


Journal of Computer Applications ›› 2026, Vol. 46 ›› Issue (2): 406-415.DOI: 10.11772/j.issn.1001-9081.2025020174
• Artificial intelligence • Previous Articles
Zeyi GUO1, Fenglian LI1( ), Lichun XU2
), Lichun XU2
Received:2025-02-25
Revised:2025-04-07
Accepted:2025-04-11
Online:2025-04-24
Published:2026-02-10
Contact:
Fenglian LI
About author:GUO Zeyi, born in 1997, M. S. candidate. His research interests include symbolic regression, deep learning.Supported by:
郭泽一1, 李凤莲1(), 徐利春2
通讯作者:
李凤莲
作者简介:郭泽一(1997—),男,山西临汾人,硕士研究生,主要研究方向:符号回归、深度学习基金资助:CLC Number:
Zeyi GUO, Fenglian LI, Lichun XU. Double decision mechanism-based deep symbolic regression algorithm[J]. Journal of Computer Applications, 2026, 46(2): 406-415.
郭泽一, 李凤莲, 徐利春. 基于双重决策机制的深度符号回归算法[J]. 《计算机应用》唯一官方网站, 2026, 46(2): 406-415.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2025020174
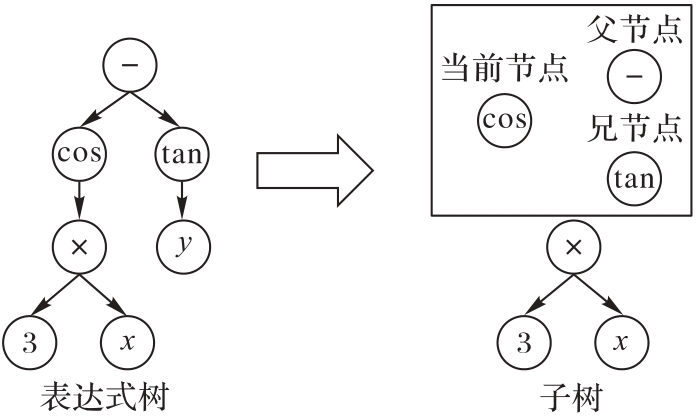
Fig. 1 Preorder traversal of expression tree
| 符号 | 定义 |
|---|---|
| RNN生成的基础概率分布 | |
| 双重决策机制得到的新的概率分布 | |
| 自反馈机制所用的权重因子 | |
| 复杂度评分运算公式 | |
| 通过 | |
| 通过 | |
| 衡量新旧策略差异的比值 | |
| RPPO算法中的裁剪损失 | |
| RPPO算法中的熵损失 | |
| 表达式树中的第i个节点 | |
| T | 表达式树的遍历长度 |
| 当前节点的父节点 | |
| 当前节点的兄节点 | |
| L | 令牌库,包含所使用运算符 |
| n | 样本数 |
| 学习率 |
Tab. 1 Symbols used in the paper and their related definitions
| 符号 | 定义 |
|---|---|
| RNN生成的基础概率分布 | |
| 双重决策机制得到的新的概率分布 | |
| 自反馈机制所用的权重因子 | |
| 复杂度评分运算公式 | |
| 通过 | |
| 通过 | |
| 衡量新旧策略差异的比值 | |
| RPPO算法中的裁剪损失 | |
| RPPO算法中的熵损失 | |
| 表达式树中的第i个节点 | |
| T | 表达式树的遍历长度 |
| 当前节点的父节点 | |
| 当前节点的兄节点 | |
| L | 令牌库,包含所使用运算符 |
| n | 样本数 |
| 学习率 |
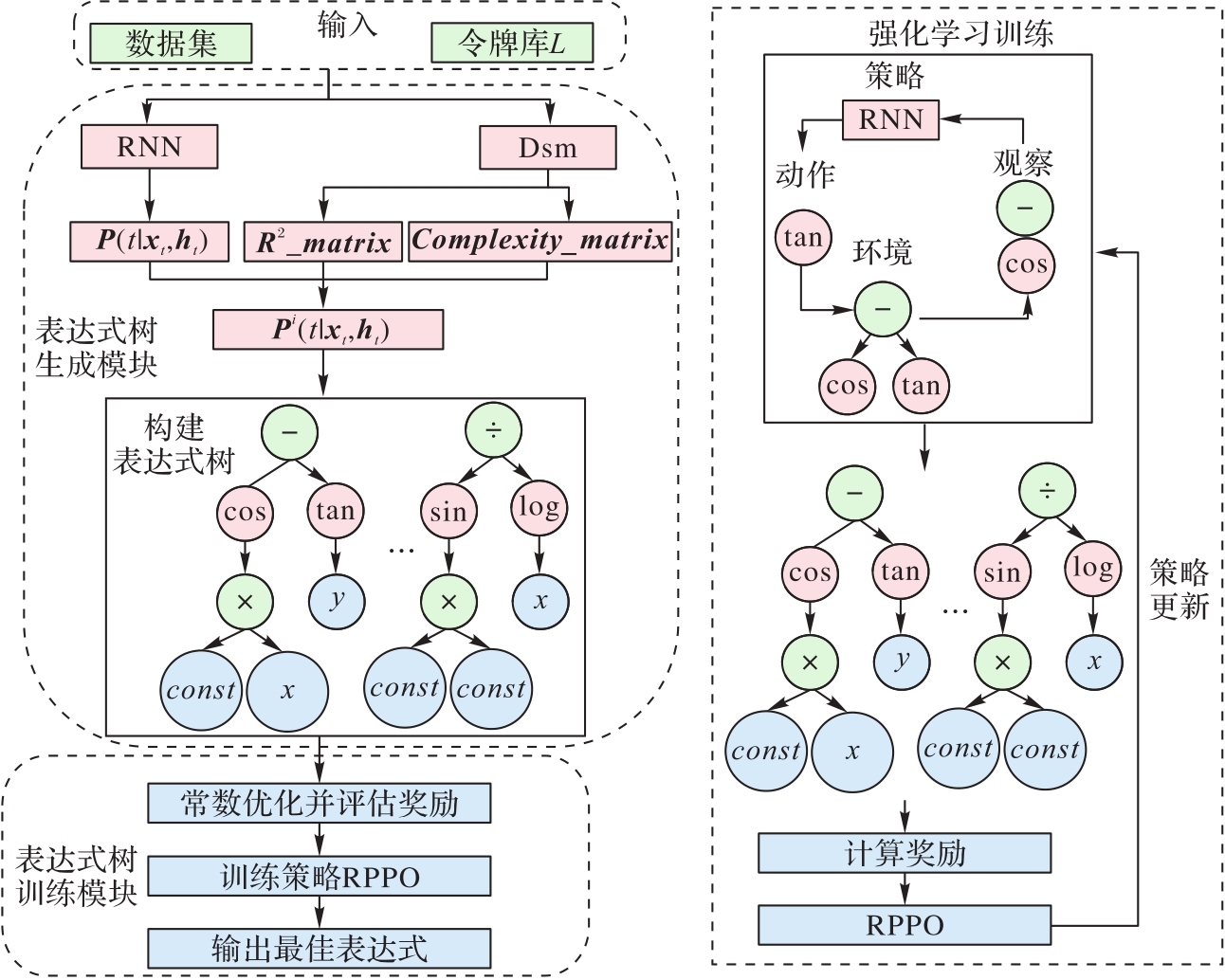
Fig. 2 Overall flow of proposed algorithm
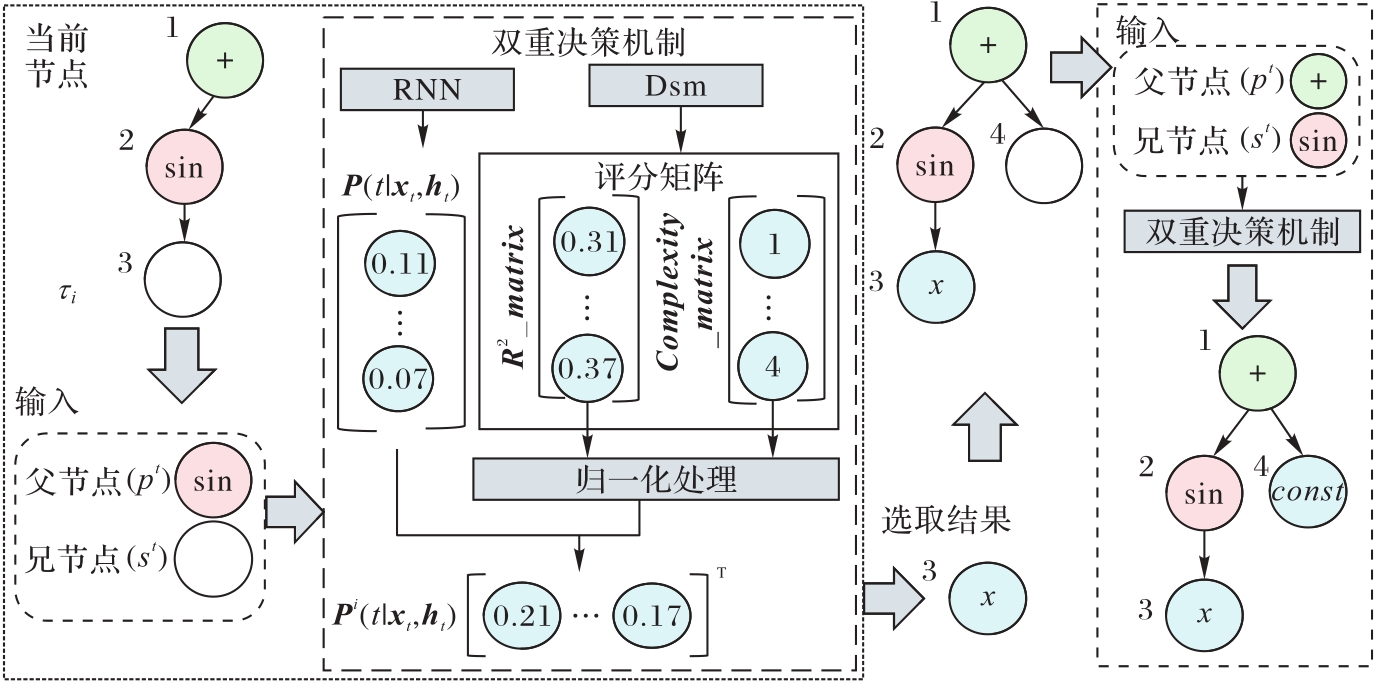
Fig. 3 Expression tree generation module
| 参数 | 参数值 |
|---|---|
| 批次大小 | 100 |
| 迭代次数 | 300 |
| 令牌库L | [+,-,×,÷,sin,cos,exp,log,**, sqrt] |
| 学习率 | 0.05 |
| 裁剪阈值 | 0.1 |
| 优化器 | Adam |
| 风险阈值 | 0.8 |
Tab. 2 DDSR algorithm’s parameter setting
| 参数 | 参数值 |
|---|---|
| 批次大小 | 100 |
| 迭代次数 | 300 |
| 令牌库L | [+,-,×,÷,sin,cos,exp,log,**, sqrt] |
| 学习率 | 0.05 |
| 裁剪阈值 | 0.1 |
| 优化器 | Adam |
| 风险阈值 | 0.8 |
| 数据集 | 样本数 | 变量数 | 是否平衡 |
|---|---|---|---|
| nikuradse_2 | 362 | 1 | 否 |
| 1027_ESL | 488 | 4 | 否 |
| 210_cloud | 108 | 5 | 是 |
| feynman_Ⅰ_6_2a | 100 000 | 1 | 是 |
| strogatz_glider1 | 400 | 2 | 是 |
| 523_analcatdata_neavote | 100 | 2 | 否 |
| feynman_Ⅲ_12_43 | 100 000 | 2 | 是 |
| 519_vinnie | 380 | 2 | 否 |
| 厚度数据集 | 999 | 1 | 否 |
Tab. 3 Introduction of datasets
| 数据集 | 样本数 | 变量数 | 是否平衡 |
|---|---|---|---|
| nikuradse_2 | 362 | 1 | 否 |
| 1027_ESL | 488 | 4 | 否 |
| 210_cloud | 108 | 5 | 是 |
| feynman_Ⅰ_6_2a | 100 000 | 1 | 是 |
| strogatz_glider1 | 400 | 2 | 是 |
| 523_analcatdata_neavote | 100 | 2 | 否 |
| feynman_Ⅲ_12_43 | 100 000 | 2 | 是 |
| 519_vinnie | 380 | 2 | 否 |
| 厚度数据集 | 999 | 1 | 否 |
| 数据集 | DSR | GP | FFX | GGGP-STGP | qlattic |
|---|---|---|---|---|---|
| nikuradse_2 | 0.583±0.003 | 0.707±0.003 | 0.971±0.002 | 0.268±0.003 | 0.978±0.001 |
