


《计算机应用》唯一官方网站 ›› 2023, Vol. 43 ›› Issue (11): 3517-3526.DOI: 10.11772/j.issn.1001-9081.2022101548
所属专题: 先进计算
陈虎1,2, 周鹏灵1( )
)
收稿日期:2022-10-14
修回日期:2023-04-22
接受日期:2023-04-24
发布日期:2023-05-24
出版日期:2023-11-10
通讯作者:
周鹏灵
作者简介:陈虎(1974—),男,江苏南京人,副教授,博士,主要研究方向:高性能计算、信息安全基金资助:
Hu CHEN1,2, Pengling ZHOU1()
Received:2022-10-14
Revised:2023-04-22
Accepted:2023-04-24
Online:2023-05-24
Published:2023-11-10
Contact:
Pengling ZHOU
About author:CHEN Hu, born in 1974, Ph. D., associate professor. His research interests include high-performance computing, information security.Supported by:摘要:
在国产高性能众核处理器上编程时,需要直接使用最底层的接口开发软件,这使编程和调试非常困难;并且各自平台的高性能软件编程模型较为基础,计算软件不能通用,造成了重复性开发。针对以上问题,实现了通用编程模型以及所对应的支撑库:一方面基于消息队列机制开发国产高性能众核处理器的线程级并行机制;另一方面基于单指令多数据流(SIMD)编程模型开发从核上的数据级并行性。首先,对国产高性能众核处理器体系结构进行抽象;其次,设计模型的消息队列机制,并为程序员提供一套异构并行编程接口,如系统参数接口、从核线程控制接口、消息队列接口、SIMD抽象接口;最后,在上述基础上形成全新的高性能计算软件开发模型和方法,方便用户开发基于国产高性能众核处理器的并行计算软件。性能传输测试结果表明,在国产众核处理器上,当启动核数较少时,所提模型的传输带宽普遍达到了峰值直接内存访问(DMA)带宽的90%;当启动的核数较多时,消息队列模型的传输带宽普遍达到了峰值DMA带宽的70%。在矩阵乘法实验中,与系统原语传输矩阵并计算的性能相比,所提模型的性能达到前者的90%;在口令猜测系统中,所提模型的代码性能与直接使用最底层的接口开发的代码性能基本持平。所提通用编程模型和支撑框架使高性能计算(HPC)软件开发更简易,并且具有更好的可移植性,可为促进国产自主HPC软件研发提供帮助。
中图分类号:
陈虎, 周鹏灵. 面向国产高性能众核处理器的编程模型[J]. 计算机应用, 2023, 43(11): 3517-3526.
Hu CHEN, Pengling ZHOU. Programming model for domestic high-performance many-core processor[J]. Journal of Computer Applications, 2023, 43(11): 3517-3526.

图1 基于本文模型的国产HPC软件开发流程
Fig. 1 Software development flow of domestic HPC based on proposed model
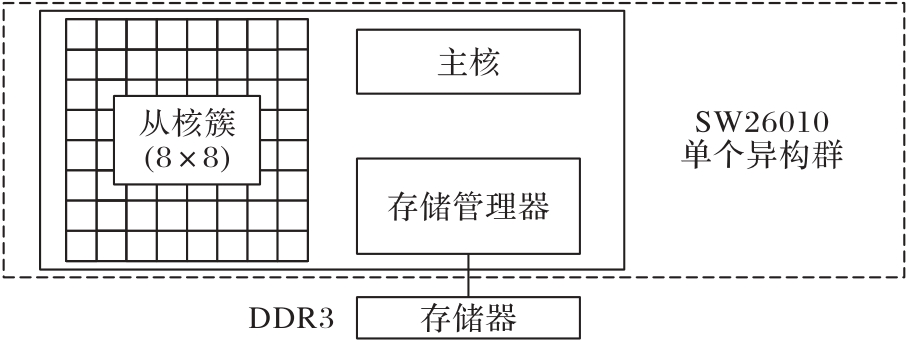
图2 SW26010处理器中单个异构群结构
Fig. 2 Single heterogeneous group structure in SW26011 processor

图3 面向E级高性能计算的加速器芯片
Fig. 3 Heterogeneous accelerator chip for exascale HPC

图4 国产高性能异构处理器的体系结构抽象
Fig. 4 Architecture abstraction of domestic high-performance heterogeneous processor
| 处理器 | 主核数 | 从核数 | 从核的局部存储器容量 | 从核SIMD宽度/bit | 从核线程模型 |
|---|---|---|---|---|---|
| x86 | 1 | 48 | — | 256 (AVX) | pthread |
| SW26010 | 64 | 64 KB | 256 | athread | |
| 面向E级高性能计算的异构融合加速器 | 16 | 24 | 768 KB AM空间+64 KB SM空间 | 1 024 | hThread |
表1 国产高性能众核处理器的主要参数
