


《计算机应用》唯一官方网站 ›› 2024, Vol. 44 ›› Issue (1): 86-93.DOI: 10.11772/j.issn.1001-9081.2023060753
收稿日期:2023-06-15
修回日期:2023-08-14
接受日期:2023-08-21
发布日期:2023-09-25
出版日期:2024-01-10
通讯作者:
杨宇恒
作者简介:李牧(1972—),男,陕西西安人,高级工程师,硕士,主要研究方向:生命体征检测、深度学习;基金资助:
Mu LI, Yuheng YANG( ), Xizheng KE
), Xizheng KE
Received:2023-06-15
Revised:2023-08-14
Accepted:2023-08-21
Online:2023-09-25
Published:2024-01-10
Contact:
Yuheng YANG
About author:LI Mu, born in 1972, M. S., senior engineer. His research interests include vital sign detection, deep learning.Supported by:摘要:
为从多模态情感分析中有效挖掘单模态表征信息,并实现多模态信息充分融合,提出一种基于混合特征与跨模态预测融合的情感识别模型(H-MGFCT)。首先,利用Mel频率倒谱系数(MFCC)和Gammatone频率倒谱系数(GFCC)及其一阶动态特征融合得到混合特征参数提取算法(H-MGFCC),解决了语音情感特征丢失的问题;其次,利用基于注意力权重的跨模态预测模型,筛选出与语音特征相关性更高的文本特征;随后,加入对比学习的跨模态注意力机制模型对相关性高的文本特征和语音模态情感特征进行跨模态信息融合;最后,将含有文本-语音的跨模态信息特征与筛选出的相关性低的文本特征相融合,以起到信息补充的作用。实验结果表明,该模型在公开IEMOCAP (Interactive EMotional dyadic MOtion CAPture)、CMU-MOSI (CMU-Multimodal Opinion Emotion Intensity)、CMU-MOSEI (CMU-Multimodal Opinion Sentiment Emotion Intensity)数据集上与加权决策层融合的语音文本情感识别(DLFT)模型相比,准确率分别提高了2.83、2.64和3.05个百分点,验证了该模型情感识别的有效性。
中图分类号:
李牧, 杨宇恒, 柯熙政. 基于混合特征提取与跨模态特征预测融合的情感识别模型[J]. 计算机应用, 2024, 44(1): 86-93.
Mu LI, Yuheng YANG, Xizheng KE. Emotion recognition model based on hybrid-mel gama frequency cross-attention transformer modal[J]. Journal of Computer Applications, 2024, 44(1): 86-93.

图1 多模态情感识别模型框架
Fig. 1 Framework of multimodal emotion recognition model
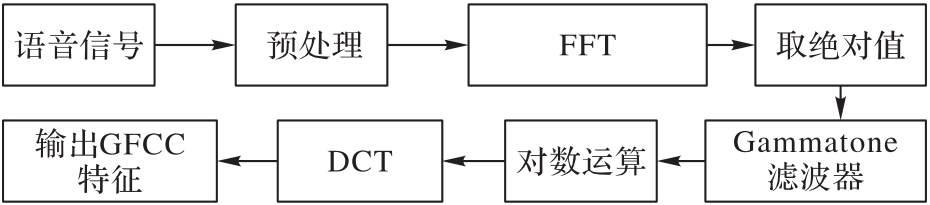
图2 MFCC特征提取过程
Fig. 2 MFCC feature extraction process

图3 基于注意力权重索引的编码器预测模型
Fig. 3 Encoder prediction model based on attention weight index
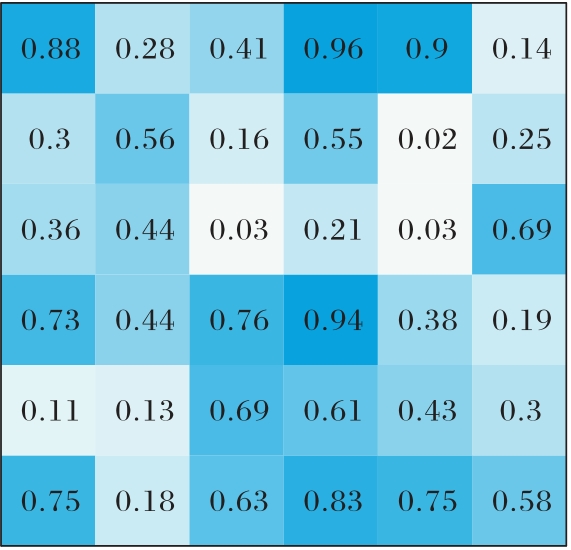
图4 预测模型生成的注意力权重图
Fig. 4 Attention weight map generated by prediction model
| 数据集 | 样本数 | |||
|---|---|---|---|---|
| 训练集 | 验证集 | 测试集 | 总计 | |
| CMU-MOSI | 1 453 | 232 | 411 | 2 096 |
| CMU-MOSEI | 16 853 | 2 103 | 2 597 | 21 553 |
| IEMOCAP | 6 711 | 634 | 1 746 | 9 091 |
表1 数据集样本规模
Tab. 1 Dataset sample size
| 数据集 | 样本数 | |||
|---|---|---|---|---|
| 训练集 | 验证集 | 测试集 | 总计 | |
| CMU-MOSI | 1 453 | 232 | 411 | 2 096 |
| CMU-MOSEI | 16 853 | 2 103 | 2 597 | 21 553 |
| IEMOCAP | 6 711 | 634 | 1 746 | 9 091 |
| 模型 | IEMOCAP | CMU-MOSI | CMU-MOSEI | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Acc/% | F1/% | MAE | Corr | Acc/% | F1/% | MAE | Corr | Acc/% | F1/% | MAE | Corr | |
| GGRU[ | 71.80 | 62.83 | 0.894 | 0.695 | 73.42 | 61.31 | 0.797 | 0.696 | 72.93 | 64.35 | 0.762 | 0.701 |
