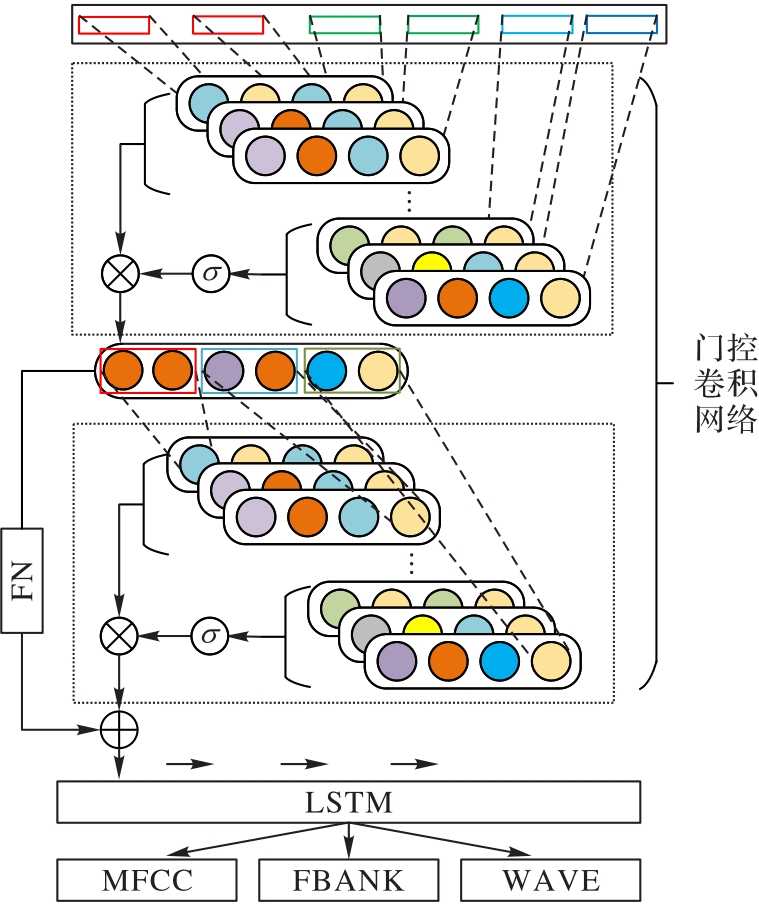
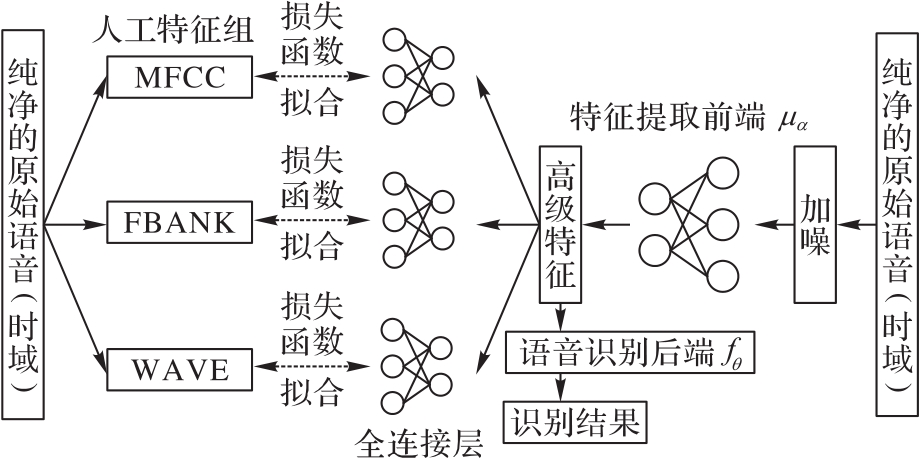
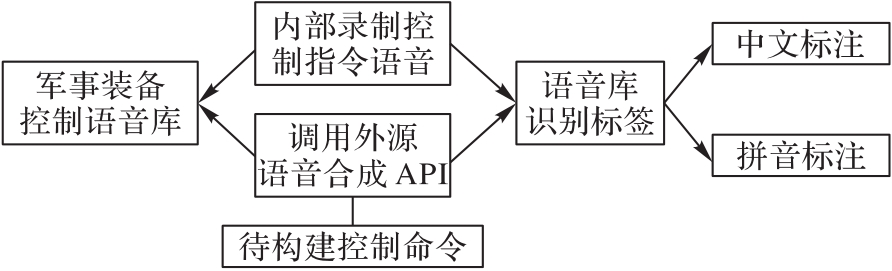
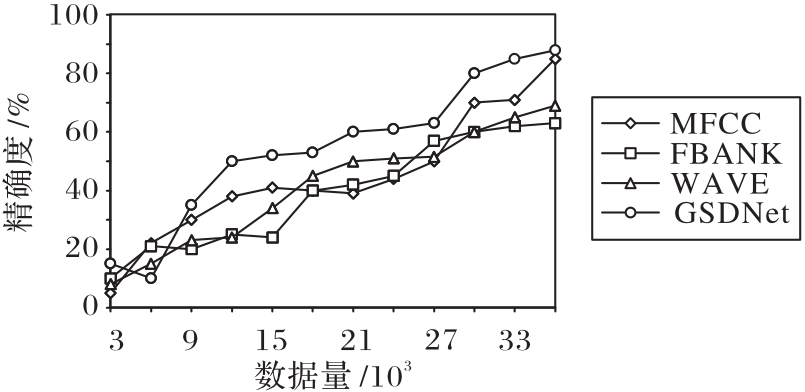
| 1 |
HE Y Z, SAINATH T N, PRABHAVALKAR R, et al. Streaming end-to-end speech recognition for mobile devices [C]// Proceedings of the 2019 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2019: 6381-6385. 10.1109/icassp.2019.8682336
|
| 2 |
JUANG B H, RABINER L R. Hidden Markov models for speech recognition[J]. Technometrics, 1991, 33(3): 251-272. 10.1080/00401706.1991.10484833
|
| 3 |
GRAVES A, SCHMIDHUBER J. Framewise phoneme classification with bidirectional LSTM and other neural network architectures[J]. Neural Networks, 2005, 18(5/6): 602-610. 10.1016/j.neunet.2005.06.042
|
| 4 |
HINTON G, DENG L, YU D, et al. Deep neural networks for acoustic modeling in speech recognition: the shared views of four research groups[J]. IEEE Signal Processing Magazine, 2012, 29(6): 82-97. 10.1109/msp.2012.2205597
|
| 5 |
CHAN W, JAITLY N, LE Q, et al. Listen, attend and spell: a neural network for large vocabulary conversational speech recognition [C]// Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2016: 4960-4964. 10.1109/icassp.2016.7472621
|
| 6 |
GRAVES A, FERNÁNDEZ S, GOMEZ F, et al. Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks [C]// Proceedings of the 23rd International Conference on Machine Learning. New York: ACM, 2006: 369-376. 10.1145/1143844.1143891
|
| 7 |
GRAVES A. Sequence transduction with recurrent neural networks[EB/OL]. (2012-11-14) [2021-05-01]. . 10.1007/978-3-642-24797-2_3
|
| 8 |
JAITLY N, SUSSILLO D, LE Q V, et al. A neural transducer[EB/OL]. (2016-08-04) [2021-05-01]. .
|
| 9 |
CHIU C C, RAFFEL C. Monotonic chunkwise attention[EB/OL]. (2018-02-23) [2021-05-01]. .
