


《计算机应用》唯一官方网站 ›› 2023, Vol. 43 ›› Issue (S1): 67-74.DOI: 10.11772/j.issn.1001-9081.2022050710
收稿日期:2022-05-18
修回日期:2022-07-21
接受日期:2022-07-21
发布日期:2023-07-04
出版日期:2023-06-30
通讯作者:
崔喆
作者简介:赵嘉昕(1998—),男,四川成都人,硕士研究生,CCF会员,主要研究方向:自然语言处理基金资助:
Jiaxin ZHAO1,2, Zhe CUI1( )
)
Received:2022-05-18
Revised:2022-07-21
Accepted:2022-07-21
Online:2023-07-04
Published:2023-06-30
Contact:
Zhe CUI
摘要:
针对法律判决文书信息点较多、结构化程度较高,传统的抽取式文摘方法容易产生冗余句子且无法覆盖全部关键信息的问题,提出BIGDCNN(BERT based Improved Gate Dilated Convolutional Neural Network)模型。首先将原始数据进行语料转换获取序列标注数据,再通过预训练语言模型BERT(Bidirectional Encoder Representations from Transformers)得到从词粒度到句子粒度的长文本表示;最后使用融合了改进门机制的膨胀卷积神经网络(DCNN)以及单模型融合方法,实现低冗余度提取原文关键信息的同时增强抗干扰性,并减小了梯度消失的风险。在法律判决文书自动文摘实验中,本模型的ROUGE-1、ROUGE-2、ROUGE-L评分为62.85%、46.56%、59.25%,较主流模型BERT+Transformer分别提升了15.10、15.75、12.97个百分点。BIGDCNN模型解决了传统抽取式文摘方法的问题,可以高效地运用在法律判决文书的自动文摘场景中。
中图分类号:
赵嘉昕, 崔喆. 面向法律判决文书的长文档抽取式文摘方法——BIGDCNN[J]. 计算机应用, 2023, 43(S1): 67-74.
Jiaxin ZHAO, Zhe CUI. BIGDCNN: Extractive summarization method for long legal judgment documents[J]. Journal of Computer Applications, 2023, 43(S1): 67-74.

图1 模型结构
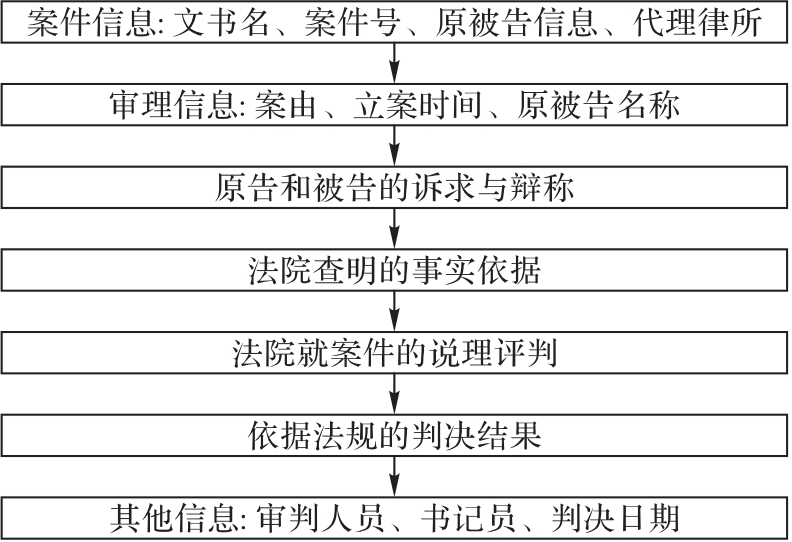
图2 篇章结构
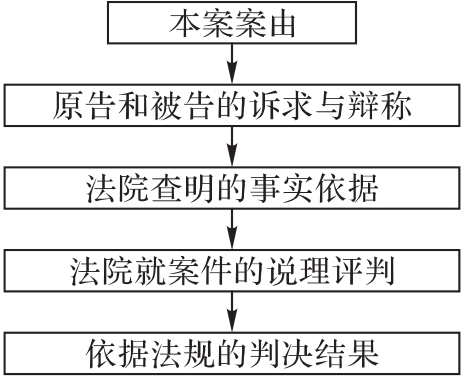
图3 参考摘要结构

图4 膨胀卷积神经网络(DCNN)

图5 改进后的门机制
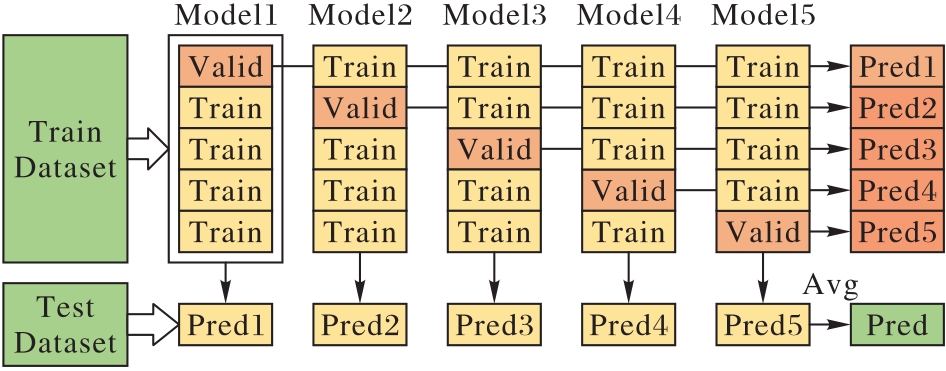
图6 单模型融合
| 数据集 | 文本 数量 | 平均 字数 | 字数 标准差 | 最大 字数 | 最小 字数 |
|---|---|---|---|---|---|
| 训练集 | 8 118 | 2 658 | 1 119 | 13 161 | 858 |
| 验证集 | 2 707 | 2 656 | 1 120 | 13 165 | 859 |
| 测试集 | 2 706 | 2 657 | 1 121 | 13 164 | 857 |
表1 语料库信息统计
| 数据集 | 文本 数量 | 平均 字数 | 字数 标准差 | 最大 字数 | 最小 字数 |
|---|---|---|---|---|---|
| 训练集 | 8 118 | 2 658 | 1 119 | 13 161 | 858 |
| 验证集 | 2 707 | 2 656 | 1 120 | 13 165 | 859 |
| 测试集 | 2 706 | 2 657 | 1 121 | 13 164 | 857 |
| 参数 | 值 | 参数 | 值 |
|---|---|---|---|
| 模型 | BERT-base | 注意力层头数 | 12 |
| 层数 | 12 | 参数量 | 110×106 |
| 隐藏层维度 | 768 |
表2 BERT模型参数
| 参数 | 值 | 参数 | 值 |
|---|---|---|---|
| 模型 | BERT-base | 注意力层头数 | 12 |