| LLA[ | 69.74 | 57.97 | 0.923 | 0.698 | 68.73 | 59.49 | 0.832 | 0.701 | 71.31 | 61.99 | 0.816 | 0.706 |
| LFC[ | 75.49 | 63.62 | 0.793 | 0.745 | 71.29 | 65.34 | 0.743 | 0.743 | 73.84 | 67.68 | 0.663 | 0.747 |
| FLFT[ | 74.27 | 67.45 | 0.787 | 0.748 | 77.83 | 74.33 | 0.693 | 0.752 | 79.33 | 69.73 | 0.593 | 0.753 |
| DLFT[ | 77.18 | 71.26 | 0.768 | 0.755 | 79.32 | 73.89 | 0.687 | 0.757 | 78.37 | 74.33 | 0.588 | 0.759 |
| 本文模型 | 80.01 | 69.73 | 0.759 | 0.763 | 81.96 | 74.33 | 0.676 | 0.768 | 81.42 | 72.46 | 0.594 | 0.765 |
表2 不同模型的情感融合效果对比
Tab. 2 Comparison of emotional fusion effects of different models
| 模型 | IEMOCAP | CMU-MOSI | CMU-MOSEI | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Acc/% | F1/% | MAE | Corr | Acc/% | F1/% | MAE | Corr | Acc/% | F1/% | MAE | Corr | |
| GGRU[ | 71.80 | 62.83 | 0.894 | 0.695 | 73.42 | 61.31 | 0.797 | 0.696 | 72.93 | 64.35 | 0.762 | 0.701 |
| LLA[ | 69.74 | 57.97 | 0.923 | 0.698 | 68.73 | 59.49 | 0.832 | 0.701 | 71.31 | 61.99 | 0.816 | 0.706 |
| LFC[ | 75.49 | 63.62 | 0.793 | 0.745 | 71.29 | 65.34 | 0.743 | 0.743 | 73.84 | 67.68 | 0.663 | 0.747 |
| FLFT[ | 74.27 | 67.45 | 0.787 | 0.748 | 77.83 | 74.33 | 0.693 | 0.752 | 79.33 | 69.73 | 0.593 | 0.753 |
| DLFT[ | 77.18 | 71.26 | 0.768 | 0.755 | 79.32 | 73.89 | 0.687 | 0.757 | 78.37 | 74.33 | 0.588 | 0.759 |
| 本文模型 | 80.01 | 69.73 | 0.759 | 0.763 | 81.96 | 74.33 | 0.676 | 0.768 | 81.42 | 72.46 | 0.594 | 0.765 |

图5 不同模型的混淆矩阵效果对比
Fig. 5 Comparison of confusion matrix effects of different models
| 实验序号 | 模型 | CMU-MOSI | CMU-MOSEI | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Acc/% | F1/% | MAE | Corr | Acc/% | F1/% | MAE | Corr | ||
| 1 | 本文模型 | 81.96 | 74.33 | 0.676 | 0.768 | 81.42 | 72.46 | 0.594 | 0.765 |
| 2 | H-MGFCT/H | 72.39 | 67.16 | 0.796 | 0.652 | 73.42 | 69.67 | 0.827 | 0.674 |
| 3 | H-MGFCT/C | 74.64 | 71.37 | 0.821 | 0.691 | 75.79 | 73.54 | 0.787 | 0.621 |
| 4 | H-MGFCT/S | 75.41 | 72.03 | 0.784 | 0.667 | 76.76 | 71.98 | 0.769 | 0.659 |
| 5 | H-MGFCT/T | 77.41 | 72.56 | 0.794 | 0.711 | 77.28 | 72.73 | 0.754 | 0.761 |
表3 H-MGFCC/CSA-Transformer/对比学习/基于注意力权重索引的编码器预测模型有效性验证
Tab. 3 Effective validation of H-MGFCC/CSA-Transformer/comparative learning/encoder prediction model based on attention weight index
| 实验序号 | 模型 | CMU-MOSI | CMU-MOSEI | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Acc/% | F1/% | MAE | Corr | Acc/% | F1/% | MAE | Corr | ||
| 1 | 本文模型 | 81.96 | 74.33 | 0.676 | 0.768 | 81.42 | 72.46 | 0.594 | 0.765 |
