


《计算机应用》唯一官方网站 ›› 2024, Vol. 44 ›› Issue (12): 3907-3914.DOI: 10.11772/j.issn.1001-9081.2023111713
熊炜1( ), 陈奕博1, 张丽真1, 杨茜1, 邹勤2()
), 陈奕博1, 张丽真1, 杨茜1, 邹勤2()
收稿日期:2023-12-09
修回日期:2024-03-20
接受日期:2024-05-24
发布日期:2024-07-25
出版日期:2024-12-10
通讯作者:
熊炜,邹勤
作者简介:熊炜(1976—),男,湖北宜昌人,副教授,博士,主要研究方向:计算机视觉、模式识别基金资助:
Wei XIONG1(), Yibo CHEN1, Lizhen ZHANG1, Qian YANG1, Qin ZOU2()
Received:2023-12-09
Revised:2024-03-20
Accepted:2024-05-24
Online:2024-07-25
Published:2024-12-10
Contact:
Wei XIONG, Qin ZOU
About author:CHEN Yibo, born in 1998, M. S. candidate. His research interests include monocular depth estimation.Supported by:摘要:
多帧自监督单目深度估计通过当前帧和上一帧之间的关系构建代价体积(CV),可以作为单目深度估计网络的额外输入源,更准确地描述场景视频中的时间序列关系和空间结构信息;然而,当场景中存在动态物体或者无纹理区域时,CV会成为不可靠的信息来源。当单目深度估计网络过度依赖CV中的不可靠信息源时,会导致深度估计精度下降。为此,设计一种多帧融合模块动态降低不可靠信息源的权重,减小不可靠信息源对网络的影响。为了应对CV中不可靠信息源对网络训练的负面影响,还设计了一种引导深度估计网络训练的网络,防止深度估计网络过度依赖不可靠信息。所提方法在KITTI数据集上取得了出色的性能,与基准方法Lite-Mono相比,它的绝对相对误差、平方相对误差和均方根误差(RMSE)分别下降了0.015、0.094和0.200;与同类方法相比,所提方法精度更高,且占用的计算资源更少。所提网络结构充分利用了多帧训练的优势,同时避免了多帧训练的缺陷(即CV不确定性对网络的影响),可有效提升模型精度。
中图分类号:
熊炜, 陈奕博, 张丽真, 杨茜, 邹勤. 利用多帧序列影像的自监督单目深度估计[J]. 计算机应用, 2024, 44(12): 3907-3914.
Wei XIONG, Yibo CHEN, Lizhen ZHANG, Qian YANG, Qin ZOU. Self-supervised monocular depth estimation using multi-frame sequence images[J]. Journal of Computer Applications, 2024, 44(12): 3907-3914.
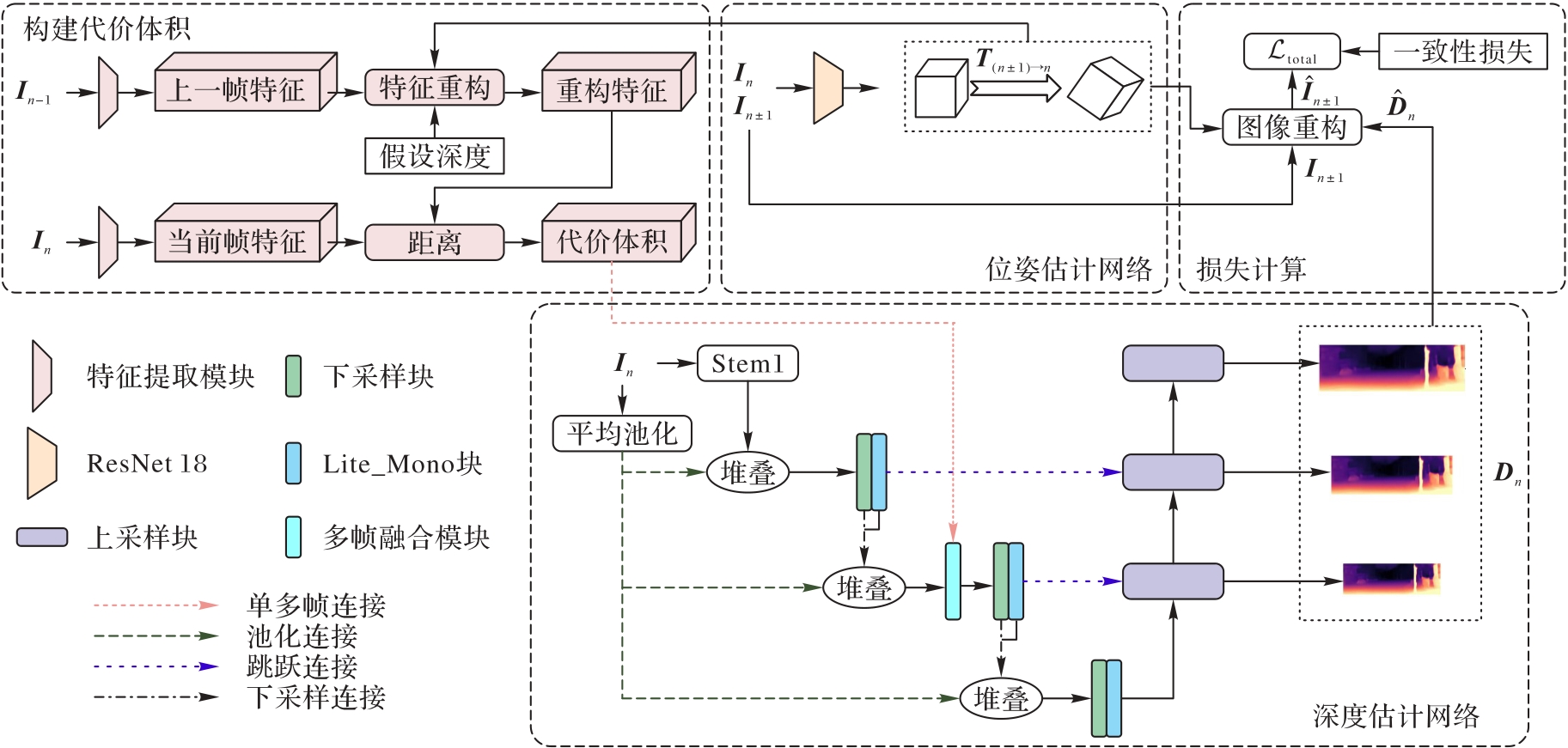
图1 整体网络架构
Fig. 1 Overall network architecture

图2 图像重构
Fig. 2 Image warping
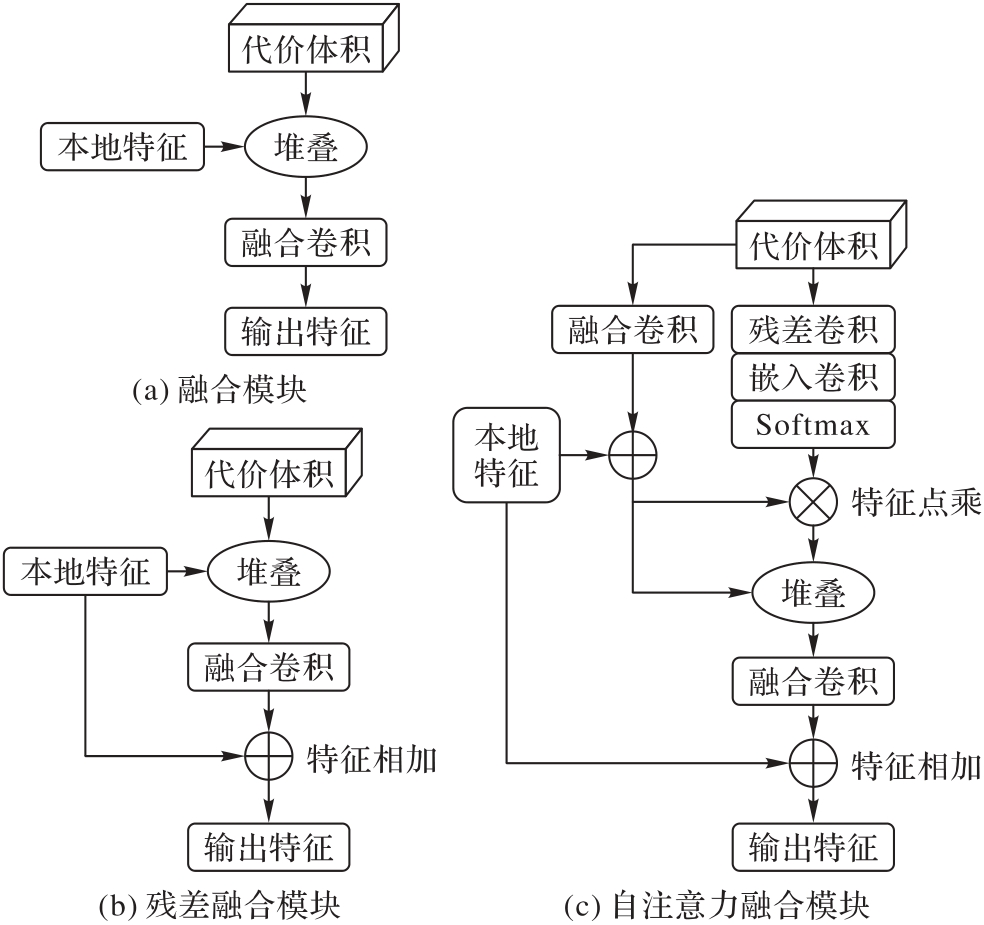
图3 多帧融合模块
Fig. 3 Multi-frame fusion module

图4 引导网络
Fig. 4 Guiding network
| 方法 | 误差(越低越好) | 阈值(越高越好) | |||||
|---|---|---|---|---|---|---|---|
| Abs.Rel | Sq.Rel | RMSE | RMSElog | ||||
| Monodepth2[ | 0.115 | 0.903 | 4.863 | 0.193 | 0.877 | 0.959 | 0.981 |
| PackNetSfm[ | 0.111 | 0.785 | 4.601 | 0.189 | 0.878 | 0.960 | 0.982 |
| ADAA[ | 0.111 | 0.817 | 4.685 | 0.188 | 0.883 | 0.961 | 0.982 |
| DepthSeg[ | 0.110 | 0.792 | 4.700 | 0.189 | 0.881 | 0.960 | 0.982 |
| MP[ | 0.112 | 0.856 | 4.778 | 0.190 | 0.880 | 0.961 | 0.982 |
