


Journal of Computer Applications ›› 2026, Vol. 46 ›› Issue (5): 1551-1559.DOI: 10.11772/j.issn.1001-9081.2025050571
• Multimedia computing and computer simulation • Previous Articles
Binhong XIE, Erdan ZHU( ), Rui ZHANG
), Rui ZHANG
Received:2025-05-26
Revised:2025-08-14
Accepted:2025-08-26
Online:2025-08-28
Published:2026-05-10
Contact:
Erdan ZHU
About author:XIE Binhong, born in 1971, M. S., professor. His research interests include intelligent software engineering, machine learning.Supported by:
谢斌红, 朱二丹(), 张睿
通讯作者:
朱二丹
作者简介:谢斌红(1971—),男,山西万荣人,教授,硕士,CCF会员,主要研究方向:智能化软件工程、机器学习基金资助:CLC Number:
Binhong XIE, Erdan ZHU, Rui ZHANG. Appearance-motion collaborative modeling for video anomaly detection[J]. Journal of Computer Applications, 2026, 46(5): 1551-1559.
谢斌红, 朱二丹, 张睿. 基于外观-运动协同建模的视频异常检测[J]. 《计算机应用》唯一官方网站, 2026, 46(5): 1551-1559.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2025050571
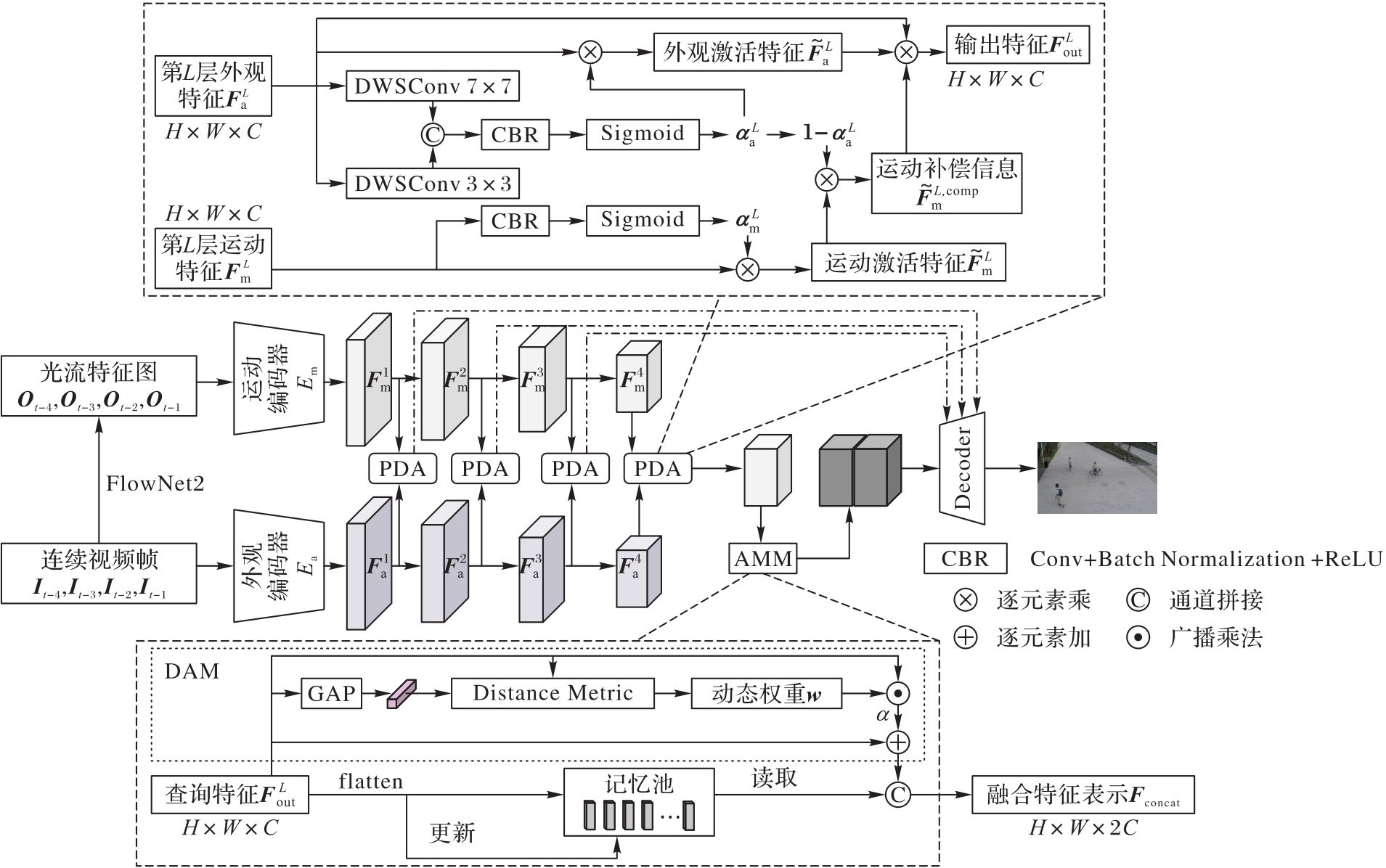
Fig. 1 Network architecture of AMC-VAD
| 类型 | 方法 | AUC/% | ||
|---|---|---|---|---|
UCSD Ped2 | CUHK Avenue | Shanghai Tech | ||
传统 方法 | MPPCA[ | 69.3 | — | — |
| MDT[ | 82.9 | — | — | |
重构 方法 | ConvAE[ | 90.0 | 70.2 | — |
| ConvLSTM-AE[ | 88.1 | 77.0 | — | |
| MNAD-R[ | 90.2 | 82.8 | 69.8 | |
| FE-MemAE[ | 97.2 | 88.5 | 74.3 | |
预测 方法 | FFP[ | 95.4 | 85.1 | 72.8 |
| AMMC-Net[ | 96.6 | 86.6 | 73.7 | |
| STCEN[ | 96.9 | 86.6 | 73.8 | |
| STR-VAD[ | 86.1 | 73.2 | ||
| CA-VAD[ | 97.9 | 74.1 | ||
| MAMC[ | 96.7 | 87.6 | 71.5 | |
| HSTforU[ | 97.3 | 87.5 | ||
| ST_MemAE[ | 97.0 | 87.7 | 76.1 | |
混合 方法 | AMC[ | 96.2 | 86.9 | — |
| IPR[ | 96.3 | 85.1 | 73.0 | |