|
| 10 |
ZHANG Z X, GEIGER J, POHJALAINEN J, et al. Deep learning for environmentally robust speech recognition: an overview of recent developments[J]. ACM Transactions on Intelligent Systems and Technology, 2018, 9(5): No.49. 10.1145/3178115
|
| 11 |
柏财通,高志强,李爱,等.基于门控网络的军事装备控制指令语音识别研究[J].计算机工程, 2021, 47(7): 301-306. 10.19678/j.issn.1000-3428.0058590
|
|
BAI C T, GAO Z Q, LI A, et al. Research on voice recognition of military equipment control commands based on gated network[J]. Computer Engineering, 2021, 47(7): 301-306. 10.19678/j.issn.1000-3428.0058590
|
| 12 |
ZHAO X J, SHAO Y, WANG D L. CASA-based robust speaker identification[J]. IEEE Transactions on Audio, Speech, and Language Processing, 2012, 20(5): 1608-1616. 10.1109/tasl.2012.2186803
|
| 13 |
DAUPHIN Y N, FAN A, AULI M, et al. Language modeling with gated convolutional networks [C]// Proceedings of the 34th International Conference on Machine Learning. New York: JMLR.org, 2017: 933-941.
|
| 14 |
RAVANELLI M, OMOLOGO M. Contaminated speech training methods for robust DNN-HMM distant speech recognition [C]// Proceedings of the Interspeech 2015. [S.l.]: International Speech Communication Association, 2015: 756-760. 10.21437/interspeech.2015-251
|
| 15 |
RAVANELLI M, ZHONG J Y, PASCUAL S, et al. Multi-task self-supervised learning for robust speech recognition [C]// Proceedings of the 2020 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2020: 6989-6993. 10.1109/icassp40776.2020.9053569
|
| 16 |
ALLEN J B, BERKLEY D A. Image method for efficiently simulating small-room acoustics[J]. The Journal of the Acoustical Society of America, 1979, 65(4): 943-950. 10.1121/1.382599
|
| 17 |
HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 770-778. 10.1109/cvpr.2016.90
|
| 18 |
HOCHREITER S, SCHMIDHUBER J. Long short-term memory[J]. Neural Computation, 1997, 9(8): 1735-1780. 10.1162/neco.1997.9.8.1735
|
| 19 |
POLS L C W. Spectral analysis and identification of Dutch vowels in monosyllabic words[D]. Amsterdam: University of Amsterdam, 1977: 152.
|
| 20 |
KINGMA D P, BA J L. Adam: a method for stochastic optimization[EB/OL]. (2017-01-30) [2021-05-01]. .
|
| 21 |
PASZKE A, GROSS S, MASSA F, et al. PyTorch: an imperative style, high-performance deep learning library[C/OL]// Proceedings of the 33rd Conference on Neural Information Processing Systems. [2021-05-01]. . 10.7551/mitpress/11474.003.0014
|
| 22 |
WANG D, ZHANG X W. THCHS-30: a free Chinese speech corpus[EB/OL]. (2015-12-10) [2021-05-01]. .
|
| 23 |
BU H, DU J Y, NA X Y, et al. AISHELL-1: an open-source Mandarin speech corpus and a speech recognition baseline [C]// Proceedings of the 20th Conference of the Oriental Chapter of the International Coordinating Committee on Speech Databases and Speech I/O Systems and Assessment. Piscataway: IEEE, 2017: 1-5. 10.1109/icsda.2017.8384449
|
| 24 |
ST-CMDS- 20170001_1, Free ST Chinese Mandarin corpus[DS/OL]. [2021-05-01]. .
|
| 25 |
KIM S, HORI T, WATANABE S. Joint CTC-attention based end-to-end speech recognition using multi-task learning [C]// Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2017: 4835-4839. 10.1109/icassp.2017.7953075
|
| 26 |
KLAKOW D, PETERS J. Testing the correlation of word error rate and perplexity[J]. Speech Communication, 2002, 38(1/2): 19-28. 10.1016/s0167-6393(01)00041-3
|
| 27 |
BA J L, KIROS J R, HINTON G E. Layer normalization[EB/OL]. (2016-07-21) [2021-05-01]. .
|
| 28 |
HINTON G E, SRIVASTAVA N, KRIZHEVSKY A, et al. Improving neural networks by preventing co-adaptation of feature detectors[EB/OL]. (2012-07-03) [2021-05-01]. .
|