Tab. 1 Main parameters of domestic high-performance many-core processors
| 处理器 | 主核数 | 从核数 | 从核的局部存储器容量 | 从核SIMD宽度/bit | 从核线程模型 |
|---|---|---|---|---|---|
| x86 | 1 | 48 | — | 256 (AVX) | pthread |
| SW26010 | 64 | 64 KB | 256 | athread | |
| 面向E级高性能计算的异构融合加速器 | 16 | 24 | 768 KB AM空间+64 KB SM空间 | 1 024 | hThread |
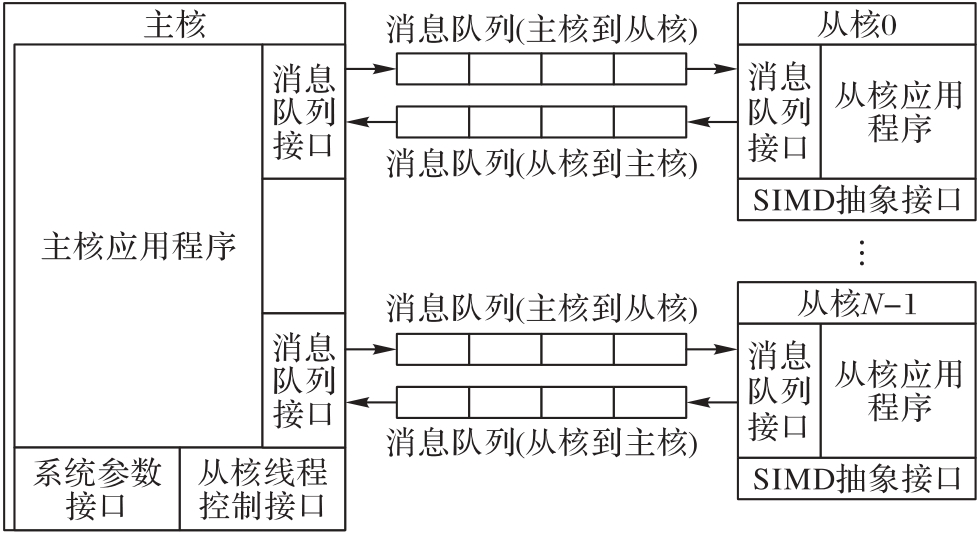
图5 针对国产高性能众核处理器的编程模型
Fig. 5 Programming model for domestic high-performance many-core processors
| 主核句柄表 | 队列名称 | 主核句柄号 | 从核A句柄号 | 从核B句柄号 |
|---|---|---|---|---|
| 从核A | MasterToA | 0 | 0 | — |
| AToMaster | 1 | 1 | — | |
| 从核B | MasterToB | 0 | — | 0 |
| BToMaster | 1 | — | 1 |
表2 队列句柄示例
Tab. 2 Examples of queue handle
| 主核句柄表 | 队列名称 | 主核句柄号 | 从核A句柄号 | 从核B句柄号 |
|---|---|---|---|---|
| 从核A | MasterToA | 0 | 0 | — |
| AToMaster | 1 | 1 | — | |
| 从核B | MasterToB | 0 | — | 0 |
| BToMaster | 1 | — | 1 |
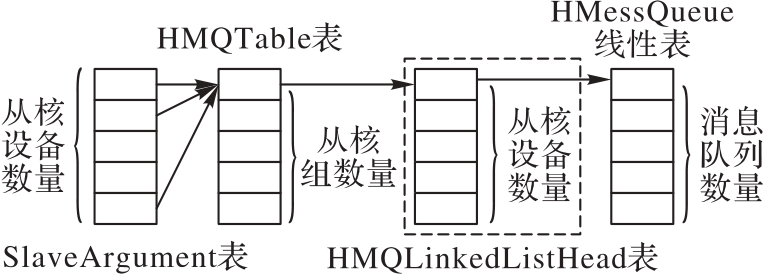
图6 系统主核的主要数据结构
Fig. 6 Main data structure of system master core

图7 消息队列的组织
Fig. 7 Organization of message queue

图8 主核到从核方向消息队列的控制信息布局
Fig. 8 Layout of control information for message queues in direction from master core to slave core

图9 从核到主核方向消息队列的控制信息布局
Fig. 9 Layout of control information for message queues in direction from slave core to master core
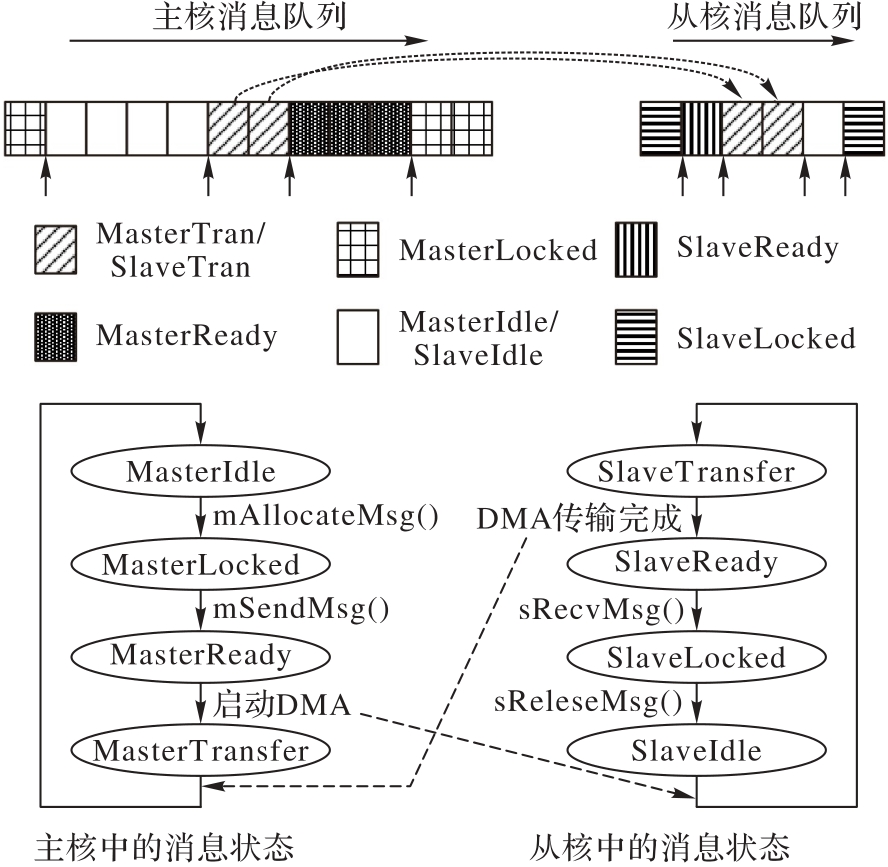
图10 主核发往从核时消息队列中消息的状态
Fig. 10 Status of messages in message queue when sending from master core to slave core
| 操作 | 描述 |
|---|---|
| 赋值操作 | _VU32 dst=_VU32_SET1(uint32_t a) 将 |
| 逻辑操作 | _VU32 dst=_VU32_NOT(_VU32 __a) a按位取反,并将结果存储在 |
| 算术操作 | _VU32 dst=_VU32_ADD(_VU32 __a, _VU32 __b) 32 bits整数的加法操作 _VU32 dst=_VU32_SUB(_VU32 __a, _VU32 __b) 32 bits整数的减法操作 |
| 移位操作 | _VU32 dst=_VU32_SLI(_VU32 a,uint32_t b) 32 bits整数的逻辑左移操作 _VU32 dst=_VU32_SRI(_VU32 a,uint32_t b) 32 bits整数的逻辑右移操作 |
| 比较操作 | _VU32 dst =_VU32_CMPEQ(_VU32 _a, _VU32 _b) 判断两个向量是否相等 _VU32 dst=_VU32_CMPNE(_VU32 _a, _VU32 _b) 判断两个向量是否不相等 |
| 访存操作 | _VU32_LOAD (_VU32 dst,uint32_t*mem_addr) 将mem_addr数据从内存加载到 |
_VU32_STORE(_VU32 dst,uint32_t *mem_addr) 将向量 |
表3 典型的32位无符号整数向量操作指令
Tab. 3 Typical 32-bit unsigned integer vector manipulation instructions
