


Journal of Computer Applications ›› 2026, Vol. 46 ›› Issue (1): 69-76.DOI: 10.11772/j.issn.1001-9081.2025010042
• Artificial intelligence • Previous Articles Next Articles
Zhihui ZAN1, Yajing WANG1( ), Ke LI1, Zhixiang YANG2, Guangyu YANG2
), Ke LI1, Zhixiang YANG2, Guangyu YANG2
Received:2025-01-13
Revised:2025-03-25
Accepted:2025-03-26
Online:2026-01-10
Published:2026-01-10
Contact:
Yajing WANG
About author:ZAN Zhihui, born in 2001, M. S. candidate. His research interests include speech emotion recognition.Supported by:
昝志辉1, 王雅静1(), 李珂1, 杨智翔2, 杨光宇2
通讯作者:
王雅静
作者简介:昝志辉(2001—),男,河北沧州人,硕士研究生,主要研究方向:语音情感识别基金资助:CLC Number:
Zhihui ZAN, Yajing WANG, Ke LI, Zhixiang YANG, Guangyu YANG. Multi-feature fusion speech emotion recognition method based on SAA-CNN-BiLSTM network[J]. Journal of Computer Applications, 2026, 46(1): 69-76.
昝志辉, 王雅静, 李珂, 杨智翔, 杨光宇. 基于SAA-CNN-BiLSTM网络的多特征融合语音情感识别方法[J]. 《计算机应用》唯一官方网站, 2026, 46(1): 69-76.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2025010042
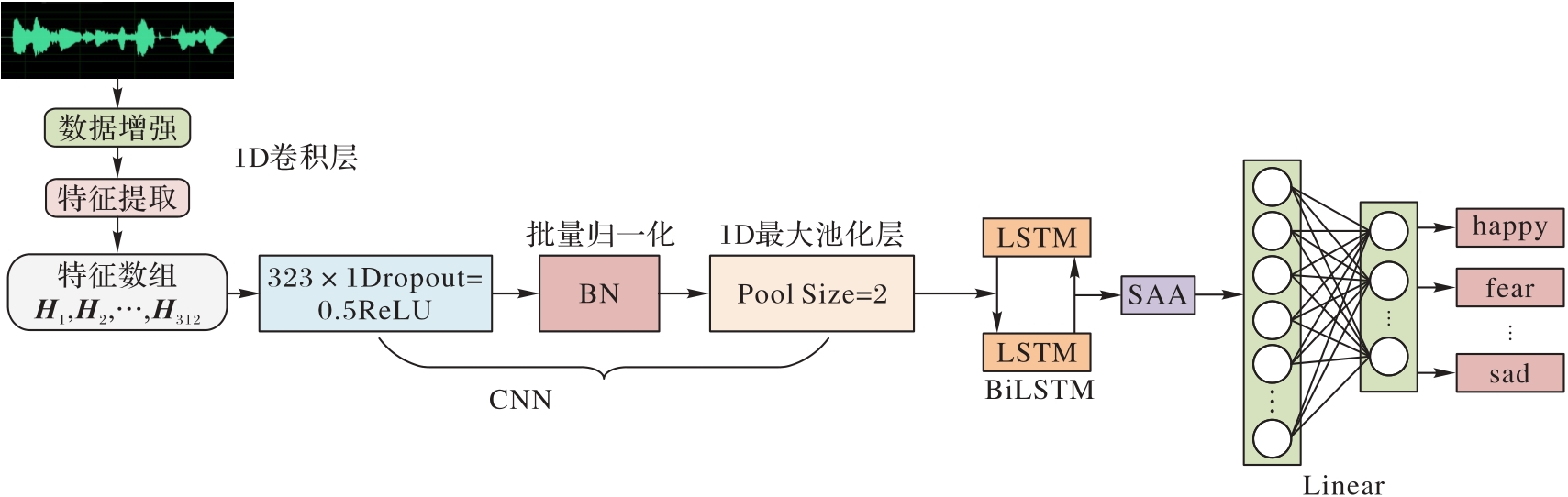
Fig. 1 Overall architecture of model
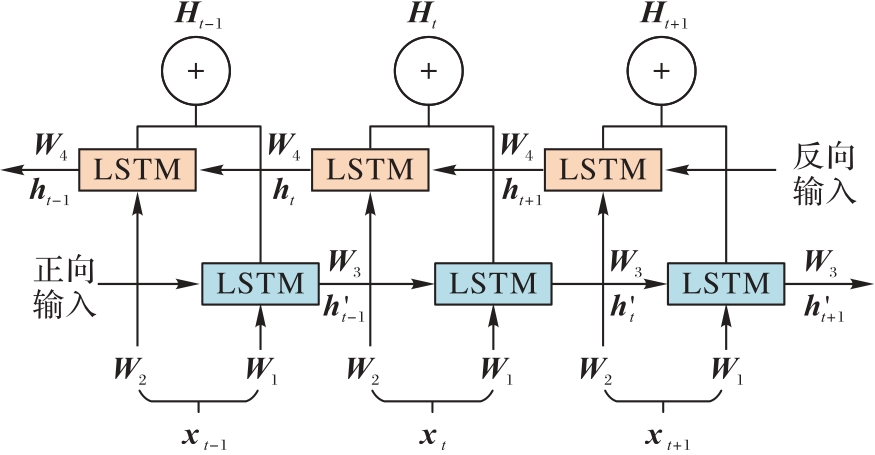
Fig. 2 Structure of BiLSTM

Fig. 3 Internal structure of CNN
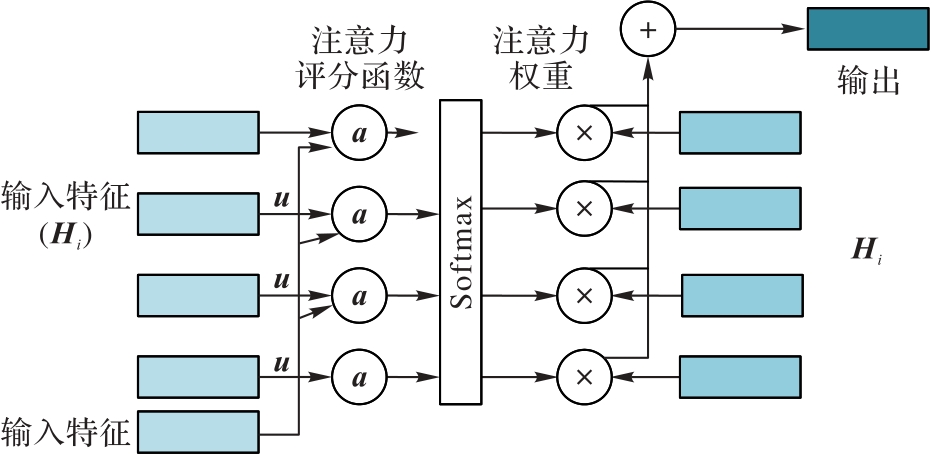
Fig. 4 Calculation process of attention weights
| 参数 | 值 |
|---|---|
| 噪声(noise)/dB | [ |
| 音量(volume)/dBFS | [-15, 15] |
| 音速(audio rate) | [0.9, 1.1] |
Tab. 1 Parameter settings of data augmenter
| 参数 | 值 |
|---|---|
| 噪声(noise)/dB | [ |
| 音量(volume)/dBFS | [-15, 15] |
| 音速(audio rate) | [0.9, 1.1] |
| 特征类型 | 具体特征 |
|---|---|
| 基频特征 | 音高极值、均值、标准差、调谐偏差 |
| 时域特征 | 过零率、振幅极值、均值、标准差 均方根能量极值、平均值、标准差 |
| 频域特征 | 梅尔频率倒谱系数极值、均值、标准差 梅尔频谱均值、色谱图均值、频谱对比度均值 频谱质心极值、均值、标准差 |
Tab. 2 Specific composition components of parameters of integrated features
| 特征类型 | 具体特征 |
|---|---|
| 基频特征 | 音高极值、均值、标准差、调谐偏差 |
| 时域特征 | 过零率、振幅极值、均值、标准差 均方根能量极值、平均值、标准差 |
| 频域特征 | 梅尔频率倒谱系数极值、均值、标准差 梅尔频谱均值、色谱图均值、频谱对比度均值 频谱质心极值、均值、标准差 |
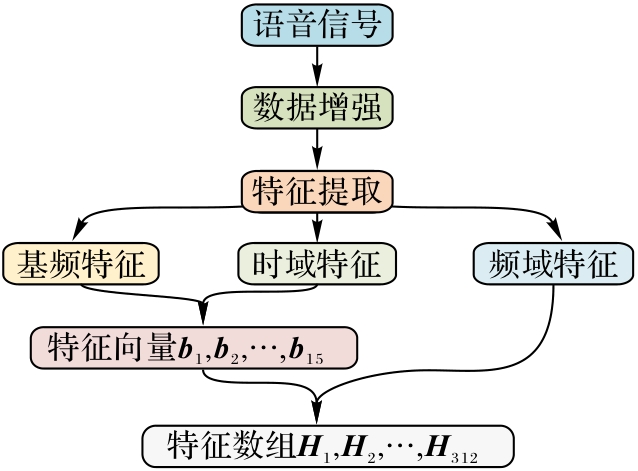
Fig. 5 Feature fusion flow