| 2 | H-MGFCT/H | 72.39 | 67.16 | 0.796 | 0.652 | 73.42 | 69.67 | 0.827 | 0.674 |
| 3 | H-MGFCT/C | 74.64 | 71.37 | 0.821 | 0.691 | 75.79 | 73.54 | 0.787 | 0.621 |
| 4 | H-MGFCT/S | 75.41 | 72.03 | 0.784 | 0.667 | 76.76 | 71.98 | 0.769 | 0.659 |
| 5 | H-MGFCT/T | 77.41 | 72.56 | 0.794 | 0.711 | 77.28 | 72.73 | 0.754 | 0.761 |
| 模型 | 参数量/106 | 平均运行时间/s | 模型大小/MB |
|---|---|---|---|
| GGRU[ | 29 | 7.74 | 5.62 |
| LLA[ | 86 | 13.89 | 9.83 |
| LFC[ | 71 | 9.92 | 6.36 |
| FLFT[ | 63 | 7.35 | 5.88 |
| DLFT[ | 55 | 5.24 | 4.84 |
| 本文模型 | 17 | 2.74 | 3.76 |
表4 不同模型的整体性能对比
Tab. 4 Overall performance comparison of different models
| 模型 | 参数量/106 | 平均运行时间/s | 模型大小/MB |
|---|---|---|---|
| GGRU[ | 29 | 7.74 | 5.62 |
| LLA[ | 86 | 13.89 | 9.83 |
| LFC[ | 71 | 9.92 | 6.36 |
| FLFT[ | 63 | 7.35 | 5.88 |
| DLFT[ | 55 | 5.24 | 4.84 |
| 本文模型 | 17 | 2.74 | 3.76 |
| 1 | KE X, CAO B, BAI J, et al. Speech emotion recognition based on PCA and CHMM [C]// Proceedings of the 2019 IEEE 8th Joint International Information Technology and Artificial Intelligence Conference. Piscataway: IEEE, 2019: 667-671. 10.1109/itaic.2019.8785867 |
| 2 | SHAH M, MIAO L, CHAKRABARTI C, et al. A speech emotion recognition framework based on latent Dirichlet allocation [C]// Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2013: 2553-2557. 10.1109/icassp.2013.6638116 |
| 3 | DUTTA K, SARMA K K. Multiple feature extraction for RNN-based Assamese speech recognition for speech to text conversion application [C]// Proceedings of the 2012 International Conference on Communications, Devices and Intelligent Systems. Piscataway: IEEE, 2012: 600-603. 10.1109/codis.2012.6422274 |
| 4 | 郭卉,姜囡,任杰.基于MFCC和GFCC混合特征的语音情感识别研究[J].光电技术应用, 2019, 34(6): 34-39. 10.3969/j.issn.1673-1255.2019.06.008 |
| GUO H, JIANG N, REN J. Research on speech emotion recognition based on mixed features of MFCC and GFCC [J]. Electro-Optic Technology Application, 2019, 34(6): 34-39. 10.3969/j.issn.1673-1255.2019.06.008 | |
| 5 | CHEN M, ZHAO X. A multi-scale fusion framework for bimodal speech emotion recognition [C]// Proceedings of the 2020 Cognitive Intelligence for Speech Processing. Baixas, FR: International Speech Communication Association, 2020: 374-378. 10.21437/interspeech.2020-3156 |
| 6 | TZIRAKIS P, TRIGEORGIS G, NICOLAOU M A, et al. End-to-end multimodal emotion recognition using deep neural networks [J]. IEEE Journal of Selected Topics in Signal Processing, 2017, 11(8): 1301-1309. 10.1109/jstsp.2017.2764438 |
