


《计算机应用》唯一官方网站 ›› 2023, Vol. 43 ›› Issue (7): 2073-2081.DOI: 10.11772/j.issn.1001-9081.2022071122
• 第39届CCF中国数据库学术会议(NDBC 2022) • 上一篇
收稿日期:2022-07-12
修回日期:2022-08-15
接受日期:2022-08-17
发布日期:2023-07-20
出版日期:2023-07-10
通讯作者:
蔡剑平
作者简介:蓝梦婕(1998—),女,福建三明人,硕士研究生,CCF学生会员,主要研究方向:联邦学习、差分隐私;
Mengjie LAN, Jianping CAI( ), Lan SUN
), Lan SUN
Received:2022-07-12
Revised:2022-08-15
Accepted:2022-08-17
Online:2023-07-20
Published:2023-07-10
Contact:
Jianping CAI
About author:LAN Mengjie, born in 1998, M. S. candidate. Her research interests include federated learning, differential privacy.摘要:
联邦学习(FL)是一种新的分布式机器学习范式,它在保护设备数据隐私的同时打破数据壁垒,从而使各方能在不共享本地数据的前提下协作训练机器学习模型。然而,如何处理不同客户端的非独立同分布(Non-IID)数据仍是FL面临的一个巨大挑战,目前提出的一些解决方案没有利用好本地模型和全局模型的隐含关系,无法简单而高效地解决问题。针对FL中不同客户端数据的Non-IID问题,提出新的FL优化算法——联邦自正则(FedSR)和动态联邦自正则(Dyn-FedSR)。FedSR在每一轮训练过程中引入自正则化惩罚项动态修改本地损失函数,并通过构建本地模型和全局模型的关系来让本地模型靠近聚合丰富知识的全局模型,从而缓解Non-IID数据带来的客户端偏移问题;Dyn-FedSR则在FedSR基础上通过计算本地模型和全局模型的相似度来动态确定自正则项系数。对不同任务进行的大量实验分析表明,FedSR和Dyn-FedSR这两个算法在各种场景下的表现都明显优于联邦平均(FedAvg)算法、联邦近端(FedProx)优化算法和随机控制平均算法(SCAFFOLD)等FL算法,能够实现高效通信,正确率较高,且对不平衡数据和不确定的本地更新具有鲁棒性。
中图分类号:
蓝梦婕, 蔡剑平, 孙岚. 非独立同分布数据下的自正则化联邦学习优化方法[J]. 计算机应用, 2023, 43(7): 2073-2081.
Mengjie LAN, Jianping CAI, Lan SUN. Self-regularization optimization methods for Non-IID data in federated learning[J]. Journal of Computer Applications, 2023, 43(7): 2073-2081.
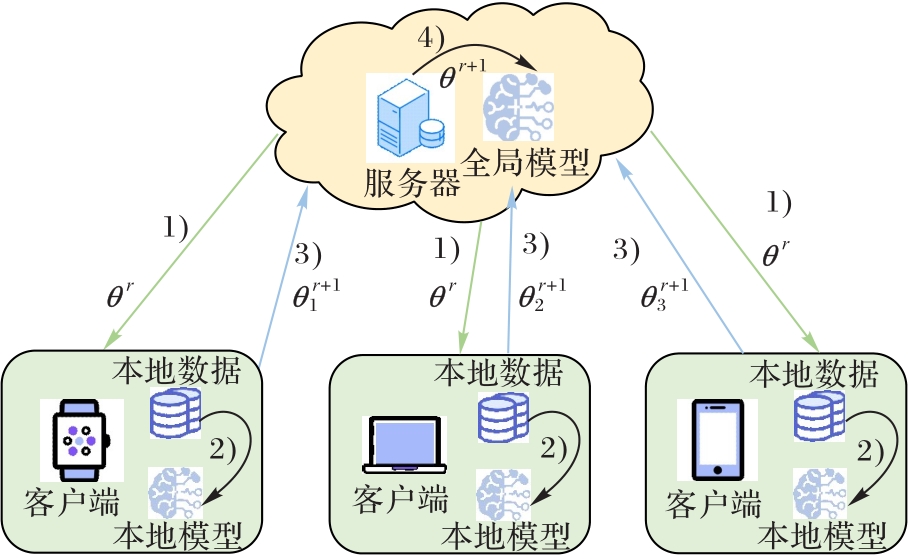
图1 联邦学习的基本流程