| DGG[ | 96.6 | 85.7 | 73.1 | |
| AMC-VAD | 98.5 | 88.5 | 73.8 | |
Tab. 1 Comparison of anomaly detection results of AMC-VAD and mainstream methods on different datasets
| 类型 | 方法 | AUC/% | ||
|---|---|---|---|---|
UCSD Ped2 | CUHK Avenue | Shanghai Tech | ||
传统 方法 | MPPCA[ | 69.3 | — | — |
| MDT[ | 82.9 | — | — | |
重构 方法 | ConvAE[ | 90.0 | 70.2 | — |
| ConvLSTM-AE[ | 88.1 | 77.0 | — | |
| MNAD-R[ | 90.2 | 82.8 | 69.8 | |
| FE-MemAE[ | 97.2 | 88.5 | 74.3 | |
预测 方法 | FFP[ | 95.4 | 85.1 | 72.8 |
| AMMC-Net[ | 96.6 | 86.6 | 73.7 | |
| STCEN[ | 96.9 | 86.6 | 73.8 | |
| STR-VAD[ | 86.1 | 73.2 | ||
| CA-VAD[ | 97.9 | 74.1 | ||
| MAMC[ | 96.7 | 87.6 | 71.5 | |
| HSTforU[ | 97.3 | 87.5 | ||
| ST_MemAE[ | 97.0 | 87.7 | 76.1 | |
混合 方法 | AMC[ | 96.2 | 86.9 | — |
| IPR[ | 96.3 | 85.1 | 73.0 | |
| DGG[ | 96.6 | 85.7 | 73.1 | |
| AMC-VAD | 98.5 | 88.5 | 73.8 | |
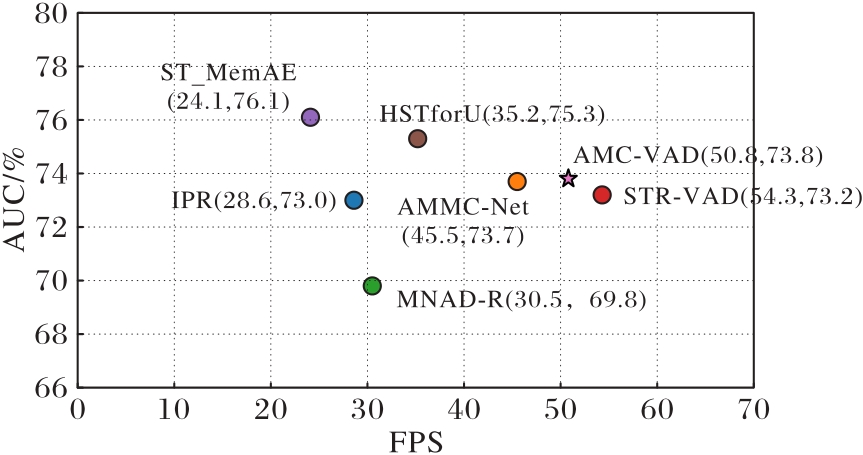
Fig. 2 Comparison of running speed and AUC of different methods on Shanghai Tech dataset
| 方法 | 参数量/106 | FPS | GFLOPs | 训练 耗时/h | GPU显存 占用/GB |
|---|---|---|---|---|---|
| MPN[ | 12.71 | 47.0 | 165.1 | 22.7 | 23.2 |
| AMMC-Net[ | 25.04 | 48.6 | 93.7 | 19.5 | 23.6 |
| P3DE[ | 12.60 | 52.0 | 55.2 | 15.2 | 18.4 |
| FDC-Net[ | 218.34 | 22.2 | — | — | — |
| AMC-VAD | 21.20 | 51.2 | 88.2 | 17.1 | 22.8 |
Tab. 2 Comparison of different models' complexity and inference efficiency on UCSD Ped2 dataset
| 方法 | 参数量/106 | FPS | GFLOPs | 训练 耗时/h | GPU显存 占用/GB |
|---|---|---|---|---|---|
| MPN[ | 12.71 | 47.0 | 165.1 | 22.7 | 23.2 |
| AMMC-Net[ | 25.04 | 48.6 | 93.7 | 19.5 | 23.6 |
| P3DE[ | 12.60 | 52.0 | 55.2 | 15.2 | 18.4 |