| 7 | SUN L, LIU B, TAO J, et al. Multimodal cross- and self-attention network for speech emotion recognition [C]// Proceedings of the 2021 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2021: 4275-4279. 10.1109/icassp39728.2021.9414654 |
| 8 | YOON S, BYUN S, DEY S, et al. Speech emotion recognition using multi-hop attention mechanism [C]// Proceedings of the 2019 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2019: 2822-2826. 10.1109/icassp.2019.8683483 |
| 9 | CHOI W Y, SONG K Y, LEE C W. Convolutional attention networks for multimodal emotion recognition from speech and text data [C]// Proceedings of the 2018 Grand Challenge and Workshop on Human Multimodal Language. Stroudsburg, PA: Association for Computational Linguistics, 2018: 28-34. 10.18653/v1/w18-3304 |
| 10 | 陈鹏展,张欣徐,徐芳萍.基于语音信号与文本信息的双模态情感识别[J].华东交通大学学报, 2017, 34(2): 100-104. |
| CHEN P Z, ZHANG X X, XU F P. Multimodal emotion recognition based on speech signals and text information [J]. Journal of East China Jiaotong University, 2017, 34(2): 100-104. | |
| 11 | ZHONG Y, HU Y, HUANG H, et al. A lightweight model based on separable convolution for speech emotion recognition [C]// Proceedings of the 2020 Cognitive Intelligence for Speech Processing. Baixas, FR: International Speech Communication Association, 2020: 3331-3335. 10.21437/interspeech.2020-2408 |
| 12 | 顾煜,金赟,马勇,等.基于声学和文本特征的多模态情感识别[J].数据采集与处理, 2022, 37(6): 1353-1362. |
| GU Y, JIN Y, MA Y, et al. Multimodal emotion recognition based on acoustic and lexical features [J]. Journal of Data Acquisition & Processing, 2022, 37(6): 1353-1362. | |
| 13 | 高玮军,赵华洋,李磊,等.基于ALBERT-HACNN-TUP模型的文本情感分析[J].计算机仿真, 2023, 40(5): 491-496. 10.3969/j.issn.1006-9348.2023.05.089 |
| GAO W J, ZHAO H Y, LI L, et al. Text sentiment analysis based on the ALBERT-HACNN-TUP model [J]. Computer Simulation, 2023, 40(5): 491-496. 10.3969/j.issn.1006-9348.2023.05.089 | |
| 14 | 王跃跃.基于Albert和句法树的方面级情感分析[J].智能计算机与应用, 2023, 13(4): 52-59. 10.3969/j.issn.2095-2163.2023.04.010 |
| WANG Y Y. Aspect-level sentiment analysis based on Albert and syntactic tree [J]. Intelligent Computer and Applications, 2023, 13(4): 52-59. 10.3969/j.issn.2095-2163.2023.04.010 | |
| 15 | 阮国恒,钟业荣,江嘉铭.基于MFCC系数的语音交互系统设计[J].自动化与仪器仪表, 2022(6): 167-171. |
| RUAN G H, ZHONG Y R, JIANG J M. Design of speech interaction system based on MFCC coefficient [J]. Automation & Instrumentation, 2022(6): 167-171. | |
| 16 | 蒙倩霞,余江,常俊,等.基于MFCC特征的Wi-Fi信道状态信息人体行为识别方法[J].计算机应用与软件, 2022, 39(12): 125-131. 10.3969/j.issn.1000-386x.2022.12.019 |