Fig. 1 Basic flow of federated learning
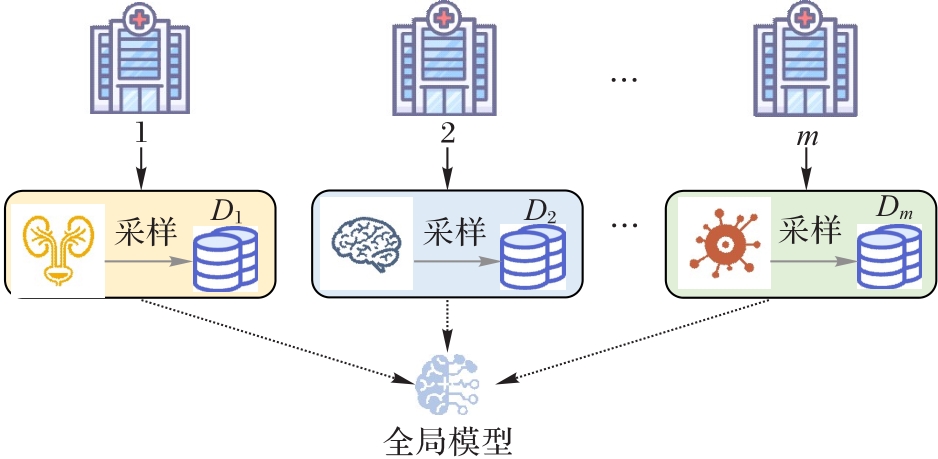
图2 联邦学习中标签分布倾斜的Non-IID问题
Fig. 2 Non-IID problem with label distribution skew in federated learning
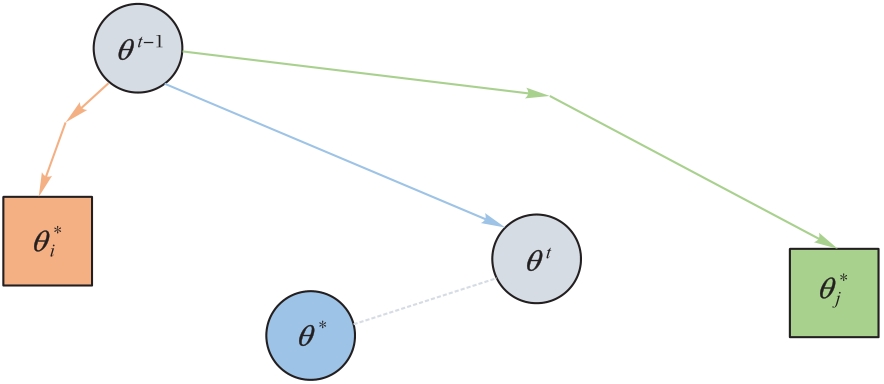
图3 联邦学习中Non-IID场景中的客户端偏移问题
Fig. 3 Client drift problem in Non-IID scenario in federated learning
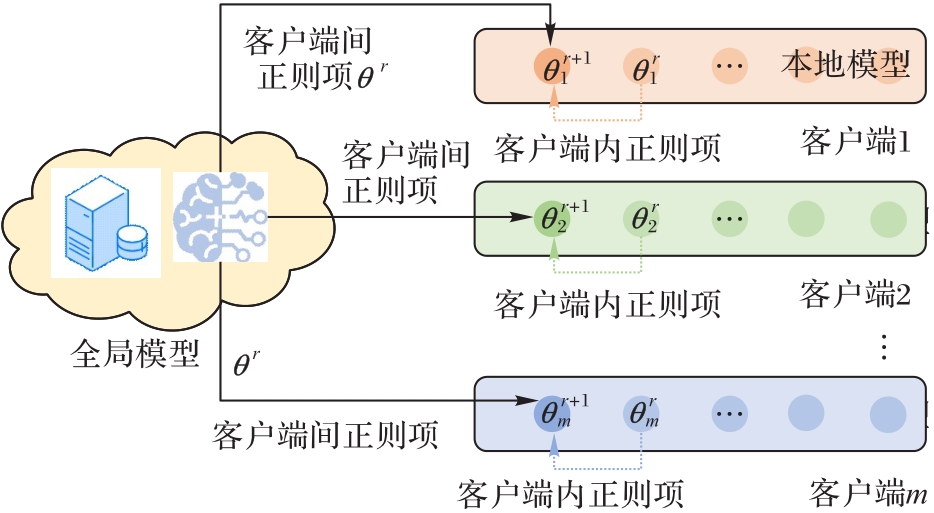
图4 FedSR整体框架
Fig. 4 Overall framework of FedSR

图5 全局模型和本地模型在MNIST数据集上的分类差异
Fig. 5 Classification difference between global model and local model on MNIST dataset
| 变量名 | 描述 | 默认值 |
|---|---|---|
| 学习率 | 0.01 | |
| batch size | 64 | |
| 本地更新Epoch次数 | 20 | |
| 客户端总数 | 1 000 | |
| 第 | 10 | |
| 训练总轮次 | 200 | |
| 狄利克雷分布参数 | 0.5 |
表1 实验参数
Tab. 1 Experimental parameters
| 变量名 | 描述 | 默认值 |
|---|---|---|
| 学习率 | 0.01 | |
| batch size | 64 | |
| 本地更新Epoch次数 | 20 | |
| 客户端总数 | 1 000 | |
| 第 | 10 | |
| 训练总轮次 | 200 | |
| 狄利克雷分布参数 | 0.5 |
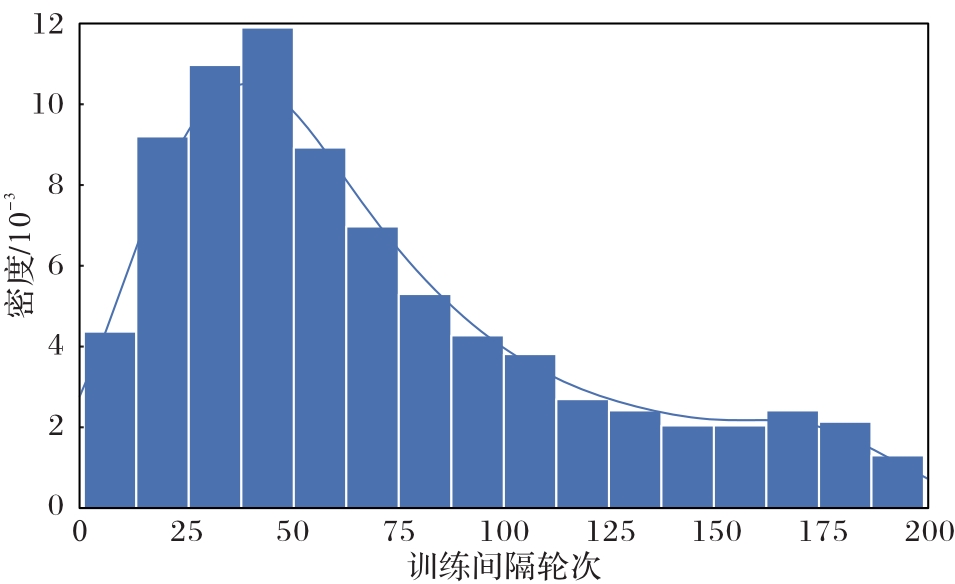
图6 客户端连续参与两次训练的间隔轮次的概率密度分布
Fig. 6 Probability density distribution of interval rounds between two successive training participated by client
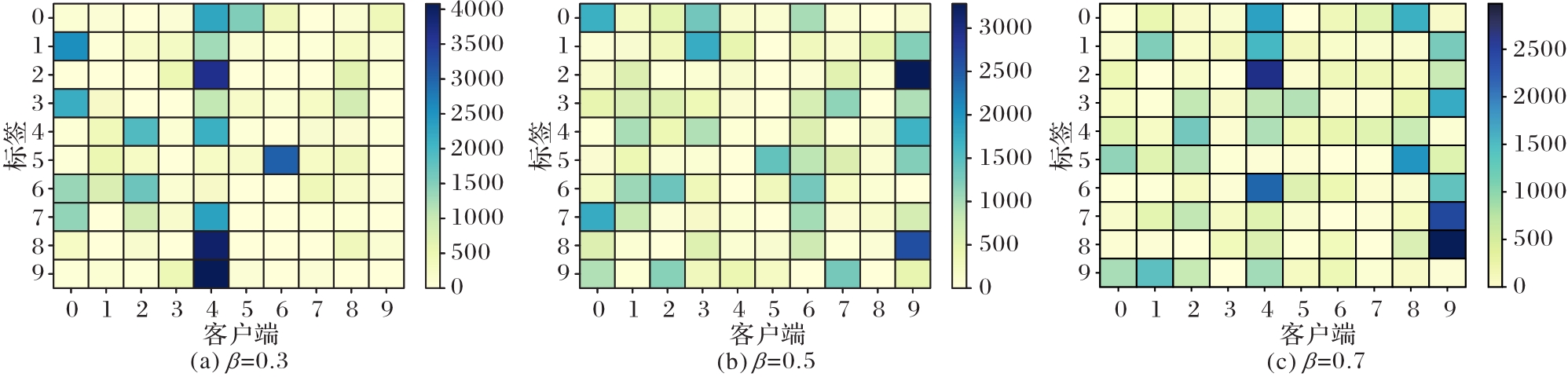
图7 不同Non-IID程度下的客户端数据分布
Fig. 7 Data distribution of clients under different Non-IID levels
| 数据集 | 正确率/% | |||||
|---|---|---|---|---|---|---|
| FedAvg | FedProx | SCAFFOLD | FedSR | Dyn-FedSR | ||
| MNIST | 88.58 | 88.45 | 88.58 | 89.28 | 89.35 | |
| 89.33 | 88.87 | 89.32 | 89.91 | 89.83 | ||