| FDC-Net[ | 218.34 | 22.2 | — | — | — |
| AMC-VAD | 21.20 | 51.2 | 88.2 | 17.1 | 22.8 |

Fig. 3 Comparison of future frame prediction error heatmaps on experimental datasets
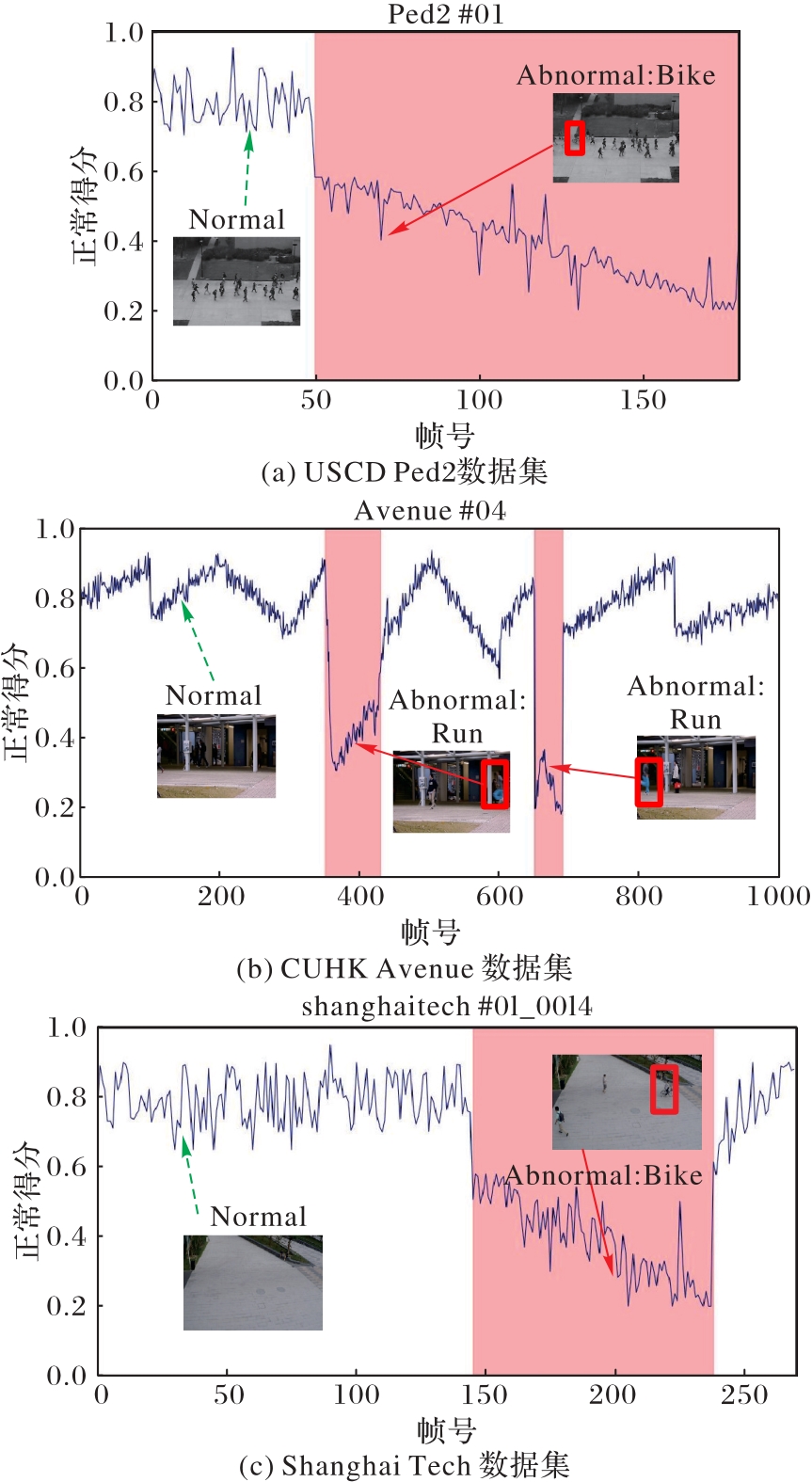
Fig. 4 Normal score curves on experimental datasets
| 方式 | PDA | AMM | Skip-connection | AUC/% | |
|---|---|---|---|---|---|
| 1 | 96.6 | ||||
| 2 | ✓ | 97.1 | |||
| 3 | ✓ | 97.2 | |||
| 4 | ✓ | ✓ | 97.3 | ||
| 5 | ✓ | ✓ | 97.5 | ||
| 6 | ✓ | ✓ | 97.7 | ||
| 7 | ✓ | ✓ | ✓ | 97.6 | |
| 8 | ✓ | ✓ | ✓ | 98.1 | |
| 9 | ✓ | ✓ | ✓ | 98.3 | |
| 10 | ✓ | ✓ | ✓ | ✓ | 98.5 |
Tab. 3 Ablation study results on USCD Ped2 dataset
| 方式 | PDA | AMM | Skip-connection | AUC/% | |
|---|---|---|---|---|---|
| 1 | 96.6 | ||||
| 2 | ✓ | 97.1 | |||
| 3 | ✓ | 97.2 | |||
| 4 | ✓ | ✓ | 97.3 | ||
| 5 | ✓ | ✓ | 97.5 | ||
| 6 | ✓ | ✓ | 97.7 | ||
| 7 | ✓ | ✓ | ✓ | 97.6 | |
| 8 | ✓ | ✓ | ✓ | 98.1 | |
| 9 | ✓ | ✓ | ✓ | 98.3 | |
| 10 | ✓ | ✓ | ✓ | ✓ | 98.5 |
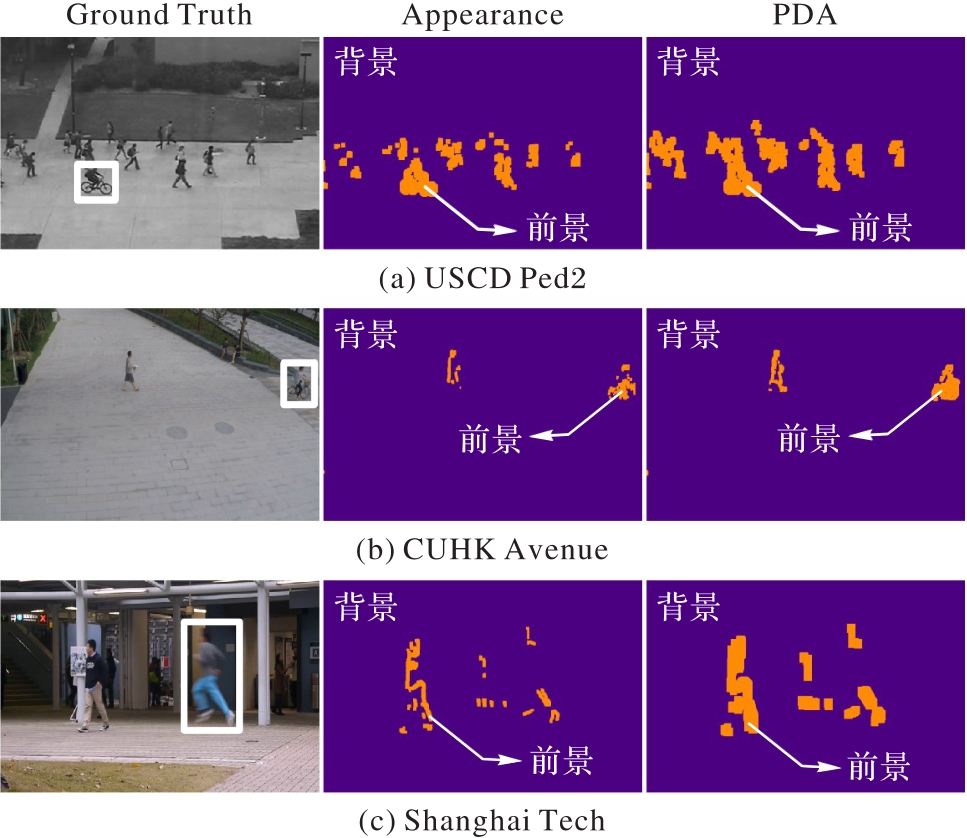
Fig. 5 Comparison of salient regions between appearance features and fused features on experimental datasets
| 组合 | AUC/% | |||
|---|---|---|---|---|
| 1 | 0.5 | 1.5 | 0.5 | 94.1 |
| 2 | 0.5 | 1 | 0.5 | 94.2 |
| 3 | 0.5 | 0.1 | 0.5 | 95.5 |
| 4 | 0.5 | 0.01 | 0.5 | 93.1 |
| 5 | 0.8 | 0.1 | 0.5 | 94.7 |
| 6 | 1 | 0.1 | 0.5 | 95.6 |
| 7 | 2 | 0.1 | 0.5 | 94.6 |
| 8 | 100 | 0.1 | 0.5 | 93.9 |
| 9 | 1 | 0.1 | 0.7 | 96.1 |
| 10 | 1 | 0.1 | 0.8 | 96.2 |
| 11 | 1 | 0.1 | 1 | 98.5 |
| 12 | 1 | 0.1 | 50 | 95.9 |
| 13 | 1 | 0.1 | 100 | 94.2 |
Tab. 4 Performance comparison of different loss function weight combinations on UCSD Ped2 dataset
