


Journal of Computer Applications ›› 2026, Vol. 46 ›› Issue (4): 1069-1076.DOI: 10.11772/j.issn.1001-9081.2025050526
• Artificial intelligence • Previous Articles Next Articles
Huanxian LIU1, Hongtao WANG1,2, Xian’ao WANG1, Hongmei WANG1, Weifeng XU1,3( )
)
Received:2025-05-14
Revised:2025-07-14
Accepted:2025-08-08
Online:2025-08-22
Published:2026-04-10
Contact:
Weifeng XU
About author:LIU Huanxian, born in 2001, M. S. candidate. Her research interests include natural language processing.Supported by:
刘欢娴1, 王洪涛1,2, 王宪奥1, 王洪梅1, 徐伟峰1,3()
通讯作者:
徐伟峰
作者简介:刘欢娴(2001—),女,吉林白山人,硕士研究生,主要研究方向:自然语言处理基金资助:CLC Number:
Huanxian LIU, Hongtao WANG, Xian’ao WANG, Hongmei WANG, Weifeng XU. Multimodal fact verification with cross-modal semantic association[J]. Journal of Computer Applications, 2026, 46(4): 1069-1076.
刘欢娴, 王洪涛, 王宪奥, 王洪梅, 徐伟峰. 跨模态语义关联的多模态事实验证[J]. 《计算机应用》唯一官方网站, 2026, 46(4): 1069-1076.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2025050526
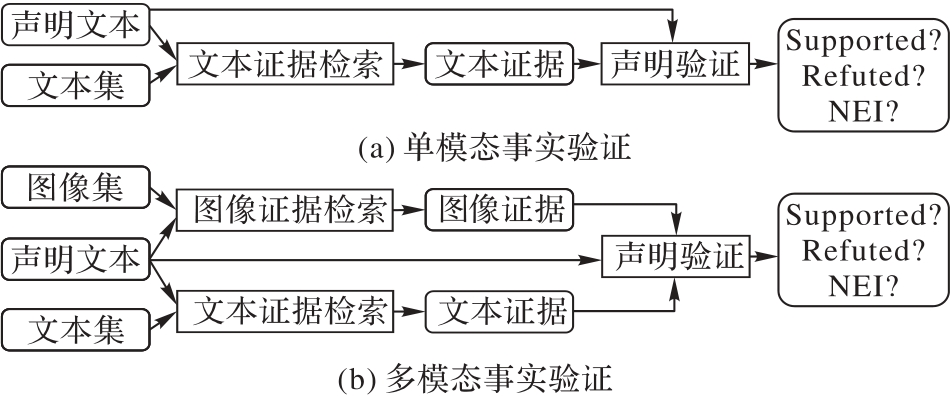
Fig. 1 Frameworks of unimodal and multimodal fact verification
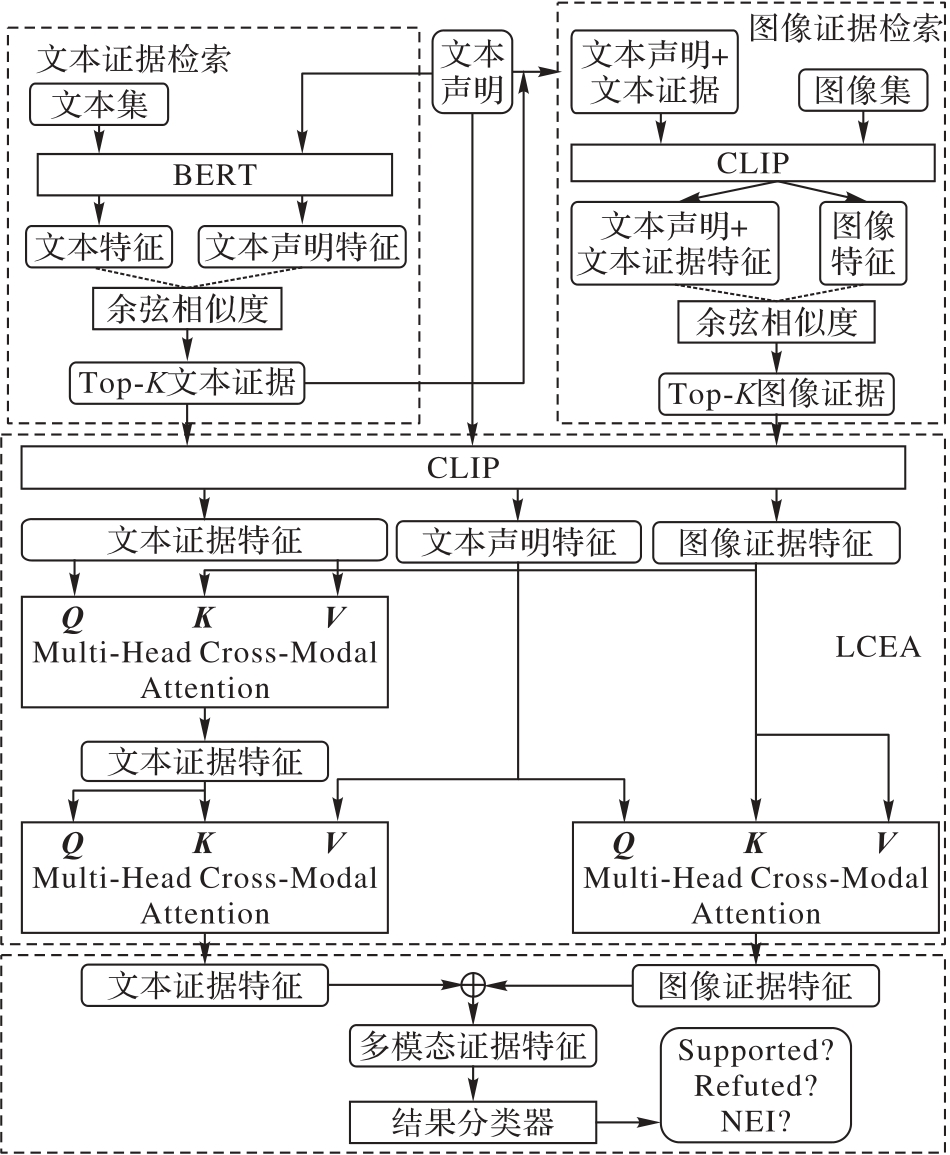
Fig. 2 Overall architecture of CMSA method
| 数据集 | 数据划分 | Supported | Refuted | NEI |
|---|---|---|---|---|
| MOCHEG | Train | 3 826 | 3 301 | |
| Val | 501 | 488 | 501 | |
| Test | 817 | 825 | 800 | |
| CEAD | Train | 1 860 | 790 | |
| Val | 610 | 900 | 340 | |
| Test | 1 034 | 504 |
Tab. 1 Basic statistics of datasets
| 数据集 | 数据划分 | Supported | Refuted | NEI |
|---|---|---|---|---|
| MOCHEG | Train | 3 826 | 3 301 | |
| Val | 501 | 488 | 501 | |
| Test | 817 | 825 | 800 | |
| CEAD | Train | 1 860 | 790 | |
| Val | 610 | 900 | 340 | |
| Test | 1 034 | 504 |
| 证据类型 | 模型 | Top-5 | Top-10 | Top-15 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Pre | Rec | F1 | Pre | Rec | F1 | Pre | Rec | F1 | ||
| 文本证据 | RoBERTa | 32.05 | 31.01 | 31.52 | 29.77 | 27.65 | 28.67 | 28.54 | 27.92 | 28.23 |
| BERT | 35.16 | 33.66 | 34.39 | 31.79 | 33.50 | 32.62 | 29.91 | 31.98 | 30.91 | |
| MOCHEG-Text | 42.59 | 42.96 | 40.37 | 41.74 | 41.48 | 41.61 | 39.22 | 38.53 | 38.88 | |
| ESCNet-Text | 42.23 | 41.72 | 41.97 | 40.42 | 40.18 | 40.80 | 38.31 | 38.78 | 38.54 | |
| MSP-Text | 43.92 | 45.14 | 44.52 | 42.71 | 44.27 | 43.48 | 41.15 | 42.66 | 41.89 | |