| 数据集 | 加权精度/% | ||
|---|---|---|---|
| p为0.0 | p为0.5 | p为1.0 | |
| EMO-DB | 80.78 | 87.02 | 78.36 |
| CASIA | 80.92 | 82.59 | 78.35 |
| SAVEE | 71.13 | 73.13 | 49.88 |
Tab. 3 Comparison of weighted precision on each dataset under different probabilities of using augmenters
| 数据集 | 加权精度/% | ||
|---|---|---|---|
| p为0.0 | p为0.5 | p为1.0 | |
| EMO-DB | 80.78 | 87.02 | 78.36 |
| CASIA | 80.92 | 82.59 | 78.35 |
| SAVEE | 71.13 | 73.13 | 49.88 |

Fig. 6 Comparison of loss decline under different probabilities of using augmenters
| 数据集 | 模型 | 加权精度/% |
|---|---|---|
| EMO-DB | CNN-BiLSTM[ | 70.24 |
| SDPA-CNN-BiLSTM | 80.35 | |
| MHA-CNN-BiLSTM | 59.95 | |
| TAA-CNN-BiLSTM | 76.91 | |
| SAA-CNN-BiLSTM | 87.02 | |
| CASIA | CNN-BiLSTM[ | 73.58 |
| SDPA-CNN-BiLSTM | 81.00 | |
| MHA-CNN-BiLSTM | 79.83 | |
| TAA-CNN-BiLSTM | 77.46 | |
| SAA-CNN-BiLSTM | 82.59 | |
| SAVEE | CNN-BiLSTM[ | 62.13 |
| SDPA-CNN-BiLSTM | 69.00 | |
| MHA-CNN-BiLSTM | 45.13 | |
| TAA-CNN-BiLSTM | 65.00 | |
| SAA-CNN-BiLSTM | 73.13 |
Tab. 4 Comparison of weighted precision of applications of different attention mechanisms on three datasets
| 数据集 | 模型 | 加权精度/% |
|---|---|---|
| EMO-DB | CNN-BiLSTM[ | 70.24 |
| SDPA-CNN-BiLSTM | 80.35 | |
| MHA-CNN-BiLSTM | 59.95 | |
| TAA-CNN-BiLSTM | 76.91 | |
| SAA-CNN-BiLSTM | 87.02 | |
| CASIA | CNN-BiLSTM[ | 73.58 |
| SDPA-CNN-BiLSTM | 81.00 | |
| MHA-CNN-BiLSTM | 79.83 | |
| TAA-CNN-BiLSTM | 77.46 | |
| SAA-CNN-BiLSTM | 82.59 | |
| SAVEE | CNN-BiLSTM[ | 62.13 |
| SDPA-CNN-BiLSTM | 69.00 | |
| MHA-CNN-BiLSTM | 45.13 | |
| TAA-CNN-BiLSTM | 65.00 | |
| SAA-CNN-BiLSTM | 73.13 |
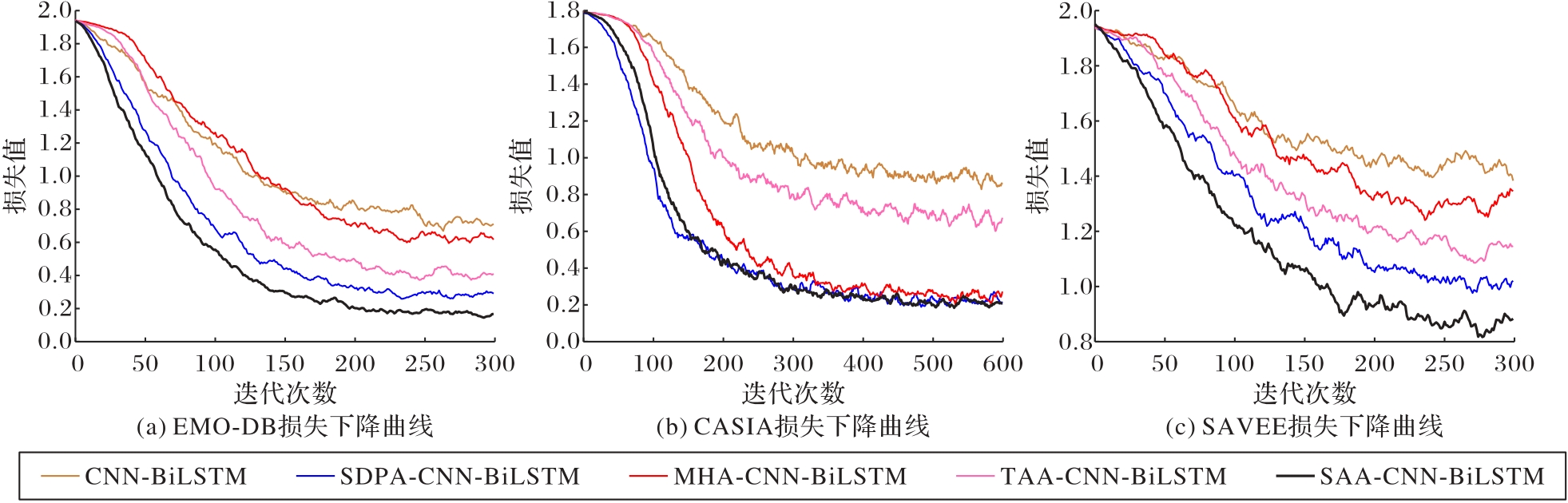
Fig. 7 Comparison of loss decline with different attention mechanisms
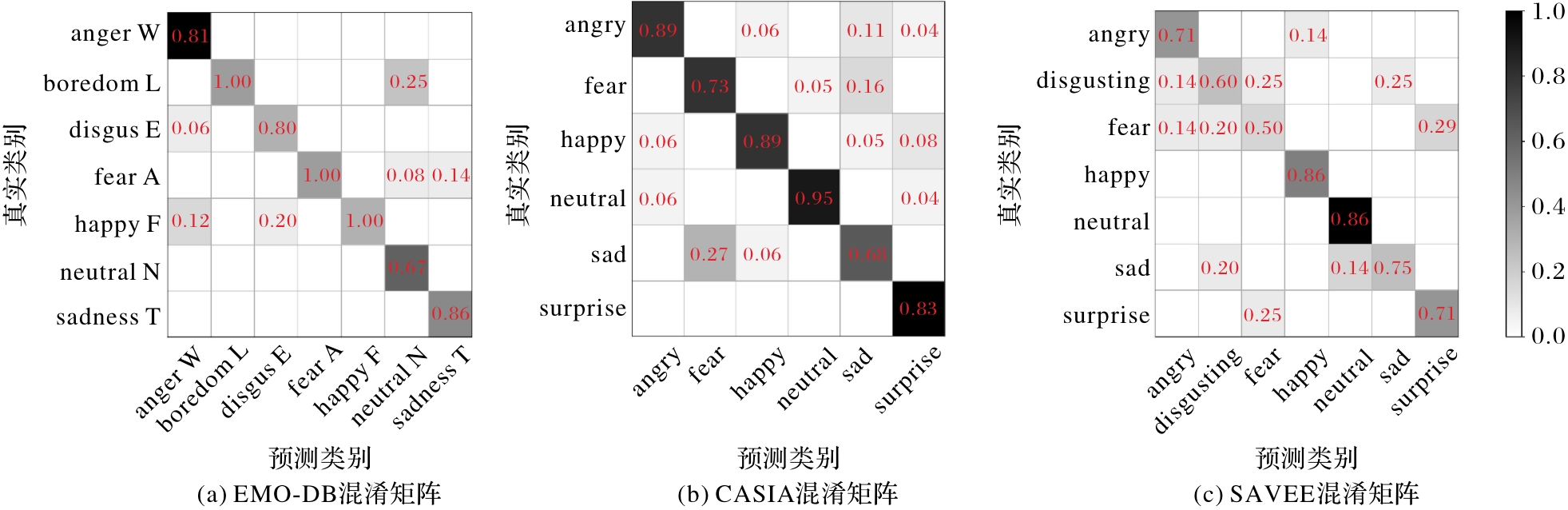
Fig. 8 Confusion matrices of model training on different datasets
| 数据集 | 方法 | 加权精度/% |
|---|---|---|
| EMO-DB | CNN-BiGRU[ | 84.08 |
| STFC-Attention[ | 85.95 | |
| 2-D CNN[ | 83.40 | |
| SAE-LS-CGAN[ | 86.42 | |
| IncConv[ | 86.50 | |