| 组合 | AUC/% | |||
|---|---|---|---|---|
| 1 | 0.5 | 1.5 | 0.5 | 94.1 |
| 2 | 0.5 | 1 | 0.5 | 94.2 |
| 3 | 0.5 | 0.1 | 0.5 | 95.5 |
| 4 | 0.5 | 0.01 | 0.5 | 93.1 |
| 5 | 0.8 | 0.1 | 0.5 | 94.7 |
| 6 | 1 | 0.1 | 0.5 | 95.6 |
| 7 | 2 | 0.1 | 0.5 | 94.6 |
| 8 | 100 | 0.1 | 0.5 | 93.9 |
| 9 | 1 | 0.1 | 0.7 | 96.1 |
| 10 | 1 | 0.1 | 0.8 | 96.2 |
| 11 | 1 | 0.1 | 1 | 98.5 |
| 12 | 1 | 0.1 | 50 | 95.9 |
| 13 | 1 | 0.1 | 100 | 94.2 |
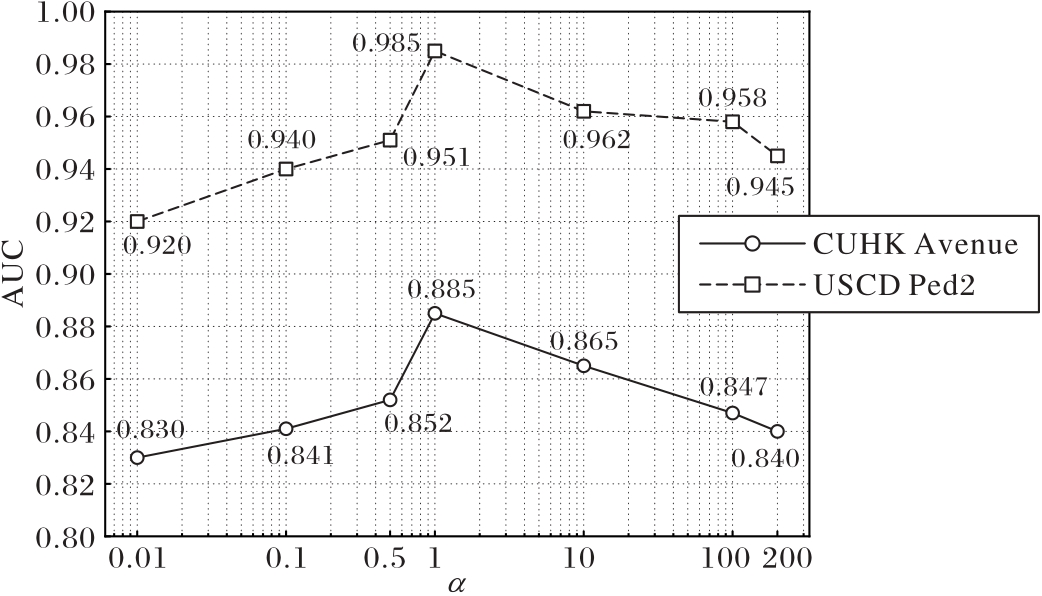
Fig. 6 AUC performance of different hyperparameters α on USCD Ped2 and CUHK Avenue datasets
| 分辨率 | 每帧推理 时间/ms | FPS | 分辨率 | 每帧推理 时间/ms | FPS |
|---|---|---|---|---|---|
| 256×256 | 19.50 | 51.2 | 1 024×1 024 | 22.80 | 43.8 |
| 512×512 | 20.90 | 47.7 | 4 000×3 036 | 32.96 | 30.3 |
Tab. 5 Comparison of PDA's time performance at different resolutions on UCSD Ped2 dataset
| 分辨率 | 每帧推理 时间/ms | FPS | 分辨率 | 每帧推理 时间/ms | FPS |
|---|---|---|---|---|---|
| 256×256 | 19.50 | 51.2 | 1 024×1 024 | 22.80 | 43.8 |
| 512×512 | 20.90 | 47.7 | 4 000×3 036 | 32.96 | 30.3 |
| [1] | LIU Y, YANG D, WANG Y, et al. Generalized video anomaly event detection: systematic taxonomy and comparison of deep models[J]. ACM Computing Surveys, 2024, 56(7): No.189. |
| [2] | CAI R, ZHANG H, LIU W, et al. Appearance-motion memory consistency network for video anomaly detection[C]// Proceedings of the 35th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2021: 938-946. |
| [3] | HASAN M, CHOI J, NEUMANN J, et al. Learning temporal regularity in video sequences[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 733-742. |