| HR-Depth[ | 0.109 | 0.792 | 4.632 | 0.185 | 0.884 | 0.962 | 0.983 |
| DDV[ | 0.105 | 0.861 | 4.699 | 0.185 | 0.889 | 0.962 | 0.982 |
| TransDSSL[ | 0.102 | 0.753 | 4.461 | 0.177 | 0.896 | 0.966 | 0.984 |
| MonoViT[ | 0.102 | 0.733 | 4.459 | 0.177 | 0.895 | 0.965 | 0.984 |
| ManyDepth[ | 0.098 | 0.770 | 4.459 | 0.176 | 0.900 | 0.965 | 0.983 |
| Dynamic[ | 0.096 | 0.720 | 4.458 | 0.175 | 0.897 | 0.964 | 0.984 |
| Lite-Mono[ | 0.107 | 0.765 | 4.561 | 0.183 | 0.886 | 0.963 | 0.983 |
| LMVS(G 18) | 0.092 | 0.671 | 4.361 | 0.173 | 0.902 | 0.965 | 0.984 |
| LMVS(G 50) | 0.092 | 0.693 | 4.324 | 0.172 | 0.905 | 0.965 | 0.984 |
表1 自监督单目深度估计方法在KITTI数据集上的性能对比
Tab.1 Performance comparison of self-supervised monocular depth estimation methods on KITTI dataset
| 方法 | 误差(越低越好) | 阈值(越高越好) | |||||
|---|---|---|---|---|---|---|---|
| Abs.Rel | Sq.Rel | RMSE | RMSElog | ||||
| Monodepth2[ | 0.115 | 0.903 | 4.863 | 0.193 | 0.877 | 0.959 | 0.981 |
| PackNetSfm[ | 0.111 | 0.785 | 4.601 | 0.189 | 0.878 | 0.960 | 0.982 |
| ADAA[ | 0.111 | 0.817 | 4.685 | 0.188 | 0.883 | 0.961 | 0.982 |
| DepthSeg[ | 0.110 | 0.792 | 4.700 | 0.189 | 0.881 | 0.960 | 0.982 |
| MP[ | 0.112 | 0.856 | 4.778 | 0.190 | 0.880 | 0.961 | 0.982 |
| HR-Depth[ | 0.109 | 0.792 | 4.632 | 0.185 | 0.884 | 0.962 | 0.983 |
| DDV[ | 0.105 | 0.861 | 4.699 | 0.185 | 0.889 | 0.962 | 0.982 |
| TransDSSL[ | 0.102 | 0.753 | 4.461 | 0.177 | 0.896 | 0.966 | 0.984 |
| MonoViT[ | 0.102 | 0.733 | 4.459 | 0.177 | 0.895 | 0.965 | 0.984 |
| ManyDepth[ | 0.098 | 0.770 | 4.459 | 0.176 | 0.900 | 0.965 | 0.983 |
| Dynamic[ | 0.096 | 0.720 | 4.458 | 0.175 | 0.897 | 0.964 | 0.984 |
| Lite-Mono[ | 0.107 | 0.765 | 4.561 | 0.183 | 0.886 | 0.963 | 0.983 |
| LMVS(G 18) | 0.092 | 0.671 | 4.361 | 0.173 | 0.902 | 0.965 | 0.984 |
| LMVS(G 50) | 0.092 | 0.693 | 4.324 | 0.172 | 0.905 | 0.965 | 0.984 |

图5 实验结果可视化
Fig. 5 Visualization of experimental result
| 方法 | GFLOPs | 参数量/MB | Abs.Rel | |
|---|---|---|---|---|
| Monodepth[ | 8.038 | 14.329 | 0.115 | 0.887 |
| MonoViT[ | 23.700 | 10.300 | 0.102 | 0.895 |