| MENG Q X, YU J, CHANG J, et al. Human behavior recognition method by Wi-Fi channel state information based on MFCC characteristics [J]. Computer Applications and Software, 2022, 39(12): 125-131. 10.3969/j.issn.1000-386x.2022.12.019 | |
| 17 | WU Y, LIN Z, ZHAO Y, et al. A text-centered shared-private framework via cross-modal prediction for multimodal sentiment analysis [C]// Proceedings of the 2021 Findings of the Association for Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2021: 4730-4738. 10.18653/v1/2021.findings-acl.417 |
| 18 | 李晋荣,吕国英,李茹,等.结合Hybrid Attention机制和BiLSTM-CRF的汉语否定语义表示及标注[J].计算机工程与应用, 2023, 59(9): 167-175. 10.3778/j.issn.1002-8331.2201-0088 |
| LI J R, LYU G Y, LI R, et al. Chinese negative semantic representation and annotation combined with hybrid attention mechanism and BiLSTM-CRF [J]. Computer Engineering and Applications, 2023, 59(9): 167-175. 10.3778/j.issn.1002-8331.2201-0088 | |
| 19 | YANG M, LI Y, HUANG Z, et al. Partially view-aligned representation learning with noise robust contrastive loss [C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 1134-1143. 10.1109/cvpr46437.2021.00119 |
| 20 | CHEN T, KORNBLITH S, NOROUZI M, et al.A simple framework for contrastive learning of visual representations [C]// Proceedings of the 37th International Conference on Machine Learning. New York: JMLR.org, 2020: 1597-1607. |
| 21 | SCHULLER B W, BATLINER A, BERGLER C, et al. The INTERSPEECH 2020 computational paralinguistics challenge: elderly emotion, breathing and masks [C]// Proceedings of the 2020 Cognitive Intelligence for Speech Processing. Baixas, FR: International Speech Communication Association, 2020: 2042-2046. 10.21437/interspeech.2020-32 |
| 22 | 李文雪,甘臣权.基于注意力机制的分层次交互融合多模态情感分析[J].重庆邮电大学学报(自然科学版), 2023, 35(1): 176-184. |
| LI W X, GAN C Q. Multimodal emotional analysis of hierarchical interactive fusion based on attention mechanism [J]. Journal of Chongqing University of Posts and Telecommunications (Natural Science Edition), 2023, 35(1): 176-184. | |
| 23 | 赖雪梅,唐宏,陈虹羽,等.基于注意力机制的特征融合-双向门控循环单元多模态情感分析[J].计算机应用, 2021, 41(5): 1268-1274. 10.11772/j.issn.1001-9081.2020071092 |
| LAI X M, TANG H, CHEN H Y, et al. Multimodal sentiment analysis based on feature fusion of attention mechanism-bidirectional gated recurrent unit [J]. Journal of Computer Applications, 2021, 41(5): 1268-1274. 10.11772/j.issn.1001-9081.2020071092 | |
| 24 | 龙英潮,丁美荣,林桂锦,等.基于视听觉感知系统的多模态情感识别[J].计算机系统应用, 2021, 30(12): 218-225. |