| 1027_ESL | 0.679±0.004 | 0.578±0.004 | 0.812±0.002 | 0.802±0.003 | 0.754±0.002 |
| 210_cloud | 0.946±0.002 | 0.946±0.002 | 0.119±0.005 | 0.948±0.002 | 0.887±0.003 |
| feynman_Ⅰ_6_2a | 0.966±0.001 | 0.975±0.001 | 0.998±0.001 | 0.943±0.002 | 0.999±0.001 |
| strogatz_glider1 | 0.766±0.003 | 0.976±0.001 | 0.897±0.002 | 0.124±0.005 | 0.886±0.003 |
| 523_analcatdata_neavote | 0.955±0.002 | 0.950±0.003 | 0.943±0.003 | 0.944±0.002 | 0.946±0.002 |
| feynman_Ⅲ_12_43 | 0.945±0.001 | 0.952±0.001 | 0.998±0.001 | 0.982±0.002 | 0.998±0.001 |
| 519_vinnie | 0.720±0.003 | 0.721±0.003 | 0.643±0.003 | 0.727±0.003 | 0.711±0.003 |
| 厚度数据集 | 0.643±0.004 | 0.708±0.002 | 0.814±0.002 | 0.514±0.004 | 0.892±0.002 |
| 数据集 | NSGA-DCGP | BSR | PySR | RILS-ROLS | DDSR |
| nikuradse_2 | 0.332±0.003 | 0.409±0.003 | 0.941±0.001 | 0.978±0.001 | 0.979±0.001 |
| 1027_ESL | 0.679±0.003 | 0.799±0.002 | 0.810±0.002 | 0.831±0.002 | 0.828±0.002 |
| 210_cloud | 0.946±0.002 | 0.836±0.003 | 0.946±0.002 | 0.891±0.002 | 0.950±0.002 |
| feynman_Ⅰ_6_2a | 0.964±0.001 | 0.961±0.001 | 0.999±0.001 | 0.999±0.001 | 0.999±0.001 |
| strogatz_glider1 | 0.762±0.003 | 0.129±0.005 | 0.999±0.001 | 0.999±0.001 | 0.956±0.002 |
| 523_analcatdata_neavote | 0.919±0.003 | 0.948±0.002 | 0.936±0.003 | 0.946±0.002 | 0.956±0.002 |
| feynman_Ⅲ_12_43 | 0.998±0.001 | 0.976±0.001 | 0.999±0.001 | 0.999±0.001 | 0.999±0.001 |
| 519_vinnie | 0.706±0.003 | — | 0.706±0.003 | 0.709±0.003 | 0.734±0.003 |
| 厚度数据集 | 0.712±0.003 | — | 0.864±0.002 | 0.896±0.001 | 0.845±0.002 |
Tab. 4 R2 comparison of DDSR algorithm and benchmark algorithms on experimental datasets
| 数据集 | DSR | GP | FFX | GGGP-STGP | qlattic |
|---|---|---|---|---|---|
| nikuradse_2 | 0.583±0.003 | 0.707±0.003 | 0.971±0.002 | 0.268±0.003 | 0.978±0.001 |
| 1027_ESL | 0.679±0.004 | 0.578±0.004 | 0.812±0.002 | 0.802±0.003 | 0.754±0.002 |
| 210_cloud | 0.946±0.002 | 0.946±0.002 | 0.119±0.005 | 0.948±0.002 | 0.887±0.003 |
| feynman_Ⅰ_6_2a | 0.966±0.001 | 0.975±0.001 | 0.998±0.001 | 0.943±0.002 | 0.999±0.001 |
| strogatz_glider1 | 0.766±0.003 | 0.976±0.001 | 0.897±0.002 | 0.124±0.005 | 0.886±0.003 |
| 523_analcatdata_neavote | 0.955±0.002 | 0.950±0.003 | 0.943±0.003 | 0.944±0.002 | 0.946±0.002 |
| feynman_Ⅲ_12_43 | 0.945±0.001 | 0.952±0.001 | 0.998±0.001 | 0.982±0.002 | 0.998±0.001 |
| 519_vinnie | 0.720±0.003 | 0.721±0.003 | 0.643±0.003 | 0.727±0.003 | 0.711±0.003 |
| 厚度数据集 | 0.643±0.004 | 0.708±0.002 | 0.814±0.002 | 0.514±0.004 | 0.892±0.002 |
| 数据集 | NSGA-DCGP | BSR | PySR | RILS-ROLS | DDSR |
| nikuradse_2 | 0.332±0.003 | 0.409±0.003 | 0.941±0.001 | 0.978±0.001 | 0.979±0.001 |
| 1027_ESL | 0.679±0.003 | 0.799±0.002 | 0.810±0.002 | 0.831±0.002 | 0.828±0.002 |
| 210_cloud | 0.946±0.002 | 0.836±0.003 | 0.946±0.002 | 0.891±0.002 | 0.950±0.002 |
| feynman_Ⅰ_6_2a | 0.964±0.001 | 0.961±0.001 | 0.999±0.001 | 0.999±0.001 | 0.999±0.001 |
| strogatz_glider1 | 0.762±0.003 | 0.129±0.005 | 0.999±0.001 | 0.999±0.001 | 0.956±0.002 |
