


《计算机应用》唯一官方网站 ›› 2022, Vol. 42 ›› Issue (12): 3831-3840.DOI: 10.11772/j.issn.1001-9081.2021101730
• 网络空间安全 • 上一篇
收稿日期:2021-10-09
修回日期:2022-01-24
接受日期:2022-02-21
发布日期:2022-04-18
出版日期:2022-12-10
通讯作者:
雷靖玮
作者简介:伊鹏(1977—),男,河南郑州人,研究员,博士,主要研究方向:入侵检测、新型网络体系结构基金资助:
Jingwei LEI( ), Peng YI, Xiang CHEN, Liang WANG, Ming MAO
), Peng YI, Xiang CHEN, Liang WANG, Ming MAO
Received:2021-10-09
Revised:2022-01-24
Accepted:2022-02-21
Online:2022-04-18
Published:2022-12-10
Contact:
Jingwei LEI
About author:YI Peng, born in 1977, Ph. D., research fellow. His research interests include intrusion detection, new network architecture.Supported by:摘要:
针对传统静态检测及动态检测方法无法应对基于大量混淆及未知技术的PDF文档攻击的缺陷,提出了一个基于系统调用和数据溯源技术的新型检测模型NtProvenancer。首先,使用系统调用捕获工具收集文档执行时产生的系统调用记录;其次,利用数据溯源技术构建基于系统调用的数据溯源图;而后,用图的路径筛选算法提取系统调用特征片段进行检测。实验数据集由528个良性PDF文档与320个恶意PDF文档组成。在Adobe Reader上展开测试,并使用词频-逆文档频率(TF-IDF)及PROVDETECTOR稀有度算法替换所提出的图的关键点算法来进行对比实验。结果表明NtProvenancer在精确率和F1分数等多项指标上均优于对比模型。在最佳参数设置下,所提模型的文档训练与检测阶段的平均用时分别为251.51 ms以及60.55 ms,同时误报率低于5.22%,F1分数达到0.989。可见NtProvenancer是一种高效实用的PDF文档检测模型。
中图分类号:
雷靖玮, 伊鹏, 陈祥, 王亮, 毛明. 基于系统调用和数据溯源的PDF文档检测模型[J]. 计算机应用, 2022, 42(12): 3831-3840.
Jingwei LEI, Peng YI, Xiang CHEN, Liang WANG, Ming MAO. PDF document detection model based on system calls and data provenance[J]. Journal of Computer Applications, 2022, 42(12): 3831-3840.
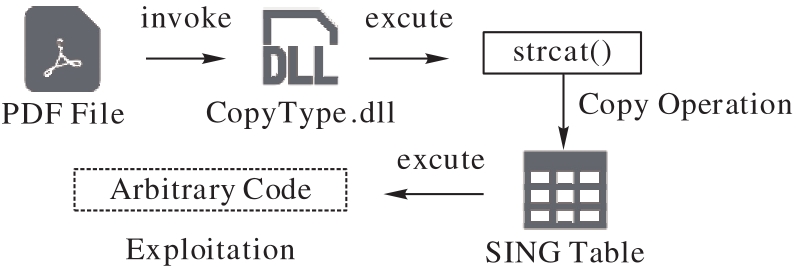
图1 CVE-2010-2883漏洞利用示意图
Fig. 1 Schematic diagram of exploiting CVE-2010-2883 vulnerability
| 受影响版本 | 编号 | 漏洞成因 | 危害影响 |
|---|---|---|---|
Acrobat Reader 2017 Acrobat Reader 2020 Acrobat Reader DC Adobe Acrobat Reader 2017 Adobe Acrobat Reader 2020 Adobe Acrobat Reader DC | CVE-2018-4901 | 缓冲区溢出 | 任意代码执行 |