| ManyDepth[ | 10.183 | 14.421 | 0.098 | 0.900 |
| Lite-Mono[ | 5.032 | 3.069 | 0.107 | 0.886 |
| LMVS | 9.241 | 3.400 | 0.092 | 0.902 |
表2 KITTI数据集上的参数量与浮点运算数
Tab.2 Parameters and GFLOPs on KITTI dataset
| 方法 | GFLOPs | 参数量/MB | Abs.Rel | |
|---|---|---|---|---|
| Monodepth[ | 8.038 | 14.329 | 0.115 | 0.887 |
| MonoViT[ | 23.700 | 10.300 | 0.102 | 0.895 |
| ManyDepth[ | 10.183 | 14.421 | 0.098 | 0.900 |
| Lite-Mono[ | 5.032 | 3.069 | 0.107 | 0.886 |
| LMVS | 9.241 | 3.400 | 0.092 | 0.902 |
| 方法 | Abs.Rel | Sq.Rel | RMSE | |
|---|---|---|---|---|
| ManyDepth[ | 0.114 | 1.193 | 6.223 | 0.875 |
| Dynamic[ | 0.103 | 1.000 | 5.867 | 0.895 |
| LMVS(G 50) | 0.101 | 0.965 | 5.652 | 0.898 |
表3 自监督单目深度估计方法在Cityscapes数据集上的性能对比
Tab. 3 Performance comparison of self-supervised monocular depth estimation methods on the Cityscapes dataset
| 方法 | Abs.Rel | Sq.Rel | RMSE | |
|---|---|---|---|---|
| ManyDepth[ | 0.114 | 1.193 | 6.223 | 0.875 |
| Dynamic[ | 0.103 | 1.000 | 5.867 | 0.895 |
| LMVS(G 50) | 0.101 | 0.965 | 5.652 | 0.898 |
代价 体积 | 引导 网络 | 多帧融合模块 | Abs.Rel | Sq.Rel | RMSE | |
|---|---|---|---|---|---|---|
| × | × | × | 0.107 | 0.765 | 4.561 | 0.886 |
| √ | × | × | 0.145 | 1.325 | 5.531 | 0.832 |
| √ | √ | × | 0.097 | 0.778 | 4.460 | 0.898 |
| √ | √ | √ | 0.092 | 0.671 | 4.361 | 0.902 |
表4 模型组件对自监督单目深度估计的消融实验结果
Tab. 4 Ablation experimental results about model components for self-supervised monocular depth estimation
代价 体积 | 引导 网络 | 多帧融合模块 | Abs.Rel | Sq.Rel | RMSE | |
|---|---|---|---|---|---|---|
| × | × | × | 0.107 | 0.765 | 4.561 | 0.886 |
| √ | × | × | 0.145 | 1.325 | 5.531 | 0.832 |
| √ | √ | × | 0.097 | 0.778 | 4.460 | 0.898 |
| √ | √ | √ | 0.092 | 0.671 | 4.361 | 0.902 |
| 多帧融合模块 | Abs.Rel | Sq.Rel | RMSE | RMSElog | |
|---|---|---|---|---|---|
| 融合模块 | 0.097 | 0.778 | 4.460 | 0.177 | 0.898 |
| 残差融合模块 | 0.092 | 0.671 | 4.361 | 0.173 | 0.902 |
| 自注意力融合模块 | 0.094 | 0.713 | 4.328 | 0.173 | 0.903 |
表5 多帧融合模块在自监督单目深度估计性能上的对比分析