| 层数 | 12 | 参数量 | 110×106 |
| 隐藏层维度 | 768 |
| 参数 | 值 | 参数 | 值 |
|---|---|---|---|
| 窗口大小 | 5 | 低频词阈值 | 10 |
| 动态窗口 | 是 | 迭代次数 | 5 |
| 子采样频率 | 0.000 01 | 负采样数 | 5 |
表3 Word2Vec训练参数
| 参数 | 值 | 参数 | 值 |
|---|---|---|---|
| 窗口大小 | 5 | 低频词阈值 | 10 |
| 动态窗口 | 是 | 迭代次数 | 5 |
| 子采样频率 | 0.000 01 | 负采样数 | 5 |
| 实验环境 | 实验设置一 | 实验设置二 |
|---|---|---|
| 操作系统 | Ubuntu18.04 | Windows10 |
| 编程语言 | Python3.6.9 | Python3.6.13 |
| 深度学习框架 | Tensorflow1.14.0 | Tensorflow1.14.0 |
| CUDA版本 | 10.0 | 10.0 |
| 开发工具 | Vim | Pycharm |
| 显卡型号 | RTX TITAN | RTX 3070TI |
表4 实验环境及设置
| 实验环境 | 实验设置一 | 实验设置二 |
|---|---|---|
| 操作系统 | Ubuntu18.04 | Windows10 |
| 编程语言 | Python3.6.9 | Python3.6.13 |
| 深度学习框架 | Tensorflow1.14.0 | Tensorflow1.14.0 |
| CUDA版本 | 10.0 | 10.0 |
| 开发工具 | Vim | Pycharm |
| 显卡型号 | RTX TITAN | RTX 3070TI |
| 超参数名称 | 含义 | 值 |
|---|---|---|
| input_size | 词向量维度 | 300/768/1 024 |
| hidden_size | 隐藏层维度 | 384 |
| epochs | 迭代次数 | 20 |
| batch_size | 单次运算大小 | 64 |
| threshold | Early stop的阈值 | 0.3 |
| kernel_size | 卷积核大小 | 3 |
| dilation_rate | 膨胀率 | 1/2/4/8 |
| D | 乘性噪声 | [-0.1,0.1] |
| 模型融合数量 | 5 |
表5 主要超参数设置
| 超参数名称 | 含义 | 值 |
|---|---|---|
| input_size | 词向量维度 | 300/768/1 024 |
| hidden_size | 隐藏层维度 | 384 |
| epochs | 迭代次数 | 20 |
| batch_size | 单次运算大小 | 64 |
| threshold | Early stop的阈值 | 0.3 |
| kernel_size | 卷积核大小 | 3 |
| dilation_rate | 膨胀率 | 1/2/4/8 |
| D | 乘性噪声 | [-0.1,0.1] |
| 模型融合数量 | 5 |
| 实验序号 | 实验 | ROUGE-1 | ROUGE-2 | ROUGE-L |
|---|---|---|---|---|
| 1 | MMR | 42.04 | 25.53 | 31.96 |
| 2 | LEAD3 | 20.04 | 7.49 | 11.82 |
| 3 | TextRank | 36.67 | 18.44 | 30.38 |
| 4 | Word2Vec+TextRank | 46.49 | 28.97 | 40.89 |
| 5 | BERT+Classifier | 45.60 | 19.99 | 43.57 |
| 6 | BERT+Transformer | 47.75 | 30.81 | 46.28 |
| 7 | BERT+DGCNN | 61.12 | 44.76 | 57.42 |
| 8 | BIGDCNN-1 | 61.96 | 45.60 | 58.14 |
| 9 | BIGDCNN | 62.85 | 46.56 | 59.25 |
表6 对比实验结果 (%)
| 实验序号 | 实验 | ROUGE-1 | ROUGE-2 | ROUGE-L |
|---|---|---|---|---|