| 89.70 | 89.35 | 89.64 | 90.17 | 90.13 | ||
| Fashion-MNIST | 70.32 | 76.86 | 71.52 | 81.19 | 81.10 | |
| 78.58 | 78.40 | 78.54 | 81.12 | 81.10 | ||
| 81.63 | 81.70 | 82.08 | 81.78 | 81.80 | ||
| EMNIST | 47.15 | 47.02 | 47.55 | 54.65 | 54.18 | |
| 56.51 | 56.43 | 56.19 | 61.68 | 61.49 | ||
| 57.59 | 58.55 | 58.34 | 63.38 | 63.52 | ||
| CIFAR-10 | 38.59 | 39.23 | 39.12 | 40.17 | 40.07 | |
| 40.25 | 40.27 | 41.38 | 42.55 | 42.61 | ||
| 41.35 | 41.72 | 41.43 | 43.03 | 43.38 | ||
表2 不同Non-IID程度下的正确率比较
Tab. 2 Accuracy comparison under different Non-IID levels
| 数据集 | 正确率/% | |||||
|---|---|---|---|---|---|---|
| FedAvg | FedProx | SCAFFOLD | FedSR | Dyn-FedSR | ||
| MNIST | 88.58 | 88.45 | 88.58 | 89.28 | 89.35 | |
| 89.33 | 88.87 | 89.32 | 89.91 | 89.83 | ||
| 89.70 | 89.35 | 89.64 | 90.17 | 90.13 | ||
| Fashion-MNIST | 70.32 | 76.86 | 71.52 | 81.19 | 81.10 | |
| 78.58 | 78.40 | 78.54 | 81.12 | 81.10 | ||
| 81.63 | 81.70 | 82.08 | 81.78 | 81.80 | ||
| EMNIST | 47.15 | 47.02 | 47.55 | 54.65 | 54.18 | |
| 56.51 | 56.43 | 56.19 | 61.68 | 61.49 | ||
| 57.59 | 58.55 | 58.34 | 63.38 | 63.52 | ||
| CIFAR-10 | 38.59 | 39.23 | 39.12 | 40.17 | 40.07 | |
| 40.25 | 40.27 | 41.38 | 42.55 | 42.61 | ||
| 41.35 | 41.72 | 41.43 | 43.03 | 43.38 | ||

图8 默认参数设置下不同通信轮次的测试集正确率
Fig. 8 Test set accuracy in different communication rounds under default parameter setting
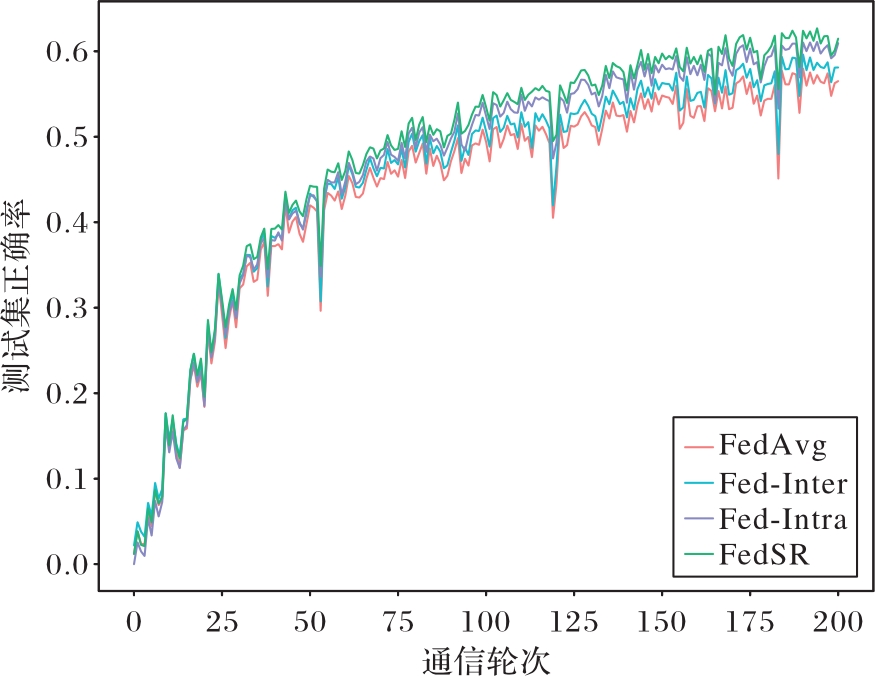
图9 消融实验结果
Fig. 9 Ablation experiment results
| 算法 | MNIST | Fashion-MNIST | EMNIST | CIFAR-10 | ||||
|---|---|---|---|---|---|---|---|---|
| 轮次 | 加速比 | 轮次 | 加速比 | 轮次 | 加速比 | 轮次 | 加速比 | |
| FedAvg | 100 | 1.00 | 100 | 1.00 | 100 | 1.00 | 100 | 1.00 |
| FedProx | 76 | 1.32 | 66 | 1.52 | 82 | 1.22 | 73 | 1.37 |
| SCAFFOLD | 70 | 1.43 | 61 | 1.64 | 92 | 1.09 | 73 | 1.37 |
| FedSR | 66 | 1.52 | 40 | 2.50 | 80 | 1.25 | 55 | 1.82 |
| Dyn-FedSR | 61 | 1.64 | 34 | 2.94 | 73 | 1.37 | 61 | 1.64 |
表3 默认参数设置下的通信效率比较
Tab. 3 Communication efficiency comparison under default parameter setting
| 算法 | MNIST | Fashion-MNIST | EMNIST | CIFAR-10 | ||||
|---|---|---|---|---|---|---|---|---|
| 轮次 | 加速比 | 轮次 | 加速比 | 轮次 | 加速比 | 轮次 | 加速比 | |
| FedAvg | 100 | 1.00 | 100 | 1.00 | 100 | 1.00 | 100 | 1.00 |
| FedProx | 76 | 1.32 | 66 | 1.52 | 82 | 1.22 | 73 | 1.37 |
| SCAFFOLD | 70 | 1.43 | 61 | 1.64 | 92 | 1.09 | 73 | 1.37 |
| FedSR | 66 | 1.52 | 40 | 2.50 | 80 | 1.25 | 55 | 1.82 |
| Dyn-FedSR | 61 | 1.64 | 34 | 2.94 | 73 | 1.37 | 61 | 1.64 |
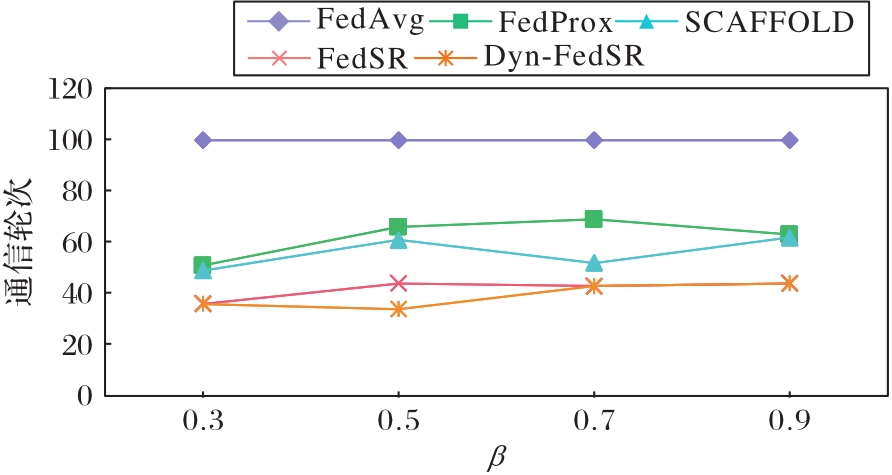
图10 不同β下达到基准正确率需要的通信轮次
Fig. 10 Communication rounds needed to reach benchmark accuracy under different β

图11 不同本地更新次数E对正确率的影响
Fig. 11 Influence of different number of local epochs E on accuracy
| 训练间隔轮次 | 正确率/% | ||
|---|---|---|---|
| FedSR | Dyn-FedSR | FedAvg | |
| 55 | 89.91 | 89.83 | 89.33 |
| 25 | 88.50 | 88.45 | 88.36 |