| Qwen-7B-Text | 43.48 | 44.35 | 43.91 | 42.38 | 43.63 | 42.99 | 41.02 | 42.21 | 41.61 | |
| 多模态证据 | RoBERTa+ViT | 33.93 | 33.91 | 33.92 | 31.48 | 34.70 | 33.01 | 37.12 | 35.17 | 36.12 |
| BERT+ViT | 35.56 | 35.95 | 35.75 | 34.34 | 33.74 | 34.04 | 32.71 | 32.39 | 32.55 | |
| RoBERTa+ResNet50 | 36.00 | 36.53 | 36.26 | 35.74 | 35.91 | 35.82 | 37.42 | 36.73 | 37.07 | |
| BERT+ResNet50 | 39.93 | 40.75 | 40.33 | 39.44 | 37.10 | 38.24 | 37.61 | 36.04 | 36.81 | |
| MOCHEG | 43.12 | 42.55 | 42.83 | 44.00 | 44.35 | 44.17 | 43.75 | 44.43 | 43.38 | |
| ESCNet | 46.82 | 47.02 | 46.92 | 45.55 | 46.01 | 45.78 | 44.81 | 45.42 | 45.11 | |
| MSP | 48.03 | 48.10 | 48.06 | 47.01 | 47.42 | 47.21 | 46.42 | 47.01 | 46.71 | |
| Qwen-7B | 47.33 | 47.60 | 47.46 | 46.41 | 46.95 | 46.67 | 45.85 | 46.64 | 46.24 | |
| CMSA | 46.56 | 47.62 | 47.09 | 47.01 | 47.75 | 47.38 | 48.61 | 47.95 | 48.28 | |
Tab. 2 Performance comparison of different models on MOCHEG dataset
| 证据类型 | 模型 | Top-5 | Top-10 | Top-15 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Pre | Rec | F1 | Pre | Rec | F1 | Pre | Rec | F1 | ||
| 文本证据 | RoBERTa | 32.05 | 31.01 | 31.52 | 29.77 | 27.65 | 28.67 | 28.54 | 27.92 | 28.23 |
| BERT | 35.16 | 33.66 | 34.39 | 31.79 | 33.50 | 32.62 | 29.91 | 31.98 | 30.91 | |
| MOCHEG-Text | 42.59 | 42.96 | 40.37 | 41.74 | 41.48 | 41.61 | 39.22 | 38.53 | 38.88 | |
| ESCNet-Text | 42.23 | 41.72 | 41.97 | 40.42 | 40.18 | 40.80 | 38.31 | 38.78 | 38.54 | |
| MSP-Text | 43.92 | 45.14 | 44.52 | 42.71 | 44.27 | 43.48 | 41.15 | 42.66 | 41.89 | |
| Qwen-7B-Text | 43.48 | 44.35 | 43.91 | 42.38 | 43.63 | 42.99 | 41.02 | 42.21 | 41.61 | |
| 多模态证据 | RoBERTa+ViT | 33.93 | 33.91 | 33.92 | 31.48 | 34.70 | 33.01 | 37.12 | 35.17 | 36.12 |
| BERT+ViT | 35.56 | 35.95 | 35.75 | 34.34 | 33.74 | 34.04 | 32.71 | 32.39 | 32.55 | |
| RoBERTa+ResNet50 | 36.00 | 36.53 | 36.26 | 35.74 | 35.91 | 35.82 | 37.42 | 36.73 | 37.07 | |
| BERT+ResNet50 | 39.93 | 40.75 | 40.33 | 39.44 | 37.10 | 38.24 | 37.61 | 36.04 | 36.81 | |
| MOCHEG | 43.12 | 42.55 | 42.83 | 44.00 | 44.35 | 44.17 | 43.75 | 44.43 | 43.38 | |
| ESCNet | 46.82 | 47.02 | 46.92 | 45.55 | 46.01 | 45.78 | 44.81 | 45.42 | 45.11 | |
| MSP | 48.03 | 48.10 | 48.06 | 47.01 | 47.42 | 47.21 | 46.42 | 47.01 | 46.71 | |
| Qwen-7B | 47.33 | 47.60 | 47.46 | 46.41 | 46.95 | 46.67 | 45.85 | 46.64 | 46.24 | |