| [4] | LIU W, LUO W, LIAN D, et al. Future frame prediction for anomaly detection — a new baseline[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 6536-6545. |
| [5] | VU H, NGUYEN T D, LE T, et al. Robust anomaly detection in videos using multilevel representations[C]// Proceedings of the 33rd AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2019: 5216-5223. |
| [6] | BAO Q, LIU F, LIU Y, et al. Hierarchical scene normality-binding modeling for anomaly detection in surveillance videos[C]// Proceedings of the 30th ACM International Conference on Multimedia. New York: ACM, 2022: 6103-6112. |
| [7] | SINGH R, SETHI A, SAINI K, et al. Attention-guided generator with dual discriminator GAN for real-time video anomaly detection[J]. Engineering Applications of Artificial Intelligence, 2024, 131: No.107830. |
| [8] | YANG D, LIU Y, HUANG C, et al. Target and source modality co-reinforcement for emotion understanding from asynchronous multimodal sequences[J]. Knowledge-Based Systems, 2023, 265: No.110370. |
| [9] | LIU Y, LIU J, LIN J, et al. Appearance-motion united auto-encoder framework for video anomaly detection[J]. IEEE Transactions on Circuits and Systems Ⅱ: Express Briefs, 2022, 69(5): 2498-2502. |
| [10] | NING Z, WANG Z, LIU Y, et al. Memory-enhanced appearance-motion consistency framework for video anomaly detection[J]. Computer Communications, 2024, 216: 159-167. |
| [11] | WESTON J, CHOPRA S, BORDES A. Memory networks[EB/OL]. [2024-11-29].. |
| [12] | PARK H, NOH J, HAM B. Learning memory-guided normality for anomaly detection[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 14360-14369. |
