| BRISQUE | 0.939 | 0.935 | 0.604 | 0.694 | 0.528 | 0.567 | |
| DB-CNN | 0.968 | 0.971 | 0.816 | 0.865 | 0.816 | 0.865 | |
| P2P-BM | 0.959 | 0.958 | 0.862 | 0.856 | 0.840 | 0.849 | |
| MetaIQA | 0.960 | 0.959 | 0.856 | 0.868 | 0.762 | 0.775 | |
| HyperIQA | 0.962 | 0.966 | 0.840 | 0.858 | 0.859 | 0.845 | |
| UNIQUE | 0.969 | 0.968 | — | — | 0.878 | 0.876 | |
| ARNIQA | 0.966 | 0.970 | 0.880 | 0.901 | 0.908 | 0.912 | |
| DSMix | 0.974 | 0.974 | |||||
| 视觉注意驱动 | TRIQ | 0.949 | 0.965 | 0.846 | 0.858 | 0.850 | 0.855 |
| TReS | 0.968 | 0.969 | 0.883 | 0.863 | 0.858 | 0.859 | |
| ADTRS | 0.972 | 0.878 | 0.897 | — | — | ||
| 本文算法 | 0.969 | 0.945 | 0.952 | 0.952 | 0.955 | ||
| 算法类型 | 算法 | CLIVE | KonIQ | SPAQ | |||
|---|---|---|---|---|---|---|---|
| SRCC | PLCC | SRCC | PLCC | SRCC | PLCC | ||
| 数据驱动 | IL-NIQE | 0.469 | 0.518 | 0.507 | 0.523 | 0.713 | 0.721 |
| BRISQUE | 0.608 | 0.629 | 0.665 | 0.681 | 0.809 | 0.817 | |
| DB-CNN | 0.851 | 0.869 | 0.875 | 0.884 | 0.910 | 0.913 | |
| P2P-BM | 0.844 | 0.842 | 0.872 | 0.885 | — | — | |
| MetaIQA | 0.802 | 0.835 | 0.850 | 0.887 | — | — | |
| HyperIQA | 0.859 | 0.882 | 0.906 | 0.917 | 0.911 | 0.915 | |
| UNIQUE | 0.854 | 0.896 | 0.901 | — | — | ||
| ARNIQA | — | — | — | — | 0.905 | 0.910 | |
| DSMix | 0.883 | 0.915 | 0.925 | — | — | ||
| 视觉注意驱动 | TRIQ | 0.845 | 0.861 | 0.892 | 0.903 | — | — |
| TReS | 0.877 | 0.846 | 0.928 | 0.915 | — | — | |
| MUSIQ | — | — | 0.916 | 0.917 | 0.921 | ||
| ADTRS | 0.836 | 0.864 | 0.905 | 0.918 | — | — | |
| 本文算法 | 0.868 | 0.893 | 0.938 | ||||
Tab. 3 Comparison of performance of algorithms on real-world distortion datasets
| 算法类型 | 算法 | CLIVE | KonIQ | SPAQ | |||
|---|---|---|---|---|---|---|---|
| SRCC | PLCC | SRCC | PLCC | SRCC | PLCC | ||
| 数据驱动 | IL-NIQE | 0.469 | 0.518 | 0.507 | 0.523 | 0.713 | 0.721 |
| BRISQUE | 0.608 | 0.629 | 0.665 | 0.681 | 0.809 | 0.817 | |
| DB-CNN | 0.851 | 0.869 | 0.875 | 0.884 | 0.910 | 0.913 | |
| P2P-BM | 0.844 | 0.842 | 0.872 | 0.885 | — | — | |
| MetaIQA | 0.802 | 0.835 | 0.850 | 0.887 | — | — | |
| HyperIQA | 0.859 | 0.882 | 0.906 | 0.917 | 0.911 | 0.915 | |
| UNIQUE | 0.854 | 0.896 | 0.901 | — | — | ||
| ARNIQA | — | — | — | — | 0.905 | 0.910 | |
| DSMix | 0.883 | 0.915 | 0.925 | — | — | ||
| 视觉注意驱动 | TRIQ | 0.845 | 0.861 | 0.892 | 0.903 | — | — |
| TReS | 0.877 | 0.846 | 0.928 | 0.915 | — | — | |
| MUSIQ | — | — | 0.916 | 0.917 | 0.921 | ||
| ADTRS | 0.836 | 0.864 | 0.905 | 0.918 | — | — | |
| 本文算法 | 0.868 | 0.893 | 0.938 | ||||

Fig. 5 Test results of samples from different datasets
| 数据集 | DBCNN | P2P-BM | HyperIQA | TReS | 本文算法 |
|---|---|---|---|---|---|
| CLIVE | 0.755 | 0.770 | 0.785 | 0.786 | 0.865 |
| SPAQ | 0.783 | 0.730 | 0.807 | 0.848 | 0.890 |
Tab.4 Comparison of SRCC for various algorithms on different datasets
| 数据集 | DBCNN | P2P-BM | HyperIQA | TReS | 本文算法 |
|---|---|---|---|---|---|
| CLIVE | 0.755 | 0.770 | 0.785 | 0.786 | 0.865 |
| SPAQ | 0.783 | 0.730 | 0.807 | 0.848 | 0.890 |
| 序号 | 组件 | LIVE | CLIVE | ||