| CMSA | 46.56 | 47.62 | 47.09 | 47.01 | 47.75 | 47.38 | 48.61 | 47.95 | 48.28 | |
| 证据类型 | 模型 | Top-5 | Top-10 | Top-15 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Pre | Rec | F1 | Pre | Rec | F1 | Pre | Rec | F1 | ||
| 文本证据 | BERT | 31.89 | 35.39 | 33.55 | 30.53 | 35.30 | 32.74 | 29.89 | 34.57 | 32.06 |
| RoBERTa | 34.07 | 38.48 | 36.14 | 33.21 | 37.26 | 35.12 | 30.45 | 36.58 | 33.23 | |
| MOCHEG-Text | 42.32 | 42.70 | 42.51 | 42.15 | 41.44 | 41.79 | 39.57 | 39.18 | 39.37 | |
| ESCNet-Text | 42.88 | 43.72 | 43.30 | 41.42 | 42.80 | 42.10 | 39.82 | 40.30 | 40.04 | |
| MSP-Text | 43.28 | 43.93 | 43.60 | 42.46 | 42.82 | 42.64 | 41.00 | 41.60 | 41.30 | |
| Qwen-7B-Text | 42.65 | 43.00 | 42.82 | 41.70 | 42.38 | 42.03 | 40.50 | 41.30 | 40.89 | |
| 多模态证据 | RoBERTa+ViT | 33.68 | 40.46 | 36.76 | 32.82 | 38.21 | 35.31 | 31.79 | 37.73 | 34.51 |
| BERT+ViT | 34.29 | 40.15 | 36.82 | 34.16 | 39.78 | 36.76 | 34.02 | 38.52 | 36.13 | |
| RoBERTa+ResNet50 | 35.63 | 39.30 | 37.38 | 33.71 | 41.74 | 37.30 | 31.72 | 39.04 | 35.00 | |
| BERT+ResNet50 | 37.92 | 40.46 | 39.15 | 37.56 | 39.43 | 38.47 | 36.14 | 38.57 | 37.32 | |
| MOCHEG | 43.80 | 43.10 | 43.45 | 42.93 | 43.66 | 43.29 | 43.27 | 43.06 | 43.16 | |
| ESCNet | 44.38 | 44.92 | 44.65 | 43.90 | 44.20 | 44.05 | 42.88 | 43.16 | 43.02 | |
| MSP | 46.05 | 46.12 | 46.08 | 45.31 | 45.52 | 45.41 | 44.60 | 45.00 | 44.80 | |
| Qwen-7B | 45.32 | 45.68 | 45.50 | 44.79 | 44.85 | 44.81 | 43.85 | 44.30 | 44.07 | |
| CMSA | 46.36 | 47.58 | 46.96 | 45.42 | 46.94 | 46.17 | 45.34 | 46.84 | 46.08 | |
Tab. 3 Performance comparison of different models on CEAD dataset
| 证据类型 | 模型 | Top-5 | Top-10 | Top-15 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Pre | Rec | F1 | Pre | Rec | F1 | Pre | Rec | F1 | ||
| 文本证据 | BERT | 31.89 | 35.39 | 33.55 | 30.53 | 35.30 | 32.74 | 29.89 | 34.57 | 32.06 |
| RoBERTa | 34.07 | 38.48 | 36.14 | 33.21 | 37.26 | 35.12 | 30.45 | 36.58 | 33.23 | |
| MOCHEG-Text | 42.32 | 42.70 | 42.51 | 42.15 | 41.44 | 41.79 | 39.57 | 39.18 | 39.37 | |
| ESCNet-Text | 42.88 | 43.72 | 43.30 | 41.42 | 42.80 | 42.10 | 39.82 | 40.30 | 40.04 | |
| MSP-Text | 43.28 | 43.93 | 43.60 | 42.46 | 42.82 | 42.64 | 41.00 | 41.60 | 41.30 | |
| Qwen-7B-Text | 42.65 | 43.00 | 42.82 | 41.70 | 42.38 | 42.03 | 40.50 | 41.30 | 40.89 | |