Tab. 5 Comparative analysis of multi-frame fusion modules for self-supervised monocular depth estimation
| 多帧融合模块 | Abs.Rel | Sq.Rel | RMSE | RMSElog | |
|---|---|---|---|---|---|
| 融合模块 | 0.097 | 0.778 | 4.460 | 0.177 | 0.898 |
| 残差融合模块 | 0.092 | 0.671 | 4.361 | 0.173 | 0.902 |
| 自注意力融合模块 | 0.094 | 0.713 | 4.328 | 0.173 | 0.903 |

图6 多帧融合模块的可视化
Fig. 6 Visualization of multi-frame fusion modules
| 引导网络 | Abs.Rel | Sq.Rel | RMSE | RMSElog | |
|---|---|---|---|---|---|
| Guided 18 | 0.115 | 0.903 | 4.863 | 0.193 | 0.877 |
| Guided 50 | 0.115 | 0.882 | 4.701 | 0.190 | 0.879 |
| Guided Lite-Mono | 0.107 | 0.765 | 4.561 | 0.183 | 0.886 |
| LMVS w/o G | 0.145 | 1.325 | 5.531 | 0.225 | 0.832 |
| LMVS G18 | 0.092 | 0.671 | 4.361 | 0.173 | 0.902 |
| LMVS G50 | 0.092 | 0.693 | 4.324 | 0.172 | 0.905 |
| LMVS GLite-Mono | 0.101 | 0.756 | 4.596 | 0.184 | 0.892 |
表6 不同引导网络对自监督单目深度估计模型的影响分析
Fig. 6 Analysis of the impact of different guiding networks on self-supervised monocular depth estimation
| 引导网络 | Abs.Rel | Sq.Rel | RMSE | RMSElog | |
|---|---|---|---|---|---|
| Guided 18 | 0.115 | 0.903 | 4.863 | 0.193 | 0.877 |
| Guided 50 | 0.115 | 0.882 | 4.701 | 0.190 | 0.879 |
| Guided Lite-Mono | 0.107 | 0.765 | 4.561 | 0.183 | 0.886 |
| LMVS w/o G | 0.145 | 1.325 | 5.531 | 0.225 | 0.832 |
| LMVS G18 | 0.092 | 0.671 | 4.361 | 0.173 | 0.902 |
| LMVS G50 | 0.092 | 0.693 | 4.324 | 0.172 | 0.905 |
| LMVS GLite-Mono | 0.101 | 0.756 | 4.596 | 0.184 | 0.892 |

图7 引导网络的可视化
Fig. 7 Visualization of guiding networks
| 1 | 罗会兰,周逸风. 深度学习单目深度估计研究进展[J]. 中国图象图形学报, 2022, 27(2): 390-403. |
| LUO H L, ZHOU Y F. Review of monocular depth estimation based on deep learning [J]. Journal of Image and Graphics, 2022, 27(2): 390-403. | |
| 2 | 曹家乐,李亚利,孙汉卿,等. 基于深度学习的视觉目标检测技术综述[J]. 中国图象图形学报, 2022, 27(6): 1697-1722. |
| CAO J L, LI Y L, SUN H Q, et al. A survey on deep learning based visual object detection [J]. Journal of Image and Graphics, 2022, 27(6): 1697-1722. | |
| 3 | HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016:770-778. |