|---|---|---|---|---|---|
| SRCC | PLCC | SRCC | PLCC | ||
| 1 | Baseline(Swim Transformer) | 0.964 | 0.967 | 0.781 | 0.795 |
| 2 | GVS+Cross Attention | 0.960 | 0.960 | 0.802 | 0.824 |
| 3 | GVS+Cross Attention+ MSFG | 0.968 | 0.966 | 0.841 | 0.865 |
| 4 | GVS+Cross Attention+ MSFG+APN | 0.969 | 0.973 | 0.854 | 0.873 |
| 5 | GVS+Cross Attention(Saliency Embedding)+ MSFG+APN | 0.969 | 0.973 | 0.855 | 0.879 |
Tab. 5 Design and results of ablation experiments
| 序号 | 组件 | LIVE | CLIVE | ||
|---|---|---|---|---|---|
| SRCC | PLCC | SRCC | PLCC | ||
| 1 | Baseline(Swim Transformer) | 0.964 | 0.967 | 0.781 | 0.795 |
| 2 | GVS+Cross Attention | 0.960 | 0.960 | 0.802 | 0.824 |
| 3 | GVS+Cross Attention+ MSFG | 0.968 | 0.966 | 0.841 | 0.865 |
| 4 | GVS+Cross Attention+ MSFG+APN | 0.969 | 0.973 | 0.854 | 0.873 |
| 5 | GVS+Cross Attention(Saliency Embedding)+ MSFG+APN | 0.969 | 0.973 | 0.855 | 0.879 |

Fig. 6 Response of attention matrix to saliency feature embedding layer

Fig. 7 Attention distributions under different distortion levels of JPEG2000 compression
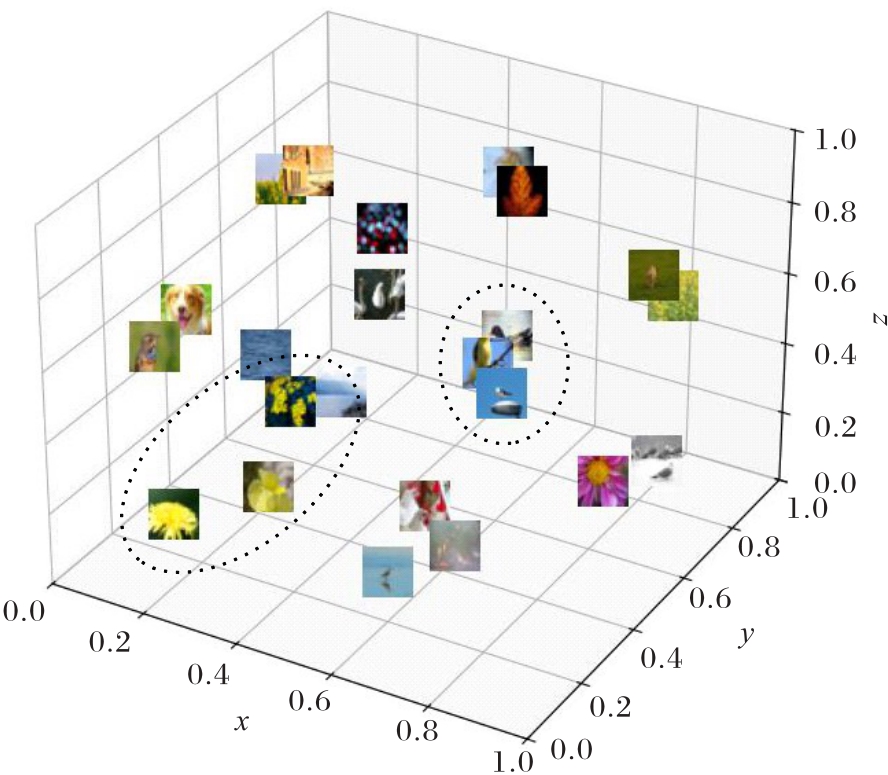
Fig. 8 Distribution of feature vectors in 3D space

Fig. 9 MOS and prediction scores of neighboring samples
| [1] | SUN G M, SHI B F, CHEN X D, et al. Learning local quality-aware structures of salient regions for stereoscopic images via deep neural networks[J]. IEEE Transactions on Multimedia, 2020, 22(11): 2938-2949. |
| [2] | CHETOUANI A. Comparative study of saliency- and scanpath-based approaches for patch selection in image quality assessment[C]// Proceedings of the 2023 International Conference on Image Processing. Piscataway: IEEE, 2023: 2670-2674. |
| [3] | ZHANG Y Z, WAN L F, LIU D Y, et al. Saliency-guided no-reference omnidirectional image quality assessment via scene content perceiving[J]. IEEE Transactions on Instrumentation and Measurement, 2024, 73: 1-15. |
| [4] | FENG J, LI S, CHANG Y. Binocular visual mechanism guided no-reference stereoscopic image quality assessment considering spatial saliency[C]// Proceedings of the 2021 International Conference on Visual Communications and Image Processing. Piscataway: IEEE, 2021: 1-5. |
| [5] | LI S, ZHAO P, CHANG Y. No-reference stereoscopic image quality assessment based on visual attention mechanism[C]// Proceedings of the 2020 IEEE International Conference on Visual Communications and Image Processing. Piscataway: IEEE, 2020: 326-329. |
| [6] | YANG L, XU M, DENG X, et al. Spatial attention-based non-reference perceptual quality prediction network for omnidirectional images[C]// Proceedings of the 2021 International Conference on Multimedia and Expo. Piscataway: IEEE, 2021: 1-6. |
| [7] | YOU J, YAN J. Explore spatial and channel attention in image quality assessment[C]// Proceedings of the 2022 International Conference on Image Processing. Piscataway: IEEE, 2022: 26-30. |
| [8] | KE J, WANG Q, WANG Y, et al. MUSIQ: multi-scale image quality Transformer[C]// Proceedings of the 2021 International Conference on Computer Vision. Piscataway: IEEE, 2021: 5128-5137. |