| 多模态证据 | RoBERTa+ViT | 33.68 | 40.46 | 36.76 | 32.82 | 38.21 | 35.31 | 31.79 | 37.73 | 34.51 |
| BERT+ViT | 34.29 | 40.15 | 36.82 | 34.16 | 39.78 | 36.76 | 34.02 | 38.52 | 36.13 | |
| RoBERTa+ResNet50 | 35.63 | 39.30 | 37.38 | 33.71 | 41.74 | 37.30 | 31.72 | 39.04 | 35.00 | |
| BERT+ResNet50 | 37.92 | 40.46 | 39.15 | 37.56 | 39.43 | 38.47 | 36.14 | 38.57 | 37.32 | |
| MOCHEG | 43.80 | 43.10 | 43.45 | 42.93 | 43.66 | 43.29 | 43.27 | 43.06 | 43.16 | |
| ESCNet | 44.38 | 44.92 | 44.65 | 43.90 | 44.20 | 44.05 | 42.88 | 43.16 | 43.02 | |
| MSP | 46.05 | 46.12 | 46.08 | 45.31 | 45.52 | 45.41 | 44.60 | 45.00 | 44.80 | |
| Qwen-7B | 45.32 | 45.68 | 45.50 | 44.79 | 44.85 | 44.81 | 43.85 | 44.30 | 44.07 | |
| CMSA | 46.36 | 47.58 | 46.96 | 45.42 | 46.94 | 46.17 | 45.34 | 46.84 | 46.08 | |
| 模型 | F1 |
|---|---|
| RoBERTa+ViT | 36.43 |
| BERT+ViT | 36.58 |
| RoBERTa+ResNet50 | 37.71 |
| BERT+ResNet50 | 41.25 |
| MOCHEG | 44.06 |
| ESCNet | 44.20 |
| MSP | 48.60 |
| Qwen-7B | 48.10 |
| CMSA | 48.65 |
Tab. 4 Comparison of optimal performance of different models on MOCHEG dataset
| 模型 | F1 |
|---|---|
| RoBERTa+ViT | 36.43 |
| BERT+ViT | 36.58 |
| RoBERTa+ResNet50 | 37.71 |
| BERT+ResNet50 | 41.25 |
| MOCHEG | 44.06 |
| ESCNet | 44.20 |
| MSP | 48.60 |
| Qwen-7B | 48.10 |
| CMSA | 48.65 |
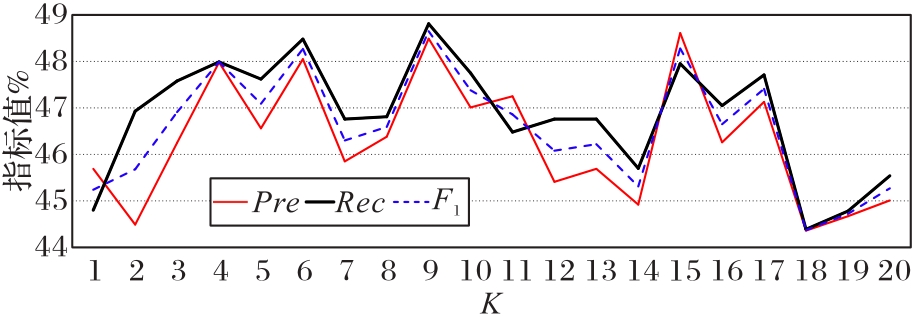
Fig. 3 Impact of different K values on final results
| 模型 | Top-5 | Top-10 | Top-15 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Pre | Rec | F1 | Pre | Rec | F1 | Pre | Rec | F1 | |
| w/o声明‒证据注意力 | 45.67 | 45.37 | 45.52 | 46.01 | 46.19 | 46.10 | 44.36 | 45.41 | 44.88 |
| w/o多模态注意力 | 46.04 | 45.86 | 45.95 | 45.59 | 45.50 | 45.54 | 43.40 | 44.47 | 43.93 |
| w/o声明‒图像证据注意力 | 46.21 | 45.94 | 46.07 | 45.68 | 45.57 | 45.62 | 45.01 | 45.24 | 45.12 |
| w/o声明‒文本证据注意力 | 46.24 | 46.33 | 46.28 | 46.32 | 46.47 | 46.39 | 45.83 | 45.49 | 45.66 |
| CMSA | 46.56 | 47.62 | 47.09 | 47.01 | 47.75 | 47.38 | 48.61 | 47.95 | 48.28 |
Tab. 5 Ablation study results on MOCHEG dataset
| 模型 | Top-5 | Top-10 | Top-15 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Pre | Rec | F1 | Pre | Rec | F1 | Pre | Rec | F1 | |
| w/o声明‒证据注意力 | 45.67 | 45.37 | 45.52 | 46.01 | 46.19 | 46.10 | 44.36 | 45.41 | 44.88 |
| w/o多模态注意力 | 46.04 | 45.86 | 45.95 | 45.59 | 45.50 | 45.54 | 43.40 | 44.47 | 43.93 |
