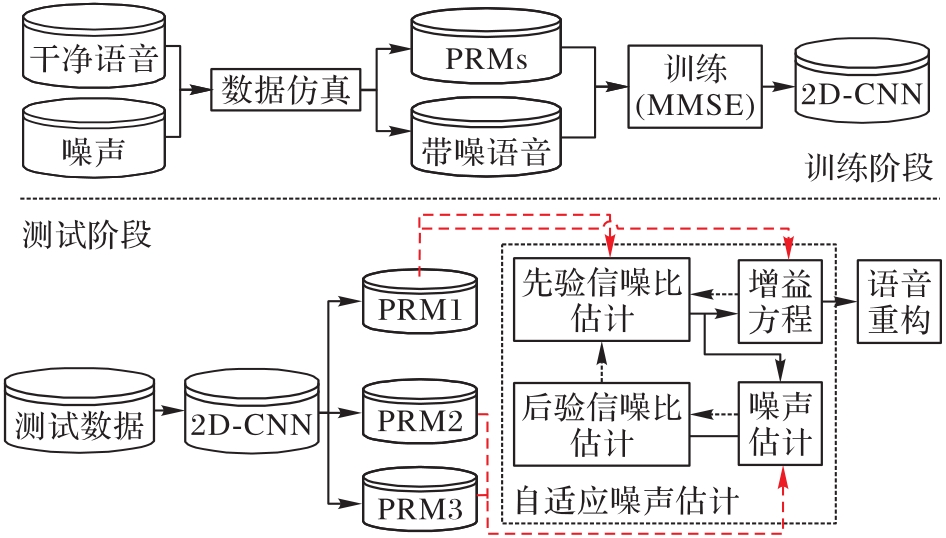
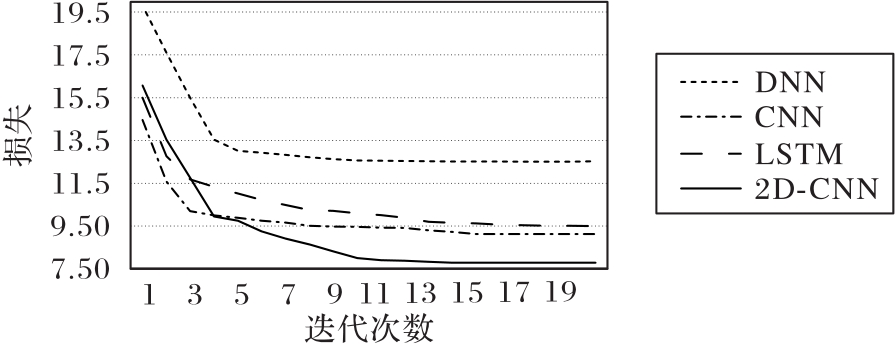
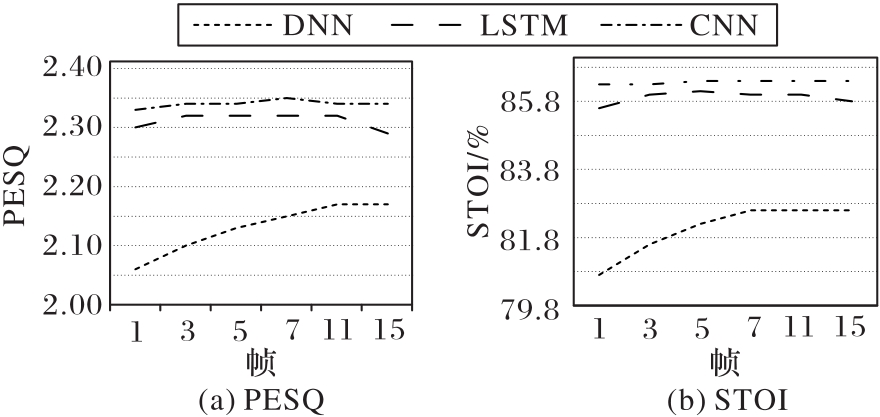
| 1 |
BROWN G J, COOKE M. Computational auditory scene analysis[J]. Computer Speech and Language, 1994, 8(4): 297-336. 10.1006/csla.1994.1016
|
| 2 |
吴镇扬,张子瑜,李想,等. 听觉场景分析的研究进展[J]. 电路与系统学报, 2001, 6(2): 68-73. 10.3969/j.issn.1007-0249.2001.02.015
|
|
WU Z Y, ZHANG Z Y, LI X, et al. The research advance of auditory scene analysis[J]. Journal of Circuits and Systems, 2001, 6(2): 68-73. 10.3969/j.issn.1007-0249.2001.02.015
|
| 3 |
CHANG J H, JO Q H, KIM D K, et al. Global soft decision employing support vector machine for speech enhancement[J]. IEEE Signal Processing Letters, 2009, 16(1): 57-60. 10.1109/lsp.2008.2008574
|
| 4 |
WILSON K W, RAJ B, SMARAGDIS P, et al. Speech denoising using nonnegative matrix factorization with priors[C]// Proceedings of the 2008 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2008: 4029-4032. 10.1109/icassp.2008.4518538
|
| 5 |
WILSON K W, RAJ B, SMARAGDIS P. Regularized non-negative matrix factorization with temporal dependencies for speech denoising[C]// Proceedings of the INTERSPEECH 2008. [S.l.]: International Speech Communication Association, 2008: 411-414. 10.21437/interspeech.2008-49
|
| 6 |
SCHMIDT M N, LARSEN J, HSIAO F T. Wind noise reduction using non-negative sparse coding[C]// Proceedings of the 2007 IEEE Workshop on Machine Learning for Signal Processing. Piscataway: IEEE, 2007: 431-436. 10.1109/mlsp.2007.4414345
|
| 7 |
WANG Y X, WANG D L. Towards scaling up classification-based speech separation[J]. IEEE Transactions on Audio, Speech, and Language Processing, 2013, 21(7): 1381-1390. 10.1109/tasl.2013.2250961
|
| 8 |
袁文浩,孙文珠,夏斌,等. 利用深度卷积神经网络提高未知噪声下的语音增强性能[J]. 自动化学报, 2018, 44(4): 751-759. 10.16383/j.aas.2018.c170001
|
|
YUAN W H, SUN W Z, XIA B, et al. Improving speech enhancement in unseen noise using deep convolutional neural network[J]. Acta Automatica Sinica, 2018, 44(4): 751-759. 10.16383/j.aas.2018.c170001
|
| 9 |
XU Y, DU J, DAI L R, et al. A regression approach to speech enhancement based on deep neural networks[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2015, 23(1): 7-19. 10.1109/taslp.2014.2364452
|
| 10 |
VINCENT E, GRIBONVAL R, FÉVOTTE C. Performance measurement in blind audio source separation[J]. IEEE Transactions on Audio, Speech, and Language Processing, 2006, 14(4): 1462-1469. 10.1109/tsa.2005.858005
|
| 11 |
WANG Y X, NARAYANAN A, WANG D L. On training targets for supervised speech separation[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2014, 22(12): 1849-1858. 10.1109/taslp.2014.2352935
|
| 12 |
PEARLMUTTER B A. Gradient calculations for dynamic recurrent neural networks: a survey[J]. IEEE Transactions on Neural Networks, 1995, 6(5): 1212-1228. 10.1109/72.410363
|
| 13 |
WENINGER F, EYBEN F, SCHULLER B. Single-channel speech separation with memory-enhanced recurrent neural networks[C]// Proceedings of the 2014 IEEE International Conference on Acoustics, Speech, and Signal Processing. Piscataway: IEEE, 2014: 3709-3713. 10.1109/icassp.2014.6854294