| PEW-BAR[ | 77.22 | |
| DN-ResNet11[ | 85.59 | |
| ATCN-GRU[ | 86.26 | |
| 本文方法 | 87.02 | |
| CASIA | Alexnet-CNN-LSTM[ | 72.83 |
| NHPC-BiLSTM[ | 79.67 | |
| DCRNN[ | 59.50 | |
| Attention-BiGRU[ | 73.33 | |
| 本文方法 | 82.59 | |
| SAVEE | NHPC-BiLSTM[ | 56.50 |
| AHPCL[ | 64.06 | |
| CNN[ | 65.83 | |
| DCNN[ | 67.00 | |
| MWA-CNN[ | 70.00 | |
| 本文方法 | 73.13 |
Tab. 5 Comparison results of proposed method and other methods
| 数据集 | 方法 | 加权精度/% |
|---|---|---|
| EMO-DB | CNN-BiGRU[ | 84.08 |
| STFC-Attention[ | 85.95 | |
| 2-D CNN[ | 83.40 | |
| SAE-LS-CGAN[ | 86.42 | |
| IncConv[ | 86.50 | |
| PEW-BAR[ | 77.22 | |
| DN-ResNet11[ | 85.59 | |
| ATCN-GRU[ | 86.26 | |
| 本文方法 | 87.02 | |
| CASIA | Alexnet-CNN-LSTM[ | 72.83 |
| NHPC-BiLSTM[ | 79.67 | |
| DCRNN[ | 59.50 | |
| Attention-BiGRU[ | 73.33 | |
| 本文方法 | 82.59 | |
| SAVEE | NHPC-BiLSTM[ | 56.50 |
| AHPCL[ | 64.06 | |
| CNN[ | 65.83 | |
| DCNN[ | 67.00 | |
| MWA-CNN[ | 70.00 | |
| 本文方法 | 73.13 |
| [1] | 王思羽.语音情感识别算法研究[D].南京:南京邮电大学, 2019. |
| WANG S Y. Research on speech emotion recognition algorithm [D]. Nanjing: Nanjing University of Posts and Telecommunications, 2019. | |
| [2] | 罗武骏,包永强,赵力.基于模糊支持向量机的语音情感识别方法[J].声学技术, 2012, 31(4): 332-335. |
| LUO W J, BAO Y Q, ZHAO L. Emotion recognition method based on fuzzy support vector machine [J]. Technical Acoustics, 2012, 31(4): 332-335. | |
| [3] | 顾鸿虹.基于高斯混合模型的语音情感识别研究与实现[D].天津:天津师范大学, 2009. |
| GU H H. Research and implementation of speech emotion recognition based on GMM [D]. Tianjin: Tianjin Normal University, 2009. | |
| [4] | 康燕.基于HMM的情感语音识别[D].太原:太原理工大学, 2011. |
| KANG Y. Research on emotion recognition of speech signal on HMM [D]. Taiyuan: Taiyuan University of Technology, 2011. | |
| [5] | LEE J, TASHEV I. High-level feature representation using recurrent neural network for speech emotion recognition [C]// Proceedings of the INTERSPEECH 2015. [S.l.]: International Speech Communication Association, 2015: 1537-1540. |