| 1 | MMR | 42.04 | 25.53 | 31.96 |
| 2 | LEAD3 | 20.04 | 7.49 | 11.82 |
| 3 | TextRank | 36.67 | 18.44 | 30.38 |
| 4 | Word2Vec+TextRank | 46.49 | 28.97 | 40.89 |
| 5 | BERT+Classifier | 45.60 | 19.99 | 43.57 |
| 6 | BERT+Transformer | 47.75 | 30.81 | 46.28 |
| 7 | BERT+DGCNN | 61.12 | 44.76 | 57.42 |
| 8 | BIGDCNN-1 | 61.96 | 45.60 | 58.14 |
| 9 | BIGDCNN | 62.85 | 46.56 | 59.25 |
| 实验序号 | 实验 | ROUGE-1 | ROUGE-2 | ROUGE-L |
|---|---|---|---|---|
| 1 | BERT+DGCNN | 61.12 | 44.76 | 57.42 |
| 2 | 只加噪声( | 61.76 | 45.62 | 57.90 |
| 3 | 只加激活函数 | 61.77 | 45.45 | 57.91 |
| 4 | 两者都加 | 61.96 | 45.60 | 58.14 |
表7 消融实验结果 (%)
| 实验序号 | 实验 | ROUGE-1 | ROUGE-2 | ROUGE-L |
|---|---|---|---|---|
| 1 | BERT+DGCNN | 61.12 | 44.76 | 57.42 |
| 2 | 只加噪声( | 61.76 | 45.62 | 57.90 |
| 3 | 只加激活函数 | 61.77 | 45.45 | 57.91 |
| 4 | 两者都加 | 61.96 | 45.60 | 58.14 |
| 模 型 | 实验样例 |
|---|---|
参考摘要 (299字) | 原被告系劳动合同纠纷。原告诉求不支付被告未签劳动合同二倍工资差额。被告辩称劳动合同到期但原告未提出续签直到被告因此提出离职,是原告过错导致被告离职,原告应支付解除劳动关系经济补偿金及未签劳动合同二倍工资差额。被告诉求原告支付未签劳动合同二倍工资差额和解除劳动关系经济补偿金。本案中原告主张已签订无固定期限劳动合同但未佐证且被告否认,故对原告主张难采信。现双方确认对仲裁未签劳动合同二倍工资差额无异议故予以确认。被告系以劳动合同超过8个月未续签为由提出解除劳动关系不属于应支付经济补偿金情形。依照《劳动合同法》八十二条,判决原告支付未签劳动合同二倍工资差额;驳回被告要求支付解除劳动关系经济补偿诉求。 |
MMR (193字) | 现被告向本院提出诉讼请求:1、判令原告支付被告2016年10月1日至2017年5月3日期间未签劳动合同二倍工资差额32,837元;2、判令原告支付被告解除劳动关系经济补偿金27,365元。经仲裁,裁决原告支付被告2016年10月29日至2017年5月3日未签劳动合同二倍工资差额28,895.10元,对被告其余请求不予支持。原告上海浦罗贸易有限公司向本院提出诉讼请求:判令原告不支付被告2016年10月29日至2017年5月3日期间未签劳动合同二倍工资差额人民币28,895.10元。 |
Word2Vec+ TextRank (276字) | 综上所述,依照《中华人民共和国劳动合同法》第八十二条第一款规定,判决如下:一、原告上海浦罗贸易有限公司于本判决生效之日起十日内支付被告冯雷2016年10月29日至2017年5月3日期间未签劳动合同二倍工资差额28,895.10元;二、驳回被告冯雷要求原告上海浦罗贸易有限公司支付解除劳动关系经济补偿金27,365元的诉讼请求。自2016年10月至2017年5月3日被告离职期间,原告每月正常发放被告工资,为被告缴纳社会保险,被告在原告处的工作并未受到影响,足以证明原、被告之前已签订了无固定期限劳动合同。经仲裁,裁决原告支付被告2016年10月29日至2017年5月3日未签劳动合同二倍工资差额28,895.10元,对被告其余请求不予支持。 |
BERT+DGCNN (610字) | 原告上海浦罗贸易有限公司与被告冯雷劳动合同纠纷一案,原、被告均不服劳动争议仲裁裁决而分别提出起诉,原告上海浦罗贸易有限公司向本院提出诉讼请求:判令原告不支付被告2016年10月29日至2017年5月3日期间未签劳动合同二倍工资差额人民币28,895.10元。原告无需支付被告2016年10月29日至2017年5月3日未签劳动合同二倍工资差额。被告冯雷辩称,原、被告的劳动合同到期,原告应向被告支付解除劳动关系经济补偿金及未签劳动合同二倍工资差额。1、判令原告支付被告2016年10月1日至2017年5月3日期间未签劳动合同二倍工资差额32,837元;2、判令原告支付被告解除劳动关系经济补偿金27,365元。被告变更第一项诉讼请求为判令原告支付被告2016年10月29日至2017年5月3日期间未签劳动合同二倍工资差额28,895.10元。本院经审理认定事实如下:要求原告支付:原告主张2016年9月29日之后已与被告签订无固定期限劳动合同,但未提供任何证据予以佐证,原告应支付被告2016年10月29日起未签订劳动合同二倍工资差额。关于被告要求原告支付解除劳动关系经济补偿金27,365元的诉讼请求。被告系以劳动合同超过8个月未续签为由,该解除理由不属于法律规定用人单位应当支付经济补偿金的情形。依照《中华人民共和国劳动合同法》第八十二条第一款规定,一、原告上海浦罗贸易有限公司于本判决生效之日起十日内支付被告冯雷2016年10月29日至2017年5月3日期间未签劳动合同二倍工资差额28,895.10元;二、驳回被告冯雷要求原告上海浦罗贸易有限公司支付解除劳动关系经济补偿金27,365元的诉讼请求。 |
BIGDCNN (450字) | 原告上海浦罗贸易有限公司与被告冯雷劳动合同纠纷一案,原告上海浦罗贸易有限公司向本院提出诉讼请求:判令原告不支付被告2016年10月29日至2017年5月3日期间未签劳动合同二倍工资差额人民币28,895.10元。原告无需支付被告2016年10月29日至2017年5月3日未签劳动合同二倍工资差额。被告冯雷辩称,现被告向本院提出诉讼请求:1、判令原告支付被告2016年10月1日至2017年5月3日期间未签劳动合同二倍工资差额32,837元;2、判令原告支付被告解除劳动关系经济补偿金27,365元。原告主张2016年9月29日之后已与被告签订无固定期限劳动合同,但未提供任何证据予以佐证,且遭被告否认,原告应支付被告2016年10月29日起未签订劳动合同二倍工资差额。该解除理由不属于法律规定用人单位应当支付经济补偿金的情形。依照《中华人民共和国劳动合同法》第八十二条第一款规定,判决如下:一、原告上海浦罗贸易有限公司于本判决生效之日起十日内支付被告冯雷2016年10月29日至2017年5月3日期间未签劳动合同二倍工资差额28,895.10元;二、驳回被告冯雷要求原告上海浦罗贸易有限公司支付解除劳动关系经济补偿金27,365元的诉讼请求。 |
表8 实验样例对比
| 模 型 | 实验样例 |
|---|---|
参考摘要 (299字) | 原被告系劳动合同纠纷。原告诉求不支付被告未签劳动合同二倍工资差额。被告辩称劳动合同到期但原告未提出续签直到被告因此提出离职,是原告过错导致被告离职,原告应支付解除劳动关系经济补偿金及未签劳动合同二倍工资差额。被告诉求原告支付未签劳动合同二倍工资差额和解除劳动关系经济补偿金。本案中原告主张已签订无固定期限劳动合同但未佐证且被告否认,故对原告主张难采信。现双方确认对仲裁未签劳动合同二倍工资差额无异议故予以确认。被告系以劳动合同超过8个月未续签为由提出解除劳动关系不属于应支付经济补偿金情形。依照《劳动合同法》八十二条,判决原告支付未签劳动合同二倍工资差额;驳回被告要求支付解除劳动关系经济补偿诉求。 |
MMR (193字) | 现被告向本院提出诉讼请求:1、判令原告支付被告2016年10月1日至2017年5月3日期间未签劳动合同二倍工资差额32,837元;2、判令原告支付被告解除劳动关系经济补偿金27,365元。经仲裁,裁决原告支付被告2016年10月29日至2017年5月3日未签劳动合同二倍工资差额28,895.10元,对被告其余请求不予支持。原告上海浦罗贸易有限公司向本院提出诉讼请求:判令原告不支付被告2016年10月29日至2017年5月3日期间未签劳动合同二倍工资差额人民币28,895.10元。 |
Word2Vec+ TextRank (276字) | 综上所述,依照《中华人民共和国劳动合同法》第八十二条第一款规定,判决如下:一、原告上海浦罗贸易有限公司于本判决生效之日起十日内支付被告冯雷2016年10月29日至2017年5月3日期间未签劳动合同二倍工资差额28,895.10元;二、驳回被告冯雷要求原告上海浦罗贸易有限公司支付解除劳动关系经济补偿金27,365元的诉讼请求。自2016年10月至2017年5月3日被告离职期间,原告每月正常发放被告工资,为被告缴纳社会保险,被告在原告处的工作并未受到影响,足以证明原、被告之前已签订了无固定期限劳动合同。经仲裁,裁决原告支付被告2016年10月29日至2017年5月3日未签劳动合同二倍工资差额28,895.10元,对被告其余请求不予支持。 |