| w/o声明‒图像证据注意力 | 46.21 | 45.94 | 46.07 | 45.68 | 45.57 | 45.62 | 45.01 | 45.24 | 45.12 |
| w/o声明‒文本证据注意力 | 46.24 | 46.33 | 46.28 | 46.32 | 46.47 | 46.39 | 45.83 | 45.49 | 45.66 |
| CMSA | 46.56 | 47.62 | 47.09 | 47.01 | 47.75 | 47.38 | 48.61 | 47.95 | 48.28 |
| [1] | 陈建贵,张儒清,郭嘉丰,等. 基于反事实推理的事实验证去偏方法[J]. 中文信息学报, 2023, 37(10): 97-105. |
| CHEN J G, ZHANG R Q, GUO J F, et al. Counterfactual inference for fact verification debiasing[J]. Journal of Chinese Information Processing, 2023, 37(10): 97-105. | |
| [2] | YAO B M, SHAH A, SUN L, et al. End-to-end multimodal fact-checking and explanation generation: a challenging dataset and models[C]// Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2023: 2733-2743. |
| [3] | MISHRA S, SURYAVARDAN S, BHASKAR A, et al. FACTIFY: a multi-modal fact verification dataset[C]// Proceedings of the 2022 Workshop on Multi-Modal Fact Checking and Hate-Speech Detection co-located with 36th AAAI Conference on Artificial Intelligence. Aachen: CEUR-WS.org, 2022: No.18. |
| [4] | WU Y, ZHAN P, ZHANG Y, et al. Multimodal fusion with co-attention networks for fake news detection[C]// Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021. Stroudsburg: ACL, 2021: 2560-2569. |
| [5] | QIAN S, WANG J, HU J, et al. Hierarchical multi-modal contextual attention network for fake news detection[C]// Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2021: 153-162. |
| [6] | RADFORD A, KIM J W, HALLACY C, et al. Learning transferable visual models from natural language supervision[C]// Proceedings of the 38th International Conference on Machine Learning. New York: JMLR.org, 2021: 8748-8763. |
| [7] | THORNE J, VLACHOS A, CHRISTODOULOPOULOS C, et al. FEVER: a large-scale dataset for fact extraction and verification[C]// Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers). Stroudsburg: ACL, 2018: 809-819. |
| [8] | NIE Y, CHEN H, BANSAL M. Combining fact extraction and verification with neural semantic matching networks[C]// Proceedings of the 33rd AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2019: 6859-6866. |
| [9] | NIE Y, WANG S, BANSAL M. Revealing the importance of semantic retrieval for machine reading at scale[C]// Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Stroudsburg: ACL, 2019: 2553-2566. |