| 14 | 87.51 | 87.46 | 87.43 |
| 9 | 87.10 | 87.05 | 86.94 |
表4 不同训练间隔对正确率的影响
Tab. 4 Influence of different training interval on accuracy
| 训练间隔轮次 | 正确率/% | ||
|---|---|---|---|
| FedSR | Dyn-FedSR | FedAvg | |
| 55 | 89.91 | 89.83 | 89.33 |
| 25 | 88.50 | 88.45 | 88.36 |
| 14 | 87.51 | 87.46 | 87.43 |
| 9 | 87.10 | 87.05 | 86.94 |
| 1 | McMAHAN H B, MOORE E, RAMAGE D, et al. Communication-efficient learning of deep networks from decentralized data [C]// Proceedings of the 20th International Conference on Artificial Intelligence and Statistics. New York: JMLR.org, 2017: 1273-1282. |
| 2 | TAN B, LIU B, ZHENG V, et al. A federated recommender system for online services [C]// Proceedings of the 14th ACM Conference on Recommender Systems. New York: ACM, 2020: 579-581. 10.1145/3383313.3411528 |
| 3 | MUHAMMAD K, WANG Q Q, O’REILLY-MORGAN D, et al. FedFast: going beyond average for faster training of federated recommender systems [C]// Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2020: 1234-1242. 10.1145/3394486.3403176 |
| 4 | CHEN Y Q, QIN X, WANG J D, et al. FedHealth: a federated transfer learning framework for wearable healthcare[J]. IEEE Intelligent Systems, 2020, 35 (4): 83-93. 10.1109/mis.2020.2988604 |
| 5 | BRISIMI T S, CHEN R D, MELA T, et al. Federated learning of predictive models from federated electronic health records[J]. International Journal of Medical Informatics, 2018, 112: 59-67. 10.1016/j.ijmedinf.2018.01.007 |
