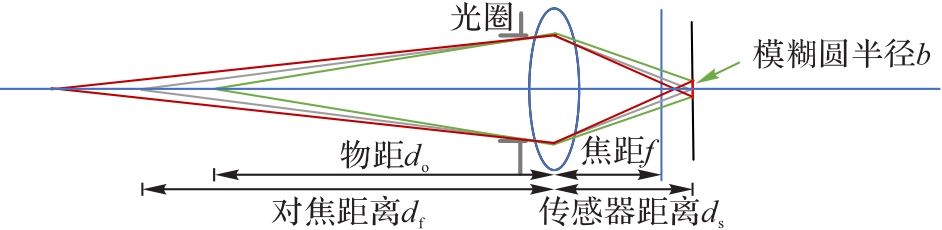
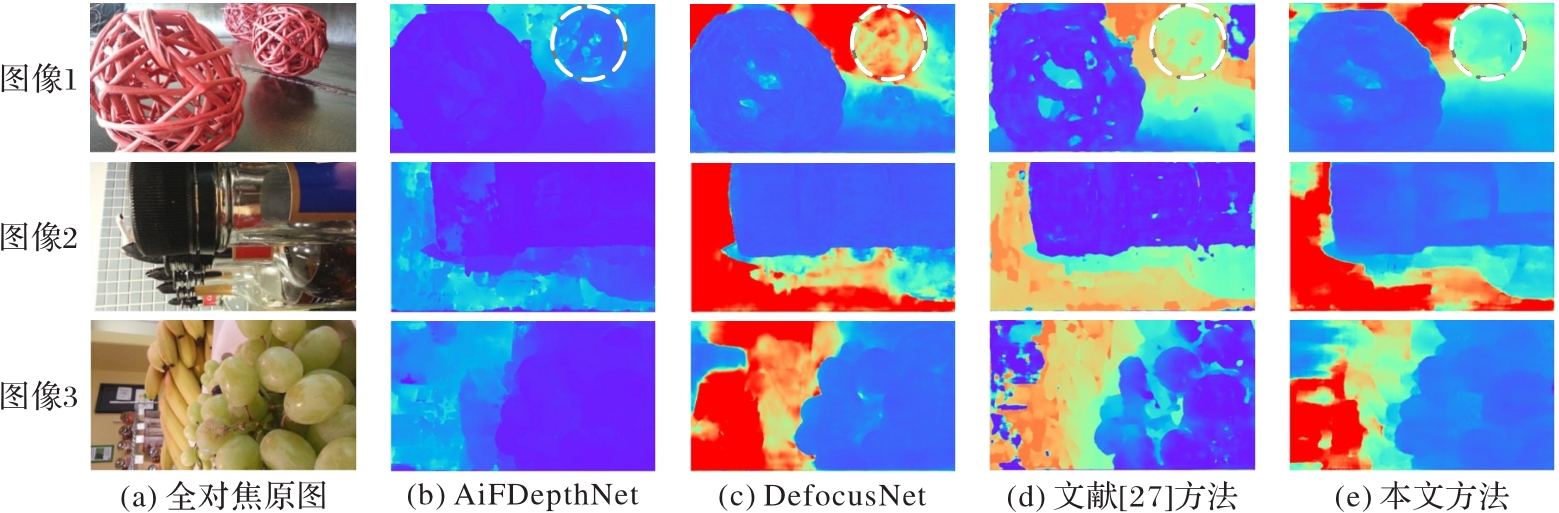
| 1 |
EIGEN D, PUHRSCH C, FERGUS R. Depth map prediction from a single image using a multi-scale deep network[C]// Proceedings of the 27th International Conference on Neural Information Processing Systems - Volume 2. Cambridge: MIT Press, 2014: 2366-2374. 10.48550/arXiv.1406.2283
|
| 2 |
LAINA I, RUPPRECHT C, BELAGIANNIS V, et al. Deeper depth prediction with fully convolutional residual networks[C]// Proceedings of the 4th International Conference on 3D Vision. Piscataway: IEEE, 2016: 239-248. 10.1109/3dv.2016.32
|
| 3 |
YIN W, LIU Y F, SHEN C H, et al. Enforcing geometric constraints of virtual normal for depth prediction[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 5683-5692. 10.1109/iccv.2019.00578
|
| 4 |
LI Z Y, WANG X Y, LIU X M, et al. BinsFormer: revisiting adaptive bins for monocular depth estimation[EB/OL]. (2022-04-03) [2022-04-17]..
|
| 5 |
SCHARSTEIN D, SZELISKI R. A taxonomy and evaluation of dense two-frame stereo correspondence algorithms[J]. International Journal of Computer Vision, 2002, 47(1/2/3): 7-42. 10.1023/a:1014573219977
|
| 6 |
MAYER N, ILG E, HÄUSSER P, et al. A large dataset to train convolutional networks for disparity, optical flow, and scene flow estimation[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 4040-4048. 10.1109/cvpr.2016.438
|
| 7 |
KENDALL A, MARTIROSYAN H, DASGUPTA S, et al. End-to-end learning of geometry and context for deep stereo regression[C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2017: 66-75. 10.1109/iccv.2017.17
|
| 8 |
GARG R, KUMAR B G V, CARNEIRO G, et al. Unsupervised CNN for single view depth estimation: geometry to the rescue[C]// Proceedings of the 2016 European Conference on Computer Vision, LNCS 9912. Cham: Springer, 2016: 740-756.
|
| 9 |
ZHOU T H, BROWN M, SNAVELY N, et al. Unsupervised learning of depth and ego-motion from video[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 6612-6619. 10.1109/cvpr.2017.700
|
| 10 |
GODARD C, AODHA O MAC, FIRMAN M, et al. Digging into self-supervised monocular depth estimation[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 3827-3837. 10.1109/iccv.2019.00393
|
| 11 |
GODARD C, AODHA O MAC, BROSTOW G J. Unsupervised monocular depth estimation with left-right consistency[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 6602-6611. 10.1109/cvpr.2017.699
|
| 12 |
SUWAJANAKORN S, HERNÁNDEZ C, SEITZ S M. Depth from focus with your mobile phone[C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2015: 3497-3506. 10.1109/cvpr.2015.7298972
|
| 13 |
MAXIMOV M, GALIM K, LEAL-TAIXÉ L. Focus on defocus: bridging the synthetic to real domain gap for depth estimation[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 1071-1080. 10.1109/cvpr42600.2020.00115
|
| 14 |
WANG N H, WANG R, LIU Y L, et al. Bridging unsupervised and supervised depth from focus via all-in-focus supervision[C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 12601-12611. 10.1109/iccv48922.2021.01239
|
| 15 |
FUJIMURA Y, IIYAMA M, FUNATOMI T, et al. Deep depth from focal stack with defocus model for camera-setting invariance[EB/OL]. (2022-02-26) [2022-03-12]..
|
| 16 |
YANG F T, HUANG X L, ZHOU Z H. Deep depth from focus with differential focus volume[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 12632-12641. 10.1109/cvpr52688.2022.01231
|
| 17 |
HAZIRBAS C, SOYER S G, STAAB M C, et al. Deep depth from focus[C]// Proceedings of the 2018 Asian Conference on Computer Vision, LNCS 11363. Cham: Springer, 2019: 525-541.
|
| 18 |
CERUSO S, BONAQUE-GONZÁLEZ S, OLIVA-GARCÍA R, et al. Relative multiscale deep depth from focus[J]. Signal Processing: Image Communication, 2021, 99: No.116417. 10.1016/j.image.2021.116417
|
| 19 |
GUO Q, FENG W, ZHOU C, et al. Learning dynamic Siamese network for visual object tracking[C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2017: 1781-1789. 10.1109/iccv.2017.196
|
| 20 |
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2017: 6000-6010.
|
| 21 |
NAYAR S K, WATANABE M, NOGUCHI M. Real-time focus range sensor[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1996, 18(12): 1186-1198. 10.1109/34.546256
|
| 22 |
SRINIVASAN P P, GARG R, WADHWA N, et al. Aperture supervision for monocular depth estimation[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 6393-6401. 10.1109/cvpr.2018.00669
|
| 23 |
CARVALHO M, LE SAUX B, TROUVÉ-PELOUX P, et al. Deep depth from defocus: how can defocus blur improve 3D estimation using dense neural networks?[C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11129. Cham: Springer, 2019: 307-323.
|
| 24 |
GALETTO F J, DENG G. Single image deep defocus estimation and its applications[EB/OL]. (2021-12-14) [2022-02-19].. 10.1007/s00371-022-02609-9
|
| 25 |
SZEGEDY C, VANHOUCKE V, IOFFE S, et al. Rethinking the inception architecture for computer vision[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 2818-2826. 10.1109/cvpr.2016.308
|
| 26 |
KASHIWAGI M, MISHIMA N, KOZAKAYA T, et al. Deep depth from aberration map[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 4069-4078. 10.1109/iccv.2019.00417
|
| 27 |
WON C, JEON H G. Learning depth from focus in the wild[C]// Proceedings of the 2022 European Conference on Computer Vision, LNCS 13661. Cham: Springer, 2022: 1-18.
|


 )
)