| [9] | LI H, WANG L, LI Y. Efficient context and saliency aware Transformer network for no-reference image quality assessment[C]// Proceedings of the 2023 International Conference on Visual Communications and Image Processing. Piscataway: IEEE, 2023: 1-5. |
| [10] | GOLESTANEH S A, DADSETAN S, KITANI K M. No-reference image quality assessment via Transformers, relative ranking, and self-consistency[C]// Proceedings of the 2022 Winter Conference on Applications of Computer Vision. Piscataway: IEEE, 2022: 3989-3999. |
| [11] | ALSAAFIN M, ALSHEIKH M, ANWAR S, et al. Attention down-sampling Transformer, relative ranking and self-consistency for blind image quality assessment[C]// Proceedings of the 2024 International Conference on Image Processing. Piscataway: IEEE, 2024: 1260-1266. |
| [12] | ZHU H, LI L, WU J, et al. MetaIQA: deep meta-learning for no-reference image quality assessment[C]// Proceedings of the 2020 Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 14131-14140. |
| [13] | SU S, YAN Q, ZHU Y, et al. Blindly assess image quality in the wild guided by a self-adaptive hyper network[C]// Proceedings of the 2020 Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 3664-3673. |
| [14] | ZHANG W X, MA K, ZHAI G T, et al. Uncertainty-aware blind image quality assessment in the laboratory and wild [J]. IEEE Transactions on Image Processing, 2021, 30: 3474-3486. |
| [15] | SHI J, GAO P, PENG X, et al. DSMix: distortion-induced sensitivity map based pre-training for no-reference image quality assessment [C]// Proceedings of the 2024 European Conference on Computer Vision, LNCS 15128. Cham: Springer, 2025: 1-17. |
| [16] | CHELAZZI L, PERLATO A, SANTANDREA E, et al. Rewards teach visual selective attention[J]. Vision Research, 2013, 85: 58-72. |
| [17] | YOU J, PERKIS A, GABBOUJ M. Improving image quality assessment with modeling visual attention[C]// Proceedings of the 2nd European Workshop on Visual Information Processing. Piscataway: IEEE, 2010: 177-182. |
| [18] | HAREL J, KOCH C, PERONA P. Graph-based visual saliency[C]// Proceedings of the 20th International Conference on Neural Information Processing Systems. Cambridge: MIT Press, 2006: 545-552. |
| [19] | WASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2017: 6000-6010. |
| [20] | 王文冠,沈建冰,贾云得. 视觉注意力检测综述[J]. 软件学报, 2019, 30(2): 416-439. |
| WANG W G, SHEN J B, JIA Y D. Review of visual attention detection[J]. Journal of Software, 2019, 30(2): 416-439. | |
| [21] | CARON M, TOUVRON H, MISRA I, et al. Emerging properties in self-supervised vision Transformers[C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 9630-9640. |
| [22] | WANG Y, SHEN X, HU S X, et al. Self-supervised Transformers for unsupervised object discovery using normalized cut[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 14523-14533. |