| [6] | VERKHOLYAK O V, KAYA H, KARPOV A A. Modeling short-term and long-term dependencies of the speech signal for paralinguistic emotion classification [J]. SPIIRAS Proceedings, 2019, 18(1): 30-56. |
| [7] | 彭鹏,蔡子婷,刘雯玲,等.基于CNN和双向GRU混合孪生网络的语音情感识别方法[J].计算机应用, 2025, 45(8): 2515-2521. |
| PENG P, CAI Z T, LIU W L, et al. Speech emotion recognition method based on hybrid Siamese network with CNN and bidirectional GRU [J]. Journal of Computer Applications, 2025, 45(8): 2515-2521. | |
| [8] | 崔晨露,崔琳.面向数据增强的轻量化语音情感识别[J].计算机与现代化, 2023(4): 83-89. |
| CUI C L, CUI L. Lightweight speech emotion recognition for data enhancement [J]. Computer and Modernization, 2023(4): 83-89. | |
| [9] | 贾婧雯,蔡英,尔古打机.基于残差网络改进的中文语音情感识别[J].计算机工程与设计, 2023, 44(3): 922-928. |
| JIA J W, CAI Y, ERGU D. Improved Chinese speech emotion recognition network based on residual network [J]. Computer Engineering and Design, 2023, 44(3): 922-928. | |
| [10] | 何朝霞,朱嵘涛,罗辉.基于F-DFCC融合特征的语音情感识别方法[J].现代电子技术, 2024, 47(6): 131-136. |
| HE Z X, ZHU R T, LUO H. Speech emotion recognition method based on F-DFCC fusion feature [J]. Modern Electronic Technique, 2024, 47(6): 131-136. | |
| [11] | 张志浩.基于深度学习的语音对话情感识别研究[D].合肥:安徽建筑大学, 2023. |
| ZHANG Z H. Research on speech dialogue emotion recognition based on deep learning [D]. Hefei: Anhui Jianzhu University, 2023. | |
| [12] | LUONG M T, PHAM H, MANNING C D. Effective approaches to attention-based neural machine translation [C]// Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2015: 1412-1421. |
| [13] | 周宇,曹英楠,王永超.面向大数据的数据处理与分析算法综述[J].南京航空航天大学学报, 2021, 53(5): 664-676. |
| ZHOU Y, CAO Y N, WANG Y C. Overview of data processing and analysis algorithms for big data [J]. Journal of Nanjing University of Aeronautics and Astronautics, 2021, 53(5): 664-676. | |
| [14] | 王丹.随机梯度下降算法研究[D].西安:西安建筑科技大学, 2020. |
| WANG D. A research of stochastic gradient descent algorithm [D]. Xi’an: Xi’an University of Architecture and Technology, 2020. | |