| 4 | FU H, GONG M, WANG C, et al. Deep ordinal regression network for monocular depth estimation [C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018:2002-2011. |
| 5 | GODARD C, AODHA O MAC, BROSTOW G J. Unsupervised monocular depth estimation with left-right consistency[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017:6602-6611. |
| 6 | LUO Y, REN J, LIN M, et al. Single view stereo matching [C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018:155-163. |
| 7 | ZHOU T, BROWN M, SNAVELY N, et al. Unsupervised learning of depth and ego-motion from video [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017:6612-6619. |
| 8 | GODARD C, AODHA O MAC, FIRMAN M, et al. Digging into self-supervised monocular depth estimation [C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019:3827-3837. |
| 9 | GUIZILINI V, AMBRUŞ R, PILLAI S, et al. 3D packing for self-supervised monocular depth estimation [C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020:2482-2491. |
| 10 | ZHANG Y, LEONARD J J. Bootstrapped self-supervised training with monocular video for semantic segmentation and depth estimation[C]// Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems. Piscataway: IEEE, 2021:2420-2427. |
| 11 | NEKRASOV V, DHARMASIRI T, SPEK A, et al. Real-time joint semantic segmentation and depth estimation using asymmetric annotations [C]// Proceedings of the 2019 International Conference on Robotics and Automation. Piscataway: IEEE, 2019:7101-7107. |
| 12 | MUN J H, JEON M, LEE B G. Unsupervised learning for depth, ego-motion, and optical flow estimation using coupled consistency conditions [J]. Sensors, 2019, 19(11): No.2459. |
| 13 | RANJAN A, JAMPANI V, BALLES L, et al. Competitive collaboration: joint unsupervised learning of depth, camera motion, optical flow and motion segmentation [C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019:12232-12241. |
| 14 | LI R, GONG D, YIN W, et al. Learning to fuse monocular and multi-view cues for multi-frame depth estimation in dynamic scenes[C]// Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2023:21539-21548. |