| [23] | SHI J, MALIK J. Normalized cuts and image segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2000, 22(8): 888-905. |
| [24] | SHIN G, ALBANIE S, XIE W. Unsupervised salient object detection with spectral cluster voting[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Piscataway: IEEE, 2022: 3970-3979. |
| [25] | SHEIKH H R, SABIR M F, BOVIK A C. A statistical evaluation of recent full reference image quality assessment algorithms[J]. IEEE Transactions on Image Processing, 2006, 15(11): 3440-3451. |
| [26] | PONOMARENKO N, IEREMEIEV O, LUKIN V, et al. Color image database TID2013: peculiarities and preliminary results[C]// Proceedings of the 2013 European Workshop on Visual Information Processing. Piscataway: IEEE, 2013: 106-111. |
| [27] | LIN H, HOSU V, SAUPE D. KADID-10k: a large-scale artificially distorted IQA database[C]// Proceedings of the 11th International Conference on Quality of Multimedia Experience. Piscataway: IEEE, 2019: 1-3. |
| [28] | GHADIYARAM D, BOVIK A C. Massive online crowdsourced study of subjective and objective picture quality[J]. IEEE Transactions on Image Processing, 2016, 25(1): 372-387. |
| [29] | HOSU V, LIN H, SZIRANYI T, et al. KonIQ-10k: an ecologically valid database for deep learning of blind image quality assessment[J]. IEEE Transactions on Image Processing, 2020, 29: 4041-4056. |
| [30] | FANG Y, ZHU H, ZENG Y, et al. Perceptual quality assessment of smartphone photography[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 3674-3683. |
| [31] | THOMEE B, SHAMMA D A, FRIEDLAND G, et al. YFCC100M: the new data in multimedia research[J] Communications of the ACM, 2016, 59(2): 64-73. |
| [32] | AGNOLUCCI L, GALTERI L, BERTINI M, et al. ARNIQA: learning distortion manifold for image quality assessment[C]// Proceedings of the 2024 IEEE/CVF Winter Conference on Applications of Computer Vision. Piscataway: IEEE, 2024: 188-197. |
| [33] | ZHANG L, ZHANG L, BOVIK A C. A feature-enriched completely blind image quality evaluator[J]. IEEE Transactions on Image Processing, 2015, 24(8): 2579-2591. |
| [34] | MITTAL A, MOORTHY A K, BOVIK A C. No-reference image quality assessment in the spatial domain[J]. IEEE Transactions on Image Processing, 2012, 21(12): 4695-4708. |
| [35] | ZHANG W, MA K, YAN J, et al. Blind image quality assessment using a deep bilinear convolutional neural network[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2020, 30(1): 36-47. |
| [36] | YING Z, NIU H, GUPTA P, et al. From patches to pictures (PaQ-2-PiQ): mapping the perceptual space of picture quality[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 3572-3582. |
| [37] | YOU J, KORHONEN J. Transformer for image quality assessment[C]// Proceedings of the 2021 IEEE International Conference on Image Processing. Piscataway: IEEE, 2021: 1389-1393. |
| [1] | Yingjie MA, Jingying QIN, Geng ZHAO, Jing XIAO. Deep compressive sensing network for IoT images and its chaotic encryption protection method [J]. Journal of Computer Applications, 2026, 46(1): 144-151. |