BERT+DGCNN (610字) | 原告上海浦罗贸易有限公司与被告冯雷劳动合同纠纷一案,原、被告均不服劳动争议仲裁裁决而分别提出起诉,原告上海浦罗贸易有限公司向本院提出诉讼请求:判令原告不支付被告2016年10月29日至2017年5月3日期间未签劳动合同二倍工资差额人民币28,895.10元。原告无需支付被告2016年10月29日至2017年5月3日未签劳动合同二倍工资差额。被告冯雷辩称,原、被告的劳动合同到期,原告应向被告支付解除劳动关系经济补偿金及未签劳动合同二倍工资差额。1、判令原告支付被告2016年10月1日至2017年5月3日期间未签劳动合同二倍工资差额32,837元;2、判令原告支付被告解除劳动关系经济补偿金27,365元。被告变更第一项诉讼请求为判令原告支付被告2016年10月29日至2017年5月3日期间未签劳动合同二倍工资差额28,895.10元。本院经审理认定事实如下:要求原告支付:原告主张2016年9月29日之后已与被告签订无固定期限劳动合同,但未提供任何证据予以佐证,原告应支付被告2016年10月29日起未签订劳动合同二倍工资差额。关于被告要求原告支付解除劳动关系经济补偿金27,365元的诉讼请求。被告系以劳动合同超过8个月未续签为由,该解除理由不属于法律规定用人单位应当支付经济补偿金的情形。依照《中华人民共和国劳动合同法》第八十二条第一款规定,一、原告上海浦罗贸易有限公司于本判决生效之日起十日内支付被告冯雷2016年10月29日至2017年5月3日期间未签劳动合同二倍工资差额28,895.10元;二、驳回被告冯雷要求原告上海浦罗贸易有限公司支付解除劳动关系经济补偿金27,365元的诉讼请求。 |
BIGDCNN (450字) | 原告上海浦罗贸易有限公司与被告冯雷劳动合同纠纷一案,原告上海浦罗贸易有限公司向本院提出诉讼请求:判令原告不支付被告2016年10月29日至2017年5月3日期间未签劳动合同二倍工资差额人民币28,895.10元。原告无需支付被告2016年10月29日至2017年5月3日未签劳动合同二倍工资差额。被告冯雷辩称,现被告向本院提出诉讼请求:1、判令原告支付被告2016年10月1日至2017年5月3日期间未签劳动合同二倍工资差额32,837元;2、判令原告支付被告解除劳动关系经济补偿金27,365元。原告主张2016年9月29日之后已与被告签订无固定期限劳动合同,但未提供任何证据予以佐证,且遭被告否认,原告应支付被告2016年10月29日起未签订劳动合同二倍工资差额。该解除理由不属于法律规定用人单位应当支付经济补偿金的情形。依照《中华人民共和国劳动合同法》第八十二条第一款规定,判决如下:一、原告上海浦罗贸易有限公司于本判决生效之日起十日内支付被告冯雷2016年10月29日至2017年5月3日期间未签劳动合同二倍工资差额28,895.10元;二、驳回被告冯雷要求原告上海浦罗贸易有限公司支付解除劳动关系经济补偿金27,365元的诉讼请求。 |
| 1 | MIKOLOV T, CHEN K, CORRADO G, et al. Efficient estimation of word representations in vector space [EB/OL]. (2013-09-07) [2022-04-20]. . 10.3126/jiee.v3i1.34327 |
| 2 | PENNINGTON J, SOCHER R, MANNING C D. GloVe: global vectors for word representation[C]// Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2014: 1532-1543. 10.3115/v1/d14-1162 |
| 3 | DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional transformers for language understanding [EB/OL]. (2019-05-24) [2022-04-20]. . 10.18653/v1/n18-2 |