| 15 | KENDALL A, MARTIROSYAN H, DASGUPTA S, et al. End-to-end learning of geometry and context for deep stereo regression[C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2017:66-75. |
| 16 | FENG Z, YANG L, JING L, et al. Disentangling object motion and occlusion for unsupervised multi-frame monocular depth [C]// Proceedings of the 2022 European Conference on Computer Vision, LNCS 13692. Cham: Springer, 2022:228-244. |
| 17 | WATSON J, AODHA O MAC, PRISACARIU V, et al. The temporal opportunist: self-supervised multi-frame monocular depth[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021:1164-1174. |
| 18 | WANG X, ZHU Z, HUANG G, et al. Crafting monocular cues and velocity guidance for self-supervised multi-frame depth learning [C]// Proceedings of the 37th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2023:2689-2697. |
| 19 | ZHANG N, NEX F, VOSSELMAN G, et al. Lite-Mono: a lightweight CNN and Transformer architecture for self-supervised monocular depth estimation [C]// Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2023:18537-18546. |
| 20 | HE K, ZHANG X, REN S, et al. Identity mappings in deep residual networks[C]// Proceedings of the 2016 European Conference on Computer Vision, LNCS 9908. Cham: Springer, 2016: 630-645. |
| 21 | DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16×16 words: Transformers for image recognition at scale[EB/OL]. (2021-06-03) [2023-08-22].. |
| 22 | GEIGER A, LENZ P, STILLER C, et al. Vision meets robotics: the KITTI dataset[J]. The International Journal of Robotics Research, 2013, 32(11): 1231-1237. |
| 23 | EIGEN D, FERGUS R. Predicting depth, surface normals and semantic labels with a common multi-scale convolutional architecture[C]// Proceedings of the 2015 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2015:2650-2658. |
| 24 | EIGEN D, PUHRSCH C, FERGUS R. Depth map prediction from a single image using a multi-scale deep network [C]// Proceedings of the 27th International Conference on Neural Information Processing Systems — Volume 2. Cambridge: MIT Press, 2014:2366-2374. |
| 25 | CORDTS M, OMRAN M, RAMOS S, et al. The Cityscapes dataset for semantic urban scene understanding [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016:3213-3223. |
| 26 | LOSHCHILOV I, HUTTER F. Decoupled weight decay regularization[EB/OL]. (2019-01-04) [2023-08-22].. |
| 27 | LOSHCHILOV I, HUTTER F. SGDR: stochastic gradient descent with warm restarts [EB/OL]. (2019-05-03) [2023-08-22].. |
| 28 | HAN D, SHIN J, KIM N, et al. TransDSSL: Transformer based depth estimation via self-supervised learning [J]. IEEE Robotics and Automation Letters, 2022, 7(4): 10969-10976. |
| 29 | ZHAO C, ZHANG Y, POGGI M, et al. MonoViT: self-supervised monocular depth estimation with a vision Transformer [C]// Proceedings of the 2022 International Conference on 3D Vision. Piscataway: IEEE, 2022:668-678. |
| 30 | KAUSHIK V, JINDGAR K, LALL B. ADAADepth: adapting data augmentation and attention for self-supervised monocular depth estimation[J]. IEEE Robotics and Automation Letters, 2021, 6(4): 7791-7798. |
| 31 | SAFADOUST S, GÜNEY F. Self-supervised monocular scene decomposition and depth estimation [C]// Proceedings of the 2021 International Conference on 3D Vision. Piscataway: IEEE, 2021:627-636. |
| 32 | ZHANG Y, GONG M, LI J, et al. Self-supervised monocular depth estimation with multiscale perception[J]. IEEE Transactions on Image Processing, 2022, 31: 3251-3266. |
| 33 | LYU X, LIU L, WANG M, et al. HR-Depth: high resolution self-supervised monocular depth estimation[C]// Proceedings of the 35th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2021:2294-2301. |
| 34 | JOHNSTON A, CARNEIRO G. Self-supervised monocular trained depth estimation using self-attention and discrete disparity volume[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020:4755-4764. |
| [1] | 胡立华, 李小平, 胡建华, 张素兰. 基于四叉树先验辅助的多视图立体方法[J]. 《计算机应用》唯一官方网站, 2024, 44(11): 3556-3564. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||