| 操作 | 描述 |
|---|---|
| 赋值操作 | _VU32 dst=_VU32_SET1(uint32_t a) 将 |
| 逻辑操作 | _VU32 dst=_VU32_NOT(_VU32 __a) a按位取反,并将结果存储在 |
| 算术操作 | _VU32 dst=_VU32_ADD(_VU32 __a, _VU32 __b) 32 bits整数的加法操作 _VU32 dst=_VU32_SUB(_VU32 __a, _VU32 __b) 32 bits整数的减法操作 |
| 移位操作 | _VU32 dst=_VU32_SLI(_VU32 a,uint32_t b) 32 bits整数的逻辑左移操作 _VU32 dst=_VU32_SRI(_VU32 a,uint32_t b) 32 bits整数的逻辑右移操作 |
| 比较操作 | _VU32 dst =_VU32_CMPEQ(_VU32 _a, _VU32 _b) 判断两个向量是否相等 _VU32 dst=_VU32_CMPNE(_VU32 _a, _VU32 _b) 判断两个向量是否不相等 |
| 访存操作 | _VU32_LOAD (_VU32 dst,uint32_t*mem_addr) 将mem_addr数据从内存加载到 |
_VU32_STORE(_VU32 dst,uint32_t *mem_addr) 将向量 |
| 处理器 | 从核数 | 次数 | 总传输量/GB | 主核发往从核耗时/s | 从核发往主核耗时/s | ||
|---|---|---|---|---|---|---|---|
| 消息队列模型 | 调用系统接口DMA | 消息队列模型 | 调用系统接口DMA | ||||
| SW26010 | 1 | 102 400 | 1.560 0 | 0.190 | 0.180 | 0.290 | 0.210 |
| 8 | 102 400 | 12.500 0 | 0.960 | 0.850 | 1.140 | 1.120 | |
| 64 | 102 400 | 100.000 0 | 5.420 | 3.830 | 7.780 | 4.350 | |
面向E级高性能计算的 加速器芯片 | 1 | 4 096 | 0.062 5 | 0.016 | 0.013 | 0.015 | 0.012 |
| 1 | 102 400 | 1.560 0 | 0.288 | 0.200 | 0.266 | 0.179 | |
| 24 | 4 096 | 1.500 0 | 0.143 | 0.133 | 0.130 | 0.108 | |
| 24 | 102 400 | 37.500 0 | 3.603 | 2.874 | 3.150 | 2.218 | |
表4 数据传输性能测试结果对比
Tab. 4 Comparison of data transmission performance test results
| 处理器 | 从核数 | 次数 | 总传输量/GB | 主核发往从核耗时/s | 从核发往主核耗时/s | ||
|---|---|---|---|---|---|---|---|
| 消息队列模型 | 调用系统接口DMA | 消息队列模型 | 调用系统接口DMA | ||||
| SW26010 | 1 | 102 400 | 1.560 0 | 0.190 | 0.180 | 0.290 | 0.210 |
| 8 | 102 400 | 12.500 0 | 0.960 | 0.850 | 1.140 | 1.120 | |
| 64 | 102 400 | 100.000 0 | 5.420 | 3.830 | 7.780 | 4.350 | |
面向E级高性能计算的 加速器芯片 | 1 | 4 096 | 0.062 5 | 0.016 | 0.013 | 0.015 | 0.012 |
| 1 | 102 400 | 1.560 0 | 0.288 | 0.200 | 0.266 | 0.179 | |
| 24 | 4 096 | 1.500 0 | 0.143 | 0.133 | 0.130 | 0.108 | |
| 24 | 102 400 | 37.500 0 | 3.603 | 2.874 | 3.150 | 2.218 | |

图11 使用编程模型的矩阵乘法主核和从核的软件模块
Fig. 11 Software module of matrix multiplication by using programming model
| 核 | 主频/MHz | Cache | 内存 | SIMD位数 | 编译选项 |
|---|---|---|---|---|---|
| 主核 | 1 500 | L1 Cache大小为32 KB L2 Cache(数据Cache和指令Cache混合) 大小为256 KB | 8 GB | 256 | sw5CC -host -O2 -fopenmp -DSW5_VERSION |
| 从核 | 1 500 | 指令Cache:16 KB | 64 KB | 256 | sw5cc -slave -msimd -std=gnu99 -O2 -DSW5_VERSION |
表5 国产众核处理器SW26010配置
Tab. 5 Configuration for SW26010 processor
| 核 | 主频/MHz | Cache | 内存 | SIMD位数 | 编译选项 |
|---|---|---|---|---|---|
| 主核 | 1 500 | L1 Cache大小为32 KB L2 Cache(数据Cache和指令Cache混合) 大小为256 KB | 8 GB | 256 | sw5CC -host -O2 -fopenmp -DSW5_VERSION |
| 从核 | 1 500 | 指令Cache:16 KB | 64 KB | 256 | sw5cc -slave -msimd -std=gnu99 -O2 -DSW5_VERSION |

图12 双缓冲操作逻辑
Fig. 12 Logic diagram with double buffering operation
| 编译选项 | x86 | SW26010 | 面向E级计算的异构融合加速器 |
|---|---|---|---|
| 主核编译器指令CXX | gcc | sw5CC | gcc |
| 从核编译器指令CC | gcc | sw5cc | tic6x-elf-gcc |
| 指定编译宏MFLAG | -DAVX-VERSION | -DSW5-VERSION | -DMT3-VERSION |
| 主核编译选CXXFLAGS | -std=gnu99 -g | -host -std=gnu99 | -std=gnu99 -g |
| 从核编译选项CFLAGS | -std=gnu99 -g -mavx2 | -slave -std=gnu99 -msimd | -std=c99 -fenable-m3000 -ffunction-sections -flax-vector-conversions |
| 主从核文件链接选项LFLAGS | -lstdc++ | -hybrid -lstdc++ | --gc-sections -Tdsp.lds |
表6 不同平台的编译选项
Tab. 6 Compile options for different platforms
| 编译选项 | x86 | SW26010 | 面向E级计算的异构融合加速器 |
|---|---|---|---|
| 主核编译器指令CXX | gcc | sw5CC | gcc |
| 从核编译器指令CC | gcc | sw5cc | tic6x-elf-gcc |
| 指定编译宏MFLAG | -DAVX-VERSION | -DSW5-VERSION | -DMT3-VERSION |
| 主核编译选CXXFLAGS | -std=gnu99 -g | -host -std=gnu99 | -std=gnu99 -g |
| 从核编译选项CFLAGS | -std=gnu99 -g -mavx2 | -slave -std=gnu99 -msimd | -std=c99 -fenable-m3000 -ffunction-sections -flax-vector-conversions |
| 主从核文件链接选项LFLAGS | -lstdc++ | -hybrid -lstdc++ | --gc-sections -Tdsp.lds |
| N | 系统原语传输矩阵并计算 | 消息队列模型传输矩阵并计算 | ||
|---|---|---|---|---|
| GFLOPs | 效率/% | GFLOPs | 效率/% | |
| 4 096 | 556 | 89.5 | 503 | 81.0 |
| 8 192 | 570 | 91.0 | 504 | 81.0 |
表7 SW26010上的性能测试对比
Tab. 7 Comparison of performance on SW26010
| N | 系统原语传输矩阵并计算 | 消息队列模型传输矩阵并计算 | ||
|---|---|---|---|---|
| GFLOPs | 效率/% | GFLOPs | 效率/% | |
| 4 096 | 556 | 89.5 | 503 | 81.0 |
| 8 192 | 570 | 91.0 | 504 | 81.0 |
| 1 | 刘鑫,郭恒,孙茹君,等.“神威·太湖之光”计算机系统大规模应用特征分析与E级可扩展性研究[J].计算机学报,2018,41(10):2209-2220. 10.11897/SP.J.1016.2018.02209 |
| LIU X, GUO H, SUN R J, et al. The characteristic analysis and exascale scalability research of large scale parallel applications on “Sunway ·TaihuLight” supercomputer[J]. Chinese Journal of Computers, 2018,41(10):2209-2220. 10.11897/SP.J.1016.2018.02209 | |
| 2 | FU H, LIAO J, YANG J, et al. The Sunway TaihuLight supercomputer: system and applications[J]. Science China Information Sciences, 2016, 59(7): No.072001. 10.1007/s11432-016-5588-7 |
| 3 | LU K, WANG Y, GUO Y, et al. MT-3000: a heterogeneous multi-zone processor for HPC[J]. CCF Transactions on High Performance Computing, 2022, 4(2):150-164. 10.1007/s42514-022-00095-y |
| 4 | 刘胜,卢凯,郭阳,等. 一种自主设计的面向E级高性能计算的异构融合加速器[J].计算机研究与发展,2021,58(06):1234-1237. 10.7544/issn1000-1239.2021.20210189 |
| LIU S, LU K, GUO Y, et al. A self-designed heterogeneous fusion accelerator for exascale high-performance computing[J]. Journal of Computer Research and Development, 2021,58(06):1234-1237. 10.7544/issn1000-1239.2021.20210189 | |
| 5 | NAGARAJAN V, SORIN D J, HILL M D, et al. A Primer on Memory Consistency and Cache Coherence[M]. 2nd ed. Cham: Springer, 2020: 10-11. 10.1007/978-3-031-01764-3_11 |
| 6 | DE SUPINSKI B R, SCOGLAND T R W, DURAN A, et al. The ongoing evolution of OpenMP[J]. Proceedings of the IEEE, 2018, 106(11): 2004-2019. 10.1109/jproc.2018.2853600 |
| 7 | ABBOTT D. Appendix B — Posix threads (pthreads) application programming interface[M]// Linux for Embedded and Real-time Applications, 2nd ed. New York: Elsevier Science Inc.,2006: 275-286. 10.1016/b978-075067932-9/50040-3 |
| 8 | BARKER D J, STUCKEY D C. A review of soluble microbial products (SMP) in wastewater treatment systems[J]. Water Research, 1999, 33(14): 3063-3082. 10.1016/s0043-1354(99)00022-6 |
| 9 | CAROTHERS C D, PERUMALLA K S, FUJIMOTO R M. The effect of state-saving in optimistic simulation on a cache-coherent non-uniform memory access architecture[C]// Proceedings of the 31st Conference on Winter Simulation: Simulation — A Bridge to the Future — Volume 2. New York: ACM, 1999: 1624-1633. 10.1145/324898.325340 |
| 10 | GUPTA K, SHARMA T. Changing trends in computer architecture: A comprehensive analysis of ARM and x86 processors[J]. International Journal of Scientific Research in Computer Science Engineering and Information Technology, 2021, 7(3): 619-631. |
| 11 | ROBISON A D. Composable parallel patterns with Intel Cilk Plus[J]. Computing in Science and Engineering, 2013, 15(2): 66-71. 10.1109/mcse.2013.21 |
| 12 | VOSS M, ASENJO R, REINDERS J. Pro TBB: C++ Parallel Programming with Threading Building Blocks[M]. Berkeley, CA: Apress, 2019: 3-31. 10.1007/978-1-4842-4398-5_1 |
| 13 | NOZAL R, BOSQUE J L. Exploiting co-execution with oneAPI: heterogeneity from a modern perspective[C]// Proceedings of the 27th International Conference on Parallel and Distributed Computing, LNTCS 12820. Cham: Springer, 2021: 501-516. |
| 14 | RAMAN S K, PENTKOVSKI V, KESHAVA J. Implementing streaming SIMD extensions on the Pentium III processor[J]. IEEE Micro, 2000, 20(4): 47-57. 10.1109/40.865866 |
| 15 | AMIRI H, SHAHBAHRAMI A. SIMD programming using Intel vector extensions[J]. Journal of Parallel and Distributed Computing, 2020, 135: 83-100. 10.1016/j.jpdc.2019.09.012 |
| 16 | STEPHENS N, BILES S, BOETTCHER M, et al. The ARM scalable vector extension[J]. IEEE Micro, 2017,37(2):26-39. 10.1109/mm.2017.35 |
| 17 | ODAJIMA T, KODAMA Y, SATO M. Performance and power consumption analysis of ARM scalable vector extension[J]. The Journal of Supercomputing, 2021, 77(6): 5757-5778. 10.1007/s11227-020-03495-5 |
| 18 | WANG D, ZHAO R, WANG Q, et al. Outer-loop auto-vectorization for SIMD architectures based on Open64 compiler[C]// Proceedings of the 17th International Conference on Parallel and Distributed Computing, Applications and Technologies. Piscataway: IEEE, 2016: 19-23. 10.1109/pdcat.2016.020 |
| 19 | TIAN X, SAITO H, SU E, et al. LLVM compiler implementation for explicit parallelization and SIMD vectorization[C]// Proceedings of the 4th Workshop on the LLVM Compiler Infrastructure in HPC. New York: ACM, 2017: No.4. 10.1145/3148173.3148191 |
| 20 | CEBRIÁN J M, JAHRE M, NATVIG L. Optimized hardware for suboptimal software: the case for SIMD-aware benchmarks[C]// Proceedings of the 2014 IEEE International Symposium on Performance Analysis of Systems and Software. Piscataway: IEEE, 2014: 66-75. 10.1109/ispass.2014.6844462 |
| 21 | KRETZ M, LINDENSTRUTH V. Vc: a C++ library for explicit vectorization[J]. Software: Practice and Experience, 2012, 42(11): 1409-1430. 10.1002/spe.1149 |
| 22 | WANG H, WU P, TANASE I G, et al. Simple, portable and fast SIMD intrinsic programming: generic simd library[C]//Proceedings of the 2014 ACM SIGPLAN Workshop on Programming Models for SIMD/Vector Processing. New York: ACM, 2014: 9-16. 10.1145/2568058.2568059 |
| 23 | FRIGO M, JOHNSON S G. FFTW: an adaptive software architecture for the FFT[C]// Proceedings of the 1998 IEEE International Conference on Acoustics, Speech and Signal Processing, Volume 3. Piscataway: IEEE, 1998: 1381-1384. 10.1109/icassp.1998.681704 |
| 24 | 华南理工大学,广东省科技基础条件平台中心.基于局部存储器的主核与从核之间消息传递系统: 2023100756041[P]. 2023-06-23. |
| South China University of Technology, Guangdong Science and Technology Infrastructure Center. Message transfer system between master and slave cores based on local memory: 2023100756041.1[P]. 2023-06-23. | |
| 25 | MAFFIONE V, LETTIERI G, RIZZO L. Cache-aware design of general-purpose Single-Producer-Single-Consumer queues[J]. Software: Practice and Experience, 2019, 49(5): 748-779. 10.1002/spe.2675 |
| 26 | ALMAN J, WILLIAMS V V. A refined laser method and faster matrix multiplication[C]// Proceedings of the 32nd Annual ACM-SIAM Symposium on Discrete Algorithms. Philadelphia, PA: SIAM, 2021: 522-539. 10.1137/1.9781611976465.32 |
| [1] | 龚鸣清, 叶煌, 张鉴, 卢兴敬, 陈伟. 基于ARMv8架构的面向机器翻译的单精度浮点通用矩阵乘法优化[J]. 计算机应用, 2019, 39(6): 1557-1562. |
| [2] | 黄胜兵, 郑启龙, 郭连伟. 分簇VLIW DSP上支持单双字模式选择的SIMD编译优化[J]. 计算机应用, 2015, 35(8): 2371-2374. |
| [3] | 张拥军, 陈艇. 基于软件无线电的并行多输入多输出均衡技术[J]. 计算机应用, 2015, 35(4): 1179-1184. |
| [4] | 索维毅 赵荣彩 姚远 刘鹏. 面向DSP的超字并行指令分析和冗余优化算法[J]. 计算机应用, 2012, 32(12): 3303-3307. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||