| CVE-2019-8197 | 缓冲区溢出 | 任意代码执行 | |
| CVE-2020-24426 | 内存越界读 | 内存泄漏 | |
| CVE-2020-24427 | 输入验证不正确 | 内存泄漏 | |
| CVE-2020-24430 | UAF | 任意代码执行 | |
| CVE-2020-24431 | 安全功能绕过 | 动态库注入 | |
| CVE-2020-24433 | 访问控制不当 | 提权 | |
| CVE-2020-24434 | 内存越界读 | 内存泄漏 | |
| CVE-2020-24436 | 内存越界写 | 任意代码执行 | |
| CVE-2020-24437 | UAF | 任意代码执行 | |
| CVE-2020-24438 | UAF | 内存泄漏 | |
| CVE-2021-21038 | 内存越界写 | 任意代码执行 | |
| CVE-2021-21044 | 内存越界写 | 任意代码执行 | |
| CVE-2021-21086 | 内存越界写 | 任意代码执行 | |
| CVE-2021-28550 | UAF | 任意代码执行 | |
| CVE-2021-28553 | UAF | 任意代码执行 | |
| CVE-2021-28557 | 内存越界读 | 内存泄漏 | |
| CVE-2021-28560 | 缓冲区溢出 | 任意代码执行 | |
| CVE-2021-28562 | UAF | 任意代码执行 | |
| CVE-2021-28564 | 内存越界写 | 任意代码执行 | |
| CVE-2021-28565 | 内存越界读 | 内存泄漏 |
表1 近年AAR漏洞信息列表
Tab. 1 List of AAR vulnerabilities in recent years
| 受影响版本 | 编号 | 漏洞成因 | 危害影响 |
|---|---|---|---|
Acrobat Reader 2017 Acrobat Reader 2020 Acrobat Reader DC Adobe Acrobat Reader 2017 Adobe Acrobat Reader 2020 Adobe Acrobat Reader DC | CVE-2018-4901 | 缓冲区溢出 | 任意代码执行 |
| CVE-2019-8197 | 缓冲区溢出 | 任意代码执行 | |
| CVE-2020-24426 | 内存越界读 | 内存泄漏 | |
| CVE-2020-24427 | 输入验证不正确 | 内存泄漏 | |
| CVE-2020-24430 | UAF | 任意代码执行 | |
| CVE-2020-24431 | 安全功能绕过 | 动态库注入 | |
| CVE-2020-24433 | 访问控制不当 | 提权 | |
| CVE-2020-24434 | 内存越界读 | 内存泄漏 | |
| CVE-2020-24436 | 内存越界写 | 任意代码执行 | |
| CVE-2020-24437 | UAF | 任意代码执行 | |
| CVE-2020-24438 | UAF | 内存泄漏 | |
| CVE-2021-21038 | 内存越界写 | 任意代码执行 | |
| CVE-2021-21044 | 内存越界写 | 任意代码执行 | |
| CVE-2021-21086 | 内存越界写 | 任意代码执行 | |
| CVE-2021-28550 | UAF | 任意代码执行 | |
| CVE-2021-28553 | UAF | 任意代码执行 | |
| CVE-2021-28557 | 内存越界读 | 内存泄漏 | |