| [10] | CHEN J, ZHANG R, GUO J, et al. GERE: generative evidence retrieval for fact verification[C]// Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2022: 2184-2189. |
| [11] | LIU Z, XIONG C, SUN M, et al. Fine-grained fact verification with kernel graph attention network[C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2020: 7342-7351. |
| [12] | HANSELOWSKI A, ZHANG H, LI Z, et al. UKP-Athene: multi-sentence textual entailment for claim verification[C]// Proceedings of the 1st Workshop on Fact Extraction and VERification. Stroudsburg: ACL, 2018: 103-108. |
| [13] | FAJCIK M, MOTLICEK P, SMRZ P. Claim-Dissector: an interpretable fact-checking system with joint re-ranking and veracity prediction[C]// Findings of the Association for Computational Linguistics: ACL 2023. Stroudsburg: ACL, 2023: 10184-10205. |
| [14] | SANTOSH T Y S S, VISHAL G, SAHA A, et al. AttentiveChecker: a bi-directional attention flow mechanism for fact verification[C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Stroudsburg: ACL, 2019: 2218-2222. |
| [15] | ZHOU J, HAN X, YANG C, et al. GEAR: graph-based evidence aggregating and reasoning for fact verification[C]// Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2019: 892-901. |
| [16] | LEE N, LI B Z, WANG S, et al. Language models as fact checkers?[C]// Proceedings of the 3rd Workshop on Fact Extraction and VERification. Stroudsburg: ACL, 2020: 36-41. |
| [17] | KOTONYA N, TONI F. Explainable automated fact-checking: a survey[C]// Proceedings of the 28th International Conference on Computational Linguistics. [S.l.]: International Committee on Computational Linguistics, 2020: 5430-5443. |
| [18] | ROY A, EKBAL A. MulCoB-MulFav: multimodal content based multilingual fact verification[C]// Proceedings of the 2021 International Joint Conference on Neural Networks. Piscataway: IEEE, 2021: 1-8. |
| [19] | DHANKAR A, ZAÏANE O, BOLDUC F. UofA-Truth at Factify 2022: a simple approach to multi-modal fact-checking[C]// Proceedings of the 2022 Workshop on Multi-Modal Fake News and Hate-Speech Detection co-located with the 36th AAAI Conference on Artificial Intelligence. Aachen: CEUR-WS.org, 2022: No.10. |
| [20] | DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional Transformers for language understanding[C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Stroudsburg: ACL, 2019: 4171-4186. |