| 6 | JIANG J C, KANTARCI B, OKTUG S, et al. Federated learning in smart city sensing: challenges and opportunities[J]. Sensors, 2020, 20 (21): No.6230. 10.3390/s20216230 |
| 7 | KAIROUZ P, McMAHAN H B, AVENT B, et al. Advances and open problems in federated learning[J]. Foundations and Trends in Machine Learning, 2021, 14 (1/2): 1-210. |
| 8 | LI X, HUANG K X, YANG W H, et al. On the convergence of FedAvg on Non-IID data[EB/OL]. (2020-06-25) [2022-05-06]. . |
| 9 | GAO D S, LIU Y, HUANG A B, et al. Privacy-preserving heterogeneous federated transfer learning [C]// Proceedings of the 2019 IEEE International Conference on Big Data. Piscataway: IEEE, 2019: 2552-2559. 10.1109/bigdata47090.2019.9005992 |
| 10 | LIU Y, KANG Y, XING C P, et al. A secure federated transfer learning framework[J]. IEEE Intelligent Systems, 2020, 35 (4): 70-82. 10.1109/mis.2020.2988525 |
| 11 | SMITH V, CHIANG C K, SANJABI M, et al. Federated multi-task learning [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2017: 4427-4437. |
| 12 | JIANG Y H, KONEČNÝ J, RUSH K, et al. Improving federated learning personalization via model agnostic meta learning[EB/OL]. (2019-09-27) [2022-05-06]. . |
| 13 | KHODAK M, BALCAN M F F, TALWALKAR A. Adaptive gradient-based meta-learning methods [C]// Proceedings of the 33rd International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2019: 5917-5928. |