| 523_analcatdata_neavote | 0.919±0.003 | 0.948±0.002 | 0.936±0.003 | 0.946±0.002 | 0.956±0.002 |
| feynman_Ⅲ_12_43 | 0.998±0.001 | 0.976±0.001 | 0.999±0.001 | 0.999±0.001 | 0.999±0.001 |
| 519_vinnie | 0.706±0.003 | — | 0.706±0.003 | 0.709±0.003 | 0.734±0.003 |
| 厚度数据集 | 0.712±0.003 | — | 0.864±0.002 | 0.896±0.001 | 0.845±0.002 |
| 数据集 | DSR | GP | FFX | GGGP-STGP | qlattic |
|---|---|---|---|---|---|
| nikuradse_2 | 0.161±0.005 | 0.135±0.004 | 0.042±0.002 | 0.213±0.005 | 0.036±0.002 |
| 1027_ESL | 0.709±0.005 | 0.814±0.005 | 0.542±0.003 | 0.557±0.003 | 0.620±0.004 |
| 210_cloud | 0.287±0.003 | 0.287±0.003 | 1.170±0.005 | 0.283±0.003 | 0.417±0.004 |
| feynman_Ⅰ_6_2a | 0.012±0.002 | 0.011±0.001 | 0.002±0.001 | 0.016±0.002 | 0.001±0.001 |
| strogatz_glider1 | 0.385±0.004 | 0.124±0.002 | 0.255±0.003 | 0.746±0.005 | 0.268±0.004 |
| 523_analcatdata_neavote | 0.749±0.005 | 0.799±0.005 | 0.844±0.005 | 0.834±0.005 | 0.824±0.005 |
| feynman_Ⅲ_12_43 | 0.190±0.003 | 0.178±0.003 | 0.036±0.002 | 0.109±0.003 | 0.002±0.001 |
| 519_vinnie | 1.599±0.005 | 1.598±0.005 | 1.808±0.005 | 1.579±0.005 | 1.626±0.005 |
| 厚度数据集 | 0.592±0.004 | 0.536±0.003 | 0.451±0.002 | 0.691±0.004 | 0.325±0.002 |
| 数据集 | NSGA-DCGP | BSR | PySR | RILS-ROLS | DDSR |
| nikuradse_2 | 0.204±0.004 | 0.191±0.004 | 0.060±0.003 | 0.036±0.002 | 0.035±0.002 |
| 1027_ESL | 0.709±0.005 | 0.560±0.003 | 0.546±0.003 | 0.514±0.002 | 0.518±0.002 |
| 210_cloud | 0.287±0.003 | 0.504±0.004 | 0.287±0.003 | 0.411±0.003 | 0.277±0.002 |
| feynman_Ⅰ_6_2a | 0.013±0.001 | 0.013±0.001 | 0.001±0.001 | 0.001±0.001 | 0.001±0.001 |
| strogatz_glider1 | 0.388±0.004 | 0.743±0.005 | 0.001±0.001 | 0.001±0.001 | 0.162±0.003 |
| 523_analcatdata_neavote | 1.010±0.005 | 0.807±0.005 | 0.898±0.005 | 0.826±0.005 | 0.737±0.004 |
| feynman_Ⅲ_12_43 | 0.032±0.002 | 0.125±0.002 | 0.001±0.001 | 0.001±0.001 | 0.001±0.001 |
| 519_vinnie | 1.641±0.005 | — | 1.641±0.005 | 1.633±0.005 | 1.546±0.005 |
| 厚度数据集 | 0.531±0.003 | — | 0.364±0.002 | 0.319±0.002 | 0.391±0.003 |
Tab. 5 RMSE comparison of DDSR algorithm and benchmark algorithms on experimental datasets
| 数据集 | DSR | GP | FFX | GGGP-STGP | qlattic |
|---|---|---|---|---|---|
| nikuradse_2 | 0.161±0.005 | 0.135±0.004 | 0.042±0.002 | 0.213±0.005 | 0.036±0.002 |
| 1027_ESL | 0.709±0.005 | 0.814±0.005 | 0.542±0.003 | 0.557±0.003 | 0.620±0.004 |
| 210_cloud | 0.287±0.003 | 0.287±0.003 | 1.170±0.005 | 0.283±0.003 | 0.417±0.004 |
| feynman_Ⅰ_6_2a | 0.012±0.002 | 0.011±0.001 | 0.002±0.001 | 0.016±0.002 | 0.001±0.001 |
| strogatz_glider1 | 0.385±0.004 | 0.124±0.002 | 0.255±0.003 | 0.746±0.005 | 0.268±0.004 |
| 523_analcatdata_neavote | 0.749±0.005 | 0.799±0.005 | 0.844±0.005 | 0.834±0.005 | 0.824±0.005 |
| feynman_Ⅲ_12_43 | 0.190±0.003 | 0.178±0.003 | 0.036±0.002 | 0.109±0.003 | 0.002±0.001 |
| 519_vinnie | 1.599±0.005 | 1.598±0.005 | 1.808±0.005 | 1.579±0.005 | 1.626±0.005 |
| 厚度数据集 | 0.592±0.004 | 0.536±0.003 | 0.451±0.002 | 0.691±0.004 | 0.325±0.002 |
| 数据集 | NSGA-DCGP | BSR | PySR | RILS-ROLS | DDSR |
| nikuradse_2 | 0.204±0.004 | 0.191±0.004 | 0.060±0.003 | 0.036±0.002 | 0.035±0.002 |
| 1027_ESL | 0.709±0.005 | 0.560±0.003 | 0.546±0.003 | 0.514±0.002 | 0.518±0.002 |
| 210_cloud | 0.287±0.003 | 0.504±0.004 | 0.287±0.003 | 0.411±0.003 | 0.277±0.002 |
| feynman_Ⅰ_6_2a | 0.013±0.001 | 0.013±0.001 | 0.001±0.001 | 0.001±0.001 | 0.001±0.001 |
| strogatz_glider1 | 0.388±0.004 | 0.743±0.005 | 0.001±0.001 | 0.001±0.001 | 0.162±0.003 |
| 523_analcatdata_neavote | 1.010±0.005 | 0.807±0.005 | 0.898±0.005 | 0.826±0.005 | 0.737±0.004 |
| feynman_Ⅲ_12_43 | 0.032±0.002 | 0.125±0.002 | 0.001±0.001 | 0.001±0.001 | 0.001±0.001 |
| 519_vinnie | 1.641±0.005 | — | 1.641±0.005 | 1.633±0.005 | 1.546±0.005 |
| 厚度数据集 | 0.531±0.003 | — | 0.364±0.002 | 0.319±0.002 | 0.391±0.003 |
| 基准测试名称 | 相关公式 | 数据样本数 | 所用标识符 |
|---|---|---|---|
| Nguyen-1 | 520 | ||
| Nguyen-2 | 520 | ||
| Nguyen-3 | 520 | ||
| Nguyen-4 | 520 | ||
| Nguyen-5 | 520 | ||
| Nguyen-6 | 520 | ||
| Nguyen-7 | 520 | ||
| Nguyen-8 | 520 | ||
| Nguyen-9 | 1 020 | ||
| Nguyen-10 | 1 020 | ||
| Nguyen-11 | 1 020 | ||
| Nguyen-12 | 1 020 |
Tab. 6 Nguyen symbolic regression’s benchmark test suite
| 基准测试名称 | 相关公式 | 数据样本数 | 所用标识符 |
|---|---|---|---|
| Nguyen-1 | 520 | ||
| Nguyen-2 | 520 | ||
| Nguyen-3 | 520 | ||
| Nguyen-4 | 520 | ||
| Nguyen-5 | 520 | ||
| Nguyen-6 | 520 | ||
| Nguyen-7 | 520 | ||
| Nguyen-8 | 520 | ||
| Nguyen-9 | 1 020 | ||
| Nguyen-10 | 1 020 | ||
| Nguyen-11 | 1 020 | ||
| Nguyen-12 | 1 020 |
| 基准测试 | DSR | GP | NSGA-DCGP | PySR | DDSR |
|---|---|---|---|---|---|
| 平均恢复率 | 61.0 | 29.7 | 21.8 | 67.5 | 73.0 |
| Nguyen-1 | 100 | 100 | 33 | 100 | 100 |
| Nguyen-2 | 100 | 100 | 10 | 100 | 100 |
| Nguyen-3 | 99 | 0 | 0 | 93 | 100 |
| Nguyen-4 | 55 | 0 | 0 | 37 | 86 |
| Nguyen-5 | 1 | 0 | 7 | 13 | 1 |
| Nguyen-6 | 71 | 0 | 4 | 100 | 100 |
| Nguyen-7 | 43 | 0 | 0 | 0 | 56 |
| Nguyen-8 | 95 | 100 | 81 | 100 | 100 |
| Nguyen-9 | 43 | 0 | 27 | 100 | 100 |
| Nguyen-10 | 29 | 56 | 16 | 80 | 33 |
| Nguyen-11 | 96 | 0 | 84 | 87 | 100 |
| Nguyen-12 | 0 | 0 | 0 | 0 | 0 |
Tab. 7 Benchmark test suite recovery rates
| 基准测试 | DSR | GP | NSGA-DCGP | PySR | DDSR |
|---|---|---|---|---|---|
| 平均恢复率 | 61.0 | 29.7 | 21.8 | 67.5 | 73.0 |
| Nguyen-1 | 100 | 100 | 33 | 100 | 100 |
| Nguyen-2 | 100 | 100 | 10 | 100 | 100 |
| Nguyen-3 | 99 | 0 | 0 | 93 | 100 |
| Nguyen-4 | 55 | 0 | 0 | 37 | 86 |
| Nguyen-5 | 1 | 0 | 7 | 13 | 1 |
| Nguyen-6 | 71 | 0 | 4 | 100 | 100 |
| Nguyen-7 | 43 | 0 | 0 | 0 | 56 |
| Nguyen-8 | 95 | 100 | 81 | 100 | 100 |
| Nguyen-9 | 43 | 0 | 27 | 100 | 100 |
| Nguyen-10 | 29 | 56 | 16 | 80 | 33 |
| Nguyen-11 | 96 | 0 | 84 | 87 | 100 |
| Nguyen-12 | 0 | 0 | 0 | 0 | 0 |
| 数据集 | DSR | DSR-D | DSR-R | DDSR |
|---|---|---|---|---|
| nikuradse_2 | 0.683 | 0.736 | 0.903 | 0.979 |
| 1027_ESL | 0.679 | 0.695 | 0.685 | 0.828 |