| CVE-2021-28560 | 缓冲区溢出 | 任意代码执行 | |
| CVE-2021-28562 | UAF | 任意代码执行 | |
| CVE-2021-28564 | 内存越界写 | 任意代码执行 | |
| CVE-2021-28565 | 内存越界读 | 内存泄漏 |
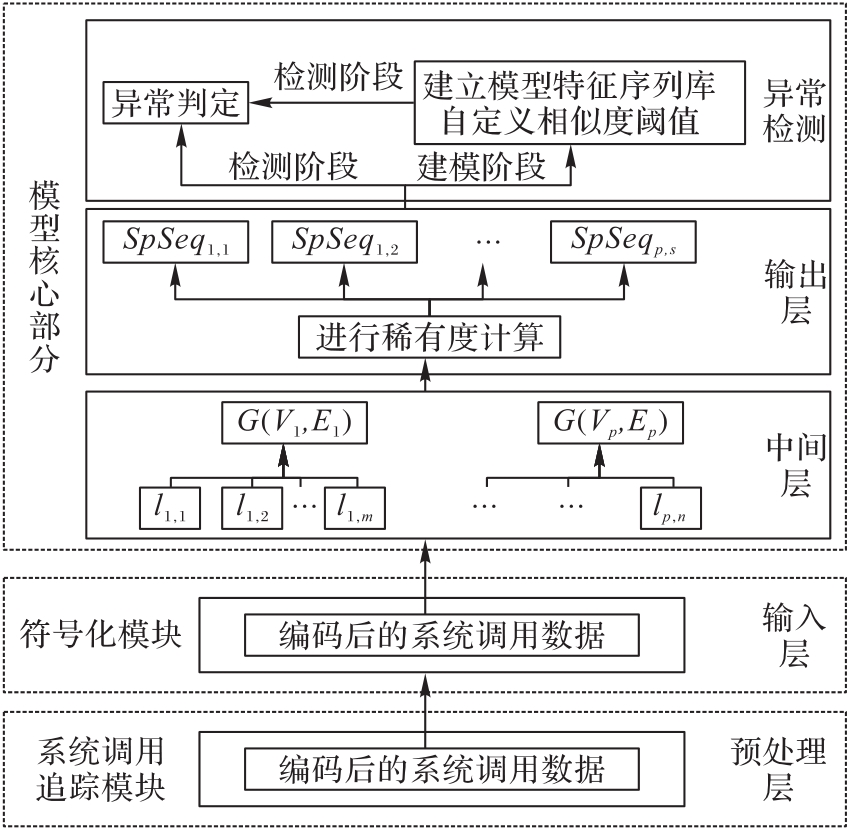
图2 本文检测模型架构
Fig.2 Framework of the proposed detection model
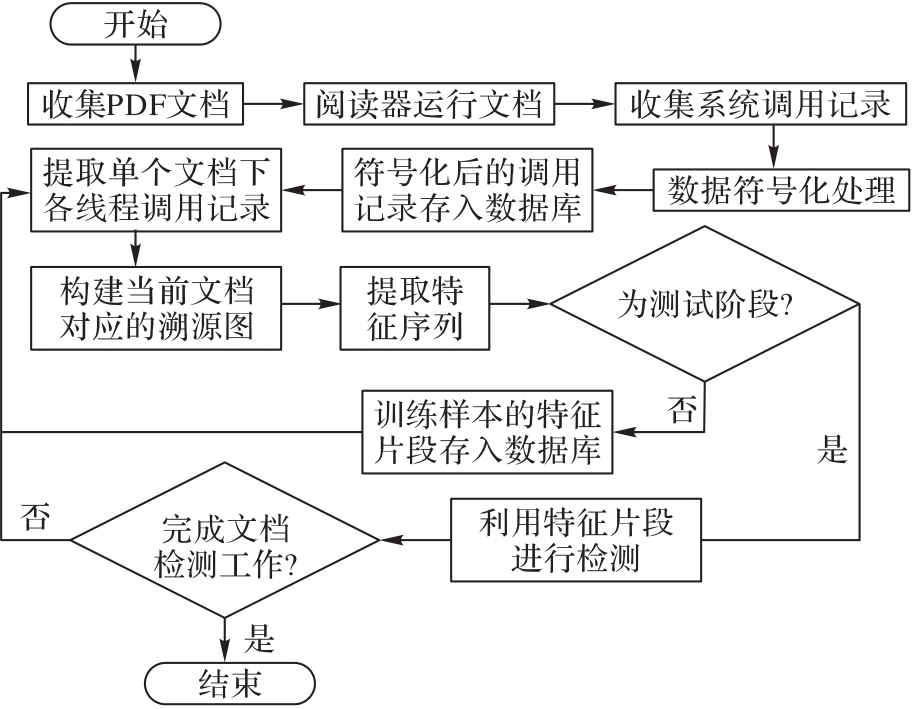
图3 文档检测流程
Fig.3 Flow chart of document detection
| K值 | 线程调用序列文件大小 |
|---|---|
| 1 | |
| 4 | |
| 8 | |
| 12 | |
| 20 |
表2 K值选取方法
Tab.2 Selection method of K-value
| K值 | 线程调用序列文件大小 |
|---|---|
| 1 | |
| 4 | |
| 8 | |
| 12 | |
| 20 |
| 真实标签 | 预测结果 | |
|---|---|---|
| 恶意 | 良性 | |
| 恶意 | TP | FN |
| 良性 | FP | TN |
表3 评价指标具体含义
Tab.3 Specific meanings of evaluation indicators
| 真实标签 | 预测结果 | |
|---|---|---|
| 恶意 | 良性 | |
| 恶意 | TP | FN |
| 良性 | FP | TN |

图4 三种算法的模型检测结果比较
Fig. 4 Model detection result comparison of three algorithms
| 阈值 | 路径筛选算法 | 精确率 | 召回率 | F1分数 |
|---|---|---|---|---|
| 0.95 | TF-IDF | 0.943 | 0.828 | 0.882 |
| PROVDETECTOR | 0.960 | 0.984 | 0.972 | |
| NtProvancer | 0.988 | 0.988 | 0.988 | |
| 0.96 | TF-IDF | 0.914 | 0.925 | 0.919 |
| PROVDETECTOR | 0.955 | 0.994 | 0.974 | |
| NtProvancer | 0.979 | 1.000 | 0.989 | |
| 0.97 | TF-IDF | 0.886 | 0.950 | 0.917 |
| PROVDETECTOR | 0.927 | 0.994 | 0.959 | |
| NtProvancer | 0.973 | 1.000 | 0.986 | |
| 0.98 | TF-IDF | 0.881 | 0.972 | 0.924 |
| PROVDETECTOR | 0.917 | 1.000 | 0.957 | |
| NtProvancer | 0.967 | 1.000 | 0.983 | |
| 0.99 | TF-IDF | 0.851 | 0.997 | 0.918 |
| PROVDETECTOR | 0.907 | 1.000 | 0.951 | |
| NtProvancer | 0.961 | 1.000 | 0.980 |
表4 三种评价指标的对比结果
Tab. 4 Comparison results of three evaluation indicators
| 阈值 | 路径筛选算法 | 精确率 | 召回率 | F1分数 |
|---|---|---|---|---|
| 0.95 | TF-IDF | 0.943 | 0.828 | 0.882 |