| [15] | 孙颖,李泽,张雪英.基于约束式双通道模型的语音情感识别[J].东北大学学报(自然科学版), 2023, 44(11): 1537-1542. |
| SUN Y, LI Z, ZHANG X Y. Speech emotion recognition based on constrained bi-channel model [J]. Journal of Northeastern University (Natural Science), 2023, 44(11): 1537-1542. | |
| [16] | YE Q, SUN Y. Diversity subspace generation based on feature selection for speech emotion recognition [J]. Multimedia Tools and Applications, 2024, 83(8): 23533-23561. |
| [17] | ÜLGEN SÖNMEZ Y, VAROL A. In-depth investigation of speech emotion recognition studies from past to present — the importance of emotion recognition from speech signal for AI- [J]. Intelligent Systems with Applications, 2024, 22: No.200351. |
| [18] | 蒯红权,吴建华,吴亮.基于注意力机制的深度循环神经网络的语音情感识别[J].电子器件, 2022, 45(1): 139-142. |
| KUAI H Q, WU J H, WU L. Deep recurrent neural network with attention mechanism for speech emotion recognition [J]. Chinese Journal of Electron Devices, 2022, 45(1): 139-142. | |
| [19] | SOHN G, ZHANG N, OLUKOTUN K. Implementing and optimizing the scaled dot-product attention on streaming dataflow [EB/OL]. [2024-10-11]. . |
| [20] | 钟善机,张学习,陈楚嘉,等.基于多尺度卷积和多头自注意力的语音情感识别模型[J].自动化与信息工程, 2024, 45(4): 36-41, 49. |
| ZHONG S J, ZHANG X X, CHEN C J, et al. Speech emotion recognition model based on multi-scale convolution and multi-head self-attention [J]. Automation and Information Engineering, 2024, 45(4): 36-41, 49. | |
| [21] | LI S, XING X, FAN W, et al. Spatiotemporal and frequential cascaded attention networks for speech emotion recognition [J]. Neurocomputing, 2021, 448: 238-248. |
| [22] | 朱永华,冯天宇,张美贤,等.基于增量方法的卷积语音情感识别网络[J].上海大学学报(自然科学版), 2023, 29(1): 24-40. |
| ZHU Y H, FENG T Y, ZHANG M X, et al. Convolutional speech emotion recognition network based on incremental method [J]. Journal of Shanghai University (Natural Science Edition), 2023, 29(1): 24-40. | |
| [23] | 应娜,邹雨鉴,杨雪滢,等.一种基于DN-ResNet11的语音情感识别算法[J].电信科学, 2025, 41(6): 139-153. |
| YING N, ZOU Y J, YANG X Y, et al. A speech emotion recognition algorithm based on DN-ResNet11 [J]. Telecommunications Science, 2025, 41(6): 139-153. | |