| 210_cloud | 0.946 | 0.936 | 0.950 | 0.950 |
| feynman_Ⅰ_6_2a | 0.966 | 0.974 | 0.991 | 0.999 |
| strogatz_glider1 | 0.766 | 0.851 | 0.842 | 0.956 |
| 523_analcatdata_neavote | 0.955 | 0.940 | 0.940 | 0.956 |
| feynman_Ⅲ_12_43 | 0.945 | 0.948 | 0.999 | 0.999 |
| 519_vinnie | 0.720 | 0.736 | 0.723 | 0.734 |
| 厚度数据集 | 0.643 | 0.738 | 0.751 | 0.845 |
Tab. 8 R2 results of ablation experiments
| 数据集 | DSR | DSR-D | DSR-R | DDSR |
|---|---|---|---|---|
| nikuradse_2 | 0.683 | 0.736 | 0.903 | 0.979 |
| 1027_ESL | 0.679 | 0.695 | 0.685 | 0.828 |
| 210_cloud | 0.946 | 0.936 | 0.950 | 0.950 |
| feynman_Ⅰ_6_2a | 0.966 | 0.974 | 0.991 | 0.999 |
| strogatz_glider1 | 0.766 | 0.851 | 0.842 | 0.956 |
| 523_analcatdata_neavote | 0.955 | 0.940 | 0.940 | 0.956 |
| feynman_Ⅲ_12_43 | 0.945 | 0.948 | 0.999 | 0.999 |
| 519_vinnie | 0.720 | 0.736 | 0.723 | 0.734 |
| 厚度数据集 | 0.643 | 0.738 | 0.751 | 0.845 |
| 数据集 | DSR | DSR-D | DSR-R | DDSR |
|---|---|---|---|---|
| nikuradse_2 | 0.141 | 0.128 | 0.078 | 0.035 |
| 1027_ESL | 0.709 | 0.692 | 0.704 | 0.518 |
| 210_cloud | 0.287 | 0.315 | 0.279 | 0.277 |
| feynman_Ⅰ_6_2a | 0.012 | 0.011 | 0.007 | 0.001 |
| strogatz_glider1 | 0.385 | 0.308 | 0.317 | 0.162 |
| 523_analcatdata_neavote | 0.749 | 0.867 | 0.867 | 0.737 |
| feynman_Ⅲ_12_43 | 0.190 | 0.185 | 0.001 | 0.001 |
| 519_vinnie | 1.599 | 1.544 | 1.592 | 1.546 |
| 厚度数据集 | 0.592 | 0.508 | 0.495 | 0.391 |
Tab. 9 RMSE results of ablation experiments
| 数据集 | DSR | DSR-D | DSR-R | DDSR |
|---|---|---|---|---|
| nikuradse_2 | 0.141 | 0.128 | 0.078 | 0.035 |
| 1027_ESL | 0.709 | 0.692 | 0.704 | 0.518 |
| 210_cloud | 0.287 | 0.315 | 0.279 | 0.277 |
| feynman_Ⅰ_6_2a | 0.012 | 0.011 | 0.007 | 0.001 |
| strogatz_glider1 | 0.385 | 0.308 | 0.317 | 0.162 |
| 523_analcatdata_neavote | 0.749 | 0.867 | 0.867 | 0.737 |
| feynman_Ⅲ_12_43 | 0.190 | 0.185 | 0.001 | 0.001 |
| 519_vinnie | 1.599 | 1.544 | 1.592 | 1.546 |
| 厚度数据集 | 0.592 | 0.508 | 0.495 | 0.391 |
| 数据集 | DSR | DSR-D | DSR-R | DDSR |
|---|---|---|---|---|
| nikuradse_2 | 32 | 4 096 | ∞ | 1 024 |
| 1027_ESL | 16 | 4 | 20 | 42 |
| 210_cloud | 16 | 10 | 4 | 54 |
| feynman_Ⅰ_6_2a | ∞ | 4 | ∞ | 9 |
| strogatz_glider1 | ∞ | 9 | 32 | 12 |
| 523_analcatdata_neavote | ∞ | 136 | 4 096 | 7 |
| feynman_Ⅲ_12_43 | 65 536 | 56 | ∞ | 4 |
| 519_vinnie | 65 536 | 22 | ∞ | 34 |
| 厚度数据集 | ∞ | 5 | ∞ | 5 |
Tab. 10 Analysis results of ablation experiments’ complexity
| 数据集 | DSR | DSR-D | DSR-R | DDSR |
|---|---|---|---|---|
| nikuradse_2 | 32 | 4 096 | ∞ | 1 024 |
| 1027_ESL | 16 | 4 | 20 | 42 |
| 210_cloud | 16 | 10 | 4 | 54 |
| feynman_Ⅰ_6_2a | ∞ | 4 | ∞ | 9 |
| strogatz_glider1 | ∞ | 9 | 32 | 12 |
| 523_analcatdata_neavote | ∞ | 136 | 4 096 | 7 |
| feynman_Ⅲ_12_43 | 65 536 | 56 | ∞ | 4 |
| 519_vinnie | 65 536 | 22 | ∞ | 34 |
| 厚度数据集 | ∞ | 5 | ∞ | 5 |
| 算法 | DDSR(p值) | DDSR(h值) |
|---|---|---|
| DSR | 0.003 906 25 | 1 |
| GP | 0.019 531 25 | 1 |
| FFX | 0.003 906 25 | 1 |
| GGGP-STGP | 0.003 906 25 | 1 |