| 4 | LIU Y, OTT M, GOYAL N, et al. RoBERTa: a robustly optimized BERT pretraining approach [EB/OL]. (2019-07-26) [2022-04-20]. . |
| 5 | LUHN H P. The automatic creation of literature abstracts [J]. IBM Journal of Research and Development, 1958, 2(2): 159-165. 10.1147/rd.22.0159 |
| 6 | MRIDHA M F, LIMA A A, NUR K, et al. A survey of automatic text summarization: progress, process and challenges[J]. IEEE Access, 2021, 9: 156043-156070. 10.1109/access.2021.3129786 |
| 7 | DEERWESTER S, DUMAIS S T, FURNAS G W, et al. Indexing by latent semantic analysis [J]. Journal of the American Society for Information Science, 1990, 41(6): 391-407. 10.1002/(sici)1097-4571(199009)41:6<391::aid-asi1>3.0.co;2-9 |
| 8 | GONG Y, LIU X. Generic text summarization using relevance measure and latent semantic analysis [C]// Proceedings of the 24th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2001: 19-25. 10.1145/383952.383955 |
| 9 | ERKAN G, RADEV D R. LexRank: graph-based lexical centrality as salience in text summarization [J]. Journal of Artificial Intelligence Research, 2004, 22(1): 457-479. 10.1613/jair.1523 |
| 10 | SUANMALI L, SALIM N, BINWAHLAN M S. Fuzzy logic based method for improving text summarization [EB/OL]. (2009-06-25) [2022-04-20]. . 10.1109/his.2009.36 |
| 11 | SANKARASUBRAMANIAM Y, RAMANATHAN K, GHOSH S. Text summarization using Wikipedia [J]. Information Processing & Management, 2014, 50(3): 443-461. 10.1016/j.ipm.2014.02.001 |
| 12 | LAFFERTY J D, McCALLUM A, PEREIRA F C N. Conditional random fields: probabilistic models for segmenting and labeling sequence data[C]// Proceedings of the Eighteenth International Conference on Machine Learning. San Francisco, CA: Morgan Kaufmann Publishers Inc., 2001: 282-289. |
| 13 | CHUANG W T, YANG J. Extracting sentence segments for text summarization: a machine learning approach [C]// Proceedings of the 23rd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2000: 152-159. 10.1145/345508.345566 |