|
| 14 |
WENINGER F, HERSHEY J R, LE ROUX J, et al. Discriminatively trained recurrent neural networks for single-channel speech separation[C]// Proceedings of the 2014 IEEE Global Conference on Signal and Information Processing. Piscataway: IEEE, 2014: 577-581. 10.1109/globalsip.2014.7032183
|
| 15 |
TU Y H, DU J, LEE C H. 2D-to-2D mask estimation for speech enhancement based on fully convolutional neural network[C]// Proceedings of the 2020 IEEE International Conference on Acoustics, Speech, and Signal Processing. Piscataway: IEEE, 2020: 6664-6668. 10.1109/icassp40776.2020.9054615
|
| 16 |
COHEN I. Noise spectrum estimation in adverse environments: improved minima controlled recursive averaging[J]. IEEE Transactions on Speech and Audio Processing, 2003, 11(5): 466-475. 10.1109/tsa.2003.811544
|
| 17 |
屠彦辉. 复杂场景下基于深度学习的鲁棒性语音识别的研究[D]. 合肥:中国科学技术大学, 2019:111.
|
|
TU Y H. Research on robust speech recognition based on deep learning in adverse environment[D]. Hefei: University of Science and Technology of China, 2019: 111.
|
| 18 |
TANG H, HSU W N, GRONDIN F, et al. A study of enhancement, augmentation, and autoencoder methods for domain adaptation in distant speech recognition[C]// Proceedings of the INTERSPEECH 2018. [S.l.]: International Speech Communication Association, 2018: 2928-2932. 10.21437/interspeech.2018-2030
|
| 19 |
GAO T, DU J, DAI L R, et al. Densely connected progressive learning for LSTM-based speech enhancement[C]// Proceedings of the 2018 IEEE International Conference on Acoustics, Speech, and Signal Processing. Piscataway: IEEE, 2018: 5054-5058. 10.1109/icassp.2018.8461861
|
| 20 |
TU Y H, DU J, GAO T, et al. A multi-target SNR-progressive learning approach to regression based speech enhancement[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2020, 28: 1608-1619. 10.1109/taslp.2020.2996503
|
| 21 |
KINGMA D P, BA J L. Adam: a method for stochastic optimization[EB/OL]. (2017-01-30) [2022-01-03]..
|
| 22 |
SUN L, DU J, DAI L R, et al. Multiple-target deep learning for LSTM-RNN based speech enhancement[C]// Proceedings of the 2017 Hands-free Speech Communications and Microphone Arrays. Piscataway: IEEE, 2017: 136-140. 10.1109/hscma.2017.7895577
|
| 23 |
ZHOU N, DU J, TU Y H, et al. A speech enhancement neural network architecture with SNR-progressive multi-target learning for robust speech recognition[C]// Proceedings of the 2019 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference. Piscataway: IEEE, 2019: 873-877. 10.1109/apsipaasc47483.2019.9023157
|
| 24 |
VINCENT E, WATANABE S, NUGRAHA A A, et al. An analysis of environment, microphone and data simulation mismatches in robust speech recognition[J]. Computer Speech and Language, 2017, 46: 535-557. 10.1016/j.csl.2016.11.005
|


 ), Yanhui TU1, Feng MA1, Zhonghua FU2
), Yanhui TU1, Feng MA1, Zhonghua FU2