| PROVDETECTOR | 0.960 | 0.984 | 0.972 | |
| NtProvancer | 0.988 | 0.988 | 0.988 | |
| 0.96 | TF-IDF | 0.914 | 0.925 | 0.919 |
| PROVDETECTOR | 0.955 | 0.994 | 0.974 | |
| NtProvancer | 0.979 | 1.000 | 0.989 | |
| 0.97 | TF-IDF | 0.886 | 0.950 | 0.917 |
| PROVDETECTOR | 0.927 | 0.994 | 0.959 | |
| NtProvancer | 0.973 | 1.000 | 0.986 | |
| 0.98 | TF-IDF | 0.881 | 0.972 | 0.924 |
| PROVDETECTOR | 0.917 | 1.000 | 0.957 | |
| NtProvancer | 0.967 | 1.000 | 0.983 | |
| 0.99 | TF-IDF | 0.851 | 0.997 | 0.918 |
| PROVDETECTOR | 0.907 | 1.000 | 0.951 | |
| NtProvancer | 0.961 | 1.000 | 0.980 |
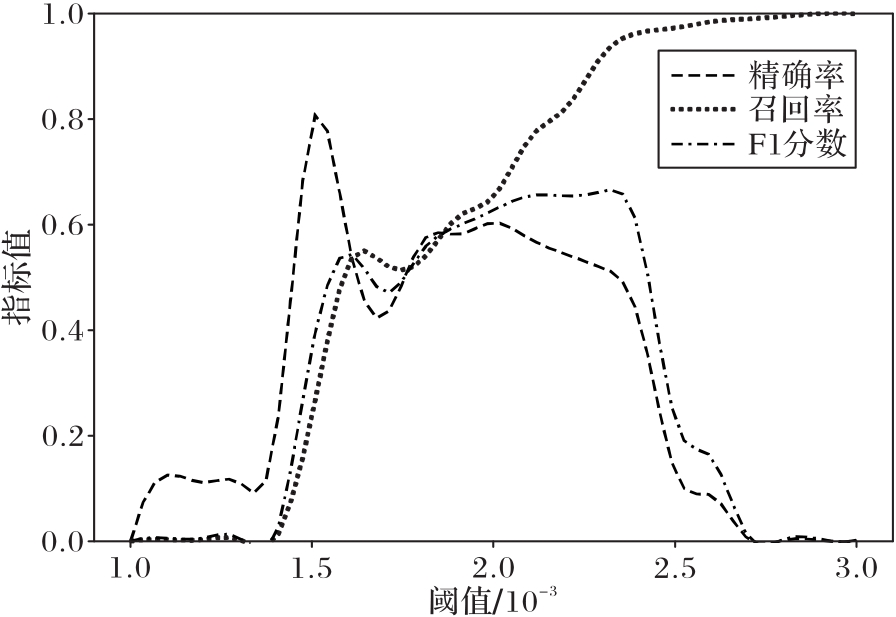
图5 稀有度均值法下模型的检测结果
Fig.5 Model detection results under rarity mean method

图6 线程调用序列中的系统调用稀有度分布
Fig.6 System call rarity distribution in sequences of thread calls
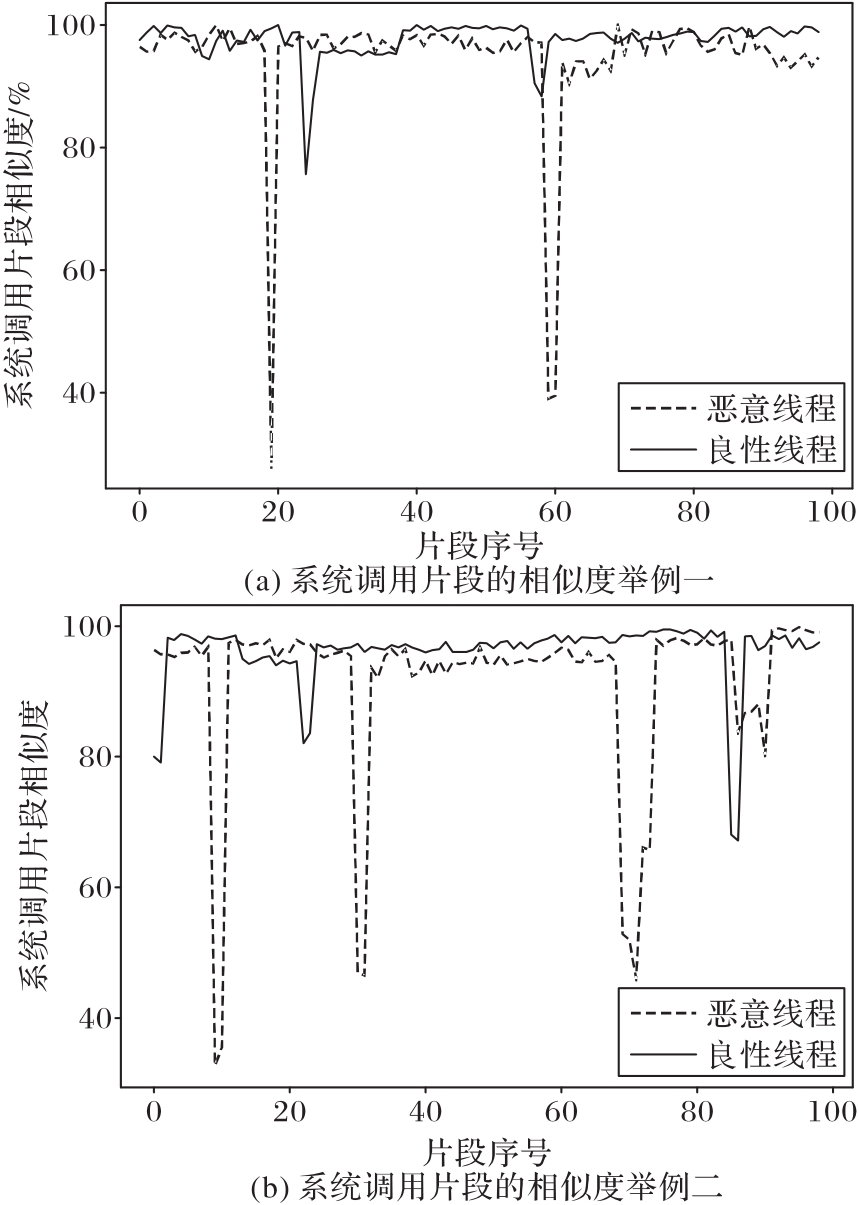
图7 两例恶意线程与良性线程的系统调用片段相似度比较
Fig. 7 Two examples of similarity among system call fragments between malicious thread and benign one
| 用时情况 | 训练阶段 | 检测阶段 |
|---|---|---|
| 共计 | 251.51 | 60.55 |
| 线程调用序列提取用时平均用时 | 19.11 | 17.83 |
| 构建溯源图平均用时 | 7.93 | 5.84 |
| 特征序列提取平均用时 | 26.50 | 23.57 |
| 构建特征库/异常检测平均用时 | 197.97 | 13.31 |
表5 训练与检测阶段的用时情况 (ms)
Tab.5 Time cost of training and detection stages
| 用时情况 | 训练阶段 | 检测阶段 |
|---|---|---|
| 共计 | 251.51 | 60.55 |
| 线程调用序列提取用时平均用时 | 19.11 | 17.83 |
| 构建溯源图平均用时 | 7.93 | 5.84 |
| 特征序列提取平均用时 | 26.50 | 23.57 |
| 构建特征库/异常检测平均用时 | 197.97 | 13.31 |
| 1 | KASPERSKY. Kaspersky Security Bulletin 2015[R/OL]. [2020-09-16].. 10.1016/s1353-4858(15)30032-5 |