| [24] | ZHANG H, HUANG H, HAN H. A novel heterogeneous parallel convolution Bi-LSTM for speech emotion recognition [J]. Applied Sciences, 2021, 11(21): No.9897. |
| [25] | 耿磊,傅洪亮,陶华伟,等.基于动态卷积递归神经网络的语音情感识别[J].计算机工程, 2023, 49(4): 125-130. |
| GENG L, FU H L, TAO H W, et al. Speech emotion recognition based on dynamic convolution recurrent neural networks [J]. Computer Engineering, 2023, 49(4): 125-130. | |
| [26] | 魏佳楠,孙颖,张雪英.基于SAE-LS-CGAN数据增强的语音情感识别[J/OL].太原理工大学学报[2024-10-11]. . |
| WEI J N, SUN Y, ZHANG X Y. Speech emotion recognition based on SAE-LS-CGAN data augmentation [J/OL]. Journal of Taiyuan University of Technology [2024-10-11]. . | |
| [27] | 应娜,吴顺朋,杨萌,等.基于小波散射变换和MFCC的双特征语音情感识别融合算法[J].电信科学, 2024, 40(5): 62-72. |
| YING N, WU S P, YANG M, et al. Dual-feature speech emotion recognition fusion algorithm based on wavelet scattering transform and MFCC [J]. Telecommunications Science, 2024, 40(5): 62-72. | |
| [28] | 樊永红,黄鹤鸣,张会云.基于焦点损失的ATCN-GRU语音情感识别[J].计算机仿真, 2024, 41(2): 249-254. |
| FAN Y H, HUANG H M, ZHANG H Y. Speech emotion recognition using focal loss-based ATCN-GRU [J]. Computer Simulation, 2024, 41(2): 249-254. | |
| [29] | 缪裕青,邹巍,刘同来,等.基于参数迁移和卷积循环神经网络的语音情感识别[J].计算机工程与应用, 2019, 55(10): 135-140. |
| MIAO Y Q, ZOU W, LIU T L, et al. Speech emotion recognition model based on parameter transfer and convolutional recurrent neural network [J]. Computer Engineering and Applications, 2019, 55(10): 135-140. | |
| [30] | 董炳辰,汤鲲.基于深度学习网络的语音情感识别方法研究[J].计算机与数字工程, 2022, 50(8): 1771-1775. |
| DONG B C, TANG K. Research on speech emotion recognition method based on deep learning network [J]. Computer and Digital Engineering, 2022, 50(8): 1771-1775. | |
| [31] | 张会云,黄鹤鸣.基于异构并行神经网络的语音情感识别[J].计算机工程, 2022, 48(4): 113-118. |
| ZHANG H Y, HUANG H M. Speech emotion recognition based on heterogeneous parallel neural network [J]. Computer Engineering, 2022, 48(4): 113-118. | |