| 14 | FALLAH A, MOKHTARI A, OZDAGLAR A. Personalized federated learning with theoretical guarantees: a model-agnostic meta-learning approach [C]// Proceedings of the 34th International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2020: 3557-3568. |
| 15 | ZHAO Y, LI M, LAI L Z, et al. Federated learning with non-IID data[EB/OL]. (2022-07-21) [2022-08-06]. . |
| 16 | LI T, SAHU A K, ZAHEER M, et al. Federated optimization in heterogeneous networks[C/OL]// Proceedings of the 3rd Machine Learning and Systems Conference [2022-05-06]. . 10.1109/ieeeconf44664.2019.9049023 |
| 17 | KARIMIREDDY S P, KALE S, MOHRI M, et al. SCAFFOLD: stochastic controlled averaging for federated learning [C]// Proceedings of the 37th International Conference on Machine Learning. New York: JMLR.org, 2020: 5132-5143. |
| 18 | LI Q B, HE B S, SONG D. Model-contrastive federated learning [C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 10708-10717. 10.1109/cvpr46437.2021.01057 |
| 19 | ACAR D A E, ZHAO Y, NAVARRO R M, et al. Federated learning based on dynamic regularization[EB/OL]. (2021-11-09) [2022-08-06]. . |
| 20 | WANG J Y, LIU Q H, LIANG H, et al. Tackling the objective inconsistency problem in heterogeneous federated optimization [C]// Proceedings of the 34th International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2020: 7611-7623. |
| [1] | 黄硕, 李艳辉, 曹建秋. 本地化差分隐私下的频繁序列模式挖掘算法PrivSPM[J]. 《计算机应用》唯一官方网站, 2023, 43(7): 2057-2064. |
| [2] | 林尚静, 马冀, 庄琲, 李月颖, 李子怡, 李铁, 田锦. 基于联邦学习的无线通信流量预测[J]. 《计算机应用》唯一官方网站, 2023, 43(6): 1900-1909. |
| [3] | 翟冉, 陈学斌, 张国鹏, 裴浪涛, 马征. 基于不同敏感度的改进K-匿名隐私保护算法[J]. 《计算机应用》唯一官方网站, 2023, 43(5): 1497-1503. |
| [4] | 郝劭辰, 卫孜钻, 马垚, 于丹, 陈永乐. 基于高效联邦学习算法的网络入侵检测模型[J]. 《计算机应用》唯一官方网站, 2023, 43(4): 1169-1175. |
| [5] | 尹春勇, 屈锐. 基于个性化差分隐私的联邦学习算法[J]. 《计算机应用》唯一官方网站, 2023, 43(4): 1160-1168. |
| [6] | 尹春勇, 李荧. 基于BCU-Tree与字典的高效用挖掘快速脱敏算法[J]. 《计算机应用》唯一官方网站, 2023, 43(2): 413-422. |
| [7] | 王腾, 霍峥, 黄亚鑫, 范艺琳. 联邦学习中的隐私保护技术研究综述[J]. 《计算机应用》唯一官方网站, 2023, 43(2): 437-449. |
| [8] | 郑赛, 李天瑞, 黄维. 面向通信成本优化的联邦学习算法[J]. 《计算机应用》唯一官方网站, 2023, 43(1): 1-7. |
| [9] | 刘炎培, 陈宁宁, 朱运静, 王丽萍. 面向5G/Beyond 5G的移动边缘缓存优化技术综述[J]. 《计算机应用》唯一官方网站, 2022, 42(8): 2487-2500. |
| [10] | 李洪亮, 张弄, 孙婷, 李想. 分布式机器学习作业性能干扰分析与预测[J]. 《计算机应用》唯一官方网站, 2022, 42(6): 1649-1655. |
| [11] | 章振宇, 谭国平, 周思源. 基于1‑bit压缩感知的高效无线联邦学习算法[J]. 《计算机应用》唯一官方网站, 2022, 42(6): 1675-1682. |
| [12] | 刘晶, 董志红, 张喆语, 孙志刚, 季海鹏. 基于联邦增量学习的工业物联网数据共享方法[J]. 《计算机应用》唯一官方网站, 2022, 42(4): 1235-1243. |
| [13] | 罗长银, 王君宇, 陈学斌, 马春地, 张淑芬. 改进的联邦加权平均算法[J]. 《计算机应用》唯一官方网站, 2022, 42(4): 1131-1136. |
| [14] | 吴静雯, 殷新春, 宁建廷. 车载自组网中可撤销的聚合签名认证方案[J]. 《计算机应用》唯一官方网站, 2022, 42(3): 911-920. |
| [15] | 邱鑫源, 叶泽聪, 崔翛龙, 高志强. 联邦学习通信开销研究综述[J]. 《计算机应用》唯一官方网站, 2022, 42(2): 333-342. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||