| 2 | CORONA I, MAIORCA D, ARIU D, et al. Lux0r: detection of malicious PDF-embedded JavaScript code through discriminant analysis of API references[C]// Proceedings of the 2014 ACM Artificial Intelligent and Security Workshop. New York: ACM, 2014: 47-57. 10.1145/2666652.2666657 |
| 3 | LASKOV P, ŠRNDIĆ N. Static detection of malicious JavaScript-bearing PDF documents[C]// Proceedings of the 27th Annual Computer Security Applications Conference. New York: ACM, 2011: 373-382. 10.1145/2076732.2076785 |
| 4 | LU X, ZHUGE J W, WANG R Y, et al. De-obfuscation and detection of malicious PDF files with high accuracy[C]// Proceedings of the 46th Hawaii International Conference on System Sciences. Piscataway: IEEE, 2013: 4890-4899. 10.1109/hicss.2013.166 |
| 5 | MAIORCA D, ARIU D, CORONA I, et al. A structural and content-based approach for a precise and robust detection of malicious PDF files[C]// Proceedings of the 2015 International Conference on Information Systems Security and Privacy. Piscataway: IEEE, 2015: 27-36. 10.5220/0005264400270036 |
| 6 | MAIORCA D, ARIU D, CORONA I, et al. An evasion resilient approach to the detection of malicious PDF files[C]// Proceedings of the 2015 International Conference on Information Systems Security and Privacy, CCIS 576. Cham: Springer, 2015: 68-85. |
| 7 | LIU L P, HE X H, LIU L, et al. Capturing the symptoms of malicious code in electronic documents by file's entropy signal combined with machine learning[J]. Applied Soft Computing, 2019, 82: No.105598. 10.1016/j.asoc.2019.105598 |
| 8 | SMUTZ C, STAVROU A. Malicious PDF detection using metadata and structural features[C]// Proceedings of the 28th Annual Computer Security Applications Conference. New York: ACM, 2012: 239-248. 10.1145/2420950.2420987 |
| 9 | ŠRNDIĆ N, LASKOV P. Detection of malicious PDF files based on hierarchical document structure[C]// Proceedings of the 20th Annual Network and Distributed System Security Symposium. Reston, VA: Internet Society, 2016: 1-16. 10.1186/s13635-016-0045-0 |
| 10 | SNOW K Z, KRISHNAN S, MONROSE F, et al. SHELLOS: enabling fast detection and forensic analysis of code injection attacks[C]// Proceedings of the 20th USENIX Security Symposium. Berkeley: USENIX Association, 2011: 1-16. 10.1109/ms.2011.67 |
| 11 | TZERMIAS Z, SYKIOTAKIS G, POLYCHRONAKIS M, et al. Combining static and dynamic analysis for the detection of malicious documents[C]// Proceedings of the 4th European Workshop on System Security. New York: ACM, 2011: No.4. 10.1145/1972551.1972555 |
| 12 | CARMONY C, ZHANG M, HU X C, et al. Extract me if you can: abusing PDF parsers in malware detectors[C]// Proceedings of the 20th Annual Network and Distributed System Security Symposium. Reston, VA: Internet Society, 2016: 1-15. 10.14722/ndss.2016.23483 |
| 13 | MAIORCA D, CORONA I, GIACINTO G. Looking at the bag is not enough to find the bomb: an evasion of structural methods for malicious PDF files detection[C]// Proceedings of the 8th ACM SIGSAC Symposium on Information, Computer and Communications Security. New York: ACM, 2013: 119-130. 10.1145/2484313.2484327 |
| 14 | HERATH J D, YANG P, YAN G H. Real-time evasion attacks against deep learning-based anomaly detection from distributed system logs[C]// Proceedings of the 11th ACM Conference on Data and Application Security and Privacy. New York: ACM, 2021: 29-40. 10.1145/3422337.3447833 |