| qlattic | 0.035 691 90 | 1 |
| NSGA-DCGP | 0.003 906 25 | 1 |
| BSR | 0.003 906 25 | 1 |
| PySR | 0.398 024 72 | 0 |
| RILS-ROLS | 0.735 316 69 | 0 |
Tab. 11 Wilcoxon signed-rank test
| 算法 | DDSR(p值) | DDSR(h值) |
|---|---|---|
| DSR | 0.003 906 25 | 1 |
| GP | 0.019 531 25 | 1 |
| FFX | 0.003 906 25 | 1 |
| GGGP-STGP | 0.003 906 25 | 1 |
| qlattic | 0.035 691 90 | 1 |
| NSGA-DCGP | 0.003 906 25 | 1 |
| BSR | 0.003 906 25 | 1 |
| PySR | 0.398 024 72 | 0 |
| RILS-ROLS | 0.735 316 69 | 0 |
| [1] | MAKKE N, CHAWLA S. Interpretable scientific discovery with symbolic regression: a review[J]. Artificial Intelligence Review, 2024, 57: No.2. |
| [2] | WITTENBERG D, ROTHLAUF F, GAGNÉ C. Denoising autoencoder genetic programming: strategies to control exploration and exploitation in search[J]. Genetic Programming and Evolvable Machines, 2023, 24: No.17. |
| [3] | 许鹏程,何磊,李川,等. 基于Transformer的深度符号回归方法[J]. 计算机应用, 2025, 45(4): 1455-1463. |
| XU P C, HE L, LI C, et al. Deep symbolic regression method based on Transformer[J]. Journal of Computer Applications, 2025, 45(4): 1455-1463. | |
| [4] | LA CAVA W, ORZECHOWSKI P, BURLACU B, et al. Contemporary symbolic regression methods and their relative performance[EB/OL]. [2025-04-03].. |
| [5] | 刘博弈,王海渝,龚严,等. 基于天气预报和符号回归算法的参考作物腾发量预测研究[J]. 中国农村水利水电, 2018(8): 22-26. |
| LIU B Y, WANG H Y, GONG Y, et al. Predicting daily reference evapotranspiration based on weather forecast data using symbolic regression method[J]. China Rural Water and Hydropower, 2018(8): 22-26. | |
| [6] | ANGELIS D, SOFOS F, KARAKASIDIS T E. Artificial intelligence in physical sciences: symbolic regression trends and perspectives[J]. Archives of Computational Methods in Engineering, 2023, 30(6): 3845-3865. |
| [7] | AGHBASHLO M, PENG W, TABATABAEI M, et al. Machine learning technology in biodiesel research: a review[J]. Progress in Energy and Combustion Science, 2021, 85: No.100904. |
| [8] | PETERSEN B K, LANDAJUELA M, MUNDHENK T N, et al. Deep symbolic regression: recovering mathematical expressions from data via risk-seeking policy gradients[EB/OL]. [2025-04-03].. |
| [9] | 谢树钦,陈梓天,徐超,等. 针对不可微多阶段算法的环境升级式强化学习方法[J]. 重庆邮电大学学报(自然科学版), 2020, 32(5): 857-866. |
| XIE S Q, CHEN Z T, XU C, et al. Environment upgrade reinforcement learning for non-differentiable multi-stage pipelines[J]. Journal of Chongqing University of Posts and Telecommunications (Natural Science Edition), 2020, 32(5): 857-866. | |
| [10] | KIM S, LU P Y, MUKHERJEE S, et al. Integration of neural network-based symbolic regression in deep learning for scientific discovery[J]. IEEE Transactions on Neural Networks and Learning Systems, 2021, 32(9): 4166-4177. |
| [11] | BIGGIO L, BENDINELLI T, NEITZ A, et al. Neural symbolic regression that scales[C]// Proceedings of the 38th International Conference on Machine Learning. New York: JMLR.org, 2021: 936-945. |