| [13] | WANG Y, LIU T, ZHOU J, et al. Video anomaly detection based on spatio-temporal relationships among objects[J]. Neurocomputing, 2023, 532: 141-151. |
| [14] | LI W, MAHADEVAN V, VASCONCELOS N. Anomaly detection and localization in crowded scenes[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2014, 36(1): 18-32. |
| [15] | LU C, SHI J, JIA J. Abnormal event detection at 150 FPS in MATLAB[C]// Proceedings of the 2013 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2013: 2720-2727. |
| [16] | LUO W, LIU W, GAO S. A revisit of sparse coding based anomaly detection in stacked RNN framework[C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2017: 341-349. |
| [17] | KIM J, GRAUMAN K. Observe locally, infer globally: a space-time MRF for detecting abnormal activities with incremental updates[C]// Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2009: 2921-2928. |
| [18] | LUO W, LIU W, GAO S. Remembering history with convolutional LSTM for anomaly detection[C]// Proceedings of the 2017 IEEE International Conference on Multimedia and Expo. Piscataway: IEEE, 2017: 439-444. |
| [19] | LIU H, HE N, HUANG X, et al. A video anomaly detection framework based on hybrid feature-enhanced memory reconstruction and jigsaw puzzle[J]. Signal, Image and Video Processing, 2025, 19: No.12. |
| [20] | HAO Y, LI J, WANG N, et al. Spatiotemporal consistency-enhanced network for video anomaly detection[J]. Pattern Recognition, 2022, 121: No.108232. |
| [21] | YANG Z, RADKE R J. Context-aware video anomaly detection in long-term datasets[C]// Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Piscataway: IEEE, 2024: 4002-4011. |