| LONG Y C, DING M R, LIN G J, et al. Emotion recognition based on visual and audiovisual perception system [J]. Computer Systems & Applications, 2021, 30(12): 218-225. | |
| 25 | YOON S, BYUN S, JUNG K. Multimodal speech emotion recognition using audio and text [C]// Proceedings of the 2018 IEEE Spoken Language Technology Workshop. Piscataway: IEEE, 2018: 112-118. 10.1109/slt.2018.8639583 |
| 26 | TRIPATHI S, TRIPATHI S, BEIGI H. Multi-modal emotion recognition on IEMOCAP dataset using deep learning [EB/OL]. (2018-04-16) [2023-01-05]. . |
| 27 | ATMAJA B T, SHIRAI K, AKAGI M. Speech emotion recognition using speech feature and word embedding [C]// Proceedings of the 2019 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference. Piscataway: IEEE, 2019: 519-523. 10.1109/apsipaasc47483.2019.9023098 |
| 28 | ZHANG X, WANG M-J, GUO X-D. Multi-modal emotion recognition based on deep learning in speech, video and text [C]// Proceedings of the 2020 IEEE 5th International Conference on Signal and Image Processing. Piscataway: IEEE, 2020: 328-333. 10.1109/icsip49896.2020.9339464 |
| [1] | 罗俊豪, 朱焱. 用于未对齐多模态语言序列情感分析的多交互感知网络[J]. 《计算机应用》唯一官方网站, 2024, 44(1): 79-85. |
| [2] | 王朱佳, 余宙, 俞俊, 范建平. 基于多尺度时空Transformer的视频动态场景图生成模型[J]. 《计算机应用》唯一官方网站, 2024, 44(1): 47-57. |
| [3] | 朱志平, 杨燕, 王杰. 基于场景图感知的跨模态图像描述模型[J]. 《计算机应用》唯一官方网站, 2024, 44(1): 58-64. |
| [4] | 张雨宁, 阿布都克力木·阿布力孜, 梅悌胜, 徐春, 麦尔达娜·买买提热依木, 哈里旦木·阿布都克里木, 侯钰涛. 基于自监督特征提取的骨骼X线影像异常检测方法[J]. 《计算机应用》唯一官方网站, 2024, 44(1): 175-181. |
| [5] | 陈丽安, 过弋. 融合个体偏差信息的文本情感分析模型[J]. 《计算机应用》唯一官方网站, 2024, 44(1): 145-151. |
| [6] | 陈佳, 张鸿. 基于特征增强和语义相关性匹配的图像文本检索方法[J]. 《计算机应用》唯一官方网站, 2024, 44(1): 16-23. |
| [7] | 史含笑, 王雷春. 结合LSTM和自注意力机制的图卷积网络短期电力负荷预测[J]. 《计算机应用》唯一官方网站, 2024, 44(1): 311-317. |
| [8] | 王红斌, 房晓, 江虹. 融入三维语义特征的常识推理问答方法[J]. 《计算机应用》唯一官方网站, 2024, 44(1): 138-144. |
| [9] | 王春雷, 王肖, 刘凯. 多模态知识图谱表示学习综述[J]. 《计算机应用》唯一官方网站, 2024, 44(1): 1-15. |
| [10] | 赵强, 王中卿, 王红玲. 融合多模态信息的产品摘要抽取模型[J]. 《计算机应用》唯一官方网站, 2024, 44(1): 73-78. |
| [11] | 杨昊, 张轶. 基于上下文信息和多尺度融合重要性感知的特征金字塔网络算法[J]. 《计算机应用》唯一官方网站, 2023, 43(9): 2727-2734. |
| [12] | 袁国龙, 张玉金, 刘洋. 基于残差反馈和自注意力的图像篡改取证网络[J]. 《计算机应用》唯一官方网站, 2023, 43(9): 2925-2931. |
| [13] | 王宏, 钱清, 王欢, 龙永. 融合大核注意力卷积的轻量化图像篡改定位算法[J]. 《计算机应用》唯一官方网站, 2023, 43(9): 2692-2699. |
| [14] | 田悦霖, 黄瑞章, 任丽娜. 融合局部语义特征的学者细粒度信息提取方法[J]. 《计算机应用》唯一官方网站, 2023, 43(9): 2707-2714. |
| [15] | 张秋余, 温永旺. 用于语音检索的三联体深度哈希方法[J]. 《计算机应用》唯一官方网站, 2023, 43(9): 2910-2918. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||