| [32] | FAROOQ M, HUSSAIN F, BALOCH N K, et al. Impact of feature selection algorithm on speech emotion recognition using deep convolutional neural network [J]. Sensors, 2020, 20(21): No.6008. |
| [33] | PADI S, MANOCHA D, SRIRAM R D. Multi-window data augmentation approach for speech emotion recognition [EB/OL]. [2024-10-11]. . |
| [34] | 乔栋,陈章进,邓良,等.基于改进语音处理的卷积神经网络中文语音情感识别方法[J].计算机工程, 2022, 48(2): 281-290. |
| QIAO D, CHEN Z J, DENG L, et al. Method for Chinese speech emotion recognition based on improved speech-processing convolutional neural networks [J]. Computer Engineering, 2022, 48(2): 281-290. | |
| [35] | MEKRUKSAVANICH S, JITPATTANAKUL A, HNOOHOM N. Negative emotion recognition using deep learning for Thai language [C]// Proceedings of the 2020 Joint International Conference on Digital Arts, Media and Technology with ECTI Northern Section Conference on Electrical, Electronics, Computer and Telecommunications Engineering. Piscataway: IEEE, 2020: 71-74. |
| [1] | Wen LI, Kairong LI, Kai YANG. Subgraph-aware contrastive learning with data augmentation [J]. Journal of Computer Applications, 2026, 46(1): 1-9. |
| [2] | Yinlong JIAN, Xuebin CHEN, Zhongrui JING, Qi ZHONG, Zhenbo ZHANG. Data augmentation scheme based on conditional generative adversarial network in federated learning [J]. Journal of Computer Applications, 2026, 46(1): 21-32. |
| [3] | Shiwei LI, Yufeng ZHOU, Pengfei SUN, Weisong LIU, Zhuxuan MENG, Haojie LIAN. Point cloud data augmentation method based on scattering and absorption effects of coal dust on LiDAR electromagnetic waves [J]. Journal of Computer Applications, 2026, 46(1): 331-340. |
| [4] | Xiaoyong BIAN, Peiyang YUAN, Qiren HU. Dual-coding space-frequency mixing method for infrared small target detection [J]. Journal of Computer Applications, 2026, 46(1): 252-259. |
| [5] | Yilin DENG, Fajiang YU. Pseudo random number generator based on LSTM and separable self-attention mechanism [J]. Journal of Computer Applications, 2025, 45(9): 2893-2901. |