| [22] | LE V T, JIN H, KIM Y G. HSTforU: anomaly detection in aerial and ground-based videos with hierarchical spatio-temporal transformer for U-net[J]. Applied Intelligence, 2025, 55(4): No.261. |
| [23] | LI H, CHEN M. A novel spatio-temporal memory network for video anomaly detection[J]. Multimedia Tools and Applications, 2025, 84(8): 4603-4624. |
| [24] | NGUYEN T N, MEUNIER J. Anomaly detection in video sequence with appearance-motion correspondence[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 1273-1283. |
| [25] | TANG Y, ZHAO L, ZHANG S, et al. Integrating prediction and reconstruction for anomaly detection[J]. Pattern Recognition Letters, 2020, 129: 123-130. |
| [26] | SUN Z, WANG P, ZHENG W, et al. Dual GroupGAN: an unsupervised four-competitor (2V2) approach for video anomaly detection[J]. Pattern Recognition, 2024, 153: No.110500. |
| [27] | LV H, CHEN C, CUI Z, et al. Learning normal dynamics in videos with meta prototype network[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 15420-15429. |
| [28] | WEN X, LAI H, GAO G, et al. Video anomaly detection based on cross-frame prediction mechanism and spatio-temporal memory-enhanced pseudo-3D encoder[J]. Engineering Applications of Artificial Intelligence, 2023, 126(Pt C): No.107057. |
| [29] | SHI R, HE Q, WANG H, et al. FDC-Net: foreground dynamic capture with deep feature enhancement for video anomaly detection[J]. Multimedia Systems, 2025, 31(2): No.102. |
| [1] | Huanxian LIU, Hongtao WANG, Xian’ao WANG, Hongmei WANG, Weifeng XU. Multimodal fact verification with cross-modal semantic association [J]. Journal of Computer Applications, 2026, 46(4): 1069-1076. |