| 14 | KAIKHAH K. Automatic text summarization with neural networks[C]// Proceedings of the 2nd International IEEE Conference on Intelligent Systems. Piscataway: IEEE, 2004: 40-44. |
| 15 | GALLEY M. A skip-chain conditional random field for ranking meeting utterances by importance [C]// Proceedings of the 2006 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2006: 22-23. 10.3115/1610075.1610126 |
| 16 | NALLAPATI R, ZHAI F, ZHOU B. SummaRuNNer: a recurrent neural network based sequence model for extractive summarization of documents[C]// Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence. Menlo Park: AAAI, 2017: 3075-3081. 10.1609/aaai.v31i1.10958 |
| 17 | LIU Y. Fine-tune BERT for Extractive Summarization [EB/OL]. (2019-09-05) [2022-04-20]. . |
| 18 | FARZINDAR A, LAPALME G. LetSum: an automatic legal text summarizing system [C]// Proceedings of the Seventeenth Annual Conference on Legal Knowledge and Information Systems. Amsterdam, Holland: IOS Press, 2004: 11-18. |
| 19 | 王义真,欧石燕,陈金菊.民事裁判文书两阶段式自动摘要研究[J].数据分析与知识发现,2021,5(5):104-114. |
| 20 | 周蔚,王兆毓,魏斌.面向法律裁判文书的生成式自动摘要模型[J].计算机科学,2021,48(12):331-336. 10.11896/jsjkx.210500028 |
| 21 | GAO Y, LIU Z, LI J, et al. Extractive summarization of chinese judgment documents via sentence embedding and memory network[C]// Proceedings of the CCF International Conference on Natural Language Processing and Chinese Computing. Cham: Springer, 2021: 413-424. 10.1007/978-3-030-88480-2_33 |
| 22 | 王刚,孙媛媛,陈彦光,等.面向法律文书的分段式摘要模型[J].计算机工程,2022,48(6):288-294. |
| 23 | NGUYEN D H, NGUYEN B S, NGHIEM N, et al. Robust deep reinforcement learning for extractive legal summarization [EB/OL]. (2021-11-23) [2022-04-20]. . 10.1007/978-3-030-92310-5_69 |
| 24 | LI Y, ZHANG X, CHEN D. CSRNet: dilated convolutional neural networks for understanding the highly congested scenes[C]// Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 1091-1100. 10.1109/cvpr.2018.00120 |