| [21] | HAN K, XIAO A, WU E, et al. Transformer in Transformer[C]// Proceedings of the 35th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2021: 15908-15919. |
| [22] | LIU Y, OTT M, GOYAL N, et al. RoBERTa: a robustly optimized BERT pretraining approach[EB/OL]. [2025-07-14].. |
| [23] | ARNAB A, DEHGHANI M, HEIGOLD G, et al. ViViT: a video vision Transformer[C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 6816-6826. |
| [24] | THECKEDATH D, SEDAMKAR R. Detecting affect states using VGG16, ResNet50 and SE-ResNet50 networks[J]. SN Computer Science, 2020, 1(2): No.79. |
| [25] | ZHANG F, LIU J, XIE J, et al. ESCNet: entity-enhanced and stance checking network for multi-modal fact-checking[C]// Proceedings of the ACM Web Conference 2024. New York: ACM, 2024: 2429-2440. |
| [26] | CHEN T C, TANG C W, THOMAS C. MetaSumPerceiver: multimodal multi-document evidence summarization for fact-checking[C]// Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2024: 8742-8757. |
| [27] | CEKINEL R F, KARAGOZ P, ÇÖLTEKIN Ç. Multimodal fact-checking with vision language models: a probing classifier based solution with embedding strategies[C]// Proceedings of the 31st International Conference on Computational Linguistics. Stroudsburg: ACL, 2025: 4622-4633. |
| [1] | Hao LIANG, Shaojie QIAO. Complex query-based question-answering model integrating bidirectional sequence embeddings [J]. Journal of Computer Applications, 2026, 46(4): 1096-1103. |
| [2] | Zuxi ZHANG, Zhancheng ZHANG, Fuyuan HU. Local and long-range temporal complementary modeling for video action recognition [J]. Journal of Computer Applications, 2026, 46(3): 758-766. |
| [3] | Peirong SHAO, Suzhen LIN, Yanbo WANG. Human-centric detail-enhanced virtual try-on method [J]. Journal of Computer Applications, 2026, 46(3): 915-923. |
| [4] | Hanqing LIU, Guoming SANG, Yijia ZHANG. Remote sensing image captioning model combining dense multi-scale feature fusion and feature knowledge-enhanced Transformer [J]. Journal of Computer Applications, 2026, 46(3): 741-749. |
| [5] | Junrui WU, Jiangchuan YANG, Haisheng YU, Sai ZOU, Wenyong WANG. Performance evaluation method for deterministic networks based on complex-enhanced attention graph neural network [J]. Journal of Computer Applications, 2026, 46(2): 505-517. |