| [2] | Hao LIANG, Shaojie QIAO. Complex query-based question-answering model integrating bidirectional sequence embeddings [J]. Journal of Computer Applications, 2026, 46(4): 1096-1103. |
| [3] | Lihu PAN, Shouxin PENG, Rui ZHANG, Zhiyang XUE, Xuzhen MAO. Video anomaly detection for moving foreground regions [J]. Journal of Computer Applications, 2025, 45(4): 1300-1309. |
| [4] | Linhao LI, Yize WANG, Yingshuang LI, Yongfeng DONG, Zhen WANG. Panoptic scene graph generation method based on relation feature enhancement [J]. Journal of Computer Applications, 2025, 45(2): 584-593. |
| [5] | Pengcheng SONG, Lijun GUO, Rong ZHANG. Weakly supervised video anomaly detection with local-global temporal dependency [J]. Journal of Computer Applications, 2025, 45(1): 240-246. |
| [6] | Yuhan LIU, Genlin JI, Hongping ZHANG. Video pedestrian anomaly detection method based on skeleton graph and mixed attention [J]. Journal of Computer Applications, 2024, 44(8): 2551-2557. |
| [7] | Qing JIA, Laihua WANG, Weisheng WANG. Anomaly detection in video via independently recurrent neural network and variational autoencoder network [J]. Journal of Computer Applications, 2023, 43(2): 507-513. |
| [8] | . Parallel OLAP query optimization method based on semantic decomposition [J]. Journal of Computer Applications, 2010, 30(07): 1956-1958. |
| [9] | . Information query based on semantic association in grid environment [J]. Journal of Computer Applications, 2009, 29(06): 1517-1526. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||