| [6] | Weigang LI, Jiale SHAO, Zhiqiang TIAN. Point cloud classification and segmentation network based on dual attention mechanism and multi-scale fusion [J]. Journal of Computer Applications, 2025, 45(9): 3003-3010. |
| [7] | Zhixiong XU, Bo LI, Xiaoyong BIAN, Qiren HU. Adversarial sample embedded attention U-Net for 3D medical image segmentation [J]. Journal of Computer Applications, 2025, 45(9): 3011-3016. |
| [8] | Chuang WANG, Lu YU, Jianwei CHEN, Cheng PAN, Wenbo DU. Review of open set domain adaptation [J]. Journal of Computer Applications, 2025, 45(9): 2727-2736. |
| [9] | Panfeng JING, Yudong LIANG, Chaowei LI, Junru GUO, Jinyu GUO. Semi-supervised image dehazing algorithm based on teacher-student learning [J]. Journal of Computer Applications, 2025, 45(9): 2975-2983. |
| [10] | Yiming LIANG, Jing FAN, Wenze CHAI. Multi-scale feature fusion sentiment classification based on bidirectional cross attention [J]. Journal of Computer Applications, 2025, 45(9): 2773-2782. |
| [11] | Hongjun ZHANG, Gaojun PAN, Hao YE, Yubin LU, Yiheng MIAO. Multi-source heterogeneous data analysis method combining deep learning and tensor decomposition [J]. Journal of Computer Applications, 2025, 45(9): 2838-2847. |
| [12] | Jin LI, Liqun LIU. SAR and visible image fusion based on residual Swin Transformer [J]. Journal of Computer Applications, 2025, 45(9): 2949-2956. |
| [13] | Bing YIN, Zhenhua LING, Yin LIN, Changfeng XI, Ying LIU. Emotion recognition method compatible with missing modal reasoning [J]. Journal of Computer Applications, 2025, 45(9): 2764-2772. |
| [14] | Yanhua LIAO, Yuanxia YAN, Wenlin PAN. Multi-target detection algorithm for traffic intersection images based on YOLOv9 [J]. Journal of Computer Applications, 2025, 45(8): 2555-2565. |
| [15] | Lina GE, Mingyu WANG, Lei TIAN. Review of research on efficiency of federated learning [J]. Journal of Computer Applications, 2025, 45(8): 2387-2398. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||