| [6] | Feng HAN, Yongfeng BU, Haoxiang LIANG, Shuwen HUANG, Zhaoyang ZHANG, Shijie SUN. Vehicle trajectory anomaly detection based on multi-level spatio-temporal interaction dependency [J]. Journal of Computer Applications, 2026, 46(2): 604-612. |
| [7] | Ming LI, Mengqi WANG, Aili ZHANG, Hua REN, Yuqiang DOU. Image steganography method based on conditional generative adversarial networks and hybrid attention mechanism [J]. Journal of Computer Applications, 2026, 46(2): 475-484. |
| [8] | Sizhong ZHANG, Jianyang LIU, Linfeng LI. Action quality assessment model based on trajectory-guided perceptual learning with X3D [J]. Journal of Computer Applications, 2026, 46(2): 555-563. |
| [9] | Jinjiao LIN, Canshun ZHANG, Shuya CHEN, Tianxin WANG, Jian LIAN, Yonghui XU. Vehicle insurance fraud detection method based on improved graph attention network [J]. Journal of Computer Applications, 2026, 46(2): 437-444. |
| [10] | Jincheng FU, Shiyou YANG. Short-term wind power prediction using hybrid model based on Bayesian optimization and feature fusion [J]. Journal of Computer Applications, 2026, 46(2): 652-658. |
| [11] | Rifeng ZHANG, Guangming LI, Yurong OUYANG. Low-light image enhancement network guided by reflection prior map [J]. Journal of Computer Applications, 2026, 46(2): 546-554. |
| [12] | Qianhui XU, Ke NIU, Shunzhe ZHU, Lin SHI, Jun LI. GAB3D-SEVSN: enhanced video steganography model via invertible neural network [J]. Journal of Computer Applications, 2026, 46(2): 467-474. |
| [13] | Hu LUO, Mingshu ZHANG. Rumor detection method based on cross-modal attention mechanism and contrastive learning [J]. Journal of Computer Applications, 2026, 46(2): 361-367. |
| [14] | Lifang WANG, Wenjing REN, Xiaodong GUO, Rongguo ZHANG, Lihua HU. Trident generative adversarial network for low-dose CT image denoising [J]. Journal of Computer Applications, 2026, 46(1): 270-279. |
| [15] | Yanan LI, Mengyang GUO, Guojun DENG, Yunfeng CHEN, Jianji REN, Yongliang YUAN. Method for life prediction of parallel branching engine based on multi-modal fusion features [J]. Journal of Computer Applications, 2026, 46(1): 305-313. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||