| 25 | 张全龙,王怀彬.基于膨胀卷积和门控循环单元组合的入侵检测模型[J].计算机应用,2021,41(5):1372-1377. |
| 26 | LIN C-Y. ROUGE: a package for automatic evaluation of summaries[C]// Proceedings of the Workshop on Text Summarization Branches Out. Stroudsburg, PA: Association for Computational Linguistics, 2004: 74-81. |
| 27 | CUI Y, CHE W, LIU T, et al. Pre-training with whole word masking for Chinese BERT[J]. IEEE/ACM Transactions on Audio, Speech and Language Processing, 2021, 29: 3504-3514. 10.1109/taslp.2021.3124365 |
| 28 | LI S, ZHAO Z, HU R, et al. Analogical reasoning on chinese morphological and semantic relations [C]// Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2018: 138-143. 10.18653/v1/p18-2023 |
| 29 | CARBONELL J, GOLDSTEIN J. The use of MMR, diversity-based reranking for reordering documents and producing summaries[C]// Proceedings of the 21st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 1998: 335-336. 10.1145/290941.291025 |
| 30 | MIHALCEA R, TARAU P. TextRank: bringing order into text[C]// Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2004: 404-411. 10.3115/1220355.1220517 |
| [1] | 高永兵, 高军甜, 马蓉, 杨立东. 用户粒度级的个性化社交文本生成模型[J]. 《计算机应用》唯一官方网站, 2023, 43(4): 1021-1028. |
| [2] | 江静, 陈渝, 孙界平, 琚生根. 融合后验概率校准训练的文本分类算法[J]. 《计算机应用》唯一官方网站, 2022, 42(6): 1789-1795. |
| [3] | 张海丰, 曾诚, 潘列, 郝儒松, 温超东, 何鹏. 结合BERT和特征投影网络的新闻主题文本分类方法[J]. 《计算机应用》唯一官方网站, 2022, 42(4): 1116-1124. |
| [4] | 王小鹏, 孙媛媛, 林鸿飞. 基于刑事Electra的编-解码关系抽取模型[J]. 《计算机应用》唯一官方网站, 2022, 42(1): 87-93. |
| [5] | 李志超, 吐尔地·托合提, 艾斯卡尔·艾木都拉. 基于动态注意力和多角度匹配的答案选择模型[J]. 《计算机应用》唯一官方网站, 2021, 41(11): 3156-3163. |
| [6] | 谭金源, 刁宇峰, 祁瑞华, 林鸿飞. 基于BERT-PGN模型的中文新闻文本自动摘要生成[J]. 计算机应用, 2021, 41(1): 127-132. |
| [7] | 陈玉娜, 史晓东. 通过标点恢复提高机器同传效果[J]. 计算机应用, 2020, 40(4): 972-977. |
| [8] | 李扬, 张伟, 彭晨. 目标依赖的作者身份识别方法[J]. 《计算机应用》唯一官方网站, 2020, 40(2): 473-478. |
| [9] | 王月, 王孟轩, 张胜, 杜渂. 基于BERT的警情文本命名实体识别[J]. 《计算机应用》唯一官方网站, 2020, 40(2): 535-540. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||