| [12] | CRANMER M, SANCHEZ-GONZALEZ A, BATTAGLIA P, et al. Discovering symbolic models from deep learning with inductive biases[C]// Proceedings of the 34th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2020: 17429-17442. |
| [13] | ABOLAFIA D A, NOROUZI M, SHEN J, et al. Neural program synthesis with priority queue training[EB/OL]. [2025-04-03].. |
| [14] | BASTIANI Z, KIRBY R M, HOCHHALTER J, et al. Complexity-aware deep symbolic regression with robust risk-seeking policy gradients[EB/OL]. [2025-04-03].. |
| [15] | LANDAJUELA M, PETERSEN B K, KIM S, et al. Discovering symbolic policies with deep reinforcement learning[C]// Proceedings of the 38th International Conference on Machine Learning. New York: JMLR.org, 2021: 5979-5989. |
| [16] | SCHULMAN J, WOLSKI F, DHARIWAL P, et al. Proximal policy optimization algorithms[EB/OL]. [2025-04-03].. |
| [17] | QU Z, WEI X M, CHEN S Q. An algorithm of image mosaic based on binary tree and eliminating distortion error[J]. PLoS ONE, 2019, 14(1): No.e0210354. |
| [18] | KOMMENDA M, BEHAM A, AFFENZELLER M, et al. Complexity measures for multi-objective symbolic regression[C]// Proceedings of the 2015 International Conference on Computer Aided Systems Theory, LNCS 9520. Cham: Springer, 2015: 409-416. |
| [19] | ROMANO J D, LE T T, LA CAVA W, et al. PMLB v1.0: an open-source dataset collection for benchmarking machine learning methods[J]. Bioinformatics, 2022, 38(3): 878-880. |
| [20] | ZENG P, SONG X, LENSEN A, et al. Differentiable genetic programming for high-dimensional symbolic regression[EB/OL]. [2025-04-03].. |
| [21] | VADDIREDDY H, SAN O. Equation discovery using fast function extraction: a deterministic symbolic regression approach[J]. Fluids, 2019, 4(2): No.111. |
| [22] | ESPADA G, INGELSE L, CANELAS P, et al. Data types as a more ergonomic frontend for grammar-guided genetic programming[C]// Proceedings of the 21st ACM SIGPLAN International Conference on Generative Programming: Concepts and Experiences. New York: ACM, 2022: 86-94. |
| [23] | WILSTRUP C, KASAK J. Symbolic regression outperforms other models for small data sets[EB/OL]. [2025-04-03].. |
| [24] | JIN Y, FU W, KANG J, et al. Bayesian symbolic regression[EB/OL]. [2025-04-03].. |
| [25] | CRANMER M. Interpretable machine learning for science with PySR and SymbolicRegression.jl[EB/OL]. [2025-04-03].. |
| [26] | KARTELJ A, DJUKANOVIĆ M. RILS-ROLS: robust symbolic regression via iterated local search and ordinary least squares[J]. Journal of Big Data, 2023, 10(1): No.71. |
| [27] | ELYASAF A, SIPPER M. Software review: the HeuristicLab framework[J]. Genetic Programming and Evolvable Machines, 2014, 15(2): 215-218. |
| [28] | MEURER A, SMITH C P, PAPROCKI M, et al. SymPy: symbolic computing in Python[J]. PeerJ Computer Science, 2017, 3: No.e103. |
| [1] | Haoqian JIANG, Dong ZHANG, Guanyu LI, Heng CHEN. SetaCRS: Conversational recommender system with structure-enhanced hierarchical task-oriented prompting strategy [J]. Journal of Computer Applications, 2026, 46(2): 368-377. |