| 15 | FLEURY N, DUBRUNQUEZ T, ALOUANI I. PDF-malware: an overview on threats, detection and evasion attacks[EB/OL]. (2021-07-27) [2021-10-15].. |
| 16 | 马洪亮,王伟,韩臻. 混淆恶意JavaScript代码的检测与反混淆方法研究[J]. 计算机学报, 2017, 40(7): 1699-1713. 10.11897/SP.J.1016.2017.01699 |
| MA H L, WANG W, HAN Z. Detecting and de-obfuscating obfuscated malicious JavaScript code[J]. Chinese Journal of Computers, 2017, 40(7): 1699-1713. 10.11897/SP.J.1016.2017.01699 | |
| 17 | 王丽娜,谈诚,余荣威, 等. 针对数据泄露行为的恶意软件检测[J]. 计算机研究与发展, 2017, 54(7): 1537-1548. |
| WANG L N, TAN C, YU R W, et al. The malware detection based on data breach actions[J]. Journal of Computer Research and Development, 2017, 54(7): 1537-1548. | |
| 18 | JIANG J G, WANG C H, YU M, et al. NFDD: a dynamic malicious document detection method without manual feature dictionary[C]// Proceedings of the 2021 International Conference on Wireless Algorithms, Systems, and Applications, LNCS 12938. Cham: Springer, 2021: 147-159. |
| 19 | MANZANO F A. Adobe Reader X BMP/RLE heap corruption[R/OL]. (2012-12) [2021-07-30].. |
| 20 | 王伟平,柏军洋,张玉婵,等. 基于代码改写的JavaScript动态污点跟踪[J]. 清华大学学报(自然科学版), 2016, 56(9): 956-962, 968. |
| WANG W P, BAI J Y, ZHANG Y C, et al. Dynamic taint tracking in JavaScript using revised code[J]. Journal of Tsinghua University (Science and Technology), 2016, 56(9): 956-962, 968. | |
| 21 | LIU D P, WANG H N, STAVROU A. Detecting malicious Javascript in PDF through document instrumentation[C]// Proceedings of the 44th Annual IEEE/IFIP International Conference on Dependable Systems and Networks. Piscataway: IEEE, 2014: 100-111. 10.1109/dsn.2014.92 |