| [2] | Lifang WANG, Wenjing REN, Xiaodong GUO, Rongguo ZHANG, Lihua HU. Trident generative adversarial network for low-dose CT image denoising [J]. Journal of Computer Applications, 2026, 46(1): 270-279. |
| [3] | Yanan LI, Mengyang GUO, Guojun DENG, Yunfeng CHEN, Jianji REN, Yongliang YUAN. Method for life prediction of parallel branching engine based on multi-modal fusion features [J]. Journal of Computer Applications, 2026, 46(1): 305-313. |
| [4] | Weigang LI, Jiale SHAO, Zhiqiang TIAN. Point cloud classification and segmentation network based on dual attention mechanism and multi-scale fusion [J]. Journal of Computer Applications, 2025, 45(9): 3003-3010. |
| [5] | Xiang WANG, Zhixiang CHEN, Guojun MAO. Multivariate time series prediction method combining local and global correlation [J]. Journal of Computer Applications, 2025, 45(9): 2806-2816. |
| [6] | Jinggang LYU, Shaorui PENG, Shuo GAO, Jin ZHOU. Speech enhancement network driven by complex frequency attention and multi-scale frequency enhancement [J]. Journal of Computer Applications, 2025, 45(9): 2957-2965. |
| [7] | Haifeng WU, Liqing TAO, Yusheng CHENG. Partial label regression algorithm integrating feature attention and residual connection [J]. Journal of Computer Applications, 2025, 45(8): 2530-2536. |
| [8] | Chao JING, Yutao QUAN, Yan CHEN. Improved multi-layer perceptron and attention model-based power consumption prediction algorithm [J]. Journal of Computer Applications, 2025, 45(8): 2646-2655. |
| [9] | Jinhao LIN, Chuan LUO, Tianrui LI, Hongmei CHEN. Thoracic disease classification method based on cross-scale attention network [J]. Journal of Computer Applications, 2025, 45(8): 2712-2719. |
| [10] | Jin ZHOU, Yuzhi LI, Xu ZHANG, Shuo GAO, Li ZHANG, Jiachuan SHENG. Modulation recognition network for complex electromagnetic environments [J]. Journal of Computer Applications, 2025, 45(8): 2672-2682. |
| [11] | Haoyu LIU, Pengwei KONG, Yaoli WANG, Qing CHANG. Pedestrian detection algorithm based on multi-view information [J]. Journal of Computer Applications, 2025, 45(7): 2325-2332. |
| [12] | Xiaoqiang ZHAO, Yongyong LIU, Yongyong HUI, Kai LIU. Batch process quality prediction model using improved time-domain convolutional network with multi-head self-attention mechanism [J]. Journal of Computer Applications, 2025, 45(7): 2245-2252. |
| [13] | Huibin WANG, Zhan’ao HU, Jie HU, Yuanwei XU, Bo WEN. Time series forecasting model based on segmented attention mechanism [J]. Journal of Computer Applications, 2025, 45(7): 2262-2268. |
| [14] | Yihan WANG, Chong LU, Zhongyuan CHEN. Multimodal sentiment analysis model with cross-modal text information enhancement [J]. Journal of Computer Applications, 2025, 45(7): 2237-2244. |
| [15] | Chen LIANG, Yisen WANG, Qiang WEI, Jiang DU. Source code vulnerability detection method based on Transformer-GCN [J]. Journal of Computer Applications, 2025, 45(7): 2296-2303. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||