| [2] | Xiaoyong BIAN, Peiyang YUAN, Qiren HU. Dual-coding space-frequency mixing method for infrared small target detection [J]. Journal of Computer Applications, 2026, 46(1): 252-259. |
| [3] | Zhihui ZAN, Yajing WANG, Ke LI, Zhixiang YANG, Guangyu YANG. Multi-feature fusion speech emotion recognition method based on SAA-CNN-BiLSTM network [J]. Journal of Computer Applications, 2026, 46(1): 69-76. |
| [4] | Hongjun ZHANG, Gaojun PAN, Hao YE, Yubin LU, Yiheng MIAO. Multi-source heterogeneous data analysis method combining deep learning and tensor decomposition [J]. Journal of Computer Applications, 2025, 45(9): 2838-2847. |
| [5] | Jin LI, Liqun LIU. SAR and visible image fusion based on residual Swin Transformer [J]. Journal of Computer Applications, 2025, 45(9): 2949-2956. |
| [6] | Bing YIN, Zhenhua LING, Yin LIN, Changfeng XI, Ying LIU. Emotion recognition method compatible with missing modal reasoning [J]. Journal of Computer Applications, 2025, 45(9): 2764-2772. |
| [7] | Weigang LI, Jiale SHAO, Zhiqiang TIAN. Point cloud classification and segmentation network based on dual attention mechanism and multi-scale fusion [J]. Journal of Computer Applications, 2025, 45(9): 3003-3010. |
| [8] | Zhixiong XU, Bo LI, Xiaoyong BIAN, Qiren HU. Adversarial sample embedded attention U-Net for 3D medical image segmentation [J]. Journal of Computer Applications, 2025, 45(9): 3011-3016. |
| [9] | Panfeng JING, Yudong LIANG, Chaowei LI, Junru GUO, Jinyu GUO. Semi-supervised image dehazing algorithm based on teacher-student learning [J]. Journal of Computer Applications, 2025, 45(9): 2975-2983. |
| [10] | Peng PENG, Ziting CAI, Wenling LIU, Caihua CHEN, Wei ZENG, Baolai HUANG. Speech emotion recognition method based on hybrid Siamese network with CNN and bidirectional GRU [J]. Journal of Computer Applications, 2025, 45(8): 2515-2521. |
| [11] | Shuo ZHANG, Guokai SUN, Yuan ZHUANG, Xiaoyu FENG, Jingzhi WANG. Dynamic detection method of eclipse attacks for blockchain node analysis [J]. Journal of Computer Applications, 2025, 45(8): 2428-2436. |
| [12] | Lina GE, Mingyu WANG, Lei TIAN. Review of research on efficiency of federated learning [J]. Journal of Computer Applications, 2025, 45(8): 2387-2398. |
| [13] | Yanhua LIAO, Yuanxia YAN, Wenlin PAN. Multi-target detection algorithm for traffic intersection images based on YOLOv9 [J]. Journal of Computer Applications, 2025, 45(8): 2555-2565. |
| [14] | Jinxian SUO, Liping ZHANG, Sheng YAN, Dongqi WANG, Yawen ZHANG. Review of interpretable deep knowledge tracing methods [J]. Journal of Computer Applications, 2025, 45(7): 2043-2055. |
| [15] | Zhenzhou WANG, Fangfang GUO, Jingfang SU, He SU, Jianchao WANG. Robustness optimization method of visual model for intelligent inspection [J]. Journal of Computer Applications, 2025, 45(7): 2361-2368. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||