| 22 | WANG Q, HASSAN W U, LI D, et al. You are what you do: hunting stealthy malware via data provenance analysis[C]// Proceedings of the 27th Annual Network and Distributed System Security Symposium. Reston, VA: Internet Society, 2020: 1-17. 10.14722/ndss.2020.24167 |
| 23 | BRIDGES R A, GLASS-VANDERLAN T R, IANNACONE M D, et al. A survey of intrusion detection systems leveraging host data[J]. ACM Computing Surveys, 2020, 52(6): No.128. 10.1145/3344382 |
| [1] | 刘炜, 张聪, 佘维, 宋轩, 田钊. 基于Merkle山脉的数据可信溯源方法[J]. 《计算机应用》唯一官方网站, 2022, 42(9): 2765-2771. |
| [2] | 张学旺, 殷梓杰, 冯家琦, 叶财金, 付康. 基于区块链与可信计算的数据交易方案[J]. 计算机应用, 2021, 41(4): 939-944. |
| [3] | 蔡梦娟, 陈兴蜀, 金鑫, 赵成, 殷明勇. 基于硬件虚拟化的虚拟机进程代码分页式度量方法[J]. 计算机应用, 2018, 38(2): 305-309. |
| [4] | 李津津, 贾晓启, 杜海超, 王利朋. 基于虚拟化技术的有效提高系统可用性的方法[J]. 计算机应用, 2017, 37(4): 986-992. |
| [5] | 赵成, 陈兴蜀, 金鑫. 基于硬件虚拟化的虚拟机文件完整性监控[J]. 计算机应用, 2017, 37(2): 388-391. |
| [6] | 周登元, 李清宝, 张擂, 孔维亮. 基于虚拟机监控器的Windows剪贴板操作监控[J]. 计算机应用, 2016, 36(2): 511-515. |
| [7] | 吴瀛 江建慧. 基于进程轨迹最小熵长度的系统调用异常检测[J]. 计算机应用, 2012, 32(12): 3439-3444. |
| [8] | 马博 袁丁. 基于Linux驱动级内核访问监控技术研究与实现[J]. 计算机应用, 2009, 29(09): 2369-2374. |
| [9] | 何志 范明钰. 基于HSC的进程隐藏检测技术[J]. 计算机应用, 2008, 28(7): 1772-1775. |
| [10] | 赵文刚 钟乐海 张娅 杨金 邹海洋. 模糊窗口Markov链在IDS中的应用[J]. 计算机应用, 2008, 28(6): 1398-1400. |
| [11] | 张军 苏璞睿 冯登国 . 基于系统调用的入侵检测系统设计与实现[J]. 计算机应用, 2006, 26(9): 2137-2139. |
| [12] | 钱丽萍;汪立东. 一种评测应用程序实际性能开销的方法[J]. 计算机应用, 2006, 26(5): 1180-1182. |
| [13] | 蒋世忠; 杨进; 张英. 基于免疫原理与粗糙集理论的入侵检测方法[J]. 计算机应用, 2006, 26(5): 1077-1080. |
| [14] | 朱国强;刘真;李宗伯. 对计算机系统中程序行为的分析和研究[J]. 计算机应用, 2005, 25(12): 2739-2741. |
| [15] | 安景琦,刘贵全,钱权. 一种基于隐Markov模型的异常检测技术[J]. 计算机应用, 2005, 25(08): 1744-1746. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||