《计算机应用》唯一官方网站 ›› 2023, Vol. 43 ›› Issue (S1): 95-99.DOI: 10.11772/j.issn.1001-9081.2022050736
Tao ZHOU1,2, Lihua XIE1( ), Xiaofei WANG3
), Xiaofei WANG3
摘要:
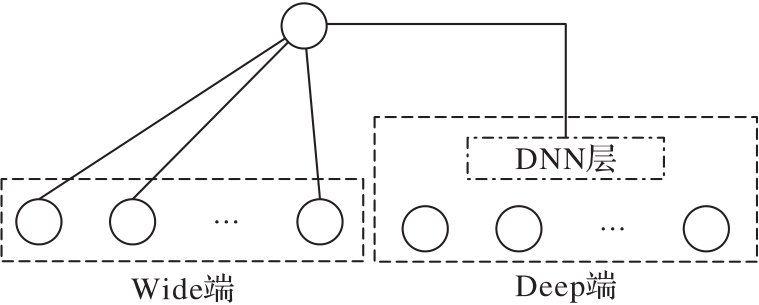
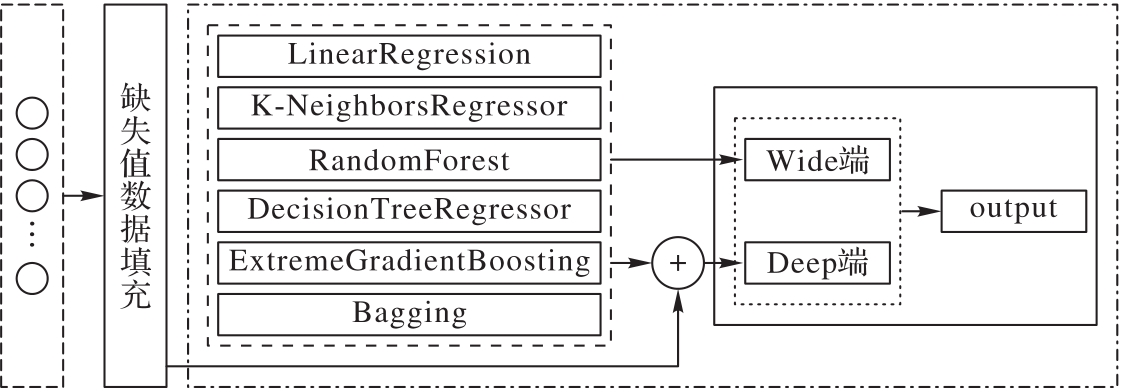
针对卷烟焦油指标预测任务中历史卷烟数据样本具有小样本和高维度的特点,导致模型预测准确度偏低的问题,提出一种基于改进Wide&Deep的卷烟焦油指标预测模型。首先通过多个机器学习模型对数据样本进行预测,并将得到的结果作为模型新特征;然后将机器学习模型得到的新特征输入到Wide&Deep模型的Wide端,同时构建融合特征输入到Wide&Deep模型的Deep端,并在Deep端通过引入二阶特征和注意力机制构建注意力特征交叉层实现特征的高阶组合以提高模型预测的准确度。实验结果表明,所提模型与未经过改进的Wide&Deep模型相比,平均绝对误差(MAE)降低了23.4%,均方根误差(RMSE)降低了21.8%;与基于卷积神经网络提取特征的改进Wide&Deep模型相比,MAE降低了15.0%,RMSE降低了16.4%;有效提升了卷烟焦油指标预测任务的准确度。
中图分类号: