


《计算机应用》唯一官方网站 ›› 2023, Vol. 43 ›› Issue (12): 3772-3778.DOI: 10.11772/j.issn.1001-9081.2022121838
所属专题: 数据科学与技术
王啸飞1,2, 鲍胜利1,2( ), 陈炯环1,2
), 陈炯环1,2
收稿日期:2022-12-12
修回日期:2023-02-13
接受日期:2023-02-16
发布日期:2023-03-09
出版日期:2023-12-10
通讯作者:
鲍胜利
作者简介:王啸飞(1997—),男,湖南慈利人,硕士研究生,主要研究方向:机器学习、推荐算法基金资助:
Xiaofei WANG1,2, Shengli BAO1,2(), Jionghuan CHEN1,2
Received:2022-12-12
Revised:2023-02-13
Accepted:2023-02-16
Online:2023-03-09
Published:2023-12-10
Contact:
Shengli BAO
About author:WANG Xiaofei, born in 1997, M. S. candidate. His research interests include machine learning, recommendation algorithm.Supported by:摘要:
针对传统聚类算法在对缺失样本进行数据填充过程中存在样本相似度难度量且填充数据质量差的问题,提出一种基于潜在因子模型(LFM)在子空间上的缺失值注意力聚类算法。首先,通过LFM将原始数据空间映射到低维子空间,降低样本的稀疏程度;其次,通过分解原空间得到的特征矩阵构建不同特征间的注意力权重图,优化子空间样本间的相似度计算方式,使样本相似度的计算更准确、泛化性更好;最后,为了降低样本相似度计算过程中过高的时间复杂度,设计一种多指针的注意力权重图进行优化。在4个按比例随机缺失的数据集上进行实验。在Hand-digits数据集上,相较于面向高维特征缺失数据的K近邻插补子空间聚类(KISC)算法,在数据缺失比例为10%的情况下,所提算法的聚类准确度(ACC)提高了2.33个百分点,归一化互信息(NMI)提高了2.77个百分点,在数据缺失比例为20%的情况下,所提算法的ACC提高了0.39个百分点,NMI提高了1.33个百分点,验证了所提算法的有效性。
中图分类号:
王啸飞, 鲍胜利, 陈炯环. 基于潜在因子模型在子空间上的缺失值注意力聚类算法[J]. 计算机应用, 2023, 43(12): 3772-3778.
Xiaofei WANG, Shengli BAO, Jionghuan CHEN. Missing value attention clustering algorithm based on latent factor model in subspace[J]. Journal of Computer Applications, 2023, 43(12): 3772-3778.
| 符号 | 定义 | 符号 | 定义 |
|---|---|---|---|
| 缺失特征样本数据集 | 特征矩阵 | ||
| 第 | 特征 | ||
| 第 | 样本类别数 | ||
| 第 | 样本 | ||
| 第 | 隐向量维度 | ||
| 子空间矩阵 |
表1 符号和定义
Tab.1 Symbols and definitions
| 符号 | 定义 | 符号 | 定义 |
|---|---|---|---|
| 缺失特征样本数据集 | 特征矩阵 | ||
| 第 | 特征 | ||
| 第 | 样本类别数 | ||
| 第 | 样本 | ||
| 第 | 隐向量维度 | ||
| 子空间矩阵 |
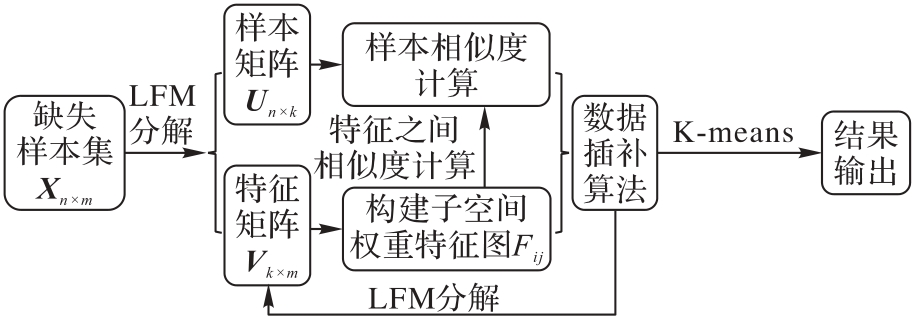
图1 本文算法的框架
Fig.1 Framework of proposed algorithm
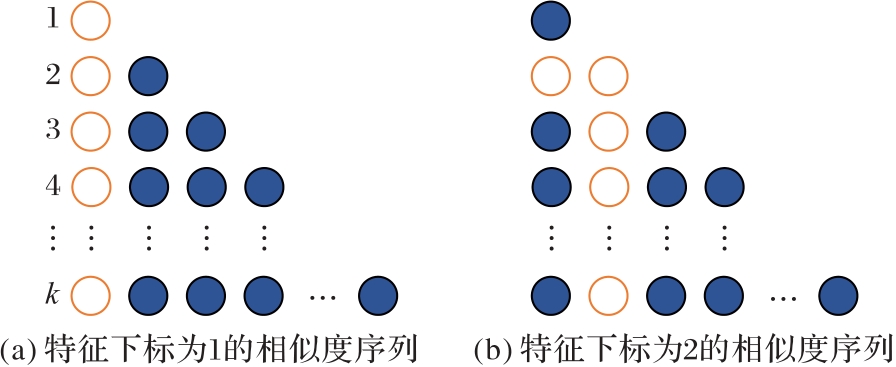
图2 样本注意力权重矩阵的结构
Fig.2 Structure of sample attention weight matrix
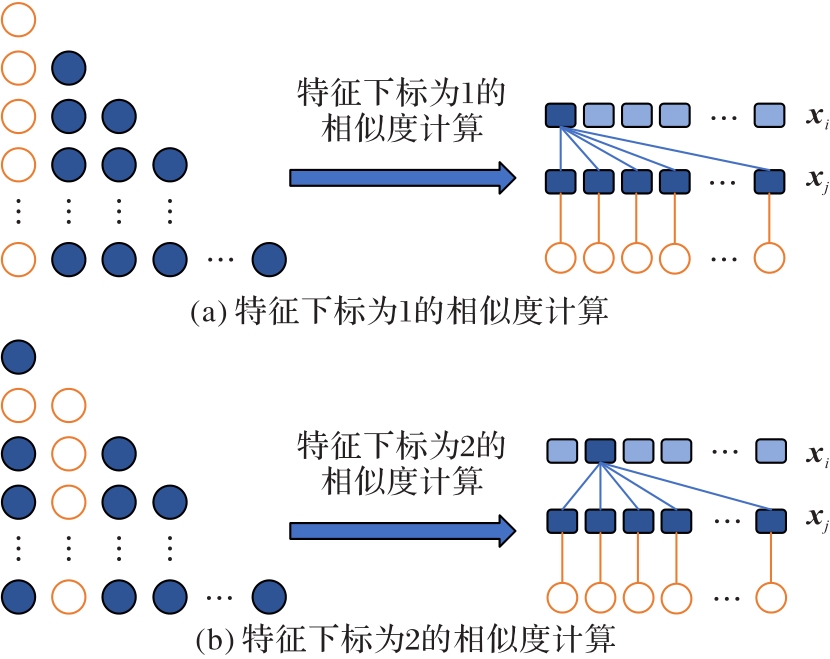
图3 样本相似度计算方式
Fig.3 Calculation method of sample similarity
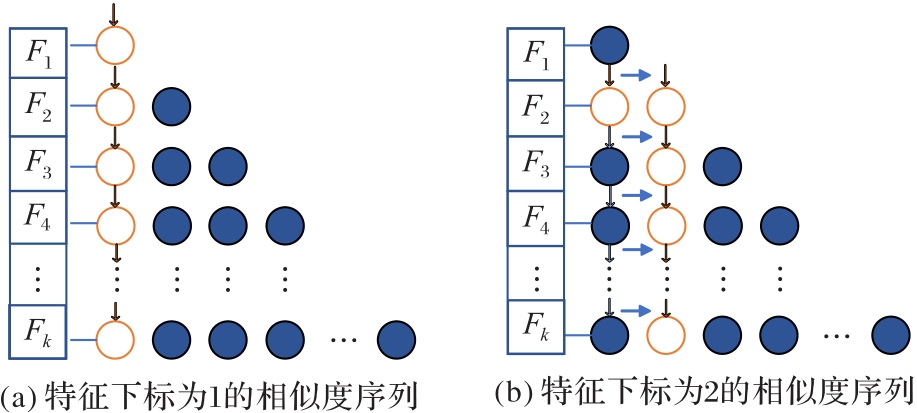
图4 多指针相似度权重图
Fig.4 Multi-pointer similarity weight graph
| 数据集 | 样本数 | 特征维度 | 类别数 |
|---|---|---|---|
| Hand-digits | 1 797 | 64 | 10 |
| COIL20 | 1 440 | 1 024 | 20 |
| Breast-cancer | 569 | 30 | 2 |
| Wine | 178 | 13 | 3 |
表2 数据集信息
Tab. 2 Information of datasets
| 数据集 | 样本数 | 特征维度 | 类别数 |
|---|---|---|---|
| Hand-digits | 1 797 | 64 | 10 |
| COIL20 | 1 440 | 1 024 | 20 |
| Breast-cancer | 569 | 30 | 2 |
| Wine | 178 | 13 | 3 |
| 数据集 | 缺失 比例/ % | 原始空间 | 子空间 | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0+K-means | Min+K-means | Max+K-mean | Mean+K-means | KISC算法 | 本文算法 | KISC算法 | 本文算法 | ||||||||||
| ACC | NMI | ACC | NMI | ACC | NMI | ACC | NMI | ACC | NMI | ACC | NMI | ACC | NMI | ACC | NMI | ||
| Hand-digits | 10 | 63.44 | 59.36 | 71.51 | 67.45 | 71.62 | 68.81 | 71.40 | 68.10 | 67.82 | 60.94 | 74.21 | 64.54 | 73.46 | 67.49 | 75.79 | 70.26 |
| 20 | 64.83 | 53.29 | 61.27 | 49.58 | 63.22 | 53.11 | 64.27 | 55.36 | 61.58 | 50.41 | 69.09 | 56.08 | 71.90 | 59.94 | 72.29 | 61.27 | |
| 30 | 32.50 | 19.82 | 39.23 | 25.29 | 42.07 | 26.74 | 35.73 | 23.66 | 55.60 | 40.55 | 58.65 | 43.05 | 44.07 | 28.05 | 49.25 | 30.27 | |
| 40 | 19.59 | 7.68 | 20.09 | 6.83 | 19.59 | 5.66 | 18.20 | 6.38 | 32.38 | 19.47 | 35.63 | 22.29 | 21.31 | 6.29 | 21.65 | 07.37 | |
| COIL20 | 10 | 62.04 | 76.01 | 61.71 | 74.59 | 60.74 | 74.92 | 61.16 | 74.74 | 63.11 | 77.27 | 70.84 | 78.72 | 70.81 | 78.61 | 71.11 | 79.10 |
| 20 | 61.74 | 75.12 | 62.65 | 74.83 | 61.40 | 74.41 | 60.10 | 73.76 | 60.33 | 73.77 | 68.67 | 78.02 | 69.62 | 79.59 | 70.03 | 79.72 | |
| 30 | 60.24 | 73.54 | 58.85 | 72.14 | 59.58 | 72.94 | 60.50 | 73.21 | 62.81 | 74.49 | 68.31 | 76.62 | 70.54 | 78.28 | 71.04 | 76.78 | |
| 40 | 52.22 | 68.16 | 54.31 | 69.10 | 53.35 | 69.05 | 55.77 | 69.57 | 57.40 | 71.64 | 63.99 | 74.38 | 62.71 | 71.83 | 64.86 | 71.31 | |
| Breast-cancer | 10 | 83.02 | 41.42 | 82.99 | 41.34 | 82.99 | 41.28 | 82.97 | 41.30 | 83.17 | 41.02 | 83.69 | 42.70 | 85.15 | 45.78 | 85.44 | 46.48 |
| 20 | 81.16 | 37.38 | 81.09 | 37.24 | 81.07 | 37.01 | 81.14 | 37.34 | 80.76 | 36.69 | 81.16 | 37.50 | 82.41 | 42.15 | 84.46 | 44.19 | |
| 30 | 79.88 | 34.26 | 79.86 | 34.23 | 79.86 | 34.32 | 79.96 | 34.44 | 79.72 | 33.53 | 80.22 | 35.66 | 80.35 | 39.12 | 84.45 | 44.10 | |
| 40 | 78.70 | 29.74 | 78.65 | 30.02 | 78.63 | 29.82 | 78.65 | 29.92 | 78.73 | 30.45 | 79.28 | 31.21 | 80.30 | 34.17 | 82.39 | 35.95 | |
| Wine | 10 | 41.42 | 36.84 | 41.34 | 36.97 | 41.34 | 37.35 | 41.30 | 35.71 | 41.02 | 35.79 | 42.70 | 37.45 | 45.78 | 38.40 | 46.48 | 38.78 |
| 20 | 37.38 | 29.54 | 37.24 | 29.70 | 37.34 | 28.61 | 37.34 | 29.33 | 36.69 | 30.60 | 37.50 | 31.42 | 42.15 | 32.56 | 44.19 | 34.65 | |
| 30 | 34.26 | 26.84 | 34.23 | 26.24 | 34.32 | 26.19 | 34.44 | 27.06 | 33.53 | 27.79 | 35.66 | 26.25 | 39.12 | 26.60 | 44.10 | 27.88 | |
| 40 | 29.74 | 23.68 | 30.02 | 22.69 | 29.82 | 22.57 | 29.92 | 23.01 | 30.45 | 20.46 | 31.21 | 22.11 | 34.17 | 22.45 | 35.95 | 22.29 | |
表3 不同算法聚类结果的ACC和NMI比较 (%)
Tab.3 Comparison of ACC and NMI in clustering results between different algorithms
| 数据集 | 缺失 比例/ % | 原始空间 | 子空间 | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0+K-means | Min+K-means | Max+K-mean | Mean+K-means | KISC算法 | 本文算法 | KISC算法 | 本文算法 | ||||||||||
| ACC | NMI | ACC | NMI | ACC | NMI | ACC | NMI | ACC | NMI | ACC | NMI | ACC | NMI | ACC | NMI | ||
| Hand-digits | 10 | 63.44 | 59.36 | 71.51 | 67.45 | 71.62 | 68.81 | 71.40 | 68.10 | 67.82 | 60.94 | 74.21 | 64.54 | 73.46 | 67.49 | 75.79 | 70.26 |
| 20 | 64.83 | 53.29 | 61.27 | 49.58 | 63.22 | 53.11 | 64.27 | 55.36 | 61.58 | 50.41 | 69.09 | 56.08 | 71.90 | 59.94 | 72.29 | 61.27 | |
| 30 | 32.50 | 19.82 | 39.23 | 25.29 | 42.07 | 26.74 | 35.73 | 23.66 | 55.60 | 40.55 | 58.65 | 43.05 | 44.07 | 28.05 | 49.25 | 30.27 | |
| 40 | 19.59 | 7.68 | 20.09 | 6.83 | 19.59 | 5.66 | 18.20 | 6.38 | 32.38 | 19.47 | 35.63 | 22.29 | 21.31 | 6.29 | 21.65 | 07.37 | |
| COIL20 | 10 | 62.04 | 76.01 | 61.71 | 74.59 | 60.74 | 74.92 | 61.16 | 74.74 | 63.11 | 77.27 | 70.84 | 78.72 | 70.81 | 78.61 | 71.11 | 79.10 |
| 20 | 61.74 | 75.12 | 62.65 | 74.83 | 61.40 | 74.41 | 60.10 | 73.76 | 60.33 | 73.77 | 68.67 | 78.02 | 69.62 | 79.59 | 70.03 | 79.72 | |
| 30 | 60.24 | 73.54 | 58.85 | 72.14 | 59.58 | 72.94 | 60.50 | 73.21 | 62.81 | 74.49 | 68.31 | 76.62 | 70.54 | 78.28 | 71.04 | 76.78 | |
| 40 | 52.22 | 68.16 | 54.31 | 69.10 | 53.35 | 69.05 | 55.77 | 69.57 | 57.40 | 71.64 | 63.99 | 74.38 | 62.71 | 71.83 | 64.86 | 71.31 | |
| Breast-cancer | 10 | 83.02 | 41.42 | 82.99 | 41.34 | 82.99 | 41.28 | 82.97 | 41.30 | 83.17 | 41.02 | 83.69 | 42.70 | 85.15 | 45.78 | 85.44 | 46.48 |
| 20 | 81.16 | 37.38 | 81.09 | 37.24 | 81.07 | 37.01 | 81.14 | 37.34 | 80.76 | 36.69 | 81.16 | 37.50 | 82.41 | 42.15 | 84.46 | 44.19 | |
| 30 | 79.88 | 34.26 | 79.86 | 34.23 | 79.86 | 34.32 | 79.96 | 34.44 | 79.72 | 33.53 | 80.22 | 35.66 | 80.35 | 39.12 | 84.45 | 44.10 | |
| 40 | 78.70 | 29.74 | 78.65 | 30.02 | 78.63 | 29.82 | 78.65 | 29.92 | 78.73 | 30.45 | 79.28 | 31.21 | 80.30 | 34.17 | 82.39 | 35.95 | |
| Wine | 10 | 41.42 | 36.84 | 41.34 | 36.97 | 41.34 | 37.35 | 41.30 | 35.71 | 41.02 | 35.79 | 42.70 | 37.45 | 45.78 | 38.40 | 46.48 | 38.78 |
| 20 | 37.38 | 29.54 | 37.24 | 29.70 | 37.34 | 28.61 | 37.34 | 29.33 | 36.69 | 30.60 | 37.50 | 31.42 | 42.15 | 32.56 | 44.19 | 34.65 | |
| 30 | 34.26 | 26.84 | 34.23 | 26.24 | 34.32 | 26.19 | 34.44 | 27.06 | 33.53 | 27.79 | 35.66 | 26.25 | 39.12 | 26.60 | 44.10 | 27.88 | |
| 40 | 29.74 | 23.68 | 30.02 | 22.69 | 29.82 | 22.57 | 29.92 | 23.01 | 30.45 | 20.46 | 31.21 | 22.11 | 34.17 | 22.45 | 35.95 | 22.29 | |
| 数据集 | 缺失率/% | 时间/s | |
|---|---|---|---|
| 结构未优化 | 结构优化 | ||
| Wine | 10 | 0.363 | 0.230 |
| 20 | 0.491 | 0.296 | |
| 30 | 0.499 | 0.302 | |
| 40 | 0.495 | 0.310 | |
| Breast-cancer | 10 | 11.150 | 3.140 |
| 20 | 12.370 | 3.190 | |
| 30 | 12.440 | 3.230 | |
| 40 | 12.340 | 3.200 | |
| Hand-digits | 10~20 | 3 272.4 | 617.1 |
| 30~40 | 3 716.6 | 670.6 | |
| COIL20 | 10~20 | 8 961.3 | 1 816.4 |
| 30~40 | 9 200.8 | 1 900.2 | |
表4 特征相似度权重图优化前后时间对比
Tab. 4 Time comparison of feature similarity weight graph before and after optimization
| 数据集 | 缺失率/% | 时间/s | |
|---|---|---|---|
| 结构未优化 | 结构优化 | ||
| Wine | 10 | 0.363 | 0.230 |
| 20 | 0.491 | 0.296 | |
| 30 | 0.499 | 0.302 | |
| 40 | 0.495 | 0.310 | |
| Breast-cancer | 10 | 11.150 | 3.140 |
| 20 | 12.370 | 3.190 | |
| 30 | 12.440 | 3.230 | |
| 40 | 12.340 | 3.200 | |
| Hand-digits | 10~20 | 3 272.4 | 617.1 |
| 30~40 | 3 716.6 | 670.6 | |
| COIL20 | 10~20 | 8 961.3 | 1 816.4 |
| 30~40 | 9 200.8 | 1 900.2 | |
| 1 | AHALYA G, PANDEY H M. Data clustering approaches survey and analysis [C]// Proceedings of the 2015 International Conference on Futuristic Trends on Computational Analysis and Knowledge Management. Piscataway: IEEE,2015: 532-537. 10.1109/ablaze.2015.7154919 |
| 2 | XU H, YAO S, LI Q, et al. An improved K-means clustering algorithm[C]// Proceedings of the 2020 IEEE 5th International Symposium on Smart and Wireless Systems within the Conferences on Intelligent Data Acquisition and Advanced Computing Systems. Piscataway: IEEE, 2020: 1-5. 10.1109/idaacs-sws50031.2020.9297060 |
| 3 | 王一妹,刘辉,宋鹏,等.基于高斯混合模型聚类的风电场短期功率预测方法[J].电力系统自动化,2021,45(7):37-43. 10.7500/AEPS20200616005 |
| WANG Y M, LIU H, SONG P, et al. Short-term power forecasting method of wind farm based on Gaussian mixture model clustering [J]. Power System Automation, 2021,45(7): 37-43. 10.7500/AEPS20200616005 | |
| 4 | JEBARI S, SMITI A, LOUATI A.AF-DBSCAN: an unsupervised automatic fuzzy clustering method based on DBSCAN approach[C]// Proceedings of the 2019 IEEE International Work Conference on Bioinspired Intelligence. Piscataway: IEEE,2019:1-6. 10.1109/iwobi47054.2019.9114411 |
| 5 | RONG Y, LIU Y.Staged text clustering algorithm based on K-means and hierarchical agglomeration clustering[C]// Proceedings of the 2020 IEEE International Conference on Artificial Intelligence and Computer Applications. Piscataway: IEEE,2020:124-127. 10.1109/icaica50127.2020.9182394 |
| 6 | 任丽娜,秦永彬,黄瑞章,等.基于多层子空间语义融合的深度文本聚类[J].计算机应用研究, 2023,40(1):70-74,79. |
| REN L N, QIN Y B, HUANG R Z,et al. Deep document clustering model via multi-layer subspace semantic fusion [J]. Application Research of Computers, 2023,40(1):70-74,79. | |
| 7 | TAN L, GU S, WU C, et al. K-means clustering method based on node similarity in traditional Chinese medicine efficacy[C]// Proceedings of the 2020 39th Chinese Control Conference. Piscataway: IEEE,2020:742-747. 10.23919/ccc50068.2020.9189618 |
| 8 | YI Y. Design of intelligent recommendation APP for eco-tourism routes based on popular data clustering of points of interest[C]// Proceedings of the 2021 2nd International Conference on Smart Electronics and Communication. Piscataway: IEEE,2021: 1270-1273. 10.1109/icosec51865.2021.9591778 |
| 9 | SHRUTHI S, JOSE A M, ANUROOP P R. Improvisation of cluster efficiency using min-cut algorithm in social networks[C]// Proceedings of the 2017 International Conference on Communication and Signal Processing. Piscataway: IEEE,2017:1641-1644. 10.1109/iccsp.2017.8286668 |
| 10 | LIU Q, HAUSWIRTH M. A provenance meta learning framework for missing data handling methods selection[C]// Proceedings of the 2020 11th IEEE Annual Ubiquitous Computing, Electronics & Mobile Communication Conference. Piscataway: IEEE,2020: 349-358. 10.1109/uemcon51285.2020.9298089 |
| 11 | 徐宇明,陈诚,熊赟,等.APT-KNN:一种面向分类问题的高效缺失值填充算法[J].计算机应用与软件,2011,28(4):135-139. 10.3969/j.issn.1000-386X.2011.04.040 |
| XU Y M, CHEN C, XIONG Y,et al. APT-KNN: an efficient missing value imputation method oriented toward classification issue [J]. Computer Applications and Software, 2011, 28 (4): 135-139. 10.3969/j.issn.1000-386X.2011.04.040 | |
| 12 | 徐鸿艳,孙云山,秦琦琳,等.缺失数据插补方法性能比较分析[J].软件工程,2021,24(11):11-14. |
| XU H Y, SUN Y S, QIN Q L, et al. Comparative analysis of the performance of interpolation methods for of missing data[J]. Software Engineering, 2021,24 (11): 11-14. | |
| 13 | ALBAYRAK M, TURHAN K, KURT B. A missing data imputation approach using clustering and maximum likelihood estimation[C]// Proceedings of the 2017 Medical Technologies National Congress. Piscataway:IEEE, 2017:1-4. 10.1109/tiptekno.2017.8238064 |
| 14 | PATTANODOM, IAM-ON N, BOONGOEN T. Clustering data with the presence of missing values by ensemble approach[C]// Proceedings of the 2016 Second Asian Conference on Defence Technology. Piscataway: IEEE, 2016: 151-156. 10.1109/acdt.2016.7437660 |
| 15 | HUAYAN S, YELI L, RUNFEI Z, et al. Accelerating EM missing data filling algorithm based on the K-means[C]// Proceedings of the 2018 4th Annual International Conference on Network and Information Systems for Computers. Piscataway: IEEE, 2018:401-406. 10.1109/icnisc.2018.00088 |
| 16 | 乔永坚,刘晓琳,白亮.面向高维特征缺失数据的K最近邻插补子空间聚类算法[J].计算机应用,2022,42(11):3322-3329. 10.11772/j.issn.1001-9081.2021111964 |
| QIAO Y J, LIU X L, BAI L. K-nearest neighbor interpolation subspace clustering algorithm for high-dimensional data with feature missing [J]. Journal of Computer Application, 2022,42(11): 3322-3329. 10.11772/j.issn.1001-9081.2021111964 | |
| 17 | 王一棠,庞勇,张立勇,等.面向盾构机不完整数据的模糊聚类与非线性回归填补[J].机械工程学报, 2023, 59(12): 28-37. |
| WANG Y T, PANG Y, ZHANG L Y,et al. Fuzzy clustering and nonlinear regression filling for incomplete data of shield machine [J]. Journal of Mechanical Engineering, 2023, 59(12): 28-37. | |
| 18 | 陈晔,刘志强.基于LFM矩阵分解的推荐算法优化研究[J].计算机工程与应用,2019,55(2):116-120. |
| CHEN Y, LIU Z Q. Research on improved recommendation algorithm based on LFM matrix factorization [J]. Computer Engineering and Applications, 2019,55(2): 116-120. | |
| 19 | XIONG Y, LI H. Collaborative filtering algorithm in pictures recommendation based on SVD[C]// Proceedings of the 2018 International Conference on Robots & Intelligent System. Piscataway: IEEE, 2018:262-265. 10.1109/icris.2018.00074 |
| 20 | 杨镆. 基于偏置LFM和LSH的混合电影推荐算法研究[D].武汉:华中师范大学,2021:13-15. |
| YANG M. Research on hybrid movie recommendation algorithm based on bias LFM and LSH[D]. Wuhan: Central China Normal University, 2021: 13-15. | |
| 21 | GUO S, LI C. Hybrid recommendation algorithm based on user behavior[C]// Proceedings of the 2020 IEEE 9th Joint International Information Technology and Artificial Intelligence Conference. Piscataway: IEEE, 2020:2242-2246. 10.1109/itaic49862.2020.9339083 |
| 22 | 龙建武,王强.反向近邻构造连通图的聚类算法[J/OL].计算机科学与探索:1-15 [2023-02-07]. . 10.3778/j.issn.1673-9418.2207017 |
| LONG J W, WANG Q. Clustering algorithm for constructing connected graphs by reverse nearest neighbors [J/OL]. Journal of Frontiers of Computer Science and Technology: 1-15 [2023-02-07]. . 10.3778/j.issn.1673-9418.2207017 |
| [1] | 赵志强, 马培红, 黑新宏. 基于双重注意力机制的人群计数方法[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2886-2892. |
| [2] | 秦璟, 秦志光, 李发礼, 彭悦恒. 基于概率稀疏自注意力神经网络的重性抑郁疾患诊断[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2970-2974. |
| [3] | 李力铤, 华蓓, 贺若舟, 徐况. 基于解耦注意力机制的多变量时序预测模型[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2732-2738. |
| [4] | 薛凯鹏, 徐涛, 廖春节. 融合自监督和多层交叉注意力的多模态情感分析网络[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2387-2392. |
| [5] | 汪雨晴, 朱广丽, 段文杰, 李书羽, 周若彤. 基于交互注意力机制的心理咨询文本情感分类模型[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2393-2399. |
| [6] | 高鹏淇, 黄鹤鸣, 樊永红. 融合坐标与多头注意力机制的交互语音情感识别[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2400-2406. |
| [7] | 李钟华, 白云起, 王雪津, 黄雷雷, 林初俊, 廖诗宇. 基于图像增强的低照度人脸检测[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2588-2594. |
| [8] | 莫尚斌, 王文君, 董凌, 高盛祥, 余正涛. 基于多路信息聚合协同解码的单通道语音增强[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2611-2617. |
| [9] | 熊武, 曹从军, 宋雪芳, 邵云龙, 王旭升. 基于多尺度混合域注意力机制的笔迹鉴别方法[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2225-2232. |
| [10] | 李欢欢, 黄添强, 丁雪梅, 罗海峰, 黄丽清. 基于多尺度时空图卷积网络的交通出行需求预测[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2065-2072. |
| [11] | 毛典辉, 李学博, 刘峻岭, 张登辉, 颜文婧. 基于并行异构图和序列注意力机制的中文实体关系抽取模型[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2018-2025. |
| [12] | 王清, 赵杰煜, 叶绪伦, 王弄潇. 统一框架的增强深度子空间聚类方法[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 1995-2003. |
| [13] | 刘丽, 侯海金, 王安红, 张涛. 基于多尺度注意力的生成式信息隐藏算法[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2102-2109. |
| [14] | 徐松, 张文博, 王一帆. 基于时空信息的轻量视频显著性目标检测网络[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2192-2199. |
| [15] | 李大海, 王忠华, 王振东. 结合空间域和频域信息的双分支低光照图像增